1.集合体系结构
分为单列集合(Collection)和双列集合(Map)
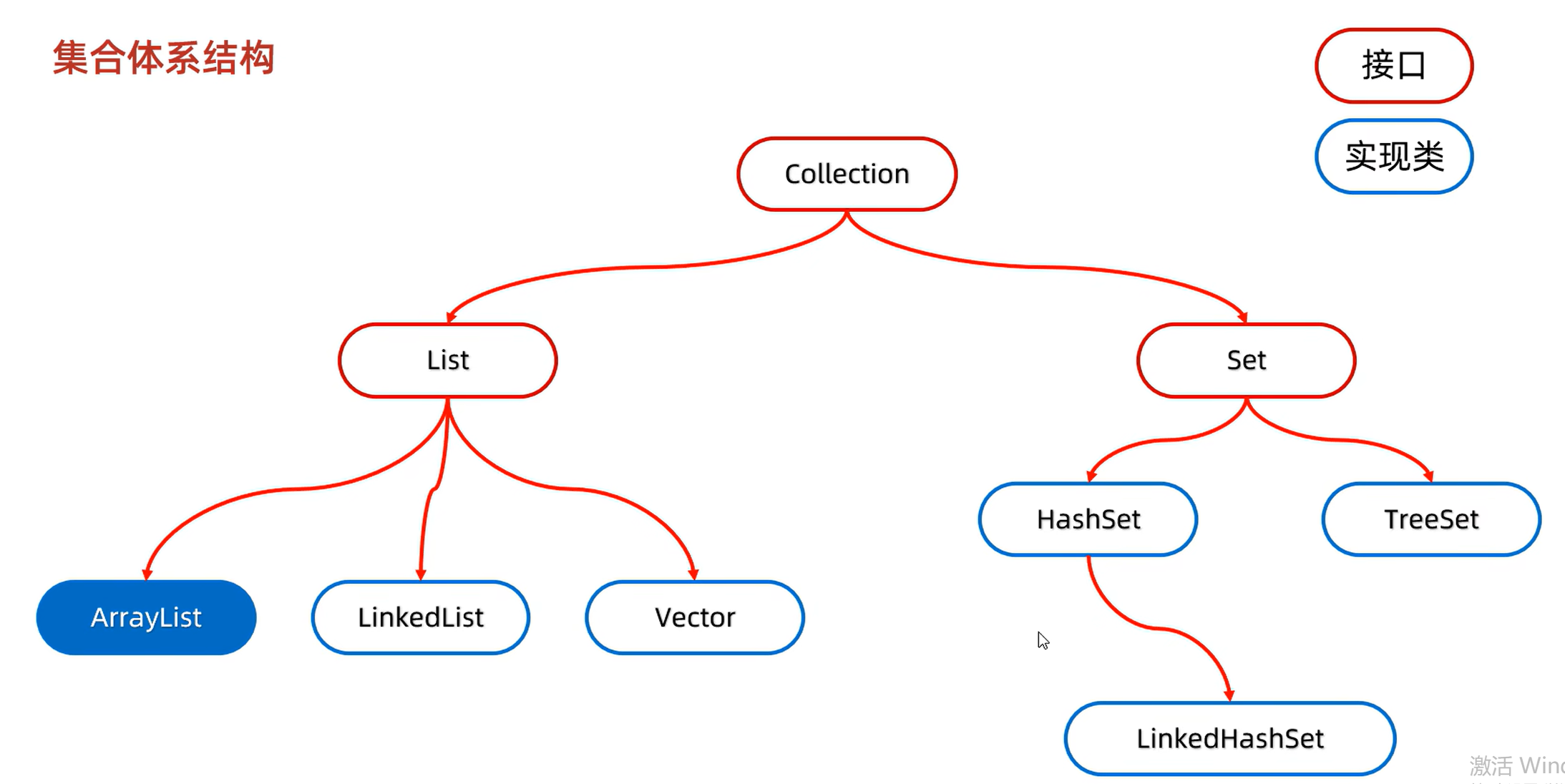
List系列集合:添加的元素是有序(存和取的顺序一样)、可重复、有索引
Set系列集合:添加的元素是无序、不重复、无索引
2.Collection
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继续使用的。Collection是一个接口,不能直接创建对象,只能创建实现类的对象,比如ArrayList。
2.1基本方法
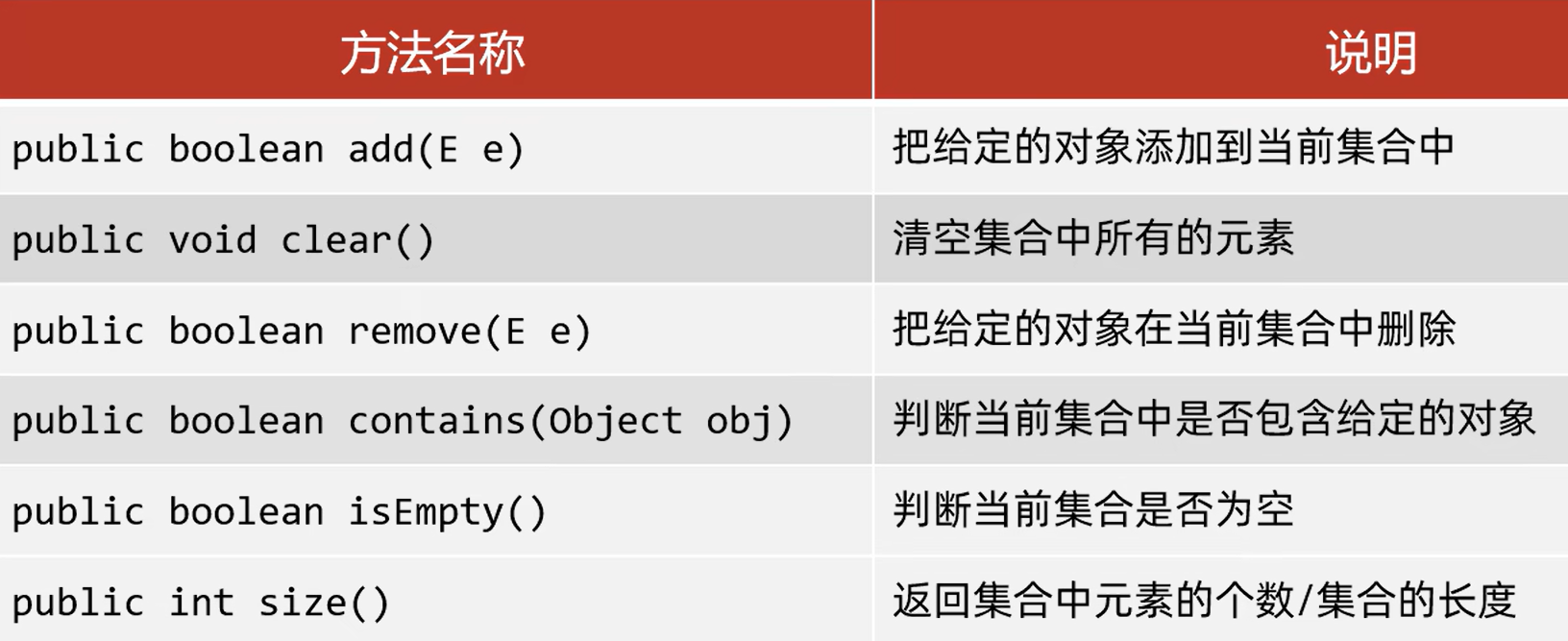
Collection里面定义的方法是共性的方法,所以不能通过索引对元素进行删除,只能通过元素的对象进行删除。
contains方法的底层是依赖equals方法进行判断是否存在的。如果集合中存储的是自定义对象,也想通过equals来判断是否包含,那在JavaBean中要重写equals方法。
2.2Collection的遍历方式:
1)迭代器遍历:
--特点:迭代器不依赖索引
--迭代器在Java中的类Iterator,迭代器是集合专用的遍历方式
--Collection集合获取迭代器:

--Iterator中常用的方法:

java
Iterator<String> it = c.iterator();//创建指针
while (it.hasNext()) {//判断是否有元素
String s = it.next();//获取元素,移动指针
System.out.println(s);
}细节:
--报错NoSuchElementException
--迭代器遍历完毕,指针不会复位
--循环中只能使用一次next方法
