为什么要拆这个项目
Hermes Agent 是 Nous Research 开源的 AI 智能体框架,今年 2 月低调发布,4 月 GitHub Stars 就破了 12 万。半年之内从 v0.1.0 迭代到 v0.14.0,社区贡献者超 240 人。
我关注它不是因为 star 多,而是因为它在技术上做了一个很少见的选择:自进化(Self-Evolving)。大多数 Agent 框架的定位是"编排工具"------帮你把 LLM 和工具串起来。Hermes 的定位是"越用越聪明"------Agent 执行完复杂任务后,会自动把解决流程沉淀为可复用的技能文件,下次遇到类似问题直接调用。
这篇文章从源码层面拆解 Hermes 最有技术含量的几个模块:记忆系统、上下文压缩、Prompt 缓存优化、MCP 集成。每个模块都会讲清楚它解决什么问题、代码怎么实现、以及实际使用中的局限。
项目地址:github.com/nousresearc...,MIT 许可证,Python 3.11+,当前版本 v0.14.0。
一、整体架构:三层分离
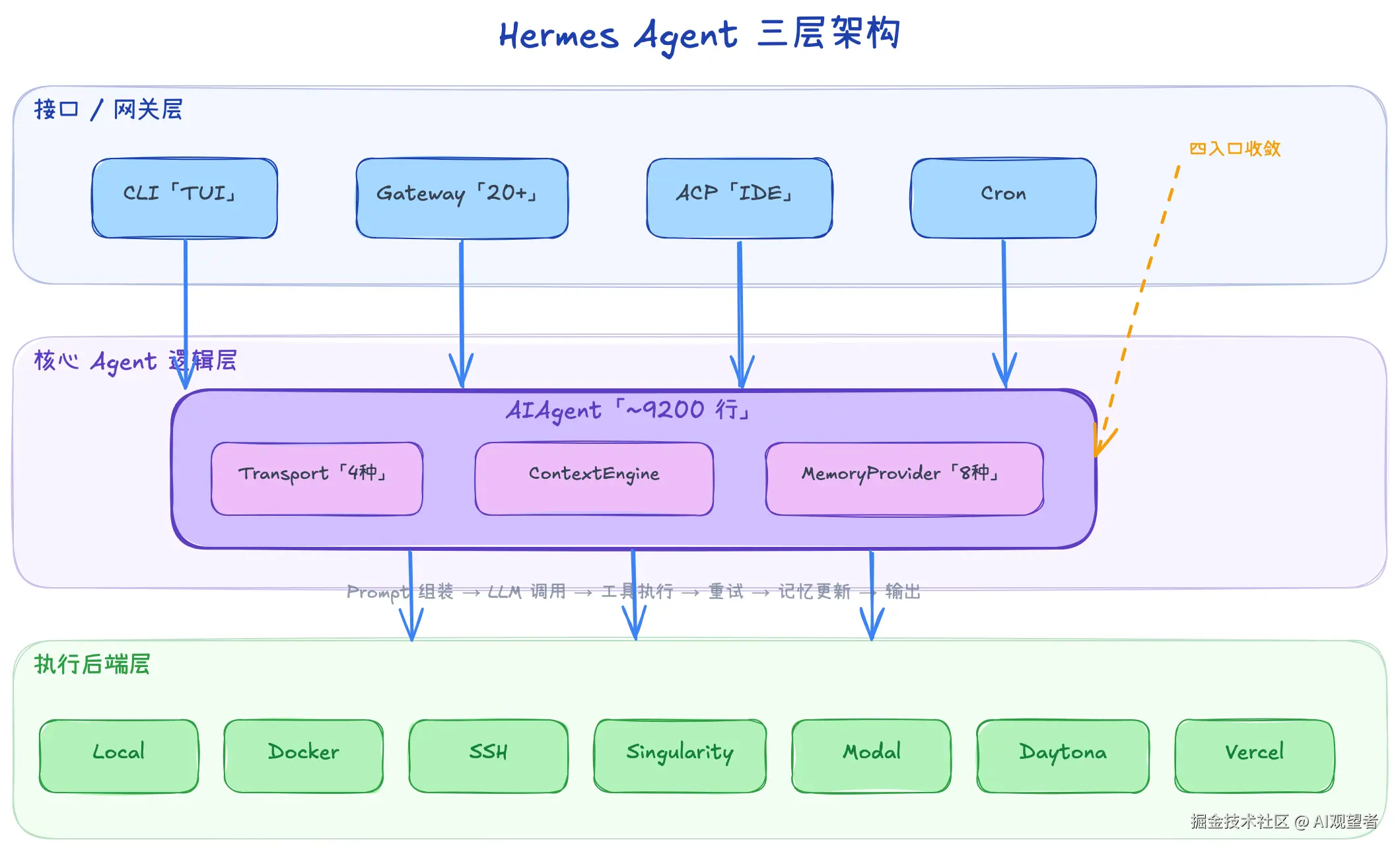
先看全局。Hermes 采用三层架构,把用户界面、Agent 逻辑、执行后端严格分开:
scss
接口层 ─────── CLI(TUI) / Gateway(20+平台) / ACP(IDE协议) / Cron(定时)
│
▼
核心逻辑层 ──── AIAgent (run_agent.py, ~9200行)
├── Transport (4种LLM通信协议)
├── ContextEngine (上下文压缩)
└── MemoryProvider (8种记忆后端)
│
▼
执行后端层 ──── Local / Docker / SSH / Singularity / Modal / Daytona / Vercel几个值得注意的设计选择:
单 Agent 模式。和 CrewAI、MetaGPT 这些多 Agent 框架不同,Hermes 核心是一个单体 Agent------一个进程、一个 session 数据库、一个记忆存储、一个工具注册表。它的理由是:多 Agent 实例会导致记忆碎片化和工具状态漂移。需要并行时,主 Agent 启动隔离的 Sub-agent 执行子任务,完成后汇报结果并销毁。
