「以 1/10 的成本,性能几乎追平 Claude Opus 4.7 这个级别的模型。」
它就是 Cursor 今天凌晨亮出的迄今为止最强大的模型 ------Composer 2.5。
官方表示,Composer 2.5 更加智能,更擅长处理耗时较长的持续任务,并且在遵循复杂指令方面也更为可靠。
未来一周内,Cursor 将会把该模型原本附赠 / 包含的使用额度翻倍。
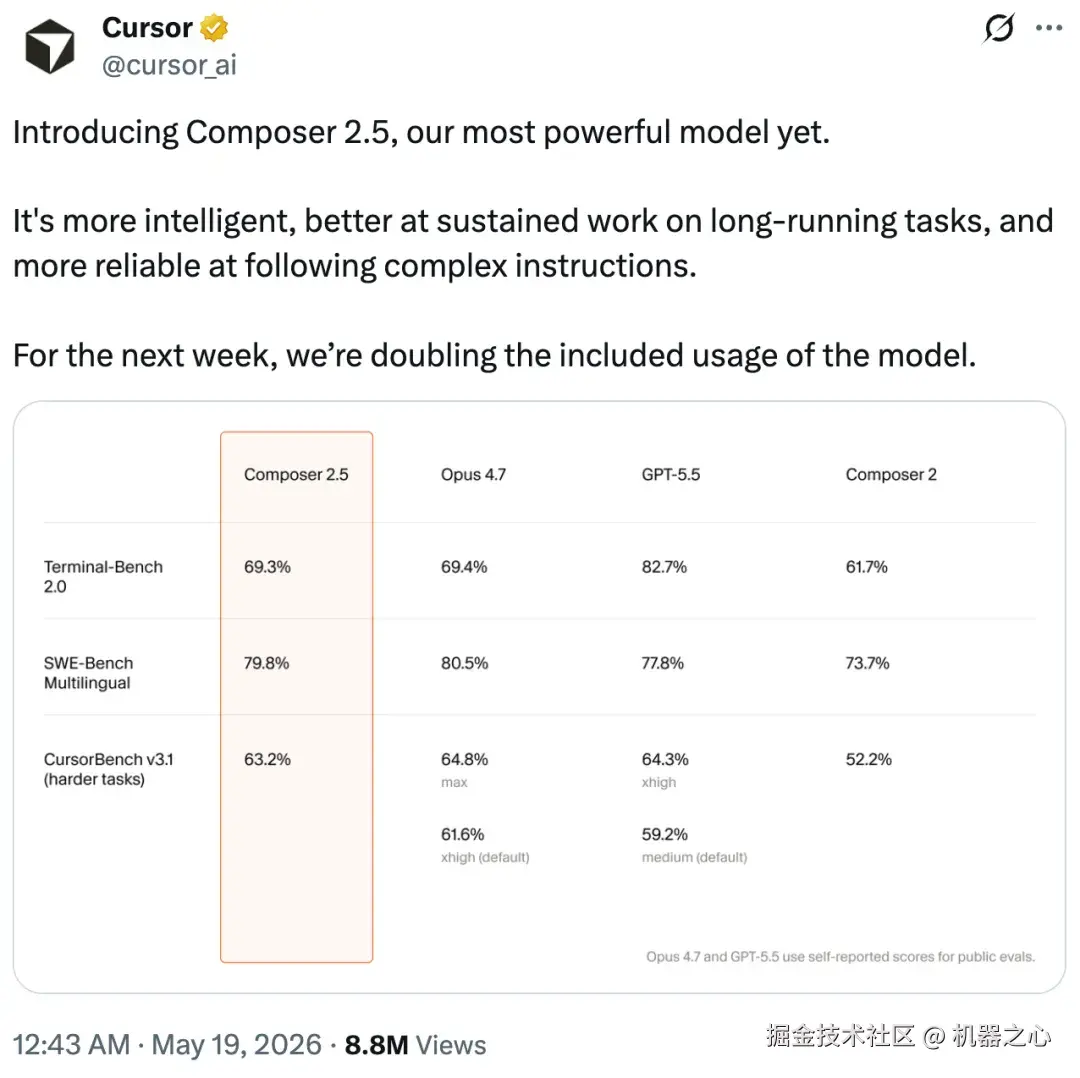
相比 Composer 2,Composer 2.5 在智能水平和行为表现上都有显著提升。
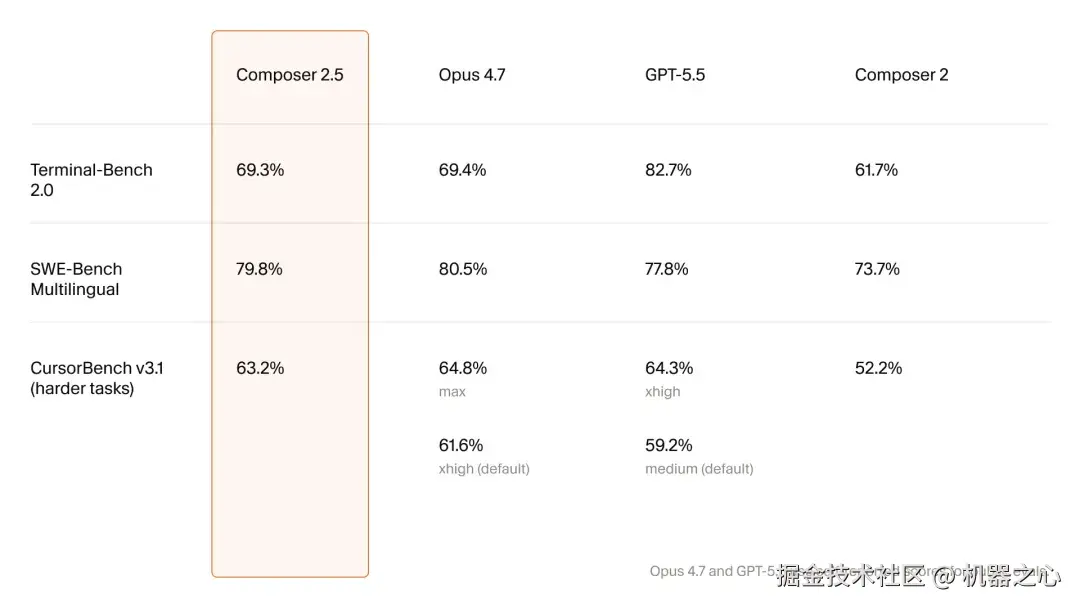
通过扩大训练规模、构建更复杂的强化学习环境,并引入新的学习方法,Cursor 全面改进了 Composer。
除了在更困难的任务上训练 Composer 2.5 外,Cursor 还优化了模型的沟通风格、努力程度校准等行为层面的表现。这些维度现有基准测试无法很好地衡量,但它们对实际使用体验至关重要。
