CVPR 2026 | 当LoRA遇上RoPE! WaDi:面向单步图像生成的权重方向感知蒸馏
论文链接:https://arxiv.org/abs/2603.08258
代码链接:https://github.com/gudaochangsheng/WaDi
Project: https://gudaochangsheng.github.io/WaDi-Page/
Demo: https://huggingface.co/spaces/gudaochangsheng/WaDi-1.5
讲解视频: https://www.youtube.com/watch?v=j6CuQxynJcA
作者:王雷|南开大学,PCA Lab

图1. 使用我们提出的方法 WaDi(即 SD 2.1)一步生成的图像。
摘要
尽管扩散模型(如 Stable Diffusion,SD)在图像生成领域表现出色,但其缓慢的推理速度限制了实际部署。近期工作通过将多步扩散蒸馏为单步生成器来加速推理。为了更好地理解蒸馏机制,我们分析了单步学生模型与多步教师模型之间 U-Net/DiT 权重的变化规律。分析表明,权重方向上的变化显著超过权重范数上的变化,这揭示了方向是蒸馏过程中的关键因素。受此启发,我们提出了权重方向低秩旋转(Low-rank Rotation of weight Direction,LoRaD)------一种专为单步扩散蒸馏设计的参数高效适配器。LoRaD 通过可学习的低秩旋转矩阵对预训练权重的方向进行建模。我们进一步将 LoRaD 集成到变分得分蒸馏(Variational Score Distillation,VSD)中,提出了权重方向感知蒸馏(Weight Direction-aware Distillation,WaDi)------一种新颖的单步蒸馏框架。WaDi 在 COCO 2014 和 COCO 2017 上取得了最先进的 FID 分数,而可训练参数仅占 U-Net/DiT 全量参数的约 10%。此外,蒸馏后的单步模型展现出强大的通用性和可扩展性,能够良好地泛化到可控生成、关系反演、高分辨率合成等多种下游任务。
1. 引言
扩散模型(DMs)在图像生成领域受到了广泛关注,在文本到图像生成、文本到视频生成以及图像到视频生成等任务中均有广泛应用。然而,扩散模型依赖多步采样,导致计算成本高、推理速度慢。为此,近期蒸馏方法将采样步数压缩至数步甚至一步。有趣的是,在蒸馏过程中,我们发现权重范数在各层间保持相对稳定,而在将权重重参数化为范数与方向时,方向则呈现出更大的变化幅度。
受权重重参数化的启发,我们采用类似的分解方式来分析扩散蒸馏中的权重变化。为此,我们研究了最先进(SOTA)单步模型(如 DMD2 和 Pixart-α DMD)与其对应多步模型(如 SD 1.5 和 Pixart-α)之间的权重更新。如图 2(a) 所示,在基于 U-Net 的架构中,各层权重范数几乎保持稳定,均值和标准差(STD)分别约为 0.1% 和 0.2%。相比之下,权重方向的变化则明显更大,均值为 2.2%,标准差为 2.1%,对应为范数变化的 22 倍和 10 倍。在基于 DiT 的架构中也观察到类似规律(见图 2(a) 右)。这些观察表明,权重方向可能携带了蒸馏中更丰富、更敏感的信息。
此外,方向上的变化是否具有结构化规律?为此,我们对残差矩阵(单步与多步方向矩阵之差)进行奇异值分解(SVD),发现仅保留 30% 的秩即可恢复 93% 的信息,突显了其低秩本质(见图 2(b))。
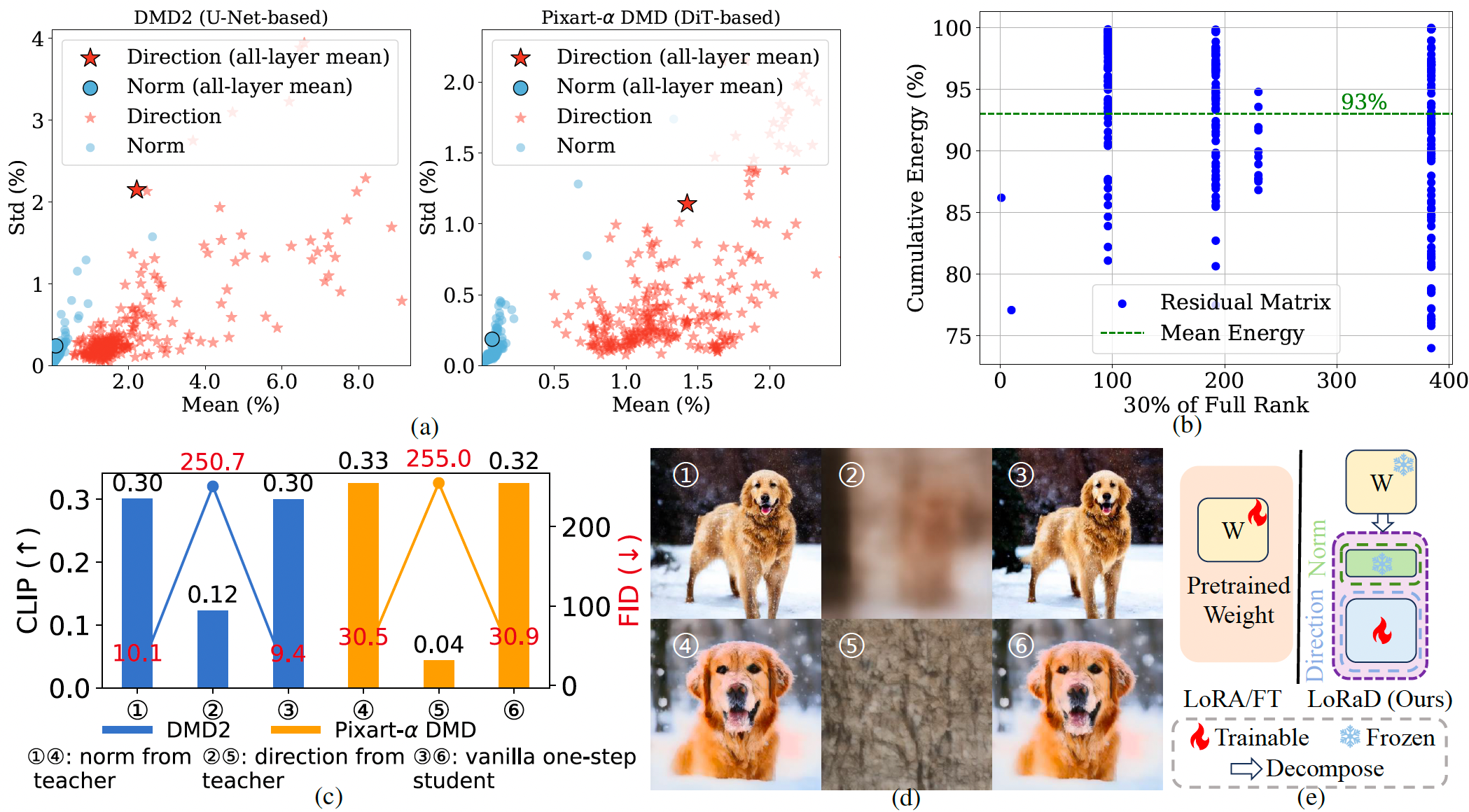
图2. 我们方法的动机分析。(a) 一步学生模型与教师模型之间的权重范数和方向差异。更多细节和补充示例见补充材料 E。(b) DMD2 残差矩阵的 SVD 分析。© 将一步模型的范数替换为多步模型的范数影响很小①④);替换方向会严重降低生成质量②⑤)。(d) 与 © 对应的定性示例。(e) LoRaD 示意图。
