

.
个人主页: 晓风飞
专栏: 数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
- 进程
- 进程
-
- 什么是进程?
- PCB(进程控制块)
- 操作系统如何管理进程?
- 示例:getpid
- 查看进程的做法
- [进程的 CWD(当前工作目录)](#进程的 CWD(当前工作目录))
- 进程状态
-
- 问题2:为什么同一个函数,会返回两次
- [问题3:为什么同一个变量,id,即 == 0,又大于0?](#问题3:为什么同一个变量,id,即 == 0,又大于0?)
- 进程状态
- 进程状态
进程
为什么要存在内存??
数据流动的本质是拷贝
数据在计算机体系结构中流动,CPU 不直接与外设打交道。CPU 需要数据时,只能从内存中读取;写数据时,也只能写入内存。
存储分级问题
外设速度太慢,与 CPU 之间存在巨大的速度代差,因此 I/O 操作的效率相对较低。
内存的作用
c++编译形成可执行程序(代码+数据)(文件)程序运行前,必须先加载到内存中(这是体系结构的规定,从纯硬件角度出发)。内存为计算机提供了更高的性价比,提升了整体运行效率。
操作系统
操作系统是一个管理软硬件资源的软件。
广义操作系统:操作系统内核 + 核心应用软件
狭义操作系统:操作系统内核
Linux 内核主要包含:
进程管理
文件管理
内存管理
驱动与设备管理
进程
什么是进程?
教材定义:运行起来的程序就是进程,加载到内存中的程序叫做进程。
更准确的理解:进程 = 内核数据结构(task_struct)+ 程序的代码和数据。可以类比为:学生 = 学籍信息 + 本人。
用户让操作系统执行某个任务、加载某个程序,都会被转换成进程。一切指令执行、工具执行、软件执行,本质上都是进程在运行。进程就是用户要做什么!
PCB(进程控制块)
PCB 内部包含了描述进程的所有属性。操作系统通过"先描述,再组织"的方式来管理进程(类似于找工作:进程是求职者,PCB 是简历,CPU 是面试官,操作系统是 HR 调度)。
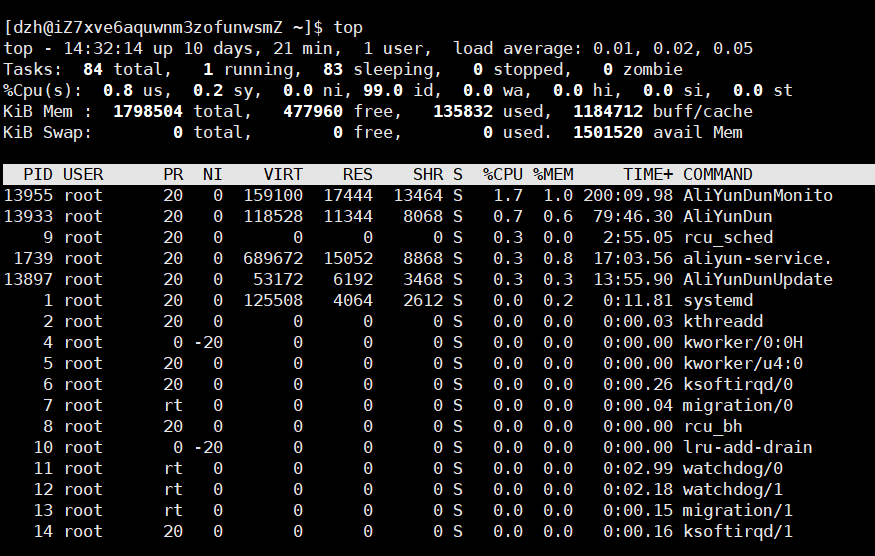
在 Linux 中输入 top 命令可以查看进程,类似于 Windows 的任务管理器。
os内部可以同时存在多个进程
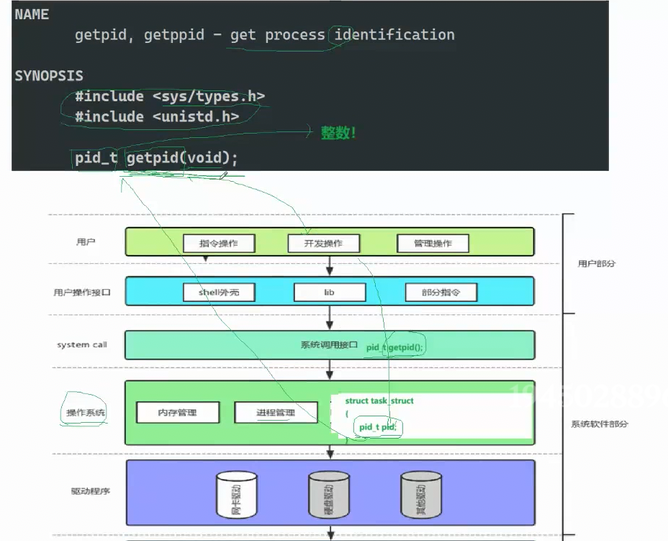
操作系统如何管理进程?
操作系统必须对进程进行管理,管理方式是"先描述,再组织"。每个进程在内核中都有一个对应的内核数据结构------PCB(Process Control Block,进程控制块)
C
struct task_struct
{
进程属性+链接字段
}进程的前身我们叫做程序, 程序在没有加载到内存之前,以文件的形式存储在磁盘上(冯·诺依曼原理)。程序加载到对应内存中才会变成进程
当程序加载到内存时,操作系统不仅会加载代码和数据,还会在内核中创建一个 task_struct)包含了描述当前进程所有属性的结构体,也包含了程序在内存中的代码和数据,操作系统创建进程。结构体来描述该进程。
如果内存中存在多个进程,操作系统会将所有 PCB 连接起来,形成一个链表。CPU 调度时,会遍历链表,选择优先级最高的进程来执行。操作系统对进程的管理,本质上就是对链表进行增删查改。
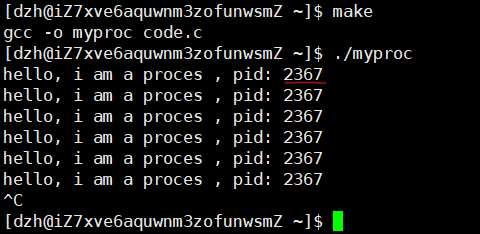
示例:getpid
c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
pid_t id = getpid();
while(1)
{
printf("hello, i am a proces , pid: %d\n",id);
sleep(1);
fflush(stdout);
}
return 0;
}对应的Makefile
c
yproc:code.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f myproc
~ 运行 ./myproc 后,可以看到当前进程的 PID(如 2367)。getpid() 本质上是从 task_struct 中获取进程的 PID 字段。
c
struct task_struct
{
pid_t pid;
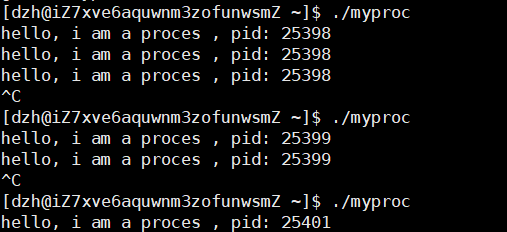
}ctrl+c本质是终止进程,终止后,下次再运行操作系统给与的pid值不同
查看进程的做法
1.process-/proc 2命令
linux一切皆文件,数字目录本身是特定进程对应的pid
我们在一个端口运行程序,另一个端口查看进程
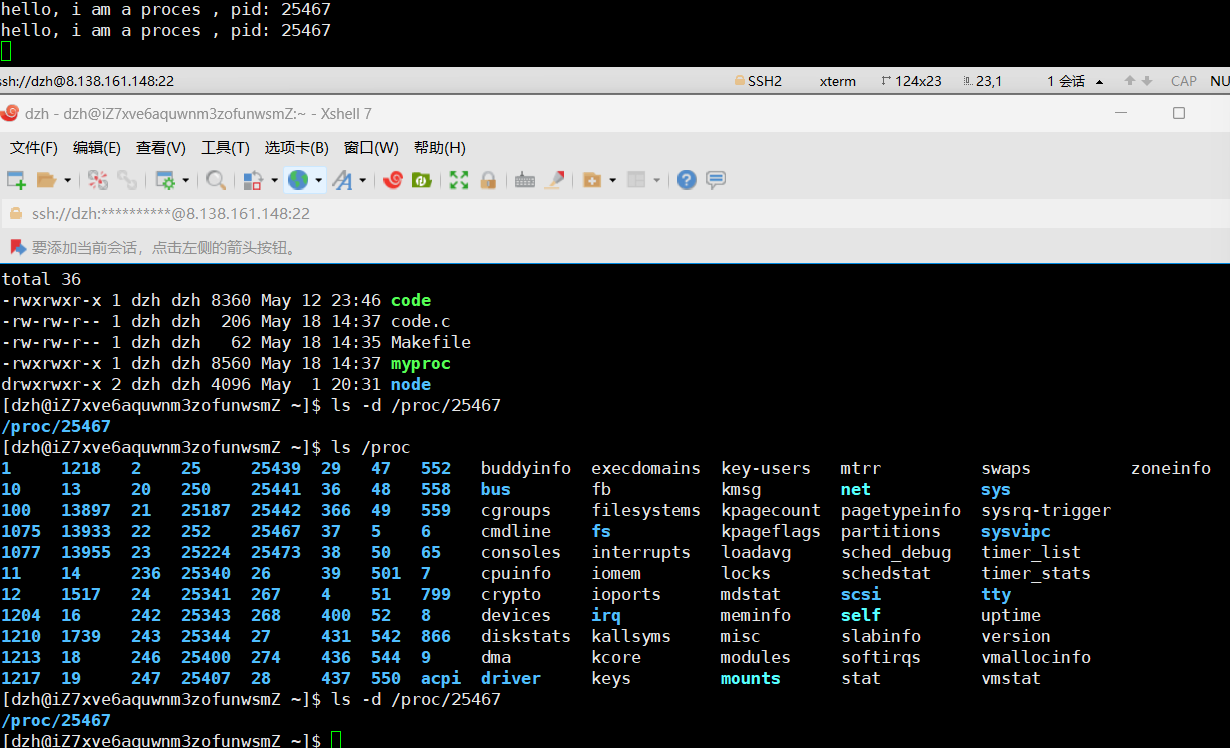
如果这时候把进程的可执行程序删除,会不会对进程暂时有影响吗?
我们输入rm proc删除掉正在执行的程序
这时候在进进程里ls下,可以发现可执行程序属性冒红发现被(deleted)删除了
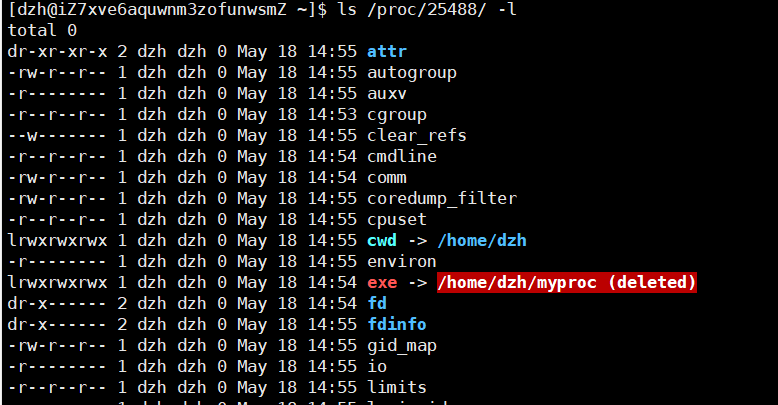
进程的 CWD 如果指向一个被删除的目录,进程依然可以正常运行(内核会持有目录的引用计数,不会立刻释放),但此时你用相对路径创建文件会失败,因为对应的目录已经不存在了。
注意

进程的 CWD(当前工作目录)
在哪里?
CWD 存储在进程文件系统信息结构体 fs_struct 中,并由进程控制块 task_struct 内的指针所管理。
子进程会继承父进程的 CWD。
为什么需要 CWD?
