注意,本文最好需要结合上一篇文章阅读,避免文章连贯性不够强,上一篇文章的链接在这里:
1. 逻辑梳理
经过刚刚的总结,我们就可以实现这样一个场景:父进程先创建一个管道,再使用 fork 创建出子进程,父进程为写端,子进程为读端,这样如法炮制来上四个子进程,并且每个父子进程的读写关系都是一样的。另外我们做一个函数数组,用于存放不同的几个任务函数
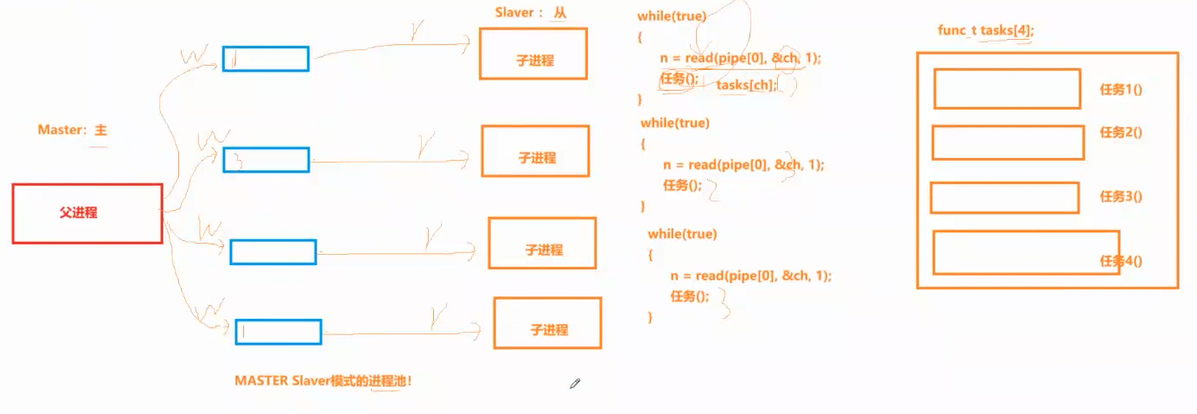
此时在子进程的代码当中,先用变量去接收 read 的返回值,因为我们说如果读端一直在读,但是写端不写的话,那么读端进程就会进入阻塞状态,一旦父进程向对应的管道写入,那么此时对应的读端子进程就会被唤醒,那么就可以根据读到的内容去执行其对应的任务函数。每个子进程通过独立管道阻塞等待父进程下发任务,循环执行任务逻辑,实现进程复用,这就属于一对一管道通信的静态进程池简单模型,或者说叫做:Master Slaver 进程池。
2. 代码编写
2.1 预备工作
那么现在,就让我们来编写一下关于一个简单进程池的代码,首先做好预备工作:
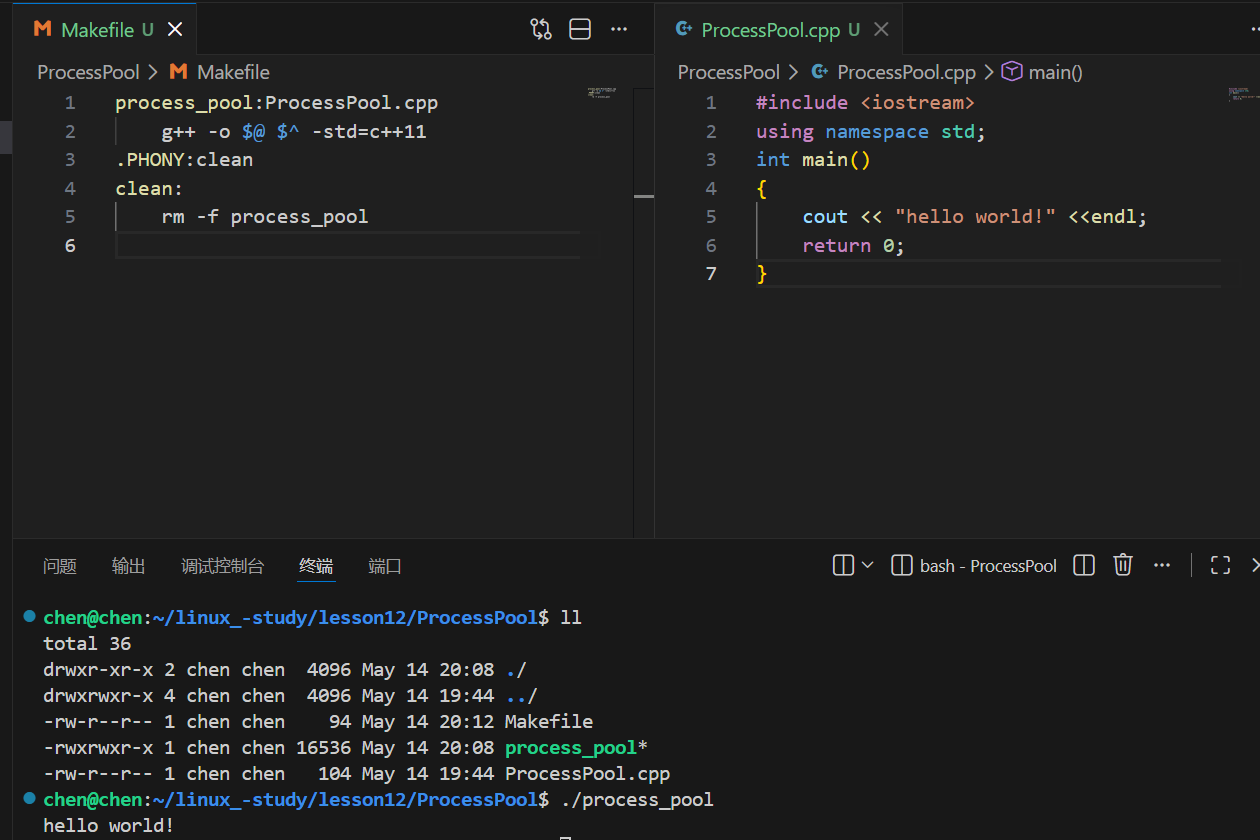
我们创建了一个 ProcessPool.cpp 的文件用于编写我们的代码,另外准备好 Makefile 文件,要注意我们后面在写进程池的时候就要使用C++的代码了,所以Makfile文件里要加上 -std=c++11 代表告诉编译器要使用 C++11 的标准。
2.2 基础框架
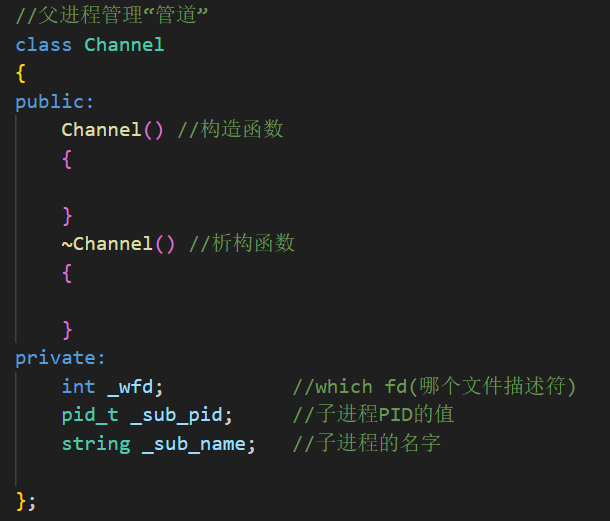
接着我们需要先创建多个进程,并且需要一个类,用来表示管道,我们把它叫做 Channel,这里面要存储的内容最主要的:1.往管道里写,这个管道对应的文件描述符是谁。2. 这个通道对应的子进程是谁:
2.3 创建多进程和多管道
简单的框架搭好了之后,我们先创建管道和子进程:
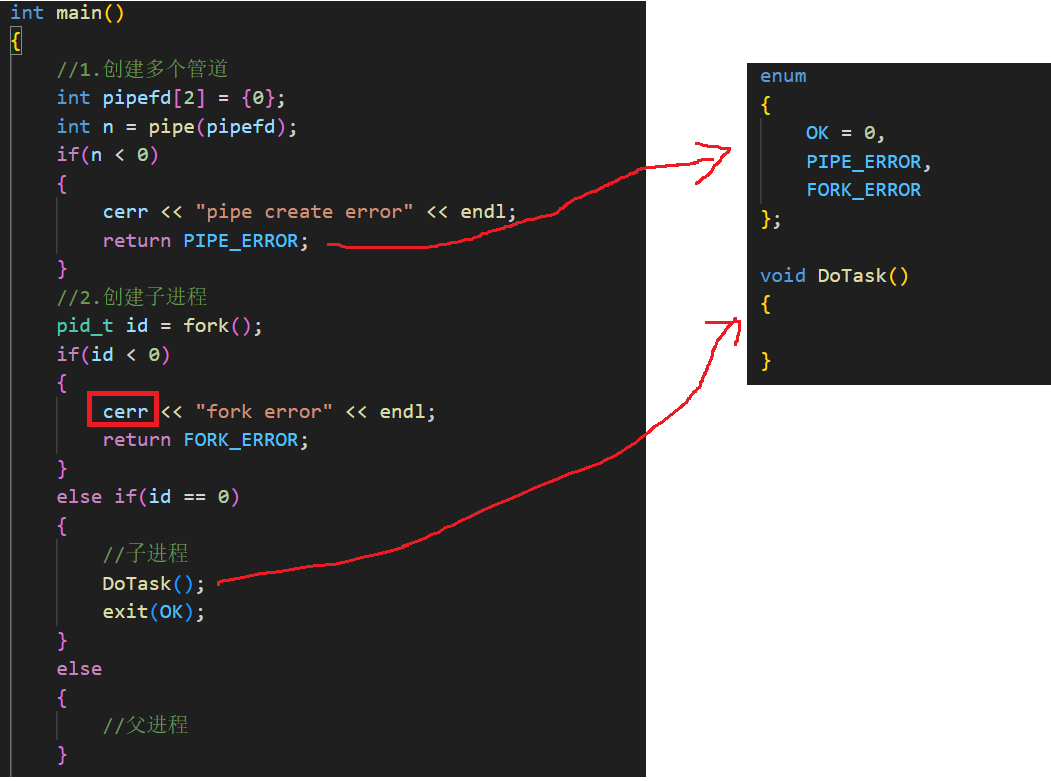
这里之所以使用枚举类型而不是直接返回数字 1 ,是因为 enum 做的事本质是 给数字起 "名字",让数字有含义。代码中enum这个结构体等价于:
cpp
#define OK 0
#define PIPE_ERROR 1如果说直接在代码中返回 1 的话,1 只是一个冷冰冰的数字 ,没有含义 ,你不知道问题到底是管道错?fork 错?参数错? 所以 这叫无语义 。而 PIPE_ERROR 是代表 "管道错误" 的类型 ,自带含义(语义) ,这就叫语义类型。
另外这里用到的 cerr 标准错误输出流 (console error),是 C++ 自带的对象,和 cout 是一对,不过 cerr 只用于报错 ,语义明确,代码可读性更强,同时还有 无缓冲,强制立即输出的特性,错误信息会立刻打印,适合排查系统调用、进程、管道这类底层错误。
接着我们修容一下代码:
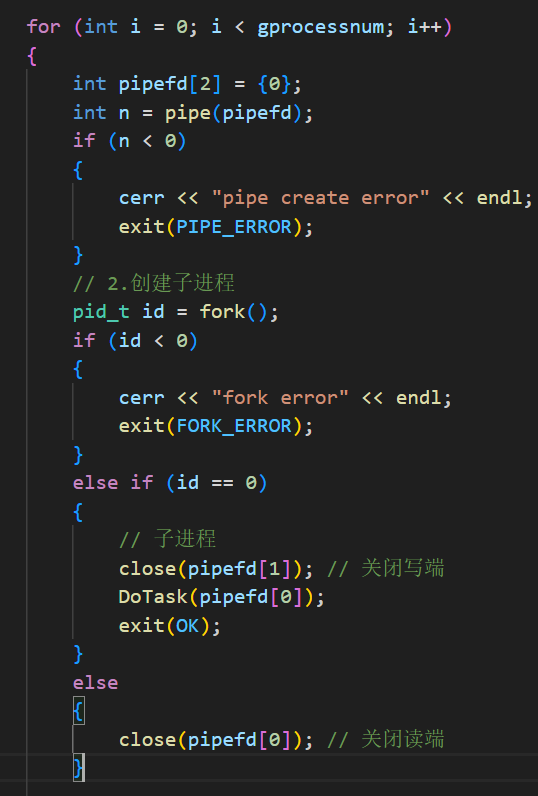
因为刚刚的代码没有套上循环,只是表示一次创建管道和一次创建子进程,我们定义创建的个数变量 gprocessnum ,然后进行循环。既然进入循环了,刚才的 return 我们干脆直接用 exit 。这样就达到了创建多进程的效果。
不过这里有个问题,对于子进程来说,要从读端读数据,在调用DoTask( )的时候可以把 pipefd0 传给函数做参数,形成临时拷贝。但是对于父进程的写端,经过一次循环之后,就会被释放空间,不能达到多管道的效果,所以这里我们还要存储一下管道:
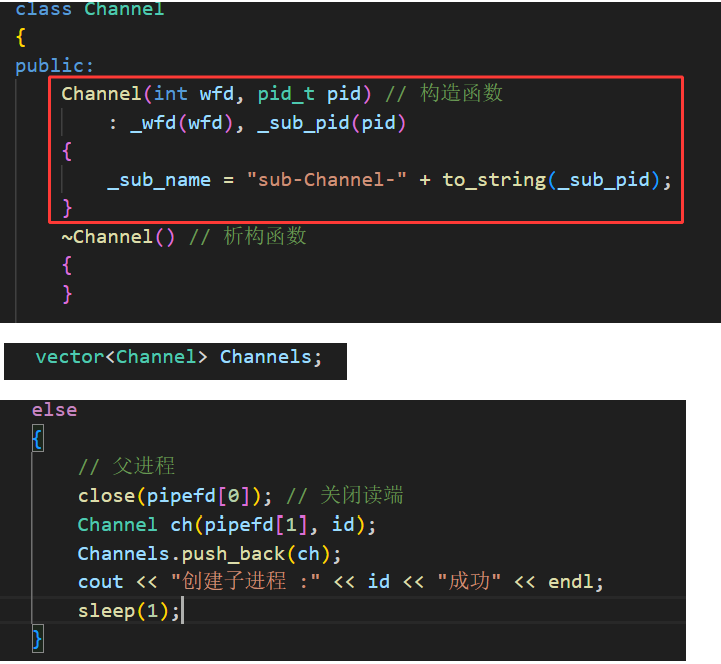
这里我们利用 vector 顺序表去做一个管理 Channel 管道的数组,写出对应的构造函数,其中子进程的名字利用 to_string 函数将 pid 转化成字符,与 sub-Channel- 结合,便于后续直观管理。接着在主函数中,每循环一次就要插入一次该管道。至此,多进程、多管道就已经搭建好了。
