企业软件有一个经典陷阱:把复杂度留在产品里,然后期待用户自己学会用。
这周我们掉进去了。然后爬出来了。
知识库上周正式上线,工作流今天进入测试,多 Agent 协作被正式列为第四个核心功能。看起来是推进顺利的一周------但认真审视细节之后,有三件值得记录的事。
一、想清楚了:工作流是给谁用的
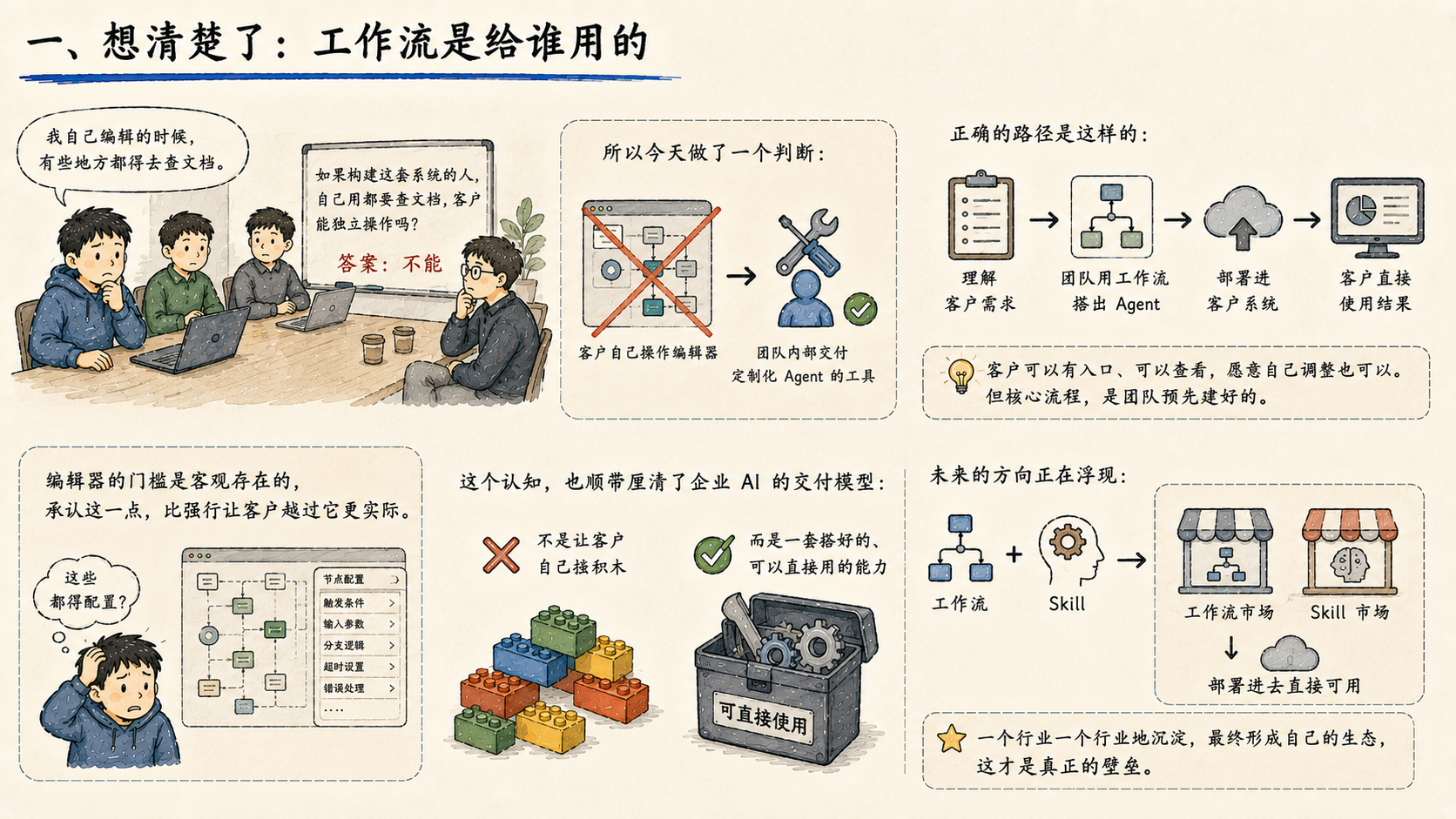
测试可视化工作流编辑器时,有人说了一句话:
"我自己编辑的时候,有些地方都得去查文档。"
会议室安静了几秒。
如果构建这套系统的人,自己用都要查文档,客户能独立操作吗?
