ELK 是一套日志采集、处理、存储、分析可视化的完整工具链,由 Elasticsearch、Logstash、Kibana 三个核心组件组成,加上 Filebeat 就构成了现在主流的 ELK Stack(也叫 Elastic Stack)
1. 日志采集:Filebeat 从业务服务器拉取日志
- 监听
/var/log/nginx/access.log和/var/log/nginx/error.log文件 - 实时读取新写入的日志,给日志打上
host、tags等元数据(比如tags: ["access"]) - 把日志通过
5044端口发送给 Logstash
2. 日志处理:Logstash 清洗和分流数据
Logstash 是整个流程的 "大脑",分为 3 个阶段:
- Input(输入) :接收 Filebeat 发来的日志(监听 5044 端口),同时也能读取本地
/var/log/messages系统日志 - Filter(过滤) :
- 统一字段:把不同来源日志的主机名,归一化成
hostname字段 - 结构化解析:用
grok把 Nginx 日志的message拆分成remote_addr、status、path等字段 - 数据清洗:过滤掉无用日志、格式转换
- 统一字段:把不同来源日志的主机名,归一化成
- Output(输出) :根据
hostname和tags分流logstash主机的系统日志 → 写入system-log-*索引server1的 access 日志 → 写入server1-nginx-access-log-*索引server1的 error 日志 → 写入server1-nginx-error-log-*索引
3. 数据存储:Elasticsearch 持久化存储日志
Logstash 把处理好的日志,通过 9200 端口写入 Elasticsearch:
- 按日期自动创建索引(比如
server1-nginx-access-log-2026.05.19) - 支持全文检索、按字段筛选、聚合统计,是整个流程的 "数据仓库"
4. 可视化分析:Kibana 操作日志数据
你在 Kibana 里看到的日志,就是从 Elasticsearch 中读取的:
- Discover :按时间、字段筛选日志,排查问题(比如你刚才看到的
