项目场景:
上一篇文章介绍了如何在泛微OA上传自定义class接口文档实现接口开放 相关链接
泛微OA自定义接口,将生成的class文件压缩包在 /weaver路径下解压,实现壳子功能。该接口接收任意格式的请求报文,传输到cmd层(转base64),调用相关ESB事件后在ESB中实现对相关报文解析(base64转码)后,调用OA内部相关方法实现对开放API的自由接收报文需求。
问题描述
请求报文含有中文字符,接口解析后变乱码。
在ESB中直接输入报文base64转码没有乱码,从postman发送请求返回乱码
"eknam": "������ҵ��_�����ɹ���1",
原因分析:
从postman-OA服务器中间件-接口代码依次分析
1.接口代码解析优化
postman使用raw方式传输请求体,初步确认是UTF-8格式,在接口的代码层,优化相关请求request数据流 ,相关代码如下:
java
package com.engine.free.web;
import com.engine.common.util.ParamUtil;
import com.engine.common.util.ServiceUtil;
import com.engine.free.service.MM017ReciveDataService;
import com.engine.free.service.impl.MM017ReciveDataServiceImpl;
import net.sf.json.JSONObject;
import weaver.general.BaseBean;
import weaver.hrm.HrmUserVarify;
import weaver.hrm.User;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.Context;
import javax.ws.rs.core.MediaType;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
public class MM017EngineAction {
public MM017EngineAction(){}
BaseBean baseBean = new BaseBean();
/**
* 自定义getService 方法,ServiceUtil对象getService方法获取自定义service对象
* @param request
* @param response
* @return
*/
private MM017ReciveDataService getService(HttpServletRequest request, HttpServletResponse response) {
User user = HrmUserVarify.getUser(request, response);
return (MM017ReciveDataServiceImpl) ServiceUtil.getService(MM017ReciveDataServiceImpl.class, user);
}
@POST
@Path("/SchemaService")
@Produces(MediaType.APPLICATION_JSON)
public String SchemaService(@Context HttpServletRequest request, @Context HttpServletResponse response) throws UnsupportedEncodingException {
Map<String,Object> apidatas = new HashMap<>();
baseBean.writeLog("CharacterEncoding: " + request.getCharacterEncoding());
baseBean.writeLog("file.encoding: " + System.getProperty("file.encoding"));
Map map = ParamUtil.request2Map(request);
try {
User user = HrmUserVarify.getUser(request, response);
InputStream is = request.getInputStream();
String jsonStr = inputStream2StringNew(is,request);
baseBean.writeLog("MM017 EngineAction jsonStr = " + jsonStr);
map.put("json", jsonStr);
apidatas = this.getService(request, response).SchemaService(user,map);
} catch (IOException exception) {
exception.printStackTrace();
((Map)apidatas).put("api_status", false);
((Map)apidatas).put("api_errormsg", "catch Exception: " + exception.getMessage());
baseBean.writeLog("ERRO api_status: "+apidatas.get("api_status"));
throw new RuntimeException(exception);
}
return ((Map)apidatas).get("result").toString();
}
/*
public static String inputStream2StringNew(InputStream is) {
try {
ByteArrayOutputStream boa = new ByteArrayOutputStream();
int len ;
byte[] buffer = new byte[1024];
while((len = is.read(buffer)) != -1) {
boa.write(buffer, 0, len);
}
is.close();
boa.close();
byte[] result = boa.toByteArray();
String temp = new String(result);
if (temp.contains("utf-8")) {
return new String(result, "utf-8");
} else {
return temp.contains("gb2312") ? new String(result, "gb2312") : new String(result, "utf-8");
}
} catch (Exception exception) {
exception.printStackTrace();
return null;
}
}
*/
public static String inputStream2StringNew(InputStream is, HttpServletRequest request) {
try {
// 1. 优先从Content-Type获取编码,如:application/json; charset=utf-8
String charset = request.getCharacterEncoding();