为了量化这两个分量的影响,我们通过有选择地将单步模型的范数或方向替换为多步模型的对应值,进行受控消融实验(见图 2(d))。如图 2© 所示,替换范数对性能影响微乎其微(如 DMD2:FID +0.7,CLIP 不变),而替换方向则导致严重退化(如 DMD2:FID +241.3,CLIP -0.18)。这些发现表明,方向重建是蒸馏中性能提升的核心因素,而范数变化的影响相对次要。一种可能的解释是:用教师权重初始化学生模型对齐了初始范数,训练过程中的权重衰减进一步约束了范数漂移;而蒸馏信号则主要通过调整权重方向来减少表征差异。综合来看,这些结果表明方向重建是蒸馏性能提升的核心驱动因素。
上述蒸馏方法大致可分为两类:全量微调(FT)和基于低秩适配(LoRA)的微调。然而,二者在优化范数和方向时均直接更新模型参数,导致范数和方向的变化相互耦合,增加了优化难度。此外,FT 和 LoRA 均面临收敛慢、不稳定和过拟合等问题,进一步增加了优化的复杂性。
为此,我们提出了权重方向低秩旋转(LoRaD)(见图 2(e)),通过可学习的旋转矩阵调整预训练权重的方向。鉴于方向变化的结构化特性(即低秩特性),旋转角度被参数化为两个低秩矩阵的乘积,以进一步减少可学习参数数量。我们将 LoRaD 集成到变分得分蒸馏(VSD)中,提出了权重方向感知蒸馏(WaDi),一种新颖的单步文本到图像蒸馏框架。在 COCO 2014 和 COCO 2017 数据集上的实验表明,WaDi 取得了最先进的 FID 分数,超越所有现有单步生成方法。这一成果仅通过优化方向实现,将蒸馏难度降低,同时 U-Net 可训练参数仅约占 10%,极大提升了参数效率。此外,我们将 WaDi 应用于可控生成、关系反演、高分辨率合成和图像定制化等下游任务,展示了其加速能力和广泛适用性。本文贡献总结如下:
-
我们对多步与单步生成模型之间 U-Net 权重变化进行了深入分析,将权重方向调整确定为单步蒸馏的关键驱动因素,为高效蒸馏提供了新的理论视角。
-
我们提出了一种新颖的单步文本到图像蒸馏框架 WaDi,采用 LoRaD 通过低秩旋转建模权重方向,有效引导学生模型对齐教师分布。
-
WaDi 在 COCO 数据集和多个下游任务上进行了评估,定性和定量结果均表明 WaDi 在显著提升推理效率的同时取得了实质性的图像质量提升。
2. 相关工作
扩散模型。扩散模型在图像生成领域表现卓越,但像素空间计算开销大。为提升效率,Rombach 等人提出了潜在扩散模型(LDM),将去噪过程迁移至潜在空间。然而,现有基于文本引导的方法由于多步生成仍然较慢。尽管大多数方法采用 U-Net 骨干,扩散 Transformer(DiT)以 Transformer 替代 U-Net 以获得更好的可扩展性,推动了文本到图像生成的进步。尽管有所改进,迭代去噪仍是一个缓慢的过程。近期,许多加速方法相继出现。
扩散模型加速。现有加速方法可分为无训练和基于训练两类。无训练加速方法主要通过缓存减少冗余计算,或采用高阶求解器减少采样步数。然而这两类方法的加速效果有限,因此基于训练的方法受到了更多关注。
基于训练的加速方法大致可分为四类:一致性蒸馏(CD)、渐进蒸馏(PD)、扩散-GAN 蒸馏和变分得分蒸馏(VSD)。CD 在轨迹层面学习一致性以加速采样,但图像保真度往往较低。PD 分阶段降低步数,引入显著训练开销。扩散-GAN 蒸馏(如 Diffusion2GAN)通过将多步扩散蒸馏为 GAN 来提升保真度。VSD 采用双教师策略实现分布对齐,SwiftBrush 实现了单步无图像生成,SwiftBrushv2 利用模型集成进一步改善,DMD 引入回归损失进一步提升性能,DMD2 将 VSD 扩展至少步生成,并支撑了近期文本到视频加速框架。
然而,现有基于训练的方法通常使用 FT 或 LoRA,这可能增加优化难度。我们发现方向变化在蒸馏中通常更具影响力,因此提出 WaDi,利用 LoRaD 专注于建模方向旋转。
3. 方法
我们首先在第 3.1 节简要回顾变分得分蒸馏(VSD),它是本工作的基础。受权重方向变化在蒸馏中发挥关键作用这一观察的启发,我们在第 3.2 节引入权重方向低秩旋转(LoRaD)模块(更多理论说明见补充材料 D)。最后,我们将 LoRaD 集成到 VSD 中,形成我们提出的蒸馏框架------权重方向感知蒸馏(WaDi)。
3.1 预备知识
潜在扩散模型(LDM)在低维潜在空间中执行扩散过程,提升了计算效率。LDM 的训练目标可以表示为:
