目录
[Stable Diffusion 介绍](#Stable Diffusion 介绍)
[Stable Diffusion 概述](#Stable Diffusion 概述)
[Stable Diffusion 架构](#Stable Diffusion 架构)
[1. 模块划分:](#1. 模块划分:)
[2. U-NET结构:](#2. U-NET结构:)
[3. DIT结构:](#3. DIT结构:)
[1. 文生图:](#1. 文生图:)
[2. 图生图:](#2. 图生图:)
[3. 图像重绘:](#3. 图像重绘:)
[4. 可控生成](#4. 可控生成)
[Stable Diffusion 在 InfiniTensor 推理框架中的适配](#Stable Diffusion 在 InfiniTensor 推理框架中的适配)
[1. 环境搭建](#1. 环境搭建)
[2. 模型下载](#2. 模型下载)
[3. 模型导出为 ONNX 文件](#3. 模型导出为 ONNX 文件)
[4. 模型预处理](#4. 模型预处理)
本文介绍 Stable Diffusion 的基本概念、工作原理及其在 InfiniTensor 推理框架中的适配。
Stable Diffusion 介绍
Stable Diffusion 概述
-
• 定义: 基于扩散模型的生成式人工智能技术,主要用于文本生成图像,支持图像生成图像、局部重绘等多种任务。
-
• 特点: 通过潜在空间逐步去噪,将随机噪声还原为高质量图像,降低计算成本,支持在普通消费级 GPU 上运行。
-
• 应用领域: 艺术创作、游戏与影视、广告设计、科研探索等。
扩散模型概念
-
• 正向扩散: 从有序到无序的固定加噪过程,由预定义的噪声调度控制。
-
• 反向扩散: 从无序到有序的去噪过程,模型学习如何逐步去除噪声。
-
• DDPM论文: 介绍扩散模型的鼻祖,提及正向和反向扩散的步骤数。
Stable Diffusion 架构
1. 模块划分:
-
• 文本语义编码: 将自然语言描述转化为数值表示,建立文本与图像的语义对齐。
-
• 迭代去噪生成: 在潜在空间中逐步处理扩散信息,通过 U-NET+Scheduler 结构实现。
-
• 空间重建解码: 使用 VAE Decoder 将潜空间运算结果解码成实际图片。
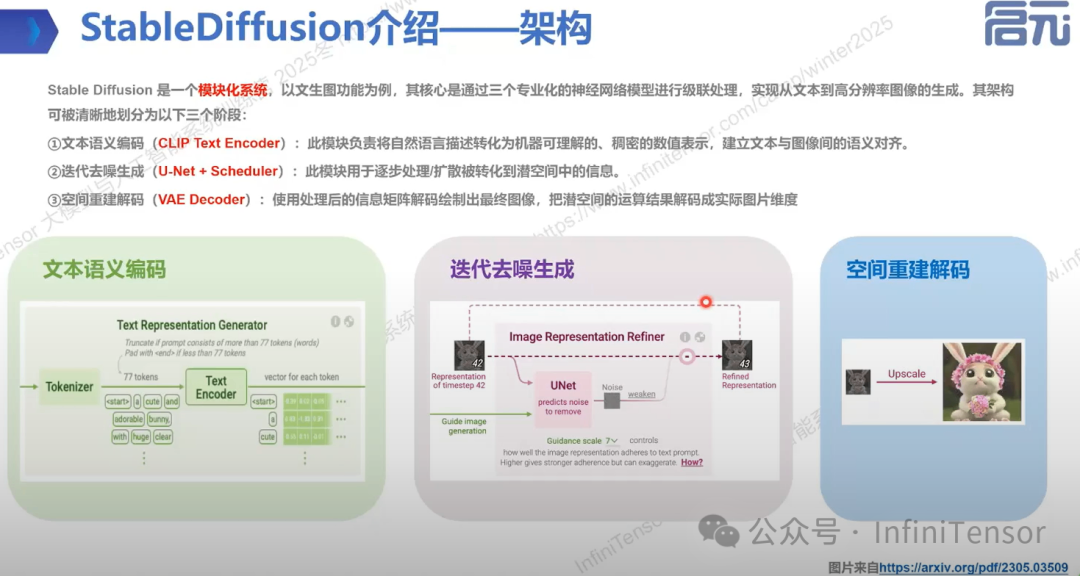
2. U-NET结构:
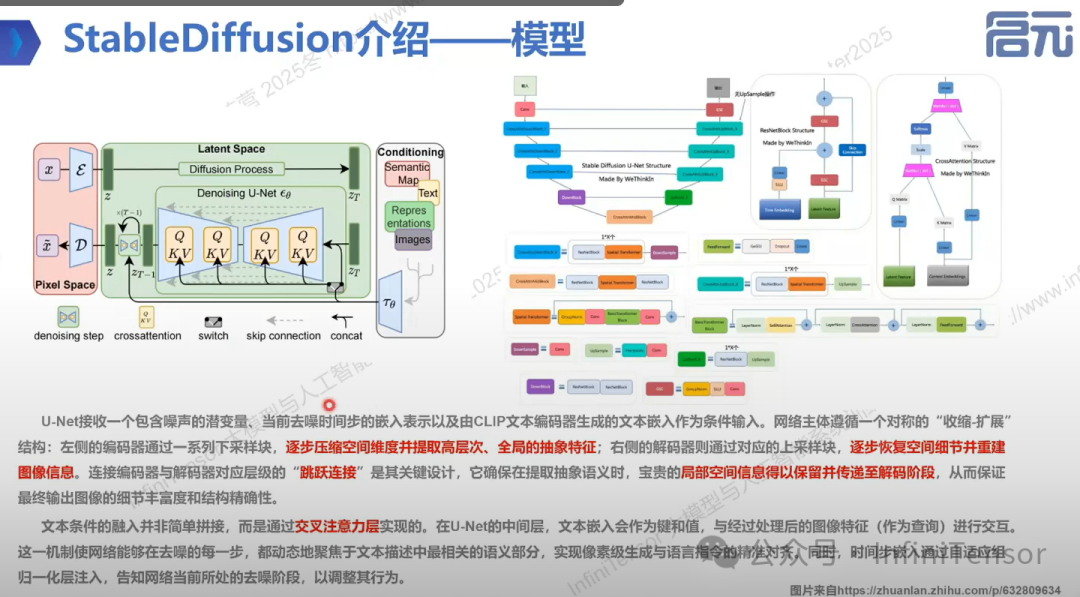
3. DIT结构:
DiT 采用纯 Transformer 结构作为去噪网络,与 Stable Diffusion 中常见的 U-Net 架构不同,代表了扩散模型在结构设计上的另一条技术路线。
工作流
1. 文生图:

