一、系统设计入门
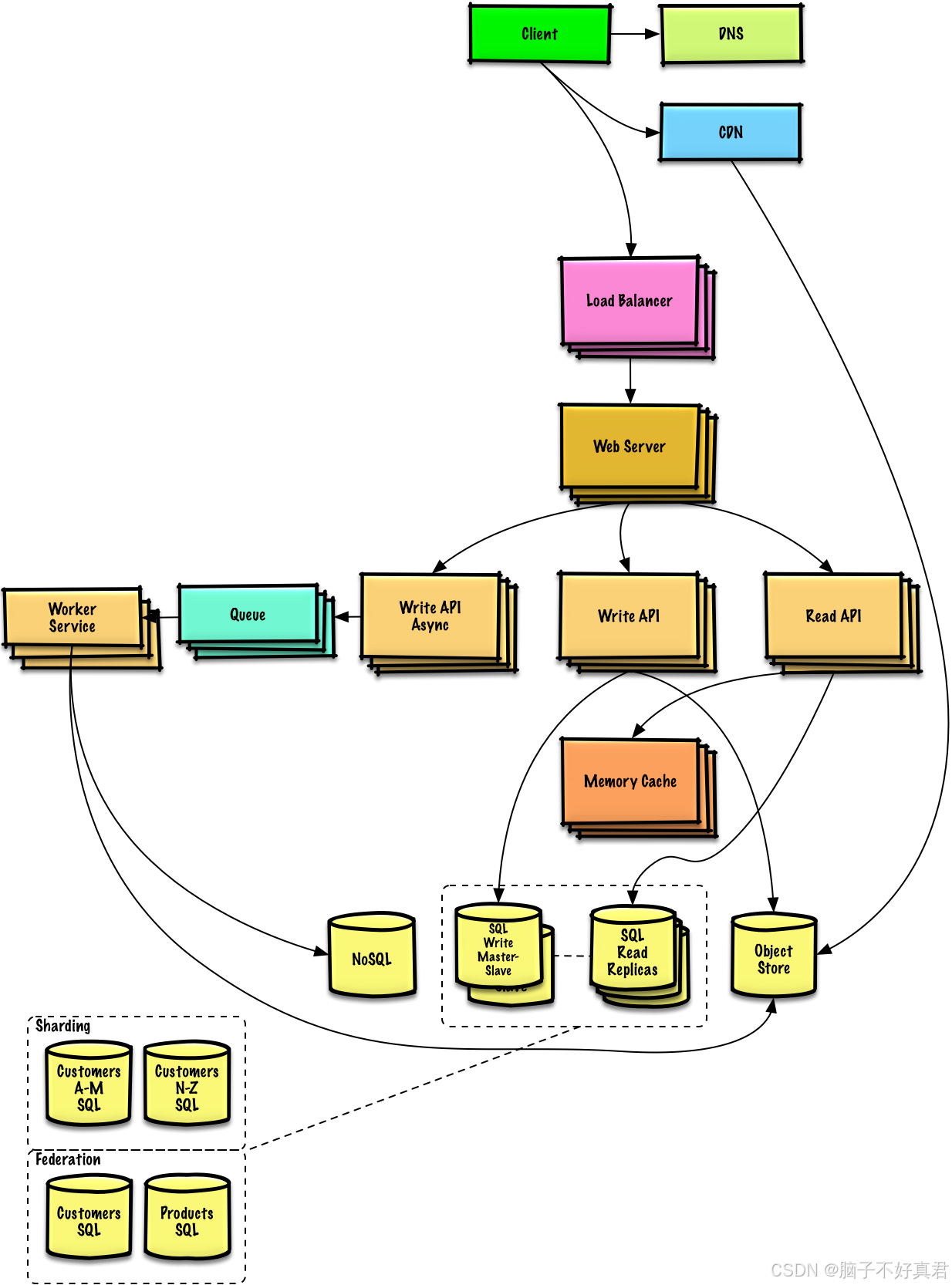
图:这是一个经典的Web系统架构图(High-Level System Architecture Diagram) 。它展示了一个为了实现高可用性(High Availability)和水平扩展(Horizontal Scaling)而设计的现代化互联网应用后端架构。
这张图主要展示了请求从客户端发出,到数据存储和异步处理的完整生命周期。
1. 核心节点
a. 接入层 (The Gateway)
这是系统的最外端,负责将用户请求引导至正确的服务器。
DNS: 负责域名解析,将网址指向服务器 IP。
CDN (内容分发网络): 在离用户最近的节点缓存静态资源(如图片、JS、CSS),减轻主服务器压力并降低延迟。
Load Balancer (负载均衡器): 系统的"交通警察"。它将海量流量均匀分配给后端的多个 Web Server,防止单台服务器过载。
b. Web 层 (Web Server)
- Web Server: 接收来自负载均衡器的请求,负责简单的逻辑处理、身份验证或将请求转发给下游的 API。
c. 应用逻辑层 (API Layer)
图中展现了读写分离 和同步/异步的思想:
Read API: 专门处理查询请求。
Write API: 专门处理数据修改请求。
Write API Async (异步写入): 这是提升性能的关键。
请求不是直接入库,而是先丢给 Queue (消息队列)。
Worker Service (工作服务) 异步地从队列中取出任务慢慢处理。
作用: 削峰填谷,避免数据库在写入高峰期崩溃。
d. 缓存层 (Caching Tier)
- Memory Cache (内存缓存): 位于 API 和数据库之间(通常是 Redis 或 Memcached)。它存储高频访问的数据,因为读取内存的速度远快于读取磁盘,能极大提升响应速度。
e. 数据存储层 (Data Tier)
这是图中最复杂的部分,展示了多种存储方案的并存:
SQL Write Master-Slave (主从架构):
Master (主库): 负责写操作。
Read Replicas (从库/只读副本): 负责读操作。通过主从同步,实现读写分离。
NoSQL: 存储非结构化或半结构化数据,适合极高并发和灵活的数据模型。
Object Store (对象存储): 用于存储大文件(如 PDF 文档、用户头像、视频文件)。
Sharding (数据库分片):
图中左下角的 Customers A-M / N-Z SQL 展示了水平分片。
当一个数据库放不下所有用户时,按首字母或 ID 将数据分散到不同的物理数据库中。
Products SQL : 展示了垂直分片,即按业务模块(如产品、用户)拆分数据库。
2.用户访问流程解析
第一阶段:接入与资源获取(Initial Entry)
域名解析(DNS) : 用户在浏览器输入网址,首先向 DNS 发起请求,将人类可读的域名转换为服务器的 IP 地址。