Lmse=minφEt,ϵ,c∥ϵφ(zt,c,t)−ϵ∥22,(1)\mathcal{L}{mse} = \min{\varphi} \mathbb{E}{t,\epsilon,c} \left\| \epsilon{\varphi}(z_t, c, t) - \epsilon \right\|_2^2, \quad (1)Lmse=φminEt,ϵ,c∥ϵφ(zt,c,t)−ϵ∥22,(1)
其中 ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0, I)ϵ∼N(0,I) 为高斯噪声,ztz_tzt 为时间步 ttt 处的潜变量,ccc 表示用于引导图像生成的条件(如提示词),ϵφ(zt,c,t)\epsilon_{\varphi}(z_t, c, t)ϵφ(zt,c,t) 为由参数 φ\varphiφ 参数化的模型预测的噪声。
变分得分蒸馏(VSD)最初用于文本到 3D 生成,以解决过饱和和多样性不足的问题,后被扩展至 2D 文本到图像生成,应用于 Swiftbrush、DMD、DMD2 和 SiD 等方法,实现了单步生成。VSD 的训练目标为:
∇λLvsd=Et,ϵ,cω(t)(ϵψ(zt,c,t)−ϵϕ(zt,c,t))∂Gλ(zinit,c)∂λ,(2)\nabla_\lambda \mathcal{L}{vsd} = \mathbb{E}{t,\epsilon,c} \left \\omega(t) \\left( \\epsilon_\\psi(z_t, c, t) - \\epsilon_\\phi(z_t, c, t) \\right) \\frac{\\partial G_\\lambda(z_{init}, c)}{\\partial \\lambda} \\right, \quad (2)∇λLvsd=Et,ϵ,cω(t)(ϵψ(zt,c,t)−ϵϕ(zt,c,t))∂λ∂Gλ(zinit,c),(2)
其中 ω(t)\omega(t)ω(t) 是时间相关的权重项,ϵψ\epsilon_\psiϵψ 是由 ψ\psiψ 参数化的真实模型,ϵϕ\epsilon_\phiϵϕ 是由 ϕ\phiϕ 参数化的虚假模型,GλG_\lambdaGλ 是以 λ\lambdaλ 为输入噪声参数化的单步生成器,zinit∼N(0,I)z_{init} \sim \mathcal{N}(0, I)zinit∼N(0,I)。此外,ϵϕ\epsilon_\phiϵϕ 利用公式 (1) 进行训练。VSD 交替更新 ϵϕ\epsilon_\phiϵϕ 和 GλG_\lambdaGλ 直至收敛。
3.2 权重方向低秩旋转
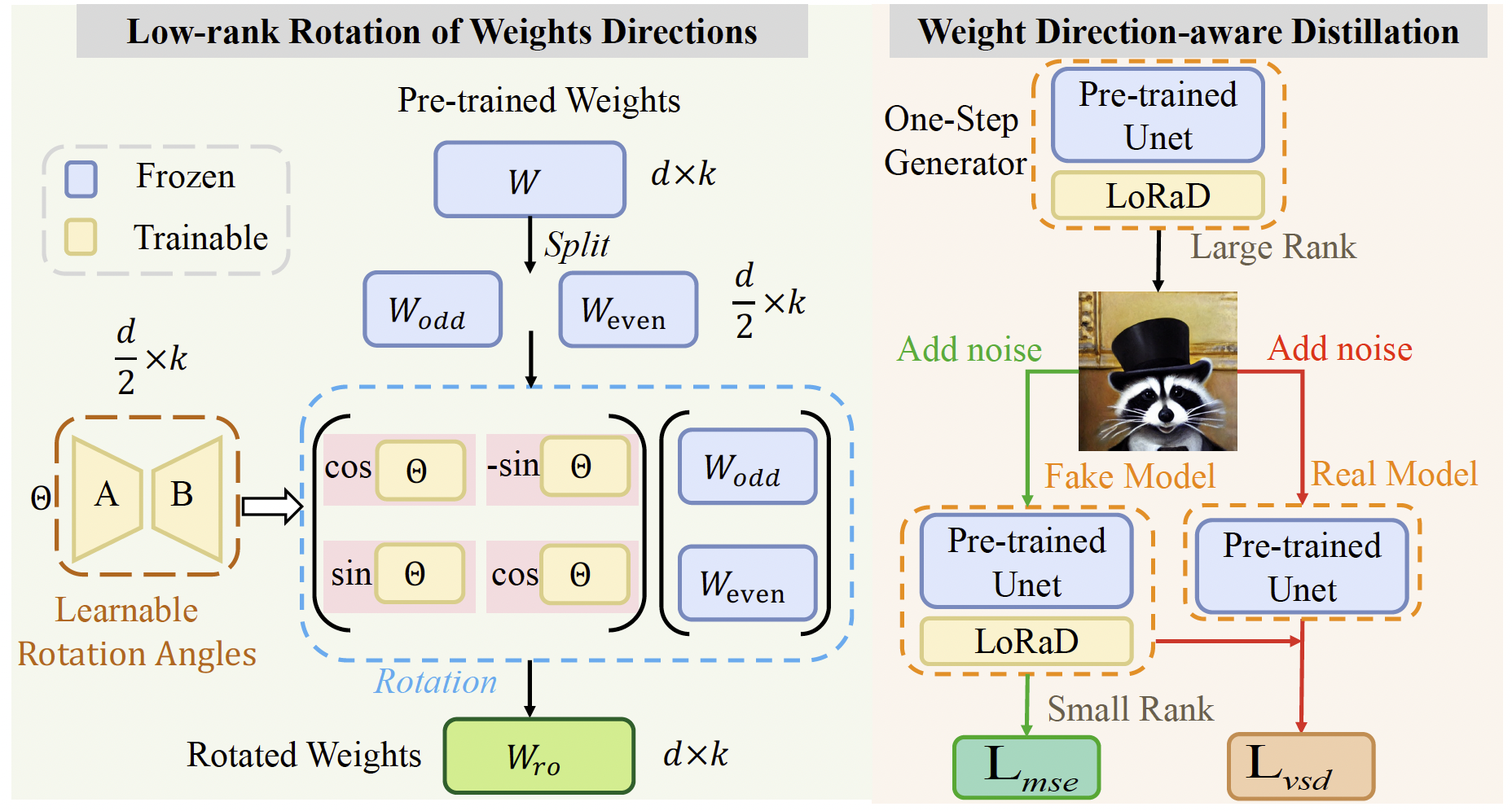
图3. (左)权重方向低秩旋转(LoRaD)模块的详细结构。LoRaD 使用可学习的低秩旋转角来旋转预训练权重方向。(右)权重方向感知蒸馏(WaDi)框架概览。
分析多步 U-Net 模型与其单步对应模型之间的权重变化,揭示了显著的方向偏移,而范数变化相对较小。受此启发,我们提出权重方向低秩旋转(LoRaD)(见图 3 左),通过学习仅改变方向的旋转来更新权重。此外,我们观察到方向变化具有低秩结构(见图 2(b))。为利用这一特性并降低全秩建模的开销(全秩建模引入的额外参数相当于原始权重的 50%),我们采用 LoRA 的低秩分解策略。从 2D 情形(d=2d=2d=2)出发,给定权重向量 α∈Rd\alpha \in \mathbb{R}^dα∈Rd,应用 2D 旋转矩阵:
αro=(cosθ−sinθsinθcosθ)(α(1)α(2)),(3)\alpha_{ro} = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix} \begin{pmatrix} \alpha^{(1)} \\ \alpha^{(2)} \end{pmatrix}, \quad (3)αro=(cosθsinθ−sinθcosθ)(α(1)α(2)),(3)
