将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,大模型并不具备在环境不断变化的场景中回答特定问题所需的全面知识。
例如,早期的ChatGPT的预训练语料库时间截至2021年,这意味着模型无法准确输出2021年以后的事实性问题,这正是现代大模型所面临的知识更新困境。
而在2023年11月,OpenAI发布的GPT-4 Turbo的知识更新时间截至2023年4月,实际上,对于一个大模型来说,更新基础模型知识库是非常困难的一件事情。首先,需要保证预训练数据的质量;其次,更新知识库后的模型通常都需要重新训练,至少要将新数据与旧数据按照一定的比例进行混合训练,而不能仅仅使用新数据,否则会出现灾难性遗忘的问题。总之,大模型的知识更新问题将成为模型的一个重要痛点。
2020年,Facebook(后更名为Meta)在"Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"一文中首先提出了一种称为检索增强生成(RAG) 的框架。该框架可以使模型访问超出其训练数据范围之外的信息,使得模型在每次生成时可以利用检索提供的外部更专业、更准确的知识,从而更好地回答用户问题。
一、RAG及核心原理
(一) 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种解决大模型"幻觉"和"知识滞后"问题的架构模式。
- 传统 LLM:像"闭卷考试",仅依赖训练时的记忆,容易编造事实。
- RAG:像"开卷考试",先查阅资料(检索),再回答问题(生成)。
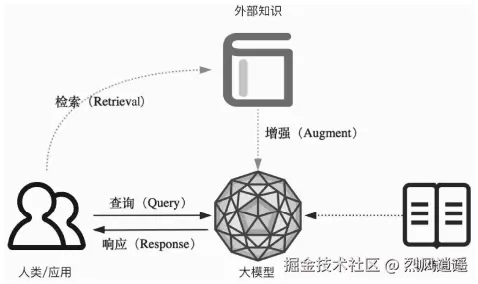
RAG 的基本思想可以简单表述如下:将传统的生成式大模型与实时信息检索技术相结合,为大模型补充来自外部的相关数据与上下文,以帮助大模型 生成更丰富、更准确、更可靠的内容。这允许大模型在生成内容时可以依赖实 时与个性化的数据和知识,而不只是依赖训练知识。如下图所示,可以简单概括为:
RAG = LLM(大模型) + 外部知识库
(二) RAG的核心工作流程
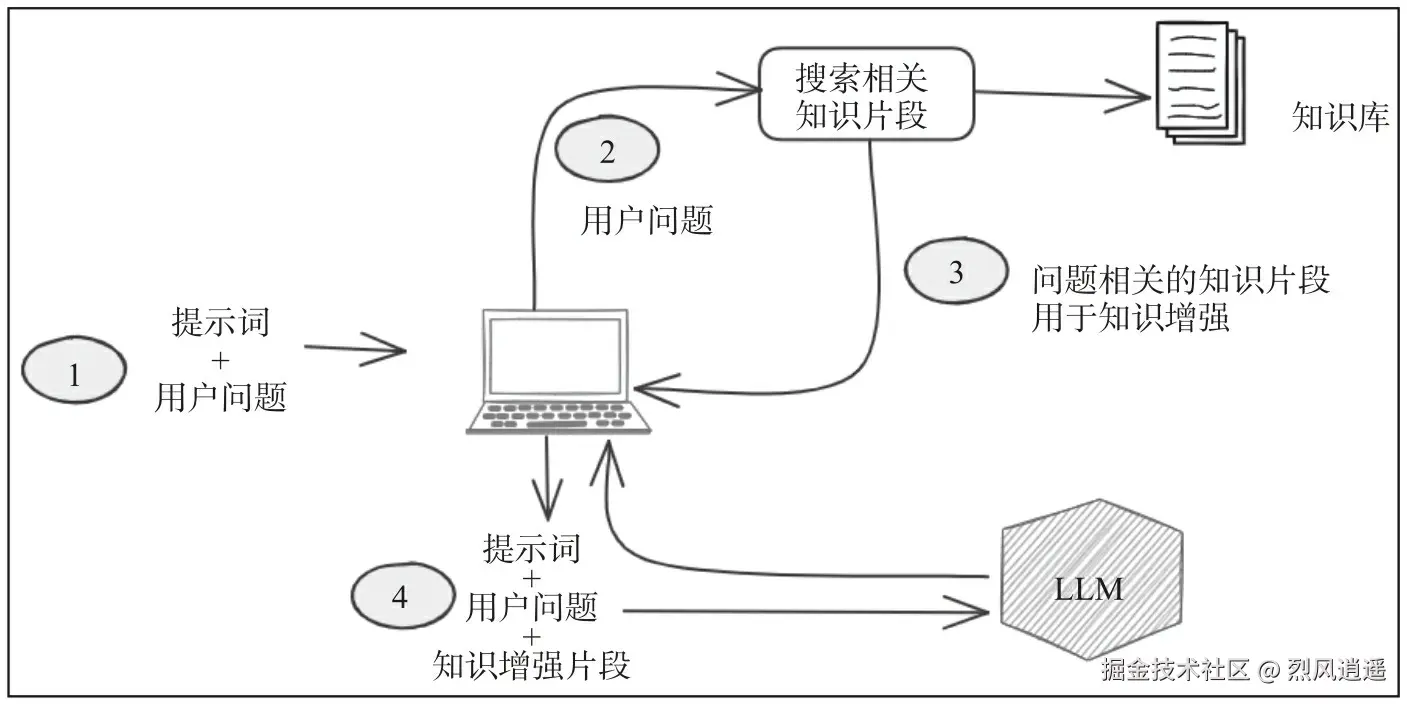
RAG的工作流程涉及3个主要阶段:数据准备 、数据召回和答案生成。
- 数据准备:包括识别数据源、从数据源提取数据、清洗数据并将其存储在数据库中。
- 数据召回:包括根据用户输入的查询条件从数据库中检索相关数据。
- 答案生成:利用检索到的数据和用户输入的查询条件生成输出结果。输出质量的高低取决于数据质量和检索策略。
2.1 数据准备阶段------构建知识库的基石
在企业环境中,数据往往是非结构化的,散落在各种文件格式中。将各种非结构化数据(PDF、Word、TXT)进行解析 、清洗 、分块(Chunking),然后存入数据库中就是这个阶段的主要工作。
这里说明下为什么要将这些数据进行解析、清洗、分块然后存入数据库,而不是直接将这些文件不做处理直接存入数据库中?
2.1.1 为什么要对数据处理?
简单来说,不对非结构化数据进行解析、清洗和分块而直接存入数据库,就像把一本厚厚的、没有目录的书直接扔给一个只能快速阅读几页书的人,让他回答书中的具体问题一样,效率低下且效果很差。
RAG系统之所以需要这套复杂的预处理流程,主要是为了克服以下三个根本性限制:
大模型的"记忆"限制(上下文窗口)
大语言模型(LLM)一次能处理的文本量是有限的,这个限制被称为"上下文窗口"。你无法将一本几百页的PDF手册或整个公司的知识库一次性塞给模型让它回答问题。
分块(Chunking)的目的: 大模型有上下文窗口限制(如 8k, 32k, 128k tokens),且检索需要细粒度。因此,必须将长文档切分成小的文本块。将冗长的文档切割成一个个大小合适、语义相对完整的"知识片段"。当用户提问时,系统只需检索出最相关的几个片段(例如3-5个)作为上下文提供给大模型,这样既在模型的处理能力范围内,又能保证信息的精准性。
检索的"精度"与"语义"难题
传统的数据库(如MySQL)擅长处理结构化数据(如Excel表格),可以通过SQL进行精确筛选(例如WHERE 价格 > 100)。但它们无法理解非结构化文本的语义。
解析与清洗的目的:原始文档(尤其是PDF)充满了页眉、页脚、页码、广告、乱码等"噪声"。如果不进行清洗,这些噪声会严重干扰检索,导致系统召回无关内容。解析还能帮助保留文档的标题、列表等结构信息,这对于理解内容至关重要。
分块的目的:检索的基本单位是"块"(Chunk),而不是整篇文档或单个句子。如果以整篇文档为单位,召回的结果会包含大量无关信息;如果以单个句子为单位,又会丢失必要的上下文。合理的分块是在"信息聚焦"和"语义完整"之间取得平衡。
向量化(Embedding)的基础:RAG的核心是语义检索。它通过Embedding模型将文本块转换为高维向量(一串数字),使得语义相近的文本在向量空间中的距离也更近。例如,"服务器宕机"和"机器无响应"字面不同,但向量表示会非常接近。这种转换必须在干净、语义完整的文本块上进行,才能保证检索的准确性。
数据库类型的"错配"
现实中提到的"数据库"通常指关系型数据库,它并非为存储和检索非结构化文本的语义信息而设计。
| 特性 | 传统关系型数据库 (如MySQL) | RAG系统使用的向量数据库 (如Milvus, Chroma) |
|---|---|---|
| 数据类型 | 擅长处理结构化数据(有固定字段和类型) | 专为存储和检索非结构化数据的向量表示而设计 |
| 检索方式 | 精确匹配(如 WHERE name = 'Alice' ) |
近似最近邻搜索,基于向量相似度(如余弦相似度) |
| 核心能力 | 快速筛选、聚合、统计 | 在海量数据中进行毫秒级的语义模糊匹配 |
RAG系统最终会将处理好的文本块及其向量表示存入向量数据库,而不是传统的关系型数据库。向量数据库就像一个高效的"语义地图",能够根据用户问题的向量,快速找到知识库中最相关的几个文本块。
2.1.2数据处理的几个步骤
数据采集与加载
- 目标:从各种来源收集原始数据。
- 操作:系统通过特定的加载器(Loader)读取不同格式的文件,如PDF、Word、Markdown、TXT、HTML网页、数据库记录、API接口数据等。这一步是知识进入RAG系统的入口。
数据清洗
- 目标:去除数据中的"噪声",保证后续处理的文本质量。
- 操作 :原始文档中常常包含大量对核心语义无用的信息,例如:
- 页眉、页脚、页码、版权声明。
- HTML/XML标签、特殊字符、乱码。
- 无关的广告、导航菜单。
- 重复的段落或文档。
- 如果不进行清洗,这些噪声会污染后续的向量化过程,导致检索结果不准确。
文档分块 (Document Chunking)
- 目标:将长文档切分成大小合适、语义相对完整的文本片段(Chunk)。
- 原因 :
- 模型限制:大语言模型的上下文窗口(Context Window)有限,无法一次性处理整本书。
- 检索精度:检索的单位应该是"知识片段"而非"整篇文档"。一个精准的Chunk能让模型更快地定位到答案,避免被无关信息干扰。
- 常见策略 :
- 固定长度切分:按固定的字符数或Token数切分,通常会设置一定的重叠(Overlap)以防止切断完整的句子。
- 语义切分:根据段落、章节标题、句子边界等自然语言结构进行切分,以保持语义的完整性。
向量化( Embedding )
- 目标:将文本块转换为计算机能够理解和计算的数学形式。
- 操作:使用一个预训练的Embedding模型,将每个文本块(Chunk)转换成一个高维向量(一串数字)。这个向量可以看作是文本的"语义指纹",语义相似的文本,其向量在数学空间中的距离也更近。例如,"猫咪喜欢玩毛线球"和"猫爱玩绒线球"的向量表示会非常接近。
索引与存储**( Indexing & Storage )**
- 目标:将向量化后的数据高效地存储起来,以便进行快速检索。
- 操作 :将每个文本块的向量、原始文本内容以及相关的元数据(如来源、标题、作者、时间等)存入专门的向量数据库(如Milvus, Chroma, FAISS等)。向量数据库会为这些向量建立索引,从而实现毫秒级的近似最近邻搜索(ANN Search),这是语义检索的核心。
2.2 数据召回阶段------检索
数据召回阶段就是从海量的向量数据库中,快速且精准地找出与用户问题最相关的 Top-K 个文本片段。
以下是关于数据召回的具体功能核心机制的详细列述:
语义检索
这是 RAG 区别于传统搜索引擎(如 Elasticsearch 的关键词匹配)的最大特征。
- 功能描述:将用户的自然语言问题通过 Embedding 模型转化为高维向量,然后在向量空间中计算该向量与数据库中存储的文本块向量的距离(通常使用余弦相似度)。
- 作用 :解决"词汇不匹配"问题。
- 示例:用户搜索"车坏了怎么办",传统搜索可能找不到包含"汽车"或"维修"的文章,但语义检索能理解"车"与"汽车"、"坏了"与"维修"在向量空间距离很近,从而召回相关内容。
多路召回
单一的策略往往存在盲区,为了提高准确率,现代 RAG 系统通常采用多路召回。
- 功能描述 :同时使用多种策略进行检索,然后合并结果。
- 向量检索:负责语义理解。
- 全文检索:负责精确匹配专有名词(如订单号、特定产品型号)。
- 元数据过滤:根据权限、时间、类别进行过滤(例如:只检索"2024年"且"部门=财务"的文档)。
- 作用:兼顾语义的广度和关键词的精度,防止因单一算法缺陷导致的漏检。
混合打分与重排序
召回的初选结果往往包含噪音,需要经过二次筛选。
- 功能描述 :
- 混合打分:对向量检索得分和关键词检索得分进行加权计算(如使用 Reciprocal Rank Fusion 算法)。
- 重排序:使用一个专门的交叉编码器模型,对初筛出的 Top-50 个片段进行精细化打分和重新排序。
- 作用:将真正最相关的内容排在最前面,剔除相关性弱的干扰信息。
上下文窗口管理
- 功能描述:根据 LLM 的上下文窗口限制(Context Window),动态截取或拼接召回的文本块。
- 作用:在保证信息完整性的前提下,最大化利用 LLM 的输入长度,避免 Token 溢出或浪费。
2.3 答案生成
在 RAG 系统中,答案生成处于整个链路的末端,是将"死数据"转化为"活智慧"的关键一步。如果说前面的召回环节是"开卷考试"时的翻书找资料,那么生成环节就是考生合上书本,根据刚刚看到的内容和自己的理解来组织语言、输出答案的过程。
这一环节主要依赖大语言模型,但它不是简单的问答,而是基于特定上下文的"阅读理解"。
以下是关于答案生成环节的具体功能、作用及核心机制的详细列述:
提示词工程与上下文组装
这是生成环节的入口,也是最考验设计功底的地方。
- 功能描述:系统需要将用户的原始问题、检索回来的 Top-K 个文本片段、以及预设的系统指令,按照特定的模板拼装成一个完整的 Prompt。
- 作用:为模型划定边界。明确告诉模型:"请仅依据以下提供的参考资料回答问题,如果资料中没有答案,请回答'我不知道'"。这能极大程度地限制模型的胡编乱造。
信息抽取与综合
大模型在此扮演了"阅读者"和"综合者"的角色。
- 功能描述:模型阅读检索回来的多个文本片段(这些片段可能来自不同的文档,甚至存在部分冲突),提取出与问题相关的核心事实,并将碎片化的信息整合成一段通顺的逻辑。
- 作用:解决信息孤岛问题。用户不需要自己去阅读5个不同的文档片段,模型帮用户完成了"阅读-理解-总结"的过程,直接提供结论。
风格控制与格式化
- 功能描述:通过系统提示词,控制生成内容的语气、长度和格式。
- 作用 :适应业务场景。
- 客服场景:要求语气亲切、回答简练。
- 法律/医疗场景:要求用词严谨、引用法条准确。
- 代码生成场景:要求输出 Markdown 格式的代码块。
来源溯源与引用
这是企业级 RAG 系统不可或缺的功能。
