AI agent:底层知识一篇通
文章目录
- [AI agent:底层知识一篇通](#AI agent:底层知识一篇通)
- 一、底层知识
-
- 1.最底层------LLM
- 2.Transformer
- 3.Token(编码和解码的核心转换机制)
- 超易懂图解
-
- [1. 原始文本与 Token 的必要性](#1. 原始文本与 Token 的必要性)
- [2. 分词与 BPE 算法](#2. 分词与 BPE 算法)
-
- [2.1 为什么需要子词分词](#2.1 为什么需要子词分词)
- [2.2 BPE(Byte Pair Encoding)核心原理](#2.2 BPE(Byte Pair Encoding)核心原理)
- [3. Token → Token ID 映射](#3. Token → Token ID 映射)
- [4. Embedding(向量化)](#4. Embedding(向量化))
- [5. 位置编码(Positional Encoding)](#5. 位置编码(Positional Encoding))
- [6. 最终输入编码器](#6. 最终输入编码器)
- [7. 总结](#7. 总结)
- 4.Context(上下文)
-
- [1.什么是 Context(上下文)](#1.什么是 Context(上下文))
- [2. Context 在 Transformer 中的体现](#2. Context 在 Transformer 中的体现)
- [3. Self-Attention 与上下文建模](#3. Self-Attention 与上下文建模)
- [4. Multi-Head Attention 与多视角上下文](#4. Multi-Head Attention 与多视角上下文)
- [5. 长序列与上下文窗口](#5. 长序列与上下文窗口)
- [6. 上下文对生成与理解的影响](#6. 上下文对生成与理解的影响)
- [7. 总结大白话](#7. 总结大白话)
- 5.RAG
-
- [1. RAG 是什么](#1. RAG 是什么)
- [2. RAG 的核心流程](#2. RAG 的核心流程)
- [3. RAG 与 Transformer / LLM 的关系](#3. RAG 与 Transformer / LLM 的关系)
- 6.Prompt(提示词)
-
- [Prompt Engineer](#Prompt Engineer)
-
- [1. 定义与作用](#1. 定义与作用)
- [2.Prompt 类型](#2.Prompt 类型)
- [3. Prompt 设计原则与技巧](#3. Prompt 设计原则与技巧)
- Prompt详解
- 7.tool(工具、函数)
- 8.MCP(实战后续文章中)
-
- 1.Model(模型)
- [2. Context(上下文)](#2. Context(上下文))
- [3. Protocol(协议)](#3. Protocol(协议))
- 9.Agent
-
- [1、什么是 Agent?核心定义](#1、什么是 Agent?核心定义)
- [2、Agent 的能力维度(核心能力)](#2、Agent 的能力维度(核心能力))
-
- 1)自主规划
- [2)工具调用能力(and MCP标准)](#2)工具调用能力(and MCP标准))
- 3)上下文感知(Context)
- [4)结果整合 & 输出](#4)结果整合 & 输出)
- [3、Agent 工作流程(落地执行图)](#3、Agent 工作流程(落地执行图))
- [4、Agent 类别](#4、Agent 类别)
-
- [☑ 简单 Agent](#☑ 简单 Agent)
- [⭐ 企业级 Agent](#⭐ 企业级 Agent)
- [5、Agent 与常见框架的关系](#5、Agent 与常见框架的关系)
- [🔹 ReAct](#🔹 ReAct)
- [🔹 Plan-and-Execute](#🔹 Plan-and-Execute)
- [6、企业级 Agent 价值总结](#6、企业级 Agent 价值总结)
- 二、Agent搭建
-
-
-