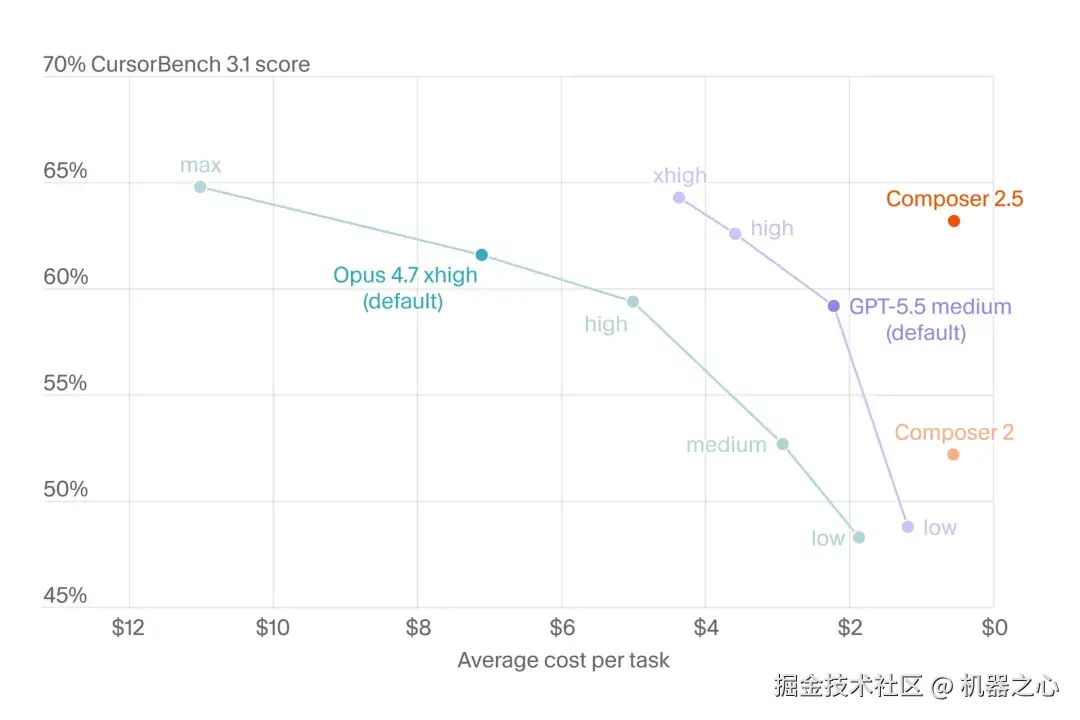
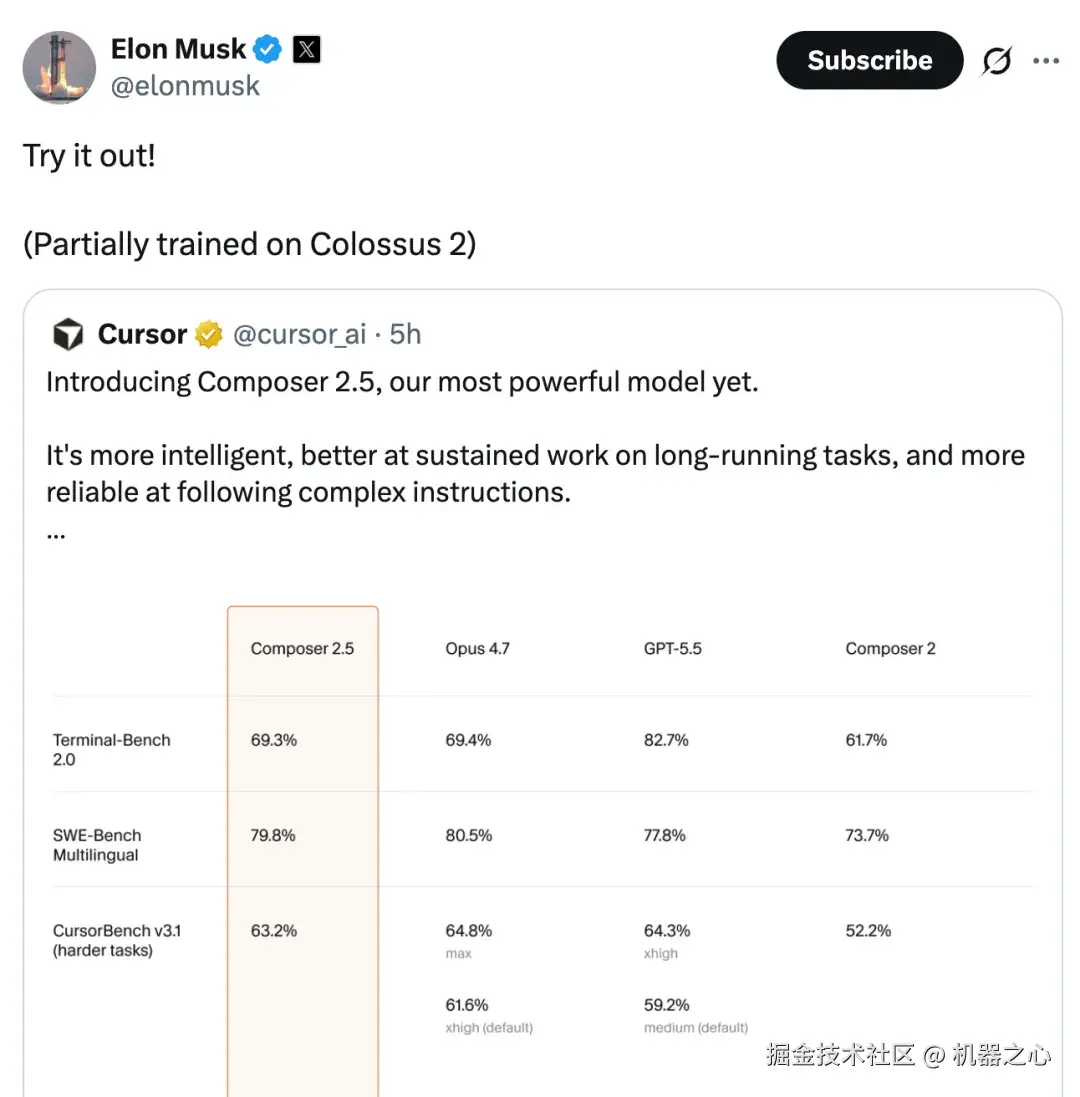
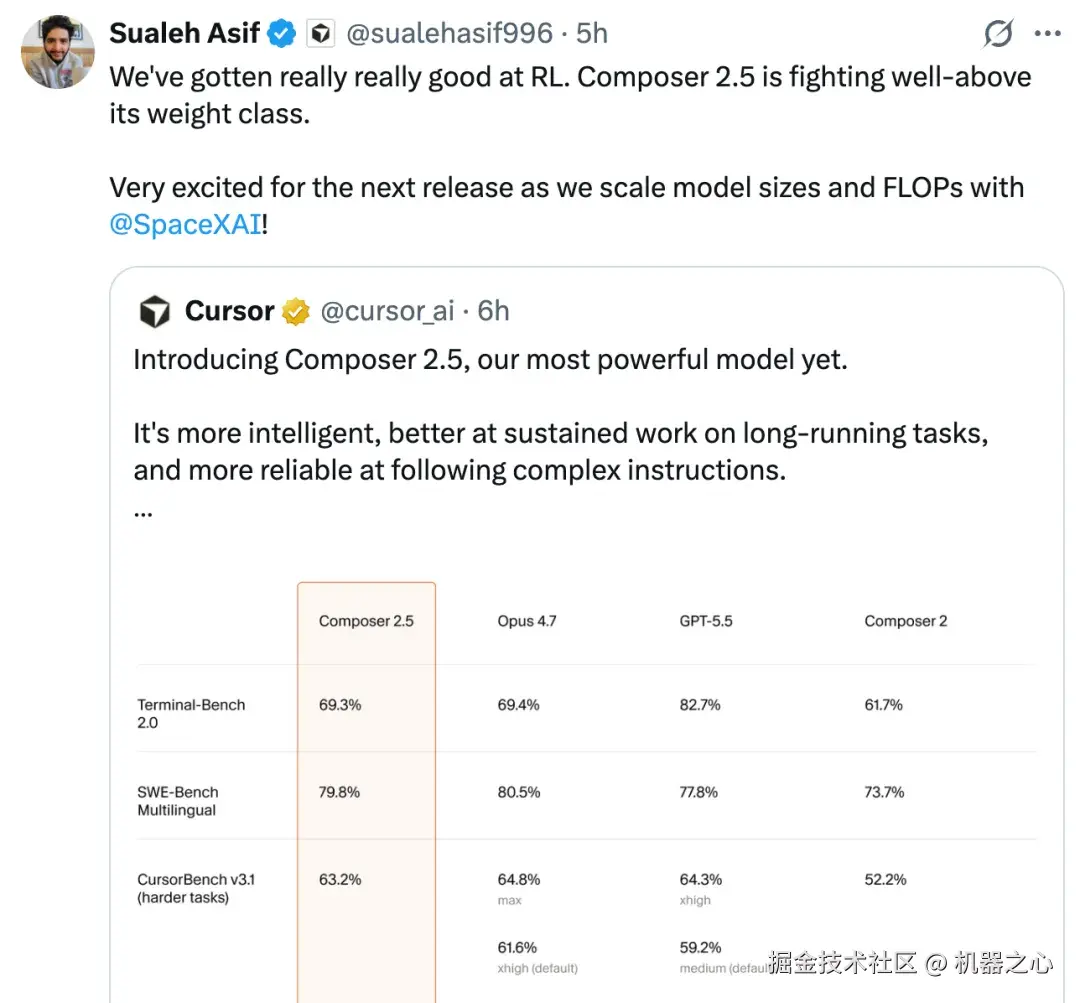
可以看到,Composer 2.5 在同等能力的模型中,它的成本效率最高可高出 10 倍。
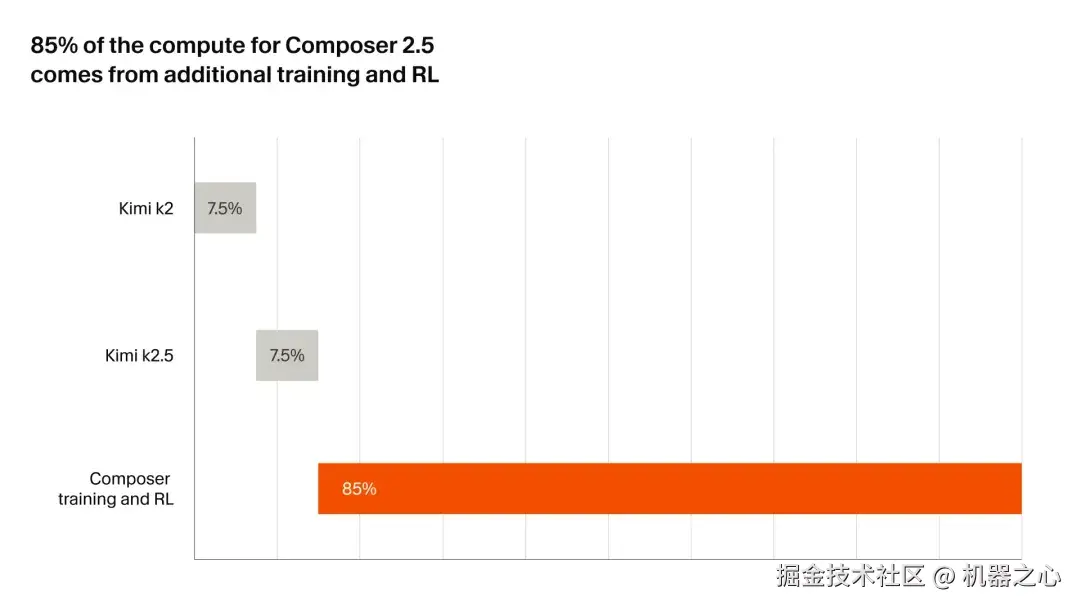
值得关注的是,Composer 2.5 基于与 Composer 2 相同的开源检查点构建,即月之暗面的 Kimi K2.5。
Cursor 还宣布了与 SpaceXAI 的合作:双方将从零开始训练一个规模大得多的模型,总算力投入是此前的 10 倍。借助 Colossus 2 的百万块 H100 等效算力,以及双方积累的数据和训练技术,预计这将是模型能力的一次重大飞跃。
马斯克发推呼吁大家伙使用 Composer 2.5,并表示该模型的训练有一部分是在 Colossus 2 上进行的。