- 功能描述:在生成答案的同时,标记出每一句话或每一个观点是参考了哪一个文本片段(Chunk),并在前端展示对应的文档链接或角标。
- 作用:建立用户信任。用户可以点击引用源去核对原文,确信 AI 没有撒谎,这对于严肃业务场景至关重要。
二、开发一个RAG系统
(一) 技术栈选型
| 模块 | 技术选型 | 说明 |
|---|---|---|
| 前端 | Vue 3 + TypeScript + Vite | 现代化前端框架,类型安全 |
| UI 组件库 | Element Plus / Ant Design Vue | 快速构建界面 |
| 后端 | Spring Boot 3 + JDK 17+ | 核心业务逻辑 |
| AI 框架 | LangChain4j | Java 生态最强的 LLM 编排框架 |
| 向量数据库 | In-Memory (演示) / PostgreSQL (PgVector) / Milvus | 存储向量数据 |
| 大模型 | DeepSeek / OpenAI / Qwen | 提供推理能力 |
为了快速实现效果,这里并没有真正的创建向量数据库,而是使用 In-Memory 将数据直接存储在计算机的随机存取存储器(RAM)中。优点是方便,快捷,缺点是没有真正存储数据,每次启动服务数据都会清空,演示效果足够了。
大模型这块使用的是deepSeek和阿里云的大模型,在官网注册一个apiKey就行
(二)整体架构概览
一个完整的 RAG 系统主要包含以下几个核心部分:
- 前端 (Vue3):提供用户交互界面,包括知识库管理、文件上传和聊天对话。
- 后端 (Spring Boot):作为业务逻辑中心,处理文件上传、调用 AI 服务、管理数据。
- AI 服务层 (Spring AI + LLM) :
- Embedding 模型:将文本转换为计算机可理解的向量。
- LLM (大语言模型):根据检索到的上下文生成最终答案。
- 向量数据库 (Vector Store):存储文档的向量表示,用于快速进行语义检索。目前使用In-Memory插件实现效果
(三) 环境搭建和后端配置
先创建一个springBoot项目,这里不过多介绍
3.1 配置文件 pom.xml
在 pom.xml 中添加必要的依赖。
xml
<!-- LangChain4j 核心 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
<!-- LangChain4j OpenAI 集成 (支持兼容协议) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.35.0</version>
</dependency>
<!-- LangChain4j ChromaDB 集成 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>0.35.0</version>
</dependency>
<!-- word Excel 处理 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.5</version> <!-- 推荐 5.2.3+ -->
</dependency>
<!-- PDFBox for PDF 文件处理 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.27</version>
</dependency>其依赖主要作用如下:
| langchain4j | LangChain4j 核心库,提供大语言模型集成、提示工程、记忆管理等核心功能。它提供了抽象接口 。这意味着你的业务代码(Service层)是写死在langchain4j接口上的,而不是具体的模型上。如果你以后想从 OpenAI 切换到 Ollama 或 Azure,只需要改配置,不需要重写业务代码。 |
|---|---|
| langchain4j-open-ai | 集成 OpenAI 模型(如 GPT-3.5/4),支持通过兼容协议调用云端大模型。虽然名字叫 OpenAI,但因为它遵循标准的 OpenAI 接口协议,所以它也常被用来连接兼容 OpenAI 协议的其他模型(例如 DeepSeek、Ollama 本地模型、阿里云百炼等) |
| langchain4j-chroma | 集成 ChromaDB 向量数据库,用于存储和检索嵌入向量,支持基于语义的相似性搜索。在 RAG 流程中,文档被切分并向量化后,需要存入一个能理解"语义距离"的数据库。Chroma 就是这样一个轻量级、高性能的向量库。当你提问时,LangChain4j 会通过这个依赖去 Chroma 中查找与你问题"语义最相似"的文档片段,作为背景知识喂给 AI。 |
| poi-ooxml | 处理 Microsoft Word 和 Excel 文件(.docx, .xlsx),支持读写办公文档 |
| pdfbox | 处理 PDF 文件,支持文本提取、文档生成和页面操作 |
3.2 配置 application.properties
配置应用、数据库和 AI 模型的相关信息。
properties
# --- AI 配置 (使用了两个AI,deepSeek和阿里云百炼 可以动态设置)---
# 活动 AI ( aliyun, deepseek)
ai.active-provider=aliyun
# DeepSeek 配置
#apiKey
ai.providers.deepseek.api-key=sk-youToken
#url地址
ai.providers.deepseek.base-url=https://api.deepseek.com/v1
#AI模型
ai.providers.deepseek.chat-model=deepseek-chat
#向量模型
ai.providers.deepseek.embedding-model=text-embedding-3-small
# aliyun 配置
#apiKey
ai.providers.aliyun.api-key=sk-youToken
#url地址
ai.providers.aliyun.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
#AI模型
ai.providers.aliyun.chat-model=qwen-plus
#向量模型
ai.providers.aliyun.embedding-model=text-embedding-v1(四) 后端核心功能实现
根据前面Rag的核心工作流程来看,后端的主要工作流程如下:
- 第一步(文档入库):将前端上传的各类格式文档接收,然后解析、清洗、分块存入数据库中;
- 第二步(问答检索 ):将从前端接收的问题通过Embedding 模型转化为高维向量 ,然后从数据库(上传的文件知识库)检索出相似的知识片段,之后将将检索的知识片段和高维向量一起发送给大模型,将大模型返回的信息发给前端显示出来。
4.1 构建实体类和配置类
实体类 ChatRequest
构建一个实体类ChatRequest.java来存储各种类型的信息,代码如下:
java
package org.seaPack.dto;
import lombok.Data;
import java.util.List;
/**
* 问答请求DTO
* 用于接收问答接口的请求参数
*/
@Data
public class ChatRequest {
/**
* 命名空间
* 指定在哪个知识库中检索相关文档
*/
private String namespace;
/**
* 用户问题
* 需要RAG系统回答的问题
*/
private String question;
// 新增内部类来映射 messages 数组中的对象
@Data
public static class MessageDTO {
//角色
private String role;
//内容
private String content;
}
// 修改这里:接收前端传来的 messages 列表
private List<MessageDTO> messages;
}其各类字段的用途如下:
| 字段名 | 名称 | 作用 |
|---|---|---|
| namespace | 命名空间 | 指定在哪个知识库中检索相关文档。用于多租户或多知识库场景,标识具体的命名空间,当系统包含多个独立的知识库时,通过此参数指定操作的目标知识库。 |
| question | 用户问题 | 存储用户提出的问题,需要RAG系统回答的核心内容。用户输入的原始问题文本。RAG系统根据此问题进行文档检索和答案生成 |
| messages | 消息列表 | 接收前端传来的消息列表,用于维护对话历史,在连续对话中传递历史交互内容,确保上下文连贯性 |
其中使用了一个内部类 MessageDTO,其字段说明如下
| 字段名 | 名称 | 作用 |
|---|---|---|
| role | 角色 | 标识消息的发送角色,区分消息来源(如用户、AI助手、系统),通常取值为"user"(用户)、"assistant"(AI助手)、"system"(系统),用于构建对话上下文 |
| content | 内容 | 存储消息的具体内容,角色发送的实际文本内容,传递用户提问、AI回复或系统提示等具体信息 |
配置类 AIProperties
创建配置类 <font style="color:rgb(6, 10, 38);">AIProperties</font>,支持动态切换底层的 AI 提供商(如 OpenAI、DeepSeek、阿里云等),利用 OpenAI 协议兼容性实现"一次代码,多处运行"。 代码如下,
java
package org.seaPack.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.Map;
@Data // Lombok 自动生成 Getter/Setter/ToString
@Component
@ConfigurationProperties(prefix = "ai") // 对应配置文件中的 ai.*
public class AIProperties {
/**
* 当前激活的 AI 提供商名称
* 对应配置文件中的: ai.active-provider (或 ai.activeProvider)
* 例如: "deepseek", "aliyun", "baidu"
*/
private String activeProvider;
/**
* 所有 AI 提供商的配置集合
* 键(Key)为提供商名称,值(Value)为具体的配置对象
* 对应配置文件中的: ai.providers.<provider-name>.*
*/
private Map<String, ProviderConfig> providers;
/**
* 单个 AI 提供商的具体配置结构
*/
@Data // 内部类也需要 @Data
public static class ProviderConfig {
/**
* 调用 AI 服务所需的 API 密钥 (Secret Key)
* 对应配置文件中的: ai.providers.<name>.api-key
*/
private String apiKey;
/**
* AI 服务的接口基础地址
* 对应配置文件中的: ai.providers.<name>.base-url
* 例如: "https://api.deepseek.com/v1"
*/
private String baseUrl;
/**
* 聊天模型名称
* 对应配置文件中的: ai.providers.<name>.chat-model