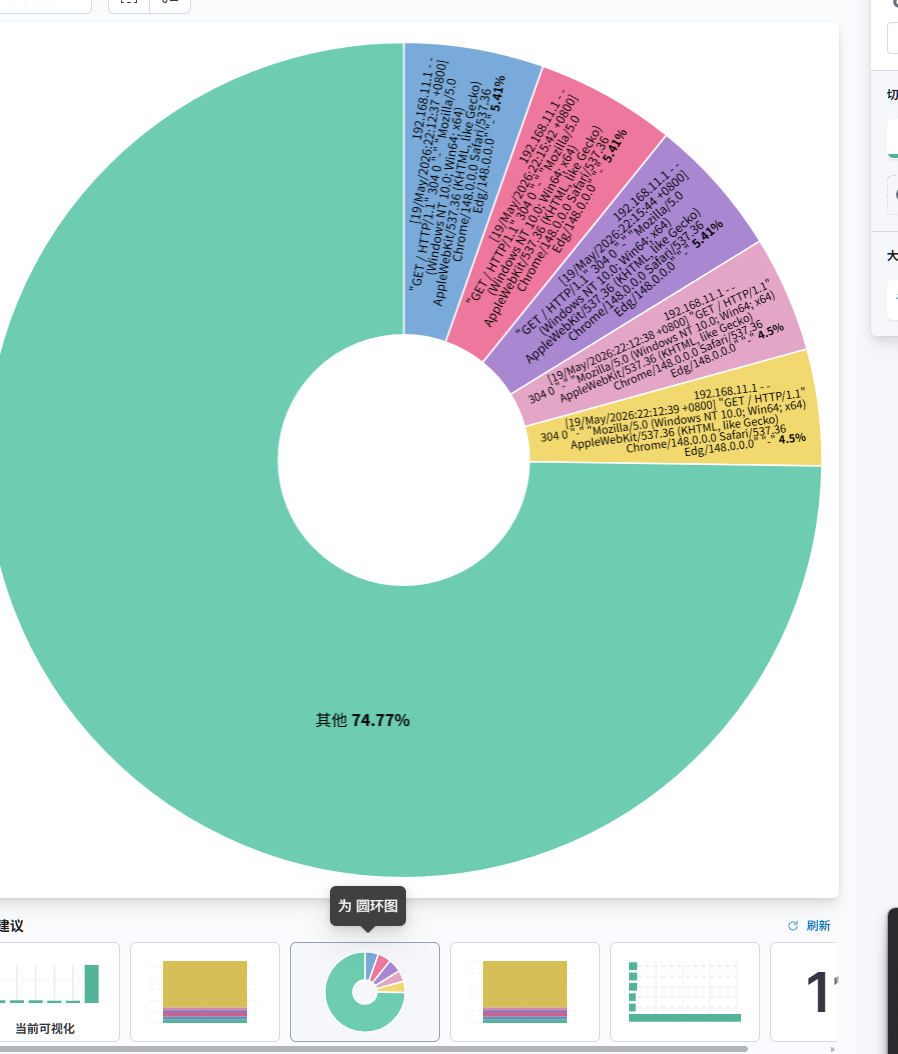
favicon.ico错误) - Visualize:制作柱状图、饼图,分析 Nginx 状态码占比、热门请求路径
- Dashboard:把多个图表组合成监控大盘,实时展示业务访问情况
Elasticsearch+Logstash+Filebeat+Kibana部署
创建es节点
编写文件vim /etc/host
下载环境 yum install -y lrzsz
拉入准备好的压缩包
rpm -ivh elasticsearch-7.17.3-x86_64.rpm
rpm -ivh logstash-7.17.3-x86_64.rpm
rpm -ivh kibana-7.17.3-x86_64.rpm
rpm -ivh filebeat-7.17.3-x86_64.rpm
依次在每个节点安装
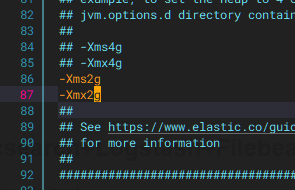
设置JVM最大堆内存大小 和初始堆内存大小 为 2GB,vim /etc/elasticsearch/jvm.options
vim /etc/elasticsearch/elasticsearch.yml
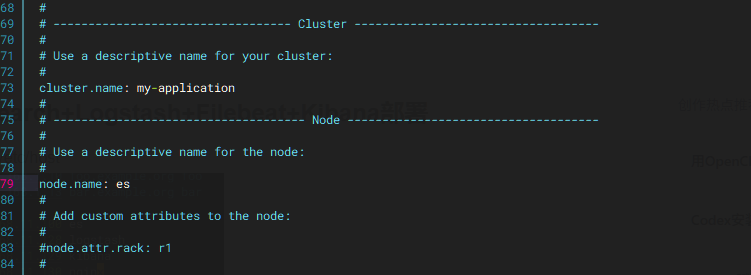
打开集群名 ,更改节点名
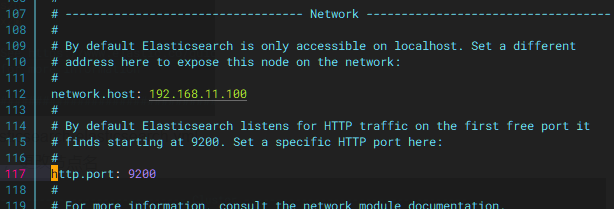
打开网络IP并更改为本机IP ,打开端口号
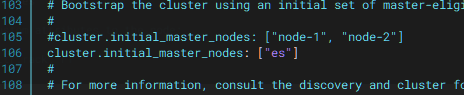
写入本节点名
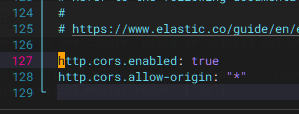
在末尾加入,解决跨域问题
启动服务systemctl enable --now elasticsearch.service
会启两个端口 一个9200是数据传输端口, 另一个9300是集群内部通信端口

查看集群健康状态
curl -XGET "192.168.11.100:9200/_cluster/health?pretty"
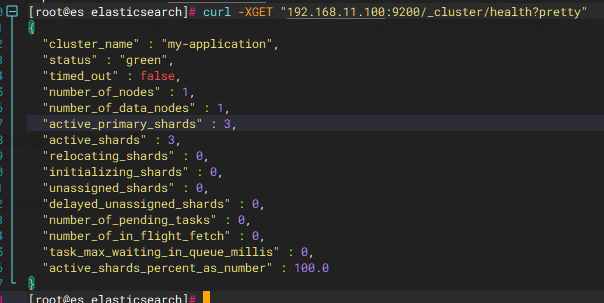
!!!green代表可用 yellow表有警告 red代表不可用!!!
