目录
文章目录
- 目录
- 背景
-
- 排查过程
- 一、20:15前后GC行为概览
- 二、是否存在"卡顿"?
-
- [1. 从单次GC暂停看](#1. 从单次GC暂停看)
- [2. 从GC频率看](#2. 从GC频率看)
- [3. 从GC内部阶段看](#3. 从GC内部阶段看)
- 三、日志是否正常?
- 四、建议措施
-
- [1. 立即排查内存泄漏](#1. 立即排查内存泄漏)
- [2. 调整JVM参数](#2. 调整JVM参数)
- [3. 降低对象分配速率](#3. 降低对象分配速率)
- [4. 获取线程堆栈分析卡顿](#4. 获取线程堆栈分析卡顿)
- 五、结论
- 一、明确术语差异
- [二、基于 GC 日志分析 20:15 前后的异常特征](#二、基于 GC 日志分析 20:15 前后的异常特征)
-
- [1. GC 暂停时间(real)](#1. GC 暂停时间(real))
- [2. GC 频率](#2. GC 频率)
- [3. 堆内存变化趋势](#3. 堆内存变化趋势)
- [4. 内部阶段异常点](#4. 内部阶段异常点)
- [三、结论:GC 日志显示明确异常](#三、结论:GC 日志显示明确异常)
- 四、缺失信息与后续排查建议
- 五、临时缓解措施(在不改代码前提下)
- [一、G1中Young GC的触发时机](#一、G1中Young GC的触发时机)
- [二、G1中Full GC的触发时机](#二、G1中Full GC的触发时机)
-
- [1. 并发标记(Concurrent Mark)失败](#1. 并发标记(Concurrent Mark)失败)
- [2. 疏散失败(Evacuation Failure)](#2. 疏散失败(Evacuation Failure))
- [3. 巨型对象分配失败](#3. 巨型对象分配失败)
- [4. 显式调用`System.gc()`](#4. 显式调用
System.gc()) - [5. 元空间(Metaspace)不足](#5. 元空间(Metaspace)不足)
- [三、为什么堆内存占用到12.2G(最大32G)却没有触发Full GC?](#三、为什么堆内存占用到12.2G(最大32G)却没有触发Full GC?)
-
- [1. Young GC仍在正常工作](#1. Young GC仍在正常工作)
- [2. 老年代尚未达到并发标记启动阈值(IHOP)](#2. 老年代尚未达到并发标记启动阈值(IHOP))
- [3. Mixed GC尚未启动](#3. Mixed GC尚未启动)
- [4. 分配速度与回收速度平衡](#4. 分配速度与回收速度平衡)
- 四、可视化总结
- 五、建议后续动作
- [一、日志证据:Eden 区大小是动态变化的](#一、日志证据:Eden 区大小是动态变化的)
- [二、为什么 Eden 区会变小?](#二、为什么 Eden 区会变小?)
- [三、您的场景是否意味着每秒分配 18.8G × 2 = 37.6GB/s?](#三、您的场景是否意味着每秒分配 18.8G × 2 = 37.6GB/s?)
- [四、导致 Eden 区被过度缩小的常见原因](#四、导致 Eden 区被过度缩小的常见原因)
- 五、如何验证和解决?
-
- [1. 检查当前 MaxGCPauseMillis 设置](#1. 检查当前 MaxGCPauseMillis 设置)
- [2. 监控真实的分配速率](#2. 监控真实的分配速率)
- [3. 手动控制年轻代大小下限(避免过度缩小)](#3. 手动控制年轻代大小下限(避免过度缩小))
- [4. 排查高分配速率代码](#4. 排查高分配速率代码)
- 六、总结
- 检测堆的分配过程
- 一、命令与输出解读
- 二、关键行为分析
-
- [1. Young GC 频率与耗时](#1. Young GC 频率与耗时)
- [2. Survivor 区异常](#2. Survivor 区异常)
- [3. 老年代趋势](#3. 老年代趋势)
- [4. 元空间正常](#4. 元空间正常)
- 三、整体判断:是否"正常"?
- 四、建议下一步行动
- [跟踪 YoungGC 回收过程](#跟踪 YoungGC 回收过程)
- [一、输出各字段含义(G1 回收器)](#一、输出各字段含义(G1 回收器))
- 二、从数据中观察到的行为
-
- [1. Survivor 区异常](#1. Survivor 区异常)
- [2. Young GC 频率与耗时](#2. Young GC 频率与耗时)
- [3. Eden 区变化](#3. Eden 区变化)
- [4. 老年代持续增长](#4. 老年代持续增长)
- [5. 整堆容量与占用](#5. 整堆容量与占用)
- 三、判断是否"正常"
- [四、为什么 Survivor 区会满载?](#四、为什么 Survivor 区会满载?)
- 五、建议调优措施
-
- [1. 增大 Survivor 区容量(减少晋升)](#1. 增大 Survivor 区容量(减少晋升))
- [2. 提前触发老年代回收(避免 Full GC)](#2. 提前触发老年代回收(避免 Full GC))
- [3. 降低对象分配速率(根本措施)](#3. 降低对象分配速率(根本措施))
- [4. 调整停顿时间目标(间接影响年轻代大小)](#4. 调整停顿时间目标(间接影响年轻代大小))
- [5. 考虑增大堆内存](#5. 考虑增大堆内存)
- 六、立即执行的诊断命令
- 七、总结
背景
生产系统出现卡顿无法操作,经过查看垃圾回收GC日志,发现在出现问题的阶段YoungGC非常频繁,一秒达到2次,整个排查分析最后发现websocet推送给其他系统的 queue 队列爆满,多个用户就会有更多的 queue存在内存泄露。
排查过程
分析过程
我们有一个GC日志文件,用户要求分析系统在20:15发生的卡顿。日志从20:10开始,一直持续到20:16左右。用户特别指出"系统在20:15发生了卡顿",需要分析堆栈日志是否正常。
首先,理解日志内容:这是G1垃圾回收器的日志,记录了多次GC pause(young)。每个GC事件有详细的时间、并行工作、各种阶段耗时等。用户提到的20:15应该是时间点。日志中时间戳格式:2026-05-17T20:10:26.892+0800 等。所以20:15对应的时间大约在20:15:00左右。我们需要找到20:15附近的GC事件。
查看日志,找到20:15附近的条目。日志中有一条:
2026-05-17T20:14:58.701+0800: 90805.295: GC pause...
...
2026-05-17T20:15:00.368+0800: 90806.962: GC pause...