* 例如: "gpt-3.5-turbo", "gpt-4"
*/
private String chatModel;
/**
* 向量化/嵌入模型名称
* 对应配置文件中的: ai.providers.<name>.embedding-model
* 用于文本向量化处理,例如: "text-embedding-ada-002"
*/
private String embeddingModel;
}
}ConfigurationProperties注解可以获取application.yml或 application.properties文件中 AI的配置信息
4.2 文档入库
在这一流程中,主要实现**文档的上传与解析**。可以分为以下几个步骤:
- 创建一个工具类 FileParserUtil ,解析不同类型的文件
- 创建 RagService 服务,获取AI配置初始化向量模型,
- 解析文档,将解析后的数据存入向量化数据库中
- 创建 RAG控制器 RagController ,提供文件上传接口,接收文件
- 在 RagService 服务中开发命名空间功能,将不同类型的文档隔离,避免干扰
创建工具类 FileParserUtil.java
创建一个工具类 FileParserUtil.java,从不同格式的文件中提取文本,代码如下:
java
package org.seaPack.components;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.springframework.stereotype.Component;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.util.List;
import java.util.stream.Collectors;
/**
* 文件解析工具类
* 核心功能:根据文件后缀名,自动解析 TXT / PDF / DOCX 格式文件,提取纯文本内容
*/
@Component
@Slf4j
public class FileParserUtil {
/**
* 根据文件后缀解析文件内容(对外提供的核心方法)
* @param inputStream 文件输入流(读取文件的数据源)
* @param fileName 文件名(用于判断文件格式)
* @return 解析后的纯文本字符串
* @throws Exception 解析过程中可能抛出的IO异常、格式不支持异常等
*/
public static String parseFile(InputStream inputStream, String fileName) throws Exception {
// 将文件名转为小写,统一判断文件后缀,避免大小写干扰(如.TXT、.Pdf)
String lowerName = fileName.toLowerCase();
try {
if (lowerName.endsWith(".txt")) {
return parseTxt(inputStream);
} else if (lowerName.endsWith(".pdf")) {
return parsePdf(inputStream);
} else if (lowerName.endsWith(".docx")) {
return parseDocx(inputStream);
} else {
throw new IllegalArgumentException("不支持的文件格式: " + fileName);
}
} catch (Exception e) {
// 统一捕获异常,打印详细日志,方便排查是哪个文件出的问题
log.error("文件解析失败: {}", fileName, e);
throw new Exception("文件解析失败: " + e.getMessage());
}
}
/**
* TXT 解析:显式指定 UTF-8
*/
private static String parseTxt(InputStream inputStream) throws Exception {
// 使用 ByteArrayOutputStream 确保完整读取
ByteArrayOutputStream result = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = inputStream.read(buffer)) != -1) {
result.write(buffer, 0, length);
}
// 强制使用 UTF-8 转换,防止默认编码导致的乱码
return result.toString("UTF-8");
}
/**
* 私有方法:专门解析PDF文件,提取文本内容
* @param inputStream PDF文件输入流
* @return PDF解析后的纯文本
* @throws Exception PDF解析异常、IO异常
*/
private static String parsePdf(InputStream inputStream) throws Exception {
// try-with-resources语法:自动关闭PDDocument资源,避免内存泄漏
// 加载输入流,创建PDF文档对象
try (PDDocument document = PDDocument.load(inputStream)) {
if (document.getNumberOfPages() == 0) {
return "";
}
// 创建PDF文本提取器
PDFTextStripper stripper = new PDFTextStripper();
// 1. 设置换行符,防止段落粘连
stripper.setSortByPosition(true); // 按位置排序,保持阅读顺序
// 2. 获取原始文本(这里会产生 WARN 日志,但不会崩溃)
String text = stripper.getText(document);
// 3. 【核心修复】清洗文本
// PDFBox 2.0 遇到无法映射的字体(如公式)时,通常会输出 '?' 或者乱码符号(如 '????')
// 我们需要把这些无效字符清理掉,或者替换为空格,防止后续 RAG 分块出错
if (text != null) {
// 替换连续的问号(通常是无法识别的数学符号)为空格
text = text.replaceAll("\\?{2,}", " ");
// 替换不可见的控制字符(除了换行和制表符)
text = text.replaceAll("[\\p{Cntrl}&&[^\r\n\t]]", "");
// 去除多余的空行
text = text.replaceAll("\n\\s*\n", "\n");
}
return text;
}
}
/**
* 私有方法:专门解析DOCX文件(Word文档),提取文本内容
* @param inputStream DOCX文件输入流
* @return DOCX解析后的纯文本(段落用换行分隔)
* @throws Exception DOCX解析异常、IO异常
*/
private static String parseDocx(InputStream inputStream) throws Exception {
// try-with-resources语法:自动关闭XWPFDocument资源
// 加载输入流,创建DOCX文档对象
try (XWPFDocument document = new XWPFDocument(inputStream)) {
// 流式处理:获取所有段落 -> 提取段落文本 -> 过滤空文本 -> 收集为List集合
List<String> texts = document.getParagraphs().stream()
// 将每个段落对象转换为文本内容
.map(XWPFParagraph::getText)
// 过滤:只保留非null、非空白的文本
.filter(text -> text != null && !text.trim().isEmpty())
// 将有效文本收集到List集合中
.collect(Collectors.toList());
// 将所有有效段落用换行符\n拼接,返回完整文本
return String.join("\n", texts);
}
}
}通过parseFile 方法解析文件,目前只支持 .txt 、.docx 、.pdf 文件,后续可增加其他文件的解析方法。
获取AI配置并初始化向量模型
在 RagService 服务中进行初始化操作。构建向量化模型,直接在本地存储向量化数据。
java
@Service
public class RagService {
/**
* 注入多模型配置类
*/
private final AIProperties aiProperties;
/**
* 向量化模型,用于将文本转换为向量表示
*/
private EmbeddingModel embeddingModel;
/**
* 构造函数注入 AIProperties
*/
public RagService(AIProperties aiProperties) {
this.aiProperties = aiProperties;
}
/**
* 初始化方法,在Bean构造完成后执行
* 初始化embedding模型和chat模型
*/
@PostConstruct
public void init() {
// 1. 获取当前激活的提供商配置
String providerName = aiProperties.getActiveProvider();
AIProperties.ProviderConfig config = aiProperties.getProviders().get(providerName);
if (config == null) {
throw new RuntimeException("未找到 AI 提供商配置: " + providerName);
}
System.out.println("正在初始化 RAG 服务,使用提供商: " + providerName);
// 2. 构建向量化模型
// 利用 OpenAiEmbeddingModel 的兼容性,指向 DeepSeek 或 阿里云 的接口
this.embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(config.getApiKey())
.baseUrl(config.getBaseUrl())
.modelName(config.getEmbeddingModel())
.build();
System.out.println("RAG 服务初始化完成。");
}
}初始化init方法会在 Spring Bean 启动时自动执行,实现RAG服务的初始化。代码逻辑比较简单,就两步:
- 读取
<font style="color:rgb(6, 10, 38);">aiProperties</font>获取当前激活的提供商配置。 - 使用
<font style="color:rgb(6, 10, 38);">OpenAiEmbeddingModel</font>构建向量化模型。
解析文档并存入向量数据库中,
这一步的工作主要数据存入,将文本数据文本数据"吃进去"(Ingest),转化为向量并存入内存数据库。它主要完成了 文本加载 -> 文本分割 -> 向量化 -> 存储 这一标准流程,并支持通过命名空间来隔离不同的知识库。
java
@Service
public class RagService {
...