其中 αro\alpha_{ro}αro 是旋转后的权重向量。受旋转位置编码(RoPE)的启发,RoPE 将 2D 情形推广至任意偶数维度 ddd,我们对预训练权重矩阵 W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k 的每列应用不同的旋转矩阵:
Wro=RΘ,1dW⋅,1, RΘ,2dW⋅,2, ⋯ , RΘ,kdW⋅,k,(4)W_{ro} = \left R_{\\Theta,1}\^d W_{\\cdot,1},\\ R_{\\Theta,2}\^d W_{\\cdot,2},\\ \\cdots,\\ R_{\\Theta,k}\^d W_{\\cdot,k} \\right, \quad (4)Wro=RΘ,1dW⋅,1, RΘ,2dW⋅,2, ⋯, RΘ,kdW⋅,k,(4)
其中旋转矩阵 RΘ={RΘ,id}i=1kR_\Theta = \{R_{\Theta,i}^d\}_{i=1}^kRΘ={RΘ,id}i=1k 定义为:
RΘ,id=(cosθ1,i−sinθ1,i00⋯00sinθ1,icosθ1,i00⋯0000cosθ2,i−sinθ2,i⋯0000sinθ2,icosθ2,i⋯00⋮⋮⋮⋮⋱⋮⋮0000⋯cosθd2,i−sinθd2,i0000⋯sinθd2,icosθd2,i),(5)R_{\Theta,i}^d = \begin{pmatrix} \cos\theta_{1,i} & -\sin\theta_{1,i} & 0 & 0 & \cdots & 0 & 0 \\ \sin\theta_{1,i} & \cos\theta_{1,i} & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos\theta_{2,i} & -\sin\theta_{2,i} & \cdots & 0 & 0 \\ 0 & 0 & \sin\theta_{2,i} & \cos\theta_{2,i} & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos\theta_{\frac{d}{2},i} & -\sin\theta_{\frac{d}{2},i} \\ 0 & 0 & 0 & 0 & \cdots & \sin\theta_{\frac{d}{2},i} & \cos\theta_{\frac{d}{2},i} \end{pmatrix}, \quad (5)RΘ,id= cosθ1,isinθ1,i00⋮00−sinθ1,icosθ1,i00⋮0000cosθ2,isinθ2,i⋮0000−sinθ2,icosθ2,i⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosθ2d,isinθ2d,i0000⋮−sinθ2d,icosθ2d,i ,(5)
其中 Θ={θj}j=1d2∈Rd2×k\Theta = \{\theta_j\}_{j=1}^{\frac{d}{2}} \in \mathbb{R}^{\frac{d}{2} \times k}Θ={θj}j=12d∈R2d×k。
注:旋转不影响范数,因此无需显式分离范数矩阵。
考虑到公式 (5) 中 RΘ,idR_{\Theta,i}^dRΘ,id 的稀疏性,矩阵-向量乘法 RΘ,idW⋅,i∈RdR_{\Theta,i}^d W_{\cdot,i} \in \mathbb{R}^dRΘ,idW⋅,i∈Rd 可高效计算为:
RΘ,idW⋅,i=(Wi(1)Wi(2)Wi(3)Wi(4)⋮Wi(d−1)Wi(d))⊙(cosθ1,icosθ1,icosθ2,icosθ2,i⋮cosθd2,icosθd2,i)+(−Wi(2)Wi(1)−Wi(4)Wi(3)⋮−Wi(d)Wi(d−1))⊙(sinθ1,isinθ1,isinθ2,isinθ2,i⋮sinθd2,isinθd2,i),(6)R_{\Theta,i}^d W_{\cdot,i} = \begin{pmatrix} W_i^{(1)} \\ W_i^{(2)} \\ W_i^{(3)} \\ W_i^{(4)} \\ \vdots \\ W_i^{(d-1)} \\ W_i^{(d)} \end{pmatrix} \odot \begin{pmatrix} \cos\theta_{1,i} \\ \cos\theta_{1,i} \\ \cos\theta_{2,i} \\ \cos\theta_{2,i} \\ \vdots \\ \cos\theta_{\frac{d}{2},i} \\ \cos\theta_{\frac{d}{2},i} \end{pmatrix} + \begin{pmatrix} -W_i^{(2)} \\ W_i^{(1)} \\ -W_i^{(4)} \\ W_i^{(3)} \\ \vdots \\ -W_i^{(d)} \\ W_i^{(d-1)} \end{pmatrix} \odot \begin{pmatrix} \sin\theta_{1,i} \\ \sin\theta_{1,i} \\ \sin\theta_{2,i} \\ \sin\theta_{2,i} \\ \vdots \\ \sin\theta_{\frac{d}{2},i} \\ \sin\theta_{\frac{d}{2},i} \end{pmatrix}, \quad (6)RΘ,idW⋅,i= Wi(1)Wi(2)Wi(3)Wi(4)⋮Wi(d−1)Wi(d) ⊙ cosθ1,icosθ1,icosθ2,icosθ2,i⋮cosθ2d,icosθ2d,i + −Wi(2)Wi(1)−Wi(4)Wi(3)⋮−Wi(d)Wi(d−1) ⊙ sinθ1,isinθ1,isinθ2,isinθ2,i⋮sinθ2d,isinθ2d,i ,(6)
其中 ⊙\odot⊙ 表示逐元素乘法。该实现利用了旋转矩阵的稀疏性,仅通过逐元素运算完成计算,从而显著降低了计算成本。
此外,由于公式 (5) 和 (6) 中的旋转矩阵由独立的 2×22 \times 22×2 子矩阵构成块对角结构,整个计算可以高效地实现为多个 2×22 \times 22×2 旋转在奇偶索引对上的并行应用。如图 3 左所示,我们将预训练权重矩阵 W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k 的 ddd 维空间拆分为 d2\frac{d}{2}2d 个子空间,对每个子空间独立旋转。通过分离 WWW 的奇偶行,定义:
Wodd=(W(1),W(3),...,W(d−1))T,W_{odd} = \left(W^{(1)}, W^{(3)}, \ldots, W^{(d-1)}\right)^T,Wodd=(W(1),W(3),...,W(d−1))T,
Weven=(W(2),W(4),...,W(d))T,(7)W_{even} = \left(W^{(2)}, W^{(4)}, \ldots, W^{(d)}\right)^T, \quad (7)Weven=(W(2),W(4),...,W(d))T,(7)
得到两个矩阵 Wodd∈Rd2×kW_{odd} \in \mathbb{R}^{\frac{d}{2} \times k}Wodd∈R2d×k 和 Weven∈Rd2×kW_{even} \in \mathbb{R}^{\frac{d}{2} \times k}Weven∈R2d×k。
每对奇偶行上的并行 2×22 \times 22×2 旋转可以紧凑地表示为:
Wro=RΘW=cosΘ−sinΘsinΘcosΘWoddWeven,(8)W_{ro} = R_\Theta W = \begin{bmatrix} \cos\Theta & -\sin\Theta \\ \sin\Theta & \cos\Theta \end{bmatrix} \begin{bmatrix} W_{odd} \\ W_{even} \end{bmatrix}, \quad (8)Wro=RΘW=cosΘsinΘ−sinΘcosΘWoddWeven,(8)
其中 Wro∈Rd×kW_{ro} \in \mathbb{R}^{d \times k}Wro∈Rd×k 是旋转后的权重矩阵,Θ∈Rd2×k\Theta \in \mathbb{R}^{\frac{d}{2} \times k}Θ∈R2d×k 是可学习的旋转角度参数矩阵。为进一步减少可训练参数数量,受 LoRA 启发,我们对 Θ\ThetaΘ 应用低秩分解:
Θ=AB,(9)\Theta = AB, \quad (9)Θ=AB,(9)
其中 A∈Rd2×rA \in \mathbb{R}^{\frac{d}{2} \times r}A∈R2d×r 和 B∈Rr×kB \in \mathbb{R}^{r \times k}B∈Rr×k 是秩为 rrr 的低秩参数矩阵。最终,公式 (8) 可以改写为:
Wro=RΘW=RABW=cosAB−sinABsinABcosABWoddWeven.(10)W_{ro} = R_\Theta W = R_{AB} W = \begin{bmatrix} \cos AB & -\sin AB \\ \sin AB & \cos AB \end{bmatrix} \begin{bmatrix} W_{odd} \\ W_{even} \end{bmatrix}. \quad (10)Wro=RΘW=RABW=cosABsinAB−sinABcosABWoddWeven.(10)
3.3 权重方向感知蒸馏
为了充分利用蒸馏中观察到的方向特性,我们将 LoRaD 集成到 VSD 中,得到一个方向感知蒸馏框架,称为权重方向感知蒸馏(WaDi)。如图 3 右所示,WaDi 采用预训练扩散模型 ϵψ\epsilon_\psiϵψ 作为教师(真实模型),并引入可训练的虚假模型 ϵϕ\epsilon_\phiϵϕ(从 ϵψ\epsilon_\psiϵψ 初始化)来近似教师分布。最终学生模型(单步生成器)GλG_\lambdaGλ 同样从 ϵψ\epsilon_\psiϵψ 初始化,经训练后能够单步合成高质量图像。算法详见补充材料 F.3。
为增强与真实分布的对齐,我们对学生模型和虚假模型均应用 LoRaD。具体而言,单步生成器 GλΘlG_{\lambda_{\Theta^l}}GλΘl 引入高秩旋转矩阵 Θl\Theta^lΘl 以更好地拟合教师;虚假模型 ϵϕΘs\epsilon_{\phi_{\Theta^s}}ϵϕΘs 采用低秩旋转矩阵 Θs\Theta^sΘs 以提供自适应引导。最终,我们交替优化 λΘl\lambda_{\Theta^l}λΘl 和 ϕΘs\phi_{\Theta^s}ϕΘs 以共同提升生成质量。
相应地,WaDi 的训练目标可以从公式 (2) 改写为:
∇λΘlLwadi=Et,ϵ,cω(t)(ϵψ(zt,c,t)−ϵϕΘs(zt,c,t))∂GλΘl(zinit,c)∂λΘl,(11)\nabla_{\lambda_{\Theta^l}} \mathcal{L}{wadi} = \mathbb{E}{t,\epsilon,c} \left \\omega(t) \\left( \\epsilon_\\psi(z_t, c, t) - \\epsilon_{\\phi_{\\Theta\^s}}(z_t, c, t) \\right) \\frac{\\partial G_{\\lambda_{\\Theta\^l}}(z_{init}, c)}{\\partial \\lambda_{\\Theta\^l}} \\right, \quad (11)∇λΘlLwadi=Et,ϵ,cω(t)(ϵψ(zt,c,t)−ϵϕΘs(zt,c,t))∂λΘl∂GλΘl(zinit,c),(11)
虚假模型 ϵϕΘs\epsilon_{\phi_{\Theta^s}}ϵϕΘs 的训练目标可以从公式 (1) 改写为:
minϕΘsEt,ϵ,c∥ϵϕΘs(zt,c,t)−ϵ∥22.(12)\min_{\phi_{\Theta^s}} \mathbb{E}{t,\epsilon,c} \left\| \epsilon{\phi_{\Theta^s}}(z_t, c, t) - \epsilon \right\|_2^2. \quad (12)ϕΘsminEt,ϵ,c∥ϵϕΘs(zt,c,t)−ϵ∥22.(12)
4. 实验
4.1 实验设置