--迭代器遍历时,不能用集合的方法进行增加或者删除。如果实在要删除,可以使用迭代器里面的方法remove进行删除
2)增强for遍历:
底层就是迭代器,为了简化迭代器的代码书写的,是jdk5之后出现的,其内部原理就是一个iterator迭代器。
所有的单列集合和数组才可以用增强for进行遍历。
java
/**
* 基本格式
* for(元素的数据类型 变量名:数组或集合){
*
* }
* 修改增强for中的变量,不会改变集合中原本的元素
*/
for(String s:c){
System.out.println(s);
}3)Lambda表达式遍历:

java
/**
* 底层原理:自己会遍历集合,依次得到每一个元素,
* 将得到的元素交给accept方法,s表示依次得到的每一个元素
*/
c.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
//替换为lambda表达式
c.forEach(s-> System.out.println(s));3.List集合
3.1基本方法
Collection的方法List都继承了,但是List有索引
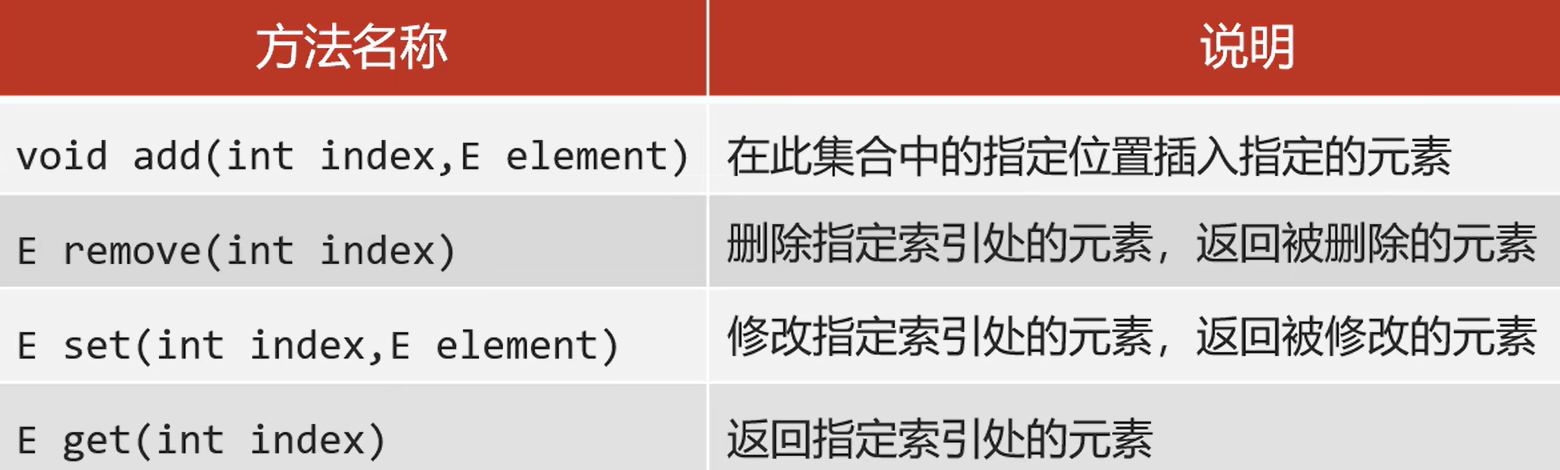
remove方法删除元素的细节:
继承了Collection的remove方法和自己的remove方法,在调用方法的时候如果方法出现重载现象,优先调用实参类型和形参类型一致的方法,如果实在要通过元素进行删除,可以手动装箱把数据编程包装类。
3.2遍历方式
1)迭代器遍历
2)列表迭代器遍历(独有的)
listIterator()迭代器,和迭代器差不多,使用方法一致,但是额外增加了一个方法,可以使用add方法添加元素
3)增强for遍历
4)Lambda表达式遍历
5)普通for循环
4.ArrayList集合
1)利用空参创建的集合,在底层创建一个默认长度为0的数组
