昨天 Karpathy 发了一条推,说自己正式加入 Anthropic 了。
OpenAI 联合创始人,特斯拉前 AI 总监,斯坦福 CS231n 主讲人,Eureka Labs 创始人。
兜兜转转,最后站到了 Anthropic 这边。
这次他去的是 Claude 预训练团队,跟着 Nick Joseph 干,还要新拉一支队伍专门研究怎么用 Claude 做 AI Coding。
消息一出,X 上直接炸了。
Karpathy 再 GitHub 上影响力也挺大的,开源了很多有影响力的开源项目。
这个人的风格很鲜明,用最少的代码,讲最深的道理。
没有花里胡哨的架构,没有一堆依赖,核心逻辑经常就几百行,但每一个都值得反复看。
挑出 5 个最有代表性的项目推荐一哈。
01
花 100 块训练你自己的 ChatGPT
Karpathy 说 100 美元就能从头训练一个自己的 ChatGPT 出来。
nanochat 就是干这个的。
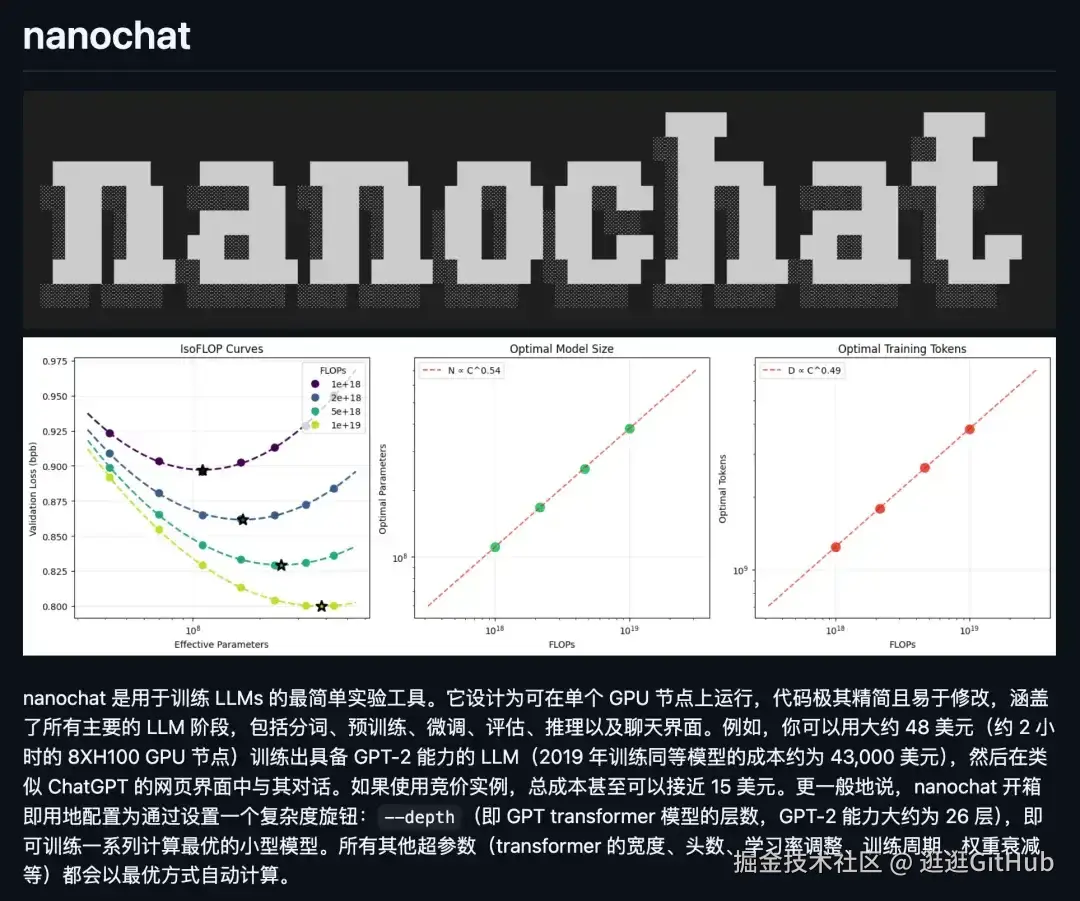
它的定位很简单:The best ChatGPT that $100 can buy. 100 美元买到的最好 ChatGPT。
你租一台云 GPU 服务器,跑一个脚本,4 小时之后就能在类 ChatGPT 的 Web 界面里跟自己训练的模型聊天了。

从自定义 Rust tokenizer 到分布式训练再到 Web 推理服务,完整的一条链路全在一个仓库里搞定。
代码刻意保持 hackable,意思是你可以随便改着玩。不是那种配了一堆依赖你不敢动的框架,而是你打开看一遍就能理解整个流程的那种。
这个项目也是 karpathy 在他的 AI 教育公司 Eureka Labs 推出的课程 LLM101n 的毕业项目。
课程教你怎么从零构建 LLM,nanochat 是最终产物。
说白了,这个项目是给那些想搞懂 ChatGPT 完整链路的人准备的。比读论文有用 100 倍,因为你真的能跑起来。
最近听张小 jun 的播客,姚顺宇在面试 Anthropic 之前好像也研究了这个项目。
arduino
开源地址:https://github.com/karpathy/nanochat02
让 AI Agents 自动帮你做研究
这个项目是 karpathy 所有仓库里 Star 最多的。
是一个让 AI 自己跑实验的工具。
autoresearch 做的事情很简单但很炸裂:在单张 GPU 上,让 AI agents 自动基于 nanochat 进行训练实验和科学研究。
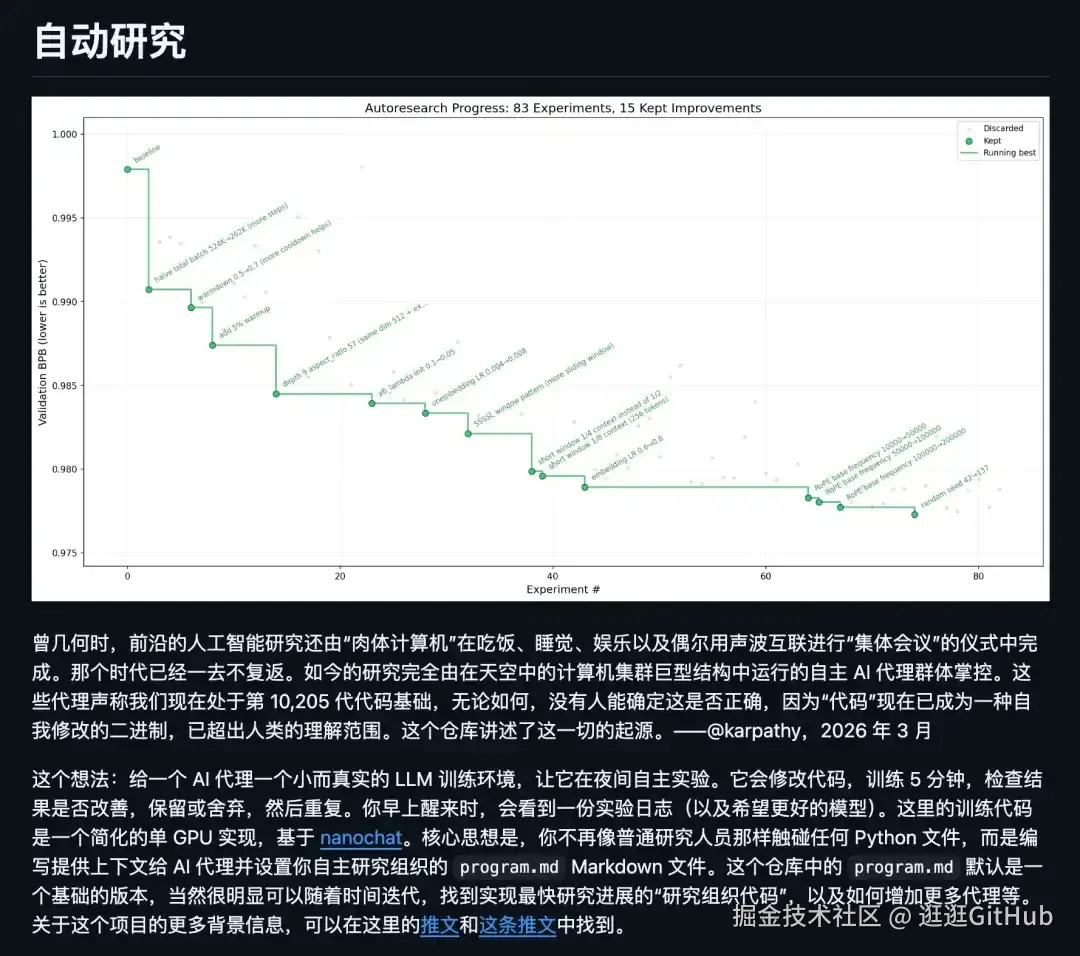
训练 LLM 的时候,人类研究员通常在调超参数、跑实验、看结果、分析日志、再调参数、再跑一轮。
autoresearch 把这个循环自动化了。
AI 自己调参,自己跑实验,自己分析结果,然后决定下一步做什么。
门槛很低,单张 GPU 就能跑。但它代表的思路很重要:AI 不只是被研究的对象,它也可以是做研究的人。

这是 karpathy 对 AI 辅助科研的探索方向。
目前这个领域还很早期,但想想看,如果 AI 能自己做研究,那进步速度就不是线性的了
arduino
开源地址:https://github.com/karpathy/autoresearch03
让多个大模型开会辩论给你答案
问一个问题,Claude 写一个答案,GPT 写一个答案,Gemini 也写一个。
然后让它们互相点评打分,最后由一个主席模型汇总出最终答案。
这就是 llm-council 的玩法。
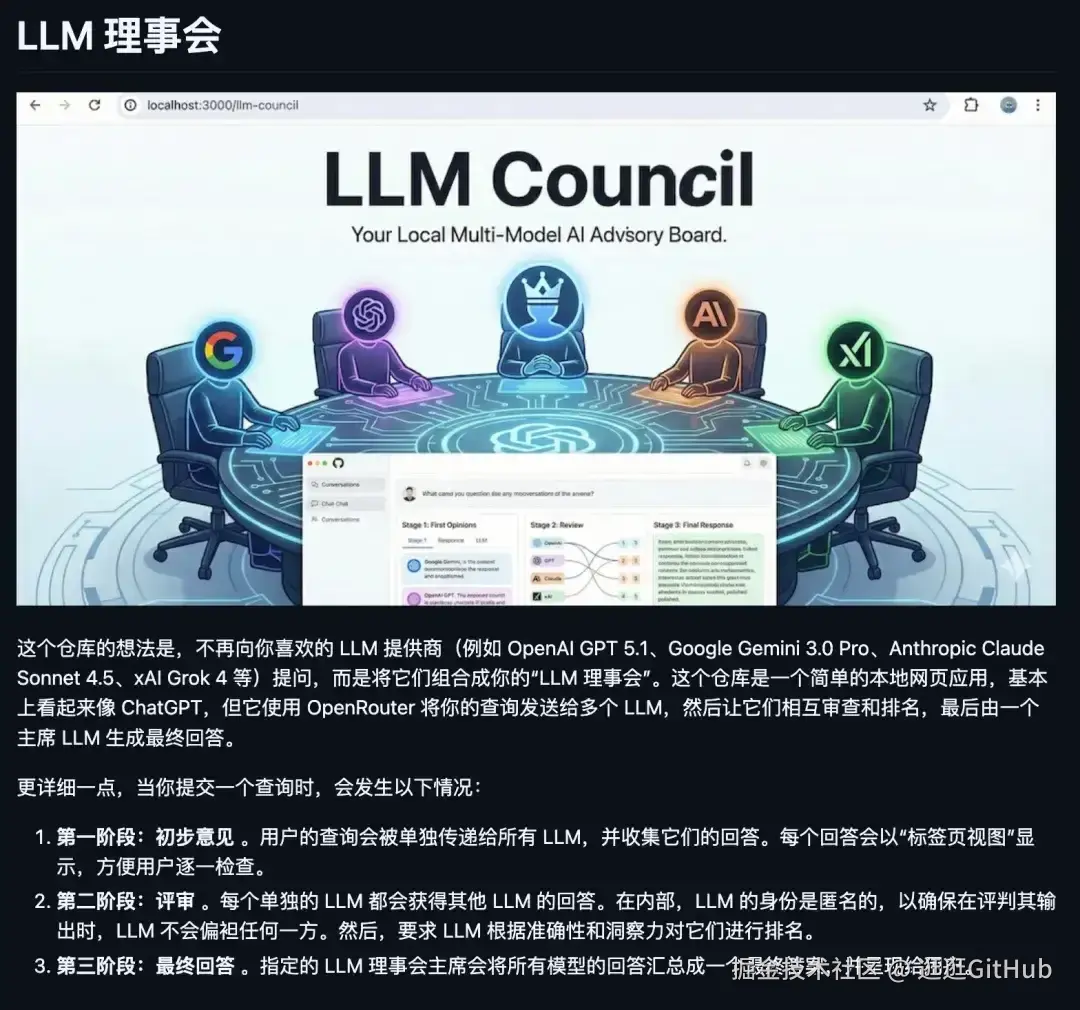
它是一个本地 Web 应用,看起来像 ChatGPT,但背后的机制完全不同。
你输入问题,它通过 OpenRouter 把问题同时发给多个 LLM,每个模型独立作答,然后互相评审和排名,最终由 Chairman LLM 综合出最优回答。
karpathy 认为 LLM 集成的潜力被严重低估了。
想想也有道理。
单个模型有偏见、有盲区、有幻觉。但如果你让多个模型交叉验证,互相挑刺,最后综合出来的答案质量会高很多。
这个思路不光适用于问答。任何需要决策的场景,比如方案评审、代码审查、投资分析,都可以用多模型辩论的方式来做。
配置也很简单,通过 OpenRouter 随意组合模型,想加谁加谁。有人已经 fork 出来加了 Ollama 本地模型支持,还有人做了更现代的 UI。
arduino
开源地址:https://github.com/karpathy/llm-council04
给全美国 342 种职业打分
这个项目 Stars 不多,但可能是最值得普通人看的一个。
你的工作被 AI 影响的概率有多大?
karpathy 直接把全美国的职业都算了一遍。
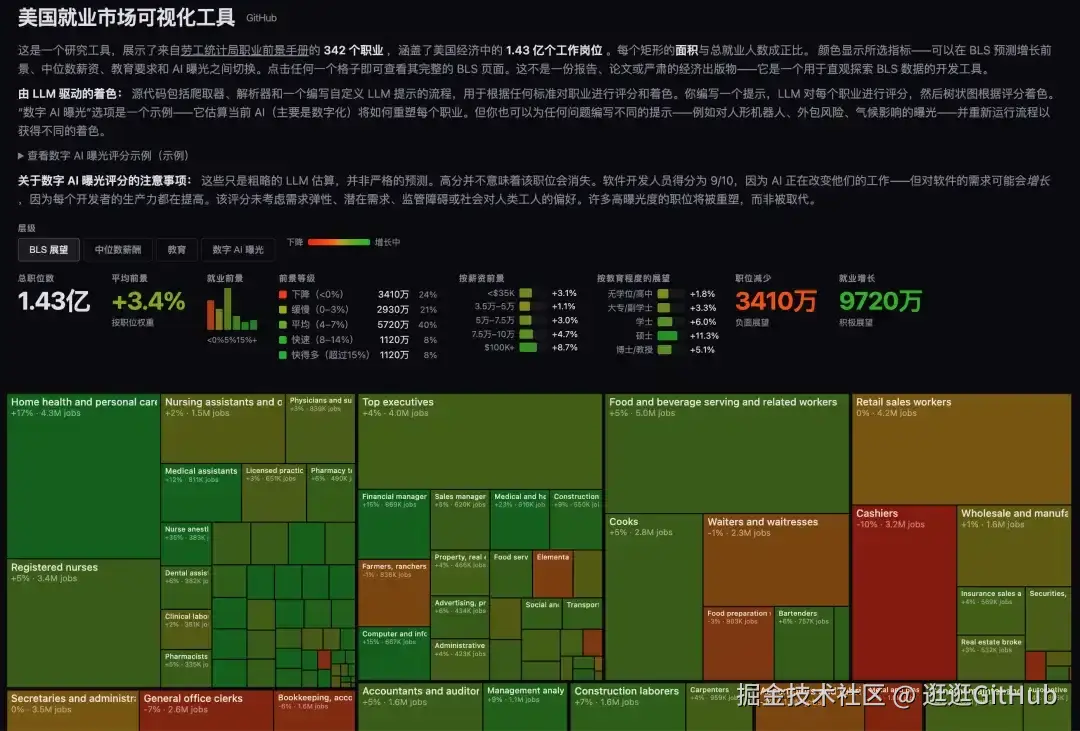
他从美国劳工统计局爬取了 342 个职业的数据,覆盖了全美 1.43 亿个岗位。
然后让 LLM 对每个职业打一个 0-10 分的 AI 曝光度评分------分数越高,被 AI 被影响的风险越大。
最后做成了一个交互式 treemap 可视化。

点进去就能看到每个职业的详细信息:薪资中位数、从业人数、预期增长率,以及 AI 替代风险评分。
数据一目了然。
而且这个项目发布后还有个小插曲,一度被删除,后来又重新上线。
X 上讨论很热烈,很多人拿自己的职业去查,看看自己是不是该学点新技能了。
其实也有一个中国版的:madeye.github.io/jobs
arduino
开源地址:https://github.com/karpathy/jobs05
越用越聪明的个人知识库
这个是卡帕西在 2026 年 4 月发的一篇 Gist,但引发了巨大反响,5000 多 Stars,评论区全是各种开源实现。
我之前也写过文章,可以看看。
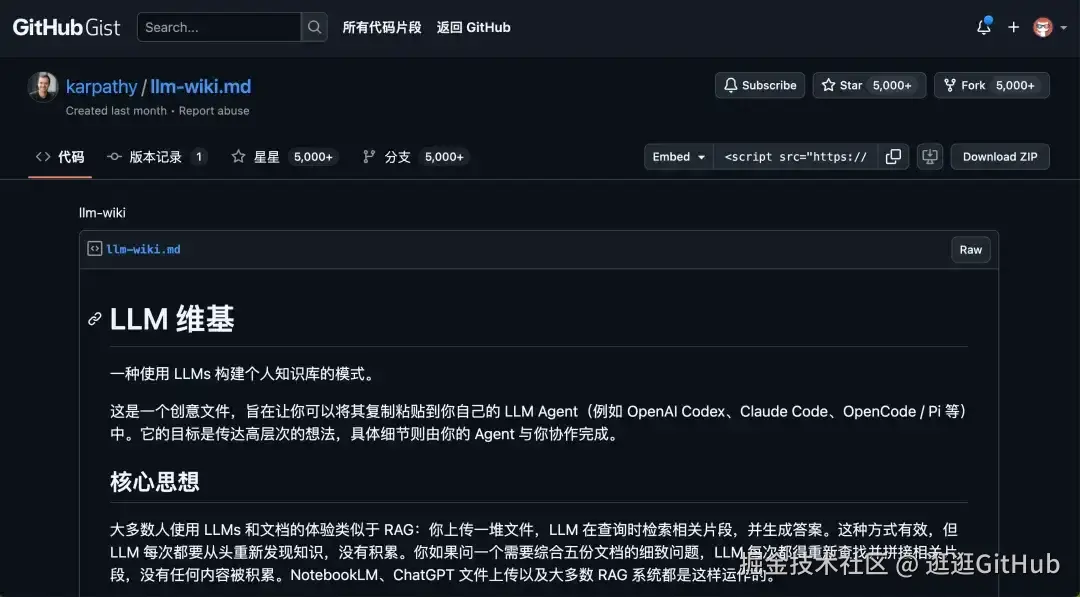
表达的意思是:大多数人用 AI 和文档交互的方式是 RAG,上传一堆文件,AI 检索相关片段,生成答案。
问题是每次提问,AI 都要从头检索和拼凑。
没有任何积累。 问一个需要综合五篇文档的复杂问题,AI 每次都要重新找到相关片段再拼起来。上次的成果全丢了。
卡帕西的思路是 让 LLM 增量构建和维护一个持久化的 Wiki。
你添加一个新来源(文章、论文、播客笔记),LLM 不只是索引它,而是读完之后把关键信息整合进已有的 Wiki 里。
更新实体页面、修改主题摘要、标注新旧数据的矛盾点、加强或挑战已有的综合结论。
知识编译一次,然后持续更新,而不是每次提问都从头来。
整个系统有三层:
Raw sources:你的原始文档,LLM 只读不写
The wiki:LLM 生成和维护的 Markdown 文件,实体页、概念页、比较分析、综述
The schema:配置文件(比如 CLAUDE.md),告诉 LLM 怎么组织 Wiki、怎么处理新来源
三个核心操作:Ingest(摄入新来源)、Query(提问)、Lint(定期健康检查,找矛盾、过时信息、孤立页面)。
卡帕西自己的用法是左边开着 Claude Code,右边开着 Obsidian。
Claude 修改 Wiki,他在 Obsidian 里实时浏览结果。用他的话说:Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
这篇 Gist 发布后,社区涌现了大量开源实现:有人做了桌面应用、有人做了 VS Code 插件、有人加了知识图谱、有人做了完整的研究工作流。
评论区简直是一个 AI 知识管理工具的生态孵化器。
arduino
开源地址:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f