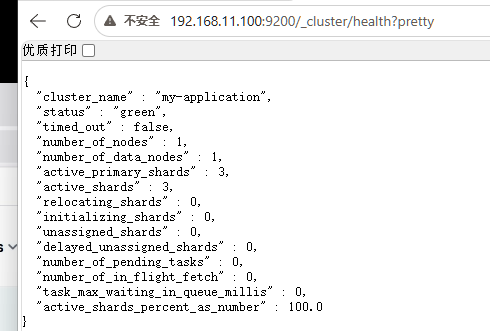
网页也可以访问:192.168.11.100:9200/_cluster/health?pretty
查看节点状态192.168.11.100:9200/_cat/nodes?v

创建logstash节点
vim /etc/host
更改主机名vim /etc/logstash/logstash.yml
更改监听地址和监听端口范围
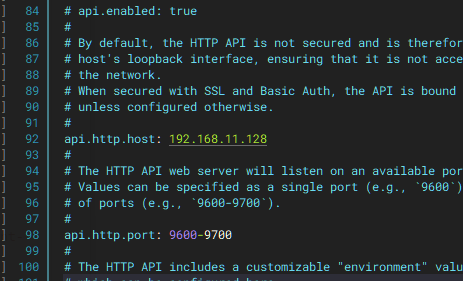
命令链接命名ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
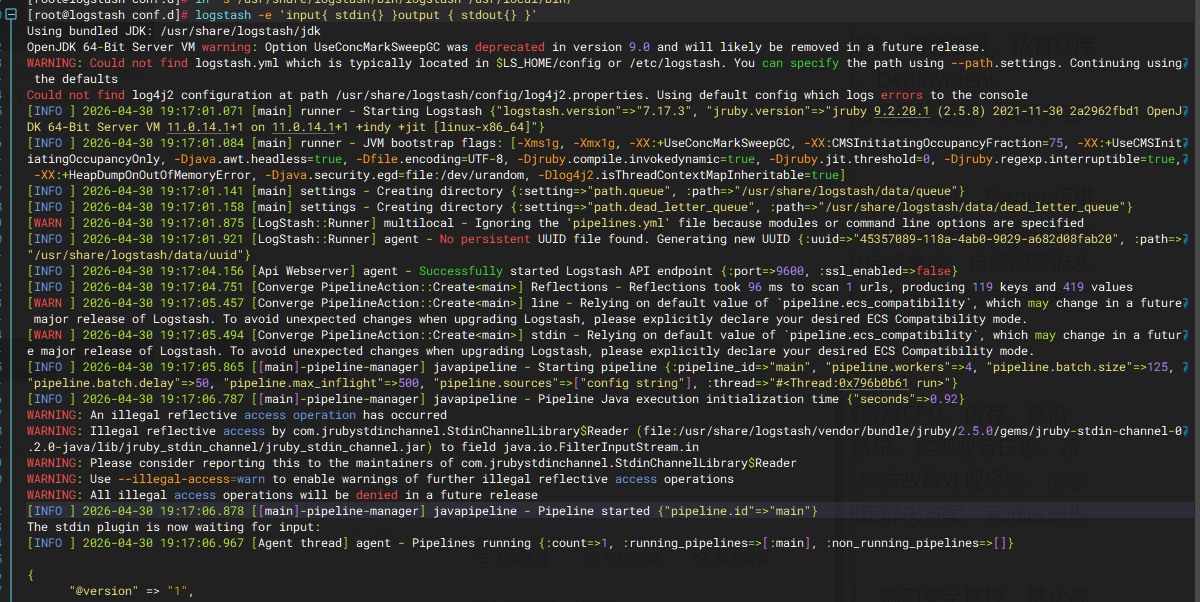
标准输入与输出测试命令:logstash -e 'input{ stdin{} }output { stdout{} }'
