标题:《ShapeR: Robust Conditional 3D Shape Generation from Casual Captures》
项目:facebookresearch.github.io/ShapeR
来源:Meta Reality Labs Research;Simon Fraser University
文章目录
- 摘要
- 一、相关工作
- [二、多模态条件流匹配(Multimodally Conditioned Flow Matching)](#二、多模态条件流匹配(Multimodally Conditioned Flow Matching))
- [三、两阶段的 Curriculum Learning](#三、两阶段的 Curriculum Learning)
- 四、推理
- 实验
摘要
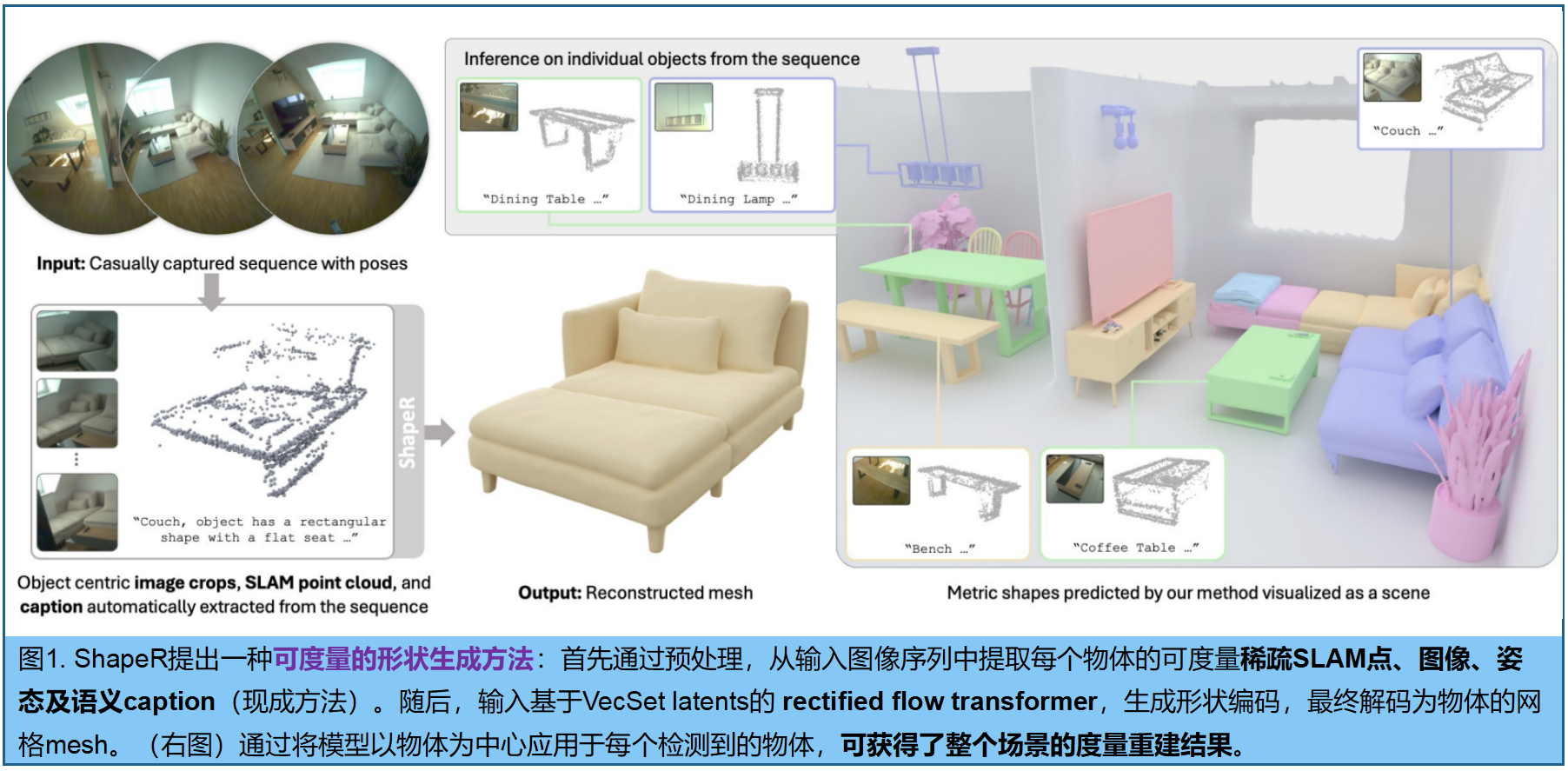
现有3D形状生成技术,大多依赖于清晰、无遮挡且分割良好的输入数据,在现实场景中往往难以满足。ShapeR ------利用随手拍摄的video,进行条件性三维物体mesh生成 。通过利用现成的视觉惯性SLAM(提取稀疏三维点云和相机位姿)、三维检测算法和视觉语言模型 ,为每个物体提取一组稀疏SLAM点、多视角构图图像及机器生成的描述文字。 作者利用custom dataset训练了一个 rectified flow transformer ,能从隐空间中回复物体的点云(哪怕有遮挡、不完整),能有效利用这些模态生成高保真度的三维形状。
为应对随手拍摄数据的挑战,我们采用了一系列技术手段 :包括实时组合增强、覆盖物体与场景级数据集的 curriculum训练方案(由易到难),以及处理背景杂乱的策略。此外,我们还引入包含178个真实场景中带几何标注的野外物体的全新评估基准。实验表明,ShapeR在这一具有挑战性的场景中显著优于现有方法,相比当前最佳方法(SoTA),其Chamfer距离指标提升了2.7倍。
一、相关工作
1.非对象为中心的重建
表面重建技术已通过学习型和优化型方法得到广泛研究19,20,35,37,58,69。近期提出的NeRF53、3DGS39及其扩展方法5,6,11,54,89虽能实现高保真视角合成,但更注重外观表现而非几何精度。基于SDF的隐式方法43,76,77,85,86在保持视角质量的同时提升了几何保真度。前馈式方法55,72,73,75,93通过姿态图像直接预测全局场景几何结构,有效降低了优化开销。但这些方法将场景重建为单一表面,导致被遮挡物体的几何信息不完整。相比之下,ShapeR通过序列显式进行物体级重建,能为每个物体生成完整的几何数据。