- [⭐ 企业级 Agent](#⭐ 企业级 Agent)
- [5、Agent 与常见框架的关系](#5、Agent 与常见框架的关系)
- [🔹 ReAct](#🔹 ReAct)
- [🔹 Plan-and-Execute](#🔹 Plan-and-Execute)
- [6、企业级 Agent 价值总结](#6、企业级 Agent 价值总结)
-
-
- 二、Agent搭建
一、底层知识
1.最底层------LLM
全称:Large Language Model (大语言模型)
简称:大模型
内部架构:基本上现在所有大模型都基于transformer这套架构训练出来的。
2.Transformer
是一种以注意力机制为核心的序列到序列深度学习模型架构,擅长捕捉长距离依赖,支持高效并行训练,是现代大语言模型(LLM)的基础。
图解
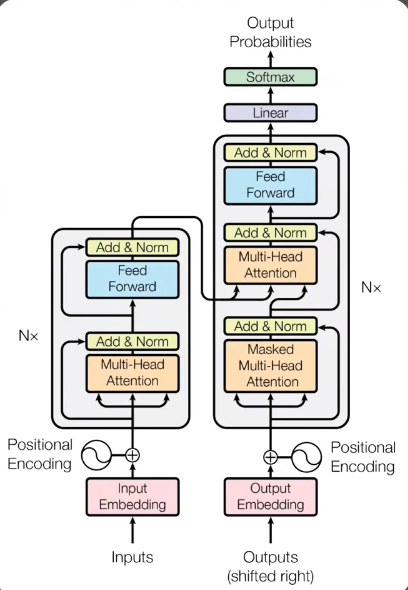
- 输入部分
Input Embedding:将输入的词(Tokens)转换成向量。
Positional Encoding:加入位置信息,因为 Transformer 不使用 RNN,需要知道词序列顺序。
- 编码器(Encoder)
多层堆叠(N×)
每层包括:
- Multi-Head Self-Attention(多头自注意力):捕捉序列中各词之间的关系。
- Add & Norm:残差连接 + 归一化。
- Feed Forward(前馈网络):对每个位置独立进行非线性变换。
- Add & Norm:再一次残差连接 + 归一化。
输出:生成编码表示(Memory),传给解码器使用。
- 解码器(Decoder)
多层堆叠(N×)
每层包括:
- Masked Multi-Head Self-Attention(掩码多头自注意力):保证生成时只能看到前面的输出。
- Add & Norm
- Encoder-Decoder Cross-Attention(编码-解码注意力):利用编码器的输出信息。
- Add & Norm
- Feed Forward
- Add & Norm
输出:每个位置生成预测向量。
- 输出层
Linear:将解码器输出映射到词表维度。
Softmax:生成概率分布,预测下一个词。
核心思想
- Encoder-Decoder + Attention 取代了 RNN,支持并行计算。
- 多头注意力可以同时关注序列不同位置的信息。
- 解码器是自回归的:生成词时只能参考左侧已生成内容。
🔴简而言之,就像是一个超级聪明的"信息整理器+思考器",它专门用来处理文字、句子、甚至代码或者图片序列。
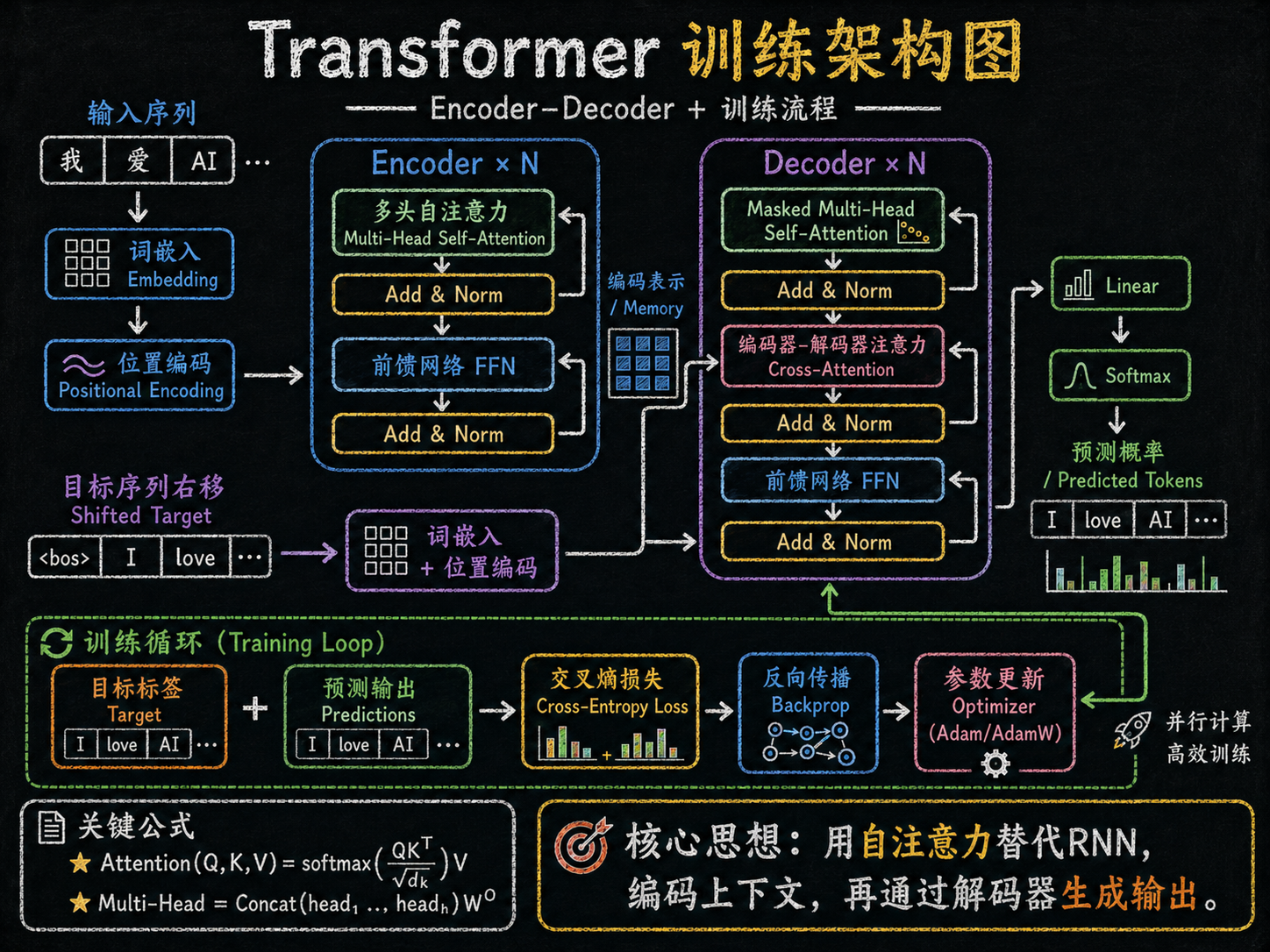
上面这张图表达的意思可以理解为:
逻辑和核心思想:
输入句子:我 爱 AI
-
输入嵌入和位置编码
每个词被转换成向量(Embedding),再加上位置信息(Positional Encoding)让模型知道词序。
在图中,输入序列经过"词嵌入 + 位置编码"进入编码器。
-
编码器(Encoder × N)文字➡️数字(切分和映射)
句子向量经过多层编码器,每层包含:
多头自注意力(Multi-Head Self-Attention)→理解句子中词之间的关系
Add & Norm(残差连接 + 层归一化)
前馈网络(Feed Forward)+ Add & Norm
输出编码表示(Memory),包含整句话的上下文信息。
-
目标序列右移
解码器在训练时,需要右移目标序列(Shifted Target),例如
<bos> 我 love AI,保证解码器自回归生成。 -
解码器(Decoder × N)数字➡️文字(映射)
解码器每层包含:
掩码多头自注意力(Masked Multi-Head Self-Attention)→防止看到未来词
编码器-解码器注意力(Cross-Attention)→利用编码器 Memory
前馈网络 + Add & Norm
-
输出层预测
解码器输出向量经过 Linear + Softmax → 预测每个词的概率(Predicted Tokens)
图中示例:模型预测"我 love AI"的下一个词概率分布。
-
