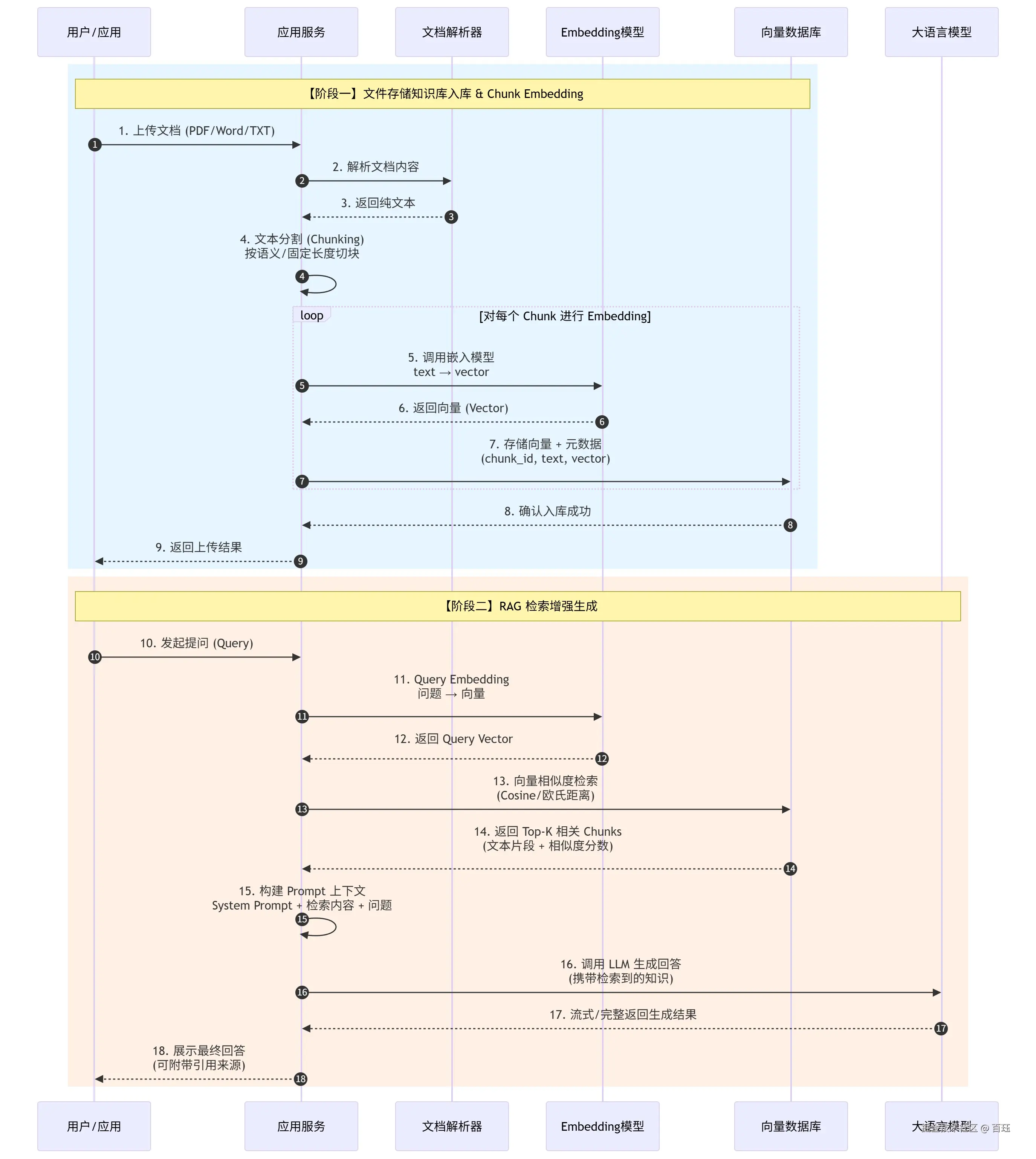
以下内容主要是在内部分享<AI 应用技术演进串讲>的大纲 讲述了gpt时刻以来 个人认为几个比较重要的改动 涵盖了主流媒体得一些理解 和相关学习内容
LLM协议格式
developers.openai.com/api/docs/qu...
api-docs.deepseek.com/zh-cn/api/c...
