
1. 先把多模态这条线串起来
1.1 多模态不是单点技术,而是一条完整生成链路
很多人复习多模态时,会把 ViT、CLIP、扩散模型、U-Net、VAE 分开背。这样很容易背散。更好的方式,是把它们放到同一条链路里理解:ViT 让图像能像文本 token 一样被 Transformer 处理;CLIP 让文本和图像进入同一个语义空间;扩散模型定义从噪声到图像的生成过程;U-Net 负责每一步去噪预测;VAE 则把图像压缩到 latent 空间,让生成成本降下来。
所以,这组面试题看起来很多,本质上都在回答一个问题:模型如何理解图像、理解文本,并把文本条件一步步变成图像。
2. ViT 架构
2.1 ViT 的核心思想:把图片切成一串视觉 token
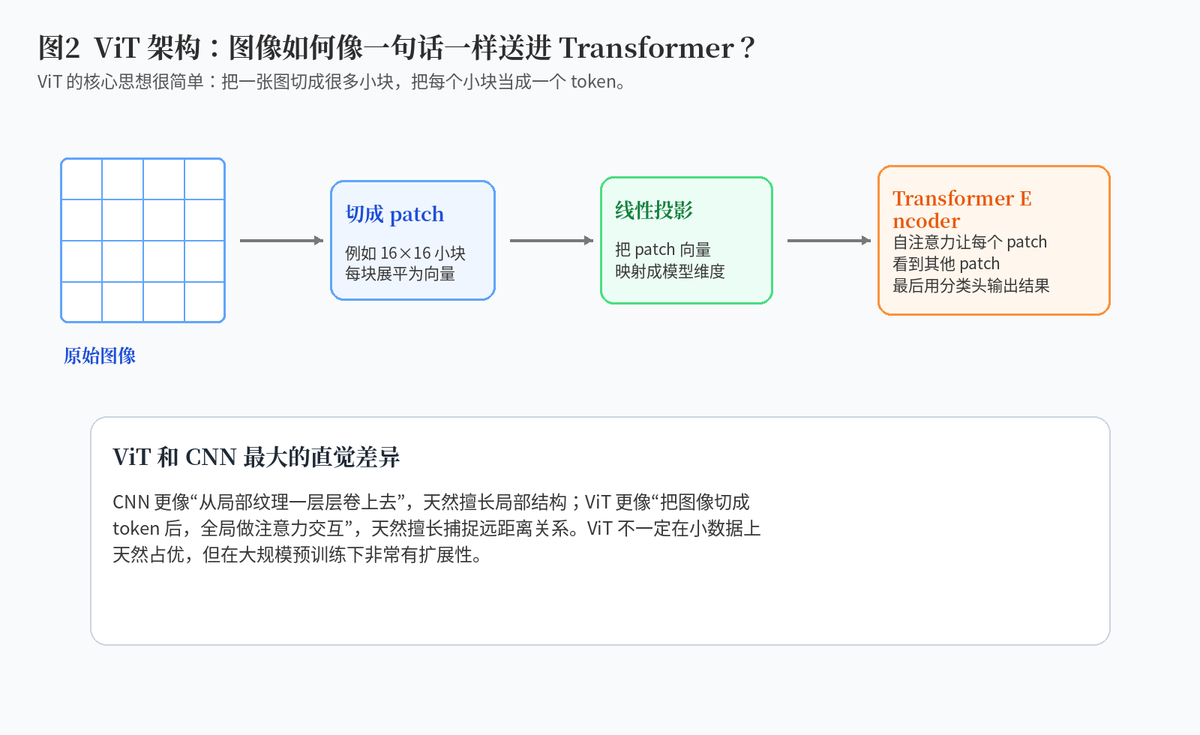
ViT,也就是 Vision Transformer,最核心的想法是把图像处理成序列。传统 Transformer 在 NLP 里吃的是词 token,ViT 则把一张图切成很多固定大小的小块,也就是 patch,再把每个 patch 变成一个向量,像一句话里的词一样送进 Transformer Encoder。
这件事的意义很大。因为它让图像任务可以直接复用 Transformer 的全局注意力能力。每个 patch 不再只能局部看邻居,而是可以通过自注意力和其他 patch 建立关系。