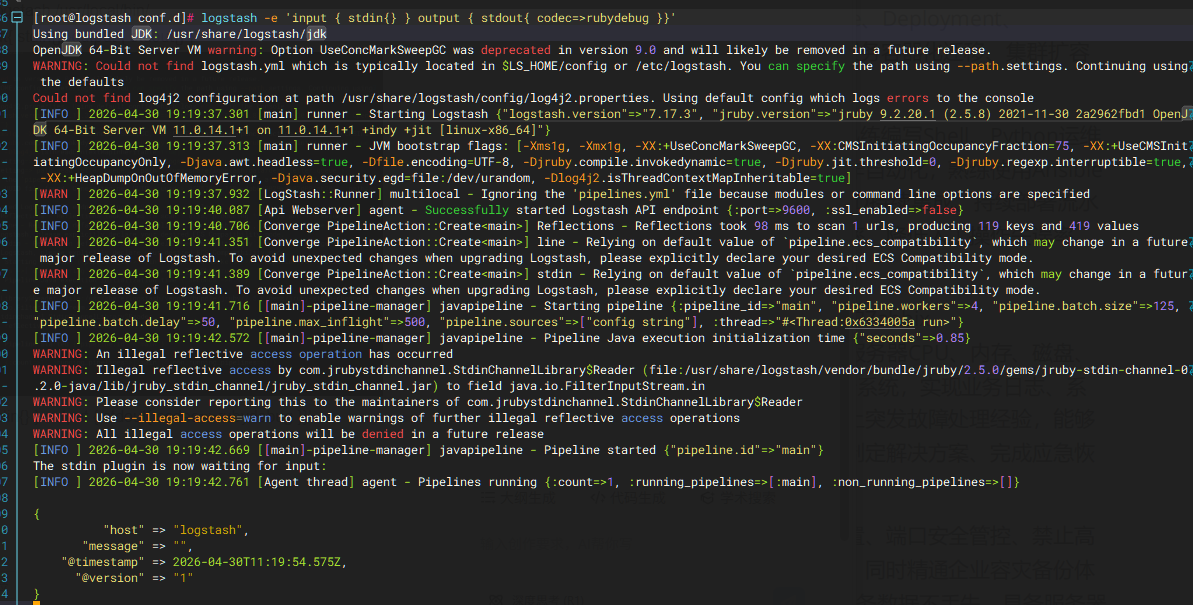
使用rubydebug解码:logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'
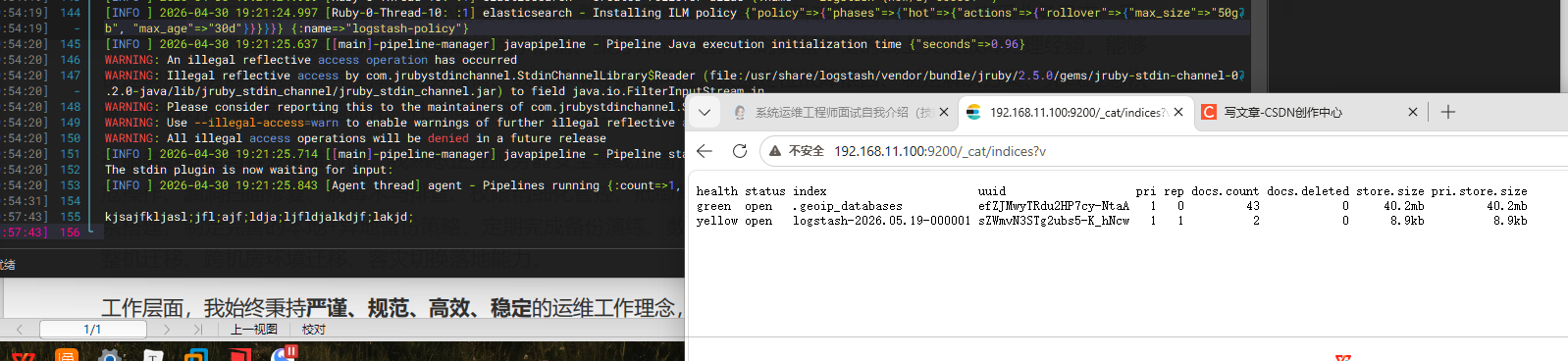
输出到elasticsearch节点IP:logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>"192.168.11.100:9200"} }' 在网页查看索引

继续在logstash节点编写,数据大小变化,证明连接正常
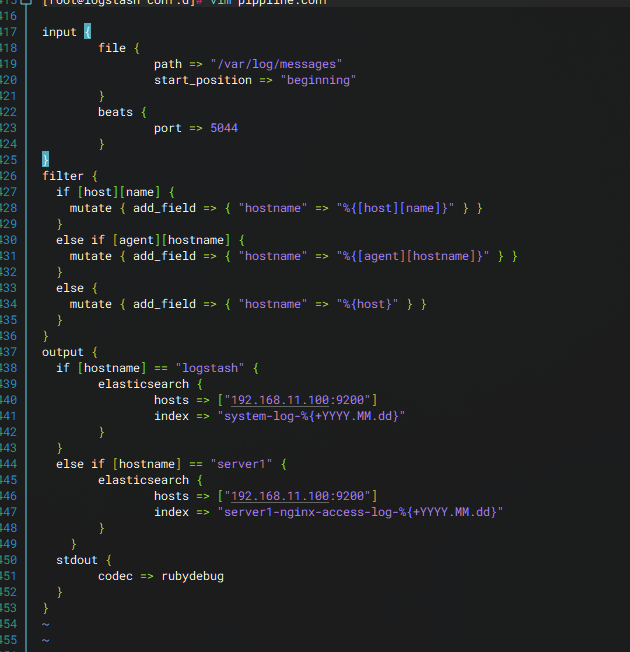
验证**收集不同主机及对应应用的不同日志 **创建文件vim /etc/logstash/conf.d/pipeline.conf