静态加速(CDN) : 用户请求网页的图片、样式表(CSS)、脚本(JS)或数字人模型文件。请求会被路由至地理位置最近的 CDN 节点。如果节点已有缓存,直接返回给用户,无需惊动后端服务器。
第二阶段:进入核心基础设施(Entry into Infrastructure)
负载均衡(Load Balancer) : 经过 DNS 解析后,用户的动态请求(如登录、提交数据)到达 Load Balancer 。它根据预设算法(如轮询或最小连接数),将请求转发给某一台健康的 Web Server。
业务接入(Web Server) : Web Server 接收请求,进行初步的处理。这包括:
身份验证:检查用户 Token 是否有效。
请求路由:判断该请求属于"读操作"还是"写操作",并分发给下游相应的 API。
第三阶段:执行具体操作(Choose Your Action)
根据用户的操作意图,流程会进入三个不同的分支:
分支 A:查询操作(如:查看文书列表、搜索法律词条)
API 调度 :请求进入 Read API。
缓存优先 :Read API 首先访问 Memory Cache(如 Redis)。
命中:直接返回数据,速度极快。
未命中 :Read API 转向 SQL Read Replicas(只读从库)提取数据,并回写至缓存以便下次使用。
分支 B:实时写入操作(如:修改个人资料、保存设置)
API 调度 :请求进入 Write API。
数据落库 :数据直接写入 SQL Write Master (主库)。随后,主库会自动将更新同步到 SQL Read Replicas,确保后续读取的一致性。
分支 C:耗时任务/高并发写入(如:生成复杂的劳务仲裁文书、处理大批量数据)
异步调度 :请求进入 Write API Async。
任务缓冲 :API 并不直接处理,而是将任务封装成消息丢进 Queue(消息队列)。此时系统会立即给用户返回"处理中"的状态,避免前端卡死。
后台处理 :Worker Service 监控队列,按顺序取出任务并执行耗时运算(例如调用 AI 模型生成内容)。
结果保存 :Worker 完成任务后,将结果存入 Master DB。
第四阶段:多样化数据持久化(Data Persistence)
在处理上述操作时,系统会根据数据类型选择不同的存储方案:
非结构化数据 :如用户的实时对话记录、非关系型的日志,存储在 NoSQL 数据库中。
大规模用户数据 :如果用户量极大,系统通过 Sharding (分片)逻辑,根据用户 ID 将数据存入 Customers A-M 或 N-Z 的物理分库中。
大文件存储 :如果用户生成了 PDF 文书或录制了视频,文件流会被上传至 Object Store(对象存储),而数据库中仅记录该文件的下载 URL。
流程总结
核心逻辑:
读操作 :走 CDN -> LB -> Read API -> Cache -> Read Replicas。快字当头。
写操作 :走 LB -> Write API -> Master DB。稳字当头。
重操作 :走 LB -> Async API -> Queue -> Worker -> DB。稳健削峰。
3.疑问
(1)为什么要设计得这么复杂?