Cursor 创始人称,「我们在强化学习方面已经做得极其出色了。Composer 2.5 完成了越级挑战,其表现远远超出了它这个参数规模应有的水平。对于下一个版本,我们无比兴奋。我们将与 SpaceXAI 一起,大幅扩展模型规模和算力投入。」
Composer 2.5 训练体系
Composer 2.5 的训练体系引入了多项新改进,这些改进同时针对模型智能和可用性。
一是,基于文本反馈的精准强化学习。
随着单次推理过程可能长达数十万 token,强化学习中的功劳分配正成为一个日益严峻的挑战。当奖励是基于整个推理过程计算时,模型很难分辨到底是哪一个具体决策帮助或损害了最终结果。当我们想要抑制某个局部行为,比如一次错误的工具调用、一处令人困惑的解释,或是一种风格违规,这种局限性尤其明显。最终奖励能告诉我们出了某种问题,但对于问题出在哪里,它只是一个充满噪声的信号。
为解决这一问题,Cursor 用精准文本反馈来训练 Composer 2.5。思路是:在模型推理轨迹中本可以表现更好的那个具体节点,直接给出反馈。针对目标模型消息,Cursor 构造一个简短的提示,描述期望的改进方向,将其插入局部上下文,并将得到的模型概率分布作为「教师」。同时,以原始上下文中的策略作为「学生」,加入一个同策略蒸馏 KL 损失,将学生的 token 概率向教师的概率拉近。这样一来,既能获得对目标行为的局部化训练信号,又保留了基于完整轨迹的整体强化学习目标。
以文本反馈过程为例:设想一个漫长的推理过程,其中包含一次工具调用错误:模型试图调用一个并不存在的工具。过程中,模型会收到「未找到工具」的错误提示,并继续做出其他有效的工具调用。在数百次工具调用中出现一次错误,对其最终奖励的影响微乎其微。
借助文本反馈,可以精准定位这一具体错误:在出错的那一轮上下文中插入一条提示,如「提醒:可用工具有......」并附上可用工具列表。这条提示改变了教师模型的概率分布,降低了错误工具的调用概率,提高了有效替代方案的概率。然后,仅针对那一轮,将学生权重向新的概率分布更新。