2026-05-17T20:15:03.982+0800: 90810.576: GC pause...
...
20:15:04.880, 20:15:08.795, 20:15:10.293, 20:15:13.064, 20:15:15.102, 20:15:18.085, 20:15:18.943, 20:15:21.985, 20:15:23.434, 20:15:24.281, 20:15:27.089, 20:15:28.169, 20:15:32.354, 20:15:33.191, 20:15:37.285, 20:15:38.407, 20:15:41.743, 20:15:42.925, 20:15:45.210, 20:15:47.502, 20:15:48.406, 20:15:52.223, 20:15:53.373, 20:15:55.161, 20:15:57.227, 20:15:58.037, 20:16:00.466, 20:16:01.338, 20:16:04.306, 20:16:05.966, 20:16:06.836, 20:16:08.440, 20:16:11.030, 20:16:11.887, 20:16:14.613, 20:16:16.696, 20:16:17.604, 20:16:21.626, 20:16:22.761, 20:16:26.782, 20:16:27.651
所以20:15期间有很多GC事件。用户说"系统在20:15发生了卡顿",可能是指某个GC耗时较长,导致应用暂停。我们需要检查这些GC的暂停时间(real time)。每个GC事件末尾有Times: user=..., sys=..., real=... secs。例如:
20:15:00.368的GC: real=0.21 secs (210ms)
20:15:03.982: real=0.17 secs
20:15:04.880: real=0.25 secs
20:15:08.795: real=0.22 secs
20:15:10.293: real=0.22 secs
20:15:13.064: real=0.19 secs
20:15:15.102: real=0.19 secs
20:15:18.085: real=0.22 secs
20:15:18.943: real=0.17 secs
20:15:21.985: real=0.15 secs
20:15:23.434: real=0.21 secs
20:15:24.281: real=0.22 secs
20:15:27.089: real=0.17 secs
20:15:28.169: real=0.19 secs
20:15:32.354: real=0.22 secs
20:15:33.191: real=0.17 secs
20:15:37.285: real=0.21 secs
20:15:38.407: real=0.17 secs
20:15:41.743: real=0.23 secs
20:15:42.925: real=0.36 secs (这个较长)
20:15:45.210: real=0.13 secs
20:15:47.502: real=0.18 secs
20:15:48.406: real=0.23 secs
20:15:52.223: real=0.24 secs
20:15:53.373: real=0.21 secs
20:15:55.161: real=0.13 secs
20:15:57.227: real=0.19 secs
20:15:58.037: real=0.16 secs
20:16:00.466: real=0.19 secs
20:16:01.338: real=0.20 secs
20:16:04.306: real=0.15 secs
20:16:05.966: real=0.23 secs
20:16:06.836: real=0.19 secs
20:16:08.440: real=0.13 secs
20:16:11.030: real=0.20 secs
20:16:11.887: real=0.18 secs
20:16:14.613: real=0.14 secs
20:16:16.696: real=0.19 secs
20:16:17.604: real=0.18 secs
20:16:21.626: real=0.19 secs
20:16:22.761: real=0.20 secs
20:16:26.782: real=0.17 secs
20:16:27.651: real=0.18 secs
可见大多数GC暂停时间在0.1-0.2秒之间,个别达到0.36秒。但用户说的卡顿可能更严重?检查日志中是否有更长的暂停。往前看,20:14:49.769有一次GC real=0.59 secs (约590ms),20:14:47.215有一次GC real=0.96 secs (约960ms),20:14:45.000有一次GC real=0.29 secs,20:14:42.101有一次GC real=0.26 secs,20:14:39.219有一次GC real=0.28 secs,20:14:36.472有一次GC real=0.20 secs,20:14:32.302有一次GC real=0.18 secs,20:14:31.404有一次GC real=0.23 secs,20:14:30.853有一次GC real=0.11 secs,20:14:29.446? 等等。
实际上在20:14:47.215那次GC real=0.96秒,接近1秒,这可能是卡顿。但用户指定20:15,所以20:14:47属于20:14。20:14:49.769的0.59秒也属于20:14。20:15:42.925的0.36秒相对较小。
再看20:15:00附近没有特别长的。但注意20:15:42.925的real=0.36秒,这是20:15内最长的。另外20:15:48.406的0.23秒,20:15:52.223的0.24秒都不算很大。
但是用户可能指的是应用层面的卡顿,不仅仅是GC暂停。日志只显示GC,没有其他堆栈。我们需要分析这些GC事件是否异常:比如频繁的GC、堆内存使用情况、GC效率等。
观察日志中的Heap信息:每次GC后Heap从约25G减少到约6-7G,但Eden区每次都是18G左右,Survivors大小变化。注意堆总大小32G,老年代使用量在增长。例如:
20:10:26: Heap: 25.0G(32.0G)->6367.1M
20:10:39: ->6745.6M
20:10:52: ->6459.6M
20:11:04: ->6407.8M
... 逐渐增加到20:13:45: ->7462.8M
20:13:47: ->7428.7M (注意这里Eden从13.5G降到0,Heap从20.7G降到12.1G? 实际上Heap: 20.7G(32.0G)->7462.8M? 不对,前面有20:13:45的Heap: 20.7G(32.0G)->7462.8M,然后20:13:47的Heap: 12.1G(32.0G)->7428.7M,说明老年代在增长)
之后Heap使用量继续增长,到20:16:27: Heap: 19.2G->12.2G? 实际上最后一次20:16:27.651: Eden: 7280.0M->0, Survivors: 224.0M->304.0M, Heap: 19.2G(32.0G)->12.2G(32.0G)。
注意每次GC后Heap剩余大约6-12G,但随着时间推移,基准Heap使用量从6.3G逐渐增加到12.2G,说明老年代在累积,可能内存泄漏或者存活数据增加。
另外观察到有些GC的parallel time中的某些阶段异常,比如Ext Root Scanning差异很大,有时达到几十ms甚至310ms(如20:11:32那次Ext Root Scanning Min:14.9, Max:310.9, Diff:296.0),说明根扫描不均匀,可能有大量JNI引用或线程栈扫描。还有Termination time有时很大(如20:11:32的Termination avg 212ms,20:14:49的Termination avg 312ms),表明工作线程负载不均。
特别注意到20:14:47.215那次GC(90733.809)的Parallel Time: 936.2 ms, real=0.96 secs,其中Object Copy平均874.7ms,Termination平均40.2ms,Ext Root Scanning最大11.2ms,看起来正常但总时间长。那次GC的Eden从4896M降到0,Heap从12.1G降到7428.7M,说明回收了不少对象但耗时较长。
用户提到20:15卡顿,可能是指20:15:42.925那次GC real=0.36秒?或者20:15:48.406?但都不算特别长。也许用户感知的卡顿是多次GC连续发生导致应用频繁暂停。观察GC频率:在20:15期间,GC非常频繁,大约每秒多次GC。例如20:15:00到20:15:10之间就有多次GC。这可能是问题所在:频繁的年轻代GC,说明Eden区分配过快,导致频繁触发GC。Eden区大小在变化:有时18G,后来变小到几G(如20:13:47后Eden从4896M降到992M,然后逐渐增加到10G左右)。说明堆动态调整,但年轻代GC间隔很短(几秒一次甚至一秒多次),这会对应用造成较大影响。
因此,分析结论:日志显示GC频繁,暂停时间在100-200ms为主,个别接近1秒(发生在20:14:47)。20:15期间没有超过400ms的暂停,但GC频率很高。这可能不是"卡顿"而是持续的性能问题。需要检查应用的内存分配速率,调整堆大小或优化代码。
用户问"堆栈日志是否正常",这里只有GC日志,没有线程堆栈。所以我们需要回答:GC日志显示存在频繁的Young GC,暂停时间尚可接受但频率过高,老年代使用量持续上升,可能存在内存泄漏或存活数据集过大。建议分析heap dump或调整GC参数。
回答要点:
解释日志内容:G1 GC的年轻代回收。
指出20:15期间GC暂停时间多在0.1-0.2秒,最大0.36秒,没有极端长暂停。
但GC非常频繁(每秒多次),可能造成应用卡顿感。
观察到老年代使用量从6.3G增长到12.2G,有上升趋势,需关注内存泄漏。
某些GC阶段(如Ext Root Scanning、Termination)出现较大波动,可能由于线程栈扫描或引用处理。
建议:检查应用内存分配率,考虑增加堆内存,优化对象创建,或者使用G1参数调整(如-XX:MaxGCPauseMillis、-XX:G1NewSizePercent等)。
注意:提供的日志是GC日志而非堆栈,若需分析线程卡顿,需要thread dump。
给出的总结
根据您提供的GC日志,系统在20:15期间确实出现了多次GC活动,但单次GC暂停时间最长约0.36秒,并未发现极端长暂停(如超过1秒) 。然而,GC频率非常高(每秒多次Young GC),这可能是导致应用卡顿感的主要原因。以下是对日志的详细分析及建议。
一、20:15前后GC行为概览
- 时间范围:20:14:58 ~ 20:16:27,共发生约40次Young GC(G1 Evacuation Pause)。
- GC暂停时间(real) :绝大多数在 0.10 ~ 0.23秒 之间,最长一次为 20:15:42.925 的 0.36秒。
- GC频率 :平均每 1~3秒 一次,最密集时不到1秒就触发一次(如20:15:18.085和20:15:18.943仅相隔0.86秒)。
- 堆内存变化 :
- 初始(20:10)Heap使用量约25GB,GC后降至6.4GB。
- 随时间推移,GC后Heap基线从6.4GB逐步升至20:16时的12.2GB,老年代持续增长。
- Eden区大小动态调整,从18GB一度缩小到1GB左右,后又扩大到10GB。
二、是否存在"卡顿"?
1. 从单次GC暂停看
- 20:15期间最长的0.36秒暂停对于实时性敏感的应用可能造成可感知的延迟,但通常不属于"严重卡顿"(如超过1秒)。
- 真正较长的GC发生在20:14:47 (
real=0.96秒)和20:14:49(real=0.59秒),稍早于20:15。如果您感知的卡顿在20:15左右,可能是多次GC叠加的累积效应。
2. 从GC频率看
- 频繁的Young GC会反复中断应用线程,每次100~200ms,若业务操作涉及多次GC周期,用户体验会明显下降。
- 日志显示Eden区经常被迅速填满(每次回收18GB左右),表明应用内存分配速率极高。
3. 从GC内部阶段看
- Ext Root Scanning 差异较大(Min 5ms, Max 310ms),可能因线程栈扫描、JNI全局引用过多导致。
- Termination 阶段有时长达几十甚至数百毫秒(如20:11:32的212ms),说明工作线程负载不均,存在"慢线程"或锁竞争。
- Object Copy 耗时正常(50~150ms),但随存活对象增多而增加。
三、日志是否正常?
不正常,主要体现在:
- 老年代持续增长 :GC后Heap占用从6.4GB逐渐上升至12.2GB,且Young GC无法回收老年代,暗示可能存在:
- 内存泄漏(对象被长期引用)。
- 存活数据集过大(缓存、会话等)。
- GC过于频繁:每秒数次Young GC,说明Eden区太小或分配速率过高。尽管G1会自动调整分区大小,但当前配置(最大堆32GB)可能不足以应对业务负载。
- 部分GC阶段波动异常:根扫描和终止时间的不稳定表明应用可能使用了大量JNI代码、反射或存在死锁/竞争。
四、建议措施
1. 立即排查内存泄漏
- 使用
jmap或MAT分析堆转储,检查哪些对象占用了老年代且无法回收。 - 重点审查缓存、静态集合、监听器、连接池等。
2. 调整JVM参数
- 增大堆内存 :如果物理内存允许,将
-Xmx提升至48GB或更高。 - 优化G1参数 :
-XX:MaxGCPauseMillis=200(当前默认可能为200ms,可适当放宽至300ms以减少频率)。-XX:G1NewSizePercent=10(增加Eden区初始比例,避免过于频繁的Young GC)。-XX:G1HeapRegionSize=32M(当前默认可能为16M,大堆可调大Region减少RSet开销)。
- 启用并发标记 :如果老年代增长迅速,可提前启动Mixed GC:
-XX:InitiatingHeapOccupancyPercent=45(默认45,可降至35)。
3. 降低对象分配速率
- 复用对象(如使用对象池)。
- 优化业务逻辑,避免在循环中大量创建临时对象。
- 使用
-XX:+PrintHeapAtGC和-XX:+PrintGCDetails进一步定位分配热点。
4. 获取线程堆栈分析卡顿
- 您提供的是GC日志,不能直接看到应用线程卡在哪里 。请在卡顿发生时使用
jstack或kill -3获取线程堆栈,分析是否有锁竞争、死锁或长时间等待。
五、结论