2)添加第一个元素时,底层会创建一个新的长度为10的数组
3)存满时,会扩容1.5倍,也就是15--接着再存满时持续扩容
4)如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
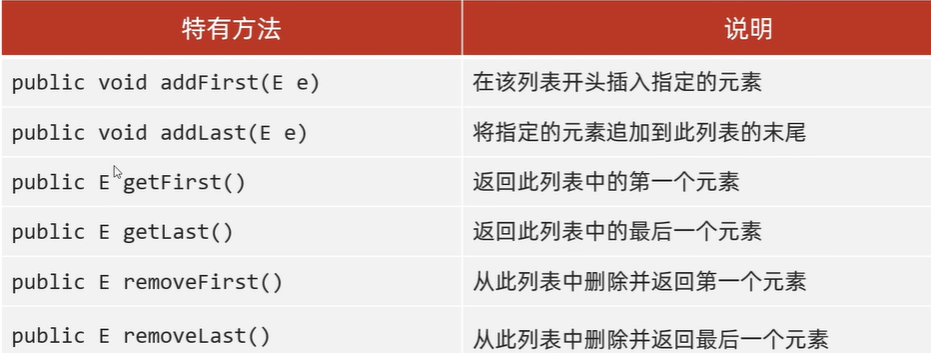
5.LinkedList集合
1)底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
2)LinkedList本身有很多直接操作首尾元素的特有API
6.泛型深入
6.1泛型基本概述
泛型:是jdk5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型格式:<数据类型>
注意:泛型只能支持引用数据类型
泛型的好处:1)统一数据类型 2)把运行时期的问题提前到了编译时间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
拓展:Java中的泛型是伪泛型
解释:编译的时候检查添加的字符串是否符合泛型,如果不是,直接编译报错,
细节:
1)泛型中不写基本数据类型
2)指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型
3)如果不写成泛型,默认类型是Object
6.2泛型的使用
泛型可以在很多地方进行定义:类后面(泛型类),方法上面(泛型方法),接口后面(泛型接口)
1)泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
格式:修饰符 class 类名<类型>{} 不确定类型时,可以把类型写成E就表示是不确定类型