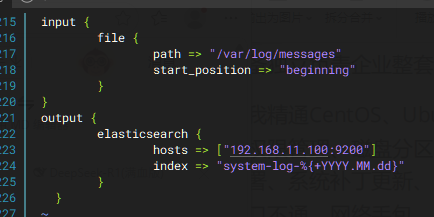
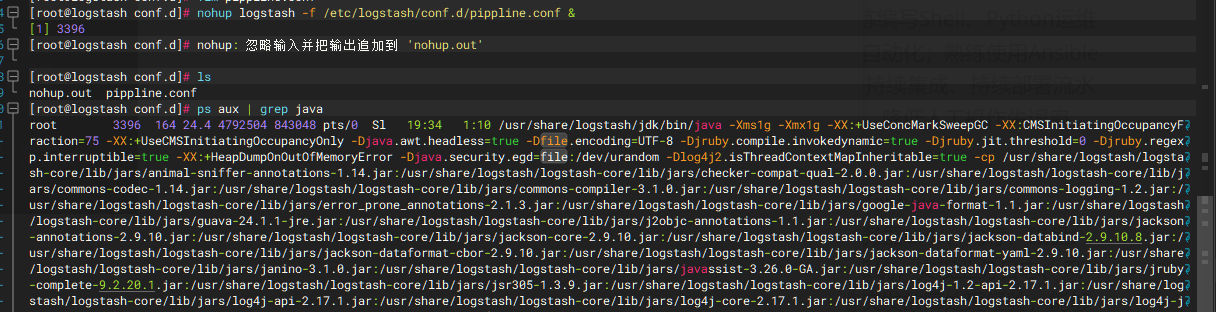
启动命令:nohup logstash -f /etc/logstash/conf.d/pipeline.conf &

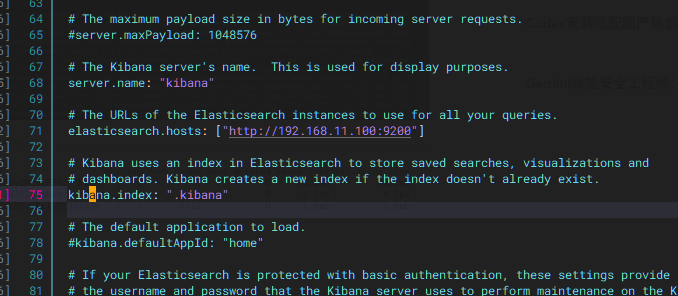
在kibana节点
写当前节点IP地址,节点名,写es节点IP地址和端口,打开kibana的索引

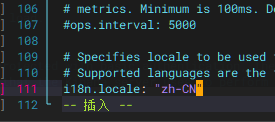
打开汉化
启动服务:systemctl enable --now kibana.service
在nginx节点
下载:yum install -y nginx
在logstash节点停掉

开启输入路径, 写上需要的日志地址
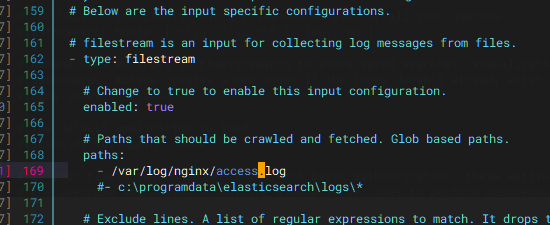