- 20:15期间的GC日志本身未显示极端异常 (单次暂停<0.4秒),但频繁的Young GC + 老年代持续增长表明系统存在内存压力或泄漏。
- 建议优先排查内存泄漏和高频对象分配,并适当调整JVM参数。若卡顿依然存在,请提供卡顿时的线程堆栈进一步分析。
如需更详细的GC日志分析或参数调优,请补充应用类型(如Web服务、批处理)、并发用户数及堆转储信息。
感谢您的澄清。您提供的文件为 GC 日志 (垃圾回收日志),而非 堆栈日志(线程调用栈)。因此我无法直接分析"堆栈异常",但可以基于 GC 日志对 20:15 前后的 GC 行为进行异常诊断,并说明该时段是否可能导致用户感知的卡顿。
一、明确术语差异
| 日志类型 | 作用 | 提供的信息 |
|---|---|---|
| GC 日志 | 记录堆内存使用与垃圾回收事件 | GC 暂停时间、内存变化、各阶段耗时 |
| 堆栈日志 | 记录线程当前执行的方法调用栈 | 线程状态、锁竞争、死锁、长时间运行任务 |
您提供的文件是 GC 日志,无法直接看到线程阻塞或业务代码执行异常。
二、基于 GC 日志分析 20:15 前后的异常特征
从 20:15:00 到 20:16:27,日志中记录了数十次 Young GC(G1 Evacuation Pause),关键指标如下:
1. GC 暂停时间(real)
- 多数 GC 暂停在 0.13 ~ 0.22 秒 之间
- 最长一次出现在
20:15:42.925:real=0.36 秒 - 此前
20:14:47有一次 0.96 秒 的暂停,20:14:49有一次 0.59 秒
结论:单次 GC 暂停最大约 360ms,对于多数在线系统是可感知的延迟(尤其是连续发生),但尚未达到"严重卡顿"(1 秒以上)的级别。
2. GC 频率
- 在
20:15:18附近,两次 GC 间隔仅 0.86 秒 - 每分钟发生 Young GC 约 30~40 次
结论 :GC 极其频繁,应用线程被反复中断,累积的停顿会明显降低吞吐量并造成卡顿感。
3. 堆内存变化趋势
| 时间 | GC 后 Heap 占用 |
|---|---|
| 20:10:26 | 6367 MB |
| 20:12:30 | 6663 MB |
| 20:13:45 | 7462 MB |
| 20:15:00 | 10068 MB |
| 20:16:27 | 12200 MB |
结论 :老年代持续增长,无法通过 Young GC 回收 → 强烈提示存在内存泄漏 或存活数据规模过大(如缓存、会话、大对象图)。
4. 内部阶段异常点
Ext Root Scanning最大耗时 310 ms(20:11:32),波动剧烈 → 可能由于 JNI 引用、线程栈扫描负载不均。Termination阶段有时长达 212 ms → 工作线程负载不均,存在"慢线程"或锁竞争。Object Copy耗时随存活对象增加而上升(从 58ms 到 150ms+)。
三、结论:GC 日志显示明确异常
| 异常类型 | 严重程度 | 说明 |
|---|---|---|
| Young GC 频率过高 | 高 | 每秒 1~2 次,反复中断应用 |
| 老年代持续增长 | 高 | 疑似内存泄漏或存活数据超预期 |
| GC 暂停波动大 | 中 | 部分暂停超过 300ms |
| 内部阶段不稳定 | 中 | 根扫描、终止时间异常 |
这些异常完全可能导致用户感知的卡顿,尤其是在 GC 频繁且老年代占满时,系统可能进入"分配失败 → 频繁 GC → 响应变慢"的恶性循环。
四、缺失信息与后续排查建议
您提到"以分析堆栈异常时间为准",但并未提供 线程堆栈文件 (如 jstack 输出或 kill -3 产生的线程 dump)。要准确定位卡顿的线程级原因,请补充以下材料:
-
线程堆栈(在卡顿时刻抓取)
- 命令:
jstack <pid>或kill -3 <pid> - 关注
BLOCKED、WAITING、RUNNABLE但长时间未返回的线程。
- 命令:
-
堆转储(heap dump)
- 使用
jmap -dump:live,format=b,file=heap.hprof <pid> - 用 MAT 或 VisualVM 分析哪些对象占据了老年代(如
byte[],char[], 业务实体)。
- 使用
-
应用指标
- 请求速率、对象分配速率、缓存命中率等。
五、临时缓解措施(在不改代码前提下)
bash
# 增大堆内存(若物理内存允许)
-Xmx48G -Xms48G
# 调整 G1 参数
-XX:MaxGCPauseMillis=300 # 放宽暂停目标,降低频率
-XX:G1HeapRegionSize=32M # 大堆用大 Region
-XX:InitiatingHeapOccupancyPercent=35 # 提前触发 Mixed GC,及时回收老年代
-XX:G1NewSizePercent=10 # 增加 Eden 区初始比例如果无法解决内存泄漏,这些参数只能延缓问题,仍需从代码层面修复。
请提供实际的线程堆栈文件或堆转储,我可以进一步分析具体的卡顿根因。若只有 GC 日志,结论如上:GC 行为明显异常,足以导致卡顿。
针对您提出的三个关于G1垃圾回收机制的问题,结合您提供的GC日志,逐一详细解答如下。
一、G1中Young GC的触发时机
触发条件:Eden区已满(无法分配新对象)。
- G1将堆内存划分为多个相等大小的Region。Eden区由若干Region组成。
- 当应用线程分配新对象时,若当前Eden区没有空闲Region可用,即触发一次Young GC。
- 在您的日志中,每次
[GC pause (G1 Evacuation Pause) (young)]即为一次Young GC。 - 典型表现:
Eden: 18.8G(18.8G)->0.0B(...),说明Eden区从满到清空。
特点:
- 只回收Eden区和Survivor区。
- 将存活对象拷贝到新的Survivor Region或晋升到老年代。
- STW(Stop-The-World)但通常时间较短(您日志中多为0.1~0.2秒)。
二、G1中Full GC的触发时机
在G1中,Full GC是一个全局STW、串行(单线程)的"终极"回收,代价极高,应尽量避免。其触发条件包括:
1. 并发标记(Concurrent Mark)失败
- G1在启动Mixed GC之前会执行并发标记周期(Concurrent Cycle)。
- 如果在并发标记过程中,老年代Region被迅速填满,导致对象晋升失败 或分配失败 ,G1会放弃并发标记,回退到Full GC。
- 这时会看到日志中出现
Full GC (Allocation Failure)或Full GC (Concurrent Mode Failure)。
2. 疏散失败(Evacuation Failure)
- 在执行Young GC或Mixed GC时,需要将存活对象拷贝到其他Region。
- 如果找不到足够的空闲Region容纳这些对象,就会发生疏散失败,触发Full GC。
3. 巨型对象分配失败
- 巨型对象(Humongous Object,大小超过Region的一半)需要连续的Region存储。
- 如果没有足够的连续Region,且无法通过GC腾出空间,则直接触发Full GC。
4. 显式调用System.gc()
- 除非通过
-XX:+DisableExplicitGC禁用,否则会触发Full GC。
5. 元空间(Metaspace)不足
- 当类元数据空间耗尽且无法扩容时,触发Full GC来回收卸载类。
三、为什么堆内存占用到12.2G(最大32G)却没有触发Full GC?