if (charset == null || charset.isEmpty()) {
charset = StandardCharsets.UTF_8.name(); // 默认UTF-8
}
// 2. 直接用正确编码一次性解码
ByteArrayOutputStream boa = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1) {
boa.write(buffer, 0, len);
}
return boa.toString(charset); // 直接用指定编码解码
} catch (IOException e) {
throw new RuntimeException("读取请求体失败", e);
}
}
}入口方法实现指定使用utf-8解码
结果还是乱码
2. tcpdump抓包排查
在安装了tcpdump的服务器上,运行tcpdump应用后使用postman发送请求抓包,ctrl+c结束
bash
tcpdump -i any -s 0 -w /app/weaver/postman_to_bes.pcap 'port 8080 and host 172.19.*.*'其中172.19.*.*'是我本地postman所在主机ip。执行以下命令查看请求报文
bash
tcpdump -r /app/weaver/postman_to_bes.pcap -X -nn 'port 8080'-r:读取指定的 pcap 文件。-A:以 ASCII 码的形式打印出数据包的内容(这样你就能看到 HTTP 请求和响应的具体文本了)。-nn:直接把 IP 和端口号显示出来,不进行域名解析,阅读起来更清晰。
效果如下:
root@localhost weaver# tcpdump -r /app/weaver/postman_to_bes.pcap -X -nn 'port 8080' reading from file /app/weaver/postman_to_bes.pcap, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 Warning: interface names might be incorrect dropped privs to tcpdump 10:56:53.250860 enp18s0 In IP 172.19.*.*.51492 > 192.168.32.44.8080: Flags S, seq 2620177529, win 64240, options mss 1460,nop,wscale 8,nop,nop,sackOK, length 0 0x0000: 4500 0034 538b 4000 7c06 1364 ac13 0aed E..4S.@.|..d.... 0x0010: c0a8 202c c924 1f90 9c2c bc79 0000 0000 ...,....,.y.... 0x0020: 8002 faf0 9aef 0000 0204 05b4 0103 0308 ................ 0x0030: 0101 0402 .... 10:56:53.250931 enp18s0 Out IP 192.168.32.44.8080 \> 172.19.10.237.51492: Flags \[S.\], seq 720001401, ack 2620177530, win 64240, options \[mss 1460,nop,nop,sackOK,nop,wscale 10\], length 0 0x0000: 4500 0034 0000 4000 4006 a2ef c0a8 202c E..4..@.@......, 0x0010: ac13 0aed 1f90 c924 2aea 5979 9c2c bc7a .......*.Yy.,.z 0x0020: 8012 faf0 97fb 0000 0204 05b4 0101 0402 ................ 0x0030: 0103 030a ....
将以上所有内容丢给AI后返回结论:Postman 发送的是正确的 UTF-8!
| 字段 | 抓包原始字节 | UTF-8 解码结果 |
| ----------- | ------------------------------------- | ------------------- |
| `name_org1` | `E7 A6 8F E8 80 80 E7 8E BB E7 92 83` | **福耀玻璃** ✅ |
| `eknam` | `E5 9B BD E9 99 85...` | **国际事业部\_备件采购组1** ✅ |
| `txz01` | `33 2F 34 E6 A1 A3 E5 8F 8C...` | **3/4档双锥环组件** ✅ |
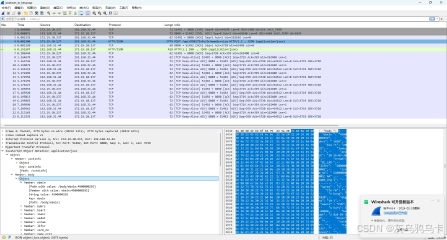
截图分析
1. 左侧:协议解析树
Wireshark 已经自动识别并解析了 JSON 结构:
-
JavaScript Object Notation: application/json -
Member: body→Object→Member: ebeln等
这说明 Wireshark 认为这是一个合法的 JSON ,并且 Content-Type 是 application/json(没有 charset 声明)。
2. 右侧:原始字节视图(关键!)
看 name_org1 字段对应的字节区域:
plain
复制
0510: ... 22 6e 61 6d 65 5f 6f 72 67 31 22 3a 20 22 e7 a6 8f "name_org1": "..
0520: e8 80 80 e7 8e bb e7 92 83 22 2c 0d 0a 20 20 20 20 22 .......",.... "name_org1 的值字节 :E7 A6 8F E8 80 80 E7 8E BB E7 92 83
这是 UTF-8 编码 ,解码为:福耀玻璃
表格
| 字段 | 原始字节 | 编码 | 内容 |
|---|---|---|---|
name_org1 |
E7A68F E88080 E78EBB E79283 |
UTF-8 | 福耀玻璃 ✅ |
ebeln |
34353030303030323932 |
ASCII | 4500000292 ✅ |
Wireshark 的 JSON 解析器能正确显示中文,说明网络层的 UTF-8 字节完全正确。
3.最可能的原因:JVM file.encoding=GBK
Postman → 网络 → 宝兰德
↑
这里的字节是正确的 UTF-8
根因确认 :字节到达宝兰德后,JVM 用 file.encoding=GBK 处理 UTF-8 字节,导致乱码。
修改宝兰德conf目录下server.config文件,
<jvm-options>-Dfile.encoding=GBK</jvm-options>改为
<jvm-options>-Dfile.encoding=UTF-8</jvm-options>
重启测试,不在是乱码,但是不建议这么做!!!
解决方案:
以上第三点确认可以实现接收中文报文,但是泛微厂商不建议这样改,因为如果修改这项配置,重启服务后,如果之前使用GBK读的jsp文件通过UTF-8变为乱码,就会不可逆的乱码!!!