数据集下载:https://gitee.com/CodeStoreHub/emotion-recognition-dataset

在情感计算和脑机接口研究中,如何从生理信号中识别人类情绪一直是一个重要问题。相比面部表情、语音、肢体动作等外显信号,脑电信号(EEG)和眼动信号更难被主动伪装,也更接近情绪产生时的生理反应。因此,基于 EEG 和眼动的情绪识别数据集,对于研究情绪的神经机制、多模态融合方法以及跨被试泛化能力都非常有价值。
SEED-VII 是上海交通大学 BCMI 实验室发布的 SEED 系列情绪数据集之一,全称为 SJTU Emotion EEG Dataset VII。根据官方页面和论文说明,SEED-VII 面向六种基本情绪与中性情绪,采集了 EEG 和眼动两类信号,并提供连续情绪强度标签。它不仅关注"这是哪一种情绪",也关注"这种情绪被诱发得有多强",因此比只提供离散类别标签的数据集更适合研究真实情绪随时间变化的动态过程。
1. 数据集定位
SEED-VII 主要服务于多模态情绪识别任务。它围绕 Ekman 提出的六种基本情绪构建实验,包括:
-
happiness,快乐
-
sadness,悲伤
-
fear,恐惧
-
disgust,厌恶
-
surprise,惊讶
-
anger,愤怒
-
neutral,中性
和早期 SEED 数据集相比,SEED-VII 的一个重要扩展是情绪类别更加完整。早期 SEED 通常关注正性、中性和负性三类情绪,而 SEED-VII 进一步细化到了六种基本情绪,并额外保留中性状态。这使它更适合研究具体情绪之间的神经差异,例如恐惧和愤怒、悲伤和中性、惊讶和快乐之间是否存在稳定可分的 EEG 或眼动模式。
论文中指出,SEED-VII 包含超过 14,000 秒的记录时长,相比许多已有 EEG 情绪数据集具有更长的视频刺激总时长和更丰富的情绪状态覆盖。数据集记录的模态包括 62 通道 EEG 信号和眼动信号,既可以用于单模态情绪识别,也可以用于 EEG 与眼动的多模态融合研究。
2. 被试与采集设备
SEED-VII 最终包含 20 名完整完成实验的被试,其中男性 10 人、女性 10 人,年龄范围为 19 至 26 岁,平均年龄约 22.5 岁。所有被试均为右利手,具有正常或矫正后正常的视觉和听觉能力。
实验中同步采集两类信号:
-
EEG:使用 62 通道 AgCl 电极帽,基于国际 10-20 系统布局,原始采样率为 1000 Hz。
-