2. 图生图:
-
• 图像输入:通过 VAE Encoder 将输入图像转化为潜变量。
-
• 噪声注入:在特定时间步加入高斯噪声。
-
• 迭代去噪:复用文生图的去噪过程,结合文本条件预测噪声。
-
• 图像生成:通过 VAE Decoder 生成新图像。
3. 图像重绘:
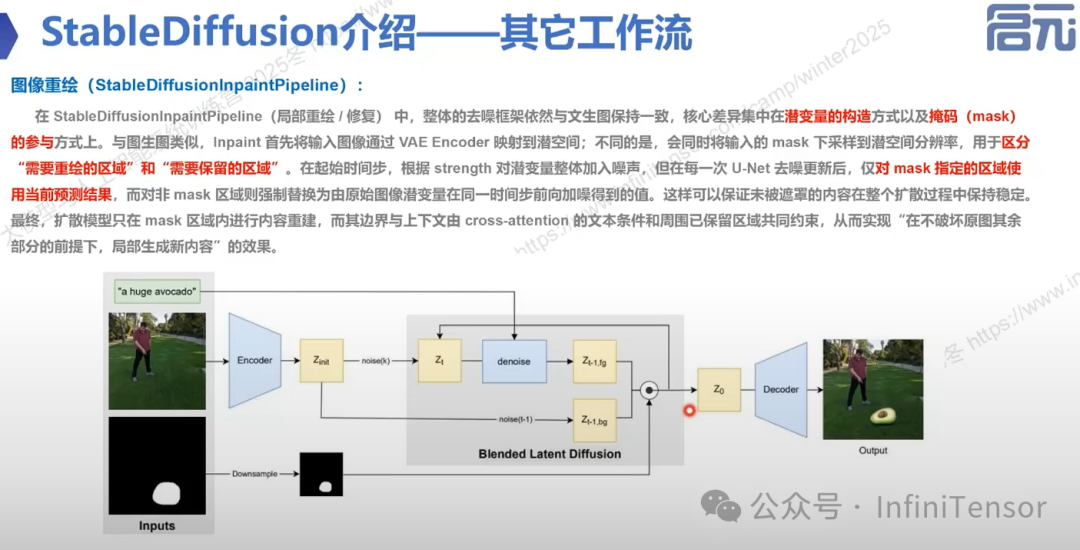
4. 可控生成