这种架构的核心目标是:
高可用性 (High Availability): 任何一个组件(如负载均衡器或数据库从库)挂掉,系统依然能运行。
高扩展性 (Scalability): 用户增加时,只需增加 Web Server 或 Read Replicas 即可,无需改动核心代码。
高性能 (Performance): 通过 CDN、Cache 和读写分离,确保用户在毫秒级得到响应。
(2)为什么同一层既有Write API Async又有Write API?
1. Write API (同步写入):追求"即时反馈"
这是传统的写入方式。当客户端发起请求时,API 会一直等到数据成功写入数据库后才返回响应。
特点: 强一致性。返回成功时,数据一定已经在硬盘里了。
适用场景:
关键设置修改: 比如修改登录密码、开启二次验证。用户需要立刻确认修改成功,否则会感到不安。
金钱交易: 账户余额扣除、订单扣款。这类操作不能容忍"晚点再说",必须在当前事务中完成。
强依赖后续操作: 如果下一步操作必须依赖上一步的结果,则必须同步。
2. Write API Async (异步写入):追求"高并发与解耦"
这种方式通常结合图中的 Queue (消息队列) 使用。API 接收到请求后,只需将任务"丢"进队列,然后立刻给用户返回一个"任务已受理"的信号。
特点: 最终一致性。用户看到成功时,数据可能还在排队处理中。
适用场景:
耗时任务: 比如用户上传一张高清头像,系统需要生成 3 种不同尺寸的缩略图。如果同步处理,用户可能要盯着转圈圈看 5 秒;异步处理则可以让用户立刻跳转,后台慢慢切图。
削峰填谷: 遇到突发大流量(如秒杀、热点事件爆火)时,数据库压力巨大。异步 API 可以先让任务在 Queue 里堆积,由 Worker 以稳定的速度处理,防止数据库崩溃。
非核心逻辑: 比如点赞、增加阅读量、发送通知邮件。这些操作迟到几秒钟,用户通常感知不到。
(3)SQL Write Master-Slave是只写的主数据库和从数据库吗?SQL Read Replicas是只读的主数据库,只有一个吗?
1. SQL Write Master-Slave (主从写入集群)
这个节点通常由一个 Master(主库) 和一个或多个 Slave(从库/备库) 组成。
Master (主库): 它是整个系统的"写入口"。所有的
INSERT、UPDATE、DELETE操作都必须在 Master 上执行。Slave (从库): 在这个特定的"写入集群"框里,Slave 通常不直接对外提供读取服务,而是作为 Hot Standby(热备) 存在。
过程: 当 Master 写入数据时,它会通过二进制日志(Binary Log)将变更同步给 Slave。如果 Master 宕机,系统会立刻将 Slave 提升为新的 Master,确保系统不会因为数据库挂掉而瘫痪。
结论: 它不是"只写"的,主库也能读,但在该架构中它专注于确保写操作的安全和数据的持久化。
2. SQL Read Replicas (只读副本)
这里的定义与你的描述有很大出入:
不是主数据库: 它们是 Slave(从库)。在分布式系统中,Master 负责写,这些 Replicas 负责读。它们通过复制 Master 的数据来保持同步。
不只有一个: 注意图中的图标是"叠放"的,且名字使用了复数 Replicas。这意味着你可以根据流量需求,横向扩展出 3 个、5 个甚至上百个只读副本。
功能: 它们专门处理来自
Read API的请求。因为互联网应用(如微博、电商)的读压力通常是写压力的 10 倍以上,通过增加多个只读副本,可以极大地分担主库的压力。3. 数据流向的过程总结
为了方便记忆,你可以这样理解整个数据链路:
写入:
Write API-> SQL Write Master (数据落地)。同步: SQL Write Master -> 异步/半同步复制 -> SQL Read Replicas (数据分发)。
读取:
Read API-> 负载均衡 -> 某一个 SQL Read Replica (返回数据)。核心区别对比表
维度 SQL Write Master SQL Read Replicas 角色 Master (主) Slaves (从/副本) 主要任务 处理数据变更 (事务、写入) 处理数据查询 (读取) 数量 通常只有一个(或主备对) 可以有多个,支持水平扩展 数据来源 客户端请求 从 Master 复制而来 架构意义 保证数据完整性与高可用 提升系统整体查询性能 (吞吐量) (4)Memory Cache、Object Store、NoSQL、SQL WriteMaster-Slave、SQL ReadReplicas存储内容的区别是什么?