2.2 ViT 图像补丁嵌入是什么?
图像补丁嵌入,也就是 Patch Embedding,可以理解为"把每个图像小块翻译成模型能读懂的向量"。具体过程是:先把图像切成大小相同的小块;再把每个小块展平;然后通过一个可学习的线性投影,把它变成固定维度的 token。
这一步很像 NLP 里的词嵌入。不同的是,NLP 里的 token 本来就是离散词,而图像 patch 是像素块,需要先通过投影层变成向量。
2.3 ViT 的图像如何输入模型?Class Token 的作用是什么?
ViT 的输入通常由三部分组成:patch embedding、class token、position embedding。Patch embedding 代表每个小图像块;class token 是一个额外放在序列开头的可学习向量;position embedding 则告诉模型每个 patch 在图像里的位置。
Class token 的作用可以理解为"全图代表"。经过多层 Transformer 后,它会通过注意力不断吸收其他 patch 的信息,最终变成整张图的全局表示。做分类时,通常拿这个 token 的输出接分类头。

3. 扩散模型:为什么要对 X0 加噪声?
3.1 前向扩散是什么意思?
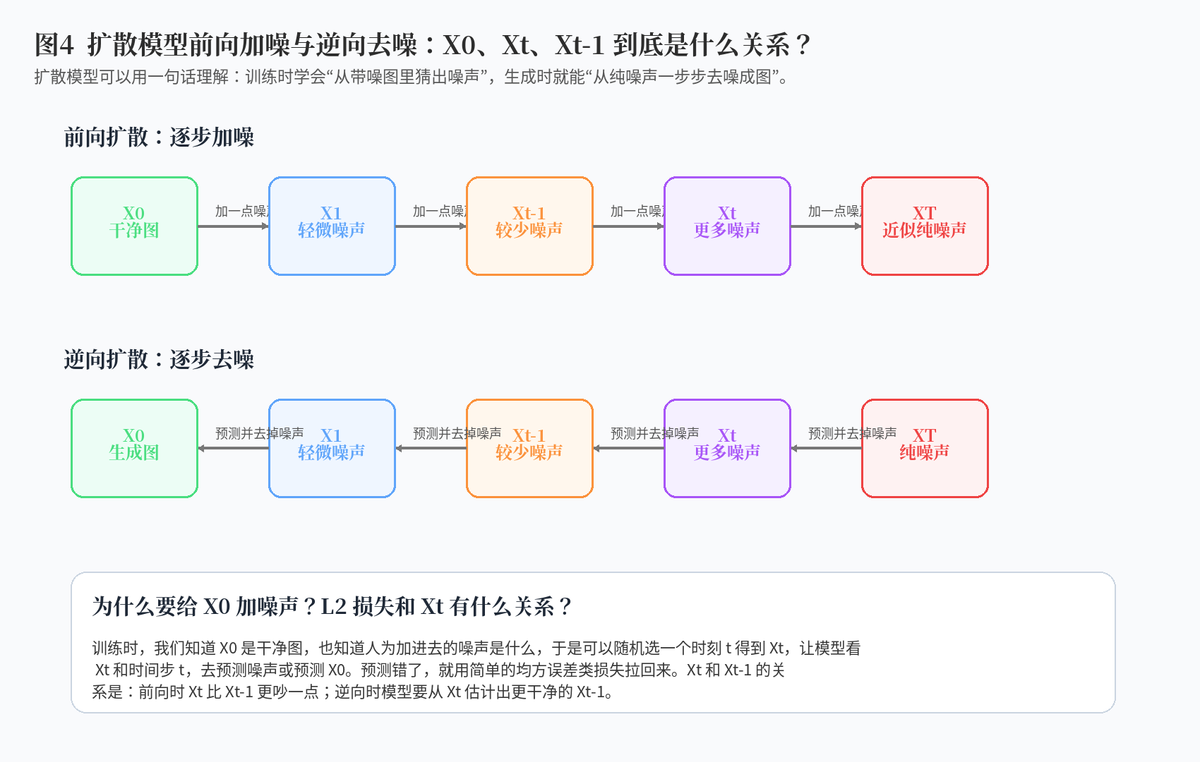
前向扩散就是从一张干净图 X0 开始,一步步往里加噪声。随着时间步 t 变大,图像越来越模糊,最后接近纯噪声。这个过程不是模型学出来的,而是人为设计好的。因为噪声是我们自己加进去的,所以训练时天然知道标准答案。
3.2 逆向扩散是什么意思?