训练循环
预测输出 + 目标标签 → 计算交叉熵损失(Cross-Entropy Loss)
反向传播(Backprop)更新参数 → 使用 Optimizer(Adam/AdamW)
训练循环持续迭代,提高模型预测准确率。
总结
聚焦例子:输入一句话 "我 爱 AI",Transformer 学会根据上下文理解关系,并逐词生成输出序列。
逻辑串起来
-
输入句子 → Encoder 理解 → Decoder 生成 → Softmax 预测概率 → 与真实标签比对 → 反向传播更新参数 → 重复训练循环。
-
训练目标是让模型逐步学会生成正确的词序列,捕捉上下文依赖关系。
例子解释
假设我们用 Transformer 来处理一句中文句子输入
例如:输入句子:我 爱 AI
首先,模型把每个词变成向量,就像把文字翻译成机器能理解的数字。为了让模型知道词的顺序,它还会给每个词加上位置标签,这样模型知道"我"在最前面,"爱"在中间。
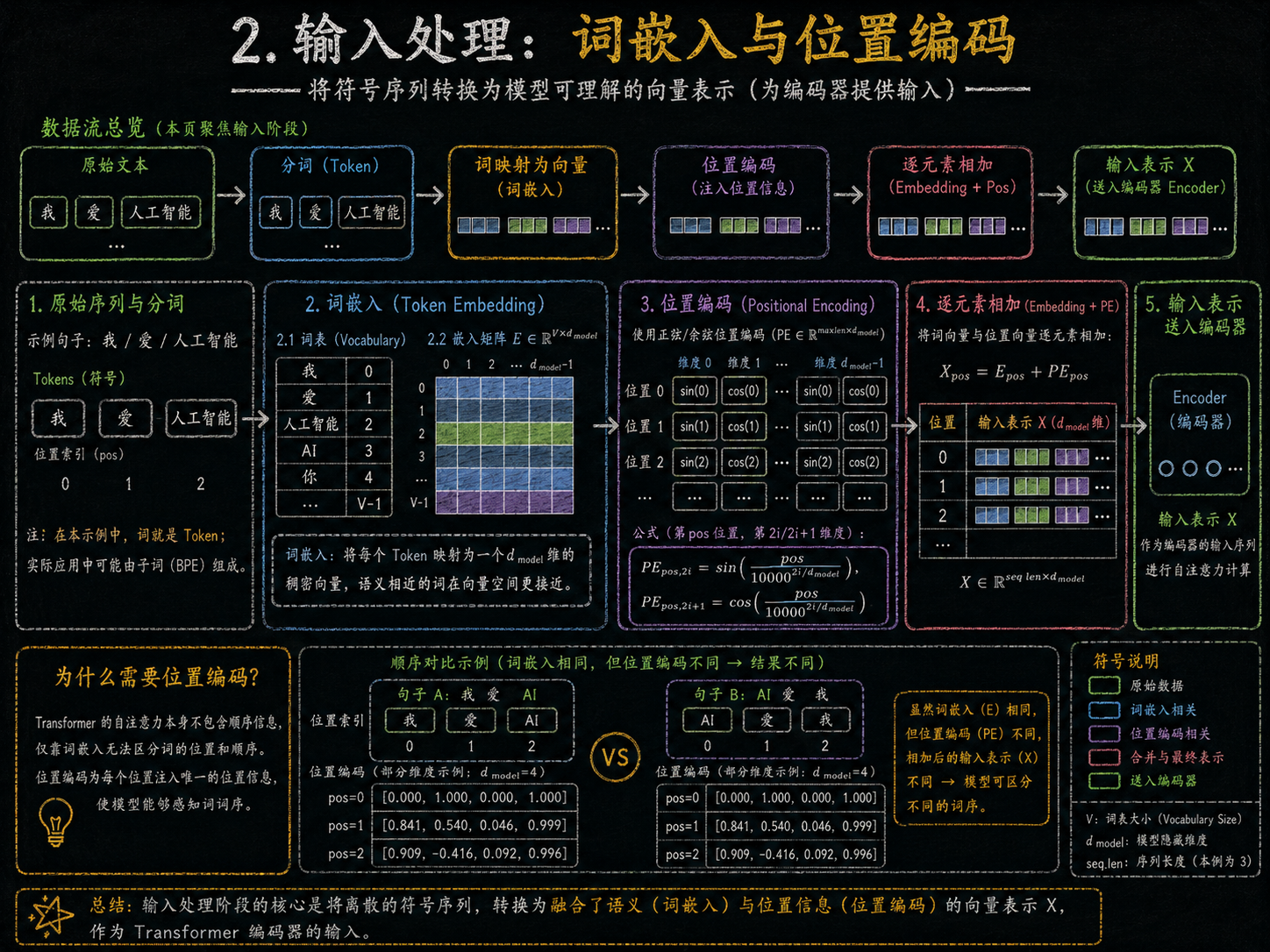
接着,这些词向量进入编码器,编码器就像一个聪明的大脑,会同时观察整个句子中每个词之间的关系。它使用自注意力机制,让每个词可以看到其他词的信息,然后经过前馈网络和归一化处理,把整个句子的意思整理成一组向量。
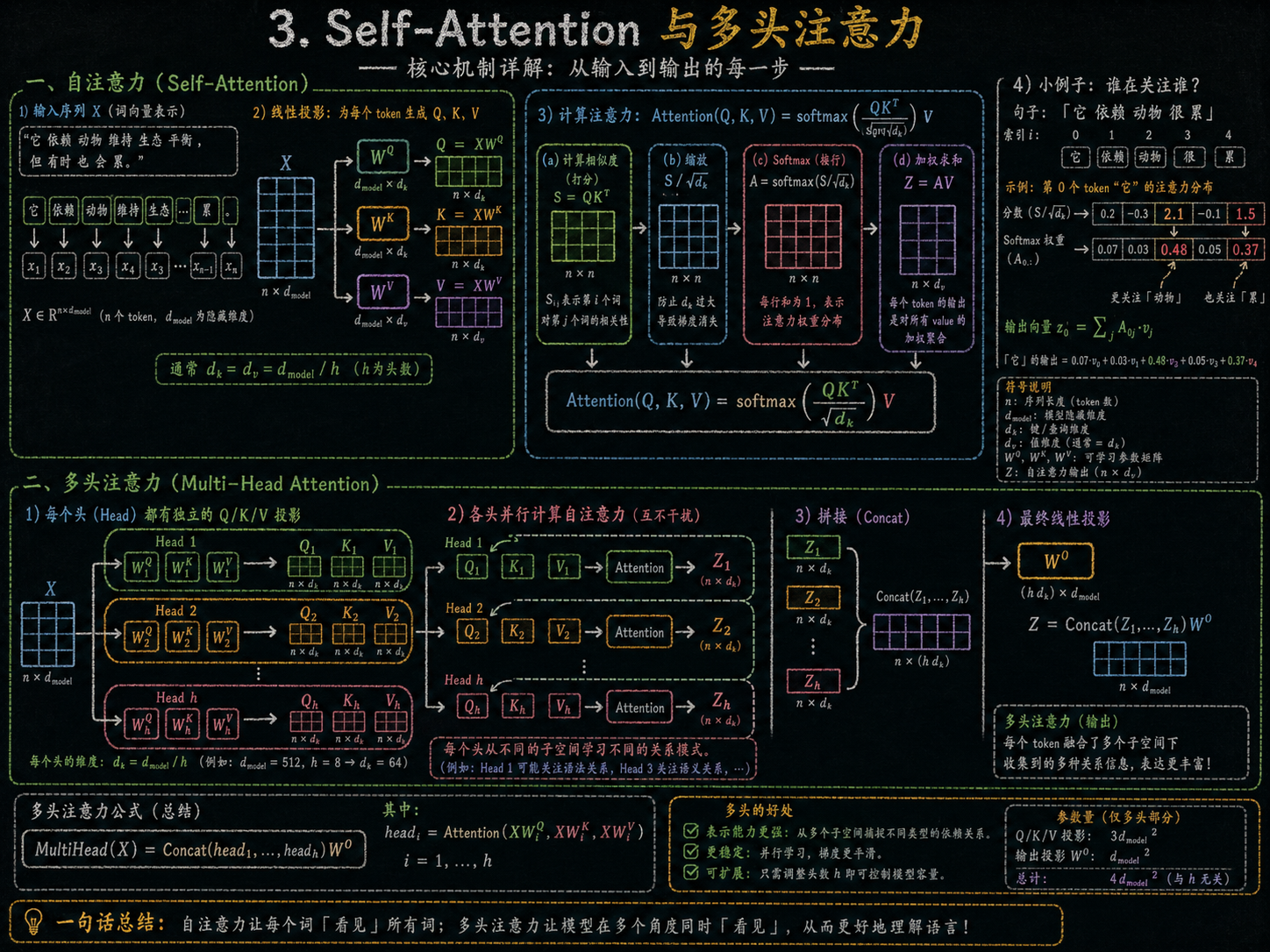
这些向量传到解码器,解码器就像模型的写作系统,它要根据编码器理解的内容逐步生成输出。训练时,目标句子会被右移一个词,让解码器一次只看到前面已经生成的词。解码器先看自己生成过的词,然后参考编码器传来的信息,生成下一个词的预测向量,再经过线性层和 Softmax 计算出每个词的概率。
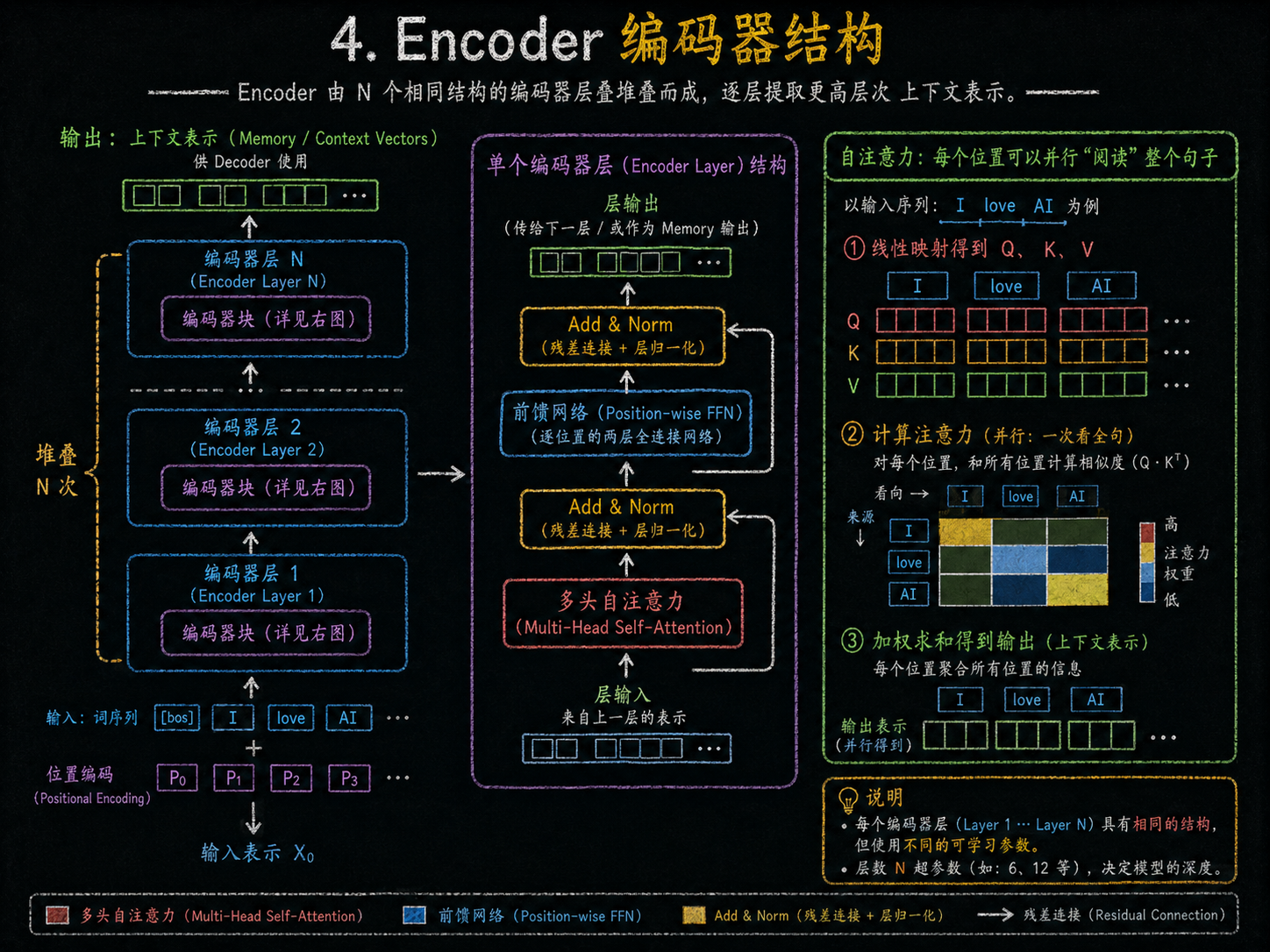
模型把预测出来的词和真实的目标词进行对比,计算损失,然后用反向传播调整内部参数。这个过程重复很多次,模型就慢慢学会在给定句子上下文的情况下正确预测下一个词。
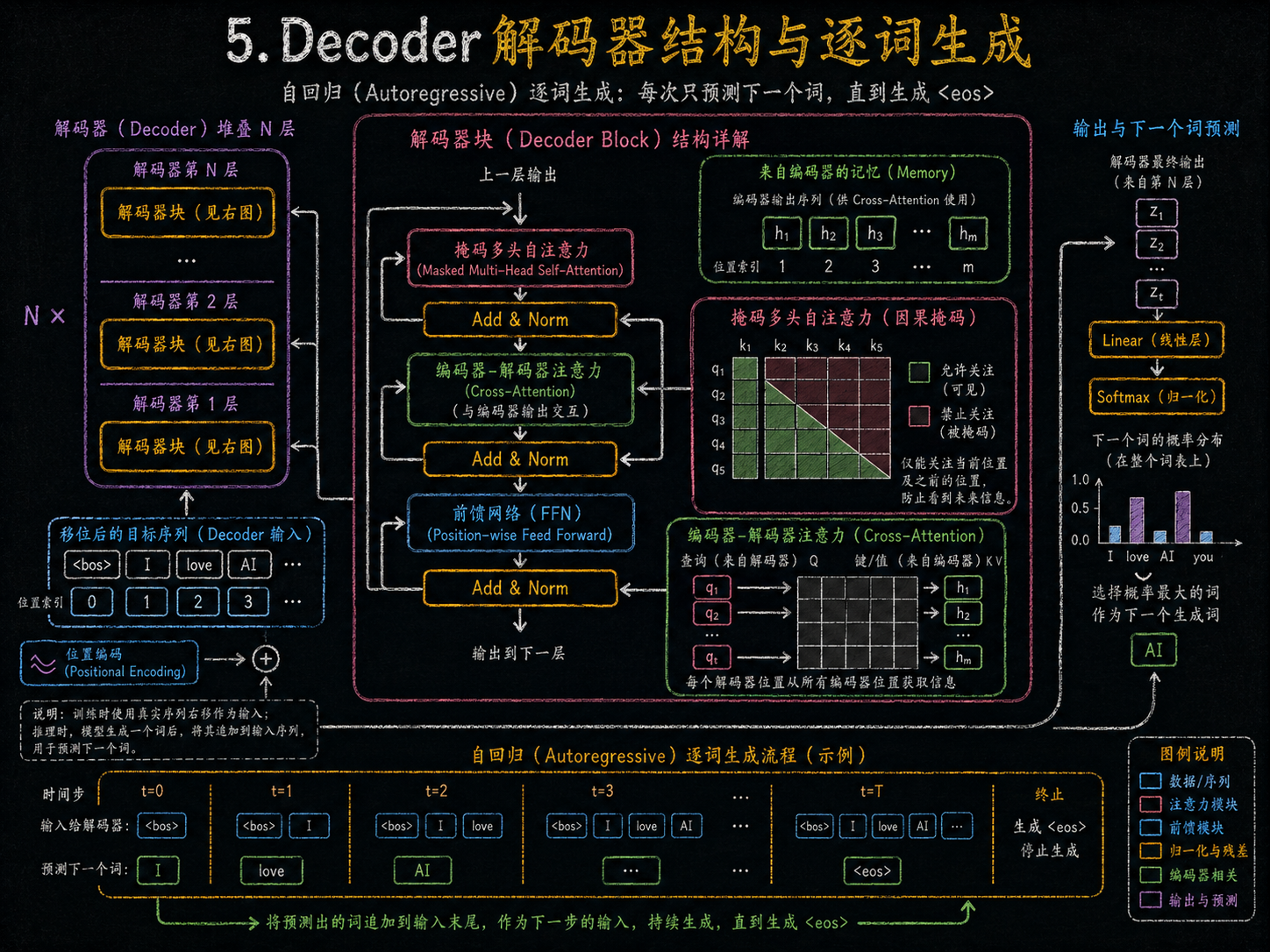
最终,经过训练的 Transformer 能够理解整个句子,抓住词与词之间的关系,并逐步生成输出句子,就像一个会同时理解和写作的超级翻译官一样。
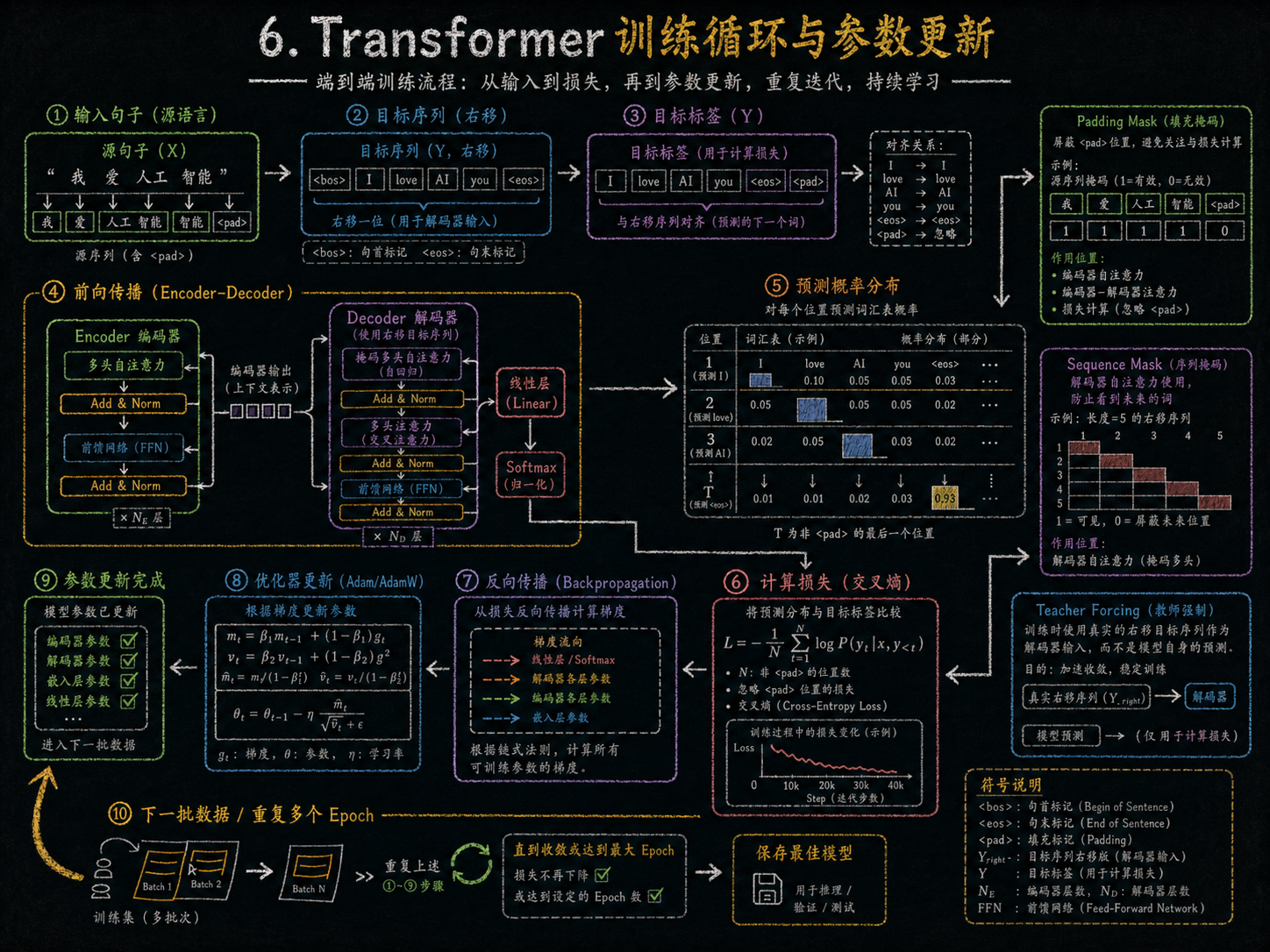
3.Token(编码和解码的核心转换机制)
大模型处理文本最基本的单位
大模型的输入输出不是文字,而是一串数字,需要通过tokenizer进行转换

超易懂图解
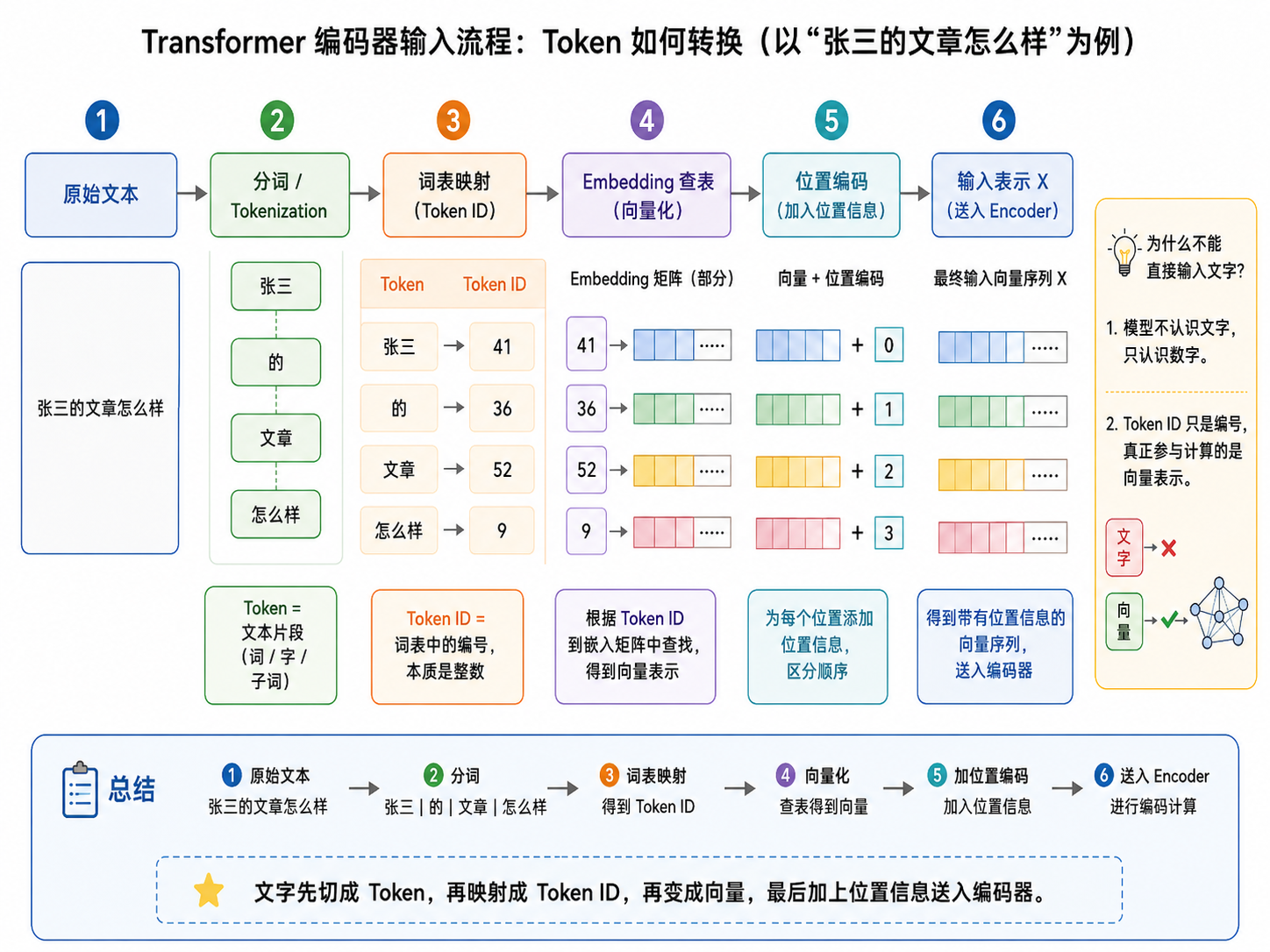
1. 原始文本与 Token 的必要性
在自然语言处理任务中,原始文本(比如"张三的文章怎么样")是人类语言,计算机无法直接理解。Transformer 需要处理的是数字向量 ,所以必须先将文字切分成可识别的最小单位,也就是 Token。Token 可以是单个字、单词,或者子词(subword)。这个步骤是 Transformer 的第一步,也是整个文本处理的基础。
2. 分词与 BPE 算法
2.1 为什么需要子词分词
直接按字或词切分会出现两种问题:
- 词表膨胀:每个词作为一个 Token,词表非常大,低频词几乎没有训练效果。
- 未知词问题:训练集中未出现的词无法处理。
2.2 BPE(Byte Pair Encoding)核心原理
BPE 是子词分词的一种算法,逻辑是从最小单位开始(字符),不断把出现频率最高的连续字符组合成新符号,直到达到目标词表大小。
例如句子"张三的文章",初始按字切分:[张][三][的][文][章]
- 高频组合
[文章]会被加入词表 - 低频组合保持拆分
[文][章]
BPE 的优点:
处理未知词时能拆成已有子词组合。
词表小而高效。
保留词语语义信息。
3. Token → Token ID 映射
每个 Token 都会被映射为唯一整数 Token ID。这是模型实际可以处理的数字表示。
例子:
张三 → 41
的 → 36
文章 → 52
怎么样 → 9- Token ID 仅是索引,模型真正计算的是后续查表得到的 Embedding 向量。
4. Embedding(向量化)
Token ID 查表得到向量表示,每个向量通常是高维的(如 512 维)。
这个向量不仅标识 Token,还会在训练中学习词语的语义信息。
对 Transformer 来说,Embedding 是让文字变成"可计算"的形式。
5. 位置编码(Positional Encoding)
Transformer 并没有循环或卷积结构,所以需要位置信息告诉模型序列中每个 Token 的顺序。
位置编码通过正弦和余弦函数生成向量,加入到 Token 向量中:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))这样模型既能理解语义,又能理解顺序。
6. 最终输入编码器
每个 Token 经历:
原始文本 → BPE Token → Token ID → Embedding 向量 → + 位置编码形成 输入向量序列:
[张三向量+位置0, 的向量+位置1, 文章向量+位置2, 怎么样向量+位置3]这个序列进入编码器,开始进行自注意力运算和前馈网络处理,生成上下文丰富的表示。
7. 总结
完整的 Token 生成机制逻辑:
- 文本切分:用 BPE 把文本拆成子词 Token
- Token 映射:每个 Token 对应唯一 Token ID
- Embedding:Token ID 转向量
- 位置编码:向量加上位置信息
- 编码器输入:形成可供 Transformer 理解的向量序列
简单比喻:Tokenizer 就像"速记翻译官",把人类语言拆分成小块子词(Token),再翻译成数字(ID + 向量)供 Transformer 处理,每个步骤都有逻辑递进,从最小单位到模型可理解的形式。
4.Context(上下文)

1.什么是 Context(上下文)
在自然语言处理(NLP)中,上下文(Context)指一段文本中,当前词或句子周围的语义信息。换句话说,就是模型生成或理解某个词时,需要参考的前后文信息。
短期上下文:当前句子或短语。
长期上下文:前几句甚至整个文档。
在 Transformer / LLM 中,上下文决定了模型对词义的理解和生成结果。
2. Context 在 Transformer 中的体现
编码器中的上下文
编码器处理输入序列时,每个词的表示不仅包含自身信息,还通过 自注意力机制(Self-Attention) 融合了整个序列中其他词的信息。
例如输入句子:"张三的文章怎么样",编码器在生成"文章"的向量时,会注意到"张三""的""怎么样",这些都是上下文信息。
解码器中的上下文
解码器生成每个词时,除了参考编码器输出(输入的上下文),还会参考已经生成的前面词(自回归上下文)。
这种机制确保:
- 模型生成的句子前后逻辑一致。
- 当前词生成依赖前文,同时结合输入上下文。
3. Self-Attention 与上下文建模
自注意力是 Transformer 捕捉上下文的核心。
-
原理:
每个词生成 Query/Key/Value 向量。
Query 对应当前词,Key/Value 对应整个序列。
通过 Q·K^T 计算每个词对当前词的影响力(注意力分数)。
将注意力权重应用到 Value 上,得到融合了全局上下文的词向量。
-
结果:
每个词的表示包含了整个序列的语义信息。
模型不仅知道词本身,还知道它在上下文里的意义。
4. Multi-Head Attention 与多视角上下文
**多头注意力(Multi-Head Attention)**允许模型从不同角度理解上下文:
每个注意力头关注不同关系,如主语-谓语、定语-名词等。
拼接所有头的输出,得到丰富的上下文表示。
这就是为什么 LLM 能处理复杂语言现象,比如歧义词和长距离依赖。
5. 长序列与上下文窗口
LLM 处理上下文时有 上下文长度限制:
例如 GPT-3 最大 2048 token,GPT-4 可达到 32k token。
超过长度的部分会被截断或滑动窗口处理。
在训练阶段,模型学习 在给定上下文窗口下预测下一个词。
在生成阶段,模型利用前面生成的词作为上下文,自回归生成后续词。
6. 上下文对生成与理解的影响
生成任务:
上下文决定了模型输出的合理性。
缺乏上下文 → 生成不连贯、逻辑不一致。
理解任务:
上下文帮助模型正确理解多义词或指代关系。
例如"它很大",上下文决定"它"指代什么。
7. 总结大白话
Transformer / LLM 的核心能力之一就是 建模上下文。
编码器通过自注意力聚合输入序列信息,解码器通过自回归和交叉注意力结合输入上下文。
上下文决定模型理解和生成效果,是模型智能的基础。
简单比喻:
上下文就像在读一篇文章时,你记住前面写了什么,然后接着写或理解下一句话。
Transformer 通过注意力机制把所有前面词的信息自动融入当前词的表示。

5.RAG
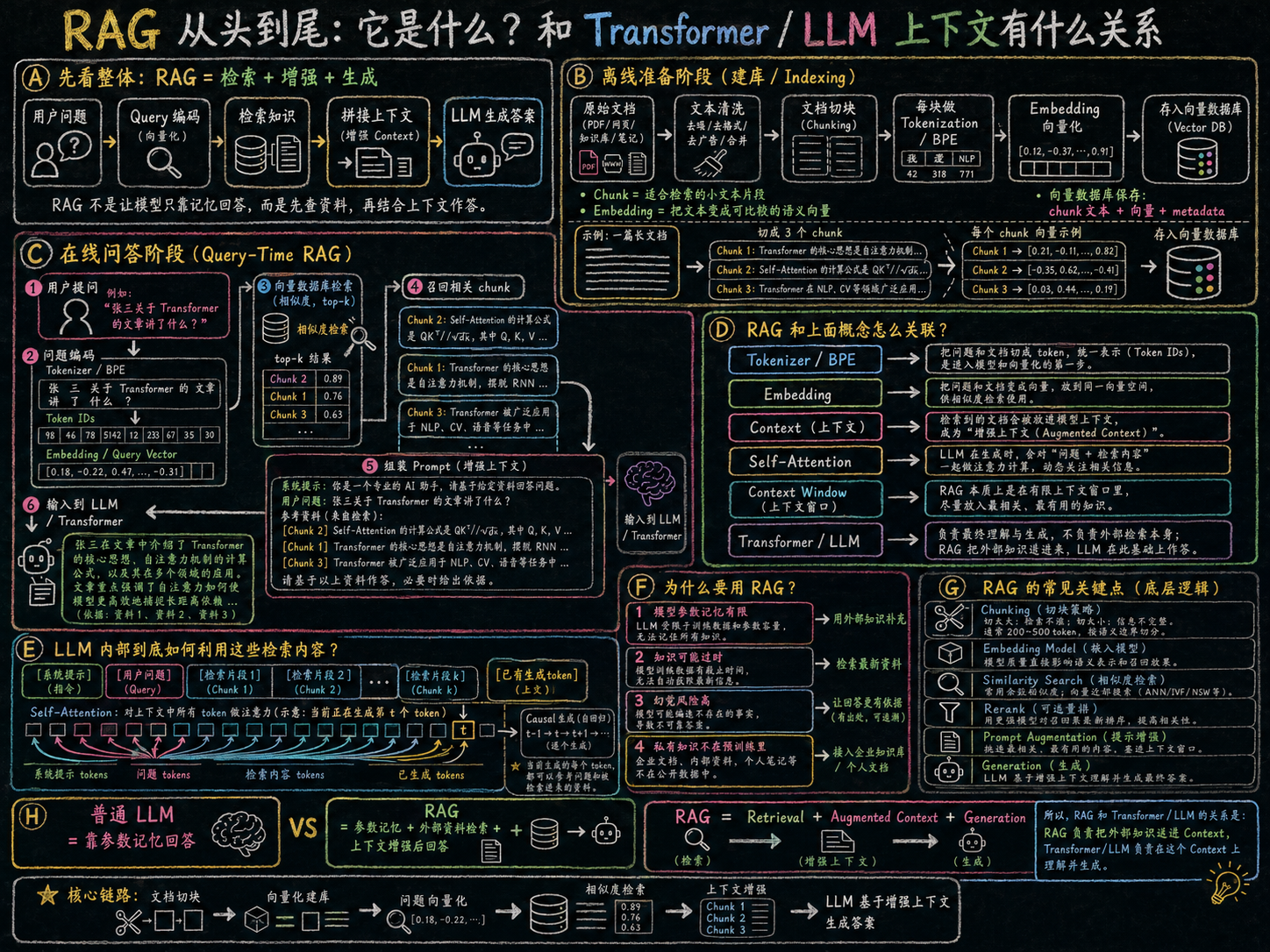
1. RAG 是什么
**RAG(Retrieval-Augmented Generation)**是一种结合 检索(Retrieval) 和 生成(Generation) 的语言模型架构。
目标:解决大语言模型在知识有限或上下文窗口受限时,无法准确回答事实性问题的问题。
核心思想:模型不仅依赖自己内部记忆(预训练参数),还可以从外部知识库检索相关信息,然后再生成回答。
2. RAG 的核心流程
假设你问:"张三的最新研究成果是什么?"
-
查询生成(Query Generation)
模型先将用户输入(问题)编码为向量表示。
Transformer / LLM 将问题转成向量查询,这一步本质上利用了之前讲的 Token → Embedding → 上下文向量。
-
知识检索(Retrieval)
用生成的向量在知识库中检索最相关的文档或段落。
知识库可以是:文档集合(PDF、文章),数据库,互联网索引,返回 top-k 个相关内容。
-
增强上下文(Augmented Context)
将检索到的文本拼接或编码成上下文,供生成模型使用。
Transformer 解码器在生成回答时,可以同时关注:
原始问题上下文(前文问题)
检索到的外部文档上下文
这样生成模型的"上下文窗口"被动态扩展。
-
生成回答(Generation)
解码器根据增强后的上下文逐词生成回答。
自注意力机制确保:
每个生成的词参考原问题和检索内容
保持逻辑一致和事实正确
-
反馈/迭代(可选)
用户可对生成结果进行反馈,进一步调整检索或生成策略。
3. RAG 与 Transformer / LLM 的关系
| 组件 | 对应概念 |
|---|---|
| 用户输入 → Token → Embedding | 上下文建模:Transformer 将问题转为上下文向量 |
| 检索模块 | 外部上下文扩展:增加原始输入上下文无法覆盖的知识 |
| 解码器生成 | LLM 的自回归生成:结合问题向量 + 检索向量生成回答 |
| 注意力机制 | 用于融合原问题与检索文档,实现增强上下文理解 |
总结:
Transformer / LLM 内部的上下文是模型生成回答的基础。
RAG 的增强上下文通过外部知识检索把模型上下文"扩展"到训练语料之外的事实信息。
换句话说,RAG 是 "上下文增强版的 LLM",结合了内部知识和外部知识。
通俗来说,普通 LLM:像一个聪明的人,回答问题只靠记忆。
RAG:聪明的人 + 资料库,你问问题时,他会先去查资料,再结合记忆回答。
Transformer 的自注意力机制仍然在核心负责理解问题和生成回答,只不过现在的上下文更丰富
6.Prompt(提示词)
给大模型发送的具体问题或指令,并不是一个复杂的东西:好的prompt是清晰的,明确的,具体的
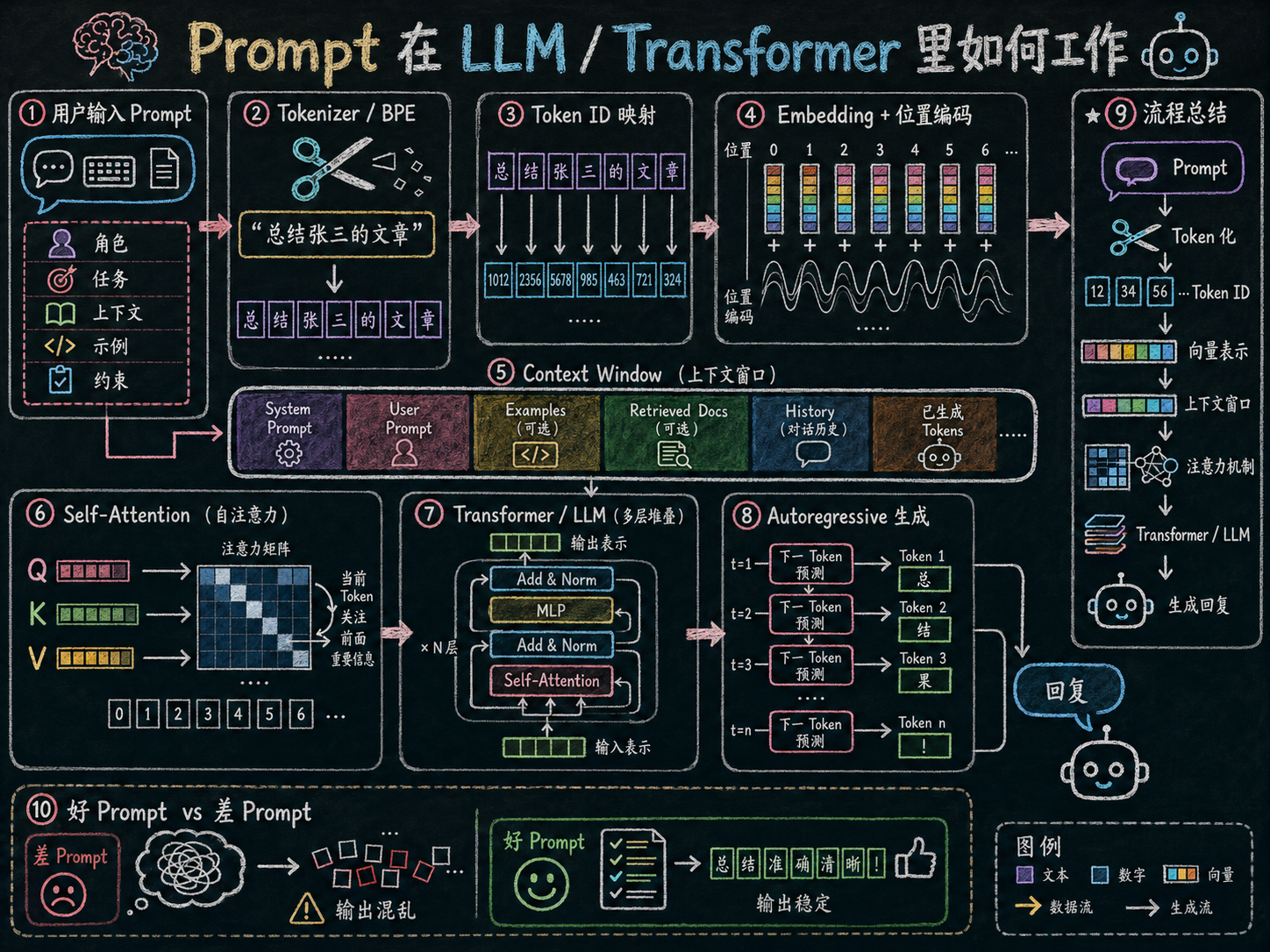
Prompt Engineer
1. 定义与作用
Prompt 工程是为大语言模型(LLM)设计和优化输入的过程,目的是让模型生成符合预期的输出 。
Prompt 是模型生成内容时的上下文条件。用户输入的文本(User Prompt)告诉模型要做什么,而系统配置的指令(System Prompt)告诉模型怎么做。结合两者,模型才能在理解和生成上表现出智能与可控性。
2.Prompt 类型
User Prompt(用户提示)
直接来自用户的任务或问题。
决定模型要完成的具体工作或回答内容。
示例:用户输入"请总结这篇文章的核心观点",或者"写一首关于春天的诗"。
System Prompt(系统提示)
模型运行时的后台指令,定义行为规则、人设或输出风格。
决定模型生成的方式、风格和逻辑约束。
示例:你是一位耐心的数学老师。当学生问问题时,不直接给出答案,而是一步步引导学生思考,帮助理解解题思路。
System Prompt 可以在整个会话或任务中持续影响模型行为。
3. Prompt 设计原则与技巧
- 明确任务:清楚告诉模型需要做什么,例如"生成总结""回答问题""翻译文本"。
- 提供上下文:包括用户问题、相关背景信息或外部文档,帮助模型理解完整语义。
- 控制输出风格:通过 System Prompt 设置行为规则、口吻、风格或格式要求。
- 示例引导:使用 Few-Shot Prompt 提供示例,让模型学习如何回答。
- 分步提示(Chain-of-Thought):引导模型先分析或思考步骤,再生成答案,提高推理能力。
结合 User Prompt 与 System Prompt 的 Prompt 工程方法,能够让模型在理解和生成中同时兼顾任务目标 和行为约束。用户输入告诉模型"做什么",系统指令告诉模型"怎么做",两者共同形成模型的增强上下文,实现准确、连贯且符合规则的输出。
Prompt详解
1.在大语言模型中,Prompt 是人类与模型沟通的桥梁,它就是模型生成内容时的输入文本。
你给模型的任何指令、问题或者示例,都是 Prompt。
可以把它理解为模型的大脑收到的"提示信息",这条信息告诉模型你希望它完成什么样的任务、回答什么样的问题或输出什么风格的内容。
Prompt 的内容直接决定了模型生成结果的方向和逻辑。
2.当模型接收到 Prompt 时,它首先会将文本拆解成 Token,也就是模型能够理解的最小单元。
3.解码器在生成输出时,会同时参考编码器输出的上下文和已经生成的词。这种自回归生成机制保证了生成序列前后逻辑一致,同时参考输入上下文,使输出更准确、更自然。解码器在生成每个词时,模型的自注意力机制会对 Prompt 中的每个 Token 进行加权计算,确保生成的词既符合语义,又符合整体上下文逻辑。
4.Prompt 的设计直接影响生成效果。
明确的指令、合理的示例、充分的上下文都能让模型生成更符合预期的内容。
例如,提供示例和问题的组合,可以让模型学习如何在特定任务中生成答案,这就是少量示例(Few-Shot Learning)提示;
直接告诉模型任务目标而不提供示例,则是零样本(Zero-Shot Learning)提示。
高级提示技术,如 Chain-of-Thought 提示,可以引导模型先"思考步骤",再给出答案,增强推理能力。
7.在 RAG(Retrieval-Augmented Generation)等增强上下文的系统中,Prompt 不仅包括用户输入,还会被扩展为增强上下文,通过外部知识库检索相关文档加入到生成上下文中。这样,模型不仅依赖内部知识,还能结合外部信息生成更精确和丰富的回答。可以理解为 Prompt 是上下文的起点,它为模型提供了生成的条件,而检索到的外部内容则丰富了上下文,使模型能够超越自身参数限制。
总的来说,Prompt 是 LLM 和 Transformer 模型理解和生成的核心,它通过 Token 化、向量化、位置编码和上下文融合,指导模型逐步生成符合人类期望的内容。好的 Prompt 能清楚地传递任务意图、提供充分的上下文,并结合外部知识扩展,使模型能够在理解、推理和生成上表现出最佳能力。Prompt 与上下文紧密结合,是大语言模型智能化表现的基础。
7.tool(工具、函数)

在实际应用中,大模型本身有局限性 。例如当用户提问"实时天气""路线规划"或者一些依赖外部数据的问题时,模型内部的预训练参数并不能提供实时答案,因为它无法感知当前环境或最新数据。这时候就需要借助 Tool(函数/外部能力),将模型生成能力与外部资源结合。
Tool 本质上是一个函数接口,它可以被模型调用,用来获取实时信息、执行计算或访问数据库。用户的问题经过大模型理解后,模型会生成调用 Tool 的请求,例如指明要调用哪种工具、需要哪些参数,然后 Tool 执行操作并返回结果。最终,模型将 Tool 返回的内容整合进回答中,并呈现给用户。
在这个流程中,不同角色协作:
- 用户提供任务或问题,例如"帮我查一下今天上海的路线"。
- 大模型负责理解任务,将用户输入转换为向量化表示,并决定调用哪些工具。
- 工具接收模型请求,执行具体操作,比如计算最短路线、查询数据库或调用 API。
- 平台/系统负责承上启下,将模型与工具连接,并将执行结果返回给模型。
- 大模型将工具返回的结果整合,生成最终自然语言输出,反馈给用户。
为了让流程更直观,我们可以用一些替代的通用工具示例来说明,比如:
- 数据分析工具:计算平均值、统计趋势
- 文档检索工具:查询指定文档或知识库内容
- 计算工具:执行数学公式或科学计算
- 地图工具:规划路线或距离计算
通过这种方式,Tool 不仅扩展了大模型的能力,还使其能够执行实时、复杂或超出训练数据范围的任务。大模型负责理解与规划,Tool 提供外部执行能力,两者结合就能实现智能化应用。
8.MCP(实战后续文章中)
所有工具的同意接入标准,类似于大部分手机都要用type-c接口一个道理。

1.Model(模型)
模型是工具接入的核心,它提供智能能力和推理能力。工具的调用必须明确关联到具体的模型或模型实例,这样模型才能理解任务需求、处理输入,并生成输出。模型不仅负责理解用户问题,还会生成工具调用请求,决定使用哪个 Tool 以及使用哪些参数。
2. Context(上下文)
上下文是工具调用时提供给模型和工具的环境信息,包括用户输入、任务状态、历史交互以及外部知识。Context 保证工具调用的准确性,使模型在执行操作时参考必要的信息。例如,如果用户问"今天的日程安排",Context 会包含日期、用户身份和已有日程数据,保证工具返回正确的结果。
3. Protocol(协议)
协议是模型与工具通信的标准化接口。它定义了工具调用的格式、参数结构、数据传输方式和返回值规范。统一的协议确保不同类型的工具能够被模型无缝调用,并且结果可以被模型正确解析和整合。例如,调用计算器工具或文档检索工具时,协议会规定参数如何传入(如 JSON),输出如何返回,以及错误处理方式。
总结:MCP 提供了工具接入的完整标准和方法。模型(Model)负责智能理解与生成,Context 提供调用所需的环境和信息,Protocol 确保工具调用标准化、可解析。通过 MCP,模型可以安全、稳定、可控地调用多种工具,实现扩展功能,突破自身知识和能力限制。
9.Agent
Agent 并不是一个简单的程序,而是一种 智能执行系统 。它将 大模型的理解与推理能力 与现实世界的 执行能力(调用工具/系统/函数) 有机结合,使大模型不再只是"会说",而是"会做"。

1、什么是 Agent?核心定义
Agent 是大模型的 行动体与执行器 。它不仅能够理解自然语言,还可以根据目标和上下文 自主规划任务步骤 、调用工具或 API 完成操作,并将执行结果整合成自然语言输出。
普通大模型只负责"生成文字/预测下一个词"。
而 Agent 更进一步,它负责"把模型智能转化成实际行动"。
关键在于:
✦ 自主规划
✦ 自主调用工具
✦ 自洽结果输出
Agent = 大模型的大脑 + 行动系统 + 工具调用闭环
2、Agent 的能力维度(核心能力)
1)自主规划
Agent 能从自然语言输入中识别任务目标,自动拆解任务步骤。例如:
用户说:"帮我生成出门清单"。
Agent 会自动理解要点:
✔ 获取用户当前位置
✔ 调用天气服务
✔ 判断天气情况
✔ 决定出门要带的物品
✔ 输出最终清单
这就不是一句话生成,而是一步步拆解和执行。
2)工具调用能力(and MCP标准)
Agent 能够调用外部"工具 / 函数 / API"。
这就是 Agent 真正在现实世界有用的关键。
使用统一的 MCP 接入标准:
| 名称 | 作用 |
|---|---|
| Model(模型) | 提供智能理解 & 计划 |
| Context(上下文) | 当前任务的关联信息 |
| Protocol(协议) | 定义工具调用规范 |
通过 MCP,Agent 能安全且可控地调用工具。
常见工具例子:
🔹 数据库查询 (ERP/CRM)
🔹 计算器/分析引擎
🔹 检索/知识库
🔹 第三方 API (地图/天气/支付)
这使 Agent 能突破模型记忆限制,查询实时数据。
3)上下文感知(Context)
Agent 不是孤立执行,它需要理解任务历史、用户状态、业务背景等信息。
"上下文"决定了 Agent 是否能正确规划:
例如:
"今天下午 2 点的会议要提醒我。"
Agent 必须知道:
- 用户是谁
- 当前日期
- 会议时间
- 是否已经提醒过
上下文是行动规划的基础。
4)结果整合 & 输出
工具调用后的返回只是原始数据。
Agent 的关键是把这些碎片化数据整合成输出结果并反馈用户。
例如:
天气:有雨
位置:经纬度坐标
建议物品:雨伞、口罩整合成:
"今天有雨,请记得带雨伞和口罩"
而不是展示代码、接口返回或原始 JSON。
3、Agent 工作流程(落地执行图)
结合你上传的截图和 Skill 文档示例,可构建如下流程:
用户输入
↓
大模型理解任务 -> 生成计划 & 工具调用意图
↓
调用定位工具 → 获取经纬度
↓
调用天气工具 → 获取天气数据
↓
调用其他业务工具 → 获取特定信息
↓
将返回结果聚合
↓
生成自然语言输出给用户
以上流程体现了:
📌 大模型负责规划逻辑
📌 工具负责真实世界操作
📌 结果由模型整合输出
4、Agent 类别
Agent 并不是一个单一模式,它可依据能力划分为两个层级:
☑ 简单 Agent
简单 Agent 是最小闭环。
它只具备:
✔ 单步任务执行
✔ 单一工具调用
✔ 生成自然语言输出
示例:
"今天上海的天气怎么样?"
输出:调用天气接口 -> 返回天气 -> 输出
⭐ 企业级 Agent
企业级 Agent 是复杂闭环执行系统,它具备:
📌 多步骤规划
📌 多工具协同调用
📌 强上下文处理
📌 可扩展到业务流程
它被用于智能客服、自动生成报表、供应链优化等复杂业务。
5、Agent 与常见框架的关系
现在业界有一些成熟的构建模式:
🔹 ReAct
模型结合推理 + 行动
在思考中生成行动指令
例如:
思考:我需要天气信息
执行:调用天气工具ReAct 使得 Agent 可以边思考边操作。
🔹 Plan-and-Execute
先制定计划,再执行
"分步骤规划 → 执行 → 汇总"
适合需要清晰步骤的大任务。
6、企业级 Agent 价值总结
Agent 的价值在于:
✨ 提升效率
自动流程替代人工操作
✨ 降低错误
统一执行标准 & 规范流程
✨ 增强扩展性
无需重新训练,添加工具即可
✨ 真实落地
模型不再是"生成语言",而是 "解决问题"
总结
企业级 Agent 是大模型逻辑落地执行的桥梁,它不仅能理解用户意图,还能制定任务执行计划、调用内部系统或外部 API、整合多来源的数据,并输出可操作的结果。技术上强依赖 MCP 接口规范与工具生态,使得系统可扩展、可控、安全、效率高。
简单 Agent 则是业务快速落地的最小闭环模型,适用于单步工具调用。
二、Agent搭建
"今天上海的天气怎么样?"
输出:调用天气接口 -> 返回天气 -> 输出
⭐ 企业级 Agent
企业级 Agent 是复杂闭环执行系统,它具备:
📌 多步骤规划
📌 多工具协同调用
📌 强上下文处理
📌 可扩展到业务流程
它被用于智能客服、自动生成报表、供应链优化等复杂业务。
5、Agent 与常见框架的关系
现在业界有一些成熟的构建模式:
🔹 ReAct
模型结合推理 + 行动
在思考中生成行动指令
例如:
思考:我需要天气信息
执行:调用天气工具ReAct 使得 Agent 可以边思考边操作。
🔹 Plan-and-Execute
先制定计划,再执行
"分步骤规划 → 执行 → 汇总"
适合需要清晰步骤的大任务。
6、企业级 Agent 价值总结
Agent 的价值在于:
✨ 提升效率
自动流程替代人工操作
✨ 降低错误
统一执行标准 & 规范流程
✨ 增强扩展性
无需重新训练,添加工具即可
✨ 真实落地
模型不再是"生成语言",而是 "解决问题"
总结
企业级 Agent 是大模型逻辑落地执行的桥梁,它不仅能理解用户意图,还能制定任务执行计划、调用内部系统或外部 API、整合多来源的数据,并输出可操作的结果。技术上强依赖 MCP 接口规范与工具生态,使得系统可扩展、可控、安全、效率高。
简单 Agent 则是业务快速落地的最小闭环模型,适用于单步工具调用。
二、Agent搭建
后续文章中