插拔式 Transport 。不同 LLM 供应商的 API 协议差异很大(OpenAI Chat Completions、Anthropic Messages、AWS Bedrock Converse......),Hermes 用 Transport 抽象层屏蔽差异。每个 Transport 负责消息格式转换、工具 Schema 转换、响应归一化。新增 Provider 只需选一个已有 Transport 配上 api_mode 字符串,不用写新 Transport。
7 种执行后端 。Agent 的"思考"和"动手"分离。Docker 后端做了安全硬化------drop 所有 capabilities、禁止特权提升、PID 限制、可选只读根文件系统。这个设计在让 Agent 自主执行 shell 命令的场景下很重要,否则一句 rm -rf / 就完蛋了。
二、记忆系统:三层设计
记忆系统是 Hermes 和其他 Agent 框架拉开差距的核心。分三层,每层解决不同的问题。 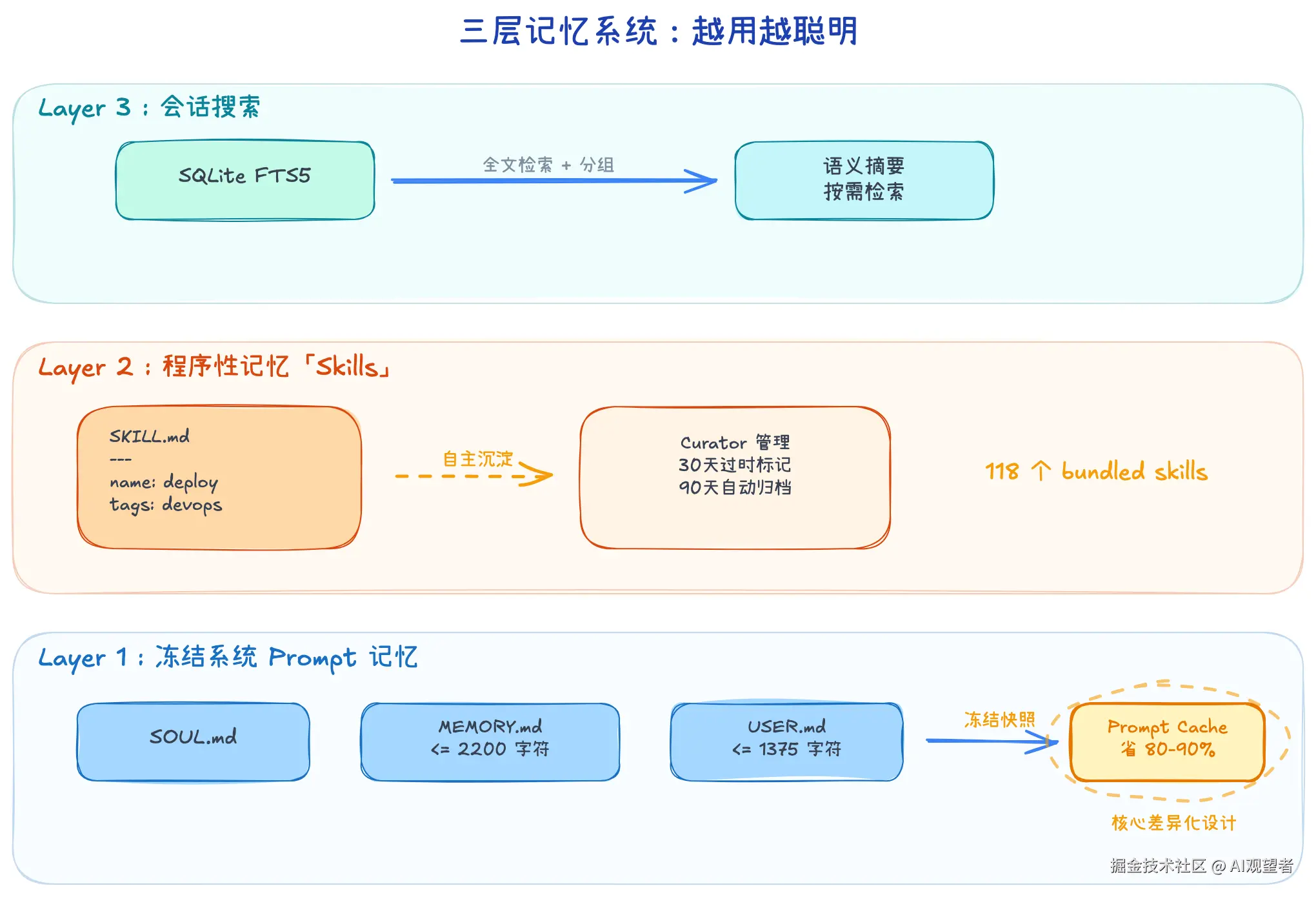
Layer 1:冻结文件------跨会话身份与知识
三个 Markdown 文件构成 Agent 的"长期人格":
bash
~/.hermes/
├── SOUL.md # Agent 身份/人格定义,注入 System Prompt 最前端
├── MEMORY.md # 环境/项目事实(技术栈、约定、踩过的坑),上限 2200 字符
└── USER.md # 用户沟通风格与偏好,上限 1375 字符MEMORY.md 的内容大概长这样:
markdown
## 项目环境
- 后端:Python 3.11 + FastAPI
- 数据库:PostgreSQL 15,ORM 用 SQLAlchemy 2.0
- 部署:Docker Compose + Nginx
## 约定
- API 路由统一放 routers/ 目录
- 所有数据库操作走 async session
- 提交代码前必须跑 ruff check
