
你有没有发现,现在的 AI 越来越 "能聊" 了? 去年你跟它聊个几千字,它就开始忘东忘西,现在你把一本 100 万字的小说丢给它,它能陪你聊完整个剧情,还能精准记得第 3 章第 5 句的细节。
你有没有好奇过,它是怎么做到的? 其实 AI 跟你聊天的时候,就像一个记性不好的朋友,它得把你说过的每一句话都记成"笔记",不然转头就忘了你之前说过啥。这个"笔记",就是大模型里的 KVCache。
但是最早的时候,这个笔记大得离谱:聊 100 万字的天,要 305GB 的空间 ------ 相当于你把整个电脑的硬盘都拿来记这个聊天记录,谁顶得住?
而现在,工程师们把这个笔记,从一整个房间的文件,压缩成了一个小小的随身本,只需要 7.4GB。 这中间到底发生了什么?今天咱们就用最生活化的例子,给你讲明白大模型的"记忆压缩魔法"。
- 什么是 KVCache?AI 的"聊天笔记本"

你跟朋友吐槽老板,聊了 3 小时,从项目截止日期说到上周的团建,中间朋友突然问你:"我刚才说的那个客户的需求,你觉得能改吗?"
你要是忘了他刚才说过啥,这天就聊不下去了,对吧? AI 也是一样的。它跟你聊天的时候,每说一句话,都得回头看看你之前说过的所有内容,才能接上话。所以它必须把你说过的每一个字的"笔记"都存起来,这个笔记就是 KVCache。
但是问题来了:你聊得越久,这个笔记就越厚。 最早的大模型,这个笔记的大小是跟着聊天长度线性增的 ------ 你多聊一个字,笔记就多一页。聊到 100 万字的时候,这个笔记直接厚到 305GB,比很多人整个电脑的内存都大。
这谁顶得住啊?所以工程师们就开始想办法:怎么把这个笔记做小一点,还不丢内容?
- 第一步:给笔记 "共享储物柜",一人一个不如分组共用

最早的 AI,记笔记的方式特别 "浪费": 比如你跟它聊工作、聊生活、聊八卦,每个话题它都单独给你准备一个储物柜,每个柜子里放你的笔记,这就是最早的 MHA 架构。80 个话题就 80 个柜子,空间直接占满了。
后来有人想:大家共用一个柜子不行吗? 所有人的话题都用同一个柜子放笔记,这就是 MQA。这下空间直接省了好多,但是问题来了:所有人的东西都塞在一个柜子,有时候会记混,找东西的时候容易拿错,AI 的回答质量就下降了。
那有没有折中办法? 有啊!几个人一组,一组共用一个柜子!比如 8 个人一组,这 8 个人的东西放一个柜子,另一组的放另一个,这就是现在最常用的 GQA。
既不会像所有人共用一个那样乱,又比一人一个省了 7/8 的空间,完美! 就像咱们公司的储物柜,原来每个人一个,后来改成 8 个人一组共用,一下子就多出了好多空柜子,能放更多东西了。
- 第二步:把笔记的字写小一点,内容一点儿没少

共享柜子还是不够,那能不能把笔记本做小一点? 原来的笔记本,字写得特别大,一页纸写不了几个字,空了好多地方。那我把字写得紧凑一点,内容一点不丢,本子不就小了吗?
这就是 DeepSeek 搞出来的 MLA 架构。 原来的每一页笔记,要 14336 个格子来写,现在它把这些字压缩了一下,只需要 576 个格子就够了 ------ 直接压缩了 96%!
而且神奇的是,因为字写得紧凑,反而帮 AI 把笔记整理了一遍,那些没用的冗余信息都去掉了,AI 的回答质量反而更好了。 就像你上学的时候,别人的笔记写得松松散散,一本笔记只记了一章的内容,你把字写得紧凑,一本笔记能记完一整本书的重点,内容一点没少,本子直接小了一圈。
- 第三步:没用的废话,直接删掉!

你有没有发现,你跟朋友聊天的时候,好多话其实根本没用? 比如 "嗯""哦""哈哈""笑死我了""对对对",这些话其实根本不影响你理解对方的意思,完全可以删掉。
AI 也是一样的!原来的 AI 傻呵呵的,把所有话都记下来,不管有用没用。现在它学会挑重点了:
-
最近的 128 句话,都是刚说的,很重要,完整记下来,一点不丢;
-
之前的话,挑最重要的那些记,没用的废话直接删掉!
这就是稀疏注意力,比如最新的 DeepSeek V4,就是这么干的。 它把 100 万个 token,先把最近的 128 个完整保留,然后之前的,先按块压缩,再挑最相关的那些保留,没用的直接扔了。这样一来,计算的厚度直接又小了好多。
就像你整理聊天记录,把那些没用的废话都删掉,只留下重点的内容,一下子聊天记录就从几百页变成了几十页,找重点的时候还更快了。
- 第四步:不管聊多久,都总结成一页摘要

上面的方法,还是要记一些笔记,你聊得越久,笔记还是会慢慢变多,只是涨得慢了点。 有没有办法,不管你聊多久,笔记的大小永远不变?
有!就是把所有的聊天内容,都总结成一页摘要! 不管你聊了 100 字,还是 100 万字,这个摘要永远只有一页,大小永远不变。
这就是线性注意力,比如 Mamba、DeltaNet 这些新架构。 它们不再把每一句话都记下来,而是边聊边把内容压缩到一个固定大小的"摘要"里,每次要接话的时候,就看这个摘要就行。
这样一来,不管你聊多久,这个摘要的大小永远是固定的,彻底解决了越聊越占空间的问题。 就像你看完一本几百页的书,最后只写一页读书笔记,不管书多厚,你的笔记永远只有一页,拿在手里一点儿不占地方。
- 还有这些小技巧:速记、共用笔记