评估数据集与指标。我们在 COCO 2014 和 COCO 2017 数据集上系统评估 WaDi 的零样本文本到图像生成能力,分别随机采样 30k 和 5k 张图像。为全面评估生成质量,我们使用 Fréchet Inception Distance(FID)衡量图像保真度,CLIP 分数评估文本-图像语义对齐。FID 使用 Inception V3 作为特征提取器,CLIP 分数基于 ViT-G/14 模型。我们还采用精确率和召回率评估保真度与多样性,并在 Human Preference Score v2(HPSv2)基准上评估文本-图像对齐质量。详见补充材料 G.1。
实现细节。遵循先前方法,WaDi 中的学生模型采用与教师相同的架构,并用教师权重初始化。WaDi 在从 JourneyDB 数据集中采样的 140 万条提示词上进行训练。训练过程中,学生模型的学习率(LR)设为 1e-4,虚假模型的学习率设为 1e-2。我们使用 AdamW 作为优化器,批大小为 128(每 GPU 16 张)。无分类器引导(CFG)系数设为 1.5,训练进行 2 个 epoch。我们在三种不同骨干上蒸馏学生模型,分别为 SD 1.5、SD 2.1 和 PixArt-α(256×256)。对于 SD 1.5 和 SD 2.1,学生模型的 LoRaD 秩设为 256,而对于 PixArt-α 设为 128。所有虚假模型的 LoRaD 秩统一设为 32。详见补充材料 F.1。
4.2 与最先进方法的比较
定量结果。我们在 COCO 2014 数据集上与三种骨干(SD 1.5、SD 2.1、PixArt-α)的 SOTA 零样本单步生成方法全面评估 WaDi。为保证公平比较并考虑计算约束,我们遵循 TiUE 的设置,统一使用 140 万条提示词复现 WaDi、DMD2、SiD-LSG 和 SwiftBrushv2。如表 1 所示,WaDi 在所有骨干上均取得最佳 FID 和召回率分数,表现出优越的保真度和多样性。在 CLIP 和精确率上也排名第一或第二,显示出强大的文本-图像对齐和感知质量。值得注意的是,SD 1.5、SD 2.1 和 PixArt-α 可训练参数分别仅占 9.74%、10.92% 和 13.30%,突显了 WaDi 的参数高效性。这些改进源于我们提出的 LoRaD,通过低秩旋转重参数化权重更新,实现稳定高效的蒸馏。
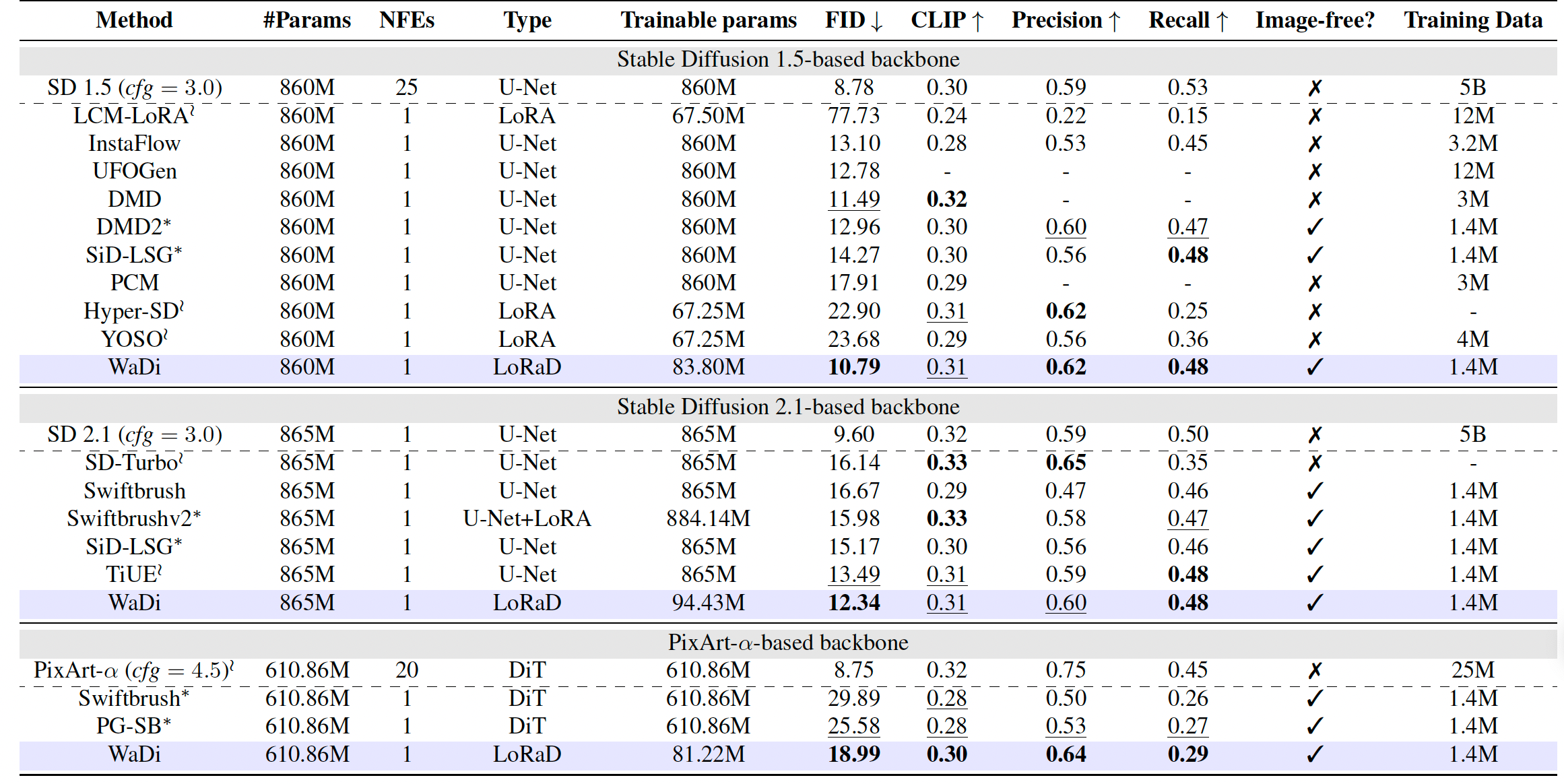
表1. WaDi 与其他方法在零样本 COCO 2014 结果上的定量比较。∗ 表示我们复现的结果,≀ 表示使用官方预训练模型得到的结果。"-"表示未知。最佳和次佳分数分别用粗体和下划线标出。"Image-free"指在没有真实图像监督的情况下进行训练。
定性结果。图 4 展示了 WaDi 与 SOTA 单步生成方法在 SD 1.5 和 SD 2.1 骨干上的定性比较。在不同提示词下,WaDi 一致地生成视觉连贯、语义对齐的结果。例如,在第一、二行中,WaDi 更好地保留了结构和风格保真度,捕捉到清晰的细节和鲜艳的色彩,无伪影或失真。在第三、四行中,它能准确跟随涉及特定主体(如 sphynx cat、corgi、shiba inu)和场景(如剧院、服装)的提示词,而其他方法往往漏掉关键属性或生成不真实的形状。值得注意的是,在最后一行,WaDi 生成了空间构图和背景细节一致的复杂场景(如狗看电视),展示了相对于其他基线更优越的整体理解能力。详见补充材料 G.5。

图4. 与其他方法的定性比较,其中 ∗ 表示我们复现的结果。
4.3 下游任务
可控生成。ControlNet 是一种广泛使用的可控生成模型,通过将空间条件整合到 SD 中实现精细控制。如图 5 所示,将 WaDi 应用于 ControlNet 可显著提升推理效率,将推理时间缩短 86.26%,同时保持图像质量,忠实遵循空间条件,提示词遵从度与 ControlNet 相当。
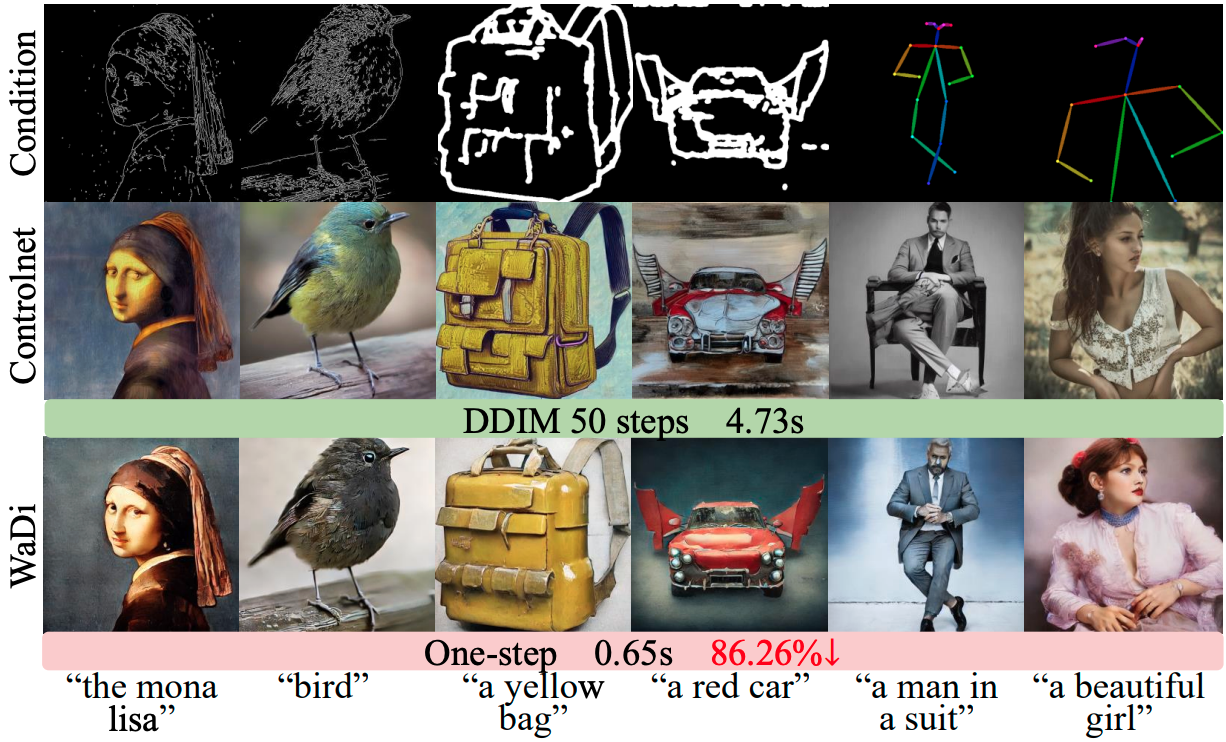
图5. 使用或不使用 WaDi 的 ControlNet 74 质量结果。
关系反演。Reversion 是首个在 SD 中通过关系提示词引导特定对象关系合成的方法。将 WaDi 集成到 Reversion 中可显著加速推理。如图 6 所示,WaDi 将推理时间缩短 88.89%,生成与关系提示词对齐的高保真图像,质量接近原始多步 Reversion。