2.基于条件的对象重建
。早期研究探索了基于图像或点云的类别特定重构模型15,51,60,62。后续方法如Dreamfusion63及其扩展版本12,36,46,49,78,通过二维扩散模型实现文本驱动的形状生成,突破了固定类别的限制。大型重建模型32及其后续改进30,44,70,74实现了图像到三维的规模化重构,并整合了网格生成、纹理贴图和可重光照资产,这些技术均基于二维扩散先验。随着大规模数据集的出现21,原生三维扩散方法42,45,80,82,91,92进一步提升了图像还原的保真度。然而,多数方法需要干净且分割良好的输入数据,且缺乏来自单张图像的度量基准,即便是无模态方法81在真实场景中也表现欠佳。ShapeR的创新之处在于利用稀疏度量点云、带pose图像和标题的多模态条件,从而在遮挡、杂乱和视角变化等条件下实现稳健且度量精确的重建。
3.以对象为中心的场景重建
早期方法主要通过联合检测与补全16,33,67或CAD模型检索2,3,41来实现以物体为中心的场景重建,但往往导致几何结构不完整或不匹配。后续方法17,48,57尝试从单个视角重建单个物体及场景布局,但通常仅适用于特定类别。近期研究1,34,50,56,83,84通过引入扩散先验、开放词汇检测和生成模型来优化单体几何与场景组装,但往往依赖高质量的二维实例分割。虽然ShapeR侧重于以物体为中心而非联合场景重建,但它能基于现成检测器的点云裁剪生成三维度量形状,这些形状可组合用于场景级重建。与先前方法在真实场景中因机器生成分割质量下降而失效不同,ShapeR对不完美分割和复杂随意拍摄条件仍保持稳健性。
二、多模态条件流匹配(Multimodally Conditioned Flow Matching)
ShapeR将对象的形状生成建模为一种 校正流(rectified flow)过程,通过去除 3D VAE 学习到的潜在表征中的噪声来实现 。
3D VAE(变分自编码器):用于压缩点云、mesh 。具体采用VecSets90的Dora变体13作为潜在自编码器。给定网格S时,其生成两个点云:
- (i)均匀分布的表面点,用于捕捉整体几何特征,
- (ii)边缘显著点,用于捕捉精细细节。
压缩过程 :这两个点云分别经过交叉注意力机制、下采样、拼接处理,并通过自注意力机制进一步加工,最终生成潜在编码 z ∈ R L × d z∈ℝ^{L×d} z∈RL×d (其中L可变取值为{256,512 ,... ,4096},特征w维度d=64) 。解码器D通过与处理后的潜在序列进行交叉注意力,预测查询点 x ∈ R 3 x∈ℝ^3 x∈R3网格的带符号距离值 s = D ( z , x ) s=D(z,x) s=D(z,x)。该 VAE 训练公式:
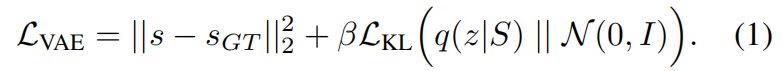
Rectified Flow Model。潜在分布 z ∼ q ( z ∣ S ) z∼q(z|S) z∼q(z∣S)作为流匹配的目标分布。训练一个去噪Transformer f θ f_θ fθ ,将高斯噪声 z 1 ∼ N ( 0 , I ) z_1∼N(0,I) z1∼N(0,I) 传输至潜在流形 z 0 z_0 z0,条件是多模态线索©:
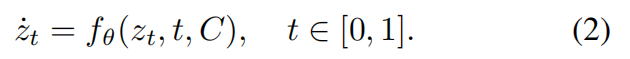
该训练目标:最小化模型预测传输速度与真实传输速度之间的期望平方误差:
我们采用一种类似FLUX.1的双单流Transformer8,其中前四个双层对文本标记进行交叉注意力,随后的双层和单层分别对图像和点标记进行交叉注意力。省略位置嵌入42,92。双流输出被拼接后,通过多个自注意力层进行后续处理。双流和单流模块均通过时间步长和CLIP64文本嵌入进行调制。
条件编码 。条件输入 C = C= C={ C p t s , C i m g , C t x t C_{pts},C_{img},C_{txt} Cpts,Cimg,Ctxt}分别包含三维SLAM点云、图像和描述文字。
- C p t s C_{pts} Cpts,采用ResNet31风格的三维稀疏卷积编码器将点特征降维为 token stream。
- C i m g C_{img} Cimg,冻结的DINOv259主干网络提取图像token,并与对应相机姿态的Plucker射线编码进行拼接。目标物体在各帧中观测到的三维点云被投影至二维空间形成二值点mask,经二维卷积提取器处理后与DINO及Plucker标记拼接。
- C t x t C_{txt} Ctxt,描述文字通过冻结的T5编码器65和CLIP64文本编码器进行token处理。值得注意的是,该方法未使用分割掩码,目标物体信息通过三维点标记和二维投影点掩码信息隐式学习获得。
三、两阶段的 Curriculum Learning
ShapeR需要学习不同类别的先验知识,来实现跨类别生成。
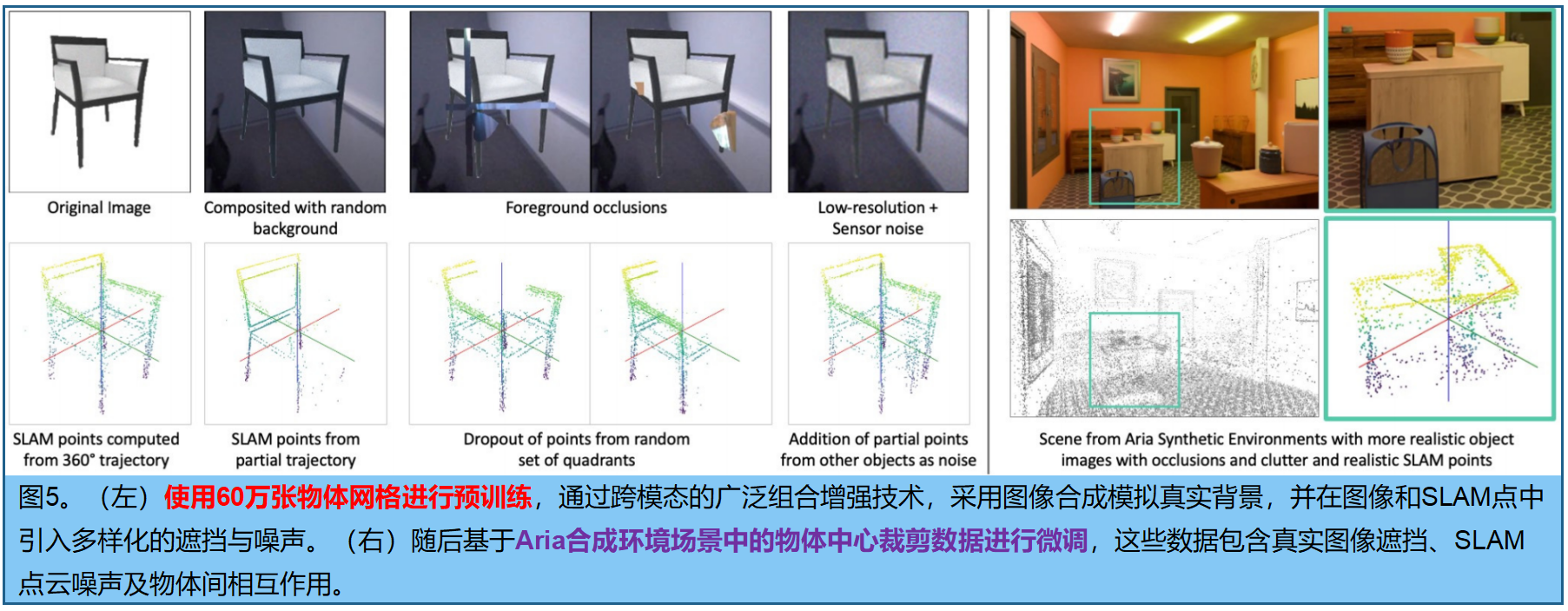