逆向扩散就是反过来:从纯噪声开始,一步步去噪,逐渐还原出清晰图像。模型真正要学的,就是在每个时刻根据当前带噪图 Xt 和时间步 t,预测应该怎样去掉噪声,得到更干净的 Xt-1。
3.3 为什么扩散模型要对 X0 加噪声再用 L2 损失?Xt 和 Xt-1 有什么联系?
对 X0 加噪声的好处是可以构造大量有监督训练样本。我们知道干净图是什么,也知道加入了什么噪声,因此可以让模型去预测噪声、预测 X0 或预测另一种去噪方向。预测错了,就用简单的均方误差类损失把它拉回来。
Xt 和 Xt-1 的关系可以这样理解:在前向过程中,Xt 比 Xt-1 多了一点噪声;在逆向过程中,模型要从更吵的 Xt 预测出更干净的 Xt-1。
4. 扩散模型训练时,预测目标是什么?
4.1 最常见:预测噪声
DDPM 这类经典扩散模型里,最常见的训练目标是预测噪声。也就是说,模型看到一张带噪图 Xt 和时间步 t,要猜出当初加进去的噪声是什么。因为噪声是人为生成的,所以训练标签非常明确。
4.2 也可以预测 X0 或 v
有些模型不直接预测噪声,而是预测干净图 X0,或者预测一种折中变量 v。无论形式怎么变,核心目标都是一样的:让网络学会从带噪状态找到回到干净图像的方向。

5. U-Net 网络是什么?在扩散模型中有什么作用?
5.1 U-Net 组件有哪些?
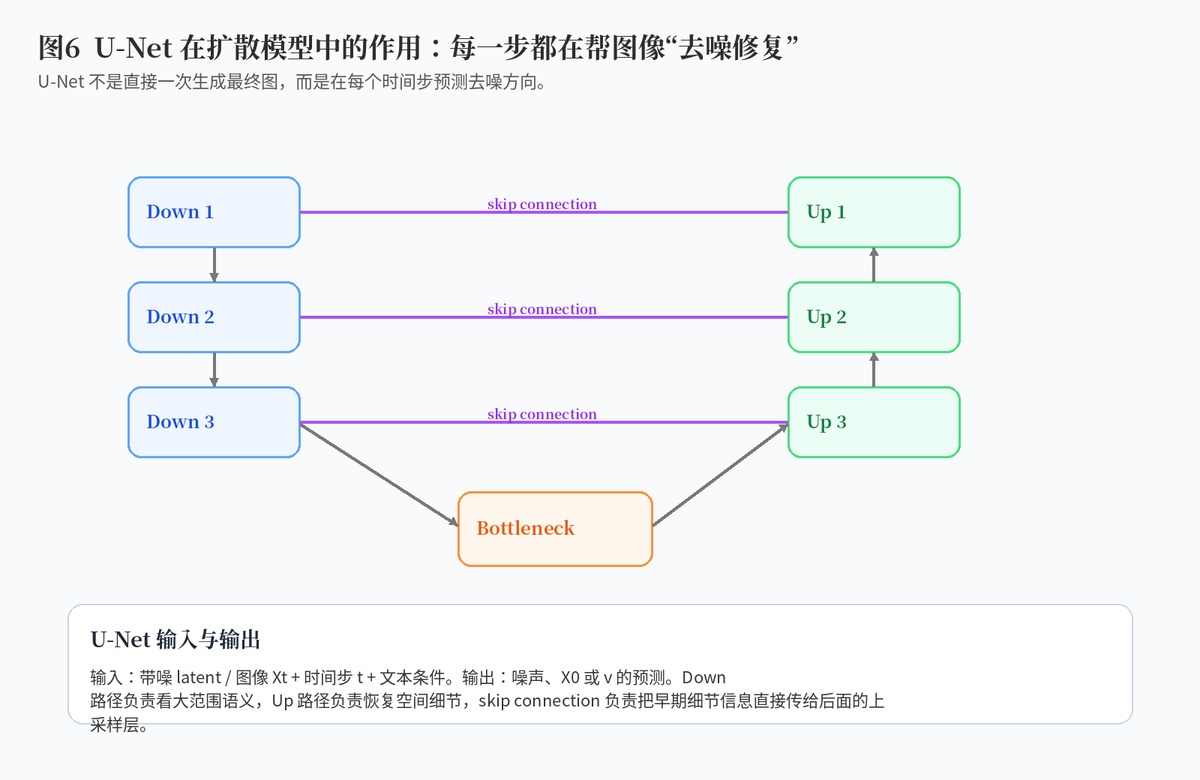
U-Net 的名字来自它像一个 U 形结构:左边是下采样路径,逐步压缩空间尺寸、提取更高层语义;中间是瓶颈层,整合全局信息;右边是上采样路径,逐步恢复空间分辨率;中间还会有 skip connection,把早期的细节特征直接传到后面的恢复阶段。