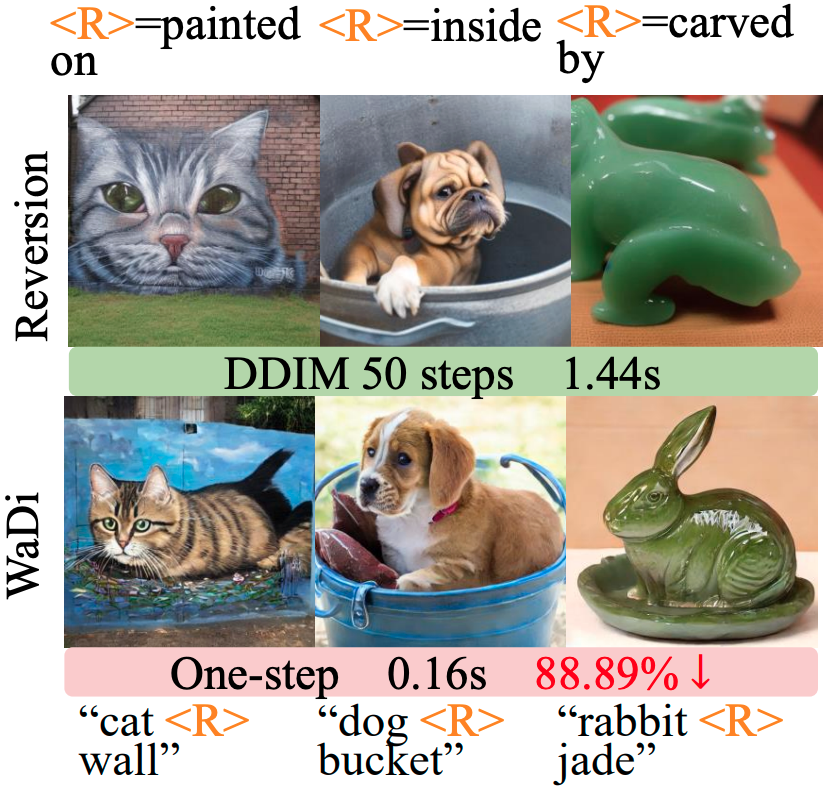
图6. 使用或不使用 WaDi 的 Reversion 22 质量结果。
图像定制化。Dreambooth 是一种开创性的个性化文本到图像框架,通过对 U-Net 进行微调将目标主体绑定到稀有标记。为增强参数效率,我们将 LoRaD 集成到 Dreambooth 中,并与 Dreambooth(FT)和 LoRA 进行比较。如图 7 所示,原始 DreamBooth 会捕捉主体但记忆训练图像,降低提示词敏感性。LoRA 缓解了过拟合,但降低了主体保真度和图像质量。相比之下,LoRaD 在保持提示词遵从度的同时维持了主体保真度,实现了更好的平衡。我们将此 DreamBooth 实验仅作为说明性示例,而非扩散微调的全面研究。

图7. 使用或不使用 LoRaD 的 DreamBooth 质量结果。
4.4 用户研究
为评估图像质量和文本-图像对齐,我们邀请 57 名参与者进行了用户研究,涵盖零样本生成和下游任务。如图 9 所示,结果清楚地表明我们的方法优于现有基线。详见补充材料 F.5。
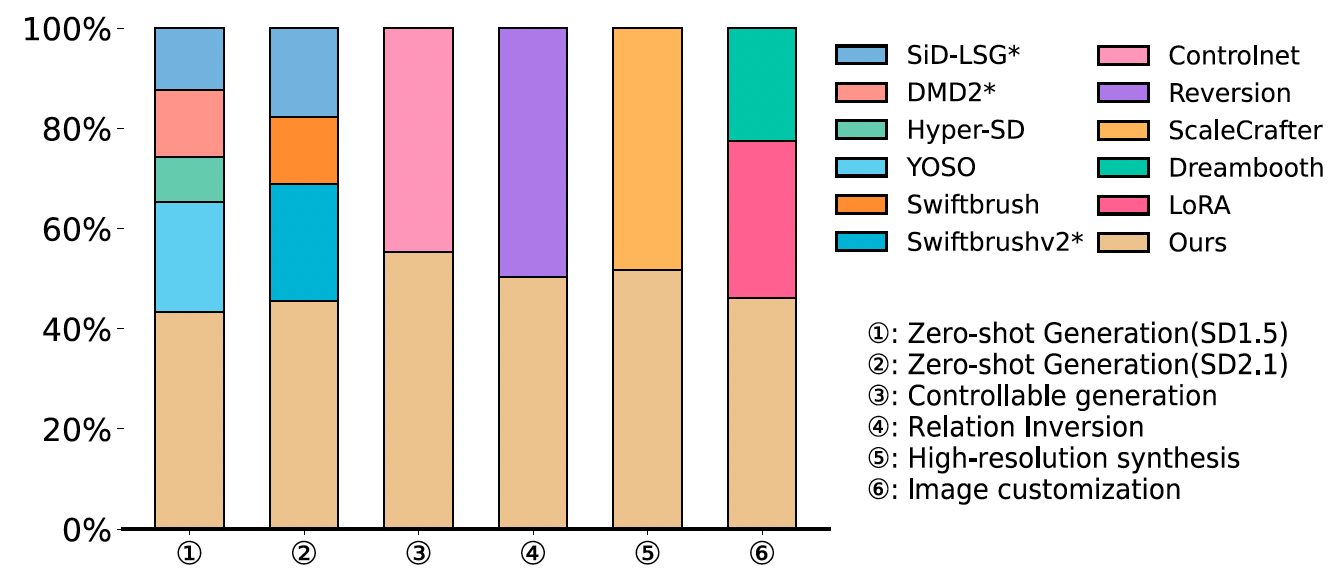
图9. 与其他方法相比的用户研究结果。
4.5 消融研究
表 2 在 COCO 2017 的 VSD 损失下比较了五种适配器类型。LoRaD 以最少 83.8M 可训练参数(比 LoRA/DoRA 少约 31%,比 FT 少约 90%)取得最低 FID(20.86)和竞争性 CLIP 分数(0.31)。它还取得最高的方向均值(2.89,而 FT 为 2.21%,LoRA/DoRA 变体为 ≤0.92%),表明在紧凑参数化下具有更广泛、更有效的更新方向空间。与 DoRA 和 DoRA(冻结范数)不同,后两者通过 LoRA 式加性更新对归一化权重后跟动态重归一化进行方向优化,LoRaD 直接将预训练权重参数化为低秩正交旋转,保留范数并纯在方向空间中操作。总体而言,LoRaD 展示了良好的质量-效率权衡。
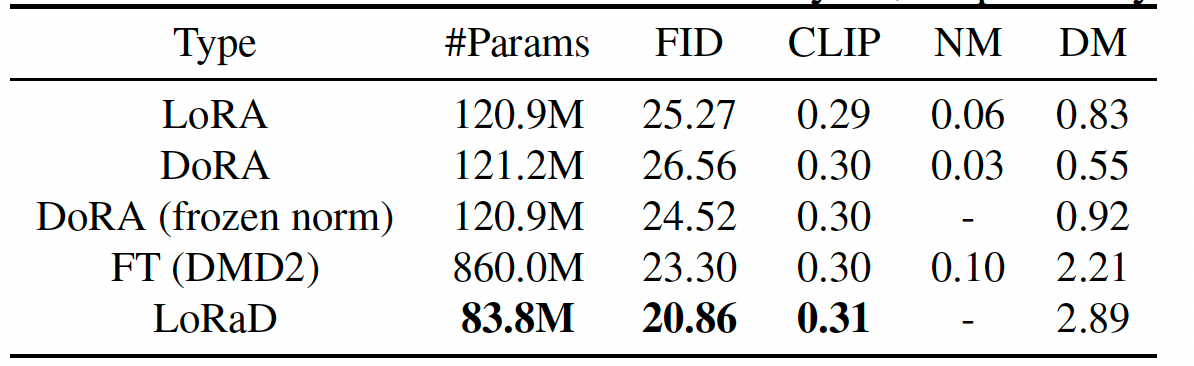
表2. 在 COCO 2017 数据集上,WaDi(SD 1.5,VSD 损失)中适配器类型影响的消融实验。"NM"和"DM"分别表示所有层的范数均值和方向均值。
我们在 COCO 2014 上进行了秩配置的消融研究。如表 3 所示,我们得出三个主要观察:1)增大学生秩可持续改善性能。将秩从设置 A 提升到 C,FID 从 13.64 降至 10.79,表明更高的秩使学生能够更好地捕捉教师分布,提升生成质量。2)超过阈值后继续增大秩会导致收益递减。对比设置 C 和 D,进一步增大秩导致 FID 退化(12.75 vs. 10.79),CLIP 也从 0.31 降至 0.30,表明过大的秩可能导致过拟合。3)虚假模型的秩对保真度的影响大于对齐度。调整虚假模型秩(设置 C、E、F)会改变 FID 但 CLIP 基本稳定,表明保真度对容量更敏感而对齐度较为稳健。综上,设置 C 在模型容量和性能之间取得了良好的权衡,与图 8 的定性结果一致。详见补充材料 G.2、G.4。
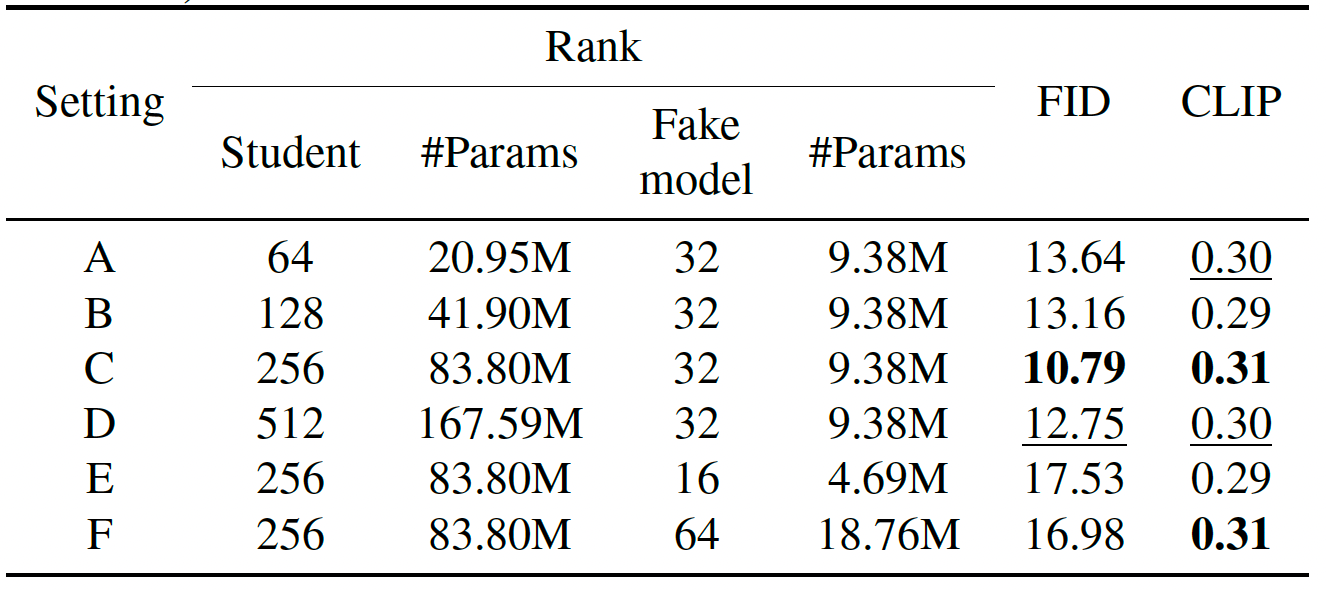
表3. 在 COCO 2014 数据集上,WaDi(SD 1.5,VSD 损失)中秩影响的消融实验。

图8. 不同设置下的一步图像生成结果。
5. 结论
本文提出了权重方向感知蒸馏(WaDi),一种高效的单步文本到图像蒸馏框架。通过对多步与单步模型权重变化的深入分析,我们发现权重方向的变化是蒸馏中的关键机制,而范数变化的作用相对次要。基于这一洞见,我们引入权重方向低秩旋转(LoRaD)模块,以参数高效的方式建模方向调整。大量实验表明,WaDi 在图像质量和推理速度上显著优于现有单步方法------包括 DMD、SiD-LSG 和 SwiftBrush。此外,蒸馏后的模型可无缝适配多种下游任务,展示了强大的泛化能力和实际适用性。本工作为高效扩散模型蒸馏提供了新颖的理论视角和实践方案。