我们来测试一下:
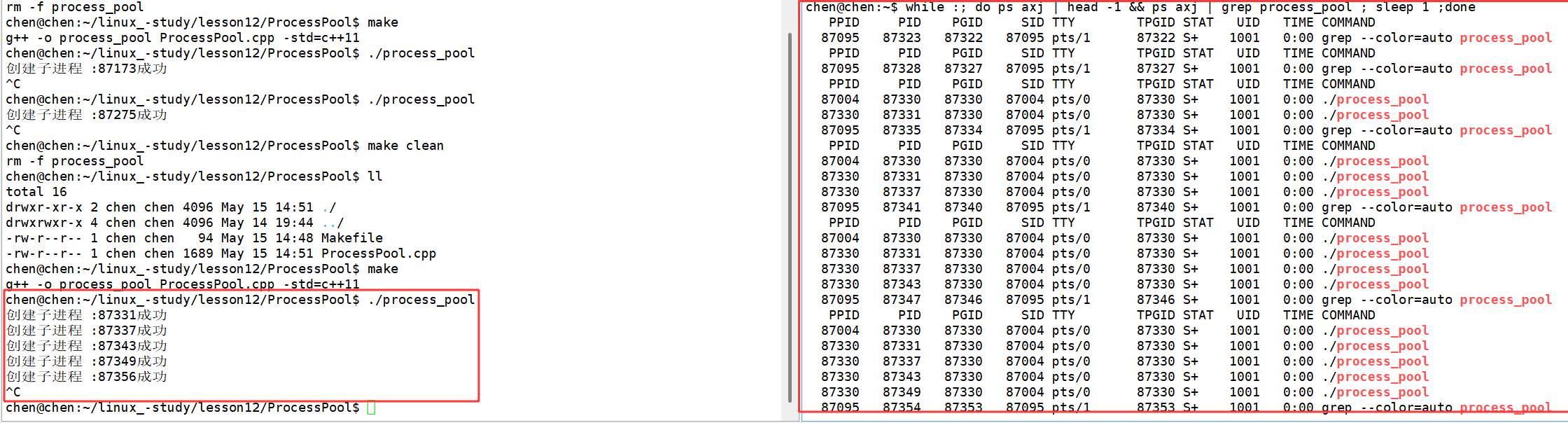
会发现确实创建了多个子进程。
2.4 修缮代码
我们先来看看从父进程这里打印管道和子进程信息:

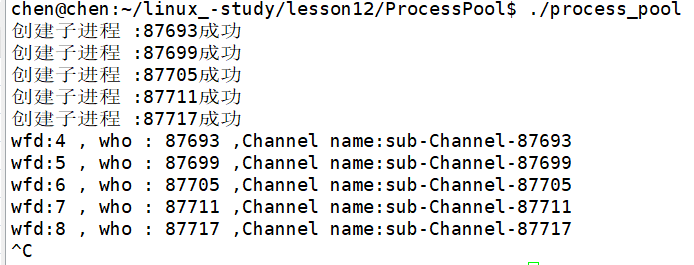
如图所示,我们现在能获取到管道对应的文件描述符,以及对应的进程,和管道名。
在编写父进程控制子进程的代码之前,我们要先修缮一下我们当前的代码, 还有很多改进的地方,我直接展示改进后的代码,然后再逐一分析:
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <vector>
#include <cstdio>
#include <functional>
using namespace std;
//typedef function<void (int)> task_t;
using task_t = function<void (int)>;
enum
{
OK = 0,
PIPE_ERROR,
FORK_ERROR
};
const int gprocessnum = 5;
void DoTask(int fd)
{
while (true)
{
// ssize_t n = read()
sleep(1);
}
}
class ProcessPool
{
public:
// 父进程管理"管道"
class Channel
{
public:
Channel(int wfd, pid_t pid) // 构造函数
: _wfd(wfd), _sub_pid(pid)
{
_sub_name = "sub-Channel-" + to_string(_sub_pid);
}
void PrintInfo()
{
printf("wfd:%d , who : %d ,Channel name:%s\n", _wfd, _sub_pid, _sub_name.c_str());
}
~Channel() // 析构函数
{
}
private:
int _wfd; // which fd(哪个文件描述符)
pid_t _sub_pid; // 子进程PID的值
string _sub_name; // 子进程的名字
};
public:
ProcessPool()
{}
~ProcessPool()
{}
void Debug()
{
for (auto &c : Channels)
{
c.PrintInfo();
sleep(1);
}
}
void Init(task_t cb)
{
CreateProcessandChannel(cb);
}
private:
void CreateProcessandChannel(task_t cb)
{
for (int i = 0; i < gprocessnum; i++)
{
// 1.创建多个管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
{
cerr << "pipe create error" << endl;
exit(PIPE_ERROR);
}
// 2.创建子进程
pid_t id = fork();
if (id < 0)
{
cerr << "fork error" << endl;
exit(FORK_ERROR);
}
else if (id == 0)
{
// 子进程
close(pipefd[1]); // 关闭写端
cb(pipefd[0]); //回调
exit(OK);
}
else
{
// 父进程
close(pipefd[0]); // 关闭读端
Channels.emplace_back(pipefd[1], id);
// Channel ch(pipefd[1], id);
// Channels.push_back(ch);
cout << "创建子进程 :" << id << "成功" << endl;