在扩散模型里,U-Net 还会接收时间步信息,有时还会接收文本条件。文本条件通常通过 cross-attention 等方式注入,让去噪过程朝着 prompt 描述的方向走。
5.2 U-Net 在扩散模型中的作用
U-Net 是扩散模型的核心去噪网络。它不是一次性生成图像,而是在每个时间步看当前带噪图、时间步和条件信息,然后预测噪声、X0 或 v。生成过程不断重复这个动作,图像就会从纯噪声逐步变清晰。
6. VAE、CLIP 和投影层分别有什么作用?
6.1 VAE 在扩散模型中的作用
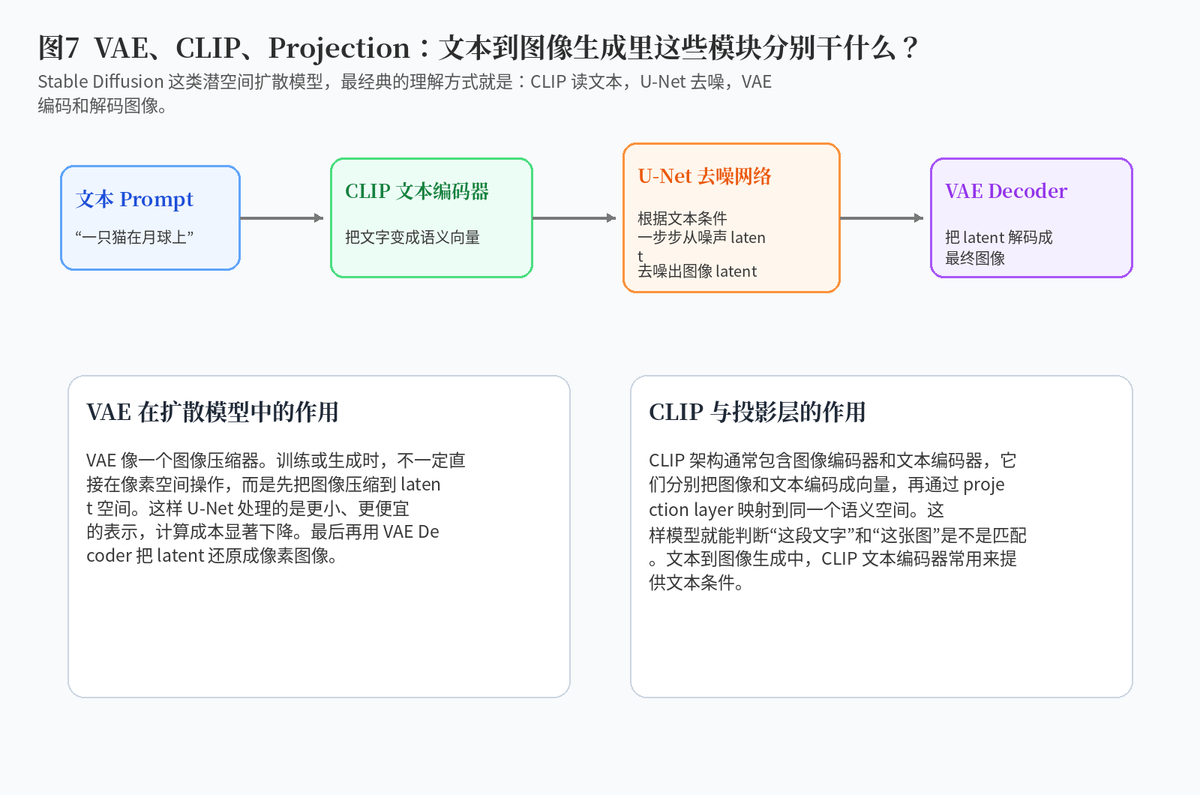
在 Latent Diffusion 这类模型里,VAE 的作用可以理解为"图像压缩和还原"。训练时,VAE Encoder 把像素图像压缩到 latent 空间;扩散模型主要在这个 latent 空间里加噪和去噪;最后 VAE Decoder 再把 latent 解码回真正的图像。
这样做的好处是计算量大幅降低。直接在高分辨率像素空间做扩散非常贵,而在 latent 空间里操作更省显存、更省计算。
6.2 CLIP 架构
CLIP 由图像编码器和文本编码器组成。图像编码器把图片变成向量,文本编码器把文字变成向量,然后二者通过投影层进入同一个语义空间。训练时,它会拉近匹配图文对的距离,拉远不匹配图文对的距离。
在文生图系统里,CLIP 文本编码器常用来把 prompt 变成文本条件,供 U-Net 在去噪时使用。它也可以作为图文对齐评估器,帮助判断生成图和提示词是否匹配。