实现 "工作目录隔离",避免路径冲突
不同进程可以有不同的 CWD,比如你在两个终端里,分别在dirA和dirB下运行同一个程序,它们打开的config.txt会分别对应dirA/config.txt和dirB/config.txt,互不干扰。
"文件不存在时进程帮忙创建",本质也是基于 CWD
比如你用fopen("new.txt", "w")创建文件,内核会基于进程的 CWD,把相对路径解析成绝对路径,再创建文件。如果没有 CWD,内核不知道文件该创建在哪个目录下。
chdir更改当前进程的工作路径
进程可以通过 int chdir(const char *path); 修改自己的 CWD,但这个修改只会影响当前进程和它后续创建的子进程,不会影响父进程(比如终端)。
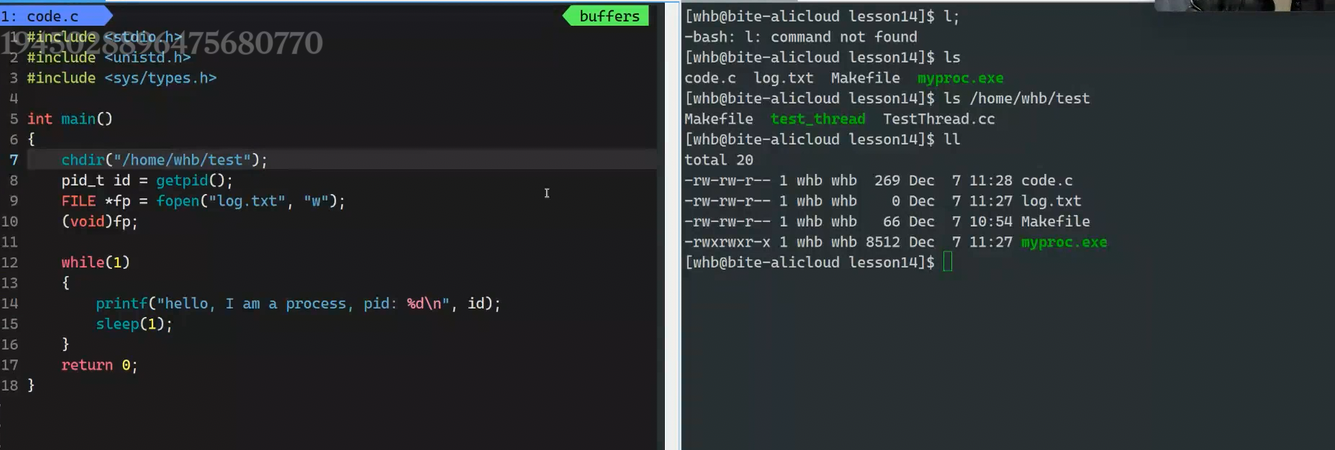
#getcwd获取当前进程的工作路径
我在 /home/dzh/work目录下gcc编译程序
c
#include <stdio.h> // 必须有 #
#include <unistd.h>
#include <sys/types.h>
int main()
{
char pwd[128];
getcwd(pwd, 128);
printf("before: %s\n", pwd);
chdir("/home/dzh/work");
getcwd(pwd, 128);
printf("after: %s\n", pwd);
pid_t id = getpid();
FILE *fp = fopen("log.txt", "w");
(void)fp;
while(1)
{
printf("hello, I am a process, pid: %d\n", id);
sleep(1);
}
return 0;
}这时候可以看到程序当前路径变成了home/dzh

2命令
ps查看当前目录进程
ps ajx | grep procmy
ps ajx 看 父子进程关系、PID、PPID、PGID、SID(偏进程关系)
ps aux | grep procmy
ps aux 看 CPU、内存占用、运行时间、用户(偏资源占用)

实用命令
ps ajx |head -1 && ps ajx | grep procmy
先打印表头,再搜索你的进程
这样你看结果时,每一列是什么意思一目了然
ps ajx | head -1 # 只输出第一行(标题头)
&& # 并且(前面成功才执行后面)
ps ajx | grep procmy # 搜索你的进程 procmy

bash
ash 命令行解释器本身也是一个进程,它以死循环的方式运行,负责接收用户输入的命令并创建子进程来执行。通过 ps ajx 可以查看进程间的父子关系。
当你登录 Linux 后,系统给你启动的 -bash 进程,就是你当前终端的父进程:
查看你的 bash 进程 PID
echo $$

查看它的父进程(通常是终端/sshd)
ps -ef | grep $PPID

它的工作就是接收你输入的命令,创建子进程来执行。
kill
kill -9 进程
可以kill掉bash,会发现掉线
类似bash,它是如何创建字进程的呢?