/**
* 向量化模型,用于将文本转换为向量表示
*/
private EmbeddingModel embeddingModel;
/**
* 命名空间到向量存储的映射,支持多知识库隔离
* Key: 命名空间名称
* Value: 该命名空间下的向量存储库
*/
private final Map<String, EmbeddingStore<TextSegment>> namespaceStore = new ConcurrentHashMap<>();
/**
* 文档入库方法,将文本转换为向量并存储
* @param namespace 命名空间,用于隔离不同知识库
* @param text 要入库的文本内容
*/
public void ingestText(String namespace, String text) {
// 获取或创建该命名空间对应的向量存储库
EmbeddingStore<TextSegment> store = namespaceStore.computeIfAbsent(namespace, k -> new InMemoryEmbeddingStore<>());
// 将文本转换为Document对象(使用构造方法)
Document document = new Document(text);
// 创建文档分割器,按段落分割,每段最大500字符,重叠100字符
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(500, 100);
// 分割文档为多个文本片段
List<TextSegment> segments = splitter.split(document);
// 简单日志,便于排查
System.out.println("[RagService] ingestText namespace=" + namespace + ", segments=" + segments.size());
// 遍历每个文本片段,进行向量化并存储
for (TextSegment segment : segments) {
// 使用embedding模型将文本片段转换为向量
Embedding embedding = embeddingModel.embed(segment.text()).content();
// 将向量和对应的文本片段存入向量存储库
store.add(embedding, segment);
}
}
...
}EmbeddingModel embeddingModel 是翻译官,将人类可读的文本(String)转换成机器可理解的数学向量(List)。Map<String, EmbeddingStore> namespaceStore 实现多用户、多知识库隔离,不同知识库的数据互不干扰。
ingestText 方法执行流程代码分析:
- 获取或创建存储实例 (懒加载):
java
EmbeddingStore<TextSegment> store = namespaceStore.computeIfAbsent(namespace, k -> new InMemoryEmbeddingStore<>());检查 namespaceStore 中是否存在当前 namespace 的存储。如果存在,直接复用,如果不存在,创建一个新的 InMemoryEmbeddingStore(内存型向量库)并放入 Map 中。
这里硬编码了使用 InMemoryEmbeddingStore ,意味着数据存储在 JVM 内存中,服务重启后数据会丢失。
- 文本包装与分割
java
Document document = new Document(text);
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(500, 100);
List<TextSegment> segments = splitter.split(document);这段代码的逻辑是将原始字符串包装成 Document对象,使用 DocumentByParagraphSplitter进行切片。500代表每个片段最大 500 个字符(或 Token,视具体实现而定),100代表片段之间有 100 个字符的重叠。重叠是为了保留上下文信息,防止切分点切断了句子的语义,提高检索时的准确率。
- 向量化与存储循环
java
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment.text()).content();
store.add(embedding, segment);
}代码逻辑为:调用模型将文本片段 segment.text()转换为高维向量 embedding。之后将 <向量, 原始文本片段> 这一对数据存入到存储实例store中。
创建 RAG控制器,提供文档上传接口
创建RagController 类,提供一个文件上传接口 /rag/ingest-file。使用FileParserUtil 工具类的文件处理方法,将不同的格式文件转化为文本,然后调用 RagService 服务的 ingestText 方法存入数据库中。
java
/**
* RAG控制器
* 提供RAG应用的相关API接口,包括文档入库、问答、命名空间管理等
*/
@RestController
@RequestMapping("/rag")
public class RagController {
/**
* RAG服务类,负责文档向量化、存储和问答处理
*/
private final RagService ragService;
/**
* 构造函数,注入RagService
* @param ragService RAG服务类
*/
public RagController(RagService ragService) {
this.ragService = ragService;
}
/**
* 文件上传接口
*/
@PostMapping("/ingest-file")
public Result<Void> ingestFile(
@RequestParam("namespace") String namespace,
@RequestParam("file") MultipartFile file) {
// 添加调试日志
System.out.println(">>> 正在接收文件: " + file.getOriginalFilename() + " 到空间: [" + namespace + "]");
if (file.isEmpty()) {
return Result.error("文件为空");
}
try {
// 1. 使用工具类解析文件为文本
String text = FileParserUtil.parseFile(file.getInputStream(), file.getOriginalFilename());
// 2. 调用原有的文本入库逻辑
ragService.ingestText(namespace, text);
return Result.success();
} catch (Exception e) {
e.printStackTrace();
return Result.error("文件解析失败: " + e.getMessage());
}
}
}至此,这一个支持多知识库隔离的、基于内存的、简单的文本入库的接口就实现了。它利用 LangChain4j 的标准组件完成了 从文本到向量存储的闭环。
命名空间开发,隔离不同文本
在之前文档入库的代码中已经实现了文本隔离的操作,在 ingestText 方法的第一行代码就是根据不同的命名空间创建不同的向量存储库。在此基础上,还需提供命名空间的查询与删除接口,对命名空间进行管理。
在RagService 服务中添加 命名空间的查询与删除操作。
java
@Service
public class RagService {
/**
* 命名空间到向量存储的映射,支持多知识库隔离
* Key: 命名空间名称
* Value: 该命名空间下的向量存储库
*/
private final Map<String, EmbeddingStore<TextSegment>> namespaceStore = new ConcurrentHashMap<>();
...
/**
* 清除指定命名空间的所有文档
* @param namespace 要清除的命名空间名称
*/
public void clearNamespace(String namespace) {
namespaceStore.remove(namespace);
}
/**
* 获取所有已存在的命名空间列表
* @return 命名空间名称列表
*/
public List<String> getNamespaces() {
return List.copyOf(namespaceStore.keySet());
}
...
}在RagController类中 提供命名空间查询与删除接口
java
@RestController
@RequestMapping("/rag")
public class RagController {
/**
* RAG服务类,负责文档向量化、存储和问答处理
*/
private final RagService ragService;
/**
* 构造函数,注入RagService
* @param ragService RAG服务类
*/
public RagController(RagService ragService) {
this.ragService = ragService;
}
/**
* 清除命名空间接口
* 删除指定命名空间下的所有文档和向量数据
* @param namespace 要清除的命名空间名称
* @return 操作结果
*/
@DeleteMapping("/namespace/{namespace}")
public Result<Void> clearNamespace(@PathVariable String namespace) {
// 调用RagService的清除命名空间方法
ragService.clearNamespace(namespace);
return Result.success();
}
/**
* 获取命名空间列表接口
* 返回所有已创建的知识库命名空间
* @return 命名空间名称列表
*/
@GetMapping("/namespaces")
public Result<List<String>> getNamespaces() {
// 调用RagService获取命名空间列表
return Result.success(ragService.getNamespaces());
}
}4.3 问答检索
这一阶段的流程是 将从前端接收的问题通过Embedding 模型转化为高维向量,然后从数据库(上传的文件知识库)检索出相似的知识片段,之后将将检索的知识片段和高维向量一起发送给大模型,将大模型返回的信息发给前端显示出来。
详细流程如图所示:
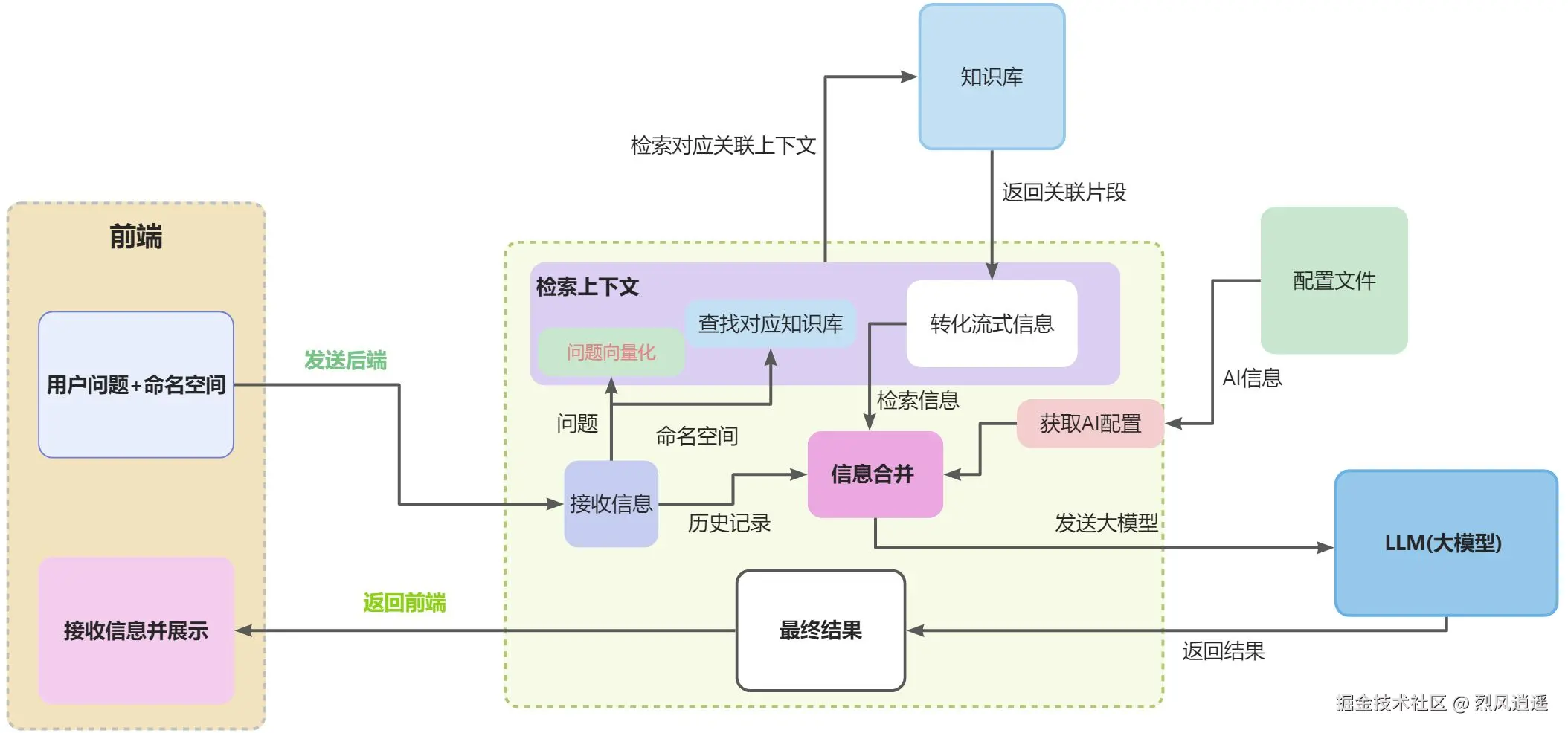
这个流程的操作就比较简单了,大体上可以分为两步:
- 根据问题在向量模型库中检索相关的信息
- 将问题和检索的信息发送给远程的大模型
向量模型库中检索相关信息
在 RagService 服务中添加检索上下文的 getRelevantContext 方法,其接收两个参数:命名空间和问题参数。其主要的功能是:根据问题在向量模型库中搜索相关的信息,之后将信息拼接后返回。
java
@Service
public class RagService {
/**
* 向量化模型,用于将文本转换为向量表示
*/
private EmbeddingModel embeddingModel;
/**
* 命名空间到向量存储的映射,支持多知识库隔离
* Key: 命名空间名称
* Value: 该命名空间下的向量存储库
*/
private final Map<String, EmbeddingStore<TextSegment>> namespaceStore = new ConcurrentHashMap<>();
...
