本章目标 :彻底掌握 LangChain 结构化输出的三种方案,从 Pydantic 模型定义到
with_structured_output()绑定,再到思维链+提取的复合模式,能够在生产环境中可靠地从非结构化文本中提取结构化数据。
前期回顾
本章你将学到
- 为什么 LLM 的字符串输出不够用,什么是结构化输出
- Pydantic 数据模型的定义方法(字段、类型、约束、描述)
with_structured_output()的工作原理(function-calling 机制)- 三种输出方案:Pydantic 绑定 / JsonOutputParser / 思维链+提取
- 嵌套模型、枚举类型、可选字段的处理技巧
- 实体提取(NER)、简历解析、代码审查等真实场景案例
前置条件
| 要求 | 说明 |
|---|---|
| Python 版本 | 3.10+ |
| 已完成章节 | 第1章(基础 LLM 调用)、第3章(Chain 链式调用) |
| 环境变量 | DASHSCOPE_API_KEY 已配置 |
| 安装依赖 | uv sync 或 pip install langchain langchain-openai pydantic |
一、为什么需要结构化输出?
1.1 LLM 天生返回"自然语言",不是"数据"
来看一个真实场景:你让 LLM 分析用户评论的情感。
python
# 问题:LLM 返回的是字符串,你怎么处理?
response = llm.invoke("分析'这个手机很棒'的情感")
# 可能返回:
# "这条评论表达了积极正面的情感,用户对产品非常满意。"
# 或者:
# "情感:正面\n置信度:0.95\n关键词:很棒"
# 或者:
# "positive(0.95)- 用户满意"痛点:每次返回格式都可能不同,你无法可靠地用代码解析它。你需要写大量字符串处理代码,还要应对各种格式变体。
1.2 结构化输出的价值
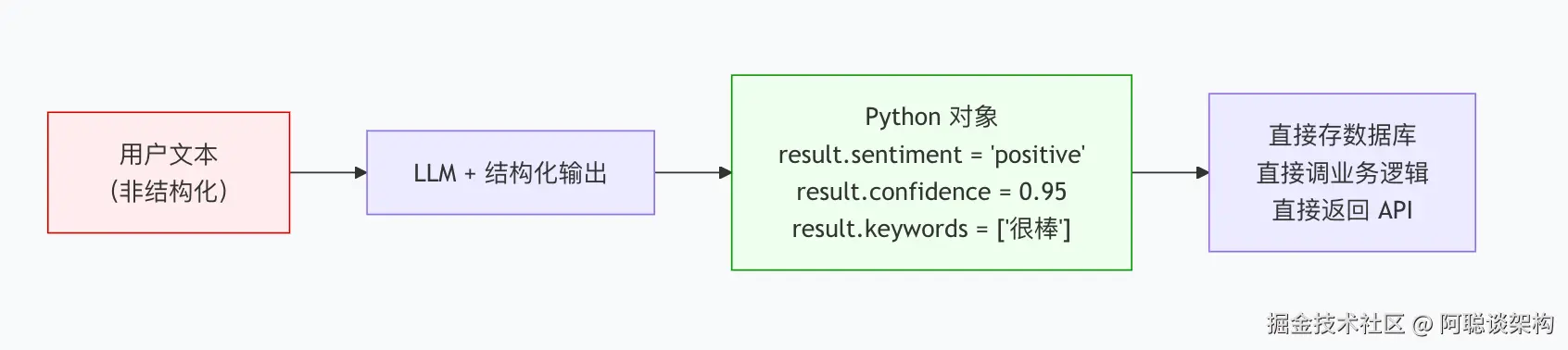
结构化输出让 LLM 变成了一个数据解析引擎:
- ✅ 类型安全:
result.confidence是float,不是字符串"0.95" - ✅ 自动校验:Pydantic 会检查
confidence是否在[0.0, 1.0]范围内 - ✅ IDE 补全:写代码时有类型提示,减少拼写错误
- ✅ 可靠解析:无需手写正则表达式
二、核心概念速览
Pydantic:一个 Python 数据验证库,让你用类定义数据结构,自动校验类型和约束。是 FastAPI 和 LangChain 的基础依赖。
BaseModel:Pydantic 的基类,继承它来定义你的数据模式(Schema)。
Field:Pydantic 的字段描述器,可以设置默认值、校验规则、字段描述。字段描述会被 LLM 读取,是结构化输出准确的关键。
Schema:数据的结构定义,告诉 LLM"我需要你返回哪些字段、每个字段是什么类型"。
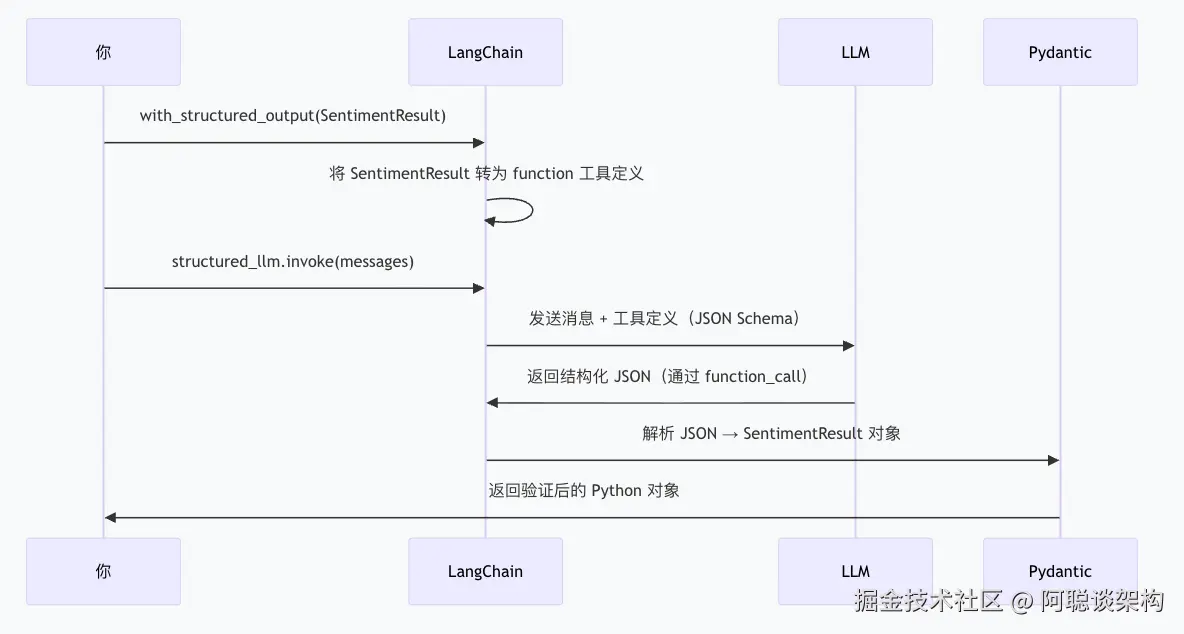
with_structured_output():LangChain 的核心方法,将 Pydantic 模型转为 function-calling 工具定义,强制 LLM 按格式输出。
Function Calling:现代 LLM(GPT-4、Qwen 等)的能力,允许外部系统传入工具定义,LLM 以 JSON 格式调用工具,是结构化输出的底层机制。
JsonOutputParser:LangChain 的 JSON 解析器,通过提示词引导 LLM 输出 JSON,兼容不支持 function-calling 的旧模型。
三、方案一:with_structured_output + Pydantic(推荐)
代码文件:lessons/11_structured_output/01_pydantic_output.py
3.1 从情感分析开始
python
import os # 读取环境变量
from enum import Enum # 定义枚举类型
from typing import Optional # 可选字段类型提示
from langchain_core.messages import HumanMessage, SystemMessage # 消息类型
from langchain_openai import ChatOpenAI # LLM 客户端
from pydantic import BaseModel, Field # 数据验证库
from dotenv import load_dotenv # 加载 .env 文件
load_dotenv() # 从 .env 读取 API 密钥