此处的E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型
2)泛型方法
使用场景:方法中形参类型不确定的时候,可以使用类名后面定义的泛型(所有方法都能使用)或者在方法申明上定义自己的泛型(只有本方法可以使用)
格式:修饰符 <类型> 返回值类型 方法名(类型 变量名){}
3)泛型接口
格式:修饰符 interface 接口名<类型>{}
使用方式:1)实现类给出具体类型 2)实现类延续泛型,创建对象时再确定
6.3泛型的继承和通配符
泛型不具备继承性,但是数据具备继承性
java
public class test{
public static void main(String[] args) {
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
method(list1);
//因为泛型不具备继承性
method(list2);//报错
method(list3);//报错
//以下方式不会报错--因为数据可以继承
list1.add(new Ye());
list1.add(new Fu());
list1.add(new Zi());
}
public static void method(ArrayList<Ye> list){
}
//如果使用E泛型写的话,那任何类型的数据都可以装配进去
public static<E> void method2(ArrayList<E> list){
}
}
class Ye{}
class Fu extends Ye{}
class Zi extends Fu{}使用通配符解决以上问题:? extends E:表示可以传递E或者E所有的子类类型
? super E:表示可以传递E或者E所有的父类类型
应用场景:
1.如果在定义类、方法、接口的时候,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口
2.如果类型不确定,但是能指定以后只能传递某个继承体系中的,就可以使用泛型的通配符
7.Set集合
Set集合的特点:无序、不重复、无索引
Set接口中的方法上基本与Collection的API一致
7.1HashSet
无序、不重复、无索引
HashSet集合底层是采取哈希表存储数据。哈希表是一种对于增删改查数据性能都比较好的结构
在jdk8之前:哈希表是由数组+链表组成的
在jdk8开始:哈希表是由数组+链表+红黑树组成的
哈希值:哈希值对象整数的表现形式
哈希值是根据hashCode方法算出来的int类型的整数
该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点:
如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
hashSet的底层原理:
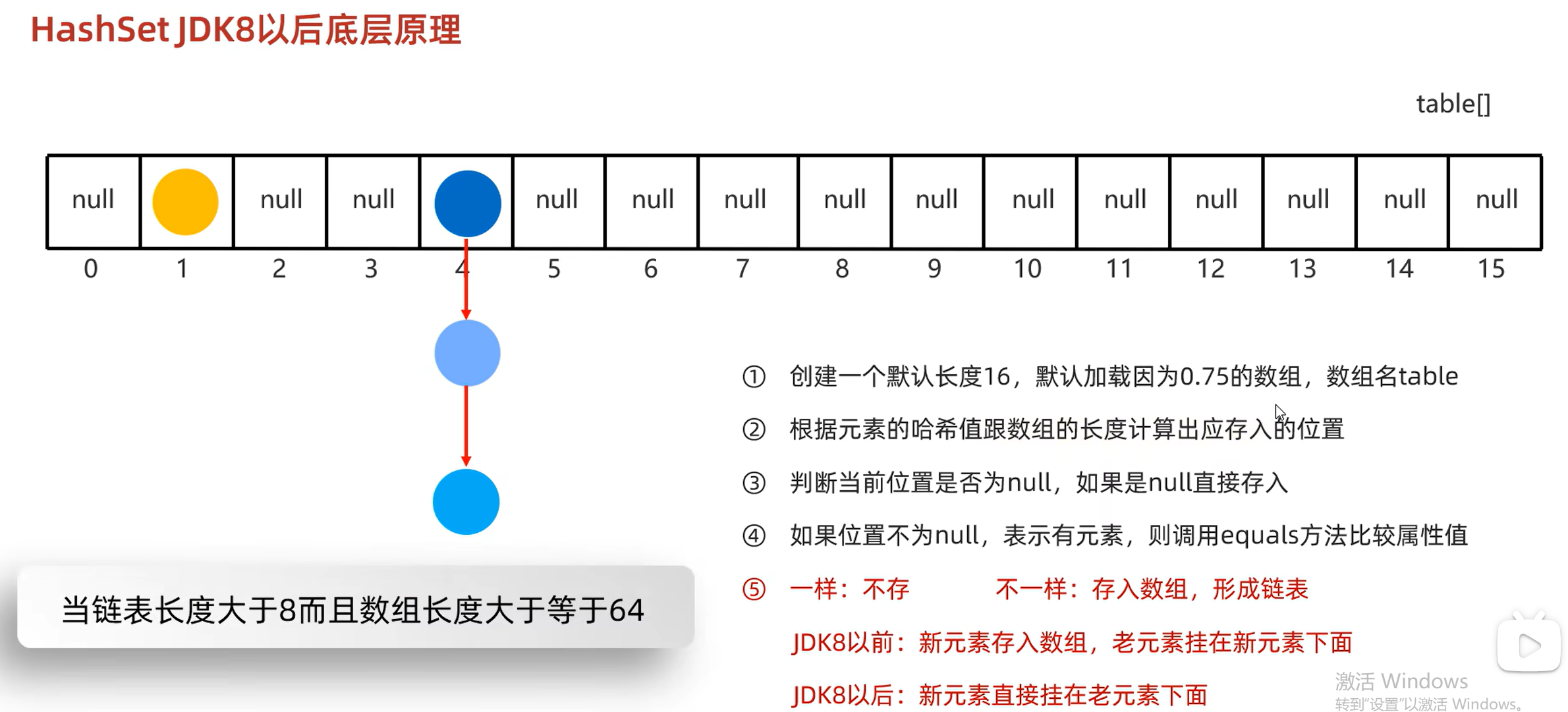
jdk8以后,当链表长度超过8且数组长度大于等于64时,自动转换为红黑树
如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
7.2LinkedHashSet
有序、不重复、无索引
底层原理:底层数据结构依然是哈希表,知识每个元素又额外的多了一个双链表的机制记录存储顺序。
7.3TreeSet
可排序、不重复、无索引
底层原理:TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都比较好
TreeSet默认的规则:
对于数值类型:Integer、double,默认找从小到大的顺序进行排序