除了这些大改动,工程师们还想了好多小技巧,进一步压缩笔记的大小:
-
速记法:原来的笔记用正常的字写,每个字要 16 位,现在用速记,每个字只需要 8 位,甚至 4 位,别人看不懂但是 AI 自己能看懂,直接把空间减半再减半,这就是量化,现在已经是标配了;
-
共用笔记:相邻的几层笔记,其实内容差不多,不用每一层都单独记,直接共用一本就好了,这就是跨层共享,又能省一半的空间。
这些小技巧加起来,又能把笔记的大小压缩一大截。
- 最后:看看我们省了多少空间?
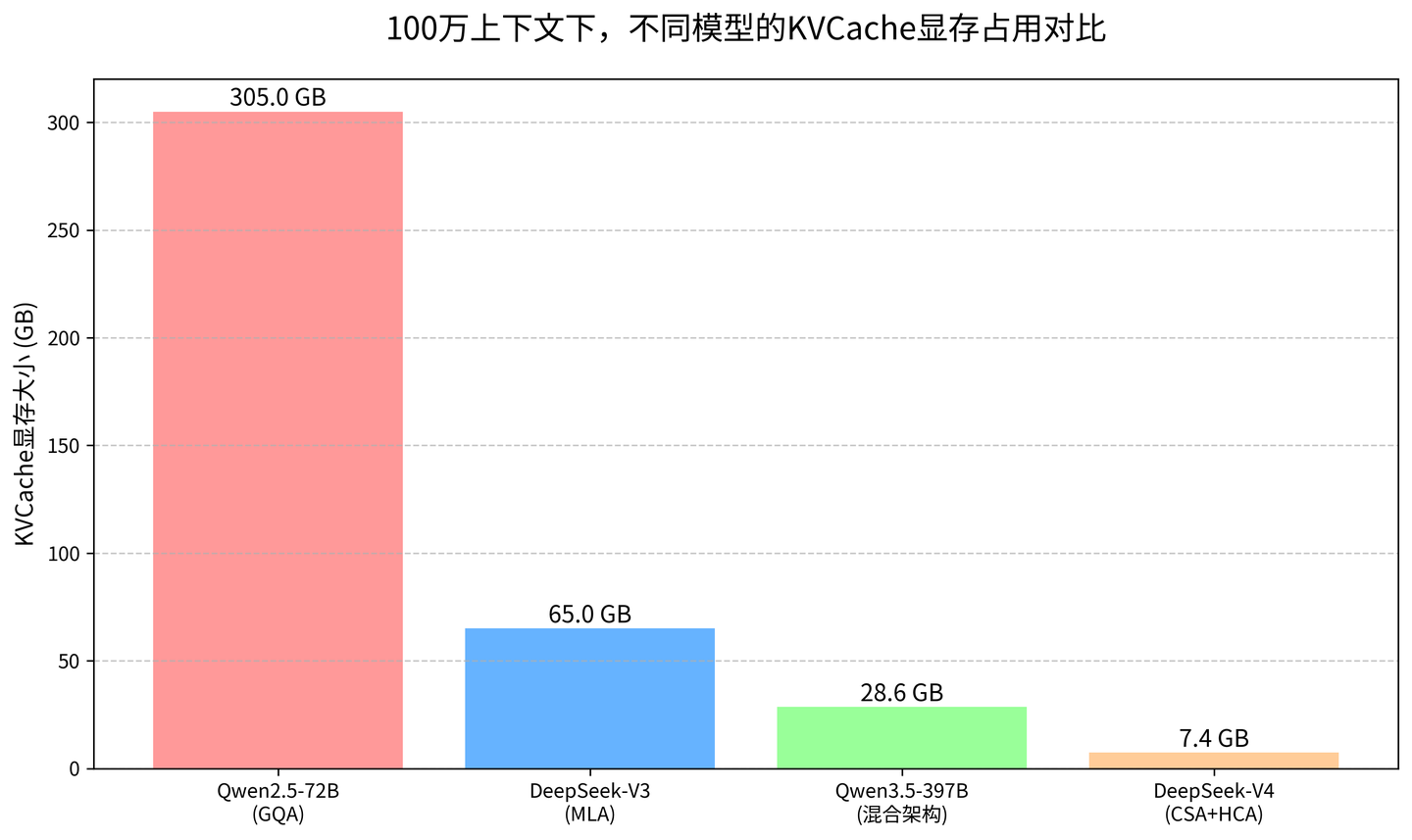
经过这么多优化,现在的笔记到底小了多少? 我们来看看同样聊 100 万字,不同模型的笔记大小:
-
最早的 Qwen2.5-72B,要 305GB,相当于你要一个 300 多 GB 的硬盘来存这个聊天;
-
后来的 DeepSeek V3,降到了 65GB,小了快 5 倍;
-
然后 Qwen3.5 的混合架构,降到了 28.6GB;
-
最新的 DeepSeek V4,只需要 7.4GB!
从 305GB 到 7.4GB,差了整整 41 倍! 原来你要一整个房间的柜子来放这些笔记,现在只需要一个小小的随身本,揣在兜里就能带走。
这意味着什么? 原来一块 GPU 只能服务几个用户,现在能服务几十个甚至上百个;原来 AI 聊到 10 万字就顶不住了,现在聊 100 万字、1000 万字都轻轻松松,还不忘记之前说过啥。
未来:AI 的记忆还能更小吗?
现在,业界有两个主流的方向: 一个是像 DeepSeek V4 那样的稀疏注意力,把笔记里的没用内容删到极致,只留重点; 另一个是像 Qwen3.5 那样的线性注意力,直接把所有内容总结成固定大小的摘要,彻底摆脱聊天长度的限制。
未来哪一个会赢?说不定是两者的融合:用线性注意力处理超长距离的全局内容,用稀疏注意力处理中近距离的重点,用滑动窗口处理最近的内容,把笔记的大小压至极致。
说不定再过两年,我们跟 AI 聊一整本书,它的笔记只需要几百 MB,跟存一张图片一样大。
💬 你有没有遇到过 AI 聊着聊着就 "失忆" 的情况?比如聊到一半它忘了你之前说过的设定,或者忘了之前的需求?你觉得未来 AI 的记忆能做到多大都不占内存吗?评论区聊聊你的经历!