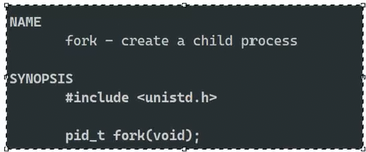
fork
创建子进程
c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main()
{
printf("fork 之前:我是一个进程:pid: %d, ppid: %d\n", getpid(), getppid());
fork();
printf("fork 之后:我是一个进程:pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
return 0;
}pid
c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main()
{
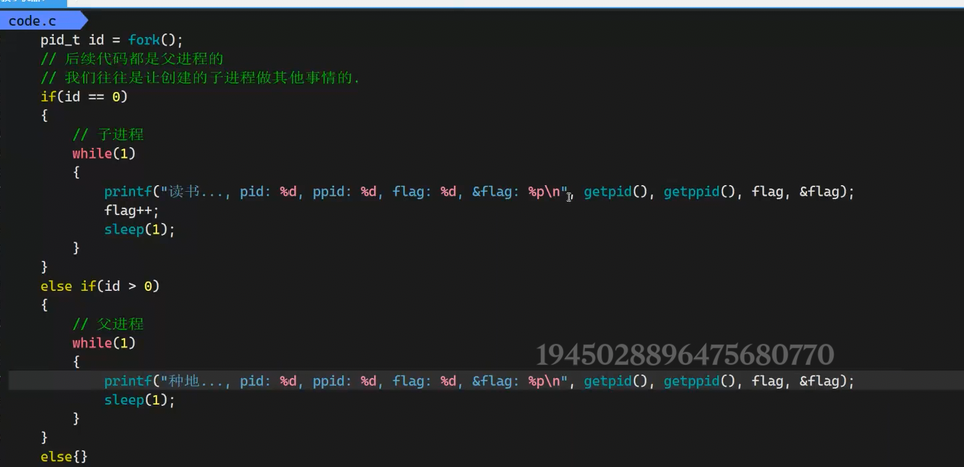
pid_t id = fork();
if(id == 0)
{
while(1)
{
printf("读书...\n");
sleep(1);
}
}
else if(id > 0)
{
while(1)
{
printf("种地...\n");
sleep(1);
}
}
return 0;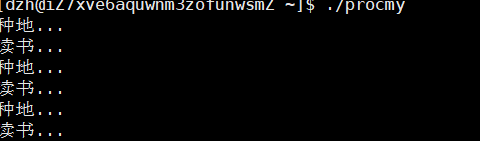
可以看到两个进程同时在运行

进程状态
子进程以父进程为模板进行创建,
父进程创建子进程,代码默认是被子进程共享的
子进程后续默认只能执行父进程fork之后的代码
问题1:为什么给子进程返回0,给父进程返回子进程的pid
子进程返回 0:子进程知道自己是谁,不需要通过返回值来获取 PID(可以通过 getpid() 获取),返回 0 只是告知它是子进程。
一个父进程可以创建多个子进程(1:n 关系),父进程需要知道每个子进程的 PID,才能对它们进行管理(比如 wait() 等待、kill() 终止)。如果父进程也返回 0,它就分不清哪个是哪个子进程了。就像家长有多个孩子,每个孩子只需要知道 "我是孩子",但家长必须知道每个孩子的学号,才能点名、管理。
问题2:为什么同一个函数,会返回两次
a,如果函数都准备return了,这个函数的核心工作做完了吗?
常规函数:工作没做完,就不会走到 return;一旦 return,函数就结束了,只返回一次。
但是fork() 的核心工作是创建一个新进程:在父进程中,将 task_struct 复制一份,修改属性(PID、PPID 等),并将新进程放入调度队列。
新进程创建完成后,两个进程都会继续执行 fork() 的剩余逻辑:父进程将子进程 PID 写入自己的变量并返回,子进程将 0 写入变量并返回。因此,fork() 不是同一个函数被调用了两次,而是两个进程各自执行了该函数的 return 部分。

问题3:为什么同一个变量,id,即 == 0,又大于0?
核心在于进程独立性与写时复制(Copy-on-Write)。
fork() 时,子进程会复制父进程的虚拟地址空间,因此父子进程的变量 id 在虚拟地址上是相同的,但它们映射到不同的物理内存。
写时复制机制:刚 fork() 完成时,父子进程共享同一块物理内存(只读)。当任意一方需要修改数据时,系统会复制一份新的物理内存给修改方,之后双方的变量就完全独立了。
因此,父进程的 id 和子进程的 id 是两个不同的物理内存变量,只是虚拟地址相同,它们的值可以不同且互不影响。
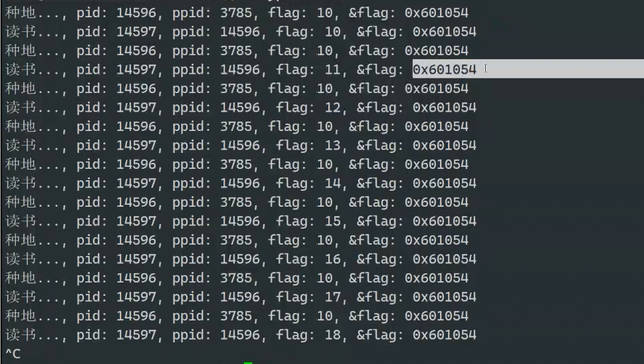
这个地址不可能是物理地址-虚拟地址
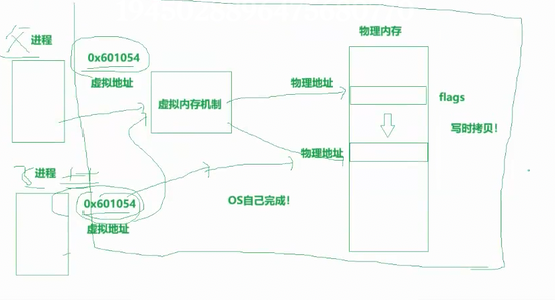
反回的本质,就是写入,本质不是同一个变量,只不过是虚拟地址相同,物理内存中,其实是分开的
进程状态
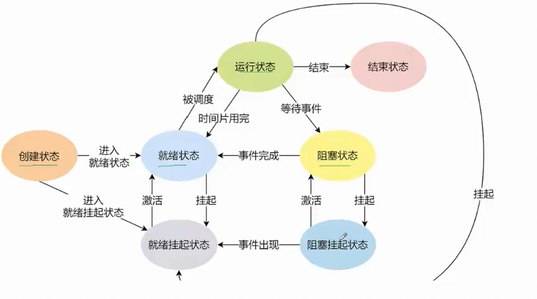
进程状态,本质就是task------struct内部的一个整型变量
站在操作系统原理角度,解释进程状态:运行,阻塞,挂起
FIFO:调度算法
进程处于运行状态
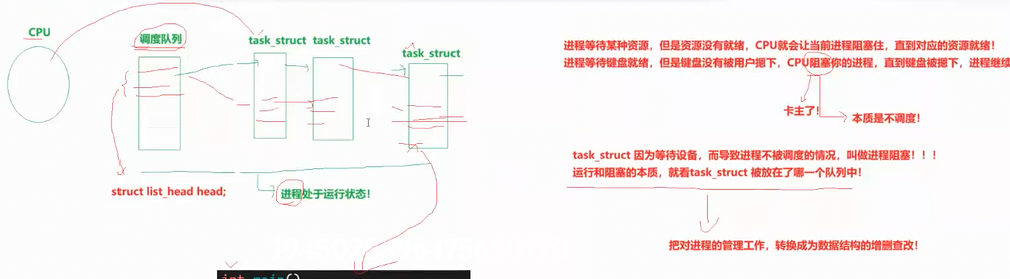
可是:task_struct他不是,属于双链表?怎么能还属于调度队列呢?
内核链表的实现
int a =10
4个字节,&a,标识一个地址??类型决定大小
结构体呢?
c语音对任何类型,开辟空间的时候,变量的地址在数字上等于开辟的众多字节中地址最小的那个数字
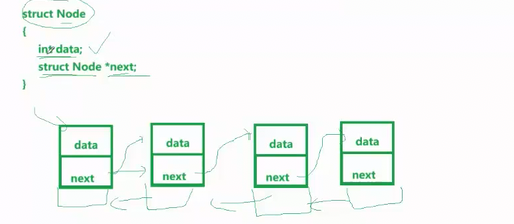
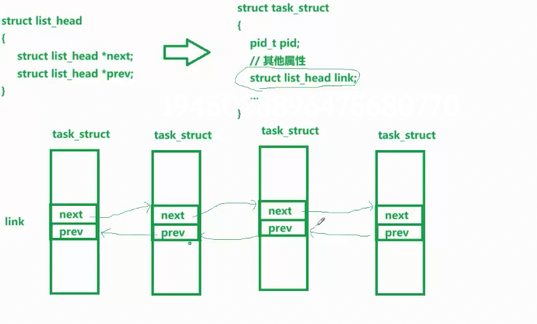
Linux中内核的链表是这样的
next指针,指向的是下一个struct task_struct 内部属性 link

重点在于偏移量怎么求
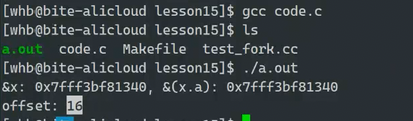
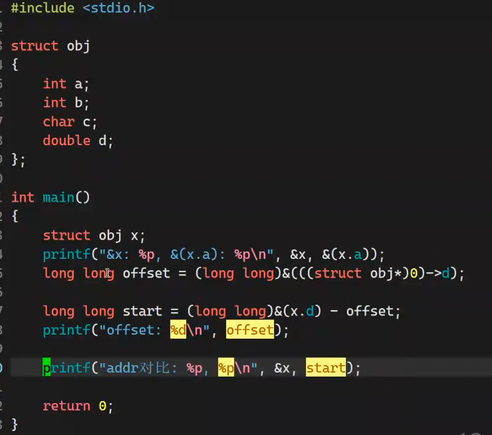
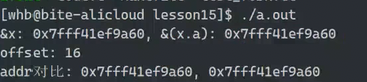
求对象d在obj中的偏移量
因为系统是64位取地址占8字节,强转(int)取地址是4字节,所以用(long long)
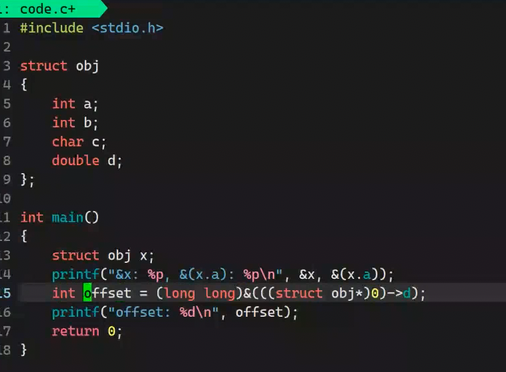
d的偏移量是16
遍历用偏移量找到pid
内核为什么要这么做
1.对内核对象进行管理,更具有通用性
2struct task_struct
{
//进程其他属性
struct list_head link;
struct list_head queue_link
struct list_head hash;
}
一个进程插入多个结构
一个struct task_struct就可以属于双链表,也可以属于调度队列,未来还可以属于任何结构
阻塞状态:
比如c语言中的scanf,输入时,用户没有输入
操作系统管理硬件,也要先描述在组织,所有它所描述的对应硬件结构体里,也可以包含进程相关的链接字段
当一个进程正在运行,比如执行scanf,发现底层的硬件没有就绪,就会把进程pcb从cpu调度中剥离下来,放到比如键盘的等待队列中,进程就不被调度了,就阻塞了,当硬件准备好了,操作系统又会把等待队列中的把对应的等待进程重新放回运行队列里
进而进行调用读取
进程状态
1. 基本状态
进程状态本质上是 task_struct 中的一个整型变量。从操作系统原理的角度,进程的基础状态主要有三种:就绪态(等待 CPU)、运行态(正在占用 CPU)、阻塞态(等待 I/O 或事件)。当系统内存紧张时,还会将某些进程的代码和数据换出到磁盘,形成挂起态(又可细分为静止就绪和静止阻塞)。
2. 阻塞状态
例如在 C 语言中执行 scanf,如果用户没有输入,硬件设备(如键盘)就未就绪。
操作系统管理硬件也遵循"先描述,再组织"的原则,硬件的结构体中会包含与进程相关的链接字段。
当进程执行 scanf 发现底层硬件未就绪时,操作系统会将进程的 PCB 从 CPU 调度队列中移除,放入该硬件(如键盘)的等待队列中。此时进程不再被调度,进入阻塞状态。
当硬件准备就绪后,操作系统会将等待队列中的进程重新放回运行队列,继续执行。
3. 挂起状态
核心概念:用时间换取内存空间。当系统物理内存紧张时,操作系统会将暂时无法运行的进程的代码段、数据段从物理内存移至磁盘的 Swap 分区 暂存,仅保留 PCB。待条件满足后,再将数据从磁盘调入内存,加入调度队列等待 CPU 执行。
内存紧张时,系统频繁做进程换入换出,本质就是用 IO 时间成本换取内存空间,以此腾出运行空间。
即便开启阻塞挂起、运行挂起,内存依旧严重不足时,系统就会执行杀进程操作,直接终止占用资源多的进程,彻底释放内存。
日常电脑、手机软件无故闪退,大多就是系统内存耗尽,主动清理杀掉进程导致。
两种挂起区分
阻塞挂起:进程处于等待阻塞状态时,提前将代码数据换到磁盘分区,等待条件满足后,再调回内存、加入调度队列等待运行。
就绪挂起:进程在就绪调度队列排队,还未轮到 CPU 执行,就先把数据转出磁盘,轮到调度再调入内存执行。
挂起 = 数据换出存磁盘,激活 = 数据换回内存,频繁读写磁盘外设,会大幅拖慢系统运行速度,这就是多开软件设备卡顿的核心原因。
补充知识
操作系统安装时,会自动划分交换分区,专门用来存放被挂起转出的进程数据。Windows、Linux 系统都可自行查看磁盘分区,直观看到该分区空间。
挂起分类:
阻塞挂起:进程因等待外设响应、系统资源或信号等进入阻塞等待队列,内存不足时,其代码与数据被换出至 Swap 分区释放内存。
就绪挂起:进程已准备就绪,在就绪队列中等待 CPU 调度。内存压力大时,系统会提前将闲置的就绪进程置换到 Swap 分区,为活跃进程腾出内存。
Swap 分区细节:
作用:充当"内存备胎",实现逻辑内存扩容;统一存放被挂起进程的代码与数据;缓解物理内存满载导致的系统运行阻塞。
弊端:底层依赖磁盘 I/O,读写速度远低于物理内存。分区过大易导致系统过度依赖 Swap,频繁触发换入换出操作,消耗系统资源,降低整机效率,使进程唤醒加载耗时增加,出现明显卡顿。
大小建议:
小内存设备:Swap 容量 = 物理内存容量
常规办公设备:Swap 容量 = 物理内存的 1/2
16G 及以上大内存设备:配置 2~4G 即可
服务器场景:主流云服务器默认关闭 Swap 分区,以节省磁盘资源、避免高频 I/O 损耗,保障高性能稳定运行。
系统弊端:进程频繁换入换出产生海量磁盘 I/O,拉高系统负载;闲置进程唤醒需二次加载数据,启动和响应速度变慢;日常多开软件卡顿、后台程序掉线,核心原因往往是内存爆满触发进程挂起置换。
内存耗尽应急机制(OOM) :当进程挂起和 Swap 全部用尽后内存依然严重不足时,操作系统会启动 OOM 进程查杀机制,自动筛选高内存占用、低优先级的后台进程强制终止,彻底释放其占用的全部内存资源,以保障系统核心进程稳定运行。
实际表现:移动端 APP 无故闪退、后台应用被清理;服务端高并发场景业务进程宕机、网站服务崩溃。
理论状态与 Linux 实际状态的区别:教材理论中的进程状态通常更完整,包括新建态、就绪态、运行态、阻塞态、挂起态等,划分细致。而 Linux 实际内核实现中的状态分类会略有不同,更为具体。
整体流程总结:
内存充足:所有进程常驻物理内存,CPU 直接调度执行。
内存紧张:闲置的阻塞或就绪进程触发挂起,数据存入 Swap 分区释放内存。
进程就绪:从 Swap 调取数据重回内存,加入就绪队列等待调度。
内存爆满:挂起机制失效,系统自动查杀多余进程,兜底保障系统运行。