# ── 第一步:初始化 LLM ─────────────────────────────────────────
llm = ChatOpenAI(
model="qwen-plus", # 使用通义千问 Plus 模型
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 百炼 API 地址
api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取密钥
temperature=0, # 设为 0:结构化任务要确定性输出
)
# ── 第二步:定义输出 Schema ────────────────────────────────────
class Sentiment(str, Enum):
"""情感枚举:限制 LLM 只能从这三个值中选一个,避免返回"非常正面"之类的自定义值。"""
POSITIVE = "positive" # 正面情感
NEGATIVE = "negative" # 负面情感
NEUTRAL = "neutral" # 中性情感
class SentimentResult(BaseModel):
"""情感分析结果。
每个字段的 description 非常重要:LLM 会读取这些描述来理解每个字段的含义。
描述写得越清楚,输出越准确。
"""
sentiment: Sentiment = Field(
description="整体情感倾向" # LLM 看到这句话来理解该字段
)
confidence: float = Field(
description="置信度,0.0-1.0 之间的浮点数",
ge=0.0, # ge = greater than or equal,最小值校验
le=1.0, # le = less than or equal,最大值校验
)
reason: str = Field(
description="判断依据,一句话说明原因" # 要求 LLM 给出判断理由
)
keywords: list[str] = Field(
description="触发情感的关键词列表,最多 5 个" # 限定关键词数量
)
# ── 第三步:绑定 Schema,创建结构化 LLM ───────────────────────
# with_structured_output() 做了三件事:
# 1. 将 SentimentResult 转换为 JSON Schema
# 2. 将 Schema 包装为 function-calling 工具
# 3. 在 invoke() 时自动解析 JSON → SentimentResult 对象
structured_llm = llm.with_structured_output(SentimentResult)
# ── 第四步:调用并获取 Python 对象 ───────────────────────────
reviews = [
"这款手机性能极强,拍照效果也很棒,但价格确实有点贵,总体来说还是值得购买!",
"快递太慢了,包装破损,商品质量也差,完全是浪费钱,不推荐!",
"收到了,外观还行,功能一般,没什么特别突出的地方。",
]
for i, review in enumerate(reviews, 1):
messages = [
SystemMessage(content="你是专业的用户评论分析师,请对以下用户评论进行情感分析。"),
HumanMessage(content=review), # 将评论作为用户消息传入
]
# invoke() 直接返回 SentimentResult 对象,不是字符串!
result: SentimentResult = structured_llm.invoke(messages)
# 使用 .attribute 访问字段,有 IDE 类型提示,不会拼错字段名
print(f"情感:{result.sentiment.value}") # 访问枚举值
print(f"置信度:{result.confidence:.2f}") # float,可以直接格式化
print(f"原因:{result.reason}") # str
print(f"关键词:{result.keywords}") # list[str]3.2 嵌套模型:简历信息提取
真实场景中数据往往是嵌套的。Pydantic 支持模型嵌套,LLM 能正确处理复杂结构:
python
# ── 定义嵌套的工作经历模型 ────────────────────────────────────
class WorkExperience(BaseModel):
"""单条工作经历,会被嵌套在 Resume 中作为列表使用。"""
company: str = Field(description="公司名称")
role: str = Field(description="职位名称")
duration: str = Field(description="在职时长,如 '2年3个月'")
key_achievements: list[str] = Field(
description="主要成就列表,最多 3 条" # 告诉 LLM 数量限制
)
# ── 主模型引用子模型 ──────────────────────────────────────────
class Resume(BaseModel):
"""简历结构化模型,包含嵌套的工作经历列表。"""
name: str = Field(description="候选人姓名")
email: Optional[str] = Field(
default=None, # 邮箱可能不存在,设置默认值 None
description="邮箱地址,不存在则为 null" # 明确告诉 LLM 什么时候输出 null
)
years_of_experience: float = Field(description="总工作年限")
skills: list[str] = Field(description="技术技能列表")
work_history: list[WorkExperience] = Field( # 嵌套模型列表
description="工作经历列表,按时间倒序"
)
summary: str = Field(description="候选人一句话总结,适合 HR 快速了解")
# ── 提取简历信息 ───────────────────────────────────────────────
resume_llm = llm.with_structured_output(Resume) # 绑定简历 Schema
resume_text = """
张伟,5年后端开发经验,擅长 Python、Go、分布式系统设计。
联系方式:zhangwei@example.com
工作经历:
2021.09 - 至今:字节跳动,高级后端工程师
- 主导重构广告推荐系统,QPS 从 10万提升至 50万
- 设计并落地分布式缓存方案,接口延迟降低 60%
2019.07 - 2021.08:美团,后端工程师
- 负责外卖配送调度系统,日均处理订单 300万+
- 优化 MySQL 慢查询,响应时间从 800ms 降至 50ms
技能:Python, Go, Kubernetes, Redis, Kafka, MySQL
"""
# 直接提取,一行代码,返回 Resume 对象
result: Resume = resume_llm.invoke([
SystemMessage(content="请从简历文本中提取结构化信息。"),
HumanMessage(content=resume_text),
])
print(f"姓名:{result.name}") # 直接访问字段
print(f"工作年限:{result.years_of_experience} 年")
for exp in result.work_history: # 遍历嵌套列表
print(f" [{exp.company}] {exp.role}")
for ach in exp.key_achievements:
print(f" • {ach}")四、方案二:实体提取(NER)
代码文件:lessons/11_structured_output/02_entity_extraction.py
命名实体识别(NER,Named Entity Recognition):从文本中识别并提取人名、地名、机构名等有意义的词语。
4.1 通用 NER 提取器
python
from typing import Optional
from langchain_core.prompts import ChatPromptTemplate # 提示词模板
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# ── 定义单个实体的数据结构 ────────────────────────────────────
class NamedEntity(BaseModel):
"""命名实体:文本中具有特定含义的词语。"""
text: str = Field(description="实体文本,即原文中出现的词语")
entity_type: str = Field(
description="实体类型:PERSON(人名)/ ORG(机构)/ LOC(地名)/ DATE(日期)/ PRODUCT(产品)"
)
context: str = Field(description="实体在文中的上下文(前后各一句话)")
class NERResult(BaseModel):
"""命名实体识别结果,包含文章中所有提取到的实体。"""
entities: list[NamedEntity] = Field(description="提取到的所有命名实体列表")
entity_count: int = Field(description="实体总数量")
dominant_topic: str = Field(description="文章主要话题,一句话概括")
# ── 构建提示词模板 ─────────────────────────────────────────────
# ChatPromptTemplate 支持变量插值,{text} 会在调用时被替换
ner_prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个专业的命名实体识别系统。请从文本中准确提取所有命名实体,"
"包括人名、机构名、地名、日期、产品名等。"),
("human", "请对以下文章进行命名实体识别:\n\n{text}"), # {text} 是占位符
])
# ── 构建提取链 ─────────────────────────────────────────────────
# LCEL 管道:提示词 → LLM → 结构化输出
# | 符号将组件串联,形成数据流水线
ner_chain = ner_prompt | llm.with_structured_output(NERResult)
# ── 执行提取 ───────────────────────────────────────────────────
news_text = """
马云在杭州宣布,阿里巴巴将在 2025 年投资 1000 亿元用于 AI 基础设施建设。
此前,字节跳动 CEO 梁汝波在北京召开的世界互联网大会上也表示,
将加大对 TikTok 和抖音算法团队的研发投入。
"""
result: NERResult = ner_chain.invoke({"text": news_text}) # {text} 被替换
print(f"实体总数:{result.entity_count}")
print(f"主要话题:{result.dominant_topic}")
for entity in result.entities:
print(f" [{entity.entity_type}] {entity.text}")4.2 产品规格提取
电商场景中,用户上传的商品描述格式千变万化,需要自动解析成标准字段:
python
class ProductSpec(BaseModel):
"""产品规格参数,从非结构化描述中提取标准化字段。"""
name: str = Field(description="商品名称")
brand: Optional[str] = Field(default=None, description="品牌名称,未提及则为 null")
price: Optional[float] = Field(default=None, description="价格(人民币),未提及则为 null")
dimensions: Optional[str] = Field(default=None, description="尺寸规格(长×宽×高),未提及则为 null")
weight: Optional[str] = Field(default=None, description="重量,未提及则为 null")
color_options: list[str] = Field(default_factory=list, description="可选颜色列表,无则为空列表")
key_features: list[str] = Field(description="核心卖点列表,最多 5 条")
target_audience: str = Field(description="目标用户群体")
# 不同格式的商品描述,全部能统一解析
descriptions = [
"""
索尼 WH-1000XM5 头戴式降噪耳机,旗舰降噪性能,售价 2999 元。
支持 30 小时续航,配备多点连接技术,可同时连接两台设备。
提供午夜黑和银白色两个配色,重量仅 250g。适合商务出行和居家办公。
""",
]
spec_llm = llm.with_structured_output(ProductSpec)
for desc in descriptions:
spec = spec_llm.invoke([
SystemMessage(content="从商品描述中提取标准化规格信息。"),
HumanMessage(content=desc),
])
print(f"商品:{spec.name} 品牌:{spec.brand} 价格:{spec.price}元")
