在一个二维平面中 存在多个障碍点 我们要找到一个最大的矩形 使得这个矩形面积最大并且不能包含任何障碍点 这一类问题叫做最大子矩形问题
对于不同的数据范围 和 图的类型 (密集图/稀疏图) 我们有不同的算法
先看最基础的:
1.单调栈
对于小数据范围的密集图 我们可以对每一行数据进行处理 然后对每一行进行单调栈 找到最大子矩形
例题:
P4147 玉蟾宫
时间限制: 1.00s 内存限制: 512.00MB
复制 Markdown
中文
退出 IDE 模式
题目背景
有一天,小猫 rainbow 和 freda 来到了湘西张家界的天门山玉蟾宫,玉蟾宫宫主蓝兔盛情地款待了它们,并赐予它们一片土地。
题目描述
这片土地被分成 N×M 个格子,每个格子里写着 R 或者 F,R 代表这块土地被赐予了 rainbow,F 代表这块土地被赐予了 freda。
现在 freda 要在这里卖萌。。。它要找一块矩形土地,要求这片土地都标着 F 并且面积最大。
但是 rainbow 和 freda 的 OI 水平都弱爆了,找不出这块土地,而蓝兔也想看 freda 卖萌(她显然是不会编程的......),所以它们决定,如果你找到的最大的土地面积为 S,它们每人给你 S 两银子。
输入格式
第一行两个整数 N,M,表示矩形土地有 N 行 M 列。
接下来 N 行,每行 M 个用空格隔开的字符 F 或 R,描述了矩形土地。
输出格式
输出一个整数,表示你能得到多少银子,即 3×S 的值。
输入输出样例
输入 #1复制运行
5 6
R F F F F F
F F F F F F
R R R F F F
F F F F F F
F F F F F F输出 #1复制运行
45说明/提示
对于 50% 的数据,1≤N,M≤200。
对于 100% 的数据,1≤N,M≤1000。
根据题目 我们要选择一个矩形区域 使得这一部分全是F 也就是不能有R障碍点 并且这一部分的面积最大 我们可以预处理每一行数据 计算出这一列往上的最大合法高度 然后每一行进行单调栈 找出最大矩形 得出答案
这种算法只能处理小数据的密集图
cpp
#include <bits/stdc++.h>
using namespace std;
const int N=1005;
char g[N][N];
int s[N][N];
int st[N],p,w[N];
int res,n,m;
int work(int x){
p=0;s[x][m+1]=0;
memset(st,0,sizeof st);
int res=0;
for(int i=1;i<=m+1;i++){
if(st[p]<=s[x][i]){
st[++p]=s[x][i];w[p]=1;
}else {
int width=0;
while(st[p]>s[x][i]){
width+=w[p];
res=max(res,width*st[p]);
p--;
}
st[++p]=s[x][i];w[p]=width+1;
}
}
return res;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin>>n>>m;
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
cin>>g[i][j];
if(g[i][j]=='F')s[i][j]=s[i-1][j]+1;
else s[i][j]=0;
}
}
int ans=0;
for(int i=1;i<=n;i++){
ans=max(ans,work(i));
}
cout<<3*ans<<'\n';
return 0;
}2.枚举所有的有效极大矩形
我们要不断优化枚举思路 使得所有被枚举的矩形都是极大化矩形 也就是没有更大的矩形可以完全包含他 只要保证每次枚举都是有效的 不是无用功 才有可能不会超时
从极大化矩形的特征入手
不难发现:每个极大化矩形的每条边都有一个障碍点或者与矩形的边界重合
为了方便处理 我们把矩形的四个顶点也设置为障碍点 方便处理边界
思路一: 枚举四个边界 并且判断枚举的矩形中是否有障碍点 很明显是o(n^5)的算法 复杂度过高 不能实现;
思路二:考虑只枚举左右边界 对于已经确定的左右边界 我们只需要将这两个边界中间的点从上到下排序 相邻两个障碍点之间的举例就是矩形的另一条边权 时间复杂度o(n^3)依旧难以实现 并且这种枚举不一定能保证所有的矩形都是极大矩形 如图:每一个格都代表一个矩形 但不一定是极大的 所以还有优化的余地
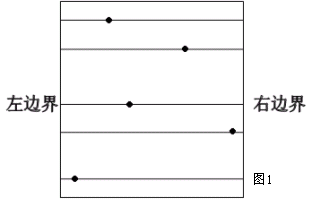
思路三:我们可以先枚举某个点 然后以这个点作为左边界 从左到右枚举其他点 上下边界默认为上界限和下界限 当枚举到第二个点的时候 这个点就是右边界 然后上下界不变 当枚举第三个点的时候 第三个点为右边界 第二个点如果在左边界那个点的下方 这个点就更新为下边界 同理 如果是上方就更新为上边界 依次类推