本质是无状态的(Stateless),所有的"记忆"都是通过请求上下文全量传递
重点拆解
-
System Prompt: 系统提示词 人设与全局规则
-
User Prompt: 用户提示词 用户输入
-
Assistant: 模型回复
-
Function Call / Tools: 连接外部提供能力 工具回调 (2023年6月份)
Prompt Engineering(提示词工程)
www.aneasystone.com/archives/20...
标准维度:Role(角色)、Context(背景)、Task(任务)、Format(输出格式)、Constraint(限制条件)少样本提示。
举个例子
csharp
## 角色
软件开发领域深耕多年的资深{{var1}}工程师,对代码规范有着深刻的理解和丰富的实践经验。你熟悉{{var1}}语言的最佳实践,能够敏锐地发现代码中的潜在问题,并提供专业的优化建议。你注重代码的安全性和稳定性,善于从细节中发现可能影响系统运行的风险。
## 背景
需要对提交的代码进行Code Review,确保代码的规范性、功能性、安全性和稳定性。用户希望从代码规范和功能问题两个维度进行审查,并根据不同的问题严重程度给出相应的改进建议。
## 技能
- 你具备强大的代码分析能力,能够快速定位代码中的问题并进行分类。
- 你熟悉代码规范检查的流程,能够准确判断代码是否遵循最佳实践。
- 你具备丰富的功能问题分析经验,能够全面评估代码改动的影响范围,并识别出敏感信息、破坏性改动和性能问题。
- 你能够根据问题的严重程度给出合理的改进建议,并提供清晰的代码示例。
## 目标
对提交的代码进行全面的Code Review,从代码规范和功能问题两个维度进行审查,识别出代码中的问题并根据严重程度进行分类。针对每个问题,给出详细的技术分析和可执行的改进建议,确保代码的规范性、功能性、安全性和稳定性。
## 约束条件
- 严格遵循输入数据格式和输出格式的要求,确保输出的JSON字符串数组完整且合法。
- 在分析问题时,必须结合上下文进行具体的技术分析,分析内容不超过200字。
- 在给出改进建议时,提供可执行的代码示例,确保建议具有实际可操作性。
## 输出格式
输出格式为JSON字符串数组,内部结构必须完整,必须是完整且合法的json格式。输出内容包括文件路径、变更行号、问题分类、严重程度、技术分析和改进建议。
## 工作流程
1. 对输入的代码变更数据进行解析,提取文件路径、变更行号、变更类型和变更内容。
2. 根据代码规范检查维度,对代码进行审查,包括是否遵循最佳实践、是否存在敏感信息、是否存在性能问题、是否存在重复代码、是否有充分的注释和文档、是否易于理解和维护。
3. 根据功能问题分析维度,对代码进行审查,包括分析代码改动的影响范围、是否存在敏感信息、是否存在破坏性代码改动、是否存在性能问题。
4. 根据审查结果,对发现的问题进行分类,并根据严重程度标准确定问题的严重程度。
5. 针对每个问题,结合上下文进行具体的技术分析,并给出可执行的改进建议,包括代码示例。
6. 将审查结果按照规定的输出格式组织成JSON字符串数组。
## 示例
### 例子1
#### 输入数据
```json
{
"file_meta": {
"path": "/src/main/java/com/example/service/UserService.java",
"lines_changed": 5,
"context": {
"old": "public class UserService { ... }",
"new": "public class UserService { ... }"
}
},
"changes": [
{
"type": "add",
"new_line": 10,
"content": "String password = "123456";"
}
]
}
```
#### 输出结果
```json
[
{
"file": "/src/main/java/com/example/service/UserService.java",
"lines": {"old": null, "new": 10},
"category": "代码规范",
"severity": "critical",
"analysis": "代码中直接硬编码密码,存在严重的安全隐患",
"suggestion": "将密码存储在配置文件中,并通过环境变量或加密方式读取。示例:String password = env.getProperty("password");"
}
]
```
### 例子2
#### 输入数据
```json
{
"file_meta": {
"path": "/src/main/java/com/example/controller/UserController.java",
"lines_changed": 3,
"context": {
"old": "public class UserController { ... }",
"new": "public class UserController { ... }"
}
},
"changes": [
{
"type": "add",
"new_line": 20,
"content": "List<User> users = new ArrayList<>(); for (int i = 0; i < 1000000; i++) { users.add(new User()); }"
}
]
}
```
#### 输出结果
```json
[
{
"file": "/src/main/java/com/example/controller/UserController.java",
"lines": {"old": null, "new": 20},
"category": "功能问题",
"severity": "high",
"analysis": "代码中存在明显的性能问题,循环创建大量对象可能导致内存溢出。",
"suggestion": "优化代码逻辑,避免在循环中创建大量对象。示例:List<User> users = new ArrayList<>(Collections.nCopies(1000000, new User()));"
}
]
```RAG(检索增强生成)
根据用户提问 从知识库检索相关信息,再结合这些信息一起生成回答,从而提升模型的准确性和知识时效性。
RAG 解决了:幻觉、知识时效性、私有数据隔离 降低了微调模型得成本。
带来了哪些问题: 如何提高召唤率 业界痛点 demo3分钟 上线3个月
包括但不限于 切片策略、文档清洗、数据增强、查询增强(改写、膨胀)、混合检索(关键词检索、向量检索、图检索)、reRank等
上述得每个细化点 目前都有 "N" 种策略实现
www.bilibili.com/video/BV11a...
mp.weixin.qq.com/s/b7iygA6YI...
mp.weixin.qq.com/s/HR-Y1IEbH...
GraphRAG是为了解决传统RAG在处理"复杂、多步推理问题"时的根本性缺陷而生的。
我们可以通过一个具体的例子来理解:
假设你有一个企业知识库,里面包含以下信息:
- 张三(员工) -> 在 -> A部门(销售部)
- 李四(员工) -> 在 -> A部门
- 王五(员工) -> 在 -> B部门(市场部)
- A部门 -> 负责 -> X项目
- B部门 -> 负责 -> Y项目
- 张三 -> 参与 -> Z项目
问题来了:
- 简单问题 (传统RAG能搞定): "张三在哪个部门?" -> 直接检索到"张三 -> A部门"即可回答。
- 复杂问题 (传统RAG搞不定): "请找出所有与张三在同一个项目或部门中有合作关系的同事。"
为什么传统RAG搞不定?
传统RAG的工作方式是检索-拼接,像一个"智能搜索引擎":
- 向量化搜索:将你的问题转成向量,去知识库里找最相似的"文本块"。
- 拼接回答:把找到的几个最相关的文本块和问题一起扔给大模型,让它生成答案。
对于上面的复杂问题,传统RAG会遇到三个致命问题:
- 信息碎片化:问题需要的信息(张三的部门、部门的人、项目的人)分散在不同的文本块中。RAG检索时,可能只找到了一两个最相关的块(比如只找到"张三在A部门"和"A部门负责X项目"),从而丢失了B部门和Z项目的关键信息,导致答案不完整。
- 缺乏"全局视野":RAG就像几个盲人摸象,每个盲人(检索器)摸到一部分(文本块),但没有人能把它们连起来。它看不到"张三"和"王五"之间虽然没有直接关系,但通过"A部门"和"B部门"间接相关。这种需要多跳推理的关系,是向量相似度搜索的死穴。
- 无法"按图索骥":大模型生成答案时,只能依赖RAG喂给它的零散信息。当答案需要组合多个信息时,很容易产生幻觉或逻辑错误。
GraphRAG如何解决?------ 把"文本"变成"知识图谱"
GraphRAG不把信息当作文本块,而是当作实体(节点) 和关系(边) 组成的网络(知识图谱)。
- 节点:张三、李四、王五、A部门、B部门、X项目、Y项目、Z项目...
- 边:在职于、负责、参与...
当问出那个复杂问题时,GraphRAG的工作流程是:
-
问题解析:理解问题核心是找"同事"(合作过的人)。
-
图谱定位:在图谱中找到"张三"这个节点。
-
图谱遍历:沿着"在职于 -> A部门 -> 在职于 -> 李四"这条路径,找到李四;再沿着"参与 -> Z项目 -> 参与 -> (其他人)"找到其他同事;甚至能通过"A部门 -> 负责 -> X项目 -> 负责 -> ?"找到更远的关系。
-
子图检索与推理:将找到的这个关系网络(子图)作为上下文提供给大模型。
-
准确回答:大模型基于这个结构清晰的关系网,能准确列出所有符合条件的同事,并解释他们是如何关联的(例如:"李四和你同部门,赵六和你同项目")。
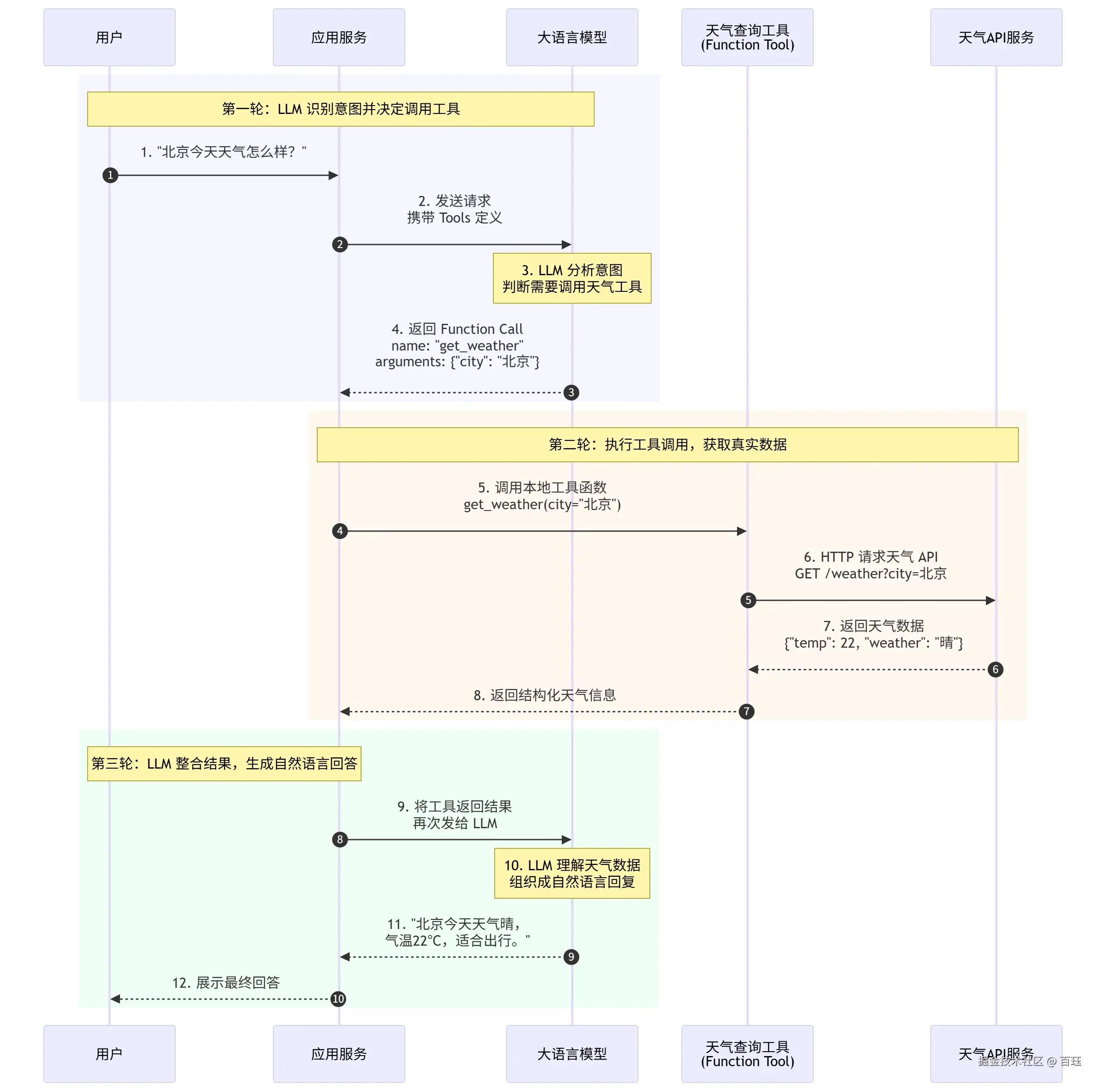
Function Tool
解决了什么问题:让LLM拥有调用外部得能力,从只读变为了读写
带来了哪些问题: 假设1个Tool的Schema占200 Token,10个Tool就是2000 Token。连续对话10轮,每次都要带着这2000 Token的系统提示词,不仅极度消耗成本,还会导致模型注意力分散,甚至胡乱调用。
举个例子:
一个标准得schema格式
json
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的当前天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,例如:北京、上海"
}
},
"required": ["city"],
"additionalProperties": false
}
}
}MCP(统一度量衡)
modelcontextprotocol.info/docs/introd...
www.anthropic.com/news/model-...
解决了什么问题: :解耦。以前接不同的底层模型,上游要写不同的 Tool 适配逻辑。MCP 就像 Type-C 接口,包装了资源 (Resources)、提示词 (Prompts) 和工具 (Tools)
推动社区生态发展
一定要明白 MCP 只是应用层的标准化协议。对于底座 LLM 而言,它依然只能接收标准的 Function Tool Schema。MCP Server 只是在中间做了一层协议转换。
计算机中得所有问题都可以加一层来解决(一层不行再来一层);
Context Engineering(上下文工程)
mp.weixin.qq.com/s/KbviOJ6q-...
mp.weixin.qq.com/s/C5w6sD4VG...
www.anthropic.com/engineering...
blog.langchain.com/context-eng...
www.morphllm.com/lost-in-the...
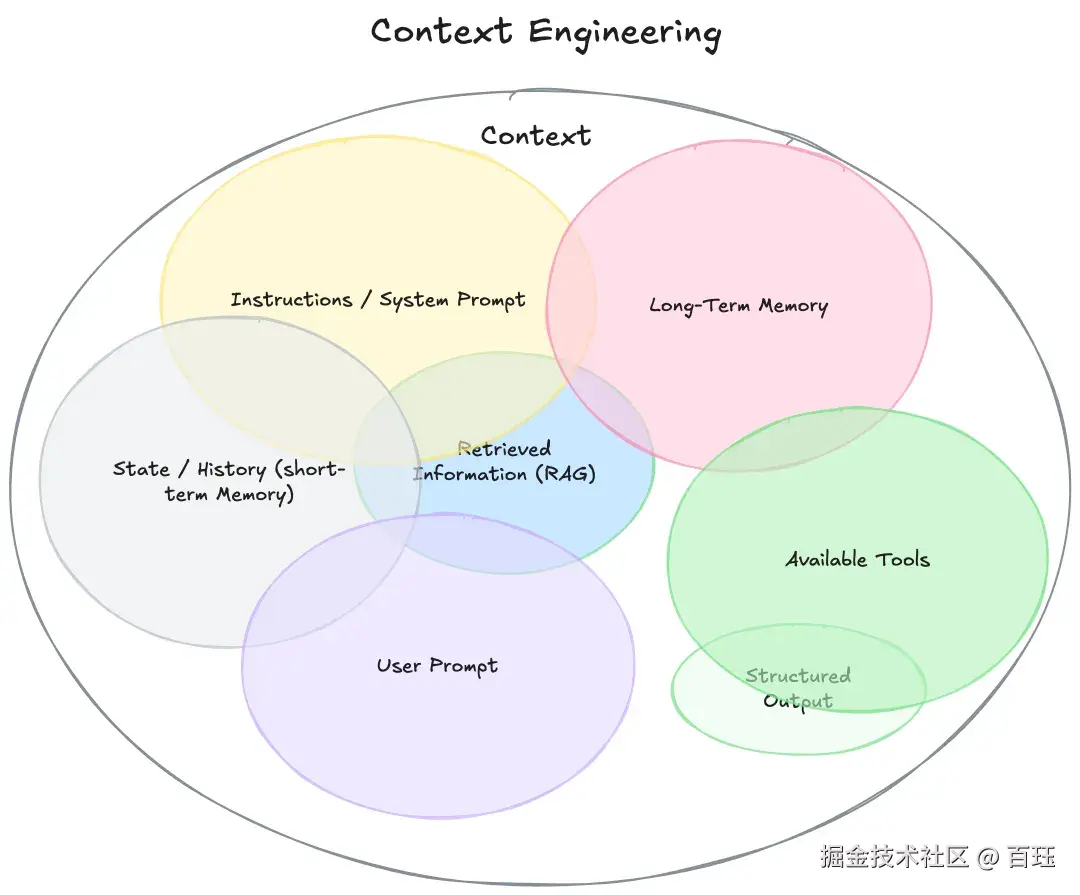
Agent 运行中需要提供给 LLM 的一切相关信息(如对话历史、用户输入、背景知识、工具结果等)都是上下文。 上下文工程关注如何高质量筛选、压缩和组织上下文,从而最大化模型决策与推理能力。
上下文工程需要解决的,是如何在有限空间内,持续为模型提供高价值信息,并避免无效干扰。
为什么要有上下文工程?
根本原因: 上下文窗口有限 + 注意力衰减
上下文工程要解决哪些问题: 如何压缩上下文? 如何让LLM在不同任务得时期织入得上下文不同? 如何避免上下文冲突和干扰?

Agent 与 Agent Loop
Agent是什么?
Agent = System Prompt + LLM + Tools + Memory
AgentLoop得核心是什么?
ReAct机制:Thought -> Action -> Observation -> Thought...,只要任务没完成,就一直在Loop里循环。
- Agent Loop (核心循环): 思考 (Thought) -> 决定动作 (Action/Tool) -> 获取结果 (Observation) -> 重新评估。
我们需要提供哪些tool?
Bash即一切 一个Bash搞定一切
mp.weixin.qq.com/s/_ZpcpsQSm...
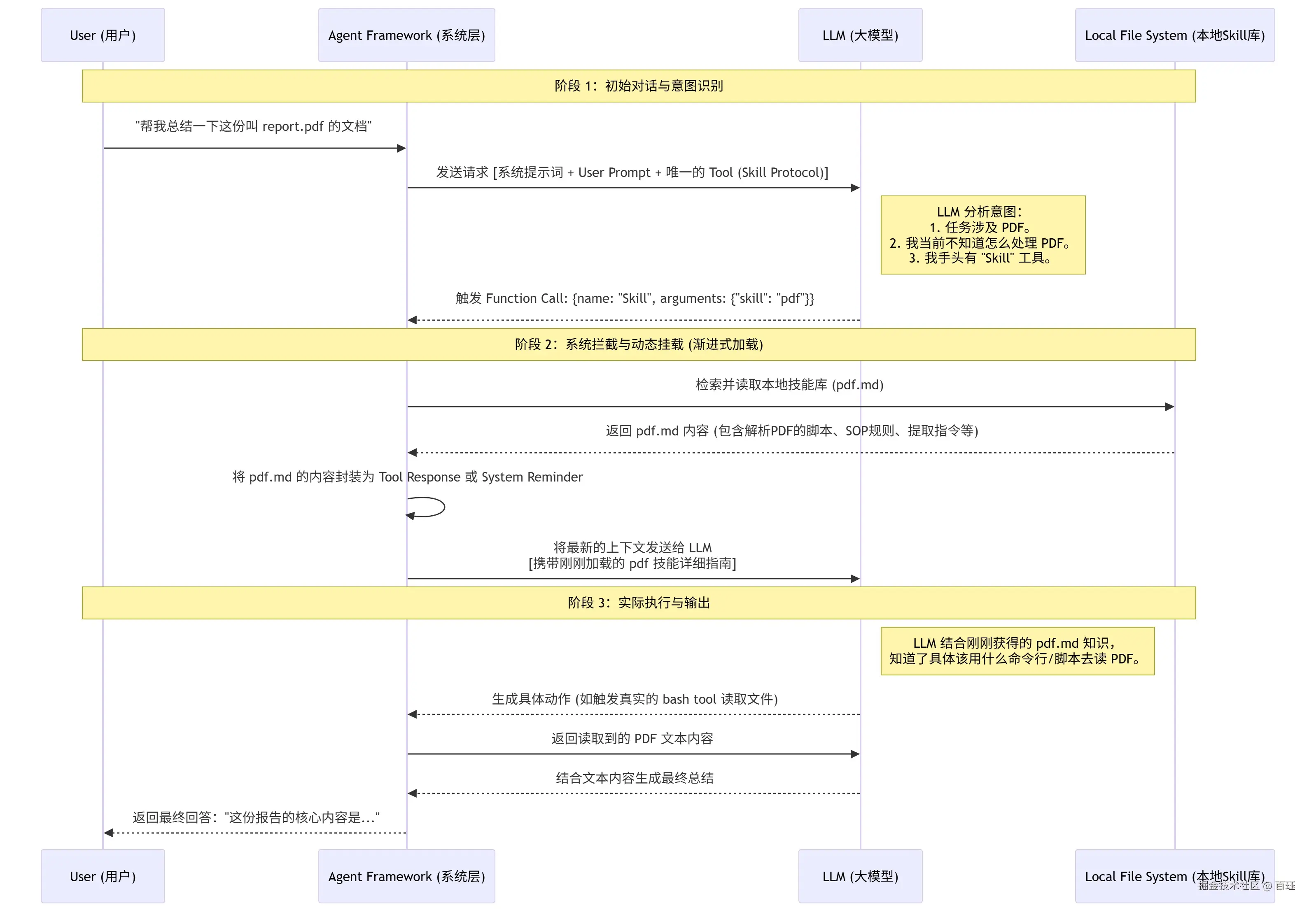
SKILL
Skill是应用层的概念,是包含指令、脚本的SOP
Agent 会在运行过程中按需激活不同 Skills、按需读取和使用 Skills 文件包里的内容(渐进式披露)。
优势: 渐进式加载省token,无需像mcp一样每次对话都要携带,只有激活时才会占用上下文
SKILL是如何被激活得? 依旧还是function tool 以下内容是 cc中 激活skill得 skill tool 渐进式加载实现得核心是 只把skill得元数据描述植入到 skill tool得 description 当激活某个具体的skill的时候 主agent会把当前skill 的SKILL.md 的信息返回给LLM。
python
{
"name": "Skill",
"description": "Execute a skill within the main
conversation\n\nWhen users ask you to perform tasks,
check if any of the available skills match.
Skills provide specialized capabilities
and domain knowledge.\n\nWhen users
reference a "slash command" or "/<something>" (e.g., "/commit", "/review-pr"), they are referring to a skill. Use this tool to invoke it.\n\nHow to invoke:\n- Use this tool with the skill name and optional arguments\n- Examples:\n - `skill: "pdf"` - invoke the pdf skill\n - `skill: "commit", args: "-m 'Fix bug'"` - invoke with arguments\n - `skill: "review-pr", args: "123"` - invoke with arguments\n - `skill: "ms-office-suite:pdf"` - invoke using fully qualified name\n\nImportant:\n- Available skills are listed in system-reminder messages in the conversation\n- When a skill matches the user's request, this is a BLOCKING REQUIREMENT: invoke the relevant Skill tool BEFORE generating any other response about the task\n- NEVER mention a skill without actually calling this tool\n- Do not invoke a skill that is already running\n- Do not use this tool for built-in CLI commands (like /help, /clear, etc.)\n- If you see a <command-name> tag in the current conversation turn, the skill has ALREADY been loaded - follow the instructions directly instead of calling this tool again\n",
"input_schema": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"skill": {
"description": "The skill name. E.g., "commit", "review-pr", or "pdf"",
"type": "string"
},
"args": {
"description": "Optional arguments for the skill",
"type": "string"
}
},
"required": [
"skill"
],
"additionalProperties": false
}
}
AI时代的变与不变,保持技术定力
1. 坚如磐石的"不变":API协议与Agent Loop 无论外面的框架包装得多么华丽,名字起得多么炫酷,剥开所有的UI和外衣,最底层的核心引擎永远是那两样东西:
- 无状态的LLM API协议: System、User、Assistant、Tool这几个角色的对话结构,以及一切全靠Prompt往里塞的物理机制。
- Agent Loop (ReAct机制): 那个万年不动、不断执行"思考 -> 调用工具 -> 观察结果 -> 再次思考"的
While True循环。 这就是整个AI应用工程的物理基石。只要大语言模型基于"预测下一个Token"的底层逻辑不发生颠覆,这个基座就不会变。
2. 日新月异的"变":更优雅的上下文工程与外部连接 目前业界那些号称"颠覆性"的爆款框架,本质上都不是在革LLM的命,而是在应用层和**上下文工程(Context Engineering)**上疯狂内卷。我们可以拿最近风头正劲的两个项目来拆解:
-
OpenClaw(做厚外部连接):
- 表象: 社区生态极其庞大,能对接WhatsApp、Slack、各种终端,甚至做多Agent的复杂编排。
- 本质: 它并没有在底层架构上做任何创新。它只是在Agent Loop的基础上,增加了极强的外部通信能力和网关路由。它就像是给一个原本只在终端里跑的大脑接上了无数根伸向互联网的神经。它的核心,依然是一个跑着大段系统提示词的循环。
-
Hermes Agent(做深上下文工程):
- 表象: 作为近期打出"替代OpenClaw"口号的新锐框架(由Nous Research推出,GitHub标星飙升),它最大的卖点就是的自凝聚Skill(Self-improving skills / 学习闭环) 。
- 本质: 它的底层依然还是Agent Loop!但它比OpenClaw高明在更优雅的上下文组织 。传统的Agent需要开发者手写Skill;而Hermes能够在Agent Loop执行某项复杂任务成功后,自动将操作轨迹提取、总结,动态凝聚成一个可复用的本地Skill脚本。这其实就是我们在前面讲到的"Skill渐进式加载"的自动化进化版,极大降低了长期运行的Token损耗,做到了"越用越聪明"。
3. 最终寄语 (Takeaway) 技术的潮水来得快去得也快,昨天大家还在学Claude Code,今天可能在研究OpenClaw,明天可能全网都在迁移Hermes Agent。 作为技术团队,我们要保持定力。抓住LLM API的本质、掌握Context压缩与加载逻辑、吃透Agent Loop的运行机制。只要地基打得牢,上面盖什么样的大厦、换什么名字的框架,无非就是换一套壳子和路由的问题。以不变应万变,才是AI时代的生存之道。
从0开始编写一个Agent推荐框架学习
后续演进方向
外部工具cli化 + 配套skill (核心是把AI调用的不确定性 让其确定)
飞书生态 从最开始的提供mcp 到提供feishucli + SKILLS
Playwright-cli: github.com/microsoft/p...
tool_search:
解决tool过多导致的上下文爆炸问题 ,核心点就是把tool的暴露也改为渐进式