在复杂的分布式架构中,存储组件的选择取决于数据的访问模式(Access Pattern) 、一致性要求 以及数据规模。
为了让你看清它们之间的本质区别,我们可以从存储的内容类型和核心职能进行对比:
存储组件核心区别对比表
组件名称 存储介质 存储内容示例 核心职能 一致性 Memory Cache RAM (内存) Session、验证码、热门推文 ID 列表 极速响应,缓解 DB 压力 最终一致性 Object Store 磁盘 (分布式) 用户头像、视频原文件、备份日志 海量存储,非结构化文件 高持久性 NoSQL 磁盘/内存 社交关系链、实时点击量、元数据 高并发读写,模式灵活 最终一致性 (BASE) SQL Write Master 磁盘 (持久化) 用户账户余额、订单状态、核心档案 数据写入,保证原子性 强一致性 (ACID) SQL Read Replicas 磁盘 (持久化) 历史订单查询、报表分析数据 高并发查询,读写分离 准实时/分钟级延迟 详细内容与场景解析
1. Memory Cache (内存缓存)
它存的是"瞬时状态 "和"热点摘要"。
内容: 并不存储完整的数据库记录,而是存储经过计算的、经常被访问的小数据块。
例子: 比如你正在登录的 Token,或者微博上排名前十的热搜列表。它追求的是微秒级的响应,数据丢了可以从数据库恢复。
2. Object Store (对象存储)
它存的是"笨重实体"。
内容: 二进制大对象(BLOBs)。数据库(SQL)不擅长处理几百 MB 的文件,所以将文件放在这里,数据库只存一个链接。
例子: 你上传到朋友圈的 9 张高清图,或者一段 1080P 的短视频。
3. NoSQL (非关系型数据库)
它存的是"高频变动 "或"半结构化"数据。
内容: 不需要严格表结构的数据。它解决了 SQL 在处理海量数据分片时的性能瓶颈。
例子: 用户的点赞列表、关注列表(图数据库)、或者是设备每秒上报的传感器数据(时序数据库)。
4. SQL Write Master-Slave (写主库/备库)
它存的是"真理之源"。
内容: 严格遵循模式(Schema)的核心业务数据。
例子: 你的银行卡余额、已支付的订单。这些数据必须保证在写入时绝对准确,宁可慢一点,也不能多一分或少一分钱。Master 负责写,Slave 负责在 Master 挂掉时"接棒"。
5. SQL Read Replicas (只读副本)
它存的是"Master 的影子"。
内容: 结构与主库完全一致,但数据可能存在几毫秒到几秒的同步延迟。
例子: 当你打开"我的历史订单"翻看去年的记录时,请求会被路由到 Read Replicas。因为它不处理写入,所以可以横向扩展出很多台,承载海量查询。
总结:数据是如何流动的?
想象一个用户修改头像并发布动态的过程:
图片原图 被扔进 Object Store。
核心信息 (谁在什么时间发了动态)同步写入 SQL Write Master。
粉丝的动态列表 (Cache Key)在 Memory Cache 中被更新或失效。
该用户的动态统计 (点赞数等)可能在 NoSQL 中累加。
其他用户 通过 SQL Read Replicas 刷出这条动态。
(5)左下角的Sharding、Federation是什么?