6.3 投影层的作用是什么?
投影层的核心作用,是把不同来源的特征映射到统一维度、统一语义空间。比如 CLIP 里,图像编码器和文本编码器输出的特征可能不是天然可比的,需要通过投影层变成可以直接计算相似度的向量。ViT 里的 patch projection 也是类似思想:把像素块转换成 Transformer 能处理的 token 向量。
7. 如何处理 prompt 和生成图像不对齐的问题?
7.1 先判断不对齐来自哪里
Prompt 和生成图像不对齐,可能是提示词写得模糊,也可能是模型对某些概念理解不足,还可能是多个物体的空间关系太复杂,或者提示词内部有冲突。比如"一个写实的二次元人物"这种描述,本身就会让模型难以统一风格。
7.2 从低成本到高成本逐层解决
最简单的是重写 prompt,把主体、数量、位置、风格、构图和负面约束写清楚;其次可以调整 guidance、采样步数和随机种子;再进一步,可以生成多张候选,用 CLIP 相似度或人工规则重排;如果还不够,可以加入参考图、姿态图、边缘图、ControlNet 或局部重绘;如果是特定角色、商品或风格长期不稳定,就需要 LoRA、DreamBooth 等微调方案。

8. 面试高频追问,建议这样回答
8.1 ViT 架构怎么说?
答:ViT 把图像切成固定大小的 patch,每个 patch 展平后通过线性投影变成 token,再加上 class token 和位置编码,送入 Transformer Encoder 做全局注意力建模,最后用 class token 输出分类结果。
8.2 扩散模型为什么加噪?