print(f"颜色:{spec.color_options}")
print(f"核心卖点:{spec.key_features}")4.3 5W1H 新闻要素提取
新闻分析的经典框架(5W1H:Who、What、When、Where、Why、How):
python
class NewsElements(BaseModel):
"""新闻五要素(5W1H),结构化提取新闻核心信息。"""
who: list[str] = Field(description="涉及的主要人物或机构")
what: str = Field(description="发生了什么事件(核心事实)")
when: Optional[str] = Field(default=None, description="事件发生时间")
where: Optional[str] = Field(default=None, description="事件发生地点")
why: Optional[str] = Field(default=None, description="事件发生原因")
how: Optional[str] = Field(default=None, description="事件经过或方式")
importance_score: int = Field(
description="新闻重要性评分 1-10",
ge=1, le=10 # 约束范围,超出会触发 Pydantic 报错
)
news_llm = llm.with_structured_output(NewsElements)
headline = "OpenAI 于 2024 年 12 月在旧金山发布 GPT-4o,该模型在多项基准测试中超越了 GPT-4,主要改进包括多模态能力的大幅提升。"
elements = news_llm.invoke([
SystemMessage(content="提取新闻中的 5W1H 要素。"),
HumanMessage(content=headline),
])
print(f"事件:{elements.what}")
print(f"时间:{elements.when} 地点:{elements.where}")
print(f"重要性:{elements.importance_score}/10")五、方案三:JSON 链与思维链+提取
代码文件:lessons/11_structured_output/03_json_chain.py
5.1 JsonOutputParser:兼容性方案
当模型不支持 function-calling 时,用提示词引导输出 JSON:
python
import json # 处理 JSON 数据
from langchain_core.output_parsers import JsonOutputParser # JSON 解析器
from langchain_core.prompts import ChatPromptTemplate
# ── JsonOutputParser 会生成格式说明,注入提示词 ──────────────
parser = JsonOutputParser() # 初始化解析器
# get_format_instructions() 返回类似于:
# "请以 JSON 格式输出,例如:{"key": "value"}"
format_instructions = parser.get_format_instructions()
recipe_prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个智能食谱生成器。根据食材生成一道菜的食谱。\n"
"{format_instructions}"), # 将格式说明注入系统提示
("human", "我有这些食材:{ingredients},帮我生成食谱。"),
])
# partial() 预填充 format_instructions 变量,后续只需传 ingredients
recipe_chain = (
recipe_prompt.partial(format_instructions=format_instructions)
| llm # 调用 LLM
| parser # 从字符串中提取并解析 JSON
)
result = recipe_chain.invoke({"ingredients": "鸡蛋、番茄、大蒜、盐"})
# result 是 dict,不是字符串
print(json.dumps(result, ensure_ascii=False, indent=2))5.2 思维链 + 结构化提取(CoT+Extraction)