在第一阶段,使用由3D artists创建的包含超过60万张 不同语义类别网格的大型物体中心数据集进行预训练。为模拟真实场景中的噪声输入,我们对所有模态进行了大量增强处理(图5左),包括背景合成、遮挡叠加、可见雾、分辨率降级以及图像光度扰动。对于SLAM点云,我们模拟了部分轨迹、多种点缺失策略、高斯噪声和点遮挡。这些增强处理通过数据加载器实时组合应用,生成了近乎无限的训练样本流。虽然这一阶段教会了模型通用的形状先验,但未能完全反映真实拍摄的复杂性。
因此, 在第二个数据集上对模型进行微调,该数据集由Aria合成环境4提取的物体裁剪图像组成。尽管数据集多样性较低,但其真实遮挡效果、物体间交互和SLAM噪声模式(图5右)仍具有高度还原性。
四、推理
给定一组带位姿图像序列 I = I 1 , . . . , I K I = I^1,... ,I^K I=I1,...,IK及其对应的相机内参与外参 Π = Π 1 . . . , Π K Π = Π^1 ... ,Π^K Π=Π1...,ΠK ,
1.首先通过跟踪和三角化高梯度图像区域,来计算稀疏度量点云 P P P 。这不仅提供了三维点位信息,还建立了帧间可见性关联,表示为 P I k ⊆ P P_{I^k} ⊆ P PIk⊆P,即在第k帧中观测到的点子集。
2.随后对图像和点云应用实例检测模型 72,预测物体实例的三维边界框。针对每个物体 i i i,使用SAM266在边界框内refine 对应的点集 P i ⊂ P P_i ⊂ P Pi⊂P,以去除邻近实例的伪样本。
3.通过点-帧关联 P I k P_{I^k} PIk,识别出物体 i i i可见的所有帧 ,并选取固定数量 N N N个代表性帧 I i I_i Ii。对于每个选定帧 I i j I_i^j Iij,将点集 P i ∩ P I j P^i ∩ P_{I^j} Pi∩PIj 投影到图像平面生成二值掩模 M i Mi Mi,近似该视角下的物体轮廓。
4 .接着在每个物体的代表性图像上调用视觉-语言模型52生成描述性caption T i T_i Ti。
最终为物体 i i i构建完整的条件集 C i = C_i= Ci={ P i , I i , Π i , M i , T i P_i,I_i,Π_i,M_i,T_i Pi,Ii,Πi,Mi,Ti}。生成前,每个物体的点云 P i P_i Pi需归一化至归一化设备坐标立方体-1,1³。流匹配模型在该归一化空间内预测物体形状,重构的网格被重新缩放回原始 P i P_i Pi度量坐标系,确保物理尺寸的准确性。采样过程通过整合学习到的流进行:
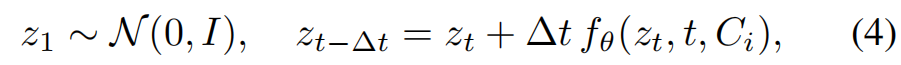