答:加噪是为了构造可监督训练任务。我们知道干净图 X0,也知道人为加进去的噪声,所以可以训练模型从 Xt 中预测噪声或干净图。生成时再从纯噪声反向去噪。
8.3 U-Net 在扩散模型里做什么?
答:U-Net 是去噪网络,每一步接收带噪图、时间步和条件信息,预测噪声或去噪方向。下采样提语义,上采样恢复细节,skip connection 保留局部信息。
8.4 CLIP 和投影层怎么讲?
答:CLIP 有图像编码器和文本编码器,二者通过投影层映射到同一个语义空间,从而可以比较图文是否匹配。投影层负责统一维度和语义空间。
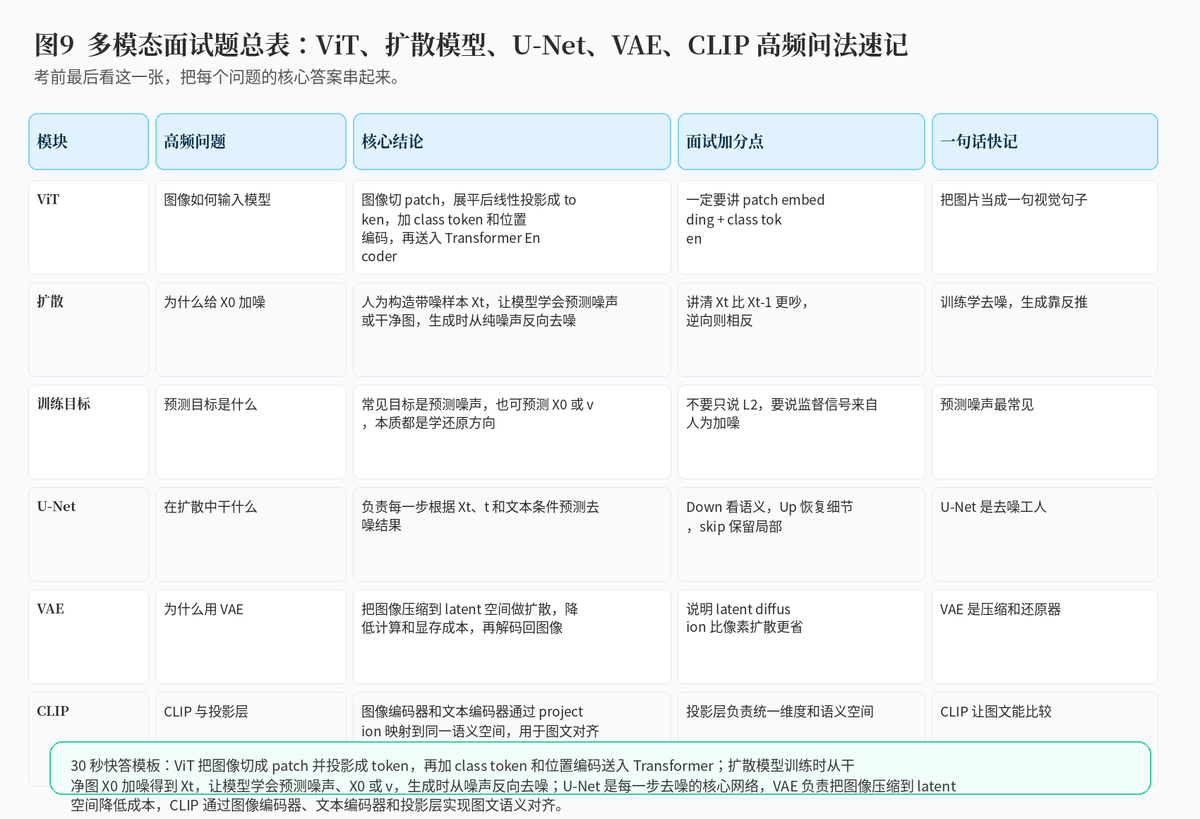
9. 总结:把多模态看成一条链路,所有问题就都顺了
如果把这组问题浓缩成一句话,那就是:ViT 解决图像如何进入 Transformer,CLIP 解决文本和图像如何对齐,扩散模型解决如何从噪声生成图像,U-Net 负责每一步去噪,VAE 负责降低生成成本并还原图像。
面试中最能拉开差距的,不是背出一堆模型名,而是能把它们放进同一条链路里讲清楚:图像怎么编码,文本怎么条件化,噪声怎么加,模型怎么学,生成怎么反向去噪,以及当 prompt 和图像不对齐时如何定位和优化。
附:30 秒快答模板
"ViT 把图像切成 patch,通过线性投影变成 token,再加 class token 和位置编码送入 Transformer;扩散模型通过前向加噪构造训练任务,让模型学会从 Xt 预测噪声、X0 或 v,生成时从纯噪声一步步反向去噪;U-Net 是每一步去噪的核心网络,VAE 用来把图像压缩到 latent 空间降低成本,CLIP 用图像编码器、文本编码器和投影层把图文映射到同一个语义空间,从而实现文本条件和图文对齐。"