/**
* 仅检索上下文,不生成回答
* 供 ChatController 在流式对话前调用
*/
public String getRelevantContext(String namespace, String question) {
//根据命名空间来获取具体的向量存储实例
EmbeddingStore<TextSegment> store = namespaceStore.get(namespace);
if (store == null) {
return null;
}
//将用户的自然语言问题(String question)转换成一个高维向量(Embedding)。
Embedding queryEmbedding = embeddingModel.embed(question).content();
//在向量数据库中查找与 queryEmbedding 最相似的向量。
// findRelevant方法参数:
// 参数一 referenceEmbedding:刚才生成的问题向量
// 参数二 maxResults:表示只返回相似度最高的 3 个结果。这是为了控制上下文窗口的大小,防止给大模型喂太多无关信息。
// 参数三 minScore:Min-Score(最小相似度阈值)。只有相似度得分高于 0.5(通常指余弦相似度)的结果才会被返回。这起到一个"过滤器"的作用,避免把不相关的内容强行塞给模型。
List<EmbeddingMatch<TextSegment>> matches = store.findRelevant(queryEmbedding, 3, 0.5);
if (matches.isEmpty()) {
return null;
}
// 拼接文档片段
return matches.stream()
.map(match -> match.embedded().text())
.collect(Collectors.joining("\n\n"));
}
...
}这段代码的主要逻辑如下:
- 根据命名空间参数查询对应的向量存储库,如果没有对应向量库则返回null;
- 将用户的自然语言问题(String question)转换成一个高维向量(Embedding);
- 在向量数据库中查找与 queryEmbedding 最相似的向量。如果没有查询到,返回null;
- 将查找到的分散的知识片段组装成了一个完整流式文本返回。
将检索信息和问题发给大模型
这一步的主要逻辑就是将知识库检索的信息和问题发送给对应的大模型。在ChatController 中添加一个和大模型对话的接口 /chat/aiModel。
java
@RestController
@RequestMapping("/chat")
@CrossOrigin(origins = "*")
@RequiredArgsConstructor // Lombok 自动生成 final 字段的构造函数 (用于注入)
public class ChatController {
private final AIProperties aiProperties;
private final RestTemplate restTemplate = new RestTemplate();
@Autowired
private RagService ragService;
@PostMapping("/aiModel")
public ResponseEntity<StreamingResponseBody> chat(@RequestBody ChatRequest request) {
// 1. 获取配置
String providerName = aiProperties.getActiveProvider();
AIProperties.ProviderConfig config = aiProperties.getProviders().get(providerName);
if (config == null) {
throw new RuntimeException("AI 配置错误:未找到提供商 [" + providerName + "]");
}
// 2. 构建 URL
String url = config.getBaseUrl().replaceAll("/+$", "") + "/chat/completions";
// 3.RAG 核心增强逻辑开始
// 获取前端传来的命名空间 (需要在 ChatRequest DTO 中添加 namespace 字段)
List<ChatRequest.MessageDTO> messagesToSent = new ArrayList<>();
// 如果前端传了 namespace,执行检索
if (request.getNamespace() != null && !request.getNamespace().trim().isEmpty()) {
// 获取最后一条用户消息作为问题(因为 RAG 服务目前是单轮问答逻辑)
// 如果你的 RagService.chat 支持历史消息,这里需要调整
String lastUserQuestion = "";
if (request.getMessages() != null && !request.getMessages().isEmpty()) {
// 简单取最后一条,或者你可以把所有 history 拼起来
lastUserQuestion = request.getMessages().get(request.getMessages().size() - 1).getContent();
} else {
lastUserQuestion = "你好"; // 防御性编程
}
// 调用 RagService 进行检索 (注意:这里同步调用会阻塞流,但为了简单实现先这样)
// 建议:RagService.chat 方法最好拆分为 retrieve 和 generate,或者只复用其中的检索逻辑
// 这里为了演示,我们假设直接获取 Context
String context = ragService.getRelevantContext(request.getNamespace(), lastUserQuestion);
if (context != null && !context.isEmpty()) {
// 构造 System Prompt
String systemPrompt = "你是一个智能助手。请根据以下检索到的上下文信息回答问题:\n\n" +
"------ 上下文开始 ------\n" +
context + "\n" +
"------ 上下文结束 ------\n\n" +
"如果上下文中没有答案,请根据你的通用知识回答。";
// 将 System Prompt 放在第一位
ChatRequest.MessageDTO systemMsg = new ChatRequest.MessageDTO();
systemMsg.setRole("system");
systemMsg.setContent(systemPrompt);
messagesToSent.add(systemMsg);
}
}
//4. 将前端传来的历史消息追加到后面
if (request.getMessages() != null) {
messagesToSent.addAll(request.getMessages());
}
// 5. 构建请求体 (利用 Map 的方式,兼容后端聊天模型的请求格式)
Map<String, Object> body = new HashMap<>();
body.put("model", config.getChatModel());
// 将系统消息和历史消息合并成最终发送到对端的 messages
List<ChatRequest.MessageDTO> messagesBody = new ArrayList<>();
if (messagesToSent != null && !messagesToSent.isEmpty()) {
messagesBody.addAll(messagesToSent);
}
if (request.getMessages() != null && !request.getMessages().isEmpty()) {
messagesBody.addAll(request.getMessages());
}
body.put("messages", messagesBody); // 发送给外部 AI 的消息序列
body.put("stream", true); // 开启流式,这样前端才能一个字一个字蹦出来
// 6. 构建请求头
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.set("Authorization", "Bearer " + config.getApiKey());
// 7. 构建请求实体
HttpEntity<Map<String, Object>> entity = new HttpEntity<>(body, headers);
// 8. 流式转发核心逻辑
StreamingResponseBody stream = out -> {
restTemplate.execute(url, HttpMethod.POST, clientHttpRequest -> {
// --- 1. 复制请求头 ---
// 直接从 entity 中获取,不再手动 set
clientHttpRequest.getHeaders().putAll(entity.getHeaders());
// --- 2. 写入请求体 ---
// 修复报错的关键:遍历转换器,找到支持 Map 类型的那个 (通常是 Jackson)
for (var converter : restTemplate.getMessageConverters()) {
if (converter.canWrite(Map.class, MediaType.APPLICATION_JSON)) {
// 这里的泛型问题通过传入 Map.class 解决
((HttpMessageConverter<Object>) converter).write(entity.getBody(), MediaType.APPLICATION_JSON, clientHttpRequest);
return; // 写完即走
}
}
throw new IllegalStateException("No HttpMessageConverter found for Map");
}, clientHttpResponse -> {
// --- 3. 处理响应流 (保持不变) ---
if (clientHttpResponse.getBody() != null) {
InputStream inputStream = clientHttpResponse.getBody();
byte[] buffer = new byte[4096]; // 稍微调大一点缓冲区
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
out.write(buffer, 0, bytesRead);
out.flush();
}
}
return null;
});
};
// 9. 返回响应 (注意设置 Content-Type 为 text/event-stream)
HttpHeaders responseHeaders = new HttpHeaders();
responseHeaders.setContentType(MediaType.TEXT_EVENT_STREAM); // SSE 标准类型
responseHeaders.setCacheControl("no-cache");
return new ResponseEntity<>(stream, responseHeaders, HttpStatus.OK);
}
}这段代码主要逻辑如下:
- 获取AI配置
- 构建 URL,准备与远程大模型链接
- 获取知识库中关联片段,这部分是RAG增强的核心逻辑
- 信息拼接,将前端传来的历史消息追加到后面
- 构建请求体 (利用 Map 的方式,兼容后端聊天模型的请求格式),开始流式,使前端字体一个个蹦出来,增强效果
- 根据APIKey构建请求头
- 构建请求体
- 流式转发
- 返回响应
至此,后端的功能全部完成了。
(五)前端实现(Vue3 + TS)
前端主要负责与用户交互,并将请求发送给后端。
5.1 安装依赖
需要的依赖 markdown-it ,实现AI对话的格式展示。pinia 缓存数据。element-plus 绘制界面
plain
npm install markdown-it pinia element-plus5.2 实现API调用
创建一个 api/rag.ts 文件,封装与后端的通信。
rag类型文件:
typescript
/**
* 聊天请求
*/
export interface ChatRequest {
// 命名空间
namespace: string;
// 问题
question: string;
}
/**
* 索引请求
*/