对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序
TreeSet的两种比较方式:
方式一:默认排序/自然排序:Javabean类实现Comparable接口指定比较规则
方式二:比较器排序:创建TreeSet对象时候,传递比较器Comparable指定规则
使用规则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
8.双列集合
特点:
1)双列集合一次需要存一对数据,分别为键和值
2)键不能重复,值可以重复
3)键和值是一一对应的,每一个键只能找到自己对应的值
4)键+值这个整体称之位键值对
Map常见API:
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
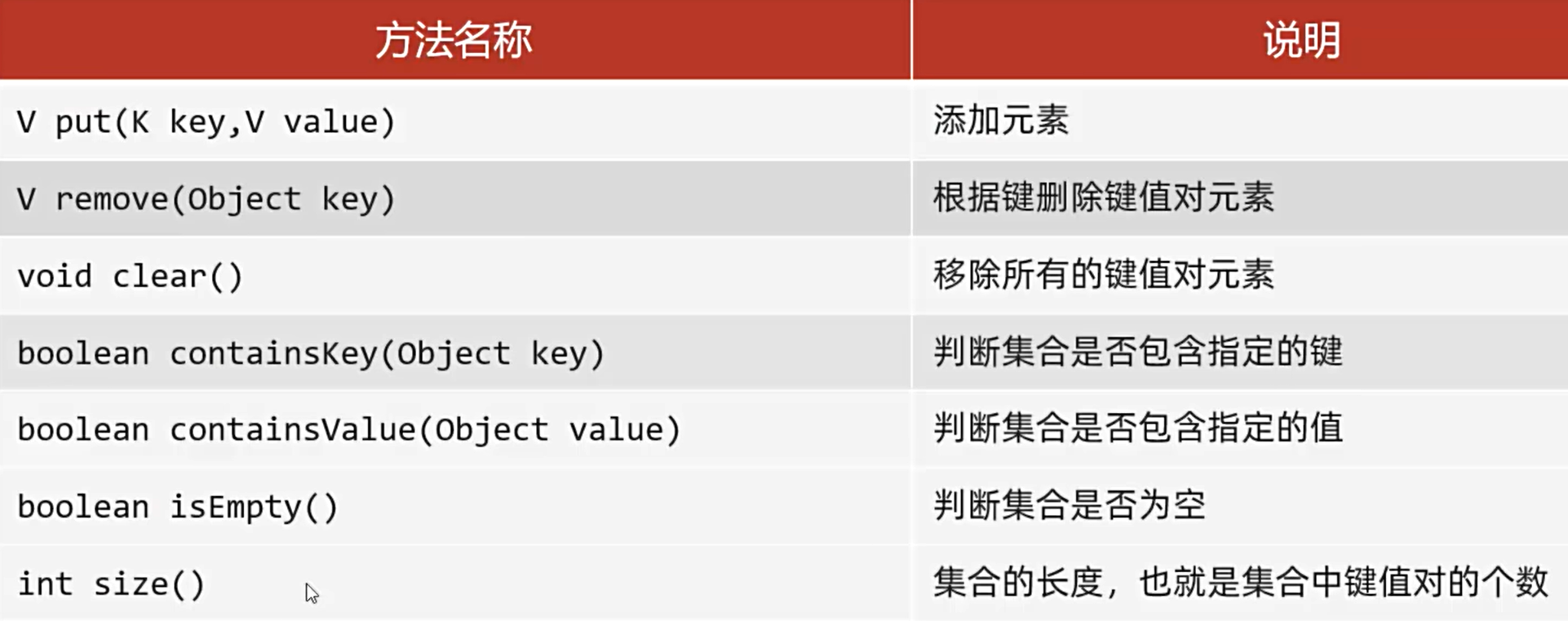
put添加元素的时候,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null。
如果键存在,那么原有的键值对对象被覆盖,会把被覆盖的值进行返回。
Map的遍历方式:
1)键找值:map.keySet();获取键集合,map.get(key);获取值
2)键值对:Set<Map.Entry<String, String>> entries = map.entrySet();获取键值对对象,String key = entry.getKey(); String value = entry.getValue();获取键和值
3)Lambda表达式

8.1HashMap
HashMap的特点:
1)HashMap是Map里面的一个实现类
2)没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