sleep(1);
}
}
}
private:
// 组织Channel的容器
vector<Channel> Channels;
};
int main()
{
// 创建进程池对象
ProcessPool pp;
// 初始化进程池
pp.Init(DoTask);
// 查看管道与进程信息
pp.Debug();
// 父进程控制子进程
sleep(1000);
return 0;
}我将多进程创建、多管道建立、进程管理、通道管理等所有相关逻辑都封装在一个类中,核心目的是为了模块化、高内聚、低耦合。把进程和管道绑定在一起管理,可以让进程池的结构更清晰,父进程不需要分散维护大量的进程 PID 和管道文件描述符;同时,集中式封装也让外部使用更加简单,只需要创建进程池对象、调用初始化接口、传入任务函数即可完成整个进程池的启动,大幅降低使用成本,也让代码更容易扩展、维护与调试。整体设计既符合系统编程的规范,也遵循 C++ 面向对象的设计思想,让底层逻辑更安全、更健壮、更易于理解。
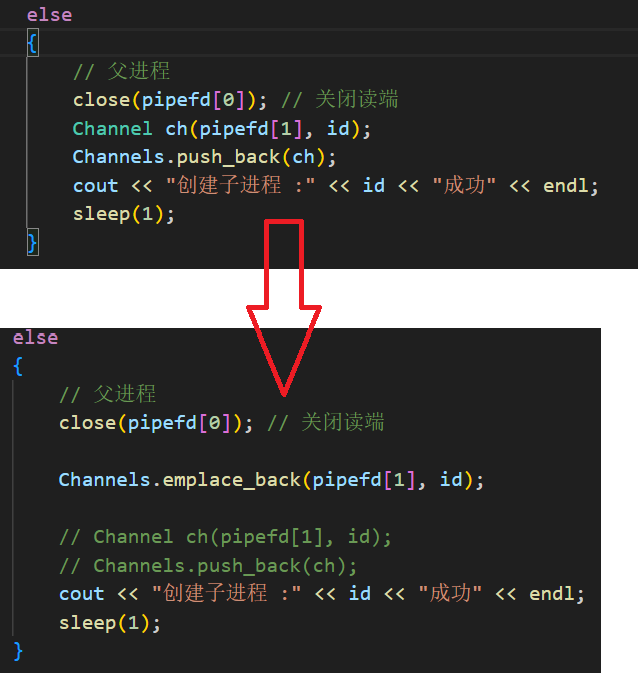
这里我们将原先的,先实例化对象再插入的做法,改成了直接调用 emplace_back ,这样做的原因是因为:emplace_back :直接在容器内部就地构造对象,无需拷贝 / 移动,效率更高,传构造参数即可。而 push_back (已实例化对象):先在外部创建对象,再通过拷贝 / 移动把对象存入容器,多一次拷贝 / 移动开销。
另外还有两个重点:
首先是这里:
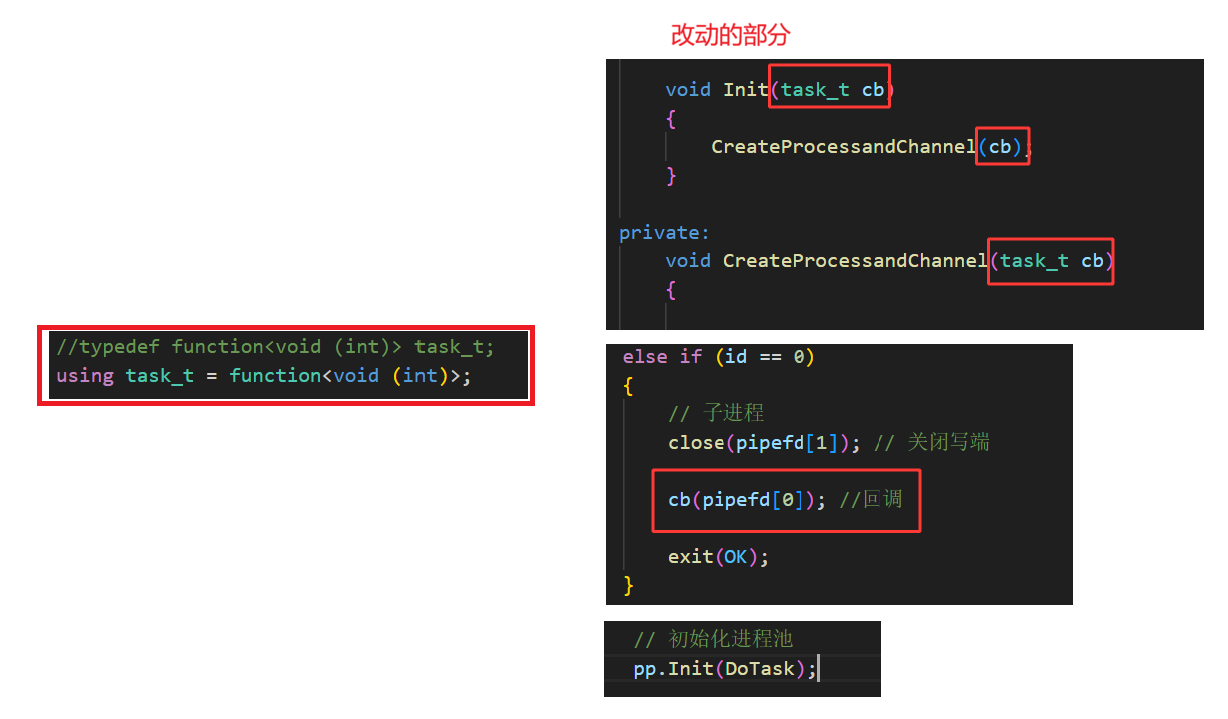
这里的 function<void (int)> 就是一个通用任务类型 ,以 task_t 为别名。两种写法的效果都是一模一样的,只不过第二种是现代写法,typedef是老式写法。最主要的是要看function <> 它是 C++ 的函数包装器类型 ,表示: 可以存放 "接收一个 int、返回 void" 的函数 /lambda/ 可调用对象。不管是 using 还是 typedef ,作用都只是取别名而已。
cpp
typedef 复杂类型 新名字; // 老写法
using 新名字 = 复杂类型; // 新写法(更像赋值,更好懂)大家可以用几个例子先来感受一下函数包装器的作用:
cpp
//绑定普通函数
void myTask(int x) {
printf("任务执行:%d\n", x);
}
// 用法
task_t t = myTask;
t(10); // 调用
cpp
// 绑定捕获外部变量的 Lambda
task_t t = [](int x) {
printf("Lambda 任务:%d\n", x);
};
t(20);
cpp
//放到 vector 里批量存任务
#include <vector>
#include <functional>
vector<task_t> tasks;
// 放任务
tasks.emplace_back([](int x) { printf("任务1:%d\n", x); });
tasks.emplace_back([](int x) { printf("任务2:%d\n", x); });
// 执行
tasks[0](111);
tasks[1](222);
cpp
//作为函数参数传递
void runTask(task_t t) {
t(666);
}
// 使用
runTask([](int x) {
printf("运行任务:%d\n", x);
});而我代码中改动的那几个部分:
用 using task_t = std::function<void(int)> 定义了任务类型;
在 Init(task_t cb)、CreateProcessandChannel(task_t cb) 里,把 task_t 类型的回调函数作为参数传入;
子进程中执行 cb(pipefd[0]),调用这个回调,把管道读端传给任务函数 DoTask;