export interface IngestRequest {
// 命名空间
namespace: string;
// 文件
file: File;
}
/**
* 响应
*/
export interface ApiResponse<T> {
// 状态码
code: number;
// 状态消息
msg: string;
// 数据
data: T;
}rag接口文件,主要有上传文件接口 /rag/ingest-file、获取命名空间接口 /rag/namespaces、删除命名空间接口 /rag/clear-namespace
typescript
import {request} from "@/utils/axios";
import { ApiResponse } from '@/api/ai/types/rag.ts';
const USER_BASE_URL = "/api";
export const ragApi = {
// 索引文件
ingestFile:(data:FormData)=>{
return request<ApiResponse<void>>(`${USER_BASE_URL}/rag/ingest-file`,{
method:'post',
data,
headers: {
'Content-Type': 'multipart/form-data',
},
})
},
//获取命名空间列表
getNamespaces:()=>{
return request(`${USER_BASE_URL}/rag/namespaces`,{
method:'GET'
}) as Promise<string[]>
},
//清空命名空间
clearNamespace:(namespace:string)=>{
return request<ApiResponse<void>>(`${USER_BASE_URL}/rag/clear-namespace/${namespace}`,{
method:'POST'
})
}
}chat接口文件,有AI对话接口 /chat/aiModel
typescript
const USER_BASE_URL = "/api";
export interface ChatMessage {
role: 'user' | 'assistant' | 'system';
content: string;
}
export async function streamChat(
messages: ChatMessage[],
onChunk: (text: string) => void,
onDone: () => void,
onError: (e: Error) => void,
namespace?: string, //命名空间参数
) {
try {
const response = await fetch(`${USER_BASE_URL}/chat/aiModel`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
messages: messages,
namespace: namespace, //命名空间参数
stream: true
})
});
if (!response.ok) {
const errorData = await response.json();
throw new Error(errorData.error?.message || 'API 请求失败');
}
if (!response.body) {
throw new Error('响应体为空,无法读取流');
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = ''; // 用于处理粘包或半包问题
while (true) {
const { done, value } = await reader.read();
if (done) {
onDone();
break;
}
// 将新读取的数据追加到缓冲区
buffer += decoder.decode(value, { stream: true });
// 按行分割
const lines = buffer.split('\n');
// 保留最后一行(可能是不完整的),留待下次循环处理
buffer = lines.pop() || '';
for (const line of lines) {
const trimmedLine = line.trim();
// 1. 确保以 data: 开头
if (trimmedLine.startsWith('data:')) {
// 2. 去掉 data: 前缀
const jsonString = trimmedLine.replace(/^data:\s*/, '');
// 3. 处理结束标记
if (jsonString === '[DONE]') {
onDone();
return;
}
try {
const parsed = JSON.parse(jsonString);
// --- 核心修复:提取路径 ---
// 截图显示 object 为 chat.completion.chunk,这是标准流式格式
// 内容通常在 delta.content 中
const content = parsed.choices?.[0]?.delta?.content;
if (content) {
onChunk(content);
}
} catch (e) {
// 忽略非 JSON 的心跳包或解析错误
console.warn('解析失败:', e, jsonString);
}
}
}
}
} catch (err) {
onError(err as Error);
}
}这是一个前端 SSE(Server-Sent Events)流式对话(Stream Chat) 的实现。它的核心作用是:向后端 AI 模型接口发起请求,并实时读取、解析服务器返回的流式数据(通常是一个字一个字往外蹦的 AI 回复),通过回调函数实时更新到前端界面上。
streamChat 函数参数作用:
messages:当前完整的对话历史。onChunk:每当接收到 AI 生成的一小段文本(增量)时触发的回调,用于实时渲染界面。onDone:对话完全结束时触发的回调。onError:发生异常时触发的回调。namespace:可选的命名空间参数,用于区分不同的业务场景或模型路由。
streamChat 函数代码解析:
流式请求
typescript
const response = await fetch(`${USER_BASE_URL}/chat/aiModel`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
messages: messages,
namespace: namespace, //命名空间参数
stream: true //流式返回
})
});代码使用fetch起一个POST请求。在请求体(body)中,除了传递对话历史和命名空间外,显式设置了 stream: true 。这个参数至关重要,它告诉后端:"请以流式的方式返回数据,不要等全部生成完再一次性返回。"
流式读取
typescript
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = ''; // 用于处理粘包或半包问题
while (true) {
const { done, value } = await reader.read();
if (done) {
onDone();
break;
}
// 将新读取的数据追加到缓冲区
buffer += decoder.decode(value, { stream: true });
// 按行分割
const lines = buffer.split('\n');
// 保留最后一行(可能是不完整的),留待下次循环处理
buffer = lines.pop() || '';
...
}- 获取读取器与解码器 :通过
response.body.getReader()获取底层的流读取器,并使用TextDecoder将二进制流(Uint8Array)实时解码为 UTF-8 字符串。 - 缓冲区(Buffer)机制 :
- 网络传输时,服务器返回的数据包可能会被拆分成多个
chunk(分块),或者多个 SSE 消息被挤在同一个chunk里。 - 代码中定义了一个
buffer变量。每次读取到新数据,先追加到buffer中。 - 然后通过
buffer.split('\n')按换行符切割。 - 关键操作 :buffer = lines.pop() || '' 。这一步把数组最后一项(很可能是一条没传完的残缺数据)重新放回
buffer,留到下一次循环拼接。这完美解决了"半包"问题。
- 网络传输时,服务器返回的数据包可能会被拆分成多个
SSE 协议解析与内容提取
SSE协议
这里需要先介绍一下SSE协议。
SSE(Server-Sent Events,服务器发送事件)就像服务器给客户端(比如你的浏览器)开了一个专属的"单向广播电台",
- 它只允许服务器源源不断地向客户端"推"数据,客户端不能通过这个通道回话(想回话得另外发普通的 HTTP 请求)。
- 它本质上还是普通的 HTTP 协议,不需要像 WebSocket 那样进行复杂的协议升级,可以轻松穿透公司的防火墙和代理。
- 如果网络波动导致广播中断了,浏览器会自动尝试重新连接服务器,甚至能告诉服务器"我上次听到哪了",接着往下听,非常省心。
大模型中使用的就是这种服务,比如 ChatGPT 回答你问题时,文字是一个字一个字"蹦"出来的,这就是服务器通过 SSE 把生成的文字一段段推送到你屏幕上。
一个完整的 SSE 协议格式主要由HTTP 响应头 和消息体格式两部分组成。下面主要介绍下消息体(事件流)格式。
| 字段 | 说明 | 是否必填 |
|---|---|---|
| data | 消息的实际内容。如果内容很长,可以拆分成多行,每行都以 data: 开头。 | 是 |
| event | 自定义的事件类型名称。如果不指定,默认为 message。 | 否 |
| id | 消息的唯一标识符(ID)。用于断线重连时,客户端通过 Last-Event-ID 请求头告知服务端上次接收到的位置。 | 否 |
| retry | 指定连接断开后,客户端尝试重新连接的时间间隔(单位为毫秒)。 | 否 |
| :(冒号) | 以冒号开头的行会被视为注释,客户端会忽略它。常用于发送心跳包以保持连接活跃。 | 否 |
实际效果如下图,这是使用的是千问大模型的回答:
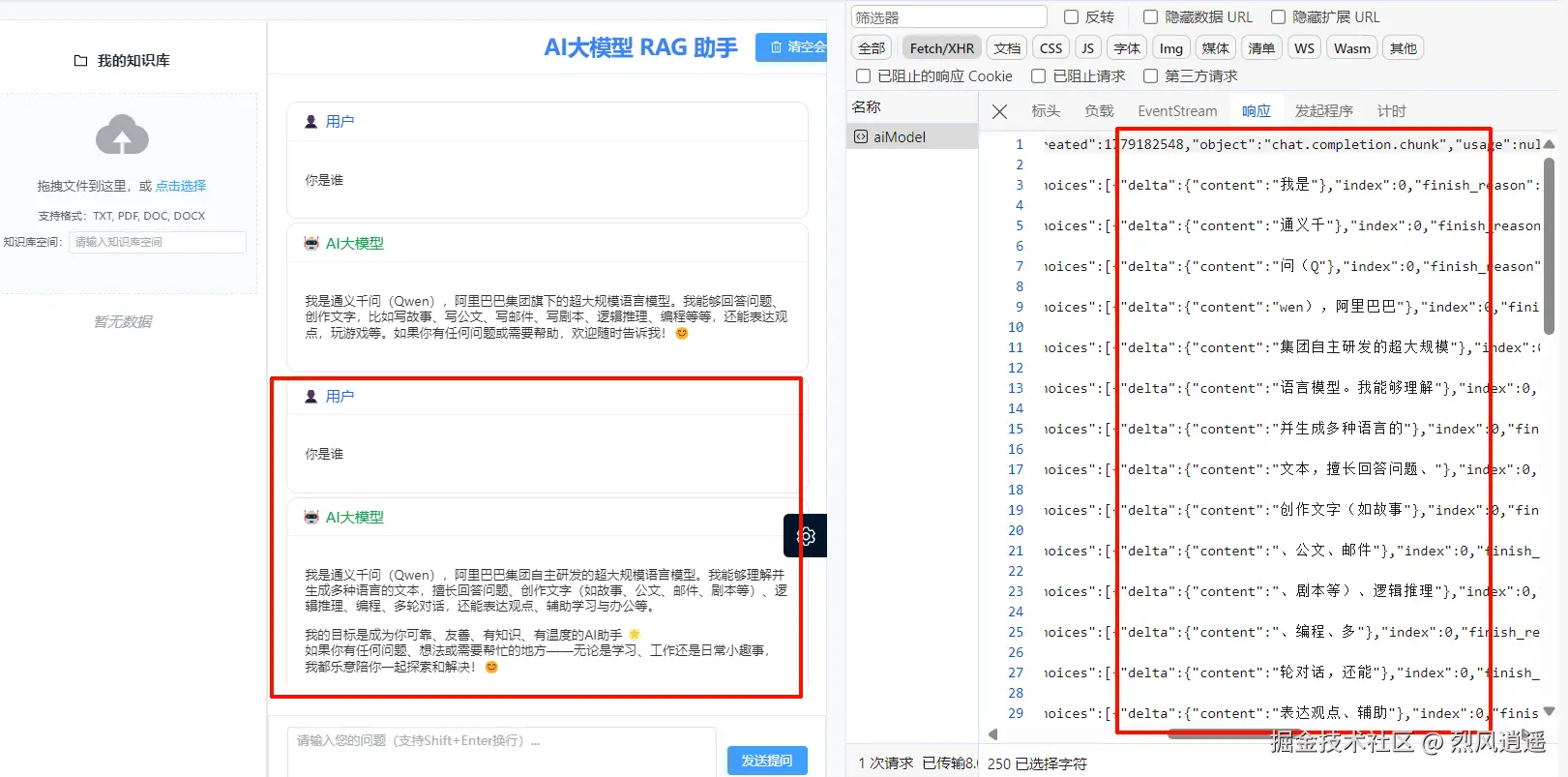
一条完整片段信息如下:
json
data: {
"model":"qwen-plus",
"id":"chatcmpl-dd3d278e-6907-9648-a6a4-fde5514c8a39",
"choices":[
{
"delta":{
"content":"wen),阿里巴巴"
},
"index":0,
"finish_reason":null,
"logprobs":null
}
],
"created":1779182548,
"object":"chat.completion.chunk",
"usage":null
}SSE 的消息体是纯文本格式,由一系列字段组成。每条消息(事件)之间通过 两个换行符 (\n\n) 来分隔
分析了消息的格式接下来需要进行解析。
内容提取
typescript
for (const line of lines) {
const trimmedLine = line.trim();
// 1. 确保以 data: 开头
if (trimmedLine.startsWith('data:')) {
// 2. 去掉 data: 前缀
const jsonString = trimmedLine.replace(/^data:\s*/, '');
// 3. 处理结束标记
if (jsonString === '[DONE]') {
onDone();
return;
}
try {
const parsed = JSON.parse(jsonString);
// --- 核心修复:提取路径 ---
// 截图显示 object 为 chat.completion.chunk,这是标准流式格式
// 内容通常在 delta.content 中
const content = parsed.choices?.[0]?.delta?.content;
if (content) {
onChunk(content);
}
} catch (e) {
// 忽略非 JSON 的心跳包或解析错误
console.warn('解析失败:', e, jsonString);
}
}
}在遍历每一行完整的字符串时,代码遵循了标准的 SSE 协议格式:
- 前缀校验 :判断行是否以
data:开头。 - 提取 JSON :去掉
data:前缀,得到纯 JSON 字符串。 - 结束判断 :如果内容是
[DONE],说明 AI 已经说完所有话,调用onDone()并结束。 - 核心修复与提取 :
- 代码尝试
JSON.parse解析字符串。 - 路径提取 :
