RAG 系统中的重排序(Reranking)是对初始检索结果进行二次排序的核心后处理环节。初始检索通常依赖向量相似度或关键词匹配,返回的结果在语义相关性上存在噪声,重排序通过更精细的相关性判断模型对候选文档重新打分,将最相关的内容提升到前列,从而提高大模型接收到的上下文质量。
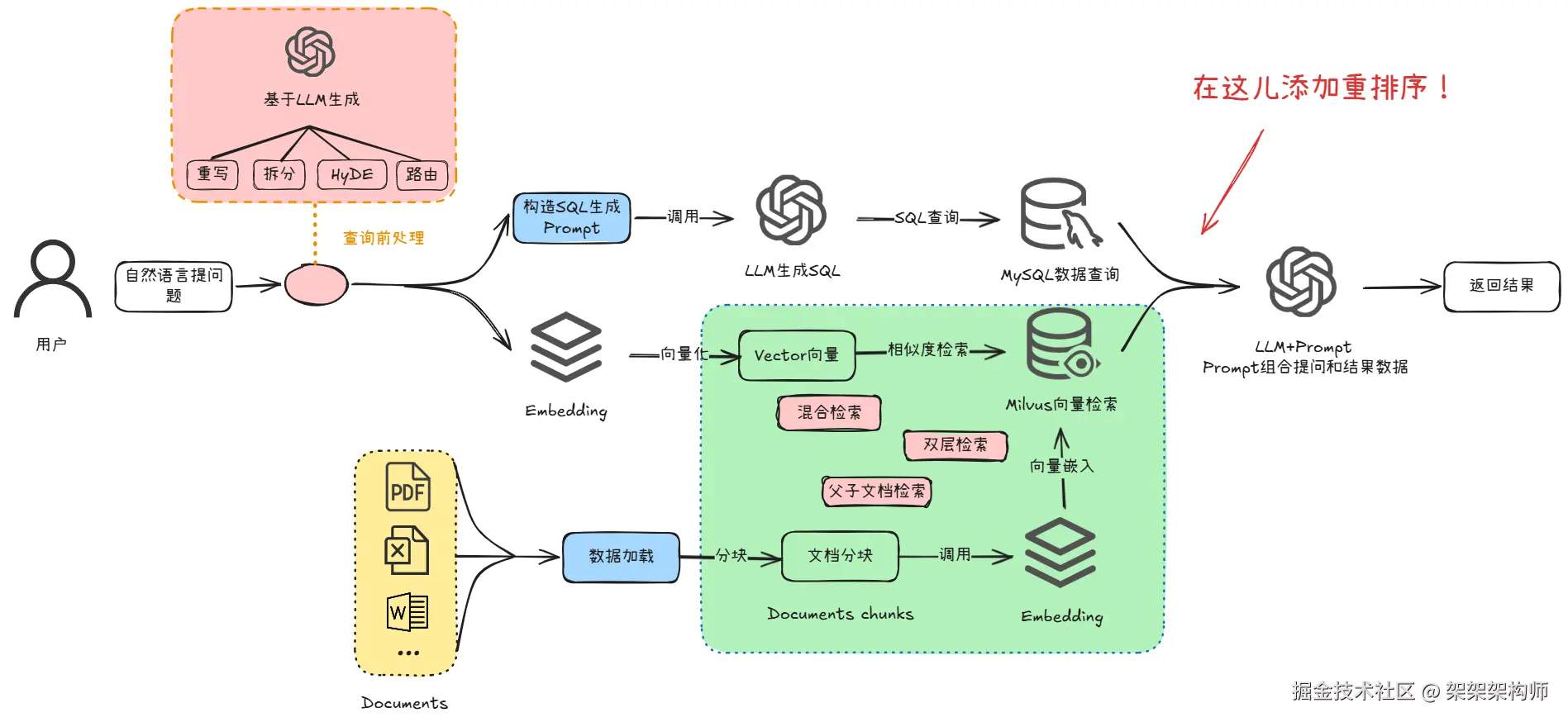
下面我们就来分享下重排序的几种方法
RRF重排
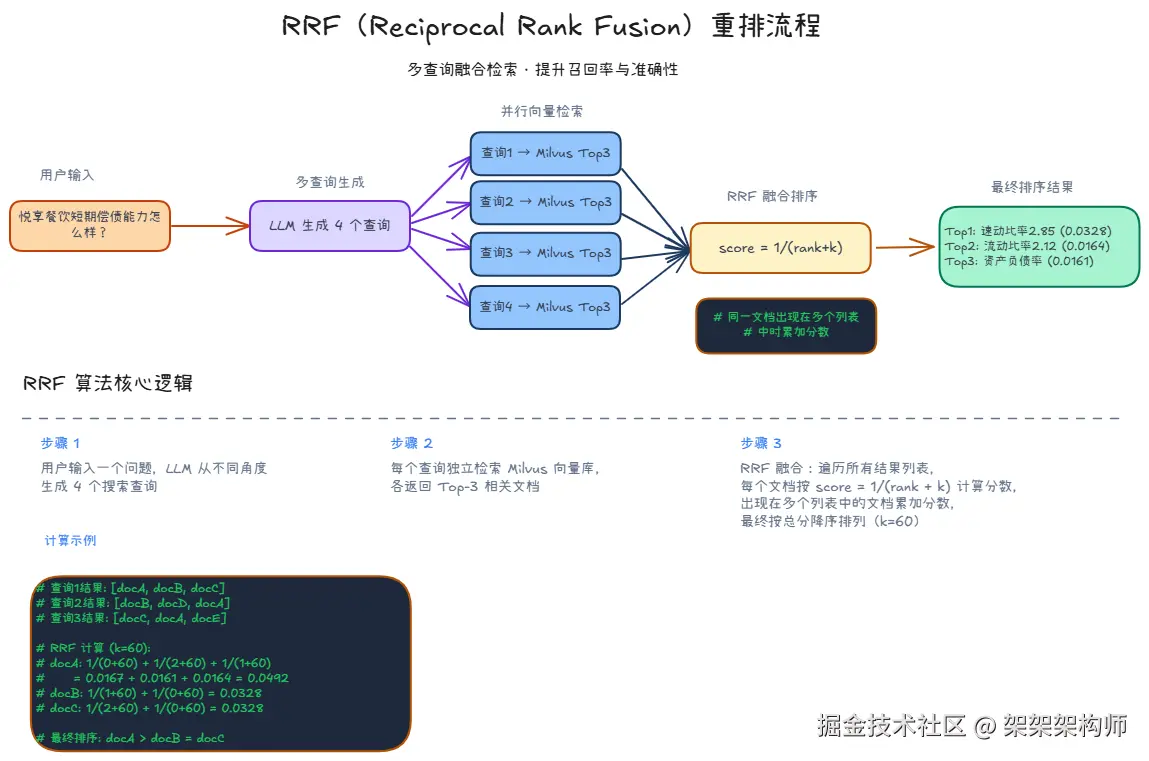
RRF(Reciprocal Rank Fusion)是一种简单而有效的多检索结果融合算法,它通过将多个检索查询的结果进行排名合并,来提高检索的准确性和覆盖面。
核心思想:
- 对于同一个用户问题,生成多个不同角度的查询
- 分别对每个查询进行检索
- 使用
RRF算法将多个检索结果列表融合成一个统一的排序列表 RRF算法为每个文档分配分数:score = 1/(rank + k),其中rank是该文档在某个结果列表中的排名
优势:实现简单、速度快、没有算力成本
劣势:缺乏深层语义理解,精度弱于模型类重排算法
流程图
代码样例
python
import os
import uuid
from dotenv import load_dotenv
from openai import OpenAI
from langchain_classic.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Milvus
from langchain_classic.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.embeddings import Embeddings
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI
from langchain_classic.load import dumps, loads
load_dotenv()
# ===================== 配置初始化 =====================
OPENAI_API_KEY = os.getenv("GLM_API_KEY")
OPENAI_BASE_URL = os.getenv("GLM_BASE_URL")
