一、搬到K8s之后,监控为什么突然"瞎了"
去年帮一个客户把核心业务从3台CentOS虚拟机迁到了K8s集群。迁之前,我们用冠服云EMS平台管着他们的全部基础设施监控------每台机器通过Agent接入,CPU、内存、磁盘、进程数全都有,告警配好了一年多,运行稳定。
迁完之后第一周就出事了。
周三下午用户报告系统间歇性502。运维一看Grafana的Node监控面板------3个Worker Node的CPU都在40%左右,内存60%,网络带宽不到30%。"服务器没问题啊?"
排查了20分钟才发现:业务Pod的一个副本因为内存泄漏触发了OOMKilled,Kubernetes自动重启了它。重启的那十几秒里,Service的流量轮到这个Pod就502了。等Pod起来又正常。然后过一会又OOM、又重启、又502------循环往复。
Node层的监控完全看不到这个问题。因为从Node视角看,总内存使用60%(其他Pod在正常跑),根本没触发告警阈值。
这就是容器环境监控的核心痛点:粒度变了,但监控体系没跟着变。
传统监控的对象是"机器",一台机器上跑一个或几个固定服务。容器环境的对象是"Pod"------数量动态变化、可能在任意Node上调度、随时可能被杀掉重建。拿监控机器的思路去监控容器,必然有盲区。
二、三层监控模型:Node / Pod / Service各看什么
搞容器监控最大的误区是"我装了Prometheus就行了"。Prometheus只是采集引擎,关键是你让它采什么指标、怎么分层告警。
我们在冠服云EMS上给客户落地容器监控的过程中总结出一个三层模型:
Node层------基础设施是否健康
这一层和传统监控类似,目的是确认"底座没问题"。
| 指标 | 采集方式 | 告警阈值建议 |
|---|---|---|
| CPU使用率 | node_exporter | >85%持续5分钟 |
| 内存使用率 | node_exporter | >90%持续3分钟 |
| 磁盘使用率 | node_exporter | >85% |
| 磁盘IO等待 | node_exporter | iowait>30%持续5分钟 |
| 网络丢包率 | node_exporter | >1%持续3分钟 |
| 文件描述符使用率 | node_exporter | >80% |
| Node状态 | kube-state-metrics | NotReady持续1分钟 |
重点:Node层告警触发了,说明底层基础设施出问题,影响面是这台Node上所有Pod。优先级最高。
Pod层------容器运行状态是否正常
这一层是容器环境独有的,传统监控体系里没有对应物。
| 指标 | 采集方式 | 告警阈值建议 |
|---|---|---|
| Pod重启次数 | kube-state-metrics | 30分钟内重启≥2次 |
| OOMKilled事件 | kube-state-metrics | 任何1次 |
| Pod处于Pending状态 | kube-state-metrics | Pending>5分钟 |
| 容器CPU使用率/Limit | cAdvisor | >90% Limit持续3分钟 |
| 容器内存使用率/Limit | cAdvisor | >85% Limit |
| 就绪探针失败 | kube-state-metrics | 连续失败3次 |
| Pod副本数不足 | kube-state-metrics | 实际副本<期望副本>5分钟 |
这一层最容易被忽略。很多团队装了Prometheus但没配kube-state-metrics,结果Pod在反复重启都不知道。
Service层------业务对外是否可用
用户不关心你的Pod和Node,只关心"系统能不能用、快不快"。
| 指标 | 采集方式 | 告警阈值建议 |
|---|---|---|
| HTTP 5xx比例 | 应用埋点/Ingress日志 | >1%持续2分钟 |
| 响应延迟P99 | 应用埋点/Blackbox | >2s持续3分钟 |
| QPS突降 | 应用埋点/Ingress | 较前1小时均值降>50% |
| 健康检查失败 | Blackbox Exporter | 连续2次探测失败 |
| 上游依赖超时 | 应用埋点 | 依赖调用超时率>5% |
Service层的告警应该最先通知到值班人员------因为它直接代表用户体验。
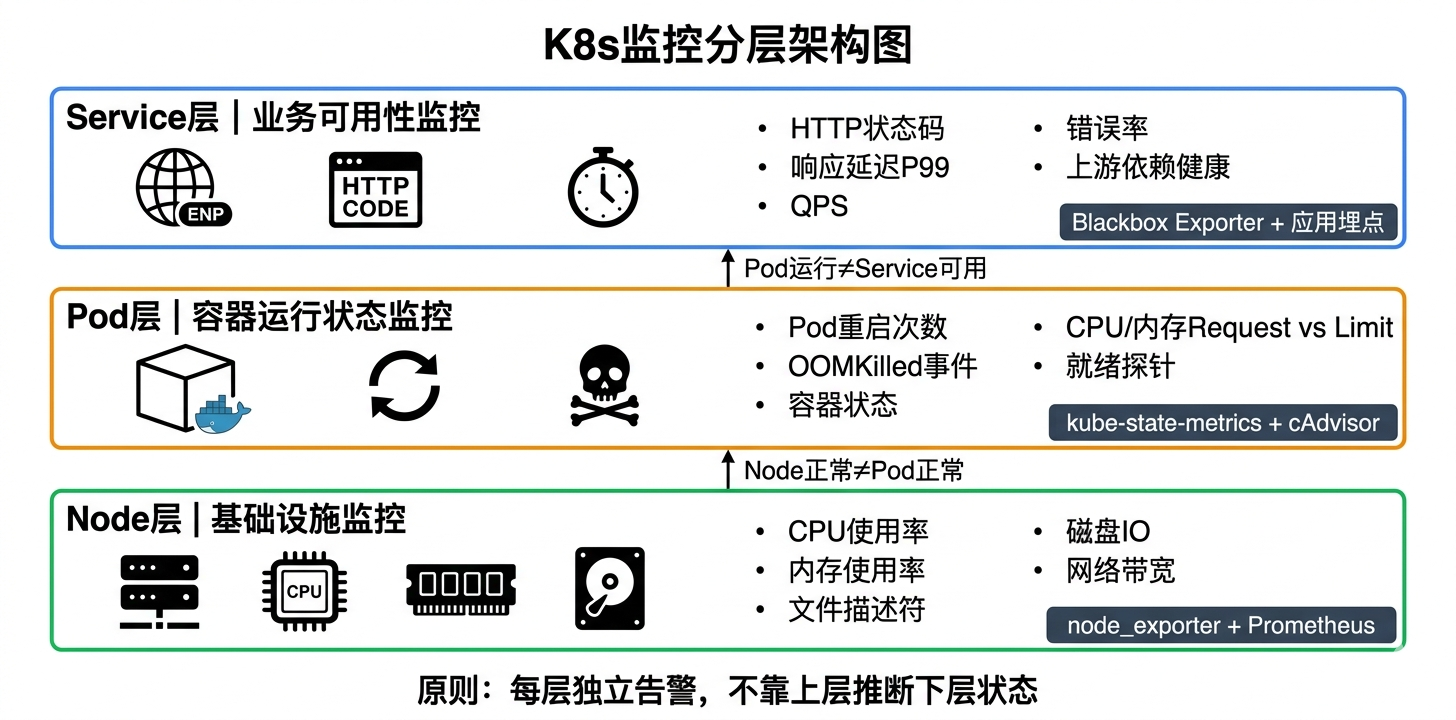
三、每层都要独立告警,不要用"推断"
一个常见错误做法:Node的CPU高了→推断Pod有问题→推断Service要出故障。
实际情况是:
- Node CPU 40%,但某个Pod的CPU已经打满了它的Limit,被throttle了(Service变慢)
- Pod全都Running,但就绪探针其实已经失败(Service流量还在打过去)
- Service响应正常,但Pod的重启次数在涨(下一次重启可能导致短暂不可用)
三层必须独立告警,不能只看一层就觉得"没事"。我们在冠服云EMS里做的设计就是三层各有独立告警视图,同时有一个汇聚面板可以一屏看全------哪一层亮红灯就往哪一层钻。