parsed.choices?.[0]?.delta?.content。这是目前主流大模型(如 OpenAI、DeepSeek 等)流式接口的标准返回结构。delta代表"增量",content就是 AI 这一次吐出来的几个字或标点。 - 如果提取到了
content,就立刻调用onChunk(content),前端界面就能实现"打字机"一样的逐字显示效果。
- 代码尝试
5.3 构建用户界面
用户界面主要拆分为两个组件:
- KnowledgeBase.vue : 侧边栏,包含文件上传 (
el-upload) 和知识库列表。 - ChatInterface.vue : 主区域,包含消息列表 (
el-card)、输入框 (el-input) 和发送按钮。
核心逻辑如下:
- 文件上传 :监听
el-upload的on-change事件,调用ragApi.ingestFile。 - 消息发送 :用户在输入框输入问题后,点击发送,调用
ragApi.chat,并将返回的答案和用户的提问一起渲染到消息列表中。 - Markdown 渲染 :使用
markdown-it将 LLM 返回的 Markdown 格式文本渲染为 HTML。
vue
<template>
<div class="h-full flex flex-col border-[#e8e8e8] border-solid border-1 gap-10 p-x-10 p-y-20 box-border">
<div class="h-[50px] flex items-center justify-center gap-10">
<el-icon ><Folder /></el-icon>
<span class="font-bold text-gray-800">我的知识库</span>
</div>
<!-- 文件上传卡片 -->
<div class="h-[220px] mb-6 border-dashed border-2 border-blue-100 bg-blue-50/30">
<!-- Element Plus 上传组件 -->
<el-upload
ref="uploadRef"
class="upload-wrapper"
drag
:auto-upload="false"
:on-change="onFileChange"
:limit="1"
:on-exceed="handleExceed"
accept=".txt,.pdf,.doc,.docx"
:disabled="uploading"
>
<el-icon class="el-icon--upload text-blue-500"><upload-filled /></el-icon>
<div class="el-upload__text">
拖拽文件到这里,或 <em>点击选择</em>
</div>
<template #tip>
<div class="el-upload__tip text-center">
支持格式:TXT, PDF, DOC, DOCX
</div>
</template>
</el-upload>
<!-- 命名空间选择 -->
<div class="mt-4 flex items-center p-r-10">
<el-text size="small" class="mr-2 w-[130px] text-right">知识库空间:</el-text>
<el-input
v-model="currentNamespace"
placeholder="请输入知识库空间"
size="small"
@keyup.enter="handleSend"
/>
</div>
</div>
<!-- 知识库列表 -->
<el-scrollbar class="flex-1 min-h-0">
<div class="p-1"> <!-- 包裹层防止 tag 贴边 -->
<div v-if="namespaceList.length === 0" class="text-gray-400 italic text-center mt-4">
暂无数据
</div>
<el-tag
v-for="ns in namespaceList"
:key="ns"
class="m-1 cursor-pointer hover:scale-105 transition-transform"
:type="ns === currentNamespace ? 'primary' : 'info'"
:effect="ns === currentNamespace ? 'dark' : 'plain'"
@click="selectNamespace(ns)"
>
{{ ns }}
</el-tag>
</div>
</el-scrollbar>
</div>
</template>
<script setup lang="ts">
import {Folder, UploadFilled } from '@element-plus/icons-vue'
import { ElMessage, ElMessageBox, ElScrollbar, UploadInstance, UploadProps } from 'element-plus'
import { useChatStore } from '@/store/modules/chat'
import { ragApi } from '@/api/ai/rag'
import emitter from '@/utils/bus';
const uploadRef = ref<UploadInstance>()
const store = useChatStore()
const currentNamespace = ref('') // 默认命名空间
const namespaceList = ref<string[]>([]) // Mock数据
const uploading = ref(false) // 新增:上传状态
// --- 文件上传逻辑 ---
// 文件改变时的钩子
const onFileChange: UploadProps['onChange'] = async (file) => {
// 1. 校验命名空间
if (!currentNamespace.value.trim()) {
ElMessage.warning('请先输入或选择"知识库空间"')
uploadRef.value?.clearFiles() // 清空文件选择
return
}
// 2. 校验文件对象是否存在
if (!file.raw) {
ElMessage.error('文件读取失败,请重新选择')
return
}
uploading.value = true // 开始上传
const formData = new FormData()
formData.append('file', file.raw!)
formData.append('namespace', currentNamespace.value)
try {
// 这里假设你有一个专门的 upload API
await ragApi.ingestFile(formData);
ElMessage.success(`《${file.name}》上传成功!`)
store.addMessage({
role: 'assistant',
content: `✅ **文件入库成功**\n\n文件名:${file.name}\n空间:${currentNamespace.value}\n\n您可以开始提问了。`
})
uploadRef.value?.clearFiles() // 清空选择
//加载知识库列表
fetchNamespaces()
} catch (err: any) {
ElMessage.error(`上传失败: ${err.message}`)
}finally {
uploading.value = false // 无论成功失败,结束上传状态
}
}
// 处理文件超出限制
const handleExceed: UploadProps['onExceed'] = () => {
ElMessageBox.alert('只允许同时上传一个文件,请先删除再上传新文件。', '警告', { type: 'warning' })
}
const handleSend = async () => {
//发送到主页面
}
// 1. 获取知识库列表
const fetchNamespaces = async () => {
namespaceList.value = await ragApi.getNamespaces();
};
// 2. 切换命名空间
const selectNamespace = (ns: string) => {
currentNamespace.value = ns
ElMessage.info(`切换到空间: ${ns}`)
}
// 监听命名空间变化
watch(() => currentNamespace.value, (newVal) => {
emitter.emit('update-namespace', newVal)
})
// 初始化时获取知识库列表
onMounted(() => {
fetchNamespaces()
})
</script>
<style lang="scss" scoped>
/* 修复 Element Plus 上传组件在 Card 中的一些边距问题 */
:deep(.el-upload-dragger) {
background-color: transparent;
border: none;
box-shadow: none;
width: 100%;
padding: 10px 0;
}
</style>
vue
<template>
<div class="flex flex-col gap-10 h-full border-[#e8e8e8] border-solid border-1 relative">
<!-- 聊天头部 -->
<el-header class="!h-[60px] flex items-center justify-center gap-20 flex-shrink-0">
<h2 class="font-bold text-blue-500">AI大模型 RAG 助手</h2>
<el-button type="primary" @click="handleClear" :icon="Delete">清空会话</el-button>
</el-header>
<!-- 消息列表 -->
<el-main class="flex-1 overflow-y-auto p-6 scroll-smooth ">
<el-scrollbar ref="scrollbarRef" class="h-full">
<div class="space-y-4">
<!-- 消息项 -->
<div
v-for="(msg, index) in store.messages"
:key="index"
class="message-item"
>
<el-card
:class="msg.role === 'user' ? 'bg-blue-50 border-blue-100' : 'bg-white border-gray-100'"
shadow="never"
>
<template #header>
<span class="font-medium" :class="msg.role === 'user' ? 'text-blue-600' : 'text-green-600'">
{{ msg.role === 'user' ? '👤 用户' : '🤖 AI大模型' }}
</span>
</template>
<div class="markdown-body" v-html="renderMarkdown(msg.content)"></div>
</el-card>
</div>
<!-- 加载状态 -->
<el-card v-if="store.loading" class="bg-gray-50 border-gray-100" shadow="never">
<div class="flex items-center text-gray-500">
<el-icon class="mr-2" :animation="true"><Loading /></el-icon>
正在检索知识库并思考...
</div>
</el-card>
</div>
</el-scrollbar>
</el-main>
<!-- 输入区域 -->
<el-footer class="bg-white !h-[100px] border-[#e8e8e8] border-solid border-1 p-4 flex items-center">
<div class="w-full flex justify-between items-center">
<el-input
v-model="inputText"
class="flex-1"
type="textarea"
:rows="3"
placeholder="请输入您的问题(支持Shift+Enter换行)..."
