前言
在现代 web scraping 场景中,获取海外社交媒体的 web data 通常需要强大的 proxy service、IP rotation 和 anti-bot 技术支持。基于上次分享的 Bright Data MCP + Dify 电商数据采集工作流的成功经验,我对其进行了升级优化,打造了一个专门针对社交媒体平台的数据采集工作流,以下是完整的教程分享。
为什么多平台采集这么难?
作为营销与社媒分析人员,需要同时监控 海外社交媒体 上的红人动态和趋势数据。但每个平台都有自己的"护城河":
|----------|-----------|--------|
| 平台 | 主要反爬机制 | DIY失败率 |
| Tik | 签名加密、设备指纹 | 极高 |
| LinkedIn | 登录墙、行为检测 | 极高 |
每加一个平台就意味着多一套维护成本,更别提还要处理数据格式混乱的问题。所以还是用 Bright Data MCP + Dify 的组合方案。
架构 介绍:Bright Data MCP + Dify
Bright Data MCP + Dify 是一个用于构建 AI 驱动数据采集工作流的架构,它允许 AI agent 直接访问企业级 Web scraping 基础设施。
架构流程:
用户输入(TikLinkedIn URL) → Dify Workflow → Bright Data MCP Server → Tik & LinkedIn → 结构化 JSON 输出 → Slack 报表
这个组合之所以有效,是因为:
- Dify 提供可视化 Workflow,不用写爬虫逻辑
- Bright Data MCP 处理所有平台的解封、代理、指纹
- 两者结合 = AI 驱动的数据采集流水线
前置准备
你需要准备:
- Bright Data 账号(免费试用$20额度)
- Dify 账号(云端或本地部署均可)
- Bright Data MCP Server API Token
- 基本的 Dify Workflow 操作经验
实战教程:手把手操作
Step 1:配置 Bright Data MCP Server
这比我预期的要简单得多,只花了我大约10分钟。
详细步骤:
- 注册 Bright Data 账号
- 访问 Bright Data 官网
- 使用邮箱注册,完成身份验证
- 注册成功后添加促销码会获得 $20 免费试用额度
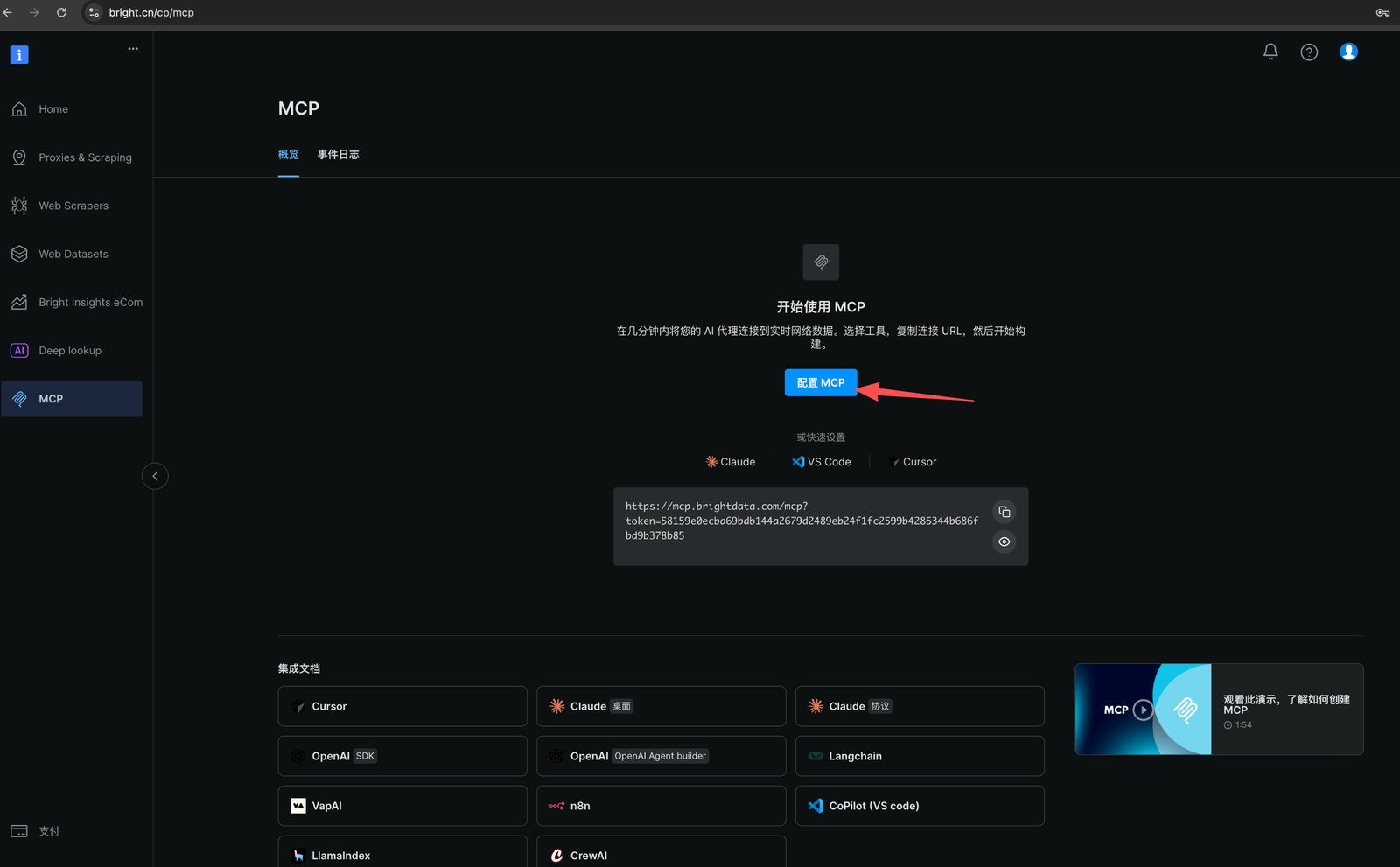
- 配置 MCP Server
登录 Bright Data 控制台,进入 MCP 配置页面。
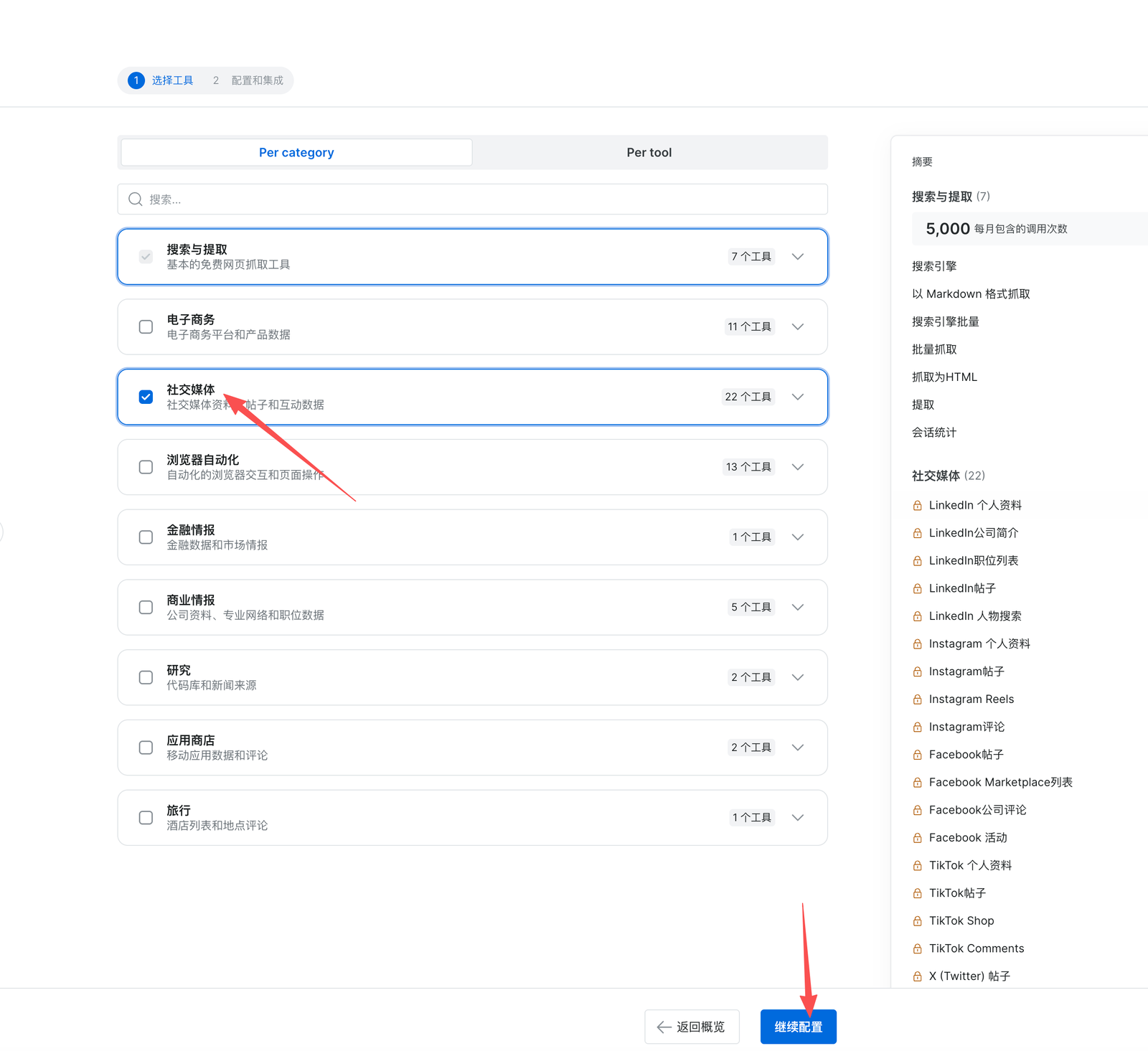
选择社交媒体,点继续配置
复制链接,我打码的部分是token,如果这里没有自动填充,可以去个人账户设置那里复制填充进来。
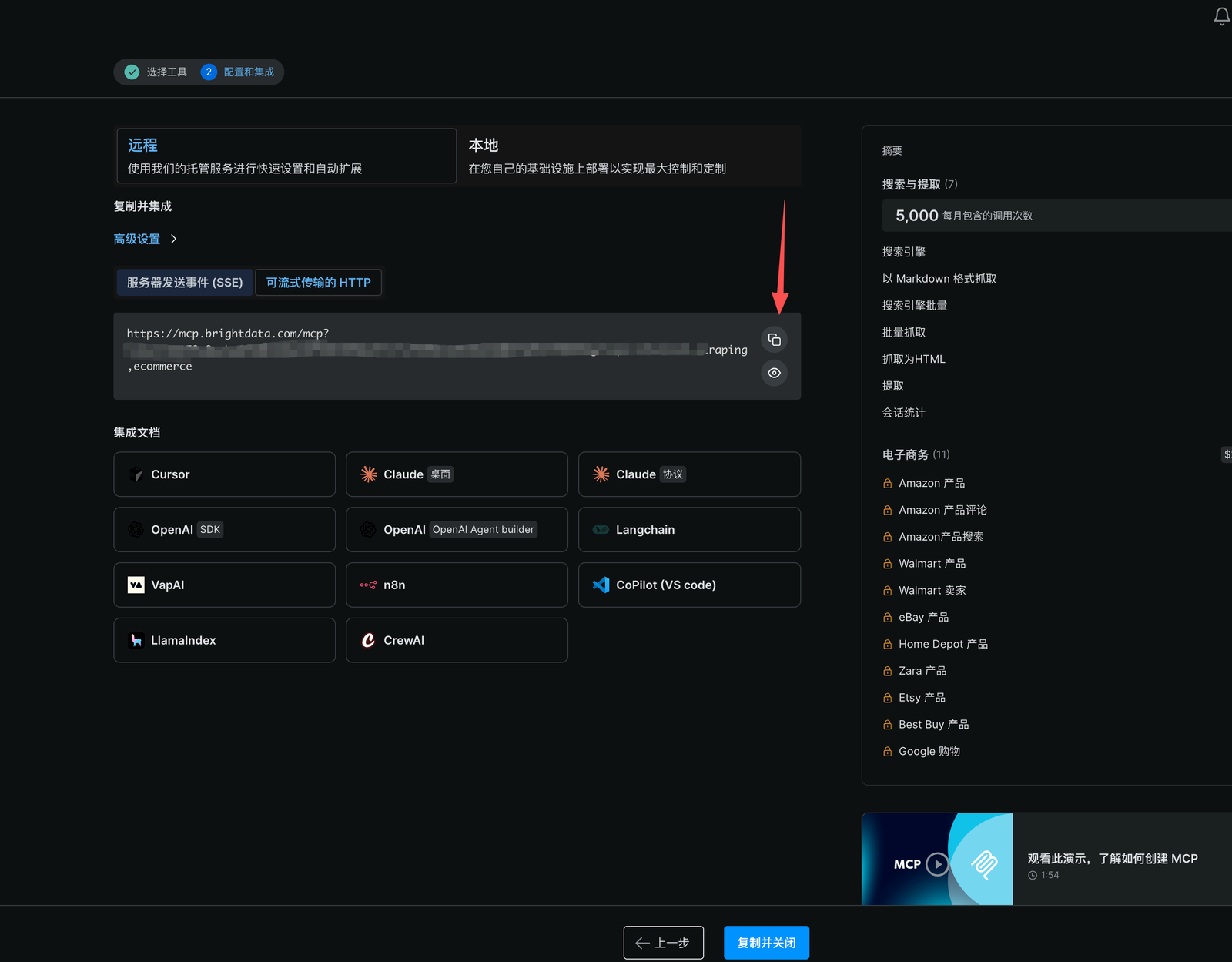
Step 2:在 Dify 中添加 Bright Data MCP 工具
进入 Dify 的「工具」页面,选择「添加外部 MCP 工具」,然后粘贴你在上一步获得的链接。
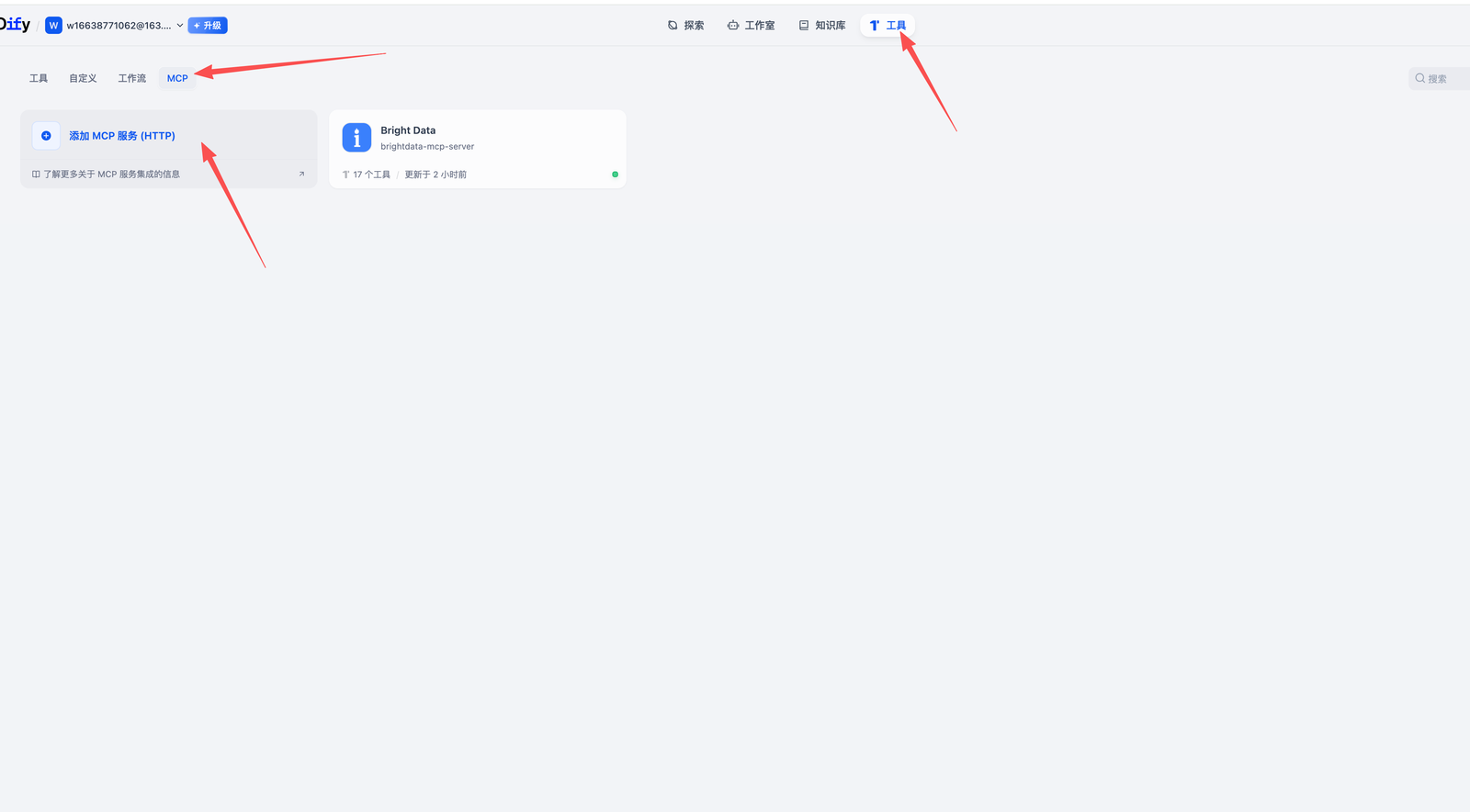
粘贴URL,名称和服务器标识直接用我这个就行,自己取一个也行。然后点击添加
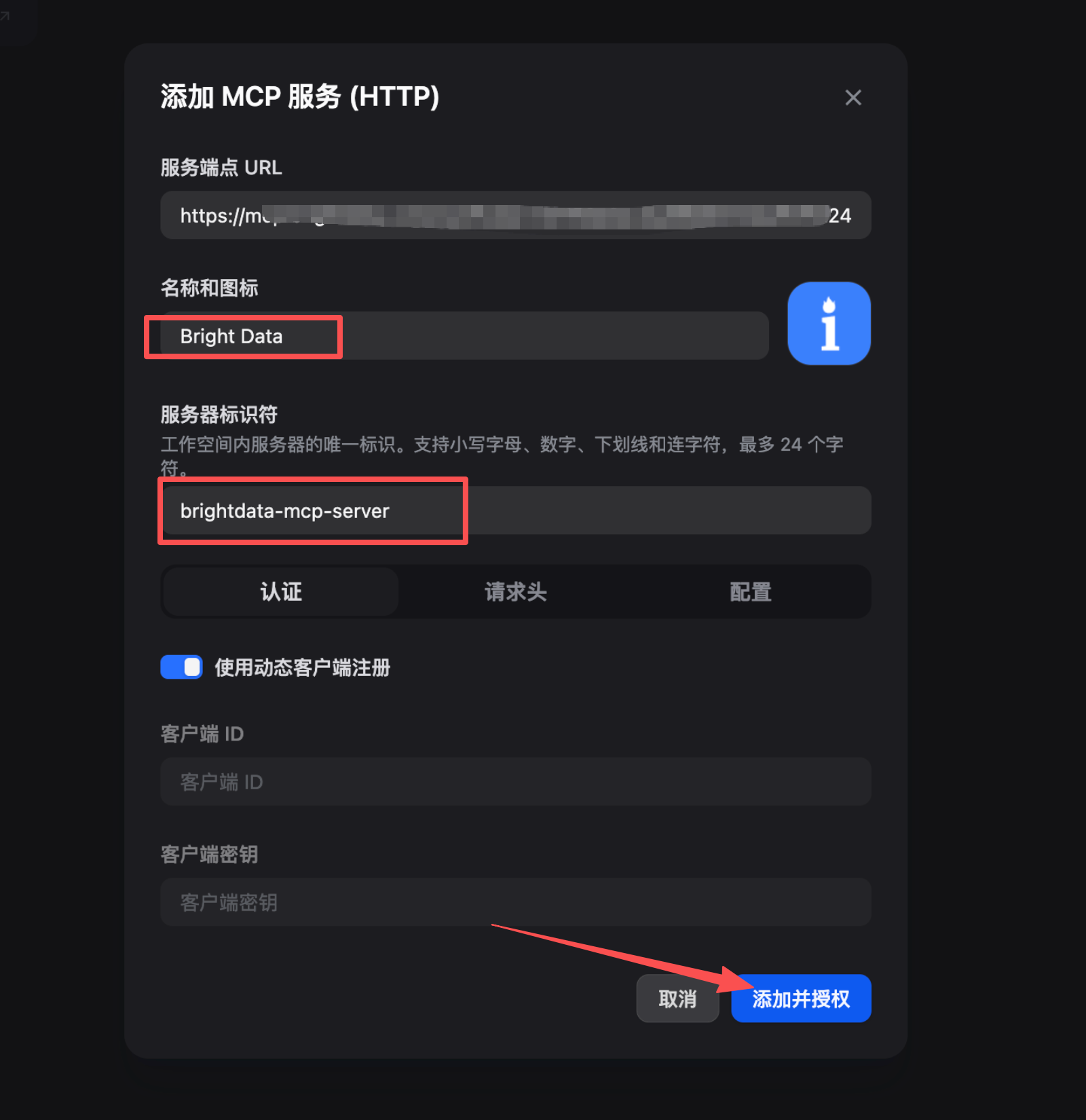
Step 3:创建多平台采集 Workflow
基于我完整的媒体数据采集.yml工作流,这里演示 TikTok + LinkedIn 社媒数据采集场景:
输入节点:账号URL(支持批量,以逗号分隔)
MCP工具节点:
web_data_tiktok_profiles:调用 TikTok 数据采集web_data_linkedin_posts:调用 LinkedIn 数据采集
LLM节点:
- TikTok:提取互动率、粉丝数、内容摘要(娱乐化语气)
- LinkedIn:提取专业领域、核心观点、价值主张(专业化语气)
输出节点:推送至 Slack
工作流还包含智能分类器,能自动识别输入的是 TikTok 还是 LinkedIn URL,并路由到相应的处理分支。
详细步骤:
创建新 Workflow
- 在 Dify 中点击 创建空白应用
- 输入名称和图标
- 选择工作流
(1) 配置输入节点
- 添加 Start 节点
- 默认已存在
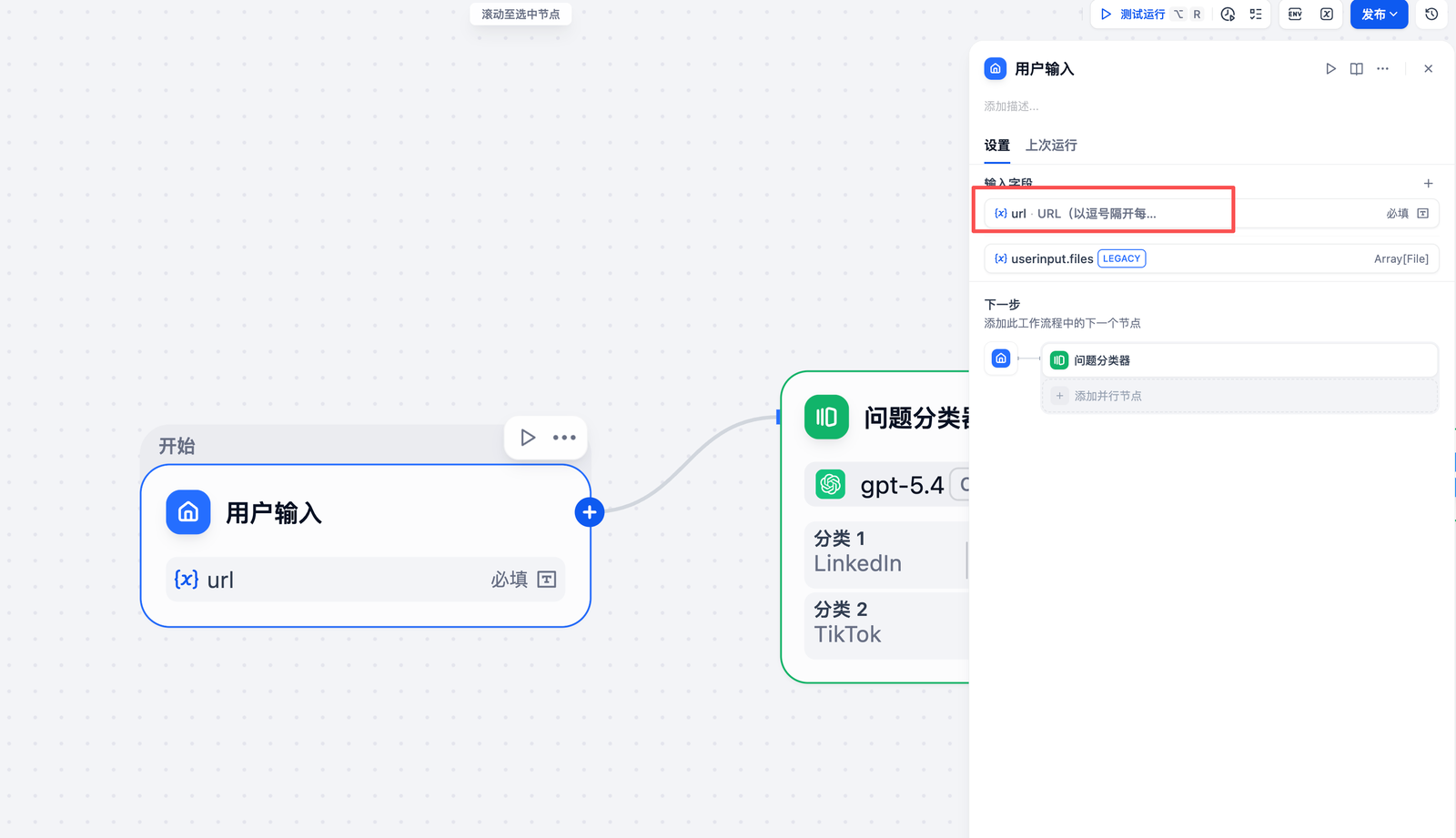
- 配置输入参数:
- Parameter Name:
social_urls - Type:
String - Required:
Yes - Description:
TikTok 或 LinkedIn 账号URL,多个URL用逗号分隔
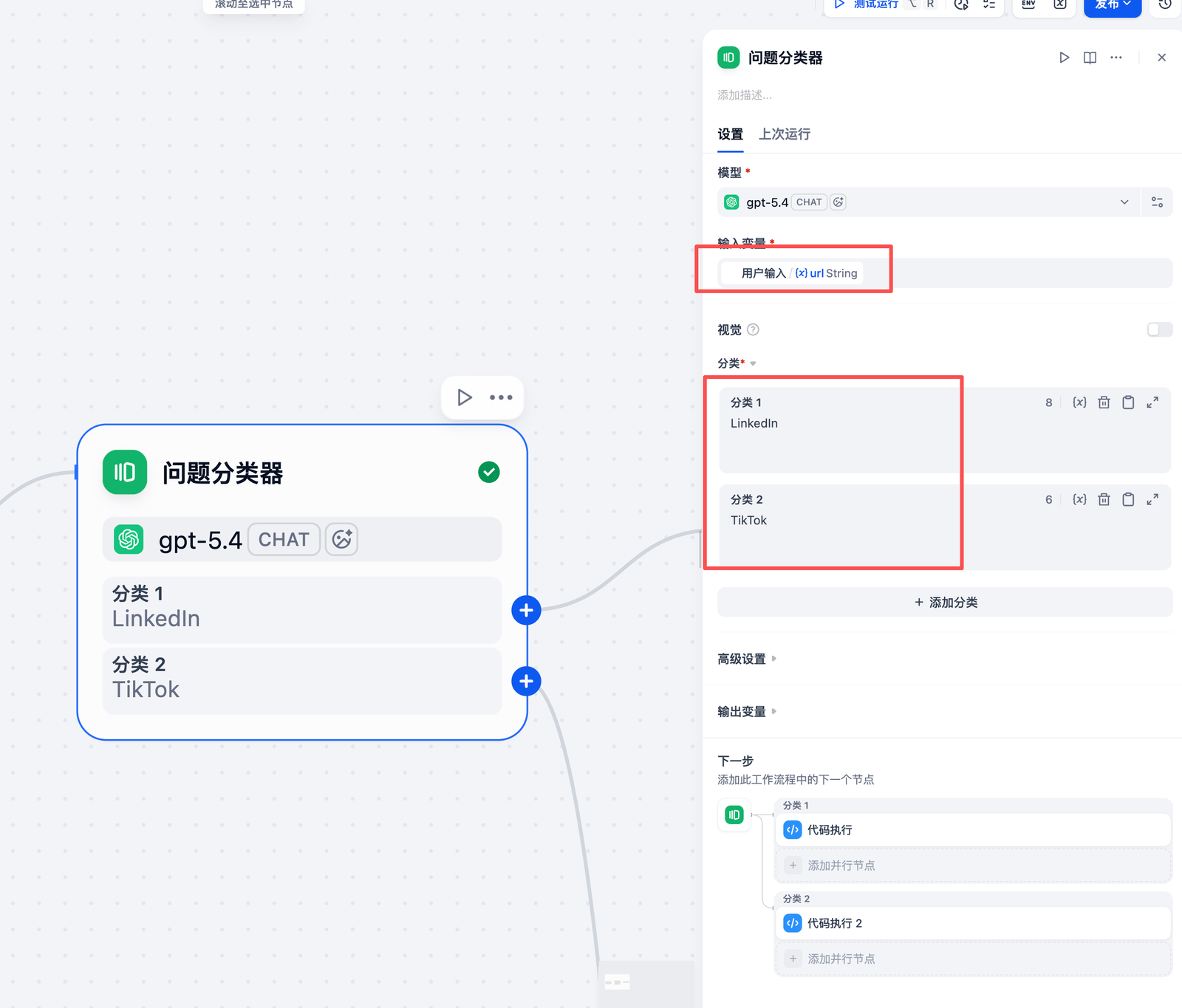
(2) 配置条件分支
- 添加条件节点
- 拖拽 "问题分类器" 节点到画布
- 连接 用户输入节点到 问题分类器节点
- 配置分类:
- 输入变量: 用户输入变量
- 分类1: TikTok 处理分支
- 分类2 LinkedIn 处理分支
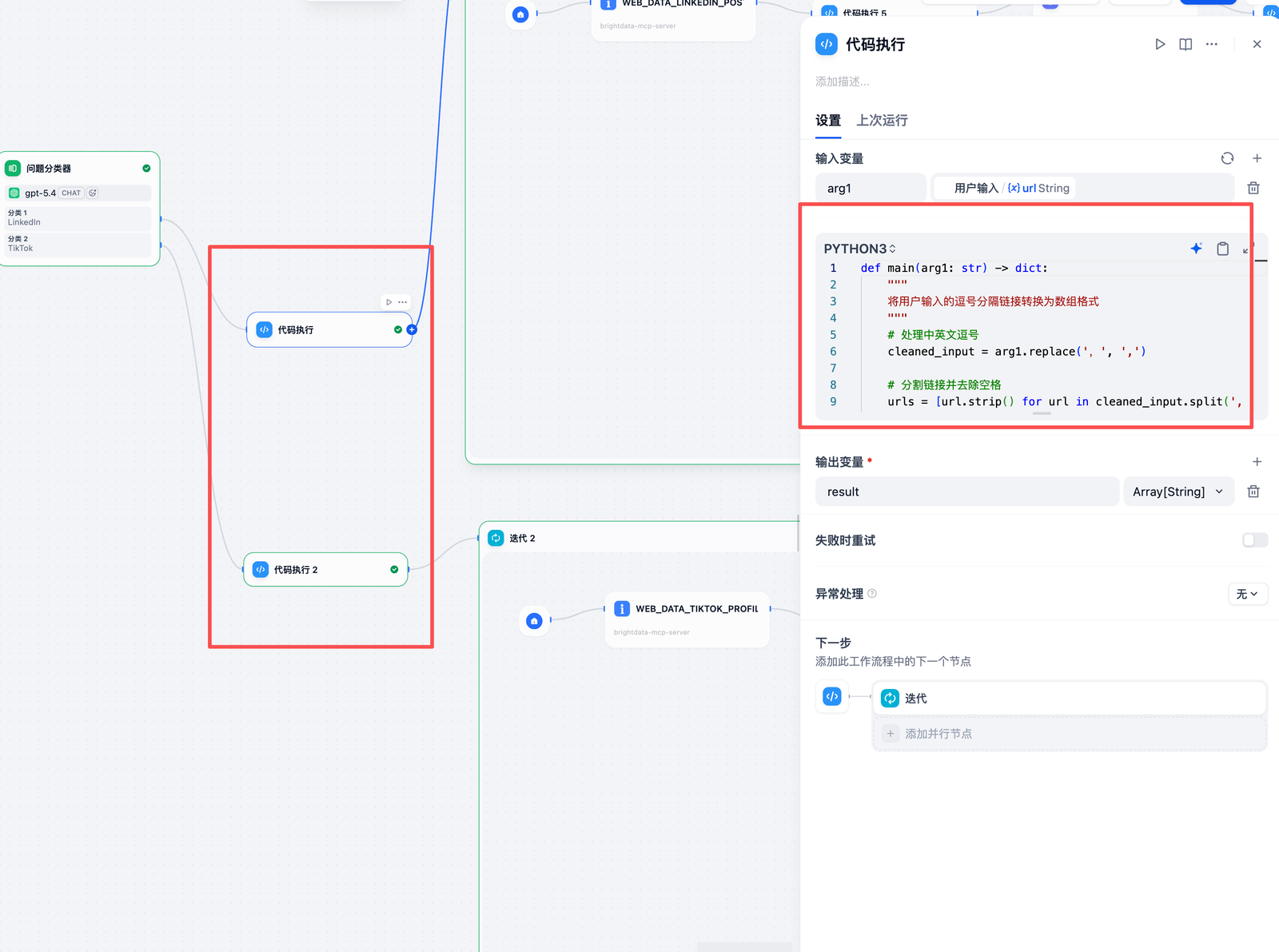
(3) URL 预处理
- 节点类型:Code(代码执行)
- 功能:将用户输入的逗号分隔 URL 转换为数组格式。
cobol
*
def main(arg
1: str) -
> dict:
*
cleaned_
input
= arg
1.
replace(
',',
',')
*
urls
= [url.strip()
for url
in cleaned_
input.split(
',')]
*
urls
= [url
for url
in urls
if url]
*
return {
"result": urls}
AI写代码
(4) 平台数据
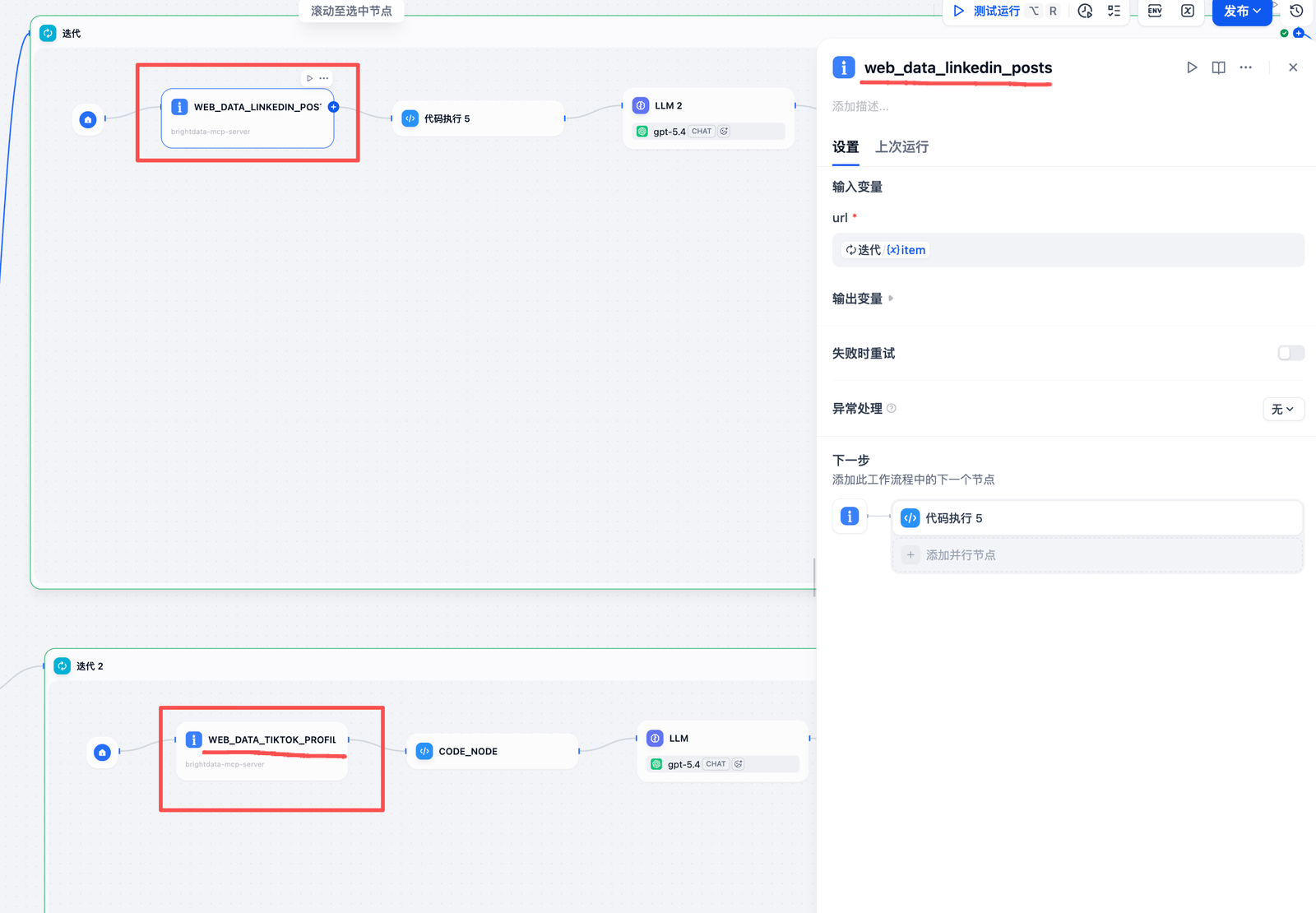
注意,虽然都是亮数据MCP但是选择的工具是不一样的
(5) 数据预处理
-
LinkedIn 流程:
- 工具:
web_data_linkedin_posts(Bright Data 提供) - 输入:单个 LinkedIn URL
- 输出:帖子数据(作者、粉丝数、点赞数、评论数、帖子文本等)
- 工具:
-
TikTok 流程:
- 工具:
web_data_tiktok_profiles(Bright Data 提供) - 输入:单个 TikTok 个人主页 URL
- 输出:账号数据(昵称、粉丝数、互动率、热门帖子描述等)
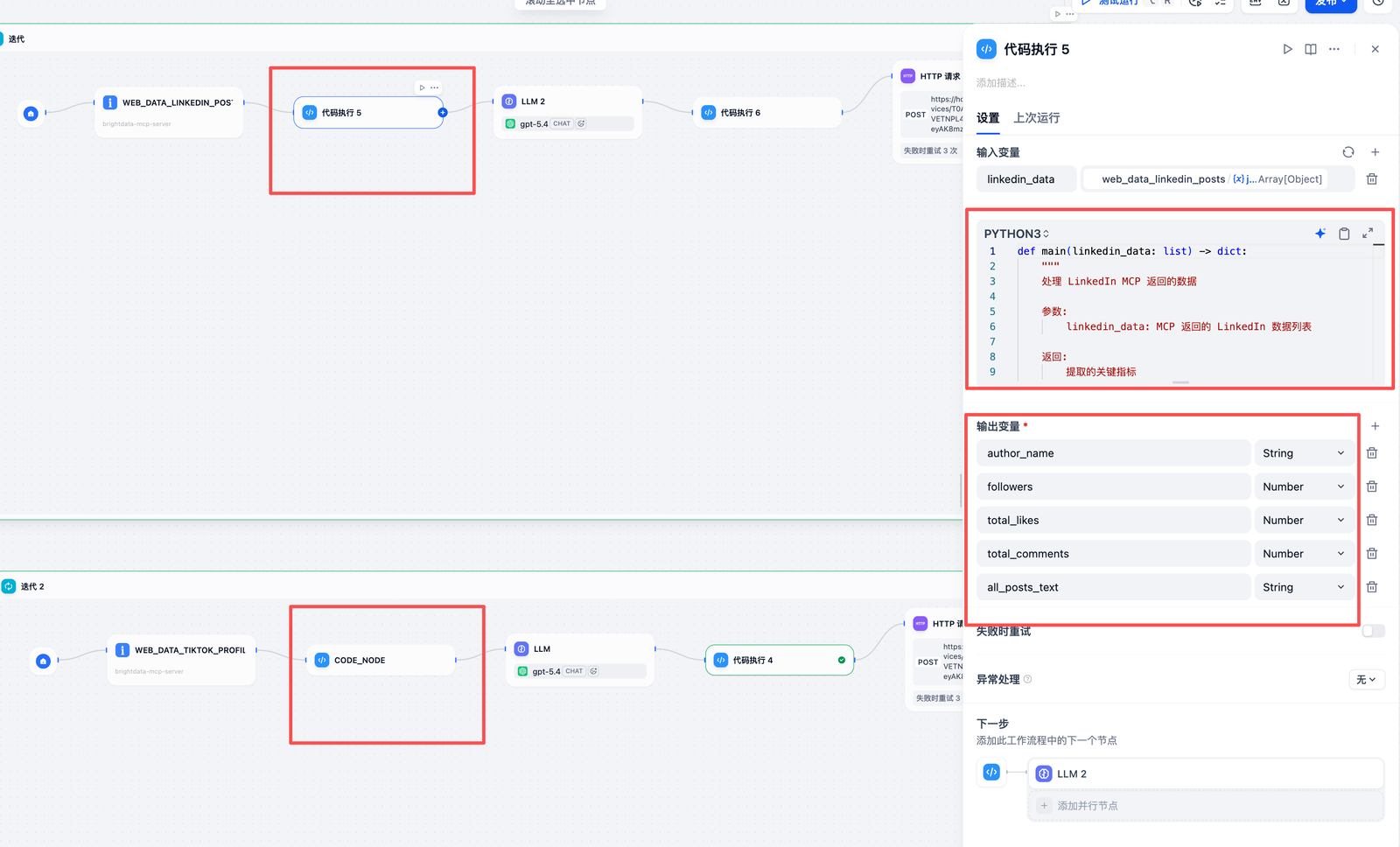
cobol* def main(linkedin_ data: list) - > dict: * "" " * 处理 LinkedIn MCP 返回的数据 * * 参数: * linkedin_data: MCP 返回的 LinkedIn 数据列表 * * 返回: * 提取的关键指标 * " "" * if not linkedin_ data or len(linkedin_ data) = = 0: * return { * "author_name": "Unknown", * "followers": 0, * "total_likes": 0, * "total_comments": 0, * "all_posts_text": "" * } * * # 获取第一个帖子的作者信息(假设所有帖子来自同一作者) * first_post = linkedin_ data[ 0] * author_name = first_post. get( "user_title", "Unknown").split( "•")[ 0].strip() * followers = first_post. get( "user_followers", 0) * * # 计算总互动数据 * total_likes = sum(post. get( "num_likes", 0) for post in linkedin_ data) * total_comments = sum(post. get( "num_comments", 0) for post in linkedin_ data) * * # 合并所有帖子文本 * all_posts_text = "\n---\n".join( * post. get( "post_text", "") for post in linkedin_ data * ) * * return { * "author_name": author_name, * "followers": followers, * "total_likes": total_likes, * "total_comments": total_comments, * "all_posts_text": all_posts_text * } AI写代码 - LinkedIn:
- 提取作者名、粉丝数、总点赞/评论数,并合并所有帖子文本。
- 代码如下:
- 工具:
cobol
*
def main(scraper_
data: list) -
> dict:
*
""
"
*
处理 MCP 节点输出的 TikTok 账号数据
*
*
参数:
*
scraper_data: MCP 节点返回的账号数据列表
*
*
返回:
*
包含预处理数据的字典
*
"
""
*
try:
*
# 验证输入数据
*
if
not isinstance(scraper_
data, list)
or len(scraper_
data)
=
=
0:
*
return {
*
"error":
"输入数据格式不正确或为空",
*
"input_type": str(
type(scraper_
data))
*
}
*
*
# 获取第一个账号数据
*
account_
data
= scraper_
data[
0]
*
*
# 提取关键字段
*
nickname
= account_
data.
get(
"nickname",
"")
*
followers
= account_
data.
get(
"followers",
0)
*
engagement_rate
= account_
data.
get(
"awg_engagement_rate",
0.0)
*
*
# 合并所有帖子描述
*
descriptions
= []
*
top_posts
= account_
data.
get(
"top_posts_data", [])
*
*
for post
in
top_posts:
*
description
= post.
get(
"description",
"")
*
if description:
*
descriptions.append(description)
*
*
all_descriptions
=
"\n---\n".join(descriptions)
*
*
# 返回结果(键名必须与输出变量名匹配)
*
return {
*
"nickname": nickname,
*
"followers": followers,
*
"engagement_rate": engagement_rate,
*
"all_descriptions":
all_descriptions
*
}
*
*
except
Exception
as e:
*
return {
*
"error": str(e),
*
"input_sample": str(scraper_
data)[:
200]
*
}
AI写代码

(6) LLM 内容分析
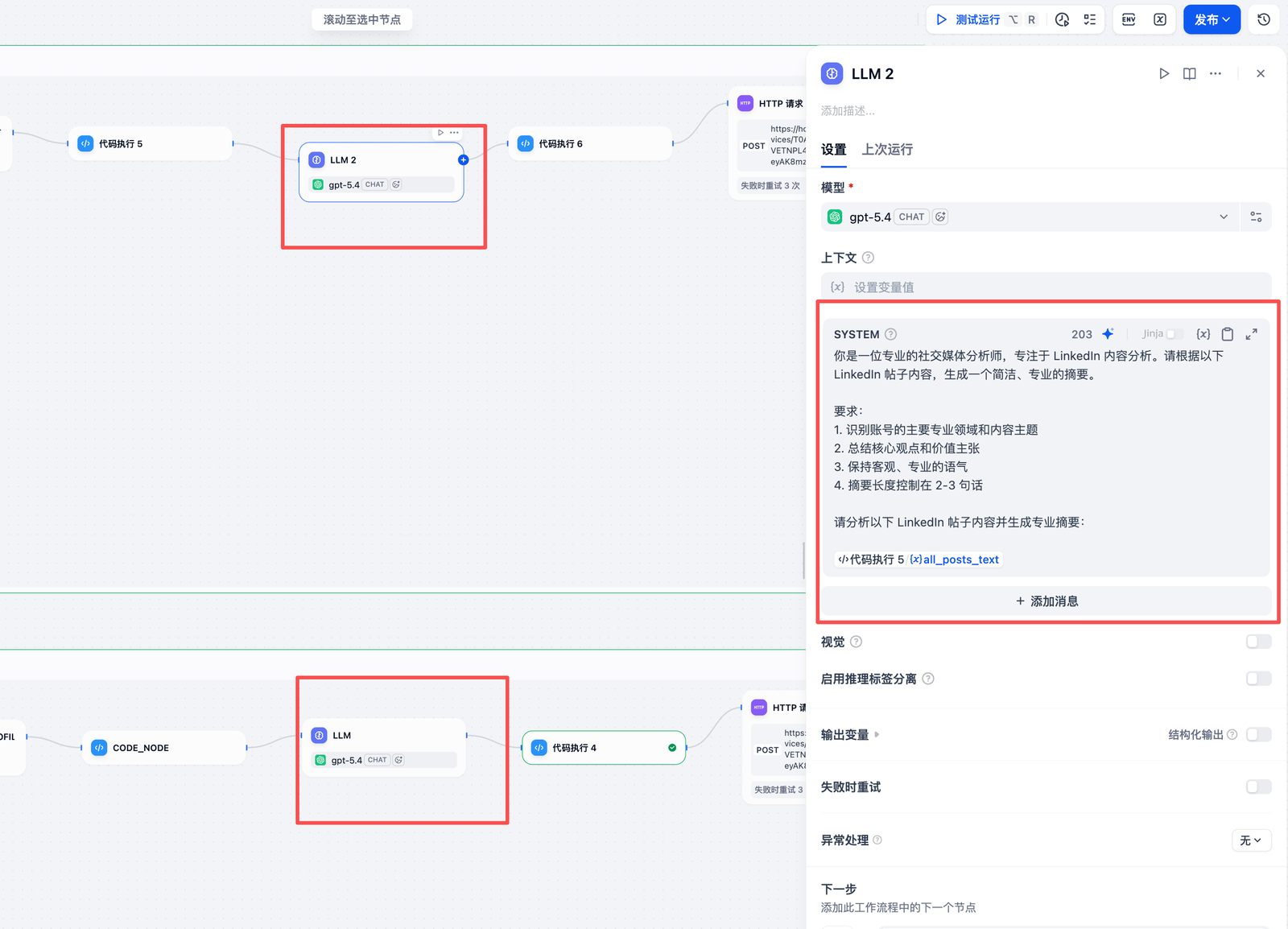
-
TikTok:
- 提取昵称、粉丝数、互动率,并合并所有帖子描述。
- 代码如下:
cobol* 你是一位专业的社交媒体分析师,专注于 LinkedIn 内容分析。请根据以下 LinkedIn 帖子内容,生成一个简洁、专业的摘要。 * * 要求: * 1. 识别账号的主要专业领域和内容主题 * 2. 总结核心观点和价值主张 * 3. 保持客观、专业的语气 * 4. 摘要长度控制在 2- 3 句话 * * 请分析以下 LinkedIn 帖子内容并生成专业摘要: * * {{# 1776177480759. all_posts_text#}} AI写代码 -
LinkedIn:
- Prompt:要求 LLM 生成专业摘要,识别账号领域、核心观点。
- 输出:2-3 句话的专业分析。
- 完整提示词如下:
handlebars* 你是一位专业的社交媒体内容分析师。请仔细阅读以下来自 TikTok 账号的多条帖子描述,并用一句简洁的话(不超过50个字)总结出该账号的核心内容主题、主要推广的产品或服务。 * * 帖子描述合集: * {{#1776153576689.all_descriptions#}} * * 请直接输出摘要,不要包含任何其他文字、解释或前缀。 AI写代码(7) 报告生成与 Slack 通知
TikTok:
- Prompt:要求 LLM 用一句话(≤50 字)总结账号核心内容或推广产品。
- 输出:简洁的内容主题摘要。
- 完整提示词如下:
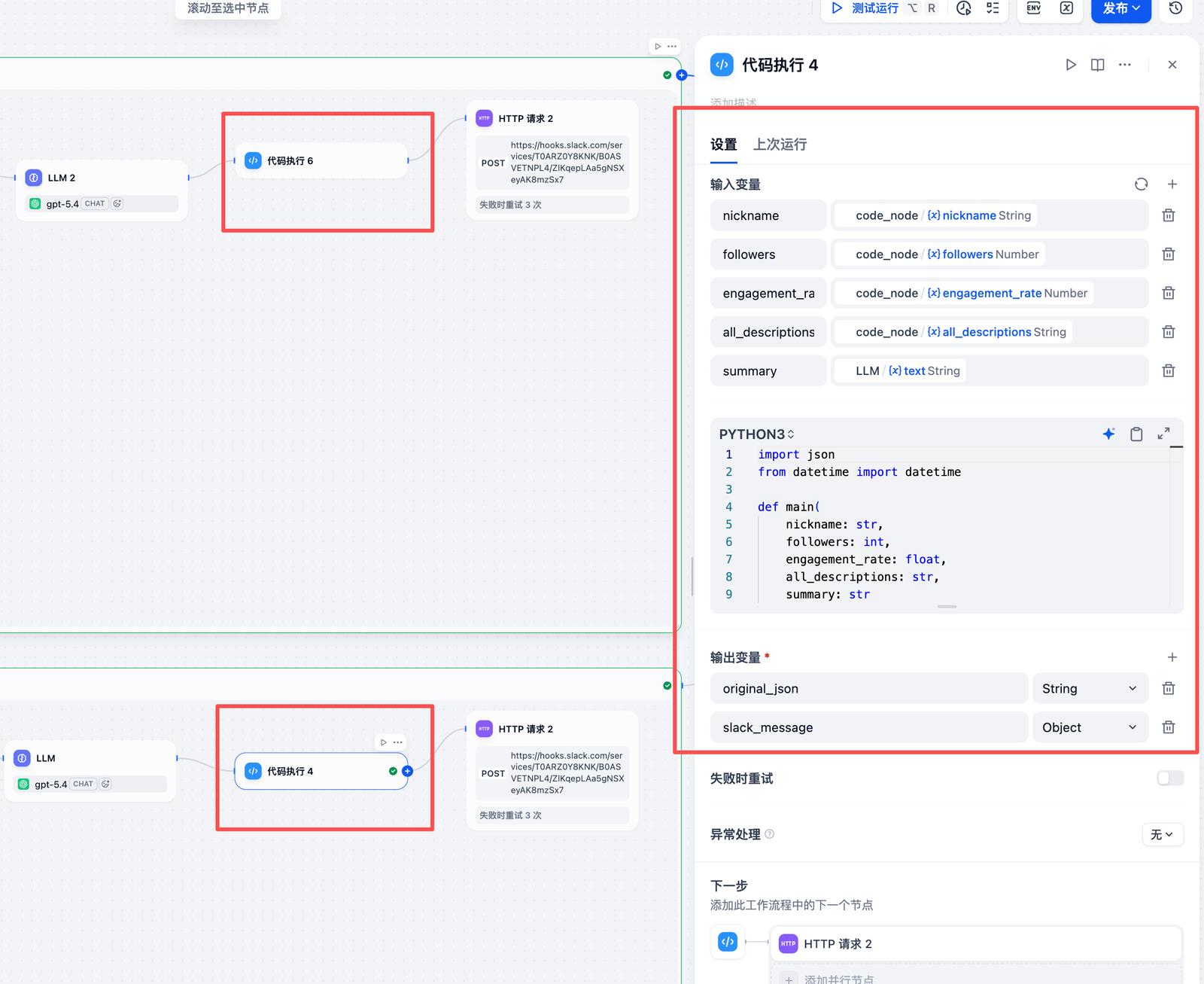
LinkedIn构建JSON代码
cobol
*
import json
*
from datetime import datetime
*
*
def main(
*
author_name: str,
*
followers: int,
*
total_likes: int,
*
total_comments: int,
*
all_posts_text: str,
*
summary: str
*
) -
> dict:
*
""
"
*
构建符合 Slack 格式的 JSON 输出
*
*
参数:
*
author_name: 作者姓名
*
followers: 粉丝数
*
total_likes: 总点赞数
*
total_comments: 总评论数
*
all_posts_text: 所有帖子文本
*
summary: LLM 生成的内容摘要
*
*
返回:
*
包含 slack_message 和 original_json 的字典
*
"
""
*
*
# 计算平均互动数据
*
post_
count
= len(
all_posts_text.split(
'---'))
if
all_posts_text
else
1
*
avg_likes
= total_likes
/ post_
count
if post_
count
>
0
else
0
*
avg_comments
= total_comments
/ post_
count
if post_
count
>
0
else
0
*
*
# 构建 Slack 消息
*
slack_message
= {
*
"text": f
"💼 LinkedIn 账号分析报告 - {author_name}",
*
"blocks": [
*
{
*
"type":
"header",
*
"text": {
*
"type":
"plain_text",
*
"text":
"LinkedIn 账号分析报告",
*
"emoji":
True
*
}
*
},
*
{
*
"type":
"section",
*
"fields": [
*
{
*
"type":
"mrkdwn",
*
"text": f
"*👤 作者:*\n{author_name}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text": f
"*👥 粉丝数:*\n{followers:,}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text": f
"*👍 平均点赞:*\n{avg_likes:.1f}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text": f
"*💬 平均评论:*\n{avg_comments:.1f}"
*
}
*
]
*
},
*
{
*
"type":
"divider"
*
},
*
{
*
"type":
"section",
*
"text": {
*
"type":
"mrkdwn",
*
"text": f
"*📝 内容分析摘要*\n{summary}"
*
}
*
},
*
{
*
"type":
"context",
*
"elements": [
*
{
*
"type":
"mrkdwn",
*
"text": f
"🕒 生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text":
"🤖 由 MCP Scraper + LLM Analysis 生成"
*
}
*
]
*
}
*
]
*
}
*
*
# 构建原始数据
*
original_
data
= {
*
"linkedin_account": {
*
"author_name": author_name,
*
"followers": followers,
*
"total_posts_analyzed": post_
count,
*
"total_likes": total_likes,
*
"total_comments": total_comments,
*
"average_engagement": {
*
"likes_per_post": round(avg_likes,
2),
*
"comments_per_post": round(avg_comments,
2)
*
}
*
},
*
"content_analysis": {
*
"summary": summary,
*
"raw_posts":
all_posts_text,
*
"post_count": post_
count
*
},
*
"metadata": {
*
"generated_at": datetime.now().isoformat(),
*
"data_source":
"MCP Scraper + LLM Analysis"
*
}
*
}
*
*
return {
*
"slack_message": slack_message,
*
"original_json": json.dumps(original_
data, ensure_ascii
=
False, indent
=
2)
*
}
AI写代码

TikTok构建JSON代码
cobol
*
import json
*
from datetime import datetime
*
*
def main(
*
nickname: str,
*
followers: int,
*
engagement_rate: float,
*
all_descriptions: str,
*
summary: str
*
) -
> dict:
*
""
"
*
构建 Slack 消息并保留原始数据
*
*
返回:
*
包含 slack_message 和 original_json 两个字段
*
"
""
*
*
# 构建扁平的 Slack 消息(用于发送)
*
slack_message
= {
*
"text": f
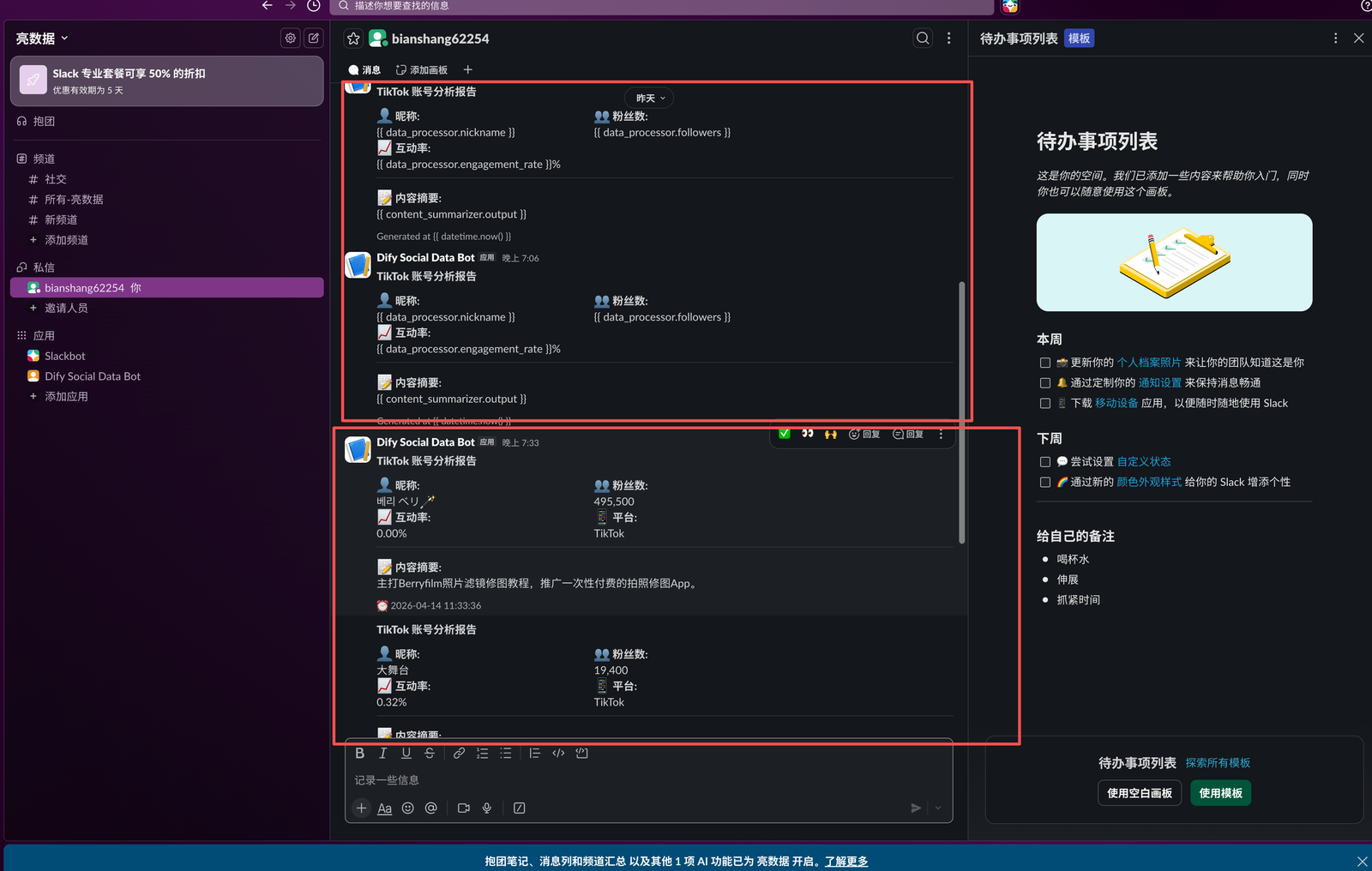
"📊 TikTok 账号分析报告 - {nickname}",
*
"blocks": [
*
{
*
"type":
"header",
*
"text": {
*
"type":
"plain_text",
*
"text":
"TikTok 账号分析报告",
*
"emoji":
True
*
}
*
},
*
{
*
"type":
"section",
*
"fields": [
*
{
*
"type":
"mrkdwn",
*
"text": f
"*👤 昵称:*\n{nickname}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text": f
"*👥 粉丝数:*\n{followers:,}"
*
},
*
{
*
"type":
"mrkdwn",
*
"text": f
"*📈 互动率:*\n{engagement_rate:.2f}%"
*
},
*
{
*
"type":
"mrkdwn",
*
"text":
"*📱 平台:*\nTikTok"
*
}
*
]
*
},
*
{
*
"type":
"divider"
*
},
*
{
*
"type":
"section",
*
"text": {
*
"type":
"mrkdwn",
*
"text": f
"*📝 内容摘要:*\n{summary}"
*
}
*
},
*
{
*
"type":
"context",
*
"elements": [
*
{
*
"type":
"mrkdwn",
*
"text": f
"⏰ {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
*
}
*
]
*
}
*
]
*
}
*
*
# 构建原始数据(用于 original_json)
*
original_
data
= {
*
"tiktok_account": {
*
"nickname": nickname,
*
"followers": followers,
*
"engagement_rate": round(engagement_rate,
4),
*
"platform":
"TikTok"
*
},
*
"content_analysis": {
*
"summary": summary,
*
"raw_descriptions":
all_descriptions,
*
"description_count": len(
all_descriptions.split(
'---'))
if
all_descriptions
else
0
*
},
*
"metadata": {
*
"generated_at": datetime.now().isoformat(),
*
"data_source":
"MCP Scraper + LLM Analysis"
*
}
*
}
*
*
# 返回两个字段
*
return {
*
"slack_message": slack_message,
*
"original_json": json.dumps(original_
data, ensure_ascii
=
False, indent
=
2)
*
}
AI写代码

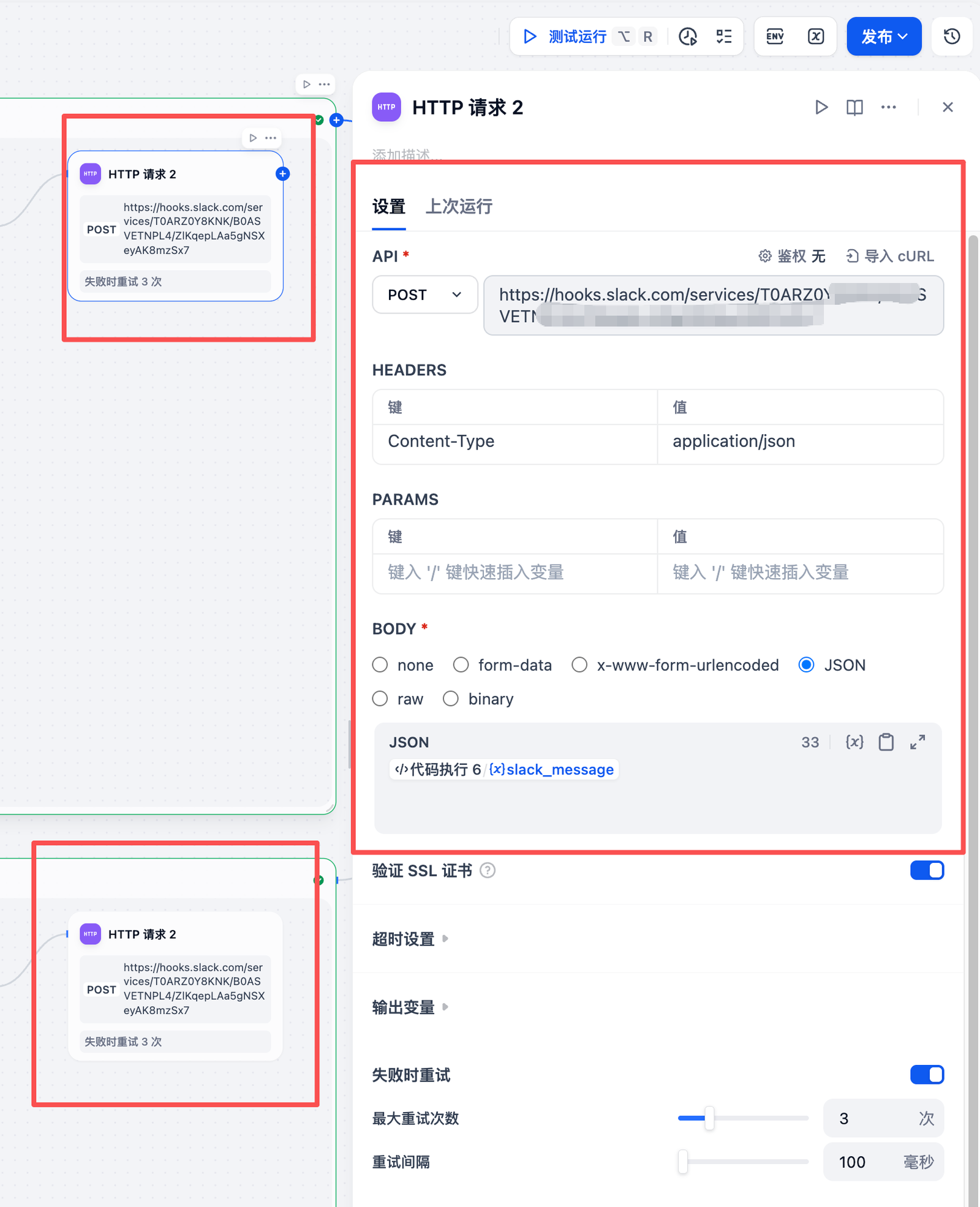
LinkedIn/TikTok 共用逻辑:
- 代码节点:构建 Slack 消息(含关键指标 + 内容摘要)和原始 JSON 数据。
- HTTP 请求:通过 Webhook 将消息发送至 Slack 频道。
运行结果展示
输入内容分别如下:
TikTok:https://www.tiktok.com/@berryveryloveyou,https://www.tiktok.com/@y5uhij3
注意:只用输入链接部分就行了。
这是工作流发送消息,请求是成功发送
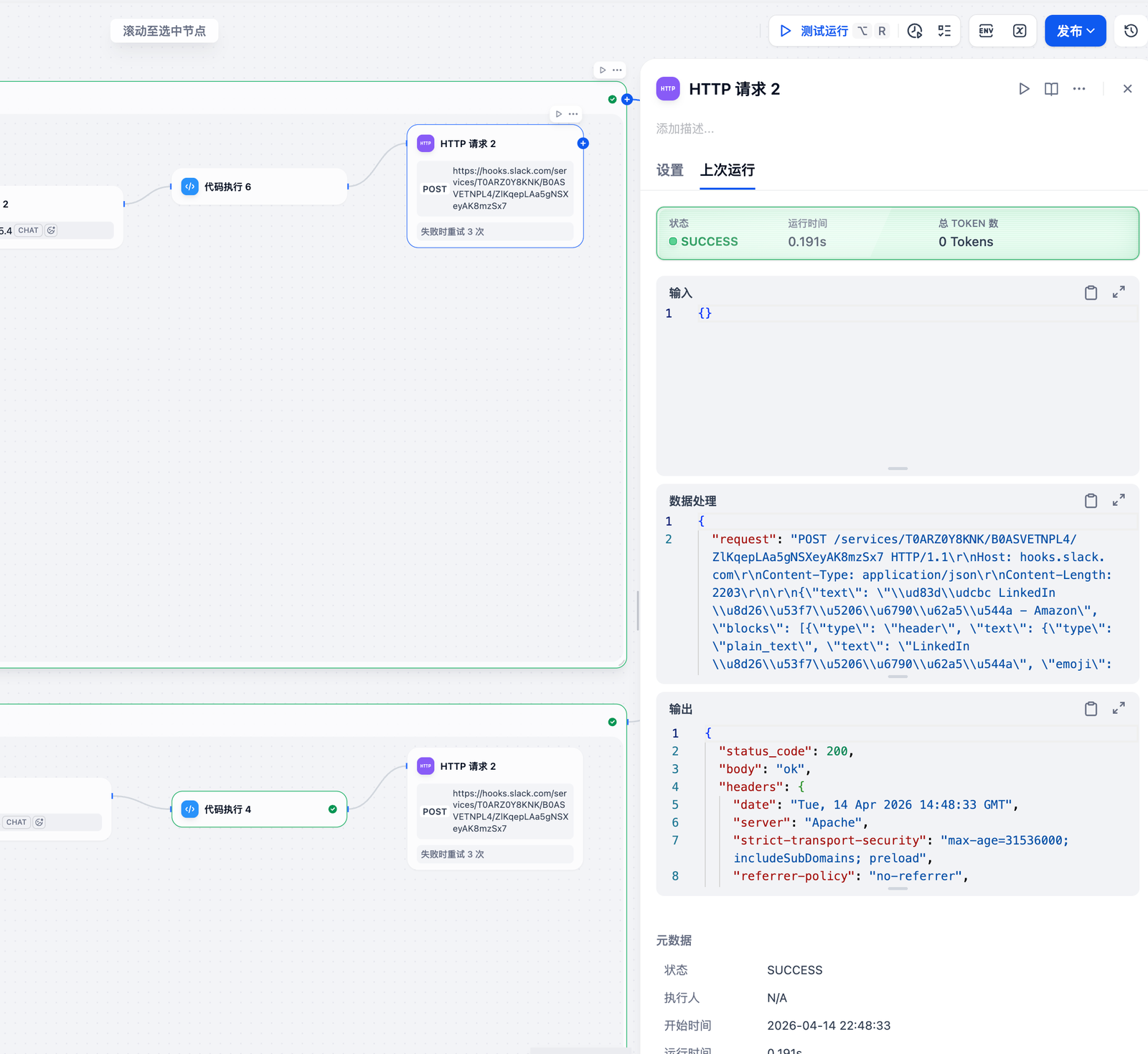
发送的内容是这个JSON
下面是Slack收到的分析报告
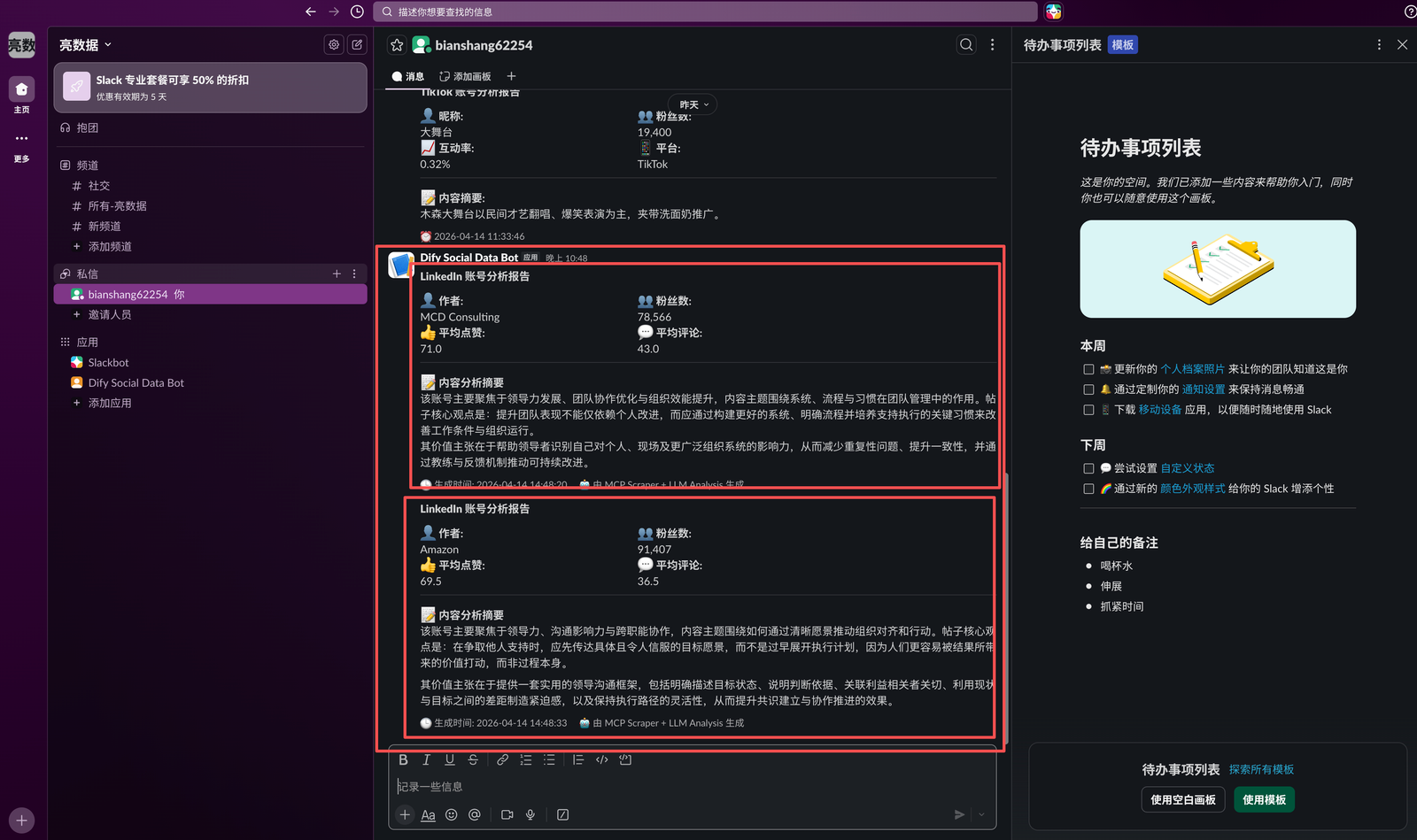
这是Slack收到的分析报告
成本分析
|------------------------|-----------|----------|----------|
| 方案 | 前期投入 | 月均维护 | 10万条数据成本 |
| 自建爬虫 | 2至 4周工程时间 | 超过20小时每月 | 工程成本难以量化 |
| Bright Data MCP + Dify | 不到1天配置 | 低于2小时每月 | 按成功采集付费 |
Bright Data 的"只为成功采集付费"定价模式,大大降低了隐性成本------工程师时间、维护成本、封锁导致的数据损失。
总结
为了让大家能立即上手,我准备了完整的工作流,导入就能用。你可以访问我的网盘https://pan.baidu.com/s/1OsEZP6uEQTeIIGr_zi15zw?pwd=b2jy获取所有资源。
使用方法:
- 下载
yml文件。 - 在 Dify 中选择「导入工作流」。
- 将 亮数据MCP中的链接 替换为你自己的。
- 完成!现在你可以输入任何帖子链接,开始监控了。
如果你也厌倦了与爬虫的无休止斗争,现在就是改变的时候。如果你想快速验证这个工作流,可以先从 Bright Data MCP免费版本开始,并下载本文提供的模板,相比传统爬虫,这套方案可以:
-
减少 90% 爬虫维护成本
-
避免 IP 封禁和 CAPTCHA
-
快速构建 AI 驱动的数据采集系统

我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3e17o7liy82sc