EMBEDDING_MODEL = os.getenv("GLM_EMBEDDING_MODEL", "embedding-3")
MILVUS_URI = os.getenv("MILVUS_URI", "http://localhost:19530")
COLLECTION_NAME = "finance_report_rrf"
# 兼容 LangChain 的嵌入适配器
class OpenAIEmbeddingsAdapter(Embeddings):
def __init__(self, client, model):
self.client = client
self.model = model
def embed_documents(self, texts):
response = self.client.embeddings.create(input=texts, model=self.model)
return [item.embedding for item in response.data]
def embed_query(self, text):
return self.embed_documents([text])[0]
client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
embed_model = OpenAIEmbeddingsAdapter(client, EMBEDDING_MODEL)
# ===================== 文档加载 =====================
def parse_finance_document():
"""构建财务分析示例文档"""
texts = [
"悦享餐饮2020-2023财务综合分析报告:短期偿债能力分析。"
"2020~2023年间,悦享餐饮速动比率分别为2.85、2.07、1.48和1.53,"
"流动比率分别为2.12、2.24、1.61和1.68,整体呈先降后升趋势。"
"2022年受非流动资产增加影响,流动比率大幅回落;"
"2023年加强应付账款管控,流动资产增加,短期偿债能力略有改善。",
"悦享餐饮2020-2023财务综合分析报告:长期偿债能力分析。"
"资产负债率先升后降(21.56%->22.03%->28.15%->26.87%),"
"产权比率同步变动(28.0%->39.9%->36.7%)。"
"2022年受外部冲击,应付账款大增,资产负债率攀升至28.15%;"
"2023年优化资产结构,总资产增至188652.47万元,负债回落。",
"悦享餐饮2020-2023财务综合分析报告:营运能力分析。"
"应收账款周转率从25.12次降至15.34次后回升至18.65次;"
"存货周转率波动较大(10.87->8.23->12.35->11.68)。",
"悦享餐饮2020-2023财务综合分析报告:盈利能力分析。"
"2020~2021年毛利率稳定在60%左右,2022年大幅下滑至-10.23%,2023年回升至8.65%。"
"净资产收益率同步下降,主要受门店扩张成本和疫情影响。",
"悦享餐饮2020-2023财务综合分析报告:发展能力分析。"
"2022年新增5家门店,成本3256.87万元,加剧资金压力;2023年暂停扩张。"
"营业收入增长率从2021年的15.2%下降至2022年的-8.3%,2023年恢复至5.1%。",
]
return [Document(page_content=t) for t in texts]
def reciprocal_rank_fusion(results: list[list], k=60):
"""
RRF(Reciprocal Rank Fusion)算法实现
参数:
results (list[list]): 多个检索结果列表,每个列表包含按相关性排序的文档
k (int): RRF算法的调节参数,默认值60(经验值)
返回:
list: 融合后的(文档, 分数)元组列表,按分数降序排序
算法原理:
score = 1 / (rank + k),同一文档出现在多个列表中时累加分数
"""
fused_scores = {}
for docs in results:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results
# ===================== 构建向量索引 =====================
print("正在加载文档...")
docs = parse_finance_document()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
print(f"文档已切分为 {len(splits)} 个文本块")
print("正在创建 Milvus 向量索引...")
vectorstore = Milvus(
embedding_function=embed_model,
collection_name=COLLECTION_NAME,
connection_args={"uri": MILVUS_URI},
auto_id=True,
)
vectorstore.add_documents(splits)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
print("向量索引创建完成")
# ===================== 配置多查询生成器 =====================
template = """你是一个帮助用户生成多个搜索查询的助手。
请根据以下问题生成4个不同角度的相关搜索查询,这些查询应该:
1. 从不同的角度理解原问题
2. 使用不同的关键词和表达方式
3. 覆盖问题的不同方面
原问题:{question}
请生成4个相关的搜索查询:"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(
model="glm-4", temperature=0, api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL
)
generate_queries = (
prompt_rag_fusion
| llm
| StrOutputParser()
| (lambda x: [q.strip() for q in x.split("\n") if q.strip()])
)
# ===================== 测试 RRF 重排 =====================
questions = [
"悦享餐饮的短期偿债能力怎么样?",
"2022年毛利率为什么下滑?",
"门店扩张对财务有什么影响?",
]
for idx, question in enumerate(questions, 1):
print(f"\n{'='*50}")
print(f"问题 {idx}: {question}")
print('='*50)
# 生成多个查询
queries = generate_queries.invoke({"question": question})
print(f"生成了 {len(queries)} 个查询:")
for i, query in enumerate(queries, 1):
print(f" 查询 {i}: {query}")
# 对每个查询进行检索
all_results = []
for query in queries:
query_docs = retriever.invoke(query)
all_results.append(query_docs)
# 使用RRF算法融合结果
reranked_docs = reciprocal_rank_fusion(all_results)
# 展示最终结果
print(f"\nRRF重排结果(前3个):")
for i, (doc, score) in enumerate(reranked_docs[:3], 1):
content_preview = doc.page_content[:200].replace('\n', ' ').strip()
print(f"\n 排名 {i} (RRF分数: {score:.4f}):")
print(f" 内容: {content_preview}...")
if doc.metadata:
print(f" 来源: {doc.metadata.get('source', '未知')}")RankLLM重排
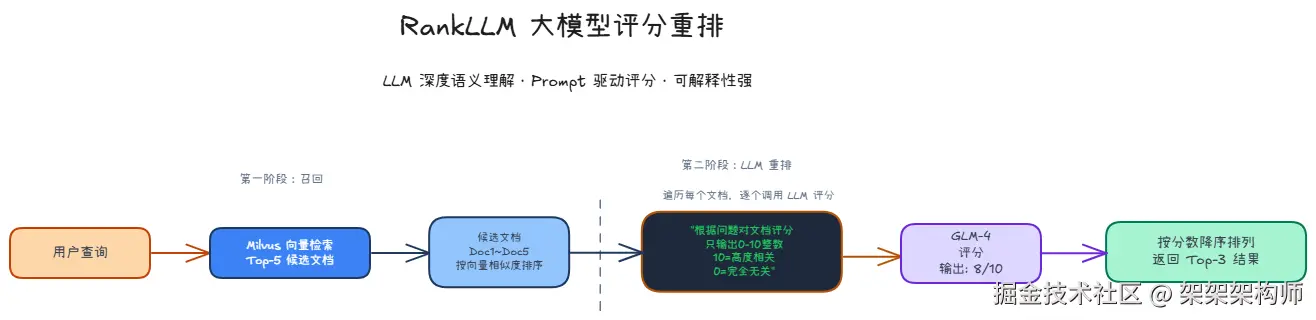
利用大语言模型(LLM)的深度语言理解能力进行文档重排,通过 prompt engineering 引导 LLM 对每个文档进行相关性评分。
优势:语义理解最深、推理能力强、可解释性好
劣势:成本高(LLM API调用)、延迟大
流程图
代码样例
python
import os
from dotenv import load_dotenv
from openai import OpenAI
from langchain_community.vectorstores import Milvus
from langchain_core.embeddings import Embeddings
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# ===================== 配置初始化 =====================
OPENAI_API_KEY = os.getenv("GLM_API_KEY")
OPENAI_BASE_URL = os.getenv("GLM_BASE_URL")
EMBEDDING_MODEL = os.getenv("GLM_EMBEDDING_MODEL", "embedding-3")
MILVUS_URI = os.getenv("MILVUS_URI", "http://localhost:19530")
COLLECTION_NAME = "finance_report_rankllm"
class OpenAIEmbeddingsAdapter(Embeddings):
def __init__(self, client, model):
self.client = client
self.model = model
def embed_documents(self, texts):
response = self.client.embeddings.create(input=texts, model=self.model)
return [item.embedding for item in response.data]
def embed_query(self, text):
return self.embed_documents([text])[0]
client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
embed_model = OpenAIEmbeddingsAdapter(client, EMBEDDING_MODEL)
# ===================== 文档加载 =====================
texts = [
"悦享餐饮2020-2023财务综合分析报告:短期偿债能力分析。"
"2020~2023年间,速动比率分别为2.85、2.07、1.48和1.53,"
"流动比率分别为2.12、2.24、1.61和1.68,整体呈先降后升趋势。",
"悦享餐饮2020-2023财务综合分析报告:长期偿债能力分析。"
"资产负债率先升后降(21.56%->22.03%->28.15%->26.87%),"
"2022年受外部冲击,应付账款大增,资产负债率攀升至28.15%。",
"悦享餐饮2020-2023财务综合分析报告:盈利能力分析。"
"2020~2021年毛利率稳定在60%左右,2022年大幅下滑至-10.23%,2023年回升至8.65%。"
"净资产收益率同步下降,主要受门店扩张成本和疫情影响。",
"悦享餐饮2020-2023财务综合分析报告:发展能力分析。"
"2022年新增5家门店,成本3256.87万元,加剧资金压力;2023年暂停扩张。"
"营业收入增长率从2021年的15.2%下降至2022年的-8.3%,2023年恢复至5.1%。",
"悦享餐饮2020-2023财务综合分析报告:营运能力分析。"
"应收账款周转率从25.12次降至15.34次后回升至18.65次;"
"存货周转率波动较大(10.87->8.23->12.35->11.68)。",
]
docs = [Document(page_content=t) for t in texts]
# ===================== 创建 Milvus 向量检索器 =====================
vectorstore = Milvus(
embedding_function=embed_model,
collection_name=COLLECTION_NAME,
connection_args={"uri": MILVUS_URI},
auto_id=True,
)
vectorstore.add_documents(docs)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# ===================== LLM 重排器 =====================
grade_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个文档相关性评分员。根据用户问题对文档进行评分。\n"
"只输出一个0-10的整数分数,10表示高度相关,0表示完全无关。"),
("human", "用户问题:{question}\n\n文档内容:{document}\n\n相关性分数(0-10):"),
])
llm = ChatOpenAI(model="glm-4", temperature=0, api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
grader = grade_prompt | llm | StrOutputParser()
def llm_rerank(query, docs, top_n=3):
"""
LLM 重排:对每个文档调用 LLM 评分,按分数降序返回前 top_n 个
参数:
query: 用户查询
docs: 候选文档列表
top_n: 返回文档数
返回:
list: 按 LLM 评分排序的 (文档, 分数) 元组列表
"""
scored_docs = []
for doc in docs:
try:
score_str = grader.invoke({
"question": query,
"document": doc.page_content
})
score = int(score_str.strip())
except (ValueError, TypeError):
score = 0
scored_docs.append((doc, score))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:top_n]
# ===================== 执行查询和重排 =====================
query = "2022年毛利率为什么下滑?"
# 第一阶段:Milvus 向量检索候选文档
candidate_docs = retriever.invoke(query)
# 第二阶段:LLM 重排
reranked = llm_rerank(query, candidate_docs, top_n=3)
print(f"查询: {query}\n")
print("LLM 重排结果(前3个):")
for i, (doc, score) in enumerate(reranked, 1):
print(f"\n 排名 {i} (相关性分数: {score}/10):")
print(f" 内容: {doc.page_content[:150]}...")
if doc.metadata:
print(f" 来源: {doc.metadata.get('source', '未知')}")CrossEncoder重排
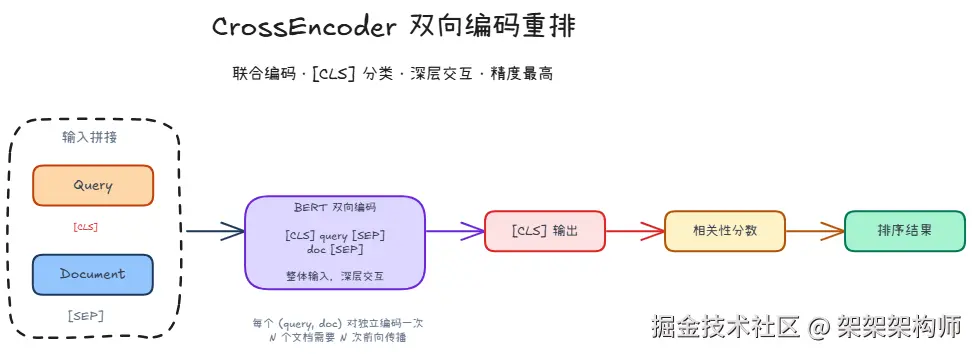
CrossEncoder是一种基于BERT的双向编码器重排模型,将查询和文档作为一个整体输入,利用[CLS]标记的输出预测相关性分数,能够捕捉查询与文档之间的深层交互。
优势:精度高、语义理解强
劣势:计算开销大,每个查询-文档对需单独编码,不适合第一阶段检索(从海量的文档里快速粗筛选出少量的候选文档)
流程图
代码样例
ini
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 1. 加载预训练的CrossEncoder模型
model_name = "cross-encoder/ms-marco-MiniLM-L-12-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
def encode_and_score(query, docs):
"""
计算查询与每个文档的相关性分数
输入格式: [CLS] query [SEP] document [SEP]
分数越高表示相关性越强
"""
scores = []
for doc in docs:
inputs = tokenizer(
query, doc,
return_tensors="pt",
truncation=True,
max_length=512,
padding="max_length"
)
with torch.no_grad():
outputs = model(**inputs)
score = outputs.logits[0][0].item()
scores.append(score)
return scores
# 2. 测试数据(财务分析场景)
query = "悦享餐饮2022年毛利率为什么下滑?"
documents = [
"2020~2021年毛利率稳定在60%左右,2022年大幅下滑至-10.23%,2023年回升至8.65%。"
"净资产收益率同步下降,主要受门店扩张成本和疫情影响。",
"2022年新增5家门店,成本3256.87万元,加剧资金压力;2023年暂停扩张。"
"营业收入增长率从2021年的15.2%下降至2022年的-8.3%。",
"2020~2023年间,速动比率分别为2.85、2.07、1.48和1.53,"
"流动比率分别为2.12、2.24、1.61和1.68,整体呈先降后升趋势。",
"资产负债率先升后降(21.56%->22.03%->28.15%->26.87%),"
"2022年受外部冲击,应付账款大增,资产负债率攀升至28.15%。",
]
# 3. 执行CrossEncoder重排
scores = encode_and_score(query, documents)
ranked_docs = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
# 4. 输出重排结果
print(f"查询: {query}\n")
print("CrossEncoder重排结果(按相关性分数降序):")
for rank, (doc, score) in enumerate(ranked_docs, start=1):
if score > 0:
level = "高度相关"
elif score > -2:
level = "中等相关"
else:
level = "低相关"
print(f"\n 排名 {rank} (分数: {score:.4f}, {level}):")
print(f" {doc[:100]}...")总结
| 重排算法 | 核心原理 | 核心优势 | 主要劣势 | 典型使用场景 |
|---|---|---|---|---|
| RRF | 多维度查询检索,通过公式1/(rank+k)融合排名得分 |
实现简单、速度快、无算力成本 | 无深层语义理解,精度偏低,依赖查询质量 | 多路召回合并、高并发快速检索 |
| RankLLM | 借助大模型 + 提示词,逐文档人工规则化打分排序 | 语义理解极强、具备逻辑推理、结果可解释 | 调用成本高、接口延迟大 | 专业问答、复杂推理、需要结果解释 |
| CrossEncoder | 拼接问句与文档整体编码,依靠 BERT 双向交互计算相关分 | 语义匹配精准、相关性判别能力强 | 逐对编码耗时高、算力开销大 | 搜索业务精排、RAG 少量候选文档排序 |
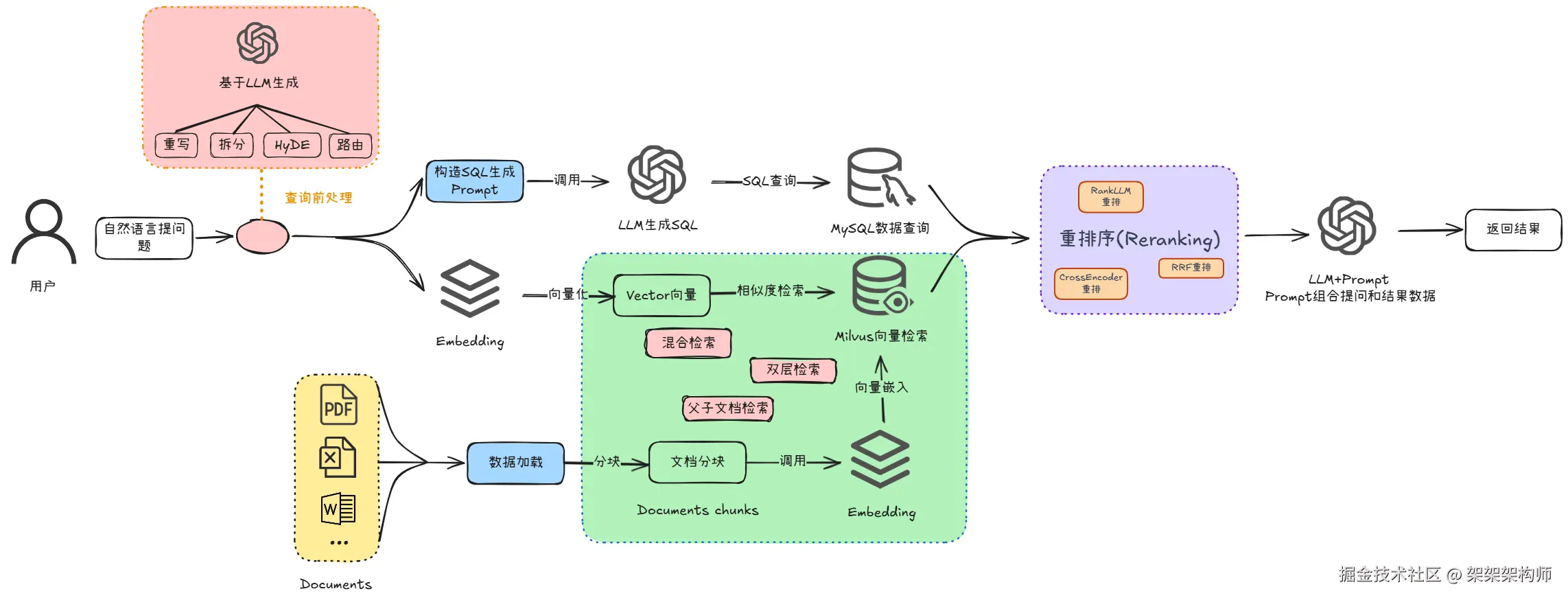
总的来说,通过重排序提升检索结果排序精度,将原始的初始检索结果打磨为高质量的生成上下文。好了,RAG系统的重排序就分享到这儿,在座的亦菲、彦祖们有想要讨论的,欢迎到评论区留言哦!