外部调用 pp.Init(DoTask),传入普通函数,本质是把可调用对象作为参数,传给进程池内部,供子进程执行。
这样的话,在代码中的真实流程就是:
- 外部调用:
cpp
pp.Init(DoTask);-
DoTask这个函数被传进去 -
变成了
cb -
子进程里:
cpp
cb(pipefd[0]);等价于:
cpp
DoTask(pipefd[0]);因此,task_t cb 就是一个 task_t 类型的回调函数参数,用于接收外部传入的任务函数,并在子进程中执行。
而所谓的 " 回调函数 " ,实际上就是 : 你把一个函数 A,传给另一个函数 B,让 B 在合适的时候自动调用 A,A 就叫回调函数。
套进现在的代码里就是:
- 写了任务函数:
void DoTask(int fd)(函数 A) - 你把它传给进程池:
pp.Init(DoTask) - 进程池内部(函数 B)不是立刻调用 ,而是等子进程创建好之后,执行
cb(pipefd[0]),自动调用DoTask
因此, DoTask 就是回调函数 ,而 cb 就是接收这个回调的参数。
2.5 父进程控制子进程
如果要实现父进程控制子进程的效果,要分三个步骤:第一步,先选择一个Channel,指定你要哪个子进程去工作。第二步,选择你要让该进程执行哪一个任务,因此我们还需要去封装一个管理任务的数组。第三步,发布该任务给目标管道。
为了避免大家看的混乱难以理解,我们先重新去梳理一下前面的代码逻辑:
创建多管道和多进程的细节就不展开了,重点看 CreateProcessandChannel 这个函数里父子进程各自做了什么。
父进程这边,关闭读端后,往 Channels 这个 vector<Channel> 容器里插入了五个新的 Channel。Channel 本质就是用来管理管道和对应子进程的,构造时传入管道写端和子进程 pid,这样一个 Channel 就分配好了。
子进程最关键的动作是 cb(pipefd[0]) 这句,它的本质就是调用 DoTask(pipefd[0]),也就是回调函数。
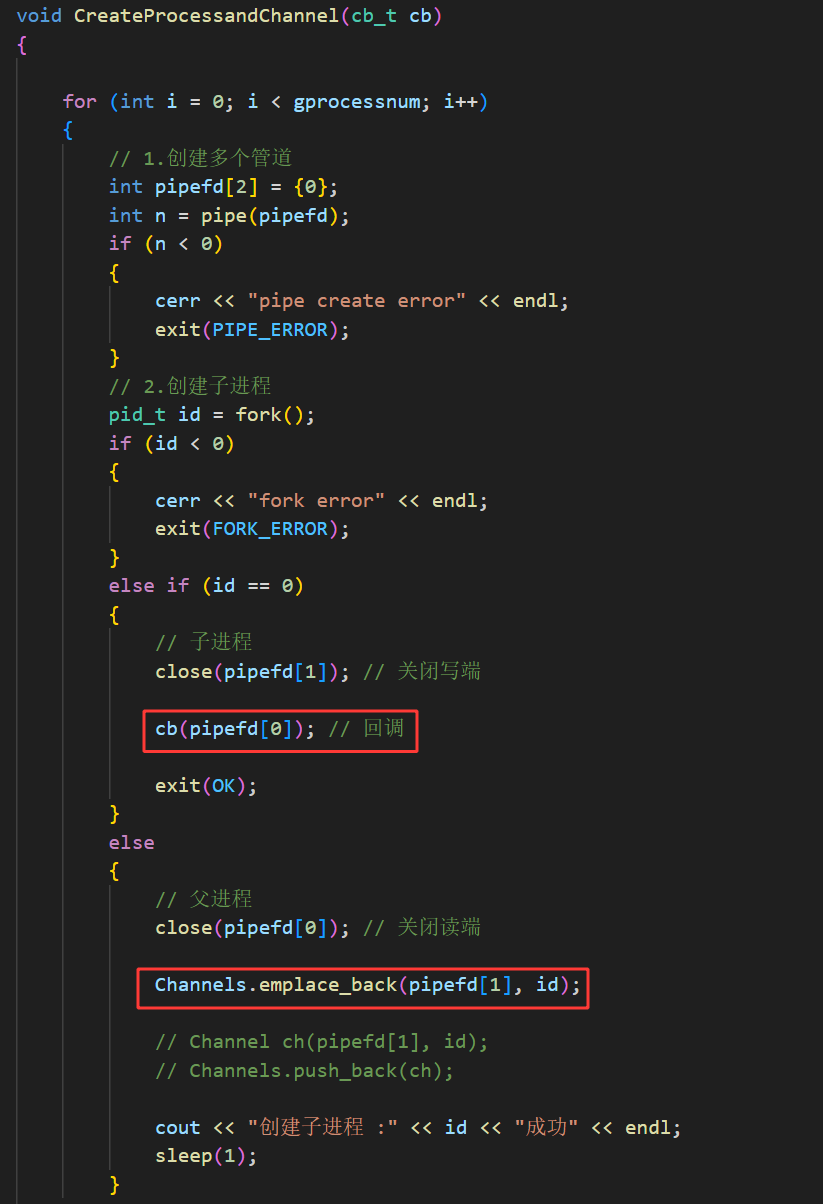
DoTask 里有一个 task_code 变量,用来记录要执行的任务下标。我们把四个任务封装在 tasks 数组里,数组类型是 task_t,它是一个返回 void、参数为空的函数指针类型。
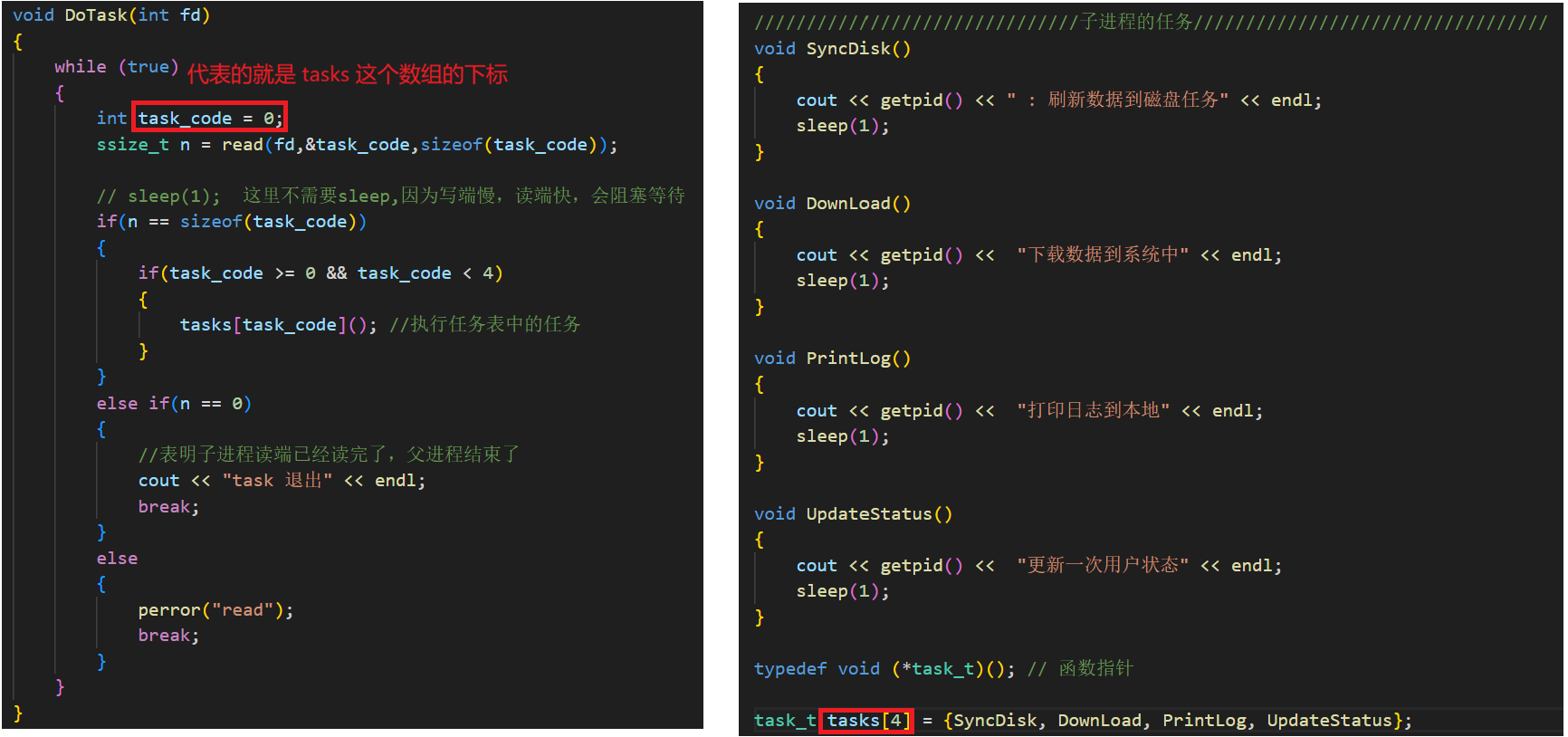
DoTask 内部调用 read,从文件描述符 fd(其实就是 pipefd[0],子进程的读端)中读取 sizeof(task_code) 个字节,存到 &task_code 这个地址上。这样一来,task_code 就能拿到要执行的任务数组下标了。
不过此时的 read 是阻塞住的,因为到目前为止父进程还没往写端(pipefd[1])写入任何数据。所以 CreateProcessandChannel 里的任务,也就是 pp.Init(DoTask) 这句,暂时就执行到这里。
接下来是 pp.Run()。
要让父进程控制子进程干活,就得先确定用哪一个 Channel 和执行哪一个任务。选择 Channel 时,调用了 SelectChannel 函数,这里采用按顺序轮询的方式,从 Channels 容器里依次取出一个下标。
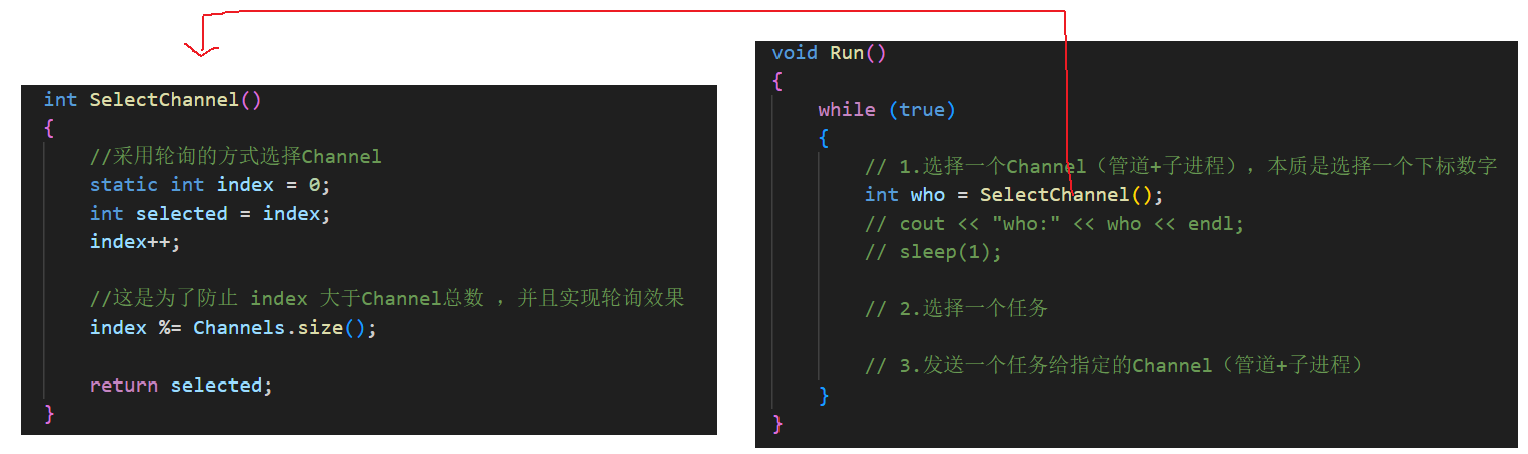
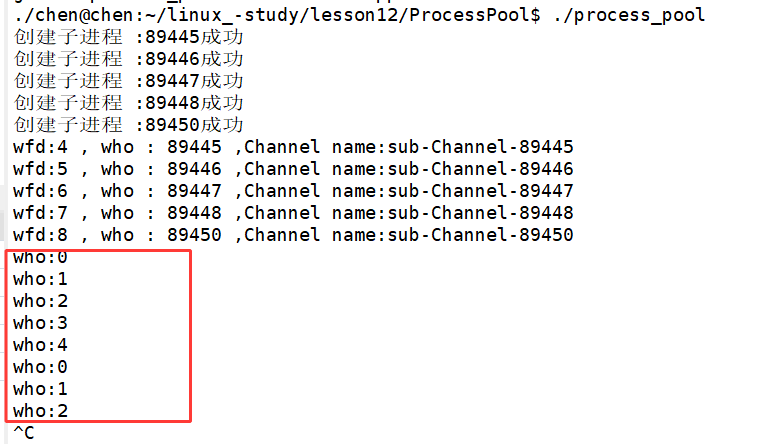
选择任务时,调用了 SelectTask 函数,采用随机选取,用到了 rand()。rand() 需要随机种子,所以早在主函数开始、实例化 ProcessPool 对象 pp 的时候,构造函数里就已经调用了 srand((unsigned int)time(nullptr) ^ getpid()) 来设置种子。