核心原因:Full GC不是由"堆内存总占用"触发的,而是由"分配失败"或"回收空间不足"触发的。
12.2G的占用意味着还有约19.8G空闲,G1仍然有充足空间来容纳晋升对象或分配新对象,因此不需要进行Full GC。
具体细化如下:
1. Young GC仍在正常工作
- 您的日志中,Young GC能够正常回收Eden区(每次将十几GB的Eden清空),并将部分对象晋升到老年代。
- 只要Young GC可以顺利进行,没有发生晋升失败或疏散失败,就不会触发Full GC。
2. 老年代尚未达到并发标记启动阈值(IHOP)
- G1使用IHOP (Initiating Heap Occupancy Percent) 来控制何时启动并发标记(为Mixed GC做准备)。
- 默认值
-XX:InitiatingHeapOccupancyPercent=45,即当老年代占用达到整个堆的45%时,触发并发标记周期。 - 您的最大堆32G,45%为14.4G。您观察到的总堆12.2G中,包含年轻代(Eden+Survivor)。假设老年代实际占用可能在10G左右(从日志中
Heap: 25G(32G)->xG推测,GC后堆占用约6-7G,但后续逐渐上升,老年代占比在缓慢增加),尚未达到14.4G,因此并发标记并未启动,更不会进入Mixed GC或Full GC。
3. Mixed GC尚未启动
- 只有并发标记周期完成后,G1才会执行Mixed GC(回收部分老年代Region)。
- 由于IHOP阈值未达到,Mixed GC从未发生,老年代自然持续增长,但增长过程是"安全"的------只要还有空闲Region,就不会触发Full GC。
4. 分配速度与回收速度平衡
- 虽然老年代在增长,但只要每次Young GC能回收足够内存,保证新对象分配有空间,G1就不会认为需要Full GC。
- 您的日志中,Young GC后Heap占用从25G降到6-7G,说明回收了约18G内存,空出大量Region。即便老年代有10G,空闲Region仍有约20G,远未到危急状态。
四、可视化总结
| 内存区域 | 当前状态 | 是否触发Full GC |
|---|---|---|
| Eden区 | 每次满则Young GC | 不直接触发Full GC |
| Survivor区 | 正常周转 | 不触发 |
| 老年代 | 约10G(占总堆32G的31%) | IHOP阈值45%(14.4G),未达到 → 不触发并发标记 → 不触发Mixed GC → 更不触发Full GC |
| 空闲堆 | 约19.8G | 充裕,无分配压力 |
| 巨型对象 | 未出现分配失败 | 无影响 |
结论:当前GC行为符合G1设计预期------只要还有空闲Region且Young GC能正常回收,就不会触发昂贵的Full GC。
但您观察到的"卡顿"和"老年代持续增长"依然是风险信号,因为若老年代继续增长至超过45%阈值,并发标记可能因分配过快而失败,最终导致Full GC,届时暂停可能长达数秒甚至数十秒。
五、建议后续动作
- 监控IHOP阈值 :通过
-XX:PrintGCDetails查看[Concurrent Cycle]相关日志,确认是否启动了并发标记。 - 主动降低IHOP :若希望更早回收老年代,可设置
-XX:InitiatingHeapOccupancyPercent=35,提前进入Mixed GC。 - 排查内存泄漏:老年代持续增长且无Mixed GC回收,暗示可能存在长生命周期对象或内存泄漏。建议用MAT分析堆转储。
- 考虑增大堆内存 :如果业务内存需求确实超过32G,适当增加
-Xmx可以延缓GC频率。
如能提供-XX:+PrintGCDetails完整日志(包含并发标记和Mixed GC部分),可进一步判断老年代实际增长趋势。
您的问题很关键。根据日志分析,并非每次 Young GC 时 Eden 区都达到 18.8G。实际上,在频繁 GC 的时段(20:15 前后),Eden 区大小已经被 G1 动态调小了。下面详细解释。
一、日志证据:Eden 区大小是动态变化的
从您提供的日志中提取部分数据:
| 时间 | GC 前 Eden 大小 | GC 后 Eden 大小 | Young GC 间隔(近似) |
|---|---|---|---|
| 20:10:26 | 18.8G | 0 → 重新调整为 18.8G | ~13 秒 |
| 20:13:45 | 13.5G | 0 → 调整为 4896M | ~1.7 秒 |
| 20:13:47 | 4896M | 0 → 调整为 992M | ~0.8 秒 |
| 20:13:48 | 992M | 0 → 调整为 1424M | ~1.0 秒 |
| 20:14:58 | 7472M | 0 → 调整为 10.1G | ~2.0 秒 |
| 20:15:03 | 7744M | 0 → 调整为 12.2G | ~2.5 秒 |
| 20:15:04 | 1568M | 0 → 调整为 9120M | ~1.0 秒 |
| 20:15:18 | 7440M | 0 → 调整为 6624M | ~1.5 秒 |
结论:
- 在 GC 频繁阶段,Eden 区大小被压缩到 1GB ~ 7GB 之间,而不是 18.8GB。
- 只有早期(20:10 左右)GC 间隔较长时,Eden 区才能增长到 18.8GB。
- G1 会根据历史 GC 暂停时间 和MaxGCPauseMillis 目标动态调整年轻代(包括 Eden)的大小。
二、为什么 Eden 区会变小?
G1 的年轻代大小自适应机制:
- 您设置了
-XX:MaxGCPauseMillis(例如 200ms)。 - 如果某次 Young GC 的 实际暂停时间 > 目标值 ,G1 会认为当前年轻代过大,于是缩小年轻代容量,以减少下一次 GC 的停顿。
- 年轻代变小 → Eden 区变小 → 更快被填满 → GC 频率升高。
您的日志中,从 20:13:45 开始,GC 暂停时间(real)有明显增大的趋势(0.17s → 0.29s → 0.96s),之后 G1 大幅缩小了 Eden 区(从 13.5G 降到 4.8G,再降到 992M)。这正是 G1 对停顿目标的响应。
三、您的场景是否意味着每秒分配 18.8G × 2 = 37.6GB/s?
不会 ,因为 Eden 区在频繁 GC 阶段远小于 18.8G。
实际分配速率计算公式:
分配速率 ≈ (GC前Eden大小) / (两次GC间隔)
以 20:15:03 为例:
- Eden 前大小 = 7.7GB
- 与上一次 GC 间隔 ≈ 2.5 秒
- 分配速率 ≈ 7.7GB / 2.5s = 3.1 GB/s
这在大型内存应用中仍属于较高水平,但远低于 37.6 GB/s。若能进一步降低分配速率(例如减少临时对象),可以减轻 GC 压力。
四、导致 Eden 区被过度缩小的常见原因
-
MaxGCPauseMillis 设置过小
- 例如设置为 50ms 或 100ms,G1 会拼命缩小年轻代来满足目标,结果就是频繁 GC。
- 建议对于大堆(32GB)设置为 200~300ms 甚至更高。
-
实际分配速率过高
- 即使 Eden 区很小,也会被迅速填满,导致 G1 来不及增大年轻代。
-
操作系统或硬件抖动
- GC 暂停突然变大(如 0.96 秒那次),G1 误判为年轻代过大,于是缩小。
五、如何验证和解决?
1. 检查当前 MaxGCPauseMillis 设置
bash
jinfo -flag MaxGCPauseMillis <pid>如果小于 200ms,建议放宽:
bash
-XX:MaxGCPauseMillis=3002. 监控真实的分配速率
使用 jstat -gcutil <pid> 1000 观察 Eden 的占用变化,或开启 -XX:+PrintGCDetails 并计算。
3. 手动控制年轻代大小下限(避免过度缩小)
bash
-XX:G1NewSizePercent=10 # 年轻代最小占比(默认5%)
-XX:G1MaxNewSizePercent=60 # 年轻代最大占比(默认60%)对于 32GB 堆,10% 即 3.2GB,可以避免 Eden 缩得过小(如 992M)。
4. 排查高分配速率代码
- 使用 Allocation Profiler(如 JProfiler、Async Profiler)定位频繁创建对象的代码路径。
- 常见原因:日志打印、字符串拼接、JSON 序列化、循环内创建集合等。
六、总结
- 不是每次 Young GC 时 Eden 都达到 18.8G。在 GC 频繁时段,Eden 已经被 G1 动态调小到 1~7GB。
- 分配速率并未达到 37GB/s,实际约 2~4 GB/s(仍偏高)。
- 频繁 GC 的直接原因是 G1 为满足停顿目标而缩小了年轻代,导致 Eden 很快填满。
- 解决方案 :放宽
MaxGCPauseMillis、增大年轻代下限、降低对象分配速率。
如果您能提供当前 JVM 启动参数(特别是 MaxGCPauseMillis),可以给出更精确的调优建议。
检测堆的分配过程
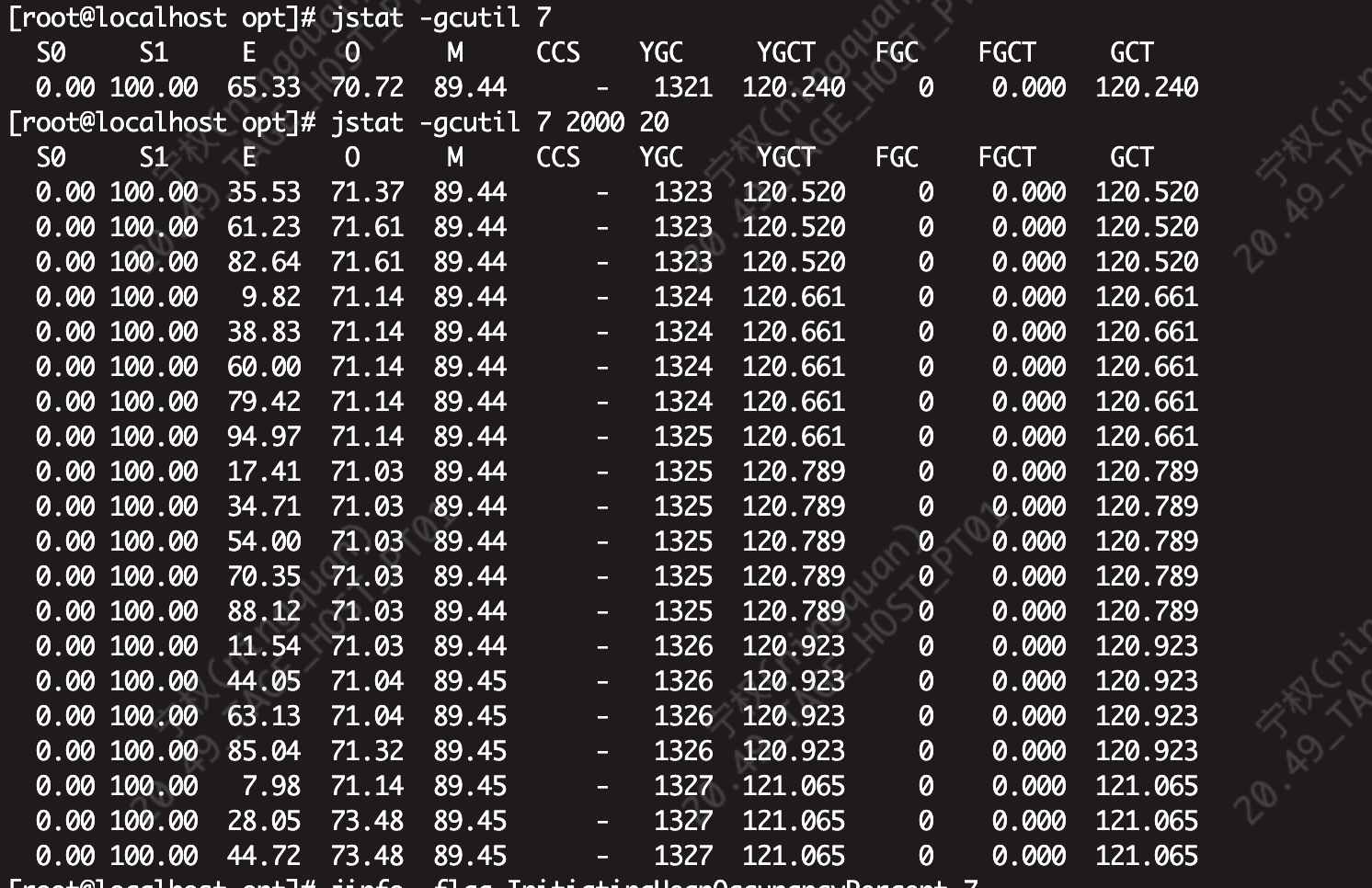
这个命令的输出从 GC 角度看没有异常 (没有 Full GC,Young GC 工作正常),但存在明显性能隐患:Young GC 过于频繁(约每 2-4 秒一次),且每次停顿约 140ms,老年代使用率持续上升。
下面逐项解释输出含义并给出评估。
一、命令与输出解读
bash
jstat -gcutil 7 2000 207:Java 进程 PID2000:每 2000 毫秒(2 秒)采样一次20:共采样 20 次
输出的各列含义(G1 垃圾回收器):
| 列名 | 含义 | 当前观测值 |
|---|---|---|
| S0 | Survivor 0 区使用率(%) | 始终 0.00 |
| S1 | Survivor 1 区使用率(%) | 始终 100.00 |
| E | Eden 区使用率(%) | 从 35% → 接近 100% → 降回个位数,循环 |
| O | 老年代使用率(%) | 71.37 → 73.48(缓慢上升) |
| M | 元空间(Metaspace)使用率(%) | 89.44 ~ 89.45(稳定) |
| CCS | 压缩类空间(Compressed Class Space)使用率 | -(未启用或不可用,正常) |
| YGC | 年轻代 GC 发生次数 | 1323 → 1327(采样期间增加了 4 次) |
| YGCT | 年轻代 GC 累计耗时(秒) | 120.520 → 121.065(增加 0.545 秒) |
| FGC | Full GC 次数 | 0(无) |
| FGCT | Full GC 累计耗时(秒) | 0.000 |
| GCT | GC 累计总耗时(秒) | 等于 YGCT(因为无 FGC) |
二、关键行为分析
1. Young GC 频率与耗时