眼动:使用 Tobii Pro Fusion 眼动仪采集,采样率为 250 Hz。
论文还提到,被试筛选时使用了 Eysenck Personality Questionnaire(EPQ)人格问卷,并倾向选择外向性得分较高的被试。这是因为过往研究认为外向性较高的人在情绪感知实验中可能具有更好的情绪体验和表达能力,有助于提升情绪诱发实验的数据质量。
3. 情绪诱发材料
SEED-VII 使用视频片段进行情绪诱发。视频相比图片或音乐更容易同时提供视觉和听觉刺激,通常能诱发更稳定、更强的情绪体验。
数据集中共有 80 个视频片段:
-
除中性外,每类情绪选取 12 个视频片段。
-
中性情绪选取 8 个视频片段。
-
每个视频片段持续 2 到 5 分钟。
-
所有视频总时长约为 14,097.86 秒。
SEED-VII 情绪刺激视频片段示意
图 1:SEED-VII 使用视频片段诱发七类情绪,每类情绪对应多段经过筛选的刺激材料。
视频材料经过志愿者评分筛选,保留情绪诱发效果较好的片段。对于惊讶情绪,研究者特别选择了魔术类视频,尽量诱发偏中性的惊讶,避免与快乐、恐惧等情绪混淆。
4. 实验流程
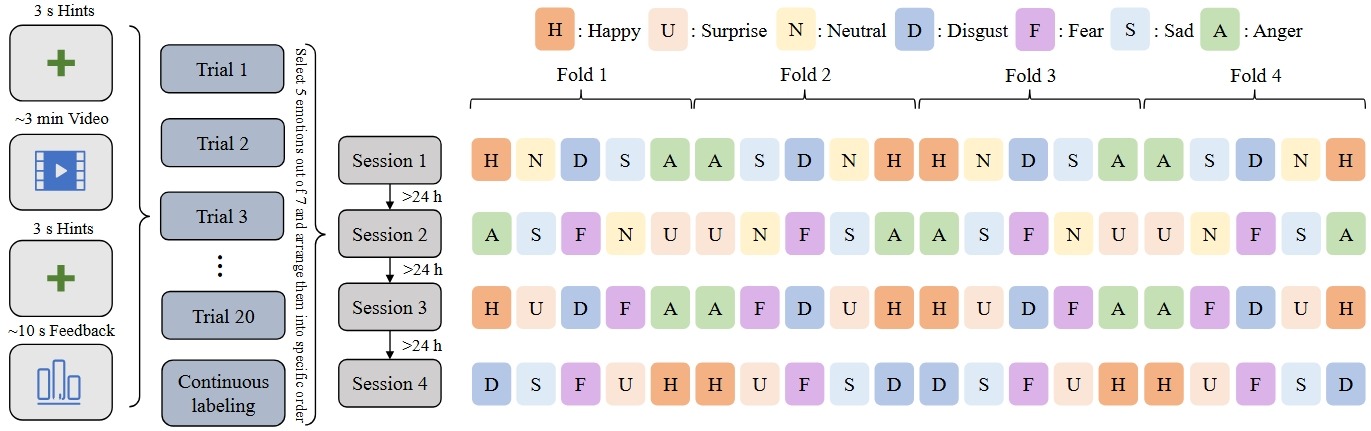
每名被试需要完成 4 个实验 session。每个 session 包含 20 个 trial,因此每名被试总共观看 80 个视频片段。
一个 trial 通常包含以下阶段:
-
开始前倒计时提示。
-
观看情绪诱发视频。
-
结束倒计时提示。
-
自我评估。
在每个 session 中,只诱发七类情绪中的五类。这一设计可以减少被试在短时间内频繁切换过多情绪状态带来的干扰。视频播放顺序也经过设计,避免情绪效价突然大幅跳变,因为真实情绪通常是逐渐过渡的。
SEED-VII 实验流程
图 2:SEED-VII 的实验流程包括视频观看、自我评估、四个 session 以及连续标签标注。
每个视频播放前后都有 3 秒倒计时,用于提示被试即将开始或结束观看。实验结束后,被试还需要回看该 session 的 20 个视频,并根据回忆到的情绪体验,用鼠标滚轮为整个 session 标注连续情绪强度。
5. 标签设计:离散类别与连续强度
SEED-VII 的标签设计是它最有价值的地方之一。它不仅提供七类情绪的离散类别标签,还提供连续情绪强度标签。
离散标签回答的是:
当前视频意图诱发哪一种情绪?
连续标签回答的是:
被试在观看过程中,这种目标情绪到底被诱发得有多强?