编写logstash节点:vim /etc/logstash/conf.d/pipeline.conf
在logstash节点执行:logstash -f /etc/logstash/conf.d/pipeline.conf
在server1节点执行:
如果要分别记录索引:vim /etc/filebeat/filebeat.yml
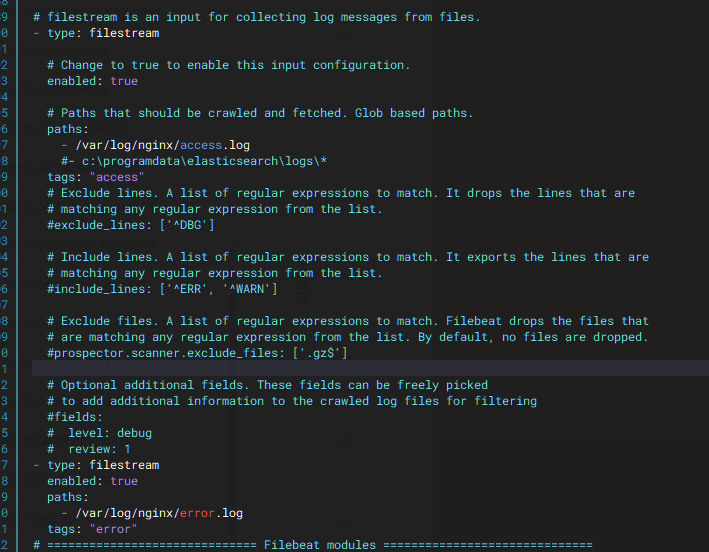
重启服务:systemctl restart filebeat.service
在logstash节点执行 vim /etc/logstash/conf.d/pipeline.conf
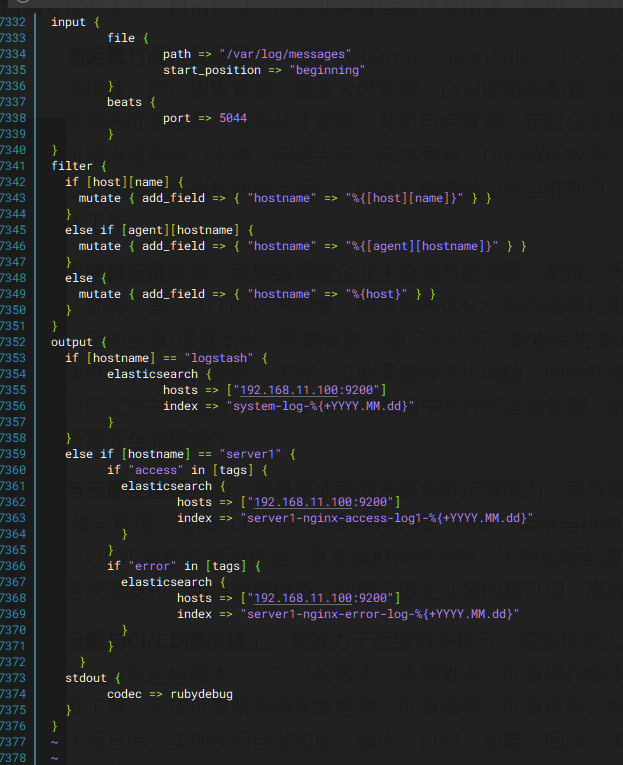
logstash -f /etc/logstash/conf.d/pipeline.conf