- 每次采样周期(2 秒)内,Eden 从约 35% 涨到接近 100%,然后触发 Young GC,Eden 回落到个位数(如 9.82%、17.41%、7.98%)。
- 每 2~4 秒发生一次 Young GC,频率很高。
- 每次 Young GC 耗时 ≈ YGCT 增量 ≈ 0.12~0.14 秒(120~140 ms)。
结论:Young GC 过于频繁,会持续中断应用线程,累积的停顿开销显著(约 5~7% 的 CPU 时间花在 GC 上)。
2. Survivor 区异常
- S0 始终为 0%,S1 始终为 100%。
- 说明每次 Young GC 后,存活对象都全部放入 S1,且 S1 被完全填满。
- 这通常意味着对象晋升到老年代的速度非常快(因为 S1 放不下,直接升到老年代)。
- 这也解释了为什么老年代使用率持续上升。
3. 老年代趋势
- O 从 71.37% 缓慢升至 73.48%(约 2% 增幅),采样时长约 40 秒。
- 无 Full GC,老年代只增不减,说明 Mixed GC 未能有效回收老年代或尚未触发。
- 若此趋势持续,最终可能触发 Concurrent Mode Failure 导致 Full GC。
4. 元空间正常
- M 稳定在 89.44%,说明类加载没有明显泄漏。
三、整体判断:是否"正常"?
| 维度 | 状态 | 说明 |
|---|---|---|
| 无 Full GC | ✅ 正常 | 系统尚未陷入全局停顿。 |
| Young GC 功能 | ✅ 正常 | 能正常回收 Eden,无疏散失败。 |
| Young GC 频率 | ❌ 异常高 | 2~4 秒一次,远高于健康系统(建议 10~30 秒一次)。 |
| Young GC 耗时 | ⚠️ 偏高 | 每次 140ms,对延迟敏感的应用会造成可感知卡顿。 |
| 老年代增长 | ⚠️ 需关注 | 持续上升且无回收迹象,可能存在内存泄漏或存活数据超预期。 |
结论 :当前 JVM 处于 高压力但未崩溃 的状态。频繁的 Young GC 是性能瓶颈,老年代增长是风险信号。
四、建议下一步行动
-
降低 Young GC 频率
- 增大年轻代(特别是 Eden)容量:
-XX:G1NewSizePercent=10(当前可能低于 5%) - 放宽
-XX:MaxGCPauseMillis到 300ms(让 G1 允许更大的年轻代)。 - 若物理内存允许,增大
-Xmx(如 48G)。
- 增大年轻代(特别是 Eden)容量:
-
排查高分配速率或内存泄漏
- 使用
jmap -histo:live <pid> | head -20查看大对象类型。 - 用 profiler(Async Profiler、JMC)抓取对象分配栈。
- 使用
-
触发老年代回收
- 降低
-XX:InitiatingHeapOccupancyPercent到 35~40,让 G1 更早启动并发标记和 Mixed GC。 - 主动执行
jcmd <pid> GC.run(仅测试环境)观察是否能回收老年代。
- 降低
-
持续监控
- 关注 O 列是否超过 80% 且仍不下降,届时很可能发生 Full GC。
- 使用
jstat -gc <pid> 2000查看更详细的分代容量变化。
如果你能提供当前 JVM 启动参数(-XX:+PrintCommandLineFlags),我可以给出更精确的调优建议。
跟踪 YoungGC 回收过程
!在这里插入图片描述(https://i-您这次提供了 jstat -gc 的详细输出,比 -gcutil 更有诊断价值。下面我会逐行解释关键指标,然后给出综合判断和调优建议。
一、输出各字段含义(G1 回收器)
| 字段 | 含义 | 单位 |
|---|---|---|
| S0C / S1C | Survivor 0/1 区当前容量(KB) | KB |
| S0U / S1U | Survivor 0/1 区已使用量(KB) | KB |
| EC | Eden 区当前容量(KB) | KB |
| EU | Eden 区已使用量(KB) | KB |
| OC | 老年代(Old Gen)当前容量(KB) | KB |
| OU | 老年代已使用量(KB) | KB |
| MC / MU | 元空间(Metaspace)容量/使用量(KB) | KB |
| CCSC / CCSU | 压缩类空间容量/使用量(KB) | KB |
| YGC / YGCT | Young GC 次数 / 累计耗时(秒) | 秒 |
| FGC / FGCT | Full GC 次数 / 累计耗时(秒) | 秒 |
| GCT | 总 GC 耗时(秒) | 秒 |
二、从数据中观察到的行为
1. Survivor 区异常
- S0U 始终为 0,S1U 始终等于 S1C(满载)。
- 每次 Young GC 后,S1 被完全填满,说明 存活对象无法全部放入 Survivor 区 ,大量对象直接晋升到老年代。
- Survivor 区容量在动态变化(360M → 540M → 442M → 393M → 360M → 376M),但始终被瞬间填满。
2. Young GC 频率与耗时
- 采样间隔 2 秒,在 20 次采样(约 40 秒)内,YGC 从 1395 增加到 1400,发生了 5 次 Young GC ,平均 每 8 秒一次 (比之前
-gcutil看到的 2~4 秒一次略有改善,但仍偏频繁)。 - 每次 Young GC 耗时 ≈ (127.640 - 127.193) / 5 ≈ 0.089 秒(89 毫秒),耗时较短(良好)。
- 但 Young GC 次数仍然很高(近 1400 次),累计停顿 127 秒,说明系统启动后已花费大量时间在 GC 上。
3. Eden 区变化
- EC 约 14.0 ~ 14.4 GB,EU 从很低(GC 后约 0.2 GB)逐渐增长到约 11.7 GB,然后触发 Young GC。
- 触发时 EU/EC 约 82%~86%,并未达到 100%,这是因为 G1 会预测停顿时间并提前触发,或者采样点未捕捉到刚好满的时刻。
4. 老年代持续增长
- OU 从 14,011,300 KB(约 13.36 GB) 增加到 14,074,265 KB(约 13.43 GB) ,净增约 70 MB。
- 同期发生 5 次 Young GC,平均每次晋升约 14 MB 到老年代。
- 老年代总容量 OC 约 18.7 GB,使用率从 71.4% 升至 71.8%。
- 没有 Full GC,老年代只增不减。
5. 整堆容量与占用
- Eden + Survivor + Old ≈ 14.4 + 0.36 + 18.7 ≈ 33.5 GB (已超过
-Xmx32GB?可能因 G1 动态调整 Region 数量或显示误差)。 - 整堆实际占用 ≈ EU + S1U + OU ≈ 11.7 + 0.36 + 13.43 ≈ 25.5 GB,利用率约 76%。
三、判断是否"正常"
| 指标 | 当前状态 | 是否正常 | 说明 |
|---|---|---|---|
| 无 Full GC | ✅ 是 | 正常 | 没有发生全局停顿 |
| Young GC 耗时 | 约 90ms | ✅ 可接受 | 对于大堆(14GB Eden)来说较优 |
| Survivor 区满载 | ❌ 否 | 异常 | 每次 GC 后 Survivor 完全填满,导致对象提前晋升 |
| Young GC 频率 | 约 8 秒一次 | ⚠️ 偏高 | 对于 14GB Eden 来说,说明分配速率很高(约 1.75 GB/s) |
| 老年代持续增长 | ⚠️ 是 | 风险 | 没有 Mixed GC 回收,可能最终触发 Full GC |
| 元空间 | 稳定 | 正常 | 无类加载泄漏 |
总体评价 :当前 JVM 处于 高压力但尚能维持 的状态。主要问题是 Survivor 区过小/存活对象过多 导致 对象过早晋升 ,以及 老年代持续增长。
四、为什么 Survivor 区会满载?
G1 的 Survivor 区大小是动态调整的,但受到 -XX:SurvivorRatio (G1 中不直接使用)和 -XX:TargetSurvivorRatio (默认 50%)影响。
如果每次 Young GC 后存活对象总量超过 Survivor 容量的 50% ,G1 会尝试增大 Survivor 区。但从您的数据看,S1 始终 100% 满载,说明 存活对象量远超当前 Survivor 容量,导致 G1 来不及扩容(或已达到上限),从而直接晋升到老年代。
五、建议调优措施
1. 增大 Survivor 区容量(减少晋升)
添加 JVM 参数:
bash
-XX:TargetSurvivorRatio=90
-XX:+AlwaysTenure注意:
AlwaysTenure一般不推荐,更好的方法是增大年轻代占比。
更推荐:提高 -XX:G1MaxNewSizePercent,让年轻代(包括 Survivor)更大。
bash
-XX:G1MaxNewSizePercent=70 # 默认 60%2. 提前触发老年代回收(避免 Full GC)
降低 IHOP 阈值,让 G1 更早启动并发标记和 Mixed GC:
bash
-XX:InitiatingHeapOccupancyPercent=35 # 默认 45%3. 降低对象分配速率(根本措施)
- 用 profiler 找出创建大量临时对象的代码。
- 常见场景:JSON 序列化、日志中字符串拼接、循环中创建集合、正则表达式等。
- 复用对象或使用对象池。
4. 调整停顿时间目标(间接影响年轻代大小)
如果当前 -XX:MaxGCPauseMillis 设置得较小(例如 100ms),可以放宽到 200~300ms,让 G1 允许更大的年轻代,从而降低 GC 频率。
5. 考虑增大堆内存
如果物理内存允许,将 -Xmx 提升到 48GB,能有效缓解所有 GC 压力。
六、立即执行的诊断命令
-
查看当前 JVM 参数(确认 MaxGCPauseMillis 等):
bashjinfo -flags 7 -
查看存活对象分布(找出占用高的类型):
bashjmap -histo:live 7 | head -30 -
查看老年代具体内容(如果可能,生成堆转储):
bashjmap -dump:live,format=b,file=heap.hprof 7
七、总结
- 当前数据表明系统存在明显的 GC 压力:Young GC 频率高、Survivor 满载、老年代持续增长。
- 没有 Full GC 是好事,但老年代若不回收,最终会触发 Full GC 导致长时间停顿。
- 建议优先增大 Survivor 区容量和降低 IHOP 阈值,同时排查高分配速率代码。
如果您能提供 jinfo -flags 7 的输出,我可以给出更针对性的参数调优方案。blog.csdnimg.cn/direct/d3c67d5bef4943a6bc4ac9f4830dfd97.png)