Subagent 实现:把脏活交给独立上下文
摘要:有了任务规划,主 Agent 知道要做什么、做到哪一步。但复杂任务的执行细节仍然会污染主 history:网页正文、命令输出、文件搜索结果、报错日志都会被带进后续推理。Subagent 的价值,就是把这些局部探索放进独立上下文里完成,最后只把高密度总结回传主线。
标签:Agent、Subagent、上下文隔离、并发、Tool Use

计划清楚了,主上下文还是会变脏
任务规划解决的是"先做什么、后做什么"。但真正执行任务时,还有一个更隐蔽的问题:中间过程会大量进入主 history。
假设用户要求:
text
抓取三个网页,分别总结观点,最后比较差异。如果主 Agent 自己调用 web_fetch,每个网页几千字都可能进入主 history。再比如它要在项目里查十几个文件,grep 输出、文件正文、报错日志也会不断堆进去。对最终回答来说,这些细节大多只是中间材料;但对上下文来说,它们又长又吵。
于是主 Agent 会越来越慢,注意力也会被无关细节稀释。即使有记忆压缩,也不应该把本来可以隔离的脏活先塞进主线。
Subagent 要解决的正是这个问题:主线负责调度,细节放到独立上下文里执行。
Subagent 是一个特殊工具
在这个项目里,子代理不是和主 Agent 平级的"另一个人",而是主 Agent 可以调用的一个特殊工具:dispatch_subagent。
它的入口在 agent/tools/dispatch.py。从主 Agent 视角看,它和 run_command、read_file 一样,都是工具;不同之处在于,这个工具内部会启动一套独立的 AgentRunner。
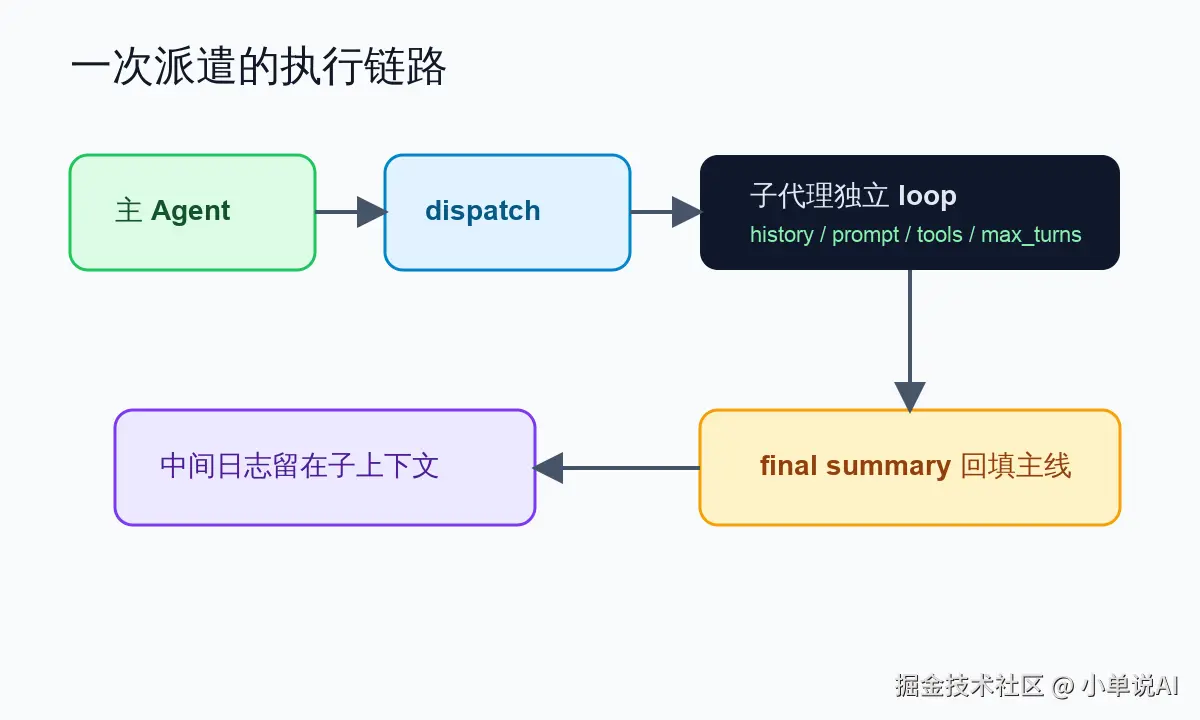
核心流程是:
text
主 Agent 发出 dispatch_subagent
↓
创建子代理独立 history
↓
子代理在自己的上下文里读文件、跑命令、抓网页
↓
子代理产出 final summary
↓
主 history 只收到一条 tool_result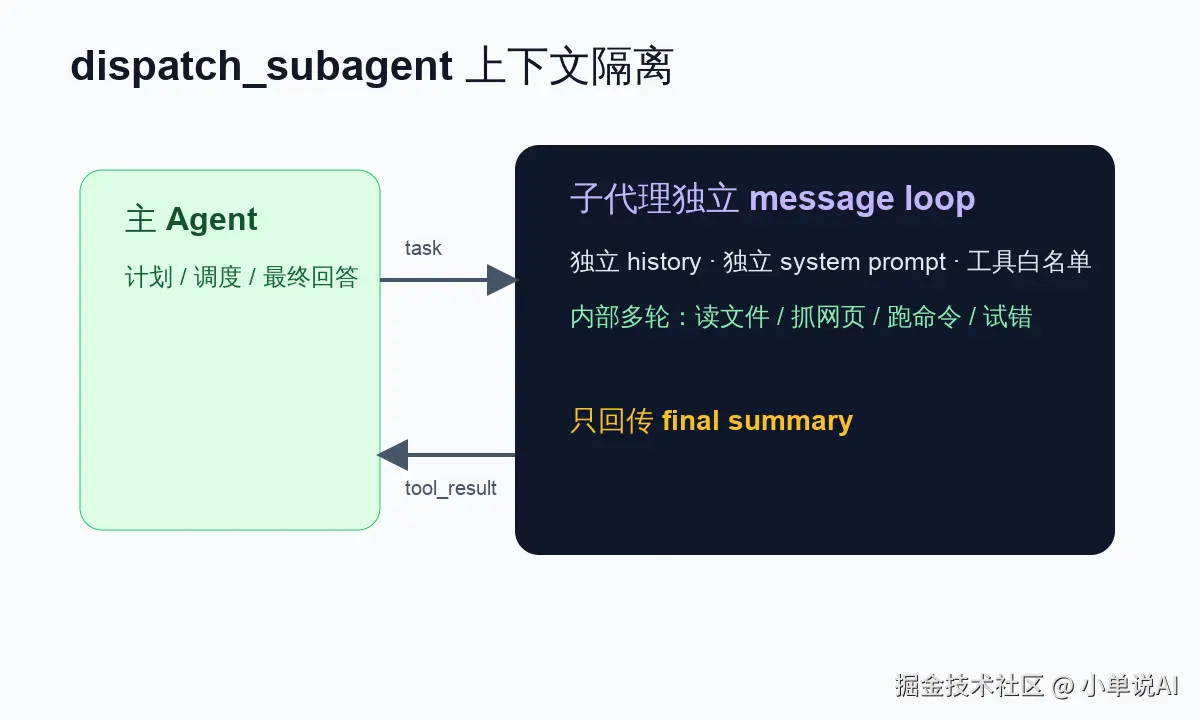
这就是 subagent 最朴素的价值:它不是为了让系统看起来有很多角色,而是为了隔离上下文。
dispatch_subagent 的参数
DispatchSubagentTool 的参数很少,但都很关键:
python
return tool_parameters_schema(
agent_type=StringSchema(
"子代理类型, 必须是 description 中列出的可用类型之一",
enum=self._subagent_registry.names(include_aliases=True),
),
task=StringSchema(
"交代给小太监的差事, 写清要做什么、希望返回什么格式的总结"
),
purpose=StringSchema(
"一句话用途标签, 仅用于终端打印",
nullable=True,
),
)agent_type 决定使用哪种子代理身份。task 是真正交给子代理的任务描述。purpose 只是日志标签,方便人类观察当前派遣出去的差事。
这里最容易被忽视的是 task。因为子代理有独立上下文,它不应该依赖主 Agent 脑内的隐含信息。一个好的 task 应该写清楚:
text
目标:要完成什么
范围:看哪些文件、网页或目录
输出:希望回传什么格式
边界:只读还是可写,是否允许运行命令例如:
text
阅读 agent/tools/dispatch.py 和 agent/subagents/registry.py,
总结子代理工具白名单如何生效,
回传三条关键结论,不要修改文件。这比"看看 subagent 怎么实现的"稳定得多。
独立 runner 和工具白名单
工具执行时,dispatch_subagent 会根据 agent_type 找到对应 spec,再为子代理组装一个新的 ToolRegistry:
python
sub_registry = ToolRegistry()
for tool_name in spec.tool_names:
tool = self._parent_registry.get(tool_name)
if tool is not None:
sub_registry.register(tool)然后创建独立 runner:
python
runner = self._runner_factory(spec=spec, sub_registry=sub_registry)
history = [{"role": "user", "content": task}]
final = runner.step(history)这几行代码把子代理边界讲得很清楚:
- 它有自己的 history;
- 它有自己的 system prompt;
- 它有自己的工具白名单;
- 它有自己的最大回合数;
- 它最终只返回一段文本给主线。
身份模板和权限分开
子代理身份定义在 templates/subagents/*.md 和 agent/subagents/registry.py。
项目里内置了几类身份:
text
xiaohuangmen 轻量只读,适合短命令和快速确认
sili_suitang 只读文书,适合阅读代码和整理提纲
dongchang_tanshi 查访资料,适合网页抓取和探索搜索
shangbao_dianbu 盘点核验,适合清单校对和遗漏检查
neiguan_yingzao 可读写可执行,适合真正动手改文件这里的角色名带有教学项目的人设风格,但工程点很严肃:不同身份绑定不同工具白名单。
比如只读文书型子代理可以使用:
python
("load_skill", "read_file", "glob", "grep")营造型子代理则可以写文件和执行命令:
python
("run_command", "web_fetch", "load_skill",
"read_file", "write_file", "edit_file", "glob", "grep")身份模板写职责和口吻,工具白名单写权限。安全边界放在代码里,而不是让 prompt 自己保证。这一点很重要。
还要注意,子代理白名单里不包含 dispatch_subagent 和 update_todos。前者防止无限递归派遣,后者避免子代理污染主 Agent 的任务计划。
并发派遣怎么发生
dispatch_subagent 标记为并发安全,因为每次派遣都有独立 history、独立 registry 和独立 runner。
主项目的 AgentRunner 会检查同一轮模型返回的 tool blocks。如果连续多个工具都 concurrency_safe,就用线程池并行执行,再按原顺序回填结果。
这意味着,如果模型在同一轮里发出三个 dispatch_subagent:
text
派 A 读文件一
派 B 读文件二
派 C 读文件三运行时可以并发等待它们完成。
但并发触发权在模型路由手里。你说"统计三个文件行数",模型可能直接调用一条 wc -l,因为那更高效。想稳定演示并发,就要明确说"分别派三个子代理,各自处理一个文件,再汇总结果"。
Subagent 适合什么场景
Subagent 最适合三类任务。
第一类是信息量很大的只读探索。比如读多个文件、抓网页、搜索项目结构。主线不需要看到所有原始输出,只需要最终结论。
第二类是边界清楚的局部任务。比如"检查这两个模块是否都注册了工具""整理这几个文档的差异"。只要 task 写清楚,子代理可以独立完成。
第三类是可以并发的分支任务。比如分别检查三个目录,分别总结三个网页,最后让主 Agent 汇总。
它不适合长期协作。子代理办完就销毁,没有持续 inbox,也没有固定状态。如果你需要一个 coder 和 reviewer 来回交接,那就不是一次性子代理能很好解决的场景。
如何观察一次派遣是否成功
验证 subagent,不要只看最终回答。你还应该看日志里是否出现三个信号。
第一,主线打印了派遣日志,能看到 agent_type 和 purpose。
第二,子上下文里出现了自己的工具调用日志,比如读取文件、网页抓取或命令执行。
第三,主线只收到最终回禀,而不是所有中间输出。项目里会打印"子代理仅向主 history 追加 N 字"这一类提示。
如果看不到这些信号,说明模型可能选择了普通工具路径。这不一定错,可能只是普通工具更直接。Subagent 是一种执行策略,不是每个任务都必须使用。
为什么子代理不能再派子代理
从能力上看,让子代理继续派子代理似乎很诱人。这样可以形成更深的分工树:主 Agent 派研究员,研究员再派抓网页的人,抓网页的人再派整理者。听起来很强,但教学项目里故意不这样做。
原因很简单:递归调度会迅速增加不可控性。你很难知道到底启动了多少上下文、每个上下文花了多少 token、哪个层级应该负责最终结论。如果某个子代理又派出多个子代理,错误和成本也会被放大。
所以白名单里明确不包含 dispatch_subagent。子代理只办自己这件差事,办完回禀主线。这个限制让系统结构更清楚:
text
主 Agent:计划、调度、最终回答
子代理:局部探索、整理结论等这个单层模型稳定后,再讨论更复杂的层级调度才有意义。
白名单比 prompt 承诺更可靠
你当然可以在子代理 prompt 里写"不要修改文件""不要派其他代理"。但 prompt 是软约束,工具白名单才是硬边界。
如果一个只读子代理根本没有 write_file 工具,它就无法写文件;如果它没有 dispatch_subagent 工具,它就无法递归派遣。模型就算想做,也没有接口。
这也是 Agent 安全设计里很重要的一点:不要只靠模型自律。能用代码约束的地方,就用代码约束。prompt 负责表达职责和策略,工具系统负责执行边界。
自己动手验证
可以设计一个适合 subagent 的任务:
text
分别阅读三个文档,提炼每个文档的核心观点,
最后只回传一个对比表,不要把原文全文带回主线。如果模型选择了 dispatch_subagent,你应该能看到子上下文里发生文件读取或搜索,而主 Agent 最后只得到总结。
再设计一个不适合 subagent 的任务:
text
查看当前目录文件数量。这类任务用普通命令更直接。如果模型没有派子代理,也很正常。好的 Agent 不是每次都派人,而是根据任务成本选择合适路径。
子代理返回什么最有价值
子代理不应该把所有中间过程原样倒回主线。那样只是把污染换了一个入口,主 history 仍然会被撑爆。
更有价值的回禀通常包含四类信息:
text
结论:子任务最终发现了什么
证据:哪些文件、命令或结果支撑结论
不确定性:哪些地方没查到或仍需主线判断
建议动作:主 Agent 下一步应该怎么做这类总结比长日志更适合回到主上下文。主 Agent 不需要知道子代理每次 rg 搜了什么、每个文件读了多少行;它需要知道哪些事实已经被验证、哪些风险还没关闭。
串行和并行的取舍
Subagent 很容易让人想到并发:既然每个子代理上下文独立,那就同时派出去做事。并发确实有用,尤其适合彼此无依赖的局部任务。
但并发不是默认更好。三个子代理同时探索三个方向,会带来三份模型调用、三份工具日志、三份总结。任务如果本来很小,调度成本可能比收益更高。
可以用一个简单标准判断:如果子任务之间没有依赖,且每个子任务都需要独立阅读或探索,就适合并行;如果后一个动作依赖前一个结果,就应该串行。
比如"分别总结三个模块职责"适合并发;"先复现 bug,再根据报错定位模块"更适合串行。好的调度不是尽量多派,而是让上下文隔离和成本匹配任务形状。
子代理任务要写成独立工单
因为子代理看不到主 Agent 的全部心智状态,所以 task 不能写得像一句随口交代。它应该像一张独立工单:背景、目标、范围、输出格式都清楚。
一个不好的 task 是:
text
帮我看看这个问题。一个更好的 task 是:
text
阅读 agent/tools/dispatch.py 和 agent/subagents/registry.py,
说明子代理白名单如何限制工具集合。
请给出结论、关键文件路径、仍不确定的地方。写得越清楚,子代理越少猜;子代理越少猜,主 Agent 收到的总结越稳定。
小结
Subagent 的核心价值,是把局部执行细节放进独立上下文。
主 Agent 负责目标、计划和最终回答;子代理负责局部探索、试错和整理;主 history 只接收高密度回禀。这样既减少上下文污染,也让不同任务可以按权限白名单被隔离执行。
当任务只是"一次性查清楚并回报",subagent 很合适。但有些任务不是办完就散,而是需要固定角色多轮交接。接下来就要考虑更持久的协作形态。
视频与源码
如果你想看完整演示,可以在主页的《从零手搓 Agent》合集里按顺序观看视频版:
文章里的示例代码和完整项目也放在这里:
- 📦 教学仓库:github.com/TheSyart/cl...
- ⚔️ 实战项目:github.com/TheSyart/em...
我会持续更新 Agent 教学与实战内容。觉得有用的话,欢迎给项目点个 Star ⭐,也谢谢你一路看到这里。