至此,我们指定的 Channel(who)和要执行的任务(itask)就准备好了。接着调用 SendTask_to_Slaver(itask, who),它最主要的工作是让下标为 who 的这个 Channel 去执行 Write(itask)。Write 内部调用 write 系统调用,把 itask 这个任务下标写到 Channel[who] 对应的 _wfd 中,也就是往该管道里写入要执行的任务编号,同时也间接指定了由哪个子进程去处理。
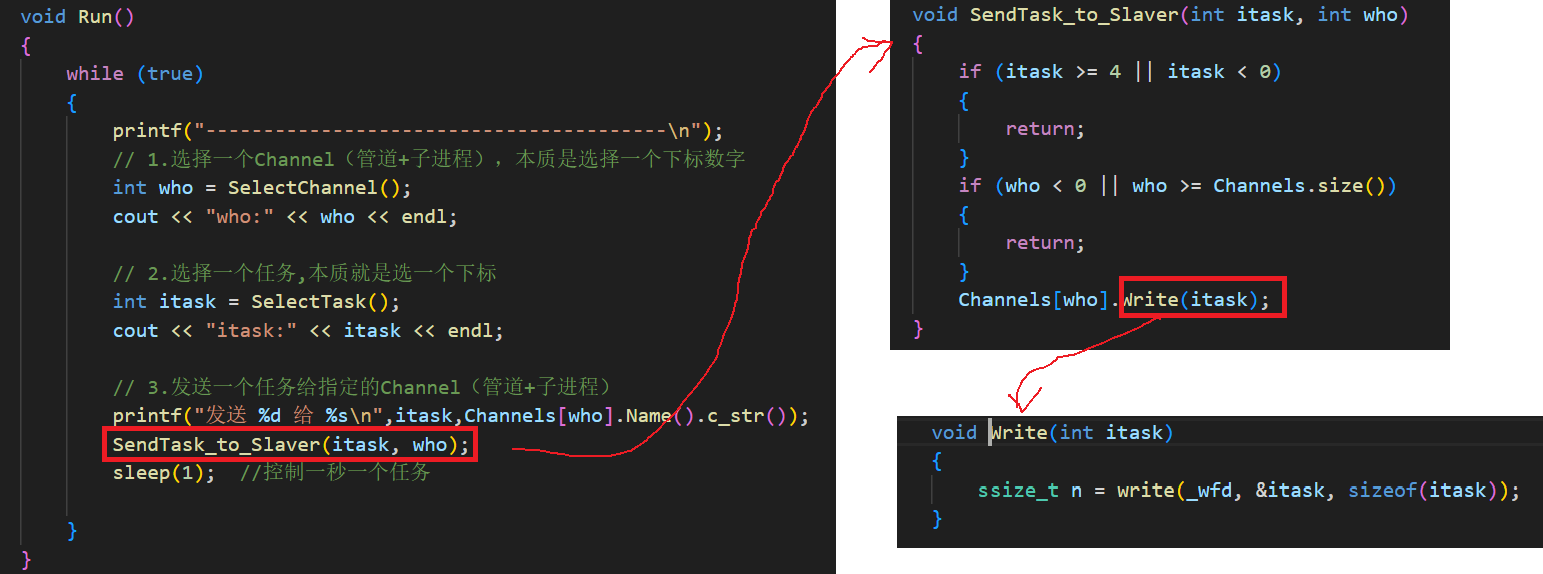
于是逻辑又回到了子进程之前卡住的地方------DoTask 里的 read。现在管道里有数据了,read 就能读到内容,task_code 接收到的正是 itask 的值,接着通过 tasks[task_code]() 这种函数指针的调用方式,去执行对应的任务函数。
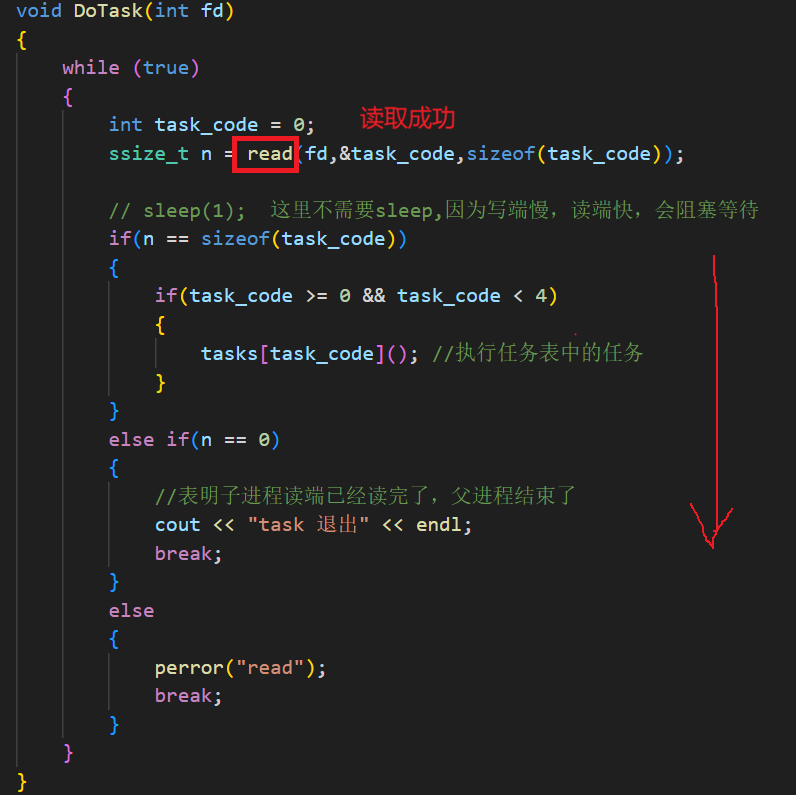
至此,整个代码逻辑就串起来了。
2.6 释放空间和回收资源
首先要明确,子进程的生命周期完全依赖于管道读端的状态,在DoTask函数中,我们对read的返回值做了严格判断,当read的返回值为 0 时,就会直接退出循环,结束子进程,而 read 只有一种情况会返回 0:管道的所有写端都被关闭了(数据读完了 + 不会再有新数据)
父进程创建了 5 个子进程和 5 条独立管道,每一条管道都只有父进程持有唯一的写端,子进程只持有读端,当我们让父进程直接退出时,操作系统会自动回收父进程占用的所有资源,其中就包括父进程持有的全部管道写端文件描述符,这一步是操作系统内核自动完成的,不需要我们手动调用close。
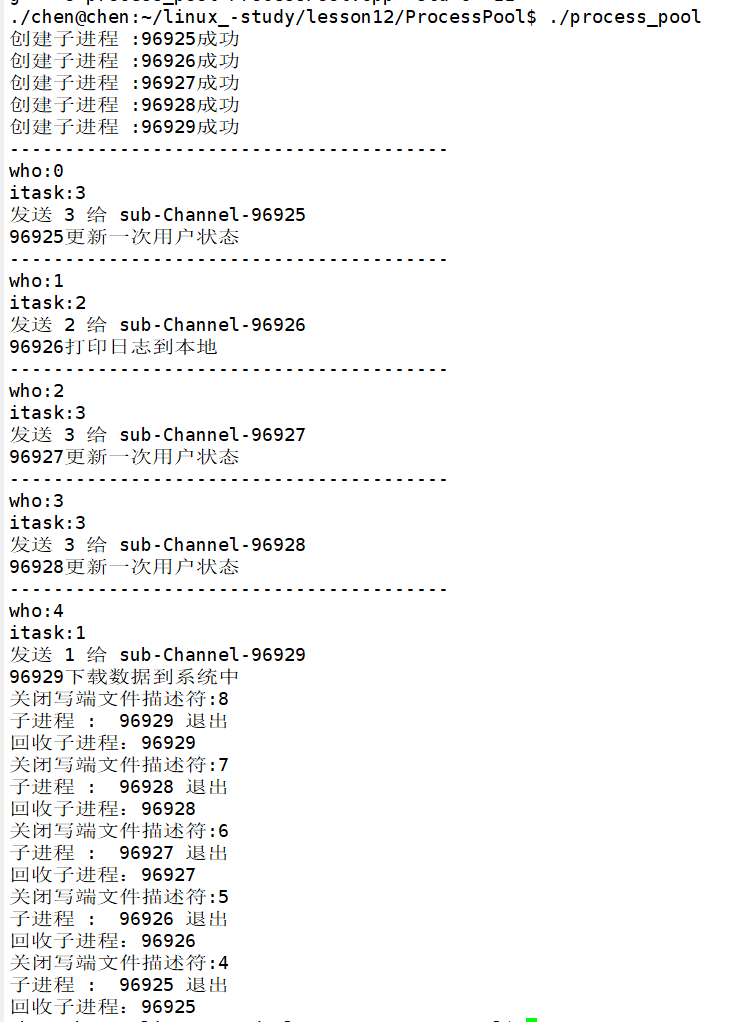
父进程将所有管道的写端被彻底关闭,此时子进程中阻塞的read函数会立刻解除阻塞,并且返回 0,子进程感知到这个状态后,就会执行cout << "task 退出" << endl;然后跳出循环,DoTask函数执行完毕,子进程随之调用exit(OK)正常退出。
至此,所有子进程都会因为父进程关闭管道写端这个机制,同步自动退出,此时父进程再对关闭的子进程进行回收,避免僵尸进程产生,最后退出父进程,整个进程池会完全解散。
简单来说,父进程是所有管道写端的唯一持有者,父进程将所有管道写端关闭 = 子进程的read返回 0 = 子进程自动退出 = 所有资源被系统回收,因此,只需要让父进程将所有管道写端关闭,再退出父进程,整个进程池就会干净、完整地完成所有收尾工作。
那我们就来执行这个操作:

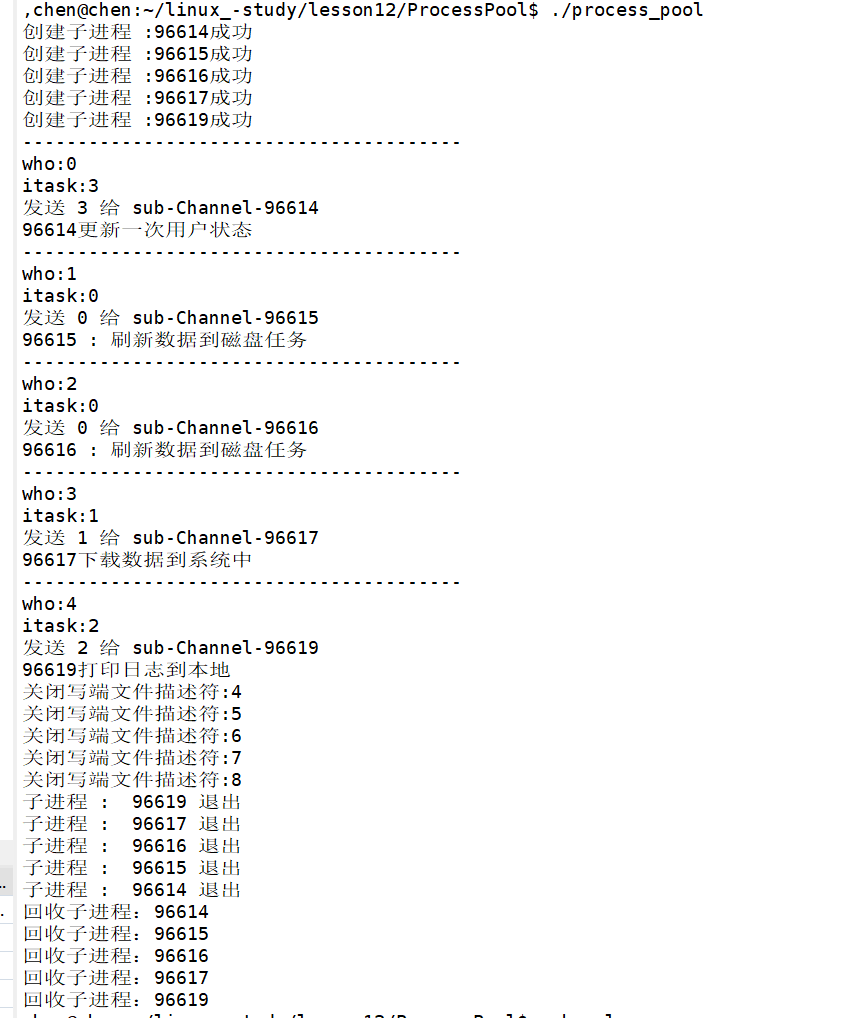
至此,我们的代码逻辑到目前为止,看上去是没有问题的。
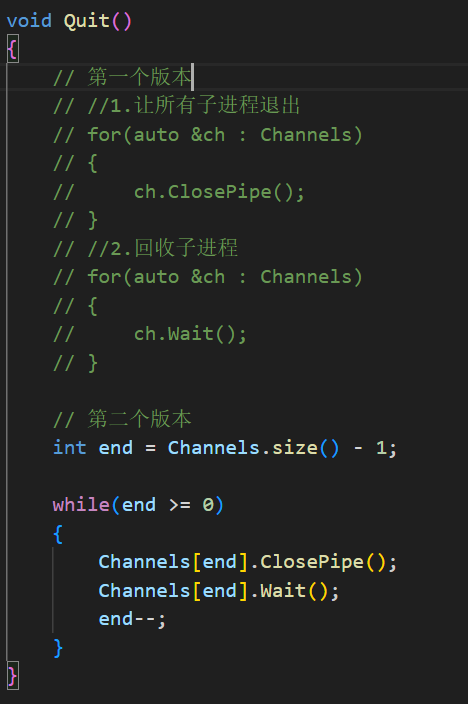
但是这时候就有人要问了,说:作者作者,你这边退出和回收的工作,使用了两次范围 for ,都是去遍历 Channels 这个数组,这不是脱裤子放屁多此一举吗,直接把 ch.Wait() 也写到第一个循环里好了呗,这样还能提高效率。
那么好,我们这样做一下试试:
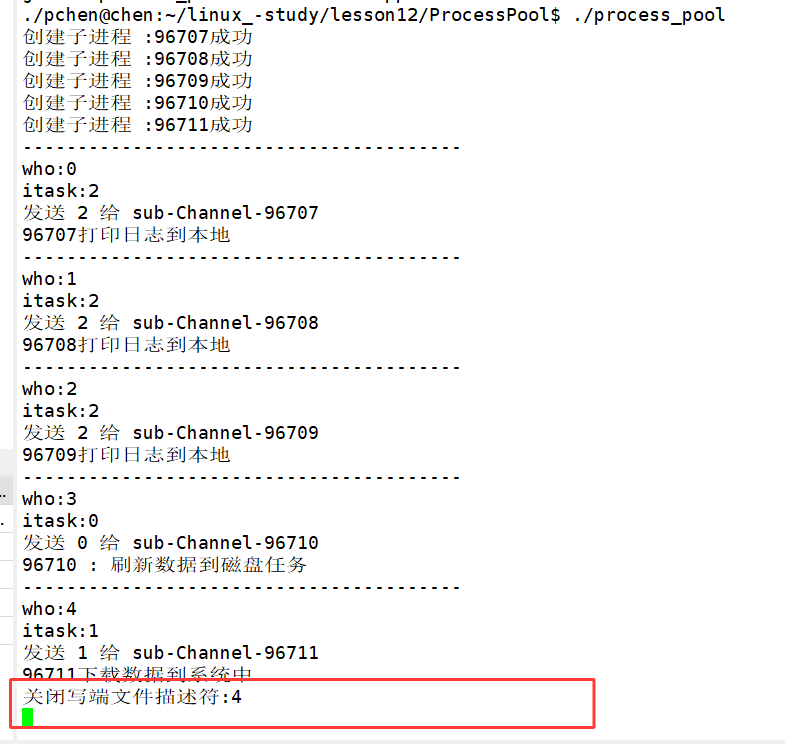
我们会发现,如果这样写的话,程序在运行到关闭描述符的时候就直接卡住不动了。这是怎么回事儿?
我们去剖析一下我们在创建管道和子进程时候的逻辑:
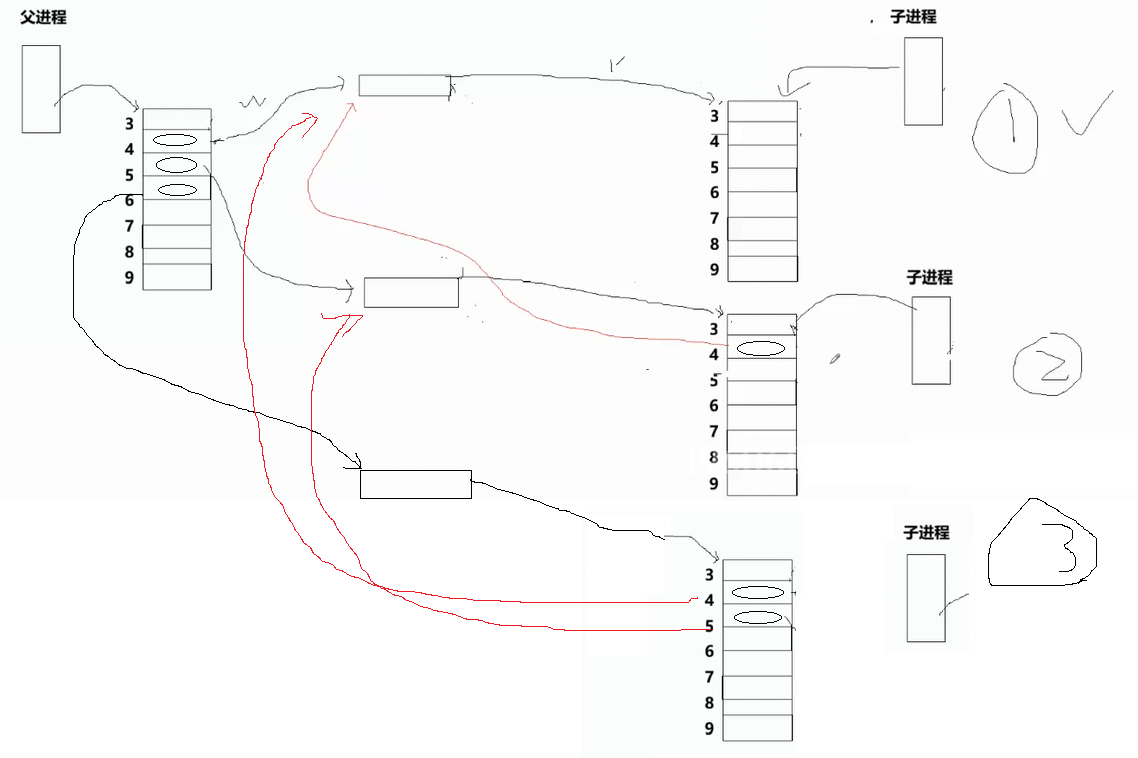
当父进程调用pipe创建管道时,会打开一对文件描述符,例如读端 3、写端 4;随后调用fork()创建子进程,为实现单向通信,父进程关闭读端 3,父进程的 3 号文件描述符空置;子进程关闭写端 4,子进程的 4 号文件描述符空置。
当再次调用pipe创建新管道时,系统会分配当前最小可用的文件描述符,即读端 3、写端 5,此时父进程的 4 号文件描述符依然有效,指向第一条管道的写端;再次fork()创建二号子进程,子进程会完整拷贝父进程的文件描述符表,因此二号子进程的 4 号文件描述符,同样指向第一条管道的写端。以此类推,每一个后续创建的子进程,都会继承前面所有管道的写端文件描述符。