## 历史踩坑
- psycopg2 和 asyncpg 不能混用,之前因为这个排查了两小时关键设计 :这三个文件在会话启动时做一次冻结快照注入到 System Prompt,会话过程中即使 Agent 更新了磁盘上的文件,已构建的 System Prompt 也不变。
为什么要这样做?因为 Prompt Cache 。Anthropic 和 OpenAI 都支持对 System Prompt 的前缀做缓存。如果 System Prompt 在会话中变来变去,缓存就失效了,每次 API 调用都要重新处理完整的前缀。冻结快照保证了前缀稳定,每次调用都能命中缓存,输入 token 成本降 80-90%。
这也解释了为什么 MEMORY.md 限制 2200 字符、USER.md 限制 1375 字符------不是技术上做不到更大,而是这些内容会塞进每一次 API 请求的 System Prompt 里。太大了一是影响缓存效率,二是挤占正文的上下文窗口。
Layer 2:程序性记忆------Skills 自进化
这是 Hermes 最有意思的设计。Agent 完成一个复杂任务(5 个以上工具调用)后,会自主把解决过程沉淀为一个 SKILL.md 文件:
markdown
---
name: deploy-docker-compose
description: 使用 Docker Compose 部署多容器应用
tags: [devops, docker, deployment]
created: 2026-03-15
last_used: 2026-05-10
use_count: 12
---
## 步骤
1. 检查 docker-compose.yml 是否存在
2. 验证所有服务的镜像是否可用
3. 执行 `docker compose up -d`
4. 检查所有容器健康状态
5. 输出服务访问地址
## 注意事项
- 端口冲突时先用 `docker ps` 检查占用
- 生产环境务必设置 `restart: always`技能文件的生命周期由 Autonomous Curator 管理。它不是一个常驻守护进程,而是在 CLI 启动时或周期性触发。核心逻辑:
- 30 天没用过的技能标记为"过时"
- 90 天没用过的技能移入
~/.hermes/skills/.archive/ - 永远不自动删除,最坏情况就是归档(可以手动恢复)
- 只管 Agent 自己创建的技能,不动内置的 118 个 bundled skills
可以先预览再决定要不要执行:
bash
hermes curator run --dry-run # 预览审查结果,不实际操作这个设计的本质是让 Agent 建立自己的"肌肉记忆"。第一次做某类任务可能要调 5 次工具、花 30 秒 token,第二次直接调技能,快得多也便宜得多。
不过实际用下来也有问题------Agent 自动生成的技能质量不一定靠谱。有时候它会把一个特定场景的解决方案泛化成通用技能,下次用的时候反而出错。Curator 的归档策略只看使用频率,不看技能质量,这块还有优化空间。
Layer 3:会话搜索------SQLite FTS5
所有历史对话存在本地 SQLite 数据库 ~/.hermes/state.db(WAL 模式支持并发读写)。数据库的 messages_fts 是一个 FTS5 虚拟表,支持全文检索。
搜索流程:
css
Agent 调用 session_search
→ FTS5 全文检索,按相关性排名
→ 按 session 分组,解析子→父 session 关系
→ 取 Top 3-5 个 session,每个截断到约 100K 字符
→ 用辅助小模型生成摘要
→ 返回摘要(不是原始全文,避免撑爆上下文)存储增长方面,每轮对话几 KB 加上 FTS5 索引,半年正常使用大概 20-100 MB,不会成为瓶颈。
三、上下文压缩:Head-Middle-Tail 策略
长对话最终会撞上上下文窗口限制。Hermes 的解法在 agent/context_compressor.py,采用三区策略:
scss
┌──────────────────────────────────────────────────────┐
│ Head (保护区) │ Middle (压缩区) │ Tail (保护区) │
│ System Prompt │ 历史对话 │ 最近 N 条消息 │
│ 永不压缩 │ 超阈值时做摘要 │ 永不压缩 │
└──────────────────────────────────────────────────────┘默认配置:上下文使用率到 50% 时触发压缩,目标压到 20%,尾部至少保护最近 20 条消息。
源码里有几个巧妙的工程细节:
增量摘要。压缩器会存上一轮的摘要结果,后续压缩在此基础上更新而非从头开始。这样即使经历多次压缩,早期的重要上下文不会被层层摘要稀释掉。
Anti-Thrashing 保护。如果最近两次压缩每次节省不到 10%,直接跳过压缩。这防止了一种死循环:上下文刚好在阈值附近震荡,反复触发压缩但每次只省一点点,白花 LLM 调用的钱。
摘要 Prompt 设计 。_summarizer_preamble 把摘要生成定位为"独立助手撰写交接文档",而不是"回答问题"。如果不这么做,摘要模型会把对话中用户提的问题当成对自己的提问,试图回答而不是总结。
已知限制:摘要模型的上下文窗口必须大于等于主 Agent 模型的,否则摘要本身就会触发 context-length 错误。这在混合使用不同模型时容易踩坑。
四、Prompt Cache 优化
实现在 agent/prompt_caching.py,策略叫 "system_and_3"。
Anthropic 允许每个请求最多 4 个 cache_control 断点。Hermes 的分配方式:
sql
断点 1:System Prompt(包含 SOUL.md + MEMORY.md + USER.md 的冻结快照)
断点 2-4:最近 3 条非系统消息的滚动窗口System Prompt 在整个 session 中是固定的(前面说的"冻结快照"设计),所以断点 1 的缓存命中率接近 100%。后面 3 个断点覆盖最近的对话上下文,大部分情况下也能命中。
实际效果是每次 API 调用只需要处理最新一轮对话的增量 token,历史部分全部走缓存。这个优化对成本控制非常关键------Hermes 号称月运行成本 $7-22,Prompt Cache 是重要原因之一。
五、MCP 集成:1900 行的双向桥梁
MCP 集成是 Hermes 与外部工具生态互联的核心,代码在 tools/mcp_tool.py,有 1900 多行,是所有工具模块里最重的。 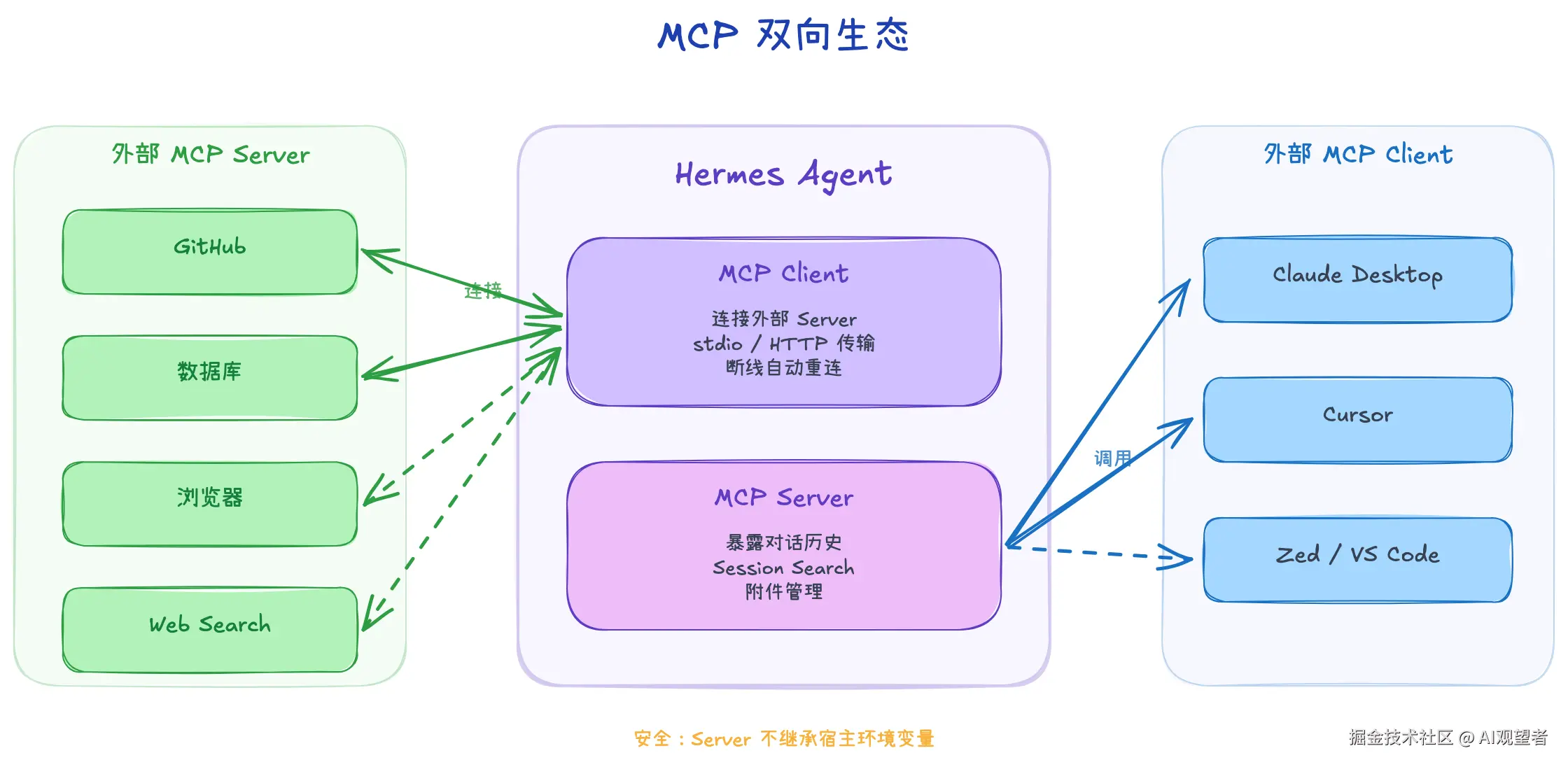
5.1 架构设计
Hermes 的 Agent 主循环是同步 Python 代码,但 MCP 协议是异步的。这产生了一个工程问题:怎么从同步代码调用异步协议?
解法是用一个独立的 daemon 线程跑 asyncio 事件循环 (_mcp_loop),同步侧通过 run_coroutine_threadsafe 提交任务并阻塞等待结果。不优雅,但管用。
python
# 简化后的核心逻辑
import asyncio
import threading
class MCPManager:
def __init__(self):
self._loop = asyncio.new_event_loop()
self._thread = threading.Thread(target=self._run_loop, daemon=True)
self._thread.start()
def _run_loop(self):
asyncio.set_event_loop(self._loop)
self._loop.run_forever()
def call_tool_sync(self, server_name: str, tool_name: str, arguments: dict):
"""从同步代码调用 MCP Server 的工具"""
future = asyncio.run_coroutine_threadsafe(
self._call_tool_async(server_name, tool_name, arguments),
self._loop
)
return future.result(timeout=30)
async def _call_tool_async(self, server_name, tool_name, arguments):
session = self._sessions[server_name]
return await session.call_tool(tool_name, arguments)5.2 工具命名和动态发现
MCP Server 暴露的工具会被加上 mcp_{server_name}_ 前缀(连字符替换为下划线),避免和内置工具冲突。比如一个叫 finance-data 的 MCP Server 暴露了 query_rating 工具,注册后的名字就是 mcp_finance_data_query_rating。
MCP Server 可以通过 notifications/tools/list_changed 通知工具列表变更,Hermes 自动重新拉取并更新注册。所以 Server 侧可以动态增删工具,Client 侧不用重启。
5.3 双向能力
Hermes 不只是 MCP Client,它同时也是 MCP Server。可以把自己的对话历史、session search、附件管理能力暴露给外部 MCP Client(比如 Claude Desktop、Cursor)。
5.4 连接管理
每个 MCP Server 作为长生命周期的 asyncio Task 运行。断线自动重连,指数退避,最多 5 次重试,最大退避 60 秒。
支持两种传输方式:stdio(本地进程间通信,通过 command + args 启动子进程)和 HTTP/StreamableHTTP(远程)。
5.5 安全处理
一个容易被忽略的细节:stdio 方式启动的 MCP Server 子进程,不会继承宿主的完整环境变量 。Hermes 只传递安全基线变量(PATH、HOME、USER 等),过滤掉所有可能包含凭证的变量。这防止了一种常见的安全隐患------MCP Server 代码(可能来自第三方)通过 os.environ 拿到宿主的 API Key。
5.6 自己写一个 MCP Server 接入 Hermes
接入外部工具只需要两步:写一个 MCP Server,然后在配置文件里注册。
以一个查询股票行情的 MCP Server 为例:
python
"""stock_server.py --- 股票行情 MCP Server"""
from mcp.server import Server
from mcp.types import Tool, TextContent
import mcp.server.stdio
import json
server = Server("stock-quotes")
@server.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="get_stock_price",
description="查询 A 股实时股价,返回最新价、涨跌幅、成交量",
inputSchema={
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "股票代码,如 600519(贵州茅台)"
}
},
"required": ["symbol"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "get_stock_price":
# 实际项目对接行情 API
data = {"symbol": arguments["symbol"], "price": 1688.00,
"change_pct": "+1.2%", "volume": "3.2万手"}
return [TextContent(type="text", text=json.dumps(data, ensure_ascii=False))]
return [TextContent(type="text", text='{"error": "unknown tool"}')]
async def main():
async with mcp.server.stdio.stdio_server() as (rs, ws):
await server.run(rs, ws, server.create_initialization_options())
if __name__ == "__main__":
import asyncio
asyncio.run(main())然后在 ~/.hermes/config.yaml 里注册:
yaml
mcp:
servers:
stock-quotes:
command: python
args: ["/path/to/stock_server.py"]重启 Hermes 后,Agent 就能自动发现并调用 mcp_stock_quotes_get_stock_price 工具了。
六、多平台接入
Hermes 的 Gateway 支持 20 多个消息平台------Telegram、Discord、Slack、钉钉、飞书、企业微信、个人微信(v0.8.0+)、QQ Bot......甚至还有 Home Assistant。
技术上并不复杂,本质是一层适配器模式:每个平台一个 Python 文件(在 gateway/platforms/ 目录下),实现消息收发的标准接口,往下调同一个 AIAgent 核心。社区在 v0.4.0 时用不到 300 行代码就加完了 Mattermost 适配,说明扩展成本很低。
比较有意思的设计是跨平台上下文:所有平台共享同一个 MEMORY.md、USER.md 和 SQLite session 数据库。你在 Telegram 上教 Agent 的东西,切到飞书上它也记得。切换平台时新 session 通过会话搜索自动恢复最相关的历史上下文。
七、RL 训练集成
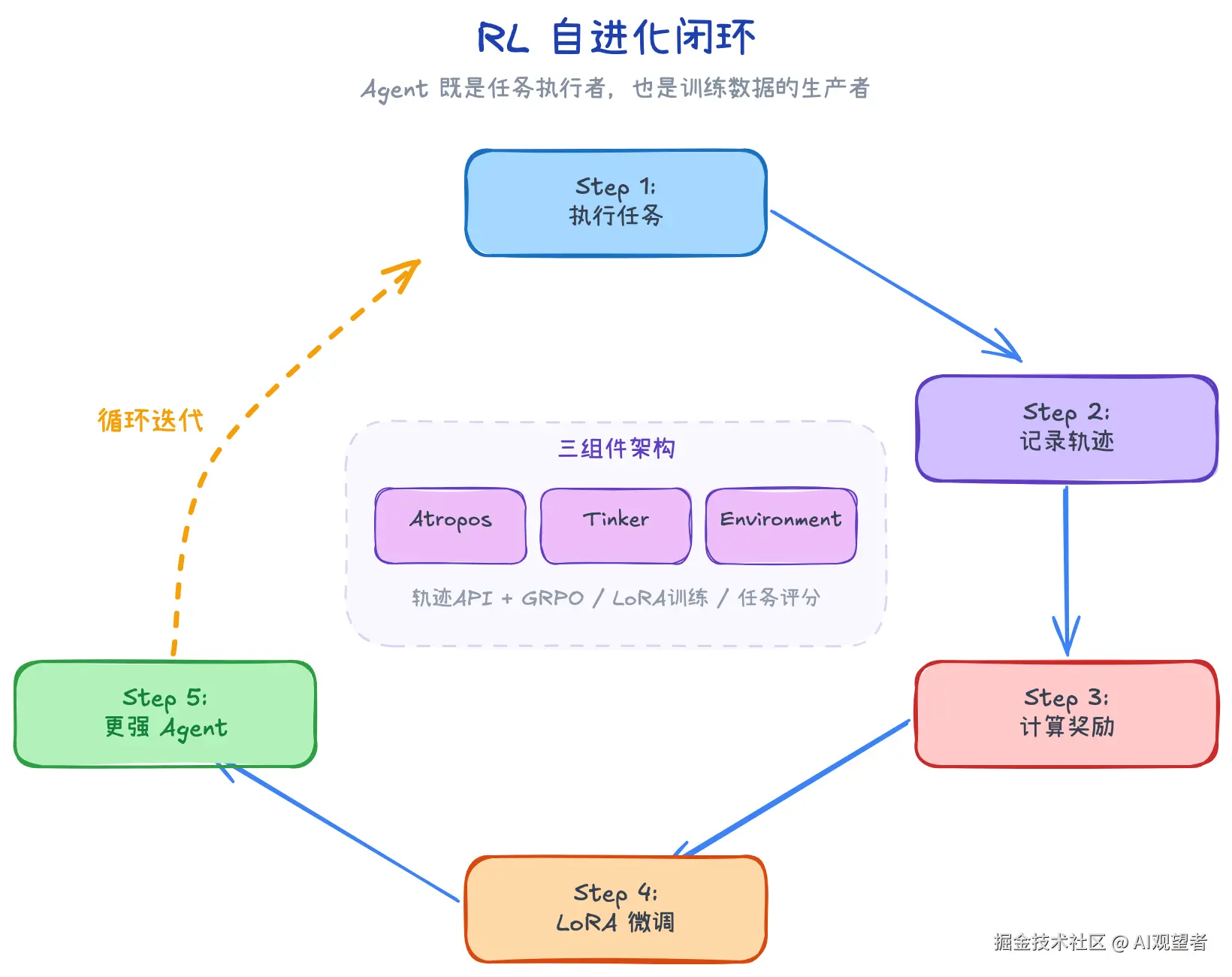
Hermes 不只是一个运行时 Agent 框架,它同时也是一个训练数据生成管线,这在开源 Agent 框架里很少见。
三个组件:Atropos(轨迹 API Server + GRPO 优势计算)、Tinker(LoRA 训练/推理)、Environment(任务/评分/奖励)。