答案很清楚:不能。
所以今天做了一个判断:工作流是团队交付定制化 Agent 的内部工具,不是客户的操作界面。
正确的路径是这样的:
理解客户需求 → 团队用工作流搭出对应的 Agent → 部署进客户系统 → 客户直接使用结果
客户可以有入口、可以查看,愿意自己调整也可以。但核心流程,是团队预先建好的。编辑器的门槛是客观存在的,承认这一点,比强行让客户越过它更实际。
这个认知,也顺带厘清了企业 AI 的交付模型:卖的不是一个让客户自己搭积木的工具,而是一套搭好的、可以直接用的能力。
未来的方向正在浮现:工作流和 Skill 做成可复用的模块,一个行业一个行业地沉淀,最终可以形成自己的生态------工作流市场、Skill 市场,部署进去直接可用,这才是真正的壁垒。
二、产品方向,这周更清晰了
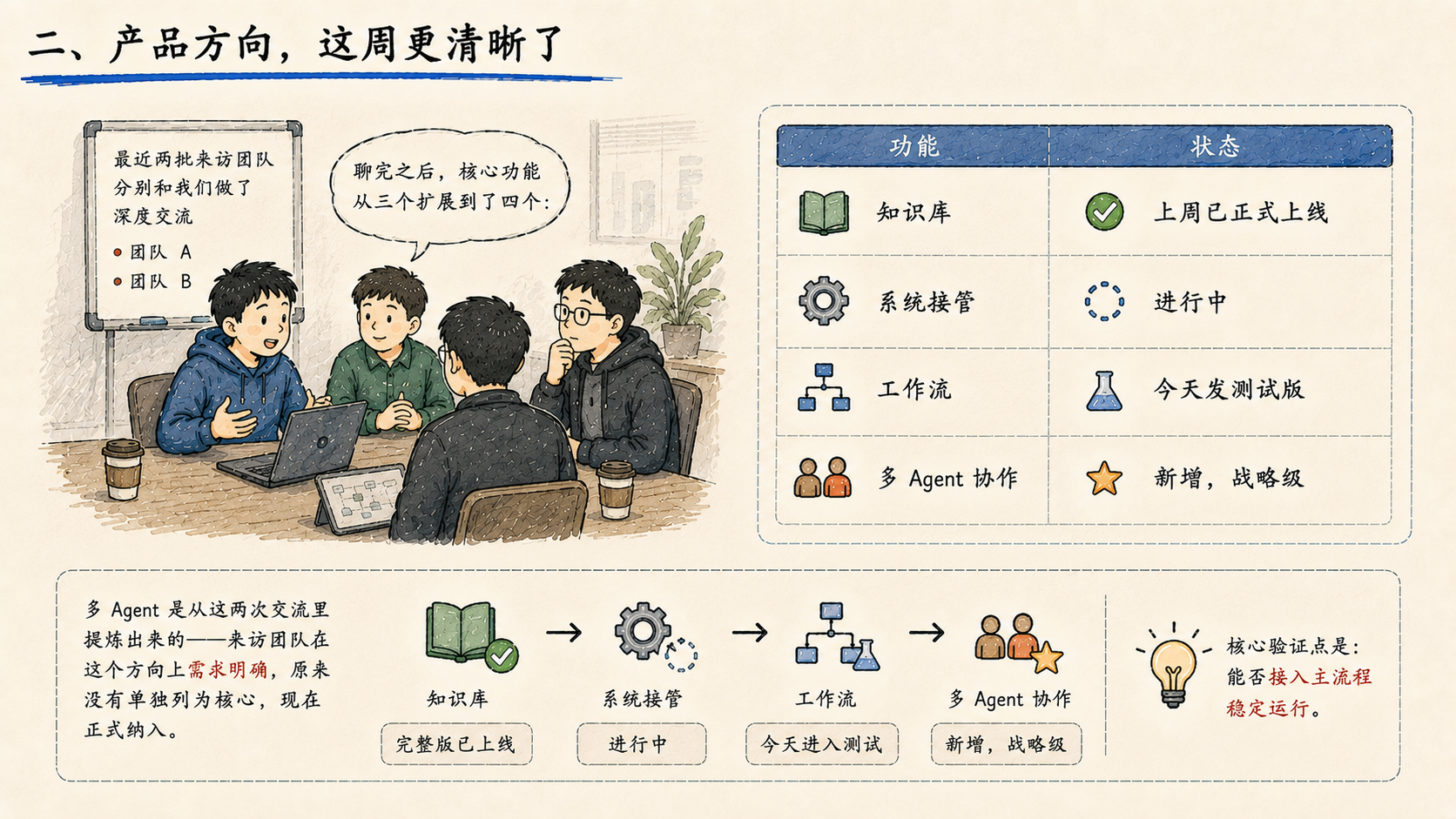
最近两批来访团队分别和我们做了深度交流,聊完之后,核心功能从三个扩展到了四个:
| 功能 | 状态 |
|---|---|
| 知识库 | 上周已正式上线 |
| 系统接管 | 进行中 |
| 工作流 | 今天发测试版 |
| 多 Agent 协作 | 新增,战略级 |
多 Agent 是从这两次交流里提炼出来的------来访团队在这个方向上需求明确,原来没有单独列为核心,现在正式纳入。知识库完整版已上线,工作流今天进入测试,核心验证点是能否接入主流程稳定运行。
三、一个让人不安的 Bug:记忆在跨会话泄漏
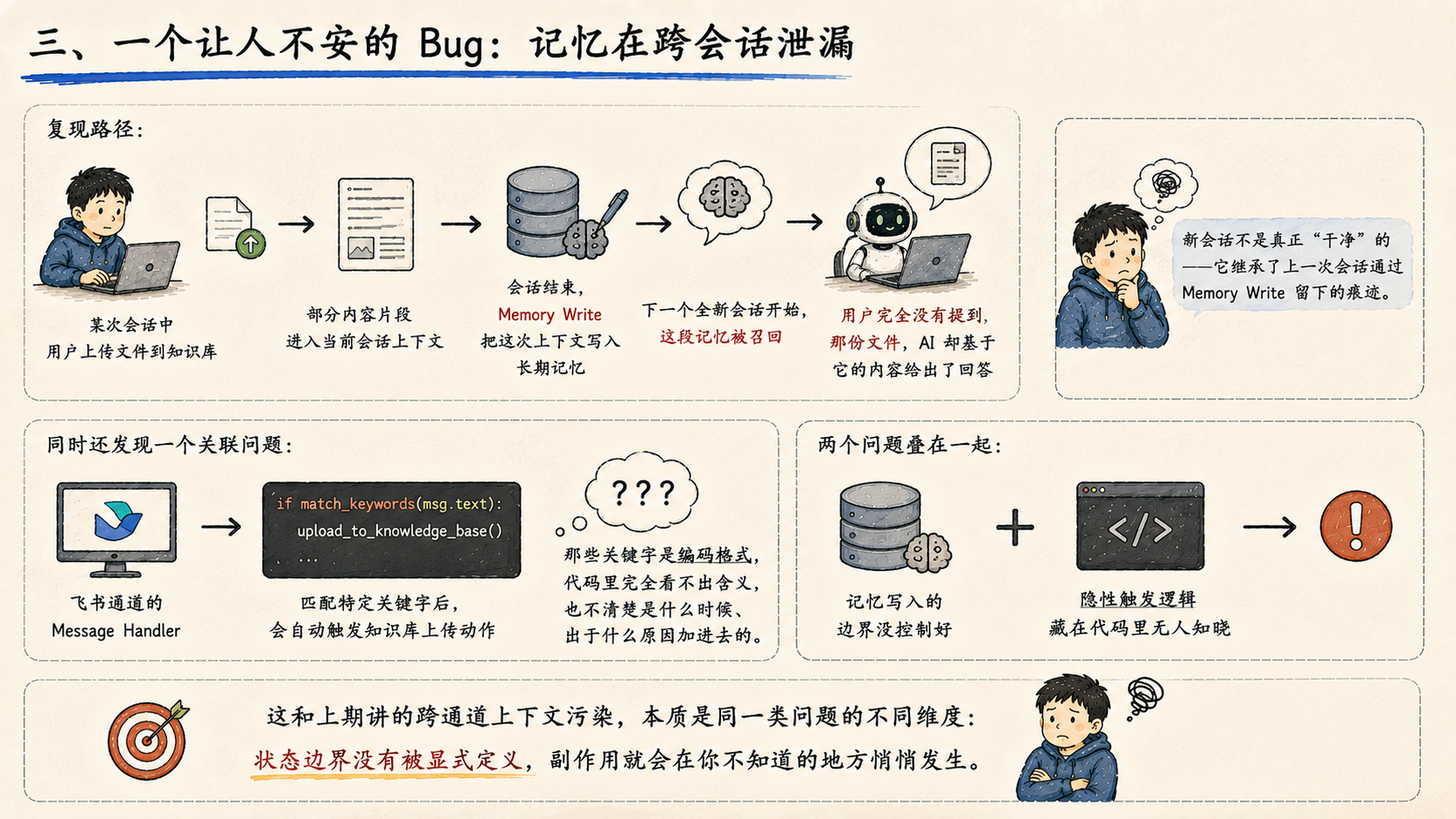
知识库上线后,测试发现了一个隐蔽的问题。
复现路径是这样的:
-
某次会话中用户上传文件到知识库,部分内容片段进入当前会话上下文
-
会话结束,Memory Write 把这次上下文写入长期记忆
-
下一个全新会话开始,这段记忆被召回
-
用户完全没有提到那份文件,AI 却基于它的内容给出了回答
新会话不是真正"干净"的------它继承了上一次会话通过 Memory Write 留下的痕迹。
同时还发现一个关联问题:飞书通道的 Message Handler 里,有一段代码在匹配特定关键字后会自动触发知识库上传动作。但那些关键字是编码格式,代码里完全看不出含义,也不清楚是什么时候、出于什么原因加进去的。
两个问题叠在一起:记忆写入的边界没控制好,加上有隐性触发逻辑藏在代码里无人知晓。
这和上期讲的跨通道上下文污染,本质是同一类问题的不同维度:状态边界没有被显式定义,副作用就会在你不知道的地方悄悄发生。
四、一个新的紧迫问题:代码不能裸着出门
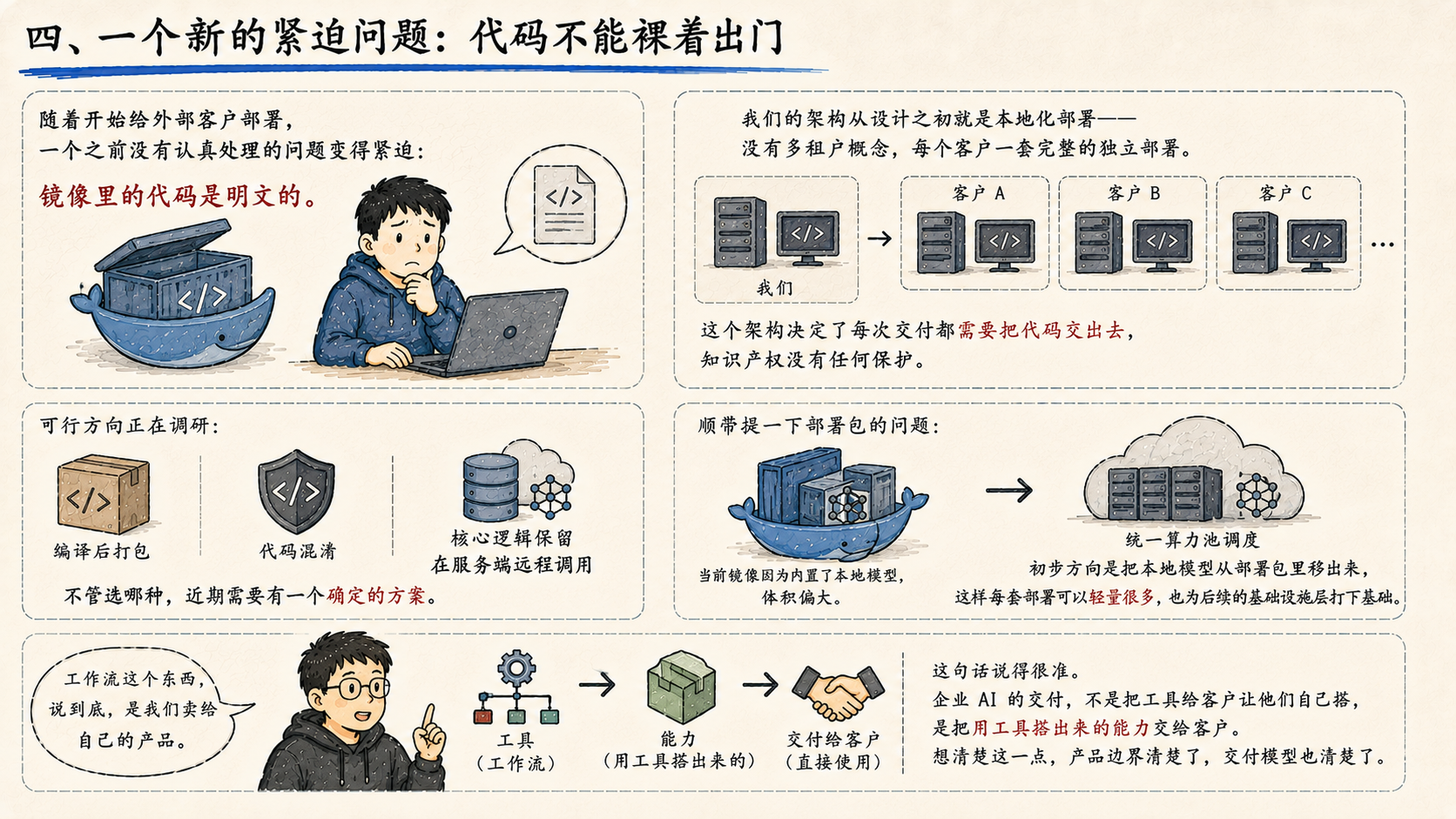
随着开始给外部客户部署,一个之前没有认真处理的问题变得紧迫:镜像里的代码是明文的。
我们的架构从设计之初就是本地化部署------没有多租户概念,每个客户一套完整的独立部署。这个架构决定了每次交付都需要把代码交出去,知识产权没有任何保护。
可行方向正在调研:编译后打包、代码混淆、或核心逻辑保留在服务端远程调用。不管选哪种,近期需要有一个确定的方案。
顺带提一下部署包的问题:当前镜像因为内置了本地模型,体积偏大。初步方向是把本地模型从部署包里移出来,集中到统一的算力池调度。这样每套部署可以轻量很多,也为后续的基础设施层打下基础。
散会前有人说:
"工作流这个东西,说到底,是我们卖给自己的产品。"
这句话说得很准。企业 AI 的交付,不是把工具给客户让他们自己搭,是把用工具搭出来的能力交给客户。想清楚这一点,产品边界清楚了,交付模型也清楚了。
这,是第二十八天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。