这就会出现一个关键问题:第一条管道,会被后面 4 个子进程额外持有 4 个写端;第二条管道,会被后面 3 个子进程额外持有 3 个写端...... ,只有最后一个子进程,只持有自己专属管道的一对读写端。 如果我们按照正序,关闭第一个管道的父进程写端后立刻调用Wait()执行waitpid阻塞回收,此时第一条管道的其他 4 个写端,还被后面的子进程持有,并未全部关闭 。管道的所有写端没有全部关闭,子进程里的read就不会返回 0,会一直阻塞等待数据,直接导致父进程的waitpid卡死。
想要解决这个问题,就必须逆序关闭、逆序回收 :从最后创建的子进程开始,依次关闭管道写端、回收子进程。因为最后创建的第五个子进程,它的文件描述符表里持有前面 4 条管道的全部写端,当逆序关闭它时,这些残留的写端会被一并释放;每关闭一个子进程,对应管道的所有残留写端都会被清理,最终保证每条管道的全部写端真正关闭 ,子进程的read正常返回 0,父进程顺利回收,彻底解决卡死问题。
不过,除了逆序回收这个方法,我们还可以采用第三个办法:修改创建子进程中的部分逻辑。因为归根到底,之所以我们刚刚正序关闭和回收会失败,是因为子进程拷贝的时候会把父进程的一些打开的文件描述符也带过来,所以我们只需要把这些没有用的文件描述符给关掉即可:
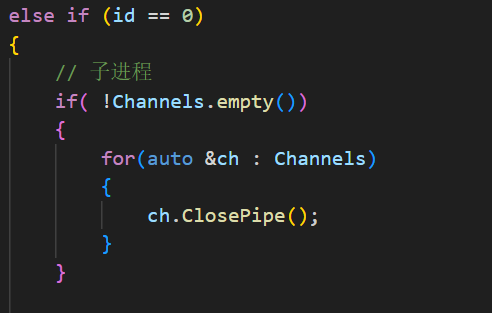
这里在子进程创建瞬间,主动清理掉从父进程继承过来的、其他管道的多余写端,保证每条管道只有父进程 1 个写端,从根源上解决管道写端关闭不干净、程序卡死的问题。因为是在子进程的 if 判断语句里,这里调用的 ch.ClosePipe 也只是子进程在操作,ClosePipe的本质是调用close函数关闭当前的 _wfd ,因为是子进程在操作,所以自动带入的是子进程的_wfd,对父进程没有影响。
至此,我们的简单进程池就编写完了,下面展示所有代码:
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <vector>
#include <cstdio>
#include <functional>
#include <cstdlib>
#include <ctime>
#include <sys/wait.h>
using namespace std;
///////////////////////////////子进程的任务//////////////////////////////////
void SyncDisk()
{
cout << getpid() << " : 刷新数据到磁盘任务" << endl;
sleep(1);
}
void DownLoad()
{
cout << getpid() << "下载数据到系统中" << endl;
sleep(1);
}
void PrintLog()
{
cout << getpid() << "打印日志到本地" << endl;
sleep(1);
}
void UpdateStatus()
{
cout << getpid() << "更新一次用户状态" << endl;
sleep(1);
}
typedef void (*task_t)(); // 函数指针
task_t tasks[4] = {SyncDisk, DownLoad, PrintLog, UpdateStatus};
////////////////////////////////进程池相关///////////////////////////////////
enum
{
OK = 0,
PIPE_ERROR,
FORK_ERROR
};
const int gprocessnum = 5;
void DoTask(int fd)
{
while (true)
{