流程是:Agent 执行任务时完整记录轨迹(对话历史 + 工具调用 + 结果),计算奖励分数,导出为训练数据,用 LoRA 微调模型,再用微调后的模型跑 Agent,循环迭代。
社区提供了 RealWorldTaskEnv,包含 30 个真实任务(编码、搜索、文件操作、数据分析、运维),支持多维奖励评分,导出 SFT-ready JSONL。
这个设计的野心是把 Agent 的使用数据变成模型改进的飞轮。不过目前来看,RL 训练的门槛还是比较高的,大部分用户停留在直接使用 Agent 的阶段。
八、安全加固
让 Agent 自主执行 shell 命令,安全就是生命线。Hermes v0.8.0 之后做了一轮大幅加强:
执行隔离:Docker 后端 drop 所有 capabilities,禁止特权提升,PID 限制,可选只读根文件系统。Singularity 后端做全命名空间隔离。
命令审批 :tools/approval.py 维护一个危险命令黑名单。fork bomb、block device 直写这类绝对禁止,不可覆盖。其他危险操作会弹出人工审批确认。
凭证保护:环境变量中含 KEY、TOKEN、SECRET、PASSWORD、CREDENTIAL、AUTH 的一律过滤,防止 Agent 在 shell 输出中暴露凭证。MCP Server 子进程只继承安全基线变量。
v0.8.0 新增:SSRF 保护、时序攻击缓解、tar 遍历防护、跨 session 隔离。
九、成本与资源
Hermes 的资源需求很低:
不跑浏览器自动化的话,1 个 vCPU + 1 GB RAM + 20 GB 存储就够了。默认调用云端 LLM API,不需要 GPU(本地跑 Ollama/vLLM 才需要)。
月成本大概 7−22:VPS5-7(Hetzner / DigitalOcean),LLM API $2-15(取决于模型选择和用量)。Prompt Cache 优化是控制 API 成本的关键------冻结快照 + system_and_3 策略让大部分请求只处理增量 token。
十、和其他框架的核心差异
和 AutoGPT、CrewAI、LangGraph 这些框架比,Hermes 最大的差异在自进化能力------Skills 自动沉淀 + Curator 生命周期管理 + 会话搜索。其他框架基本没有这个维度。
代价是它押注了单 Agent 模式。如果你的场景需要多个 Agent 角色协作(比如 MetaGPT 的软件团队模拟),Hermes 原生支持不够好,要靠 Parent-Subagent 机制变通。实际上约 20% 的用户同时用 Hermes + 另一个多 Agent 框架,各取所长。
另一个差异是多平台接入。大部分 Agent 框架只提供 CLI 或 API 入口,Hermes 直接支持 20+ 消息平台,可以把 Agent 部署到 Telegram、飞书、企业微信这些日常使用的工具里。这对非技术用户的可达性好很多。
十一、局限和开放问题
用下来也有些问题值得注意:
Skills 质量参差。Agent 自动生成的技能有时会过度泛化------把一个特定场景的解决方案变成"通用技能",下次用的时候可能不适用。Curator 只按使用频率归档,不评估质量。
记忆容量天花板。MEMORY.md 限制 2200 字符、USER.md 限制 1375 字符。对于复杂项目,这个容量可能不够。但放宽限制会影响 Prompt Cache 效率和上下文窗口利用率,这是一个 trade-off。
上下文压缩的摘要模型限制。摘要模型的 Context Window 必须大于等于主模型,否则摘要本身就会 context-length 错误。混合使用不同模型时容易踩这个坑。
EvoMap 争议。2026 年 4 月,中国 AI 团队 EvoMap 指控 Hermes 的自进化引擎与其开源项目 Evolver 高度雷同。Nous Research 否认抄袭。此事目前仍有争议,使用时自行判断。