3)特点都是由键决定的:无序、不重复、无索引
4)hashMap和hashSet的底层原理是一样的,都是哈希表结构的,依赖hashCode和equals方法保证键的唯一性。如果键存储的是自定义对象,需要重写hashCode和equals方法;如果值存储的是自定义对象,不需要重写hashCode和equals方法
8.2LinkedHashMap
特点:
1)由键决定:有序(存和取的顺序一样)、不重复、无索引
2)原理:底层数据结构是哈希表,只是每个键值对元素额外多了一个双链表的机制记录存储顺序
8.3TreeMap
特点:
1)TreeMap跟TreeSet底层原理一样,都是红黑树结构的
2)由键决定特性:不重复、无索引、可 排序(对键进行排序)
3)默认按照键的从小到大进行排序,也可以自己规定键的排序规则
书写两种排序规则:
1)实现Comparable接口,指定比较规则
2)创建集合时进行传递Comparator比较器对象,指定比较规则
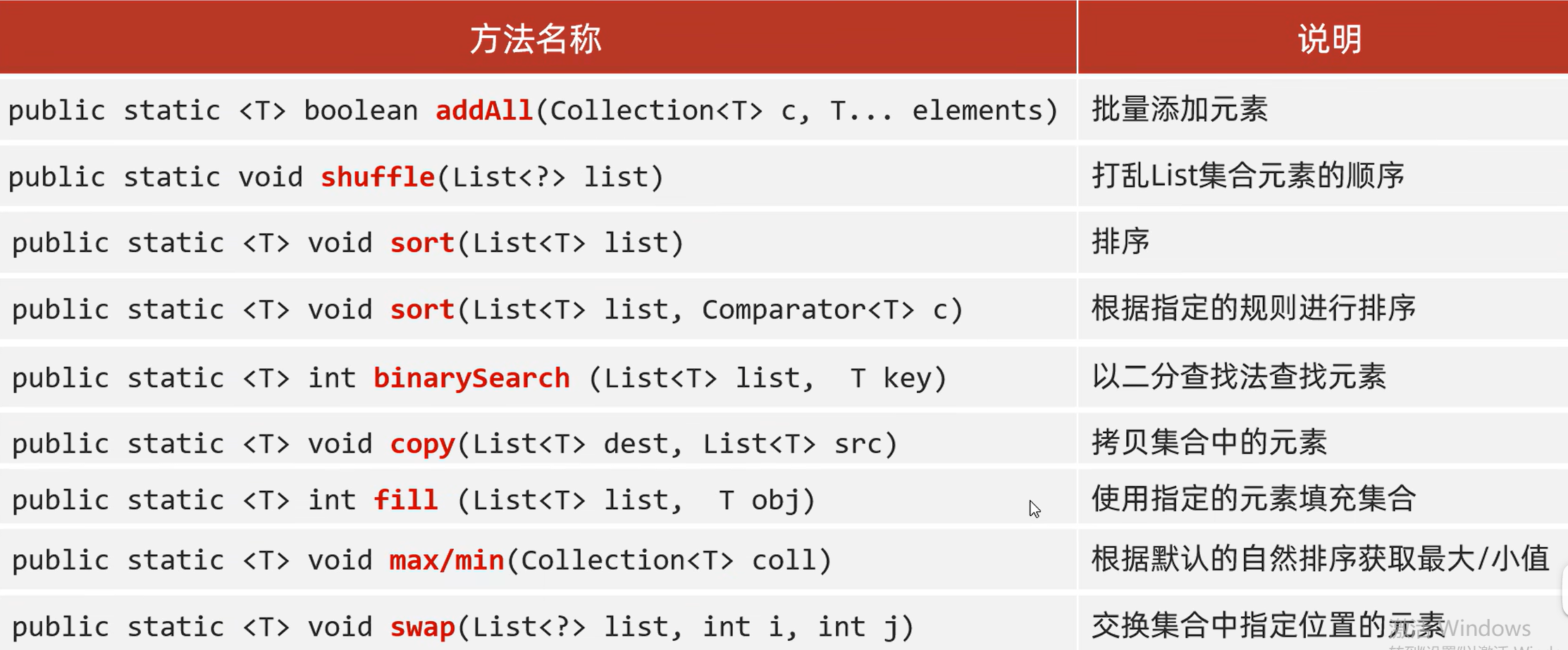
9.Collections
java.util.Collections是集合类工具。作用:Collections不是集合,而是集合的工具类
常用API:
10.不可变集合
应用场景:
1)如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践。
2)或者当集合对象被不可信的库调用时,不可变形式是安全的。
在List、Set、Map接口中,都存在静态的of方法,可以获取一个不可变的集合。

一旦创建无法修改、添加、删除,只能进行查询操作。
三个方法的细节:
List:直接使用
Set:元素不能重复
Map:元素不能重复、键值对数量最多10个,超过十个用ofEntries方法。jdk10之后还可以使用copyof的方法