int task_code = 0;
ssize_t n = read(fd,&task_code,sizeof(task_code));
// sleep(1); 这里不需要sleep,因为写端慢,读端快,会阻塞等待
if(n == sizeof(task_code))
{
if(task_code >= 0 && task_code < 4)
{
tasks[task_code](); //执行任务表中的任务
}
}
else if(n == 0)
{
//表明子进程读端已经读完了,父进程结束了
printf("子进程 : %d 退出\n",getpid());
break;
}
else
{
perror("read");
break;
}
}
}
// typedef function<void (int)> task_t;
using cb_t = function<void(int)>;
class ProcessPool
{
public:
// 父进程管理"管道"
class Channel
{
public:
Channel(int wfd, pid_t pid) // 构造函数
: _wfd(wfd), _sub_pid(pid)
{
_sub_name = "sub-Channel-" + to_string(_sub_pid);
}
void PrintInfo()
{
printf("wfd:%d , who : %d ,Channel name:%s\n", _wfd, _sub_pid, _sub_name.c_str());
}
~Channel() // 析构函数
{
}
void ClosePipe()
{
cout << "关闭写端文件描述符:" << _wfd <<endl;
close(_wfd);
}
void Wait()
{
pid_t rid = waitpid(_sub_pid,nullptr,0);
(void)rid;
cout << "回收子进程:" << _sub_pid << endl;
}
void Write(int itask)
{
ssize_t n = write(_wfd, &itask, sizeof(itask));
}
string Name()
{
return _sub_name;
}
private:
int _wfd; // which fd(哪个文件描述符)
pid_t _sub_pid; // 子进程PID的值
string _sub_name; // 子进程的名字
};
public:
ProcessPool()
{
srand((unsigned int)time(nullptr) ^ getpid());
}
~ProcessPool()
{
}
void Quit()
{
// 第一个版本
// //1.让所有子进程退出
// for(auto &ch : Channels)
// {
// ch.ClosePipe();
// }
// //2.回收子进程
// for(auto &ch : Channels)
// {
// ch.Wait();
// }
// // 第二个版本
// int end = Channels.size() - 1;
// while(end >= 0)
// {
// Channels[end].ClosePipe();
// Channels[end].Wait();
// end--;
// }
//第三个版本
for(auto &ch : Channels)
{
ch.ClosePipe();
ch.Wait();
}
}
void Debug()
{
for (auto &c : Channels)
{
c.PrintInfo();
sleep(1);
}
}
void Init(cb_t cb)
{
CreateProcessandChannel(cb);
}
void Run()
{
int cnt = 5;
while (cnt--)
{