这样并没有枚举出所有矩形 我们还要考虑左右为边界的情况
一种是左边界与整个举行的左边界重合,而右边界覆盖了一个障碍点的情况 这种明显可以用类似上方的思路实现 只不过从右边往左搜索一遍
另一种是左右边界均与整个矩形的左右边界重合的情况,对于这类情况我们可以在预处理中完成:先将所有点按纵坐标排序,然后可以得到以相邻两个点的纵坐标为上下边界,左右边界与整个矩形的左右边界重合的矩形,显然这样的矩形也是极大子矩形,因此也需要被枚举到
加了整个矩形右上角和右下角的两个点,所以不会遗漏右边界与整个矩形的右边重合的极大子矩形 。
时间复杂度为o(n^2) 这里的n为障碍点的个数
P1578 WC2002 奶牛浴场
时间限制: 1.00s 内存限制: 125.00MB
复制 Markdown
中文
退出 IDE 模式
题目描述
由于 John 建造了牛场围栏,激起了奶牛的愤怒,奶牛的产奶量急剧减少。为了讨好奶牛,John 决定在牛场中建造一个大型浴场。但是 John 的奶牛有一个奇怪的习惯,每头奶牛都必须在牛场中的一个固定的位置产奶,而奶牛显然不能在浴场中产奶,于是,John 希望所建造的浴场不覆盖这些产奶点。这回,他又要求助于 Clevow 了。你还能帮助 Clevow 吗?
John 的牛场和规划的浴场都是矩形。浴场要完全位于牛场之内,并且浴场的轮廓要与牛场的轮廓平行或者重合。浴场不能覆盖任何产奶点,但是产奶点可以位于浴场的轮廓上。
Clevow 当然希望浴场的面积尽可能大了,所以你的任务就是帮她计算浴场的最大面积。
输入格式
输入文件的第一行包含两个整数 L 和 W,分别表示牛场的长和宽。
文件的第二行包含一个整数 n,表示产奶点的数量。
以下 n 行每行包含两个整数 x 和 y,表示一个产奶点的坐标。
输出格式
输出文件仅一行,包含一个整数 S,表示浴场的最大面积。
输入输出样例
输入 #1复制运行
10 10
4
1 1
9 1
1 9
9 9输出 #1复制运行
80说明/提示
对于所有数据,0≤n≤5×103,1≤L,W≤3×104。所有产奶点都位于牛场内,即:0≤x≤L,0≤y≤W。
感谢 @凯瑟琳98 提供了 4 组 hack 数据。
按照上述思路实现即可
cpp
#include <bits/stdc++.h>
using namespace std;
const int N=5e3+5;
int l,w,n;
struct node{
int x,y;
}a[N];
bool cmp1(node a,node b){
if(a.y!=b.y)return a.y<b.y;
return a.x<b.x;
}
bool cmp2(node a,node b){
if(a.x!=b.x)return a.x<b.x;
return a.y<b.y;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin>>l>>w;
cin>>n;
for(int i=1;i<=n;i++)cin>>a[i].x>>a[i].y;
a[++n]={0,0};
a[++n]={0,w};
a[++n]={l,0};
a[++n]={l,w};
sort(a+1,a+1+n,cmp1);
int ans=0;
for(int i=1;i<=n;i++){
int up=0,down=l;
for(int j=i+1;j<=n;j++){
ans=max(ans,abs(a[j].y-a[i].y)*abs(up-down));
if(a[j].x<a[i].x)up=max(up,a[j].x);
else down=min(down,a[j].x);
}
}
for(int i=n;i>=1;i--){
int up=0,down=l;
for(int j=i-1;j>=1;j--){
ans=max(ans,abs(a[j].y-a[i].y)*abs(up-down));
if(a[j].x<a[i].x)up=max(up,a[j].x);
else down=min(down,a[j].x);
}
}
sort(a+1,a+1+n,cmp2);{
for(int i=1;i<=n-1;i++){
ans=max(ans,w*abs(a[i].x-a[i+1].x));
}
}
cout<<ans<<'\n';
return 0;
}3.悬线法
相比于上一种算法枚举所有极大矩形 这种算法并不要求只枚举极大化矩形 而是所有极大化矩形都被枚举到 当障碍点密集的时候 明显上种做法并不占优势 这种算法与障碍点无关 而是根据边长有关 是一种o(nm)的算法
(TO DO LIST)