在 Composer 2.5 的训练过程中,Cursor 将这一方法应用于多种模型行为,从代码风格到模型沟通方式。

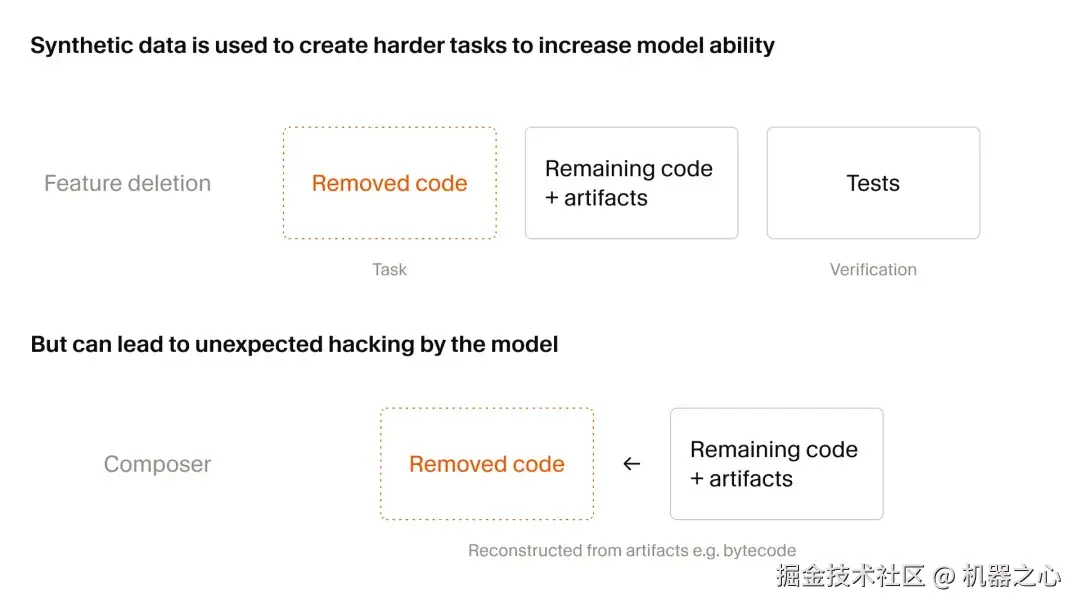
二是,合成数据。
在强化学习训练期间,Composer 的编程能力会显著提升,直到能正确完成大部分训练任务。为了持续提升智能水平,Cursor 在整个训练过程中动态筛选并创建更困难的任务。Composer 2.5 使用的合成任务数量是 Composer 2 的 25 倍。
Cursor 采用了多种方法来创建基于真实代码库的合成任务。例如,其中一种方法是「功能删除」:给智能体一个包含大量测试用例的代码库,要求它以某种方式删除代码和文件,使得代码库在移除某些可测试功能后仍能保持运行。合成任务就是重新实现被删除的功能,而测试用例则用作可验证的奖励。
大规模创建合成任务带来的一个附带后果是,它可能引发意想不到的奖励破解行为。