四、Prometheus告警规则YAML(直接用)
Node层告警
yaml
groups:
- name: node-alerts
rules:
- alert: NodeHighCPU
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 5m
labels:
severity: warning
annotations:
summary: "Node {{ $labels.instance }} CPU使用率超过85%"
description: "当前值: {{ $value | printf \"%.1f\" }}%"
- alert: NodeHighMemory
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 90
for: 3m
labels:
severity: critical
annotations:
summary: "Node {{ $labels.instance }} 内存使用率超过90%"
- alert: NodeDiskAlmostFull
expr: (1 - node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs"} / node_filesystem_size_bytes) * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "Node {{ $labels.instance }} 磁盘 {{ $labels.mountpoint }} 使用率超过85%"
- alert: NodeNotReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Node {{ $labels.node }} 状态NotReady"Pod层告警
yaml
groups:
- name: pod-alerts
rules:
- alert: PodCrashLooping
expr: increase(kube_pod_container_status_restarts_total[30m]) >= 2
for: 0m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 30分钟内重启{{ $value }}次"
- alert: PodOOMKilled
expr: kube_pod_container_status_last_terminated_reason{reason="OOMKilled"} == 1
for: 0m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 容器 {{ $labels.container }} OOMKilled"
- alert: PodPendingTooLong
expr: kube_pod_status_phase{phase="Pending"} == 1
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} Pending超过5分钟"
- alert: PodCPUThrottled
expr: rate(container_cpu_cfs_throttled_seconds_total[5m]) > 0.5
for: 3m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} CPU被限流"
- alert: PodMemoryNearLimit
expr: container_memory_usage_bytes / container_spec_memory_limit_bytes * 100 > 85
for: 3m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 内存使用率接近Limit"
- alert: DeploymentReplicasMismatch
expr: kube_deployment_spec_replicas != kube_deployment_status_available_replicas
for: 5m
labels:
severity: warning
annotations:
summary: "Deployment {{ $labels.namespace }}/{{ $labels.deployment }} 可用副本数不足"Service层告警
yaml
groups:
- name: service-alerts
rules:
- alert: HighErrorRate
expr: sum(rate(http_requests_total{code=~"5.."}[2m])) by (service) / sum(rate(http_requests_total[2m])) by (service) * 100 > 1
for: 2m
labels:
severity: critical
annotations:
summary: "Service {{ $labels.service }} 5xx错误率超过1%"
- alert: HighLatencyP99
expr: histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le, service)) > 2
for: 3m
labels:
severity: warning
annotations:
summary: "Service {{ $labels.service }} P99延迟超过2秒"
- alert: QPSDrop
expr: sum(rate(http_requests_total[5m])) by (service) < sum(rate(http_requests_total[5m] offset 1h)) by (service) * 0.5
for: 5m
labels:
severity: warning
annotations:
summary: "Service {{ $labels.service }} QPS较1小时前下降超50%"
- alert: BlackboxProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: critical
annotations:
summary: "探测 {{ $labels.instance }} 连续失败"
五、最容易踩的4个坑
坑1:只装了Prometheus没装kube-state-metrics
Prometheus本身只通过cAdvisor能拿到容器的CPU/内存使用数据。但Pod的状态(重启次数、是否Pending、OOMKilled原因)这些信息来自Kubernetes API,必须通过kube-state-metrics暴露成Prometheus格式。
很多人装完Prometheus觉得"有监控了",实际上Pod层的关键指标一个都没采集。我们在冠服云EMS里把kube-state-metrics作为容器场景的默认数据源之一,客户接入K8s集群时平台会自动检查这块有没有部署,避免这个盲区。
部署kube-state-metrics:
bash
# Helm安装
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install kube-state-metrics prometheus-community/kube-state-metrics -n monitoring
# 验证是否正常采集
kubectl port-forward svc/kube-state-metrics 8080:8080 -n monitoring
curl http://localhost:8080/metrics | grep kube_pod_container_status_restarts_total坑2:容器CPU告警配成Node粒度
错误写法:
yaml
# 这只能看到Node级别的CPU,看不到单个Pod被throttle
expr: node_cpu_seconds_total...正确写法------看容器级别的CPU throttle:
yaml
# 这才是Pod层面的CPU瓶颈指标
expr: rate(container_cpu_cfs_throttled_seconds_total[5m]) > 0.5关键理解:在K8s里,CPU Limit是通过CFS(完全公平调度器)实现的。Pod的CPU使用到Limit后不是被kill,而是被throttle(限速)。表现就是"进程还在跑但变慢了"------Node层完全看不出来。
坑3:Liveness和Readiness探针配错了
很多团队的Liveness探针和Readiness探针指向同一个endpoint。结果:
- 如果业务依赖的数据库挂了,健康检查返回500
- Kubernetes认为Pod不健康,先摘流量(Readiness失败)
- 然后杀Pod重启(Liveness失败)
- 重启后数据库还是挂的,又失败,又重启------无限循环
正确做法:
- Liveness探针:只检查"进程是否卡死"(如/healthz返回200就行)
- Readiness探针:检查"是否能正常处理请求"(包括下游依赖)
yaml
livenessProbe:
httpGet:
path: /healthz # 只验证进程存活
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready # 验证完整可用性(含依赖)
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3坑4:没设Resource Request/Limit导致监控失真
如果Pod没设memory limit,container_memory_usage_bytes / container_spec_memory_limit_bytes这个比值就没意义(limit=0时除法会出问题或告警永远不触发)。