@keyup.enter="handleEnter"
:disabled="store.loading"
resize="none"
/>
<div class="w-[100px] flex justify-end mt-2">
<el-button
type="primary"
:loading="store.loading"
@click="handleSend"
size="default"
>
{{ store.loading ? '生成中...' : '发送提问' }}
</el-button>
</div>
</div>
</el-footer>
</div>
</template>
<script setup lang="ts">
import { Delete } from '@element-plus/icons-vue'
import { useChatStore } from '@/store/modules/chat'
import { streamChat } from '@/api/ai/index.ts'
// @ts-ignore // 忽略类型检查,解决缺少声明文件的问题
import MarkdownIt from 'markdown-it'
import emitter from '@/utils/bus';
const namespace = ref('');
// 初始化 Markdown 解析器
const md = new MarkdownIt({
html: true,
linkify: true,
typographer: true
})
const store = useChatStore()
const inputText = ref('')
const messageContainer = ref<HTMLElement | null>(null);
//渲染 Markdown
const renderMarkdown = (text:string) =>{
return md.render(text);
}
//自动滚动到底部
const scrollToBottom = ()=>{
nextTick(()=>{
if(messageContainer.value){
messageContainer.value.scrollTop = messageContainer.value.scrollHeight;
}
})
}
// 监听消息列表变化,自动滚动
watch(() => store.messages.length, scrollToBottom);
//处理回车发送
const handleEnter = (e: KeyboardEvent)=>{
if (!e.shiftKey) {
handleSend()
}
}
// 发送消息核心逻辑
const handleSend = async ()=>{
const text = inputText.value.trim();
if(!text || store.loading) return;
//添加用户消息
store.addMessage({role:"user",content:text});
inputText.value = "";
store.loading = true;
//预设一个空的AI消息,用于接收流式数据
store.addMessage({role:"assistant",content:""});
//调用API 注意:这里发送的是除了最后一条空消息之外的所有历史
const history = store.messages.slice(0,-1);
await streamChat(
history,
// onChunk: 收到文本片段
(text)=>store.updateLastMessage(text),
// onDone: 完成
()=>{ store.loading = false},
// onError: 报错
(err)=>{
store.updateLastMessage(`\n\n[错误: ${err.message}]`)
store.loading = false
},
//传递命名空间
namespace.value,
)
}
// 清空会话
const handleClear = () => {
store.clearHistory()
ElMessageBox.confirm('会话已清空', '提示', { type: 'info' })
}
// 设置命名空间
const setNamespace = (ns: string) => {
namespace.value = ns;
}
onMounted(() => {
// 订阅事件
emitter.on('update-namespace', setNamespace);
})
onUnmounted(() => {
// 取消订阅事件
emitter.off('update-namespace', setNamespace);
})
</script>
<style lang="scss" scoped>
// 消息气泡圆角
.message-item {
:deep(.el-card) {
border-radius: 12px;
border-width: 1px;
}
:deep(.el-card__header) {
background: transparent;
padding: 10px 16px;
border-bottom: 1px solid rgba(0,0,0,0.05);
}
}
// Markdown 样式微调
:deep(.markdown-body) {
font-size: 14px;
code {
background-color: #f1f2f4;
padding: 2px 6px;
border-radius: 4px;
font-family: 'Courier New', monospace;
}
pre {
background-color: #f6f8fa;
padding: 16px;
border-radius: 8px;
overflow: auto;
border: 1px solid #eaeaea;
}
}
</style>三、效果演示
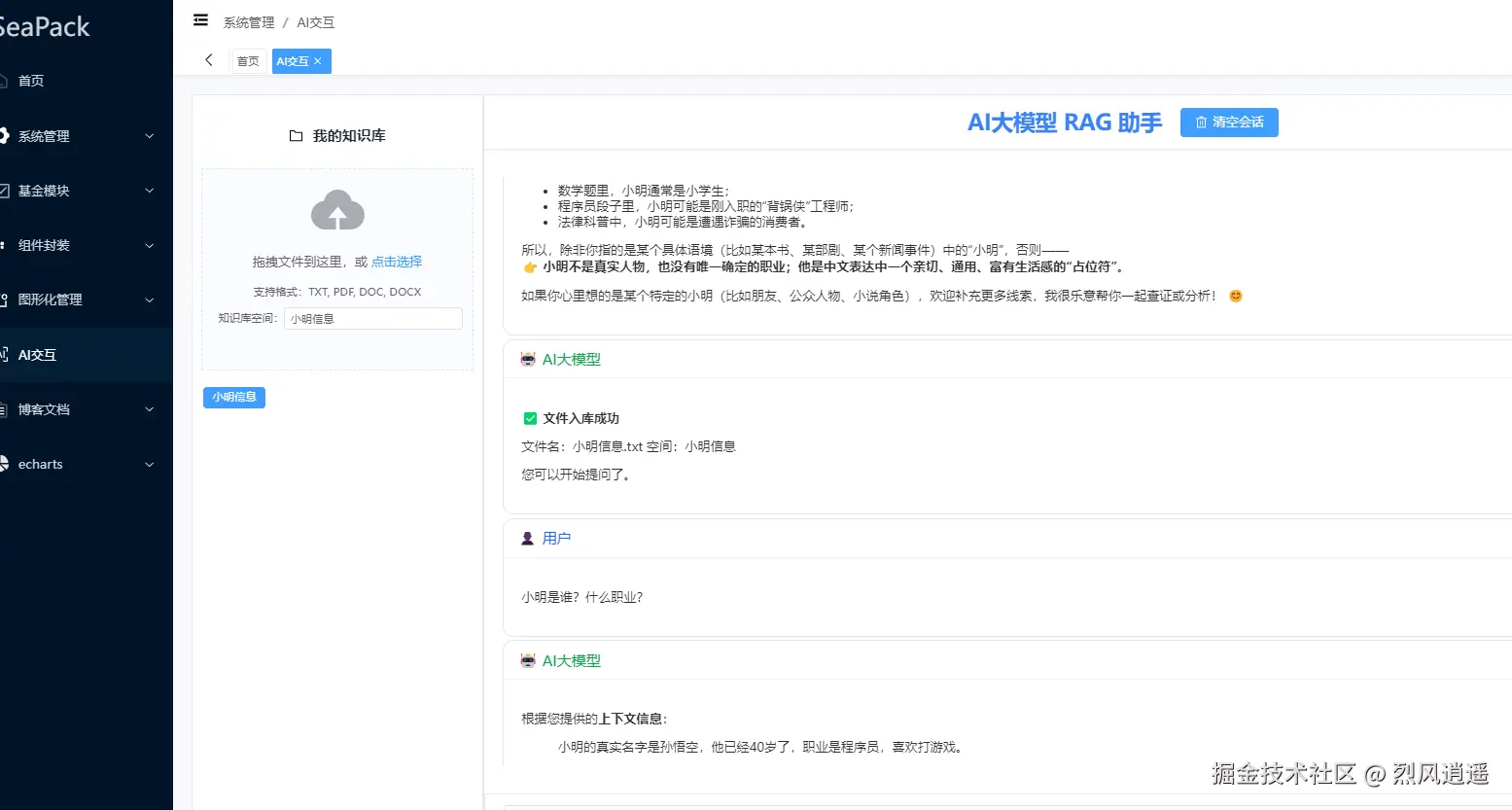
开始效果调试:
提问:小明是谁,什么职业?
大模型回答如下:
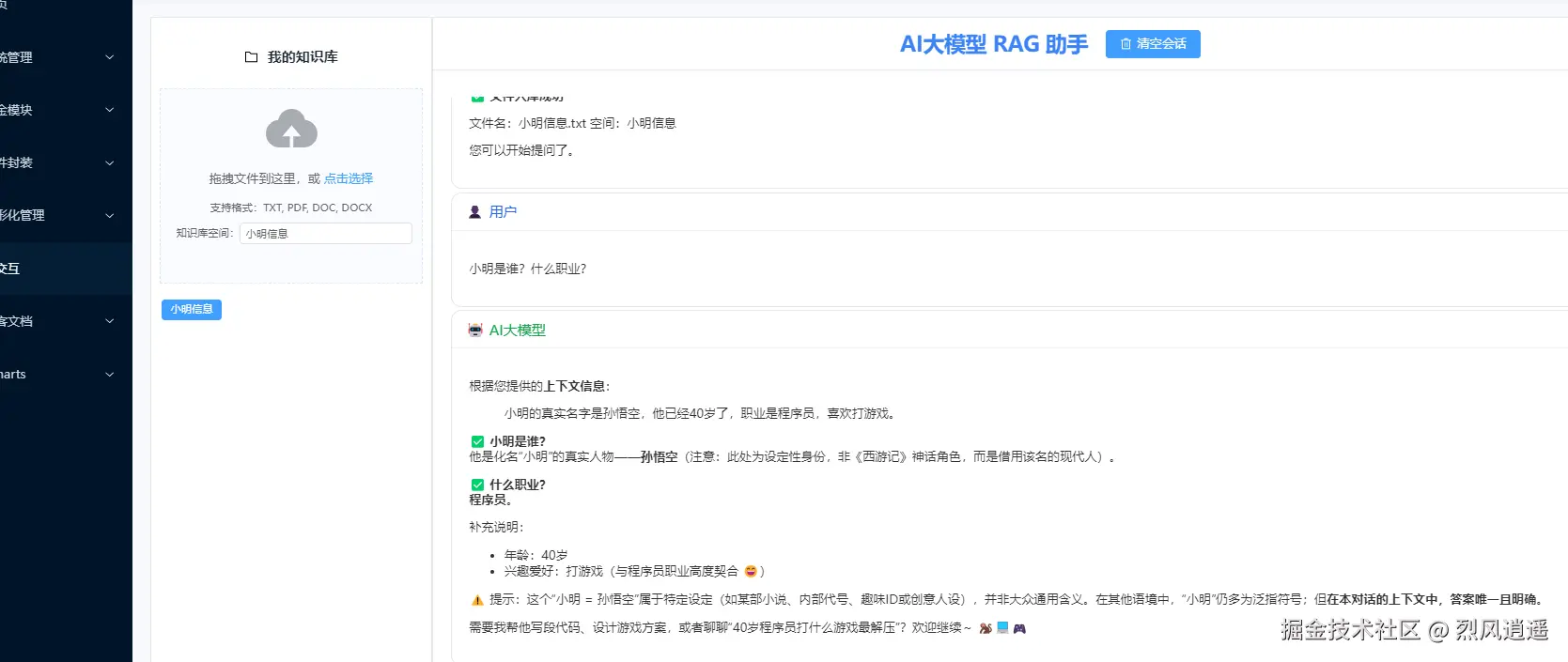
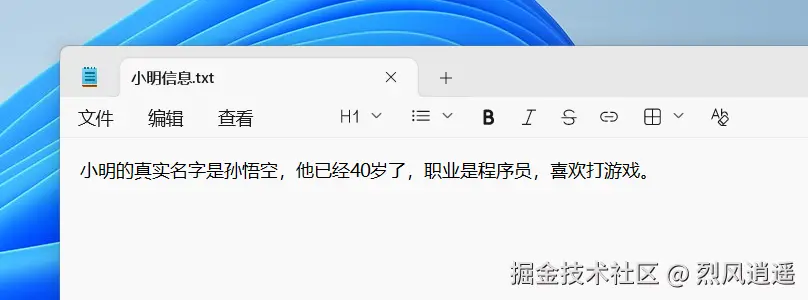
创建一个txt文件。里面输入小明的相关信息,然后再提问:
txt信息如下:
上传文件然后再次提问: