目录
[支持 len()、in、索引访问(ri)](#支持 len()、in、索引访问(r[i]))
[2. 需要切片赋值](#2. 需要切片赋值)
[2.扩展:使用 range 实现自定义间隔的循环](#2.扩展:使用 range 实现自定义间隔的循环)
[3.扩展:range 与 len 的替代方案](#3.扩展:range 与 len 的替代方案)
[zip() 的作用](#zip() 的作用)
[使用 round() 四舍五入](#使用 round() 四舍五入)
[4.扩展:使用内置函数 sum()、math.fsum() 提高精度](#4.扩展:使用内置函数 sum()、math.fsum() 提高精度)
[5.扩展:累加时进行变换(map 替代)](#5.扩展:累加时进行变换(map 替代))
[2.扩展:使用 collections.Counter](#2.扩展:使用 collections.Counter)
[4. 扩展:使用 defaultdict(int) 实现更灵活的计数](#4. 扩展:使用 defaultdict(int) 实现更灵活的计数)
[defaultdict(int) 的含义](#defaultdict(int) 的含义)
[4.if 判断在 for 循环中的高级应用](#4.if 判断在 for 循环中的高级应用)
[1.any() 与 all() 替代显式循环](#1.any() 与 all() 替代显式循环)
[3.使用 for-else 实现"查找-未找到"模式](#3.使用 for-else 实现“查找-未找到”模式)
[4.使用 filter() 替代带 if 的循环](#4.使用 filter() 替代带 if 的循环)
[代码中的 lambda](#代码中的 lambda)
[lambda 表达式的特点](#lambda 表达式的特点)
[1.使用 enumerate 获得索引的扩展](#1.使用 enumerate 获得索引的扩展)
[2. 使用 zip 并行遍历的扩展](#2. 使用 zip 并行遍历的扩展)
3.无限序列生成:itertools.count、cycle
[4.使用 accumulate 进行累加](#4.使用 accumulate 进行累加)
[5. 使用 for 循环实现滑动窗口](#5. 使用 for 循环实现滑动窗口)
[1.列表推导式 vs for循环追加](#1.列表推导式 vs for循环追加)
[2.使用 map 替代显式循环](#2.使用 map 替代显式循环)
[3. 尽量减少循环内的属性查找](#3. 尽量减少循环内的属性查找)
[4. 使用 timeit 测量不同累加方式](#4. 使用 timeit 测量不同累加方式)
1.range整数列表
range 是 Python 内置的不可变序列类型,专门用于生成等间隔的整数序列。
1.基本用法回顾
# 1. 直接传数字
for i in range(5): # 等价于 0,1,2,3,4
print(i)
# 2. 先定义变量再传入
stop = 5
for i in range(stop): # 这时 stop 已定义,正常运行
print(i) #0,1,2,3,4
# 3. 带起点的 range(start, stop)
for i in range(2, 6): # 2,3,4,5
print(i)
# 4. 带步长的 range(start, stop, step)
for i in range(1, 10, 2): # 1,3,5,7,9
print(i)
# 5. 负步长(倒序)
for i in range(5, 0, -1): # 5,4,3,2,1
print(i)特性:
惰性求值(懒加载)
不预先存储所有数字,只记下起点、终点、步长,每次循环时才"现算"一个数。
r = range(1, 1000000) # 想表示 1 到 999999-
如果是列表,内存里要立刻存下 100 万个整数,很占地方。
-
但
range只记住了start=1, stop=1000000, step=1,占用空间极小。
当你 for i in r: 的时候,它才根据步长逐个 算出下一个数字。
这就叫"惰性"------不着急把所有数据都准备好,用到时再生成。
支持 len()、in、索引访问(r[i])
虽然 range 没把数字全存起来,但你可以像使用列表一样,用这些操作
r = range(10, 20, 2) # 表示 10, 12, 14, 16, 18
print(len(r)) # 5 → 直接根据公式算出来
print(14 in r) # True → 不是挨个遍历,是通过数学计算判断
print(r[2]) # 14 → 直接计算 start + 2 * step = 10 + 4 = 14这些操作都是 O(1) 的快速计算,不需要把数字全展开,非常高效。
可以转换成列表,但通常不需要
确实能把 range 变成一个真实的列表。
但如果你只是为了循环,直接用 range 就够了 ,没必要额外转成列表去占用内存。
只有在需要修改元素、需要切片赋值、或者要传给某个只接受列表的函数时,才考虑转换。
range显示转换成list
当需要以下这些操作时,就必须把 range 显式转换成 list,否则会报错或得不到想要的结果:
1.需要修改元素
range 是不可变序列,不能像列表那样给某个位置赋新值。
# 错误:range 不支持元素赋值
r = range(5)
r[2] = 10 # TypeError: 'range' object does not support item assignment
# 正确:先转成列表再修改
lst = list(range(5))
lst[2] = 10 # lst 现在是 [0, 1, 10, 3, 4]报错
Traceback (most recent call last):
File "c:\Users\wozha\Desktop\vs\python\1.py", line 3, in <module>
r2 = 10 # TypeError: 'range' object does not support item assignment
TypeError: 'range' object does not support item assignment
2. 需要切片赋值
列表可以一次性替换掉一段连续的元素,range 做不到。
# 错误:range 不支持切片赋值
r = range(10)
r[2:5] = [20, 30] # TypeError
# 正确:转为列表后切片赋值
lst = list(range(10)) # [0,1,2,3,4,5,6,7,8,9]
lst[2:5] = [20, 30] # 用两个元素替换掉索引 2,3,4 的三个位置
print(lst) # [0, 1, 20, 30, 5, 6, 7, 8, 9]3.传给只接受列表的函数
有些函数或方法要求传入 list 类型 ,传 range 会报错。典型如:
-
random.shuffle():需要原地打乱顺序,必须传可变列表。 -
一些只声明了
list参数类型的旧接口或第三方库函数。import random
错误:shuffle 不接受 range
r = range(10)
random.shuffle(r) # TypeError: 'range' object does not support item assignment正确:先转成列表
numbers = list(range(10))
random.shuffle(numbers)
print(numbers) # 例如 [3, 7, 0, 9, 1, 5, 8, 2, 4, 6]
range 是不可变序列 ,而 random.shuffle 要求原地修改序列,两者冲突
random.shuffle(x) 会直接打乱传入的序列 x (就地修改),它内部通过随机交换两个位置的元素来实现洗牌。
2.扩展:使用 range 实现自定义间隔的循环
# 反向步长
for i in range(10, 0, -2):
print(i) # 10, 8, 6, 4, 2
# 生成等差数列,但需要浮点步长时怎么办?range 不接受浮点,可以用 numpy.arange 或手动 while
# 或者使用 itertools.count 配合 takewhile3.扩展:range 与 len 的替代方案
当需要遍历列表索引时,enumerate 比 range(len(...)) 更优雅:
len() 只是计算了列表的长度,返回一个数字。比如 len(fruits) 返回 3。这个 3 被用在 range() 里,生成了一个索引序列 0, 1, 2。然后 for 循环依次取这些索引,通过 fruits[i] 获取元素,再用 print() 输出。
enumerate 是 Python 内置函数,用于将一个可迭代对象 (如列表、元组、字符串)组合成一个索引序列 ,让你在循环中同时获取元素的索引 和元素本身。
fruits = ["苹果", "香蕉", "橙子"]
# 不推荐
for i in range(len(fruits)):
print(f"{i}: {fruits[i]}")
# 推荐
for i, fruit in enumerate(fruits):
print(f"{i}: {fruit}")
# 如果还需要修改原列表元素,仍然可以用 range,但可以结合 enumerate 和索引赋值
for i, fruit in enumerate(fruits):
fruits[i] = fruit + "好吃"
print("修改后:", fruits) #修改后: ['苹果好吃', '香蕉好吃', '橙子好吃']2.累加
1.累加基础回顾
total = 0
for i in range(1, 101):
total += i
print(total)2.扩展:加权求和
scores = [85, 92, 78, 88] # 成绩
weights = [0.3, 0.2, 0.4, 0.1] # 对应的权重
weighted_sum = 0 # 初始化加权和
for s, w in zip(scores, weights):
weighted_sum += s * w # 累加成绩×权重
print(weighted_sum) # 输出 83.9zip() 的作用
-
zip(scores, weights)将两个列表中位置相同的元素打包成元组:-
第1次迭代:
(85, 0.3) -
第2次迭代:
(92, 0.2) -
第3次迭代:
(78, 0.4) -
第4次迭代:
(88, 0.1)
-
-
通过
for s, w in zip(...)将每个元组解包给变量s和w,实现并行遍历。
3.扩展:累乘与对数累加
import math # 导入了 math 模块,但本代码中并未使用(可以删除)
data = [2, 4, 8] # 原始数据
product = 1 # 初始化乘积为 1(累乘的起点)
for x in data: # 遍历列表中的每个数
product *= x # 累乘:product = product * x
geometric_mean = product ** (1 / len(data)) # 几何平均 = 所有数的乘积 开 n 次方
print(geometric_mean) # 输出 3.9999999999999996 ** 是 Python 中的幂运算符,用于计算一个数的乘方(指数运算)。
使用 round() 四舍五入
geometric_mean = round(product ** (1/len(data)), 10) # 保留10位小数4.扩展:使用内置函数 sum()、math.fsum() 提高精度
sum() 可以对任何可迭代对象求和,底层使用 C 循环,比手动 for 快。
total = sum(range(1, 101)) # 5050
print(total)对于浮点数累加,math.fsum() 能提供更高精度(使用 Kahan 求和算法)。
import math
float_list = [0.1] * 10
print(sum(float_list)) # 0.9999999999999999
print(math.fsum(float_list)) # 1.05.扩展:累加时进行变换(map 替代)
如果需要先对元素进行某种变换再累加,可以用生成器表达式:
# 平方和
numbers = [1,2,3,4]
total = sum(x**2 for x in numbers) # 30这比手动for更简洁高效
3.计数器
统计与分组
1.基础计数器回顾
count = 0
data = [2, 4, 8]
condition = 2
for x in data:
if x==condition:
count += 1
print(count)2.扩展:使用 collections.Counter
当需要统计多个类别时,手动计数器写起来较繁琐。Counter 是专门为计数设计的字典子类:
from collections import Counter
data = ['a', 'b', 'a', 'c', 'b', 'a']
counter = Counter(data)
print(counter) # Counter({'a':3, 'b':2, 'c':1})甚至可以一次性统计频率
from collections import Counter
sentence = "hello world"
counter = Counter(sentence)
print(counter) # 包含空格、字母的计数
# Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})3.扩展:多条件计数与分组
假设有一个学生列表(姓名、成绩),统计及格与不及格人数:
students = [('Alice', 85), ('Bob', 58), ('Charlie', 92), ('David', 45)]
pass_cnt = 0
fail_cnt = 0
for name, score in students:
if score >= 60:
pass_cnt += 1
else:
fail_cnt += 1用 Counter 也可以,但需要先映射:
status = ['及格' if score>=60 else '不及格' for _, score in students]
counter = Counter(status)
print(counter) # Counter({'及格':2, '不及格':2})循环部分:for _, score in students
-
students是一个可迭代对象,通常包含多个学生的信息。假设每个元素是一个元组或列表,例如[('张三', 85), ('李四', 42), ('王五', 73), ('赵六', 58)]。 -
_是一个常见的占位符变量名,表示忽略该位置的值。这里假设每个学生数据的第一项(如姓名)不需要使用,只关心第二项(分数)。 -
score接收每个学生的分数。
4. 扩展:使用 defaultdict(int) 实现更灵活的计数
from collections import defaultdict
counts = defaultdict(int)
for x in data:
counts[x] += 1defaultdict(int) 的含义
-
defaultdict是内置字典dict的子类,当访问的键不存在时,不会抛出KeyError,而是自动调用传入的工厂函数生成一个默认值。 -
int作为工厂函数,调用int()返回整数0。所以counts[x]如果不存在,会自动初始化为0,然后+= 1将值变为1。 -
如果键已存在,
counts[x]返回当前值,然后加 1。
4.if 判断在 for 循环中的高级应用
1.any() 与 all() 替代显式循环
当只需要判断是否存在或是否全部满足时,可以用内置函数:
any(iterable)
含义 :只要可迭代对象中至少有一个元素为
True,就返回True;如果所有元素都为False(或可迭代对象为空),则返回False。逻辑 :相当于"或 "运算的短路版本------一旦遇到第一个真值,立即返回
True。
all(iterable)
含义 :只有可迭代对象中所有元素都为
True,才返回True;如果存在至少一个False,则返回False(空的可迭代对象返回True)。逻辑 :相当于"与 "运算的短路版本------一旦遇到第一个假值,立即返回
False。
numbers = [2,4,6,8]
# 是否存在奇数?
has_odd = any(x % 2 == 1 for x in numbers)
print(has_odd) # False
# 是否全部为偶数?
all_even = all(x % 2 == 0 for x in numbers)
print(all_even) # True这些函数内部会短路(类似 break),比手动 for 更简洁。
2.在循环中捕获异常
当遍历可能引发异常的操作时,可以用 try-except 包裹:
data = ['1', '2', 'abc', '4']
total = 0
for item in data:
try:
total += int(item)
except ValueError:
print(f"跳过非数字: {item}")
print(total) # 1+2+4=7核心机制:try-except
-
int(item)如果item不是合法的整数表示(如'abc'),会抛出ValueError异常。 -
except ValueError捕获该异常,执行异常处理代码(打印提示),然后继续下一次循环。 -
正常转换的项(
'1','2','4')会被成功累加到total。
3.使用 for-else 实现"查找-未找到"模式
# 查找列表中第一个大于 50 的数
numbers = [12, 45, 67, 23]
for n in numbers:
if n > 50:
print(f"找到: {n}")
break
else:
print("未找到大于50的数")else 在未触发 break 时执行,非常适合这种"如果找到了就处理,没找到就做另一件事"的场景。
4.使用 filter() 替代带 if 的循环
# 筛选出偶数
numbers = range(10)
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
# 等价于列表推导式 [x for x in numbers if x % 2 == 0]filter 返回迭代器,惰性求值。
filter 是 Python 内置函数,用于筛选可迭代对象中满足条件的元素,返回一个迭代器。
lambda表达式
代码中的 lambda
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))-
lambda x: x % 2 == 0定义了一个匿名函数,等价于:def is_even(x): return x % 2 == 0 -
filter函数接收两个参数:一个函数和一个可迭代对象。它会将numbers中的每个元素传入 lambda 函数,保留返回True的元素。
lambda 表达式的特点
-
单行表达式,不能包含语句或赋值。
-
常用于需要简单函数但不想正式定义
def的场合(如filter,map,sorted的key参数等)。
5.循环的进阶工具与模式
1.使用 enumerate 获得索引的扩展
enumerate 可以指定起始值:
fruits = ["苹果", "香蕉", "橙子"]
for idx, fruit in enumerate(fruits, start=1):
print(f"{idx}. {fruit}")2. 使用 zip 并行遍历的扩展
zip 可以处理不等长序列(以最短的为准)。若要以最长的为准并填充缺失值,使用 itertools.zip_longest:
from itertools import zip_longest
a = [1,2,3]
b = ['a','b']
for x, y in zip_longest(a, b, fillvalue=None):
print(x, y) # 1 a, 2 b, 3 None3.无限序列生成:itertools.count、cycle
count(start, step) 生成无限递增序列,常与 takewhile 配合:
from itertools import count, islice
for i in count(10, 2):
if i > 20:
break
print(i) # 10,12,14,16,18,20
# 或者使用 islice 限制个数
for i in islice(count(0, 5), 3): # 0,5,10
print(i)cycle 重复遍历一个序列:
from itertools import cycle
colors = ['红', '绿', '蓝']
for i, color in zip(range(5), cycle(colors)):
print(i, color) # 0红,1绿,2蓝,3红,4绿4.使用 accumulate 进行累加
itertools.accumulate 返回累积和(或其他二元运算):
from itertools import accumulate
data = [1,2,3,4]
cumsum = list(accumulate(data)) # [1,3,6,10]
# 指定运算符
import operator
cumprod = list(accumulate(data, operator.mul)) # [1,2,6,24]5. 使用 for 循环实现滑动窗口
def sliding_window(iterable, size):
result = []
for i in range(len(iterable) - size + 1):
result.append(iterable[i:i+size])
return result
print(sliding_window([1,2,3,4,5], 3)) # [[1,2,3],[2,3,4],[3,4,5]]6.性能对比与优化建议
1.列表推导式 vs for循环追加
import timeit
# 使用 for 循环 + append
def loop_append():
result = []
for i in range(1000):
result.append(i**2)
return result
# 使用列表推导式
def list_comp():
return [i**2 for i in range(1000)]
print(timeit.timeit(loop_append, number=10000))
print(timeit.timeit(list_comp, number=10000))
# 列表推导式通常快 20%~50%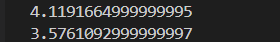
2.使用 map 替代显式循环
当只需要对每个元素应用函数时,map 通常比 for 循环更快(因为内部 C 循环):
result = list(map(lambda x: x**2, range(1000)))3. 尽量减少循环内的属性查找
data = [1,2,3,4]
# 不推荐
for i in range(len(data)):
data[i] = data[i] * 2
print(data)
# 推荐:将 data 赋值给局部变量
lst = data
for i in range(len(lst)):
lst[i] = lst[i] * 2
print(data)
# 或者使用 enumerate
for i, val in enumerate(data):
data[i] = val * 2
print(data)
4. 使用 timeit 测量不同累加方式
# 手动循环
def manual_sum(n):
s = 0
for i in range(n):
s += i
return s
# 内置 sum
def builtin_sum(n):
return sum(range(n))
print(timeit.timeit(lambda: manual_sum(10000), number=1000))
print(timeit.timeit(lambda: builtin_sum(10000), number=1000))
# sum 通常更快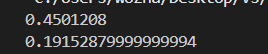
感谢你的观看,期待我们下次再见!