思维链(Chain of Thought,CoT):让 LLM 先一步步推理,再得出结论。适合复杂分析任务,推理过程让最终结构化结论更准确:
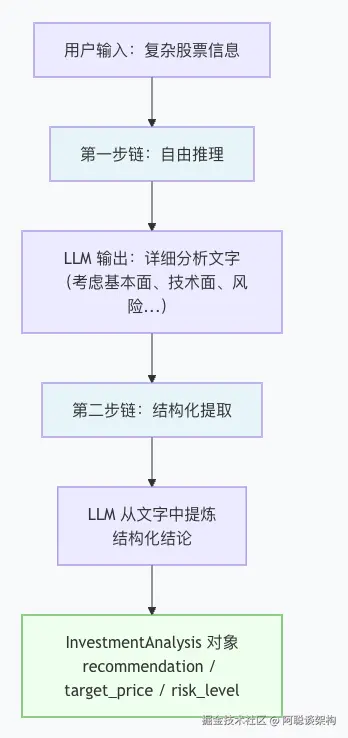
python
from langchain_core.output_parsers import StrOutputParser # 字符串解析器
# ── 定义投资分析结果模型 ──────────────────────────────────────
class InvestmentAnalysis(BaseModel):
"""投资分析结论,从推理文字中提取。"""
recommendation: str = Field(description="投资建议:买入/持有/卖出")
target_price: float = Field(description="目标价格(元)")
risk_level: str = Field(description="风险等级:低/中/高")
key_factors: list[str] = Field(description="关键决策因素,3-5条")
time_horizon: str = Field(description="持有周期:短期(<1年)/中期(1-3年)/长期(>3年)")
# ── 第一步:推理链(输出字符串,自由推理) ───────────────────
analysis_prompt = ChatPromptTemplate.from_messages([
("system", "你是资深股票分析师,请对股票信息进行深入分析,"
"考虑基本面、技术面、市场环境等维度,写出详细推理过程。"),
("human", "分析此股票:\n{stock_info}"),
])
analysis_chain = analysis_prompt | llm | StrOutputParser() # 输出是字符串
# ── 第二步:提取链(从推理文字中提炼结构化结论) ─────────────
extract_prompt = ChatPromptTemplate.from_messages([
("system", "你是信息提取专家,从以下分析文章中提取结构化投资建议,"
"不要添加原文没有的内容。"),
("human", "从以下分析中提取投资建议:\n\n{analysis}"),
])
extract_chain = extract_prompt | llm.with_structured_output(InvestmentAnalysis)
# ── 执行两步链 ─────────────────────────────────────────────────
stock_info = """
比亚迪 (002594) 当前价格 278元,PE 25倍(行业均值30倍),
近6个月涨幅+18%,Q3营收同比+32%,净利润同比+18%。
风险:原材料价格波动,海外监管不确定性。
"""
print("第一步:LLM 自由推理...")
analysis_text = analysis_chain.invoke({"stock_info": stock_info}) # 推理文字
print(f"推理(节选):{analysis_text[:150]}...")
print("\n第二步:从推理中提取结构化结论...")
result: InvestmentAnalysis = extract_chain.invoke({"analysis": analysis_text}) # 提取
print(f"建议:{result.recommendation} 目标价:{result.target_price}元")
print(f"风险:{result.risk_level} 周期:{result.time_horizon}")
for factor in result.key_factors:
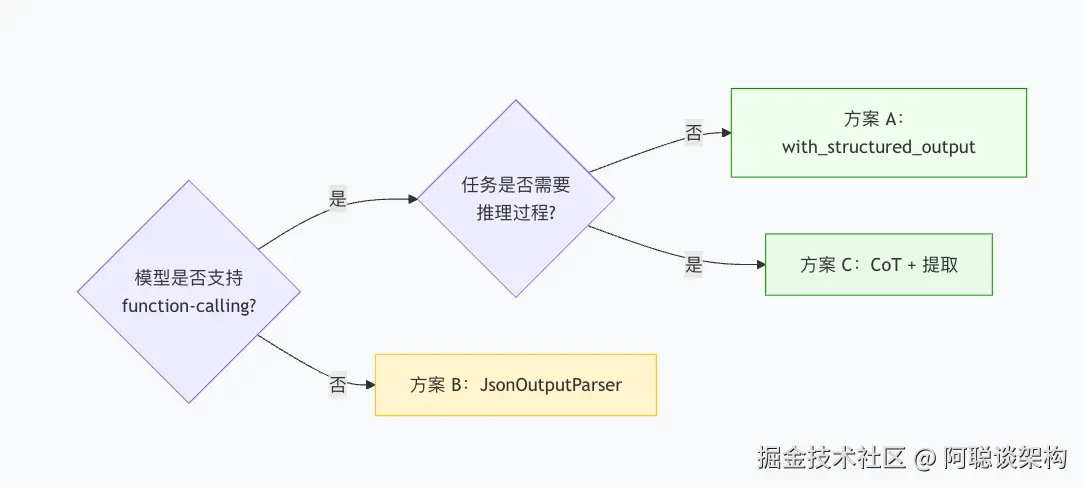
print(f" • {factor}")六、三种方案对比与选型
| 方案 | 方法 | 类型安全 | 适用场景 | 备注 |
|---|---|---|---|---|
| A | with_structured_output(Model) |
✅ Pydantic 对象 | 生产首选,支持 function-calling 的模型 | 推荐 |
| B | JsonOutputParser |
⚠️ dict | 旧模型兼容,快速原型 | 无类型校验 |
| C | 推理 + 提取(两步) | ✅ Pydantic 对象 | 复杂分析任务(需要推理过程) | 多一次 LLM 调用 |
七、逐步追踪:with_structured_output() 做了什么?
理解底层机制有助于排查问题:
javascript
1. 你调用:llm.with_structured_output(SentimentResult)
↓
2. LangChain 将 SentimentResult 转为 JSON Schema:
{
"name": "SentimentResult",
"properties": {
"sentiment": {"enum": ["positive", "negative", "neutral"], "description": "整体情感倾向"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1, ...},
...
}
}
↓
3. LangChain 将 Schema 包装为 OpenAI function 工具,随请求发送给 LLM
↓
4. LLM 理解工具定义,返回:
{"function_call": {"name": "SentimentResult", "arguments": "{\"sentiment\":\"positive\",...}"}}
↓
5. LangChain 解析 arguments JSON → 调用 SentimentResult(**data)
↓
6. Pydantic 校验数据类型和约束 → 返回 SentimentResult 对象给你八、常见错误与排查
| 错误信息 | 原因 | 解决方法 |
|---|---|---|
ValidationError: confidence must be <= 1.0 |
LLM 返回了超出范围的值(如 1.5) |
在字段描述中加强约束说明,同时保留 ge/le 校验 |
OutputParserException: Failed to parse |
LLM 输出不是有效 JSON(模型不支持 function-calling) | 改用 JsonOutputParser,或换用支持 function-calling 的模型 |
字段为 None 但你期望有值 |
字段定义为 Optional[str] 且原文没有相关信息 |
检查字段描述是否足够清晰,或将字段改为必填(移除 Optional) |
| 枚举字段返回了意外的值 | Enum 里的取值与描述不一致 |
确保 Field(description=...) 中的取值与 Enum 定义完全一致 |
嵌套列表为空 [] |
原文中没有相关信息,或提示词没有引导提取 | 在系统提示中明确说明"如果找不到请返回空列表" |
temperature=0.7 导致字段取值不稳定 |
高温度增加随机性,结构化任务需要确定性 | 结构化提取任务统一设置 temperature=0 |
九、最佳实践总结
python
# ✅ 最佳实践示范
# 1. 结构化任务:temperature=0,确保确定性输出
llm = ChatOpenAI(model="qwen-plus", temperature=0, ...)
# 2. 每个字段都写 description,且描述精确
class GoodModel(BaseModel):
score: int = Field(
description="质量评分 1-10,其中 1=极差,5=一般,10=完美", # 给出评分标准
ge=1, le=10 # 加上范围校验兜底
)
# 3. Optional 字段明确说明什么时候为 null
email: Optional[str] = Field(
default=None,
description="邮箱地址;如果文本中未提及,则返回 null" # 明确说明 null 场景
)
# 4. 列表字段说明数量限制
items: list[str] = Field(
description="核心要点列表,3-5 条,每条不超过 20 字" # 限定数量和长度
)
# 5. 使用 Enum 替代自由文本字段,限制取值范围
class Status(str, Enum):
PASS = "pass"
FAIL = "fail"
# 不要写 status: str = Field(description="pass 或 fail")
# 因为 LLM 可能返回"通过"、"合格"、"PASS"等各种变体下一章预告
掌握了结构化输出之后,下一章我们进入高级 RAG(检索增强生成)技术。
第12章 将解答:
- 为什么用户问的问题往往找不到正确答案?(表述不一致问题)
- Multi-Query:一问变多问,全面覆盖语义空间
- Contextual Compression:只留下最相关的内容,降噪提质
- HyDE:用假设答案的向量去检索,突破专业术语壁垒
结构化输出是"数据进数据出"的钥匙,高级 RAG 是"找到正确信息"的利器。两者结合,才能构建真正可靠的生产级 AI 应用。
AI入门开发系列文章合集
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码