随着模型能力越来越强,Composer 2.5 找到越来越精巧的变通方法来完成任务。有一个例子是,模型找到了一个遗留的 Python 类型检查缓存,并逆向工程其格式,从而找到了一个被删除的函数签名。另一个例子中,它找到并反编译了 Java 字节码,重建了一个第三方 API。Cursor 通过智能体监控工具发现并诊断了这些问题,但它们也说明,大规模强化学习需要越来越谨慎。
三是,分片 Muon 与双网格 HSDP。
在持续预训练中,Cursor 采用分布式正交化的 Muon 优化器。生成动量更新后,以模型的自然粒度运行 Newton-Schulz 迭代:对注意力投影按每个注意力头处理,对堆叠的 MoE 权重按每个专家处理。
主要开销来自专家权重的正交化。对于分片参数,将同形状的张量分批处理,通过全量交换(all-to-all)将分片汇聚为完整矩阵,运行 Newton-Schulz,再通过全量交换将结果传回原始分片布局。这些传输是异步的:当一个任务在等待通信时,优化器运行时会推进其他 Muon 任务,使网络传输与计算重叠。这等效于全矩阵 Muon,但能保持分片组持续忙碌;在 1T 参数模型上,优化器单步耗时仅 0.2 秒。
这与 Cursor 为 MoE 模型使用 HSDP 的方式密切相关。HSDP 构成多个 FSDP 副本,并在对应的分片之间进行梯度的全归约操作。Cursor 对非专家权重和专家权重使用各自独立的 HSDP 布局:非专家权重相对较小,其 FSDP 组可以保持较窄的范围,通常在一个节点或机架内;而专家权重承载了绝大部分参数和大部分 Muon 计算量,因此使用更宽的专家分片网格。
保持这些布局独立还能让独立的并行维度得以重叠:例如 CP=2 和 EP=8 可以在 8 块 GPU 上运行,而不需要在单一共享网格中占用 16 块。这样既避免了小型非专家状态的大范围通信,又将专家优化器的计算工作分摊到更多 GPU 上。
Composer 2.5 定价
Composer 2.5 定价为每百万输入 token 0.50 美元,每百万输出 token 2.50 美元。
另有一个速度更快、智能水平相同的变体,定价为每百万输入 token 3.00 美元,每百万输出 token 15.00 美元,比其他前沿模型的快速版更便宜。