-
• 控制图提取:从输入图像中提取边缘检测图、人体姿态图等控制图。
-
• 条件注入:通过零卷积将控制图信息注入到 U-NET 结构中,实现语义和结构的双重控制。
Stable Diffusion 在 InfiniTensor 推理框架中的适配
推理前准备
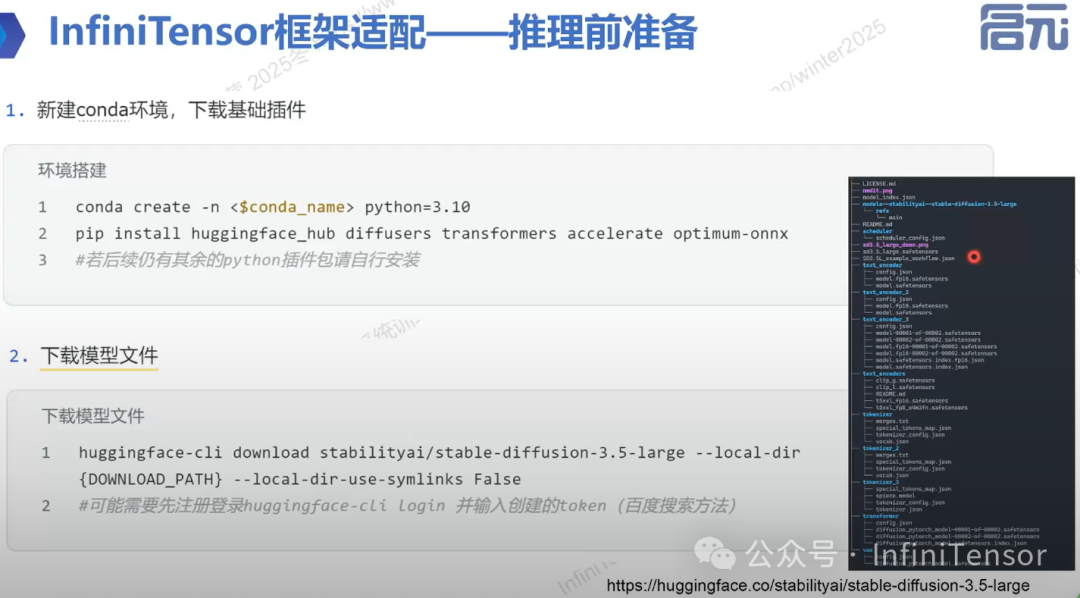
1. 环境搭建
2. 模型下载
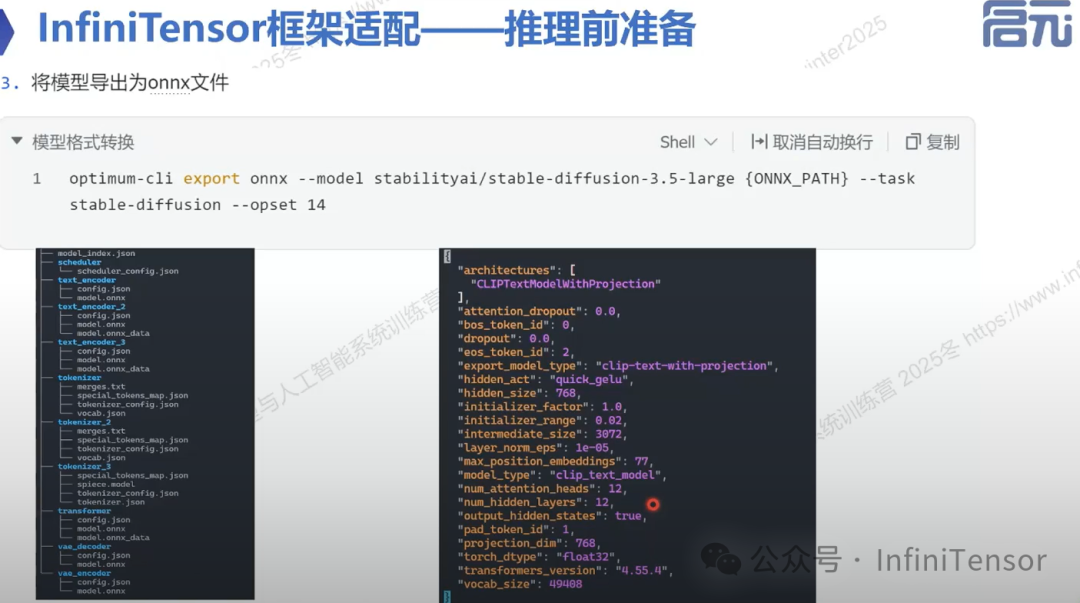
3. 模型导出为 ONNX 文件
4. 模型预处理
推理过程
- • 1. 输入准备: 创建批处理输入字典,指定prompt、batchsize、steps、guidance scales 等参数。

-
• 2. 初始化常量参数: 从 diffuser 库中获取潜在空间大小、是否做 CFG 操作、潜在空间通道维度等参数。
-
• 3. 模型初始化: 根据配置文件初始化文本编码器、U-NET/DIT 模块、tokenizer、scheduler等。

-
• 4. 推理执行:
-
• 文本预处理:调用文本编码器(在部分模型配置下可能包含多个编码器)提取文本特征,并进行必要的特征对齐。

-
• 时间步生成:根据输入步骤数生成时间序列。
-
• 潜在变量初始化:随机生成潜在空间变量。
-
• 迭代去噪:根据时间步和文本嵌入,逐步去除噪声,更新潜在变量。
-
• 图像生成:通过 VAE Decoder 生成最终图像,进行后处理(如颜色空间转化和归一化逆变换)。
结果展示

总结
本文详细讲述了 Stable Diffusion 的基本概念、工作原理及其在 InfiniTensor 推理框架中的适配过程。通过这节课让大家理解 Stable Diffusion 这一类的模型的整个工作流。