而且没设Request的Pod在Node资源紧张时会被优先驱逐,但你的监控可能还以为"Pod内存才用了20%"(因为分母是Node总内存而不是Pod的Limit)。
基线建议:
yaml
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"先按实际压测数据的2-3倍设Limit,跑1-2周后根据监控数据逐步收紧。
六、一份容器环境监控自检清单
用这个清单检查你的K8s监控是否有盲区:
Node层
- node_exporter已部署到每个Node(DaemonSet方式)
- CPU/内存/磁盘/网络基础告警已配置
- Node NotReady告警已配置(1分钟触发)
- 磁盘IO告警已配置(iowait阈值)
Pod层
- kube-state-metrics已部署并正常采集
- Pod重启告警已配置(30分钟内≥2次)
- OOMKilled告警已配置(0延迟)
- Pod Pending告警已配置(5分钟)
- CPU throttle告警已配置
- 内存接近Limit告警已配置(85%)
- Deployment副本数不匹配告警已配置
- 所有业务Pod都设置了Resource Request/Limit
- Liveness和Readiness探针分开配置
Service层
- HTTP 5xx错误率告警已配置
- P99延迟告警已配置
- QPS突降告警已配置
- 关键URL的Blackbox探测已配置
- 上游依赖超时告警已配置
基础设施
- Prometheus存储容量足够(至少保留15天数据)
- Grafana Dashboard已按三层分面板展示
- AlertManager已对接企业微信/钉钉
- 告警静默规则已配置(避免维护窗口误告警)
七、一个完整的Grafana Dashboard JSON变量配置参考
不贴完整JSON了(太长),但给一下关键的变量和面板设计思路。实际上我们在冠服云EMS里给客户预置了一套容器监控Dashboard模板------接入K8s集群后自动生成三层面板,不需要手动拼JSON。下面说一下这套模板背后的设计逻辑,用纯开源Grafana自建也可以参考:
Dashboard布局(4行):
├── Row 1: Node Overview(CPU/内存/磁盘/网络,按Node分组)
├── Row 2: Pod Status(重启次数Top10 + OOM事件 + Pending列表)
├── Row 3: Container Resources(CPU/内存 vs Limit对比图,按Namespace分组)
└── Row 4: Service Health(5xx率 + P99延迟 + QPS趋势)
关键Grafana变量:
- $namespace: label_values(kube_pod_info, namespace)
- $deployment: label_values(kube_deployment_labels{namespace="$namespace"}, deployment)
- $node: label_values(kube_node_info, node)每个Row里的关键Panel PromQL:
promql
# Pod重启次数Top10
topk(10, sum by(namespace, pod) (increase(kube_pod_container_status_restarts_total[1h])))
# 容器内存使用 vs Limit(百分比)
container_memory_usage_bytes{container!=""} / container_spec_memory_limit_bytes{container!=""} * 100
# Service 5xx错误率
sum(rate(http_requests_total{code=~"5.."}[5m])) by (service) / sum(rate(http_requests_total[5m])) by (service) * 100
# CPU Throttle时间(秒/秒)
rate(container_cpu_cfs_throttled_seconds_total[5m])八、小结
容器环境的监控本质上是粒度的转变:从"监控机器"变成"监控工作负载"。Node层确认底座健康,Pod层确认容器运行正常,Service层确认用户体验合格------三层各自告警,互不替代。
最小改造路径:
- 先把kube-state-metrics装上(10分钟搞定,立刻填补Pod层盲区)
- 补上Pod重启、OOMKilled、Pending三个关键告警(覆盖80%的容器特有故障)
- 加Blackbox Exporter做Service层探测(补上"用户视角")
- 最后调整Grafana Dashboard按三层分区展示
不需要一步到位。先把这4步跑完,容器环境里最常见的"Node正常但业务出问题"的监控盲区就堵住了。如果不想自己一步步拼,我们冠服云EMS平台的容器监控模块基本是开箱即用的------接入集群后三层告警规则和Dashboard自动生成,相当于把上面这4步打包做完了。