连续标签范围为 0 到 1,数值越大表示目标情绪诱发越强。对于非中性情绪,如果被试观看快乐视频后确实感到快乐,则评分应接近 1;如果没有明显情绪反应,则评分接近 0。对于中性视频,逻辑相反:如果被试保持自然平静状态,评分更高;如果情绪产生明显波动,则评分较低。
这种连续强度标签为后续研究提供了更多可能性。例如,研究者可以只筛选高诱发强度片段训练分类器,也可以尝试直接回归情绪强度,还可以分析情绪诱发从弱到强时 EEG 和眼动特征如何变化。
6. 数据模态与特征
SEED-VII 包含 EEG 和眼动两种模态,两者具有互补性。EEG 更直接反映大脑活动,眼动则能反映注意、唤醒、注视行为和瞳孔变化等信息。
EEG 信号
官方处理流程中,原始 EEG 信号首先经过预处理:
-
人工检查 EEG 信号并插值坏道。
-
使用 MNE-Python 工具箱进行处理。
-
带通滤波范围为 0.1 Hz 到 70 Hz。
-
使用 50 Hz 陷波滤波去除工频干扰。
-
从原始 1000 Hz 下采样到 200 Hz。
在特征层面,SEED-VII 提供 differential entropy(DE,微分熵)特征。DE 是 EEG 情绪识别中常用的手工特征,可以近似看作特定频段能量的对数表达。论文中使用 4 秒非重叠 Hanning 窗进行 STFT,并在五个频段提取 DE 特征:
-
delta:1-4 Hz
-
theta:4-8 Hz
-
alpha:8-14 Hz
-
beta:14-31 Hz
-
gamma:31-49 Hz
EEG 微分熵特征示意
图 3:SEED-VII 对 EEG 信号在多个频段上提取 differential entropy(DE)特征。
DE 特征计算公式
图 4:在高斯分布假设下,DE 特征可简化为与方差相关的对数能量表达。
由于 EEG 有 62 个通道,每个样本在五个频段上形成 62 x 5 = 310 维特征。论文还使用 linear dynamic system(LDS)方法对 DE 特征进行平滑,以减少与情绪状态无关的波动。
眼动信号
眼动信号来自 Tobii Pro Fusion 眼动仪。数据集中关注的眼动信息包括瞳孔直径、注视、扫视、眨眼等特征。
SEED-VII 眼动特征列表
图 5:SEED-VII 从瞳孔、注视、扫视和眨眼等维度提取眼动特征。
论文中提到,瞳孔直径对情绪识别尤其重要,但它也容易受到环境亮度影响。因此,研究者先对眨眼造成的缺失瞳孔样本进行线性插值,再利用 PCA 去除光照反射带来的影响。随后,对左右眼瞳孔直径提取低频 DE 特征,并结合瞳孔均值、标准差以及其他眼动统计量,最终得到 33 维眼动特征。
7. 官方数据组织
根据 SEED-VII 官方页面,完整数据包主要包含以下内容:
| 路径或文件 | 内容说明 |
|---|---|
EEG_features |
20 名被试的 EEG DE 特征,文件通常命名为 subjectID.mat。 |
EEG_raw |
Neuroscan 设备采集的原始 EEG .cnt 文件,命名格式为 subjectID_date_sessionID.cnt。 |
EYE_features |
提取后的眼动特征。 |
EYE_raw |
眼动设备导出的原始 .tsv 文件。 |
src |
示例代码与 62 通道 EEG 头皮位置文件。 |
save_info |
每个 session 的触发时间信息和被试反馈评分。 |
emotion_label_and_stimuli_order.xlsx |
情绪标签与刺激顺序。 |
subject info.xlsx |
被试元信息。 |
Channel Order.xlsx |
DE 特征对应的通道顺序。 |
在本地数据目录 /mnt/e/lishuo/code/MMPDMamba/SEED_VII 中,可以看到 EYE_raw、save_info 和 src 等目录。其中 save_info 下包含两类重要 CSV 文件:
-
*_trigger_info.csv:记录 trial 开始和结束时间,trigger 1 表示 trial 开始,trigger 2 表示 trial 结束。 -