采用midpoint采样法。最终网格重构为:
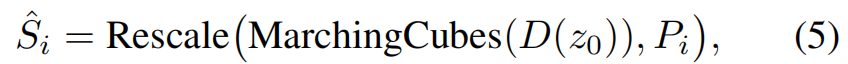
为每个检测到的物体 i i i 生成度量一致且完全重建的网格,其尺寸与输入序列的实际尺度和位置对齐
实施细节。点云数据通过SLAM或SfM技术从图像中提取,具体采用Project Aria's Machine Perception Services 28提供的半稠密点云,该数据由Aria单色相机与惯性测量单元(IMU)组成的视觉-惯性SLAM系统获取。训练阶段采用每个对象随机选取的两个视角进行预处理,推理阶段则使用Aria Mono场景SLAM相机提供的最高16个选定视角(分辨率280×280像素)。
实验
在一个新型高质量数据集 上评估并消融了ShapeR的关键组件,与九种领先的3D重建和生成方法进行对比,这些方法根据其利用的输入类型和重建任务的性质进行分组。
shapeR评估数据集。尽管目前存在多个用于3D重建基准测试的数据集7,10,18,21,23,25,40,87,但多数数据集在真实感或完整性方面存在局限。
- 合成数据集如ShapeNet10和Objaverse21,22虽能提供大规模覆盖,却缺乏现实世界的复杂性。
- 受控数据集如 DTC 23、GSO25和StanfordORB40主要聚焦于摄影棚环境中的孤立桌面物体。
- 野外数据集如ScanNet18、ScanNet++87和ARKitScenes7虽能提供逼真影像,却缺乏完整的物体级3D几何结构用于评估(图10)。
为填补这些空白,我们推出ShapeR评估数据集 ,旨在挑战日常拍摄条件下重建性能的基准测试。该数据集包含来自不同杂乱场景的7组日常拍摄记录,标注了178种多样化的高质量物体 形状。涵盖范围广泛,从家具等大型物体到遥控器、烤面包机和工具等小型物品,如图6、7、11和12所示。针对每个序列,提供多视角图像、校准后的相机参数、SLAM点云以及机器生成的物体描述 。每个标注对象均包含一个完整的参考网格,该网格采用理想条件下生成的 internal image-to-3D 建模方法创建,并经人工精修与重新对齐以确保几何形状和姿态的一致性。、
评估指标 。采用3种互补指标对重建几何结构进行评估,参照先前研究62,69,70:倒角 ℓ2 距离(CD)、法线一致性(NC)以及 F-score(F1),阈值设为1%。所有指标均在归一化坐标空间中计算。
代码实现
由于算法输入的数据,严重依赖于硬件,暂时无法使用自建数据集。只能直接下载作者提供的pkl文件: