PointNet 发表于 CVPR 2017,PointNet++ 发表于 NIPS 2017,两者都来自斯坦福大学。前者提出了用一个对称函数(Max Pooling)来处理天然无序的点集,实现了端到端的点云学习。后者针对 PointNet 无法感知局部结构的缺陷,引入了层级化的特征提取,使网络能够像 CNN 处理图像那样,从局部到全局逐步提炼语义。
第一部分:PointNet
1.1 点云数据有哪三个挑战
点云数据有三个性质,使得传统的卷积神经网络完全无法直接使用:
挑战一:无序性(Unordered)
图像的像素排列在一个规则的二维网格上,像素 (i, j) 永远在它该在的地方。但点云没有这种规则结构------同一个物体,LiDAR 扫描的顺序完全取决于扫描路径和采样过程,可能今天先扫到车顶,明天先扫到车轮。本质上,一个有 N 个点的点云,有 N! 种排列方式,都代表同一个形状。
网络必须对这 N! 种排列都给出相同的输出。
挑战二:局部结构中的点间交互(Interaction among Points)
点不是独立的------相邻点之间有空间结构关系。这个关系包含了表面法线、曲率、边缘走向等几何信息。网络不能只处理每个点,还必须建模点之间的关系。
挑战三:几何变换不变性(Invariance under Transformations)
同一个椅子,无论你把它旋转多少度、放在坐标系的哪个位置,它还是那把椅子。网络对于点云经过刚体变换(旋转 + 平移)之后应当给出一致的语义预测。
PointNet 的设计是一个完整的三层解法:
- 用对称函数(Max Pooling)解决排列不变性
- 用 T-Net 解决几何变换不变性
- 通过共享权重的 MLP + Max Pooling 的组合隐式建模局部交互
1.2 整体架构概览
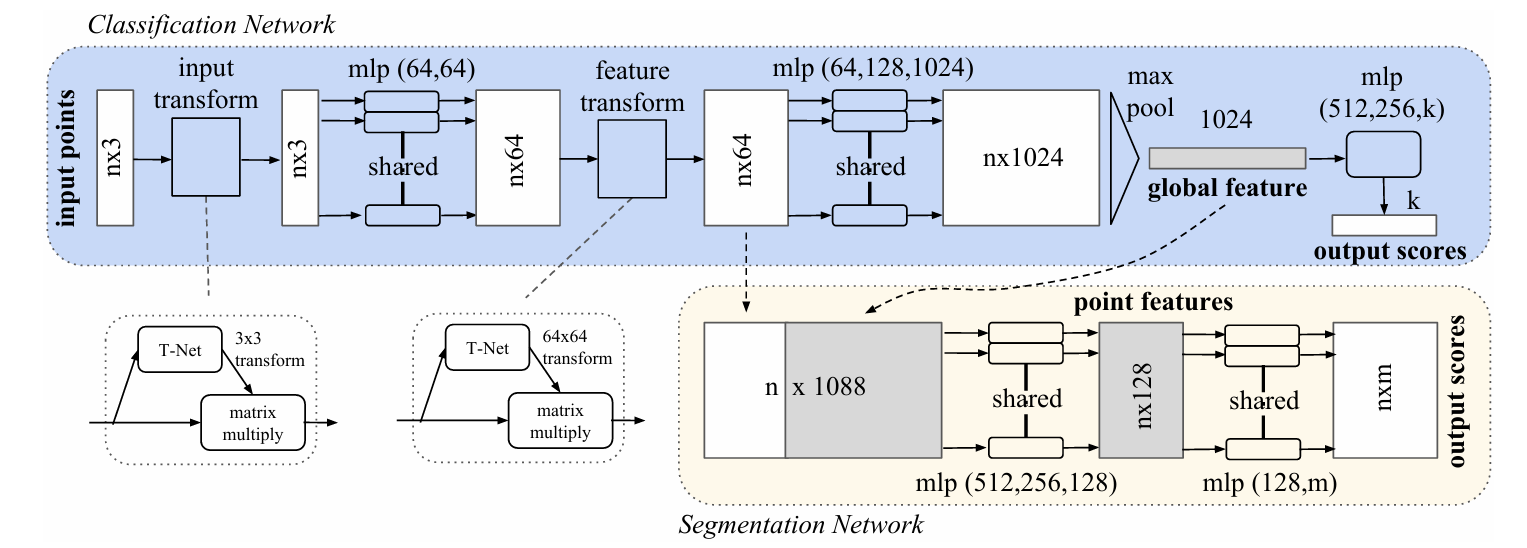
PointNet 接受 N 个点作为输入,每个点有 d 个特征(最简单的情况是 d=3,即 (x, y, z) 坐标)。输入的形状是 (N, 3)。
整个网络的数据流分为以下几个阶段(以分类任务为例):
输入点云: (N, 3)
↓ Input T-Net(3×3 变换矩阵)
对齐后点云: (N, 3)
↓ Shared MLP(64, 64)
逐点特征: (N, 64)
↓ Feature T-Net(64×64 变换矩阵)
对齐后特征: (N, 64)
↓ Shared MLP(64, 128, 1024)
逐点高维特征: (N, 1024)
↓ Global Max Pooling(over N dimension)
全局特征向量: (1024,)
↓ MLP(512, 256, k)
分类输出: (k,) ← k 是类别数
对于分割任务,全局特征 (1024,) 会被复制 N 次变成 (N, 1024),再和逐点特征 (N, 64) 拼接,得到 (N, 1088),然后用 MLP 预测每个点的标签。
1.3 Shared MLP:不是矩阵乘,是逐点独立处理
PointNet 用的 MLP 是所有点共享权重的,英文叫 Shared MLP 或 Point-wise MLP。
具体来说,对输入 (N, 3),第一个 MLP 的操作是:对每个点的 3 维坐标,独立地用同一套权重做线性变换 + BN + ReLU,输出 64 维特征。这可以用 1×1 卷积来高效实现(和 PointPillars 里的操作一样):把 (N, 3) 视为有 N 个位置、每个位置 3 个通道的"序列",用 1×1 卷积(即 Conv1D,kernel_size=1)实现对每个位置独立的 3 到 64 维的映射。
为什么叫共享?因为所有点用的是同一套权重参数,不是位置 1 的点用一套权重,位置 2 的点用另一套。这种共享保证了网络对点的排列不敏感。
1.4 T-Net:用一个小网络预测变换矩阵
T-Net 是 PointNet 中重要设计之一。
设计动机:点云可能以任意朝向出现。如果在送进特征提取网络之前,先把点云对齐到一个标准姿态(canonical space),后续的特征提取就不需要对每个朝向都学一遍。
如何对齐? 预测一个仿射变换矩阵,把点云乘上这个矩阵,就完成了对齐。
T-Net 本身就是一个小型的 PointNet:
输入: (N, 3) ← 当前点云
↓ Shared MLP(64, 128, 1024)
(N, 1024)
↓ Global Max Pooling
(1024,)
↓ FC(512) → FC(256) → FC(3×3=9)
输出: 9 个数字,reshape 成 (3, 3) 的变换矩阵 T
然后用这个矩阵对输入点云做变换:
这个变换在训练时是可微的,因为 T 是网络预测的,整个过程端到端可以反向传播。
第二个 T-Net(特征空间对齐) :在逐点特征变成 64 维之后,还有第二个 T-Net,预测一个 的变换矩阵,对特征空间也做对齐:
正交约束的正则化项:64 维的变换矩阵优化空间极大,完全自由地优化容易产生数值不稳定。论文加了一个正则化项,约束变换矩阵 A 尽量接近正交矩阵:
其中 是 Frobenius 范数(矩阵各元素平方和的平方根)。正交矩阵满足
,偏离程度由这个 Loss 项控制,加入到总损失中,权重系数为 0.001。
为什么正交矩阵是好的? 正交变换是旋转(或反射),它保持向量的内积和范数,即不改变几何形状,只改变朝向。约束 A 接近正交矩阵,实际上是在告诉网络"你预测的变换应该尽量是旋转,而不是任意的仿射拉伸"。
1.5 Global Max Pooling
在所有点经过 Shared MLP 变成 (N, 1024) 的逐点特征之后,需要把它们聚合成一个固定长度的全局描述符。
PointNet 的选择是 Channel-wise Global Max Pooling:对每个特征维度,取 N 个点在该维度上的最大值。(N, 1024) → (1024,)。
为什么是 Max 而不是 Sum 或 Average?
从数学上说,对称函数是指对其输入集合的任意排列都产生相同输出的函数。Max、Sum、Average 都是对称函数。但论文通过实验证明 Max Pooling 效果最好。
1.6 关键点集:PointNet 为什么对噪声鲁棒
论文在理论部分证明了一个非常直觉的结论:对于最终的全局特征向量 f 中的每一维,都只有少数几个点(那个维度上取得最大值的点)真正贡献了这一维的信息。其余的点,不管它们如何变动,只要那些关键点不变,f 就不变。
形式化地,设 CS 是所有关键点的集合(即在某个维度上取得全局最大值的那些点),论文证明了:
- f 对 CS 以外的所有点的扰动、删除、或增加都是不敏感的
- 只要 CS 中的点不发生变化,f 就不变
- CS 的大小(关键点的数量)不超过特征维度数 K=1024
这个性质在直觉上解释了 PointNet 对噪声和点缺失的鲁棒性:即便你随机删掉 50% 的点,只要关键点还在,全局特征就不会变化太多。
1.7 分类头和分割头的维度细节
分类任务:
全局特征: (1024,) ← Global Max Pooling 的输出
↓ FC(512) + BN + ReLU + Dropout(0.3)
(512,)
↓ FC(256) + BN + ReLU + Dropout(0.3)
(256,)
↓ FC(k) ← k 是类别数,如 ModelNet40 中 k=40
(40,)
↓ Softmax
(40,) 概率分布
分割任务:分割需要逐点预测,因此既要全局信息(这是什么物体),又要局部信息(这个点属于哪个部件)。PointNet 的解法是把全局特征拼接到每个点的局部特征上:
逐点特征(来自第二个 T-Net 之后): (N, 64)
全局特征(重复 N 次): (N, 1024) ← 用 repeat/expand 操作
↓ Concatenate along feature dim
(N, 1088) ← 64 + 1024 = 1088
↓ Shared MLP(512, 256, 128, m) ← m 是 part 类别数
(N, m)
↓ Per-point Softmax
(N, m) ← 每个点的分类概率
第二部分:PointNet++
理解了 PointNet 之后,它的局限性其实很清晰:
PointNet 没有局部结构感知 。所有点的特征是独立提取的(Shared MLP 对每个点独立操作),然后用一个 Global Max Pooling 聚合成全局特征。点之间的空间邻域关系在这个过程中完全没有被利用。
对比 CNN 处理图像的方式:CNN 用卷积核在图像上滑动,卷积核覆盖的小邻域里的像素相互交互,产生局部特征;这些局部特征再逐层聚合成更大尺度的特征。这种从局部到全局的层次化特征提取,使得 CNN 能够识别边缘、纹理、形状,最终理解语义。
PointNet 跳过了这一切,直接从点的原始坐标跳到全局特征。在简单物体(如 ModelNet40 的椅子、桌子)上,这已经足够好了。但在需要精细局部结构理解的场景(如室内场景语义分割、细粒度 part 分割)上,PointNet 就明显力不从心了。
PointNet++ 的核心思路 :把 CNN 的层次化局部特征提取搬到非均匀、无序的点集上------通过一种叫做 **Set Abstraction(集合抽象)**的模块,递归地对点集做"局部采样 → 邻域划分 → 局部 PointNet"的操作,从细粒度到粗粒度逐步提炼语义。
2.1 Set Abstraction
Set Abstraction(SA)是 PointNet++ 的核心构件,每一个 SA 层完成三件事:采样(Sampling)→ 分组(Grouping)→ 局部 PointNet。
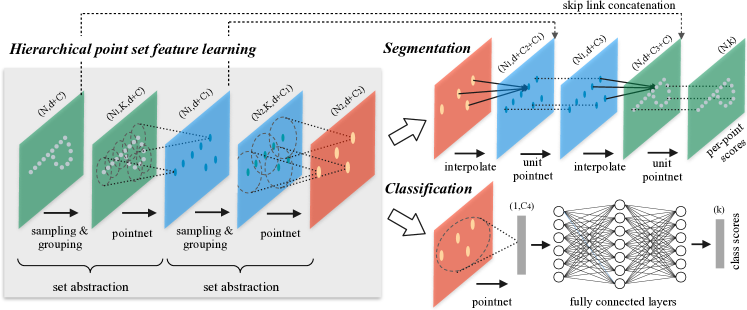
2.1.1 Set Abstraction 的输入输出
一个 SA 层接受一个点集,输出一个更稀疏的点集(中心点)及其对应的特征向量。
输入 : 的矩阵,其中 N 是点的数量,d 是坐标维度(通常 d=3),C 是每个点的附加特征维度(在第一个 SA 层,C=0,只有坐标;在后续层,C 是上一层提取的特征维度)。
输出 : 的矩阵,其中 N' < N 是子采样后的中心点数量,C' 是新提取的特征维度。
用 PointNet++ 论文的符号记法,一个 SA 层写成:
:输出的中心点数量
2.2.2 Sampling Layer:最远点采样(FPS)
目标:从 N 个点里选出 N' 个点作为中心点,这些中心点要尽可能均匀地覆盖整个点云。
方法 :Farthest Point Sampling(最远点采样,FPS)
算法步骤:
- 随机选一个点
- 从所有点里选出离
- 从所有点里选出离
- 重复直到选出
为什么不用随机采样? 随机采样在点密集的区域会过度采样,在稀疏区域欠采样,导致中心点分布不均匀,某些区域得不到充分的特征提取。FPS 的最远点策略天然地倾向于在稀疏区域也选出代表性的点,覆盖更加均匀。
FPS 的随机性:第一个点的选择是随机的,所以每次 FPS 的结果略有不同。论文实验显示,这个随机性对最终分类结果的影响非常小,因此不需要担心。
FPS 后得到 N' 个中心点的坐标,形状 (N', 3)。
2.2.3 Grouping Layer:Ball Query 分组
目标:以每个中心点为球心,半径为 r,找出球内的所有点,形成该中心点的"局部邻域"。
Ball Query 算法:
- 对于每个中心点
- 为了计算效率,设置邻域内点数的上限 K
- 若邻域内点数 < K:随机重复采样已有点来填充到 K 个(zero padding 也是一种方式,但重复采样更常见)
- 若邻域内点数 > K:随机丢弃多余的点
输出:(N', K, d+C) 的 Tensor,每个中心点对应 K 个邻域点,每个点有 d+C 维特征。
Ball Query vs K-NN:
论文比较了 Ball Query 和 K 近邻(K-NN)两种邻域查找方式。主要区别是:
- Ball Query:固定物理半径,邻域内点数可变(通过截断统一到 K)。局部邻域对应固定的空间区域,跨不同位置的特征更具可比性------在密集区域 K 个点覆盖较小范围,在稀疏区域可能覆盖较大范围。
- K-NN:固定点数,但对应的物理区域大小可变。在均匀密度点云上效果相当,但在非均匀密度点云(真实 LiDAR 数据)上,K-NN 会导致不同区域的局部感受野物理尺度差异巨大,泛化性差。
结论:Ball Query 更适合需要局部模式识别的任务(如语义分割),因为它保证了局部区域的物理尺度一致性。
一个关键的坐标系转换 :在把邻域点送进局部 PointNet 之前,需要把每个邻域点的坐标转换到以中心点为原点的局部坐标系:
其中 是中心点坐标,
是邻域内第 i 个点的坐标。
这一步至关重要,如果不转换,同一种局部几何形状(比如一个平面)在空间不同位置的绝对坐标完全不同,局部 PointNet 就必须学会"这些点虽然绝对坐标不同,但相对排列一样"。这既困难又低效。
转换到局部坐标系后,同一种几何形状不管在空间哪里出现,它在局部坐标系里的点排列都是一样的,局部 PointNet 可以高效地学习和复用这些局部模式------就像 CNN 的卷积权重共享一样。
2.2.4 PointNet Layer:局部特征提取
输入:(N', K, d+C),即 N' 个局部邻域,每个邻域有 K 个点,每个点 d+C 维。
操作:对每个局部邻域独立地运行一个小型 PointNet:
- Shared MLP(各层宽度为
- Channel-wise Max Pooling over K:从 K 个点聚合出一个局部特征向量
输出 :,即 N' 个中心点,每个中心点有一个
维的特征向量,编码了该中心点局部邻域的几何信息。
结合中心点坐标,最终输出形状为 ,作为下一个 SA 层的输入。
2.2 一个完整的 SSG维度追踪
以论文 ModelNet40 分类任务的 SSG 网络架构为例,完整追踪维度变化:
输入点云: (B, 1024, 3) ← B=batch size, N=1024, d=3
== 第一个 SA 层: SA(512, r=0.2, 64,64,128) ==
Sampling(FPS): (B, 512, 3) ← 选出 512 个中心点坐标
Grouping(Ball r=0.2, K=32):(B, 512, 32, 3) ← 每个中心点找 32 个邻域点(K 由实现决定)
坐标局部化: (B, 512, 32, 3) ← 减去各自中心点坐标
PointNet Layer:
MLP(3→64)+ BN+ReLU: (B, 512, 32, 64)
MLP(64→64)+BN+ReLU: (B, 512, 32, 64)
MLP(64→128)+BN+ReLU:(B, 512, 32, 128)
MaxPool over K=32: (B, 512, 128)
拼接中心点坐标: (B, 512, 3+128) = (B, 512, 131) ← 输出给下一层
== 第二个 SA 层: SA(128, r=0.4, 128,128,256) ==
输入: (B, 512, 131) ← 512 个点,131 维(3 坐标 + 128 特征)
Sampling(FPS): (B, 128, 3) ← 选出 128 个中心点坐标
Grouping(Ball r=0.4, K=64):(B, 128, 64, 131)
坐标局部化: (B, 128, 64, 3) ← 只对坐标部分做局部化
PointNet Layer:
MLP(131→128)+...: (B, 128, 64, 128)
MLP(128→128)+...: (B, 128, 64, 128)
MLP(128→256)+...: (B, 128, 64, 256)
MaxPool over K=64: (B, 128, 256)
拼接中心点坐标: (B, 128, 3+256) = (B, 128, 259)
== 第三个 SA 层: SA(256,512,1024)(全局,无采样和分组)==
输入: (B, 128, 259)
此层对所有 128 个点做一次全局 PointNet:
MLP(259→256)+...: (B, 128, 256)
MLP(256→512)+...: (B, 128, 512)
MLP(512→1024)+...: (B, 128, 1024)
Global MaxPool: (B, 1024) ← 全局特征向量
== 分类头 ==
FC(1024→512) + BN + ReLU + Dropout(0.5): (B, 512)
FC(512→256) + BN + ReLU + Dropout(0.5): (B, 256)
FC(256→40): (B, 40)
Softmax: (B, 40)
2.3 密度自适应------MSG 和 MRG
SSG(Single Scale Grouping)是 PointNet++ 最基础的版本,每个 SA 层只用一个固定半径 r 做 Ball Query。但这有一个问题:真实 LiDAR 扫描的点云密度是非均匀的,近处的物体点密集,远处的点稀疏。用固定半径 r,在密集区域可能邻域内有很多点(精细),在稀疏区域可能邻域内几乎没有点(粗糙),泛化性很差。
论文提出了两种密度自适应方法。
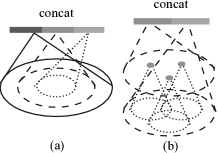
2.3.1 Multi-Scale Grouping(MSG,多尺度分组)
思路 :在同一层,用多个不同半径 (
)分别做 Ball Query,每个尺度用一个独立的 PointNet 提特征,然后把不同尺度的特征拼接起来。
对于某个中心点:
- 小半径
- 大半径
把三个尺度的特征向量拼接,每个中心点的特征既包含精细局部信息,又包含宏观上下文信息。
以论文 MSG 网络的第一个 SA 层为例:
- 512 个中心点
- 3 个半径:0.1、0.2、0.4
- 对应 3 个 PointNet,输出维度分别为 64、128、128
- 三个特征拼接:64 + 128 + 128 = 320 维维度变化:
随机 Input Dropout 训练策略 :为了让 MSG 学会在不同密度下自适应地利用不同尺度特征,训练时对每个 batch 随机丢弃一定比例的点(丢弃概率从 均匀采样)。这样网络在训练时见过各种密度的点云,学会了如果局部点密度低,就更多依赖大尺度特征;如果密度高,就利用细粒度特征。
2.3.2 Multi-Resolution Grouping(MRG,多分辨率分组)
MSG 的问题是计算量大:在每个中心点位置,要做多个不同尺度的 Ball Query + PointNet,尤其在最底层(中心点最多时)代价极高。
MRG 提出了一种更高效的替代:利用层级关系,把不同层的特征拼接来模拟多尺度。
对于 层的某个局部区域,MRG 计算两个特征向量:
向量 A(精细) :把 层在这个区域内的各个子区域的特征,通过 SA 层聚合起来。这个特征包含了从更底层提取的精细局部信息。
向量 B(粗粒度) :直接对这个区域内的所有原始点(或 层的点)运行一个单独的 PointNet,得到粗粒度特征。
然后把 A 和 B 拼接起来。
当局部区域密度高时,A 更可靠(底层的子区域特征包含精细信息);当密度低时,A 来自底层子区域,而底层子区域更稀疏,A 不可靠,这时 B(直接处理当前层的点)更稳健。
MRG 的计算效率比 MSG 更高,因为它不需要在底层对大邻域做昂贵的 PointNet 计算,而是复用了已经计算好的层级特征。
2.4 Feature Propagation------从粗糙到精细的特征反传
对于分割任务 (语义场景分割、part 分割),最终需要为每个原始点预测一个标签。但 SA 层是在做下采样------每经过一层,点的数量从 N 变成更小的 N'。
如何把特征从少量的中心点传播回原始的大量点?PointNet++ 的解法是 Feature Propagation(FP,特征传播)层 ,使用基于距离的插值(Inverse Distance Weighted Interpolation)。
2.4.1 插值公式
设 层有
个点(已有特征),需要把特征插值到
层的
个点(
)。
对于 层的每个点 x,找到
层中距离它最近的 k 个点(论文默认 k=3),用距离的倒数加权平均来插值特征:
其中 是点 x 到第 i 个近邻的距离,p=2(距离的平方反比),j = 1, ......, C 遍历所有特征维度。
为什么用距离倒数加权? 距离越近的点贡献越大(权重越高),距离越远的点贡献越小。这是一种保持空间平滑性的插值方式,比线性插值更适合非均匀分布的点云。
2.4.2 Skip Link + Unit PointNet
插值后, 个点有了来自上一层的特征 C' 维。这个特征和 SA 阶段保留的
层的原始特征(Skip Link,C 维)拼接起来:C + C'
然后用一个小型的 MLP(论文叫"unit PointNet",等价于 1×1 卷积)处理每个点的拼接特征,更新特征向量。
这个过程和 U-Net 的 decoder 非常相似:跳跃连接(skip link)把 encoder 层的精细特征直接传给 decoder,补充 decoder 里因为上采样可能损失的局部细节。
2.4.3 完整的分割网络维度追踪
以论文 ScanNet 语义场景分割网络为例:
架构:4 个 SA 层(下采样)+ 4 个 FP 层(上采样)
== 下采样阶段 ==
输入: (B, N, 3) N=8192
SA1(1024, 0.1, 32,32,64): (B, 1024, 3+64) = (B, 1024, 67)
SA2(256, 0.2, 64,64,128): (B, 256, 3+128) = (B, 256, 131)
SA3(64, 0.4, 128,128,256):(B, 64, 3+256) = (B, 64, 259)
SA4(16, 0.8, 256,256,512):(B, 16, 3+512) = (B, 16, 515)
== 上采样阶段(FP 层,从底部往上传播)==
FP1: 从 SA4 的 16 个点插值到 SA3 的 64 个点
插值后: (B, 64, 512)
Skip link(SA3): (B, 64, 256)
Concat: (B, 64, 768)
MLP(256,256): (B, 64, 256)
FP2: 从 64 个点插值到 256 个点
插值后: (B, 256, 256)
Skip link(SA2): (B, 256, 128)
Concat: (B, 256, 384)
MLP(256,256): (B, 256, 256)
FP3: 从 256 个点插值到 1024 个点
插值后: (B, 1024, 256)
Skip link(SA1): (B, 1024, 64)
Concat: (B, 1024, 320)
MLP(256,128): (B, 1024, 128)
FP4: 从 1024 个点插值到原始 N 个点
插值后: (B, N, 128)
Skip link(输入点云特征,如果有的话): (B, N, ...)
MLP(128,128,128,128,K): (B, N, K) ← K 是语义类别数
Per-point Softmax: (B, N, K)
最终每个原始点都有一个 K 维的概率向量,取 argmax 即为该点的预测语义标签。