*_save_info.csv:记录每个视频片段对应的目标情绪材料路径和被试评分。
src/load_cnt_file_with_mne.py 是读取和预处理 .cnt EEG 文件的示例代码。它展示了如何使用 MNE 读取 Neuroscan CNT 文件、丢弃无关通道、设置 montage、滤波、陷波、重采样,并根据 trigger 将连续 EEG 切分成视频 trial 片段。
8. 基准方法与实验结果
SEED-VII 论文不仅发布数据集,还提出了 Multimodal Adaptive Emotion Transformer(MAET)作为基准模型。MAET 的设计目标是同时适配单模态和多模态输入:它既可以只使用 EEG,也可以只使用眼动,还可以融合 EEG 与眼动信号。
论文中的实验包括:
-
subject-dependent 情绪识别:每个被试内部做四折交叉验证。
-
cross-subject 情绪识别:使用 leave-one-subject-out(LOSO)验证泛化能力。
-
单模态实验:分别评估 EEG 和眼动信号。
-
多模态实验:融合 EEG 与眼动特征。
-
连续标签分析:研究高诱发强度样本筛选对识别性能的影响。
结果显示,多模态融合通常优于单模态输入。论文中 MAET 在 subject-dependent 多模态七分类任务上取得了最好的平均表现,准确率达到 71.28%,F1 分数达到 69.16%。在 cross-subject EEG 情绪识别中,MAET 也取得了最高的平均准确率 40.90% 和 F1 分数 38.85%。这些结果说明,SEED-VII 的跨被试设置仍然具有明显挑战:即使同样是 EEG 情绪识别,不同被试之间的生理差异也会显著降低模型泛化性能。
9. 数据集中观察到的情绪模式
论文还分析了不同情绪在 EEG 和眼动上的稳定模式。
在 EEG 方面,研究者观察到:
-
快乐情绪在 beta 和 gamma 频段的颞叶区域有更强激活。
-
惊讶情绪在多个频段上的 DE 特征整体较低,因此在 EEG 单模态下相对更容易区分。
-
中性情绪在顶叶和枕叶区域表现出较强 alpha 反应,可能与较低注意水平有关。
-
恐惧情绪在额叶区域表现出较强激活,尤其是在低频段。
-
悲伤和愤怒在部分神经模式上相似,因此更容易互相混淆。
在眼动方面,瞳孔直径是最有区分度的特征之一。论文指出,恐惧情绪通常对应更大的瞳孔直径,而中性情绪的瞳孔直径最小;中性状态下的注视持续时间也更长,说明被试可能处于更放松、注意水平更低的状态。
10. 为什么 SEED-VII 值得关注
SEED-VII 的价值不只是"又一个 EEG 情绪数据集",而在于它同时补足了几个常见短板。
首先,它覆盖了更完整的基本情绪类别。许多 EEG 情绪数据集只做正负性或高低唤醒分类,而 SEED-VII 直接面向快乐、悲伤、恐惧、厌恶、惊讶、愤怒和中性七类状态,有助于研究更细粒度的离散情绪识别。
其次,它提供 EEG 与眼动两种互补模态。EEG 适合捕捉大脑神经活动,眼动适合反映注意和生理唤醒。两种信号结合后,可以更全面地描述情绪反应。
第三,它提供连续强度标签。真实情绪并不是静态类别,而是会随时间变化、有强弱程度的动态过程。连续标签让研究者能够过滤低质量诱发片段、研究情绪强度回归,或者建立更接近真实情绪体验的模型。
最后,它的跨被试实验具有现实意义。实际应用中,模型经常需要面对从未见过的新用户。SEED-VII 的 LOSO 设置揭示了跨被试泛化仍然困难,也为领域泛化、个体差异建模和自适应情绪识别提供了测试平台。
11. 适合的研究方向
基于 SEED-VII,可以开展以下研究:
-
EEG 单模态七分类情绪识别。
-
眼动单模态情绪识别。
-
EEG 与眼动多模态融合。
-
跨被试情绪识别与领域泛化。
-
连续情绪强度回归。
-
高诱发强度样本筛选与数据质量评估。
-
EEG 频段、通道和脑区的情绪相关性分析。
-
多模态 Transformer、图神经网络、状态空间模型等方法在情绪识别中的比较。