printf("----------------------------------------\n");
// 1.选择一个Channel(管道+子进程),本质是选择一个下标数字
int who = SelectChannel();
cout << "who:" << who << endl;
// 2.选择一个任务,本质就是选一个下标
int itask = SelectTask();
cout << "itask:" << itask << endl;
// 3.发送一个任务给指定的Channel(管道+子进程)
printf("发送 %d 给 %s\n",itask,Channels[who].Name().c_str());
SendTask_to_Slaver(itask, who);
sleep(1); //控制一秒一个任务
}
}
private:
void SendTask_to_Slaver(int itask, int who)
{
if (itask >= 4 || itask < 0)
{
return;
}
if (who < 0 || who >= Channels.size())
{
return;
}
Channels[who].Write(itask);
}
int SelectTask()
{
// 采用随机方法选择任务
// 其实就是随机选择 0~3 中的一个
int itask = rand() % 4;
return itask;
}
int SelectChannel()
{
// 采用轮询的方式选择Channel
static int index = 0;
int selected = index;
index++;
// 这是为了防止 index 大于Channel总数 ,并且实现轮询效果
index %= Channels.size();
return selected;
}
void CreateProcessandChannel(cb_t cb)
{
for (int i = 0; i < gprocessnum; i++)
{
// 1.创建多个管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
{
cerr << "pipe create error" << endl;
exit(PIPE_ERROR);
}
// 2.创建子进程
pid_t id = fork();
if (id < 0)
{
cerr << "fork error" << endl;
exit(FORK_ERROR);
}
else if (id == 0)
{
// 子进程
if( !Channels.empty())
{
for(auto &ch : Channels)
{
ch.ClosePipe();
}
}
close(pipefd[1]); // 关闭写端
cb(pipefd[0]); // 回调
exit(OK);
}
else
{
// 父进程
close(pipefd[0]); // 关闭读端
Channels.emplace_back(pipefd[1], id);
// Channel ch(pipefd[1], id);
// Channels.push_back(ch);
cout << "创建子进程 :" << id << "成功" << endl;
sleep(1);
}
}
}
private:
// 组织Channel的容器
vector<Channel> Channels;
};
int main()
{
// 创建进程池对象
ProcessPool pp;
// 初始化进程池
pp.Init(DoTask);
// 查看管道与进程信息
//pp.Debug();
// 父进程控制子进程
pp.Run();
//释放和回收资源
pp.Quit();
return 0;
}本文到此结束,感谢各位读者的阅读,如果有讲解的错误或者不到位的地方,欢迎各位读者批评或指正。