这一套组合拳保证了系统在处理海量数据时,既能"存得下",又能"找得快",还不怕"数据丢"。
这张图展示了数据库扩展(Database Scaling)中两种最核心的策略:分片(Sharding)与联邦(Federation)。
当单个数据库无法承载海量数据或高并发访问时,架构师会通过这两种方式将压力分散到多台服务器上。
1. Sharding (数据库分片 / 水平拆分)
图中上方展示的是将同一种数据(Customers)拆分到不同的数据库中。
逻辑: 按照某种规则(分片键,如用户名的首字母)将同一张表的行分配到不同的数据库实例上。
图例解释: * 名字 A-M 的客户存放在左边的数据库。
- 名字 N-Z 的客户存放在右边的数据库。
目的: 解决单表数据量过大的问题。
优点: 理论上可以无限横向扩展;单台服务器的 I/O 和存储压力显著降低。
挑战: 跨分片的查询(Join)非常困难且性能低下。
2. Federation (数据库联邦 / 垂直拆分)
图中下方展示的是按照业务功能将不同的数据分开存放。
逻辑: 按照功能模块,将不同的表拆分到不同的数据库实例中。
图例解释: * 将客户信息(Customers SQL)和产品信息(Products SQL)放在完全不同的服务器上。
目的: 解决单台服务器承载过多业务逻辑的问题。
优点: 各个业务模块的数据相互隔离,互不影响;方便针对特定业务进行单独优化。
挑战: 如果业务之间存在强关联(例如订单需要关联查询客户和产品),会增加应用层的开发复杂度。
3. 核心区别对比
维度 Sharding (水平拆分) Federation (垂直拆分/联邦) 拆分对象 同一张表的不同行 不同业务模块的表 数据关系 各库表结构一致,数据不重叠 各库表结构完全不同 解决痛点 解决"数据行数太多" (海量数据) 解决"业务逻辑太杂" (系统解耦) 扩展方向 横向扩展 (Scale Out) 功能扩展 (Functional Decomposition)
二、系统设计主题的索引
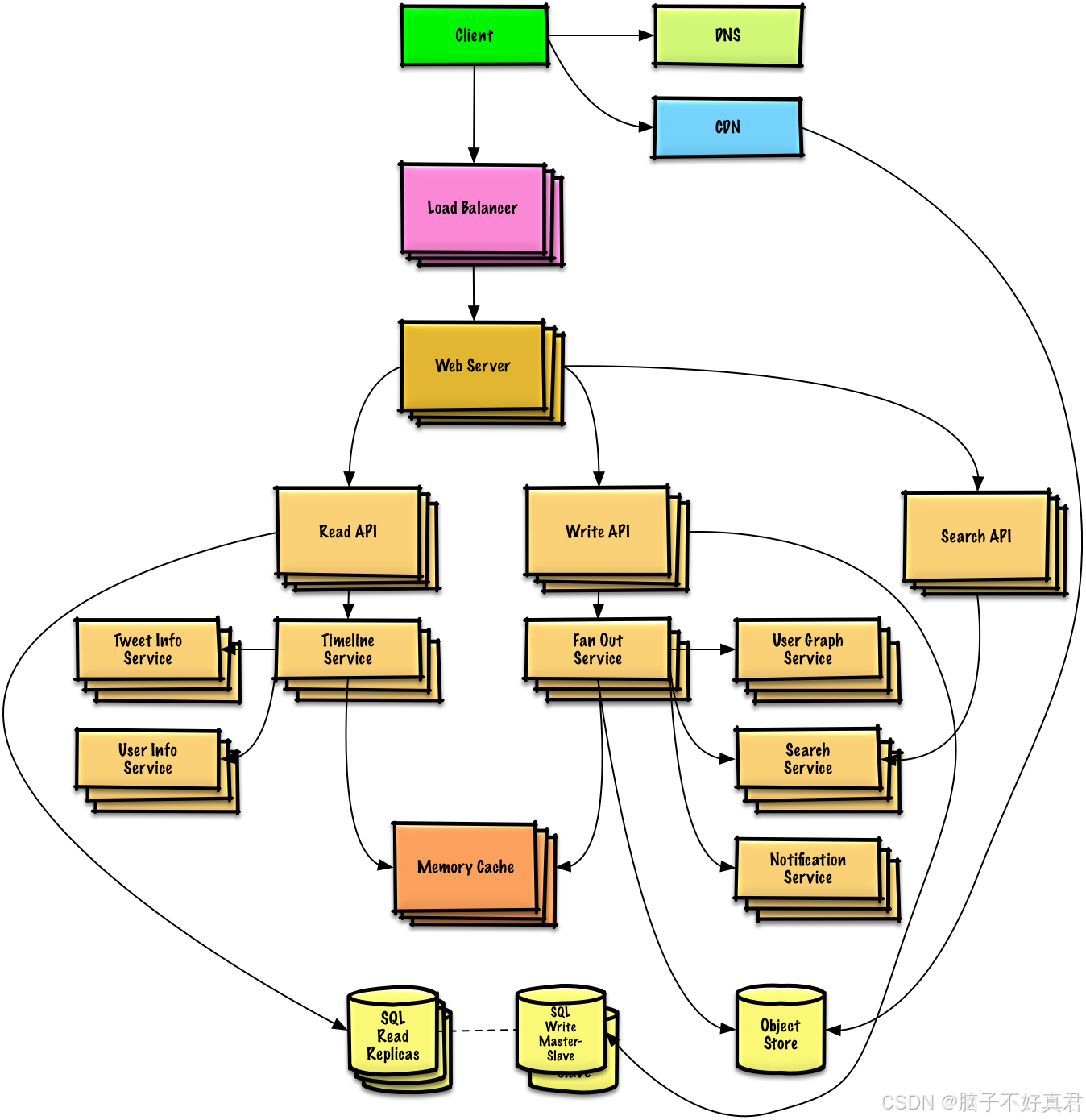
0.图解
图:这张图展示的是一个社交媒体系统(以 Twitter/X 为例)的大规模系统架构图。它从通用的 Web 架构进化到了专门针对"社交关系"和"时间线渲染"优化的微服务架构。
1. 核心节点功能分解
我们可以根据功能逻辑将节点分为以下几个核心模块:
A. 接入层 (Ingress Layer)
- DNS/CDN/Load Balancer/Web Server: 这一层与你之前看到的通用架构一致,负责流量接入、静态资源加速和负载均衡。
B. 业务服务层 (Service Layer)
这里采用了微服务架构,将不同的业务逻辑拆分为独立的组件:
节点名称 功能描述 Read/Write/Search API 入口网关: 分别处理读取、发布和搜索的请求路由。 Tweet Info Service 推文服务: 管理推文的基础数据(文本、多媒体链接、发布时间)。 User Info Service 用户服务: 管理用户资料、设置等基本信息。 Timeline Service 时间线服务: 核心组件,负责为每个用户生成"关注的人"的动态流。 Fan Out Service 推流服务: 社交媒体最关键的组件。当用户发推时,该服务负责将新推文分发给该用户的所有关注者。 User Graph Service 社交关系服务: 维护"谁关注了谁"的复杂图结构数据(Social Graph)。 Search Service 搜索服务: 对推文内容进行索引,支持实时检索。 Notification Service 通知服务: 负责点赞、转发、被关注时的实时推送(Push Notification)。 C. 数据持久化与缓存层 (Storage & Cache Layer)
Memory Cache (Redis/Memcached): 缓存用户的 Timeline。在社交平台中,读操作远多于写操作,因此预先计算并缓存 Timeline 是性能的关键。
SQL (Master-Slave): 存储用户、推文等结构化数据,通过读写分离分担压力。
Object Store: 存储非结构化数据(如用户上传的图片、视频原文件)。
2. 核心业务过程:发推与阅读
这张图最能体现社交媒体特性的过程是 "Fan-Out"(扇出)机制:
过程一:用户发布推文 (Write Path)
用户通过 Write API 发送请求。
Tweet Info Service 将推文存入数据库。
系统触发 Fan Out Service 。它会调用 User Graph Service 找到该用户的所有粉丝。
Fan Out Service 将这条推文的 ID 插入到这些粉丝在 Memory Cache 中的"预排好序的时间线列表"里。
过程二:用户刷新动态 (Read Path)
用户通过 Read API 访问。
请求直接到达 Timeline Service。
Timeline Service 不需要去数据库里进行复杂的 Join 查询,而是直接从 Memory Cache 中拉取已经由 Fan Out 预先准备好的推文列表。
结合 User Info Service 和 Tweet Info Service 填充具体的文字和图片,最后返回给用户。
3.疑问
(1)
A.系统设计主题:从这里开始
首先,需要对一般性原则有一个基本的认识,知道它们是什么,怎样使用以及利弊。
a.回顾可扩展性(scalability)的视频讲座
- 主题涵盖
- 垂直扩展(Vertical scaling)
- 水平扩展(Horizontal scaling)
- 缓存
- 负载均衡
- 数据库复制
- 数据库分区
b.回顾可扩展性文章
接下来的步骤
接下来是高阶的权衡和取舍:
- 性能 与可扩展性
- 延迟 与吞吐量
- 可用性 与一致性
记住每个方面都面临取舍和权衡。
然后深入更具体的主题,如 DNS、CDN 和负载均衡器。