Redis与多线程
1.引言
大家可能都听说过,Redis是单线程的 。所以,对Redis与多线程这个组合多多少少有一些疑问。
我们平时所说的Redis是单线程的,这里的单线程指的是Redis的命令执行是单线程的 。Redis的所有命令,全部交给一个线程来执行。和MySQL不同,MySQL是一连接一线程,每个连接需要执行的命令,都对应在处理这条连接的线程上执行。
为什么Redis选择将所有命令放到同一个线程执行?
在回答这个问题之前,我们先了解原始的Redis模型是怎么处理客户端请求的。
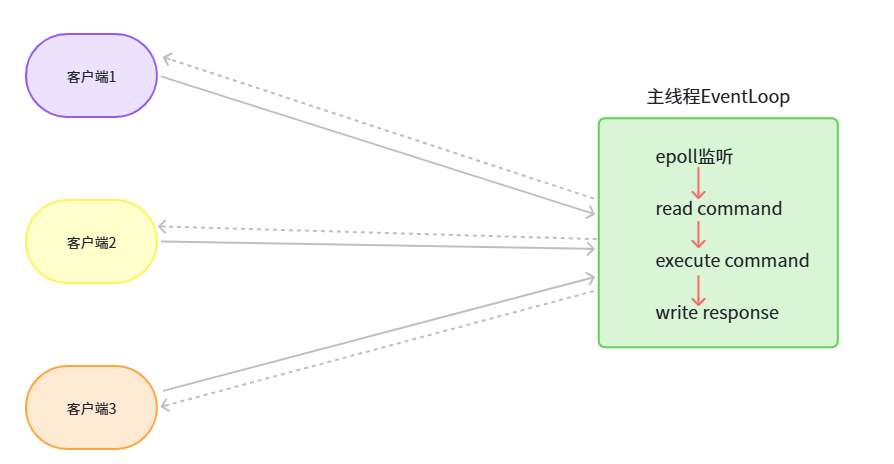
通过epoll监听所有客户端的连接,当连接的可读事件就绪后,通过epoll_wait拿到所有就绪的fd。然后将数据读到客户端对应的read buffer,接着对数据进行解析并执行,将结果写入到客户端对应的write buffer,最后,将执行结果返回给客户端。整个过程,都由主线程自己完成。
Redis是内存接数据库,所有操作基本上都是基于内存的,加上Redis底层设计的高效数据结构,命令的执行相当快。而且,单线程执行所有命令和MySQL的多线程执行命令不同。单线程天然就没有锁竞争,而多线程在同时访问同一个数据库表的时候,为了避免数据混乱,是要加锁的。基于这些原因,Redis早期都是使用主线程来完成所有任务的。
单线程最担心的是什么?归根结底就四个字:耗时操作。
单线程的服务,一旦被某个耗时的操作卡住,那么将导致其他客户端的响应变慢,甚至导致整理服务暂时不可用。这也是后来Redis官方引入多线程的原因。
2.Redis引入多线程
后来,Redis官方发现有些操作有点慢,比如开启AOF持久化后,需要将数据进行落盘。这就需要和磁盘打交道,速度比较慢。
于是,在Redis2.6就引入了BIO线程池(Background IO)。
- bio_aof_fsync: 专门做AOF异步刷盘。
- bio_close_file: 关闭文件。
你可能会好奇:为什么关闭文件是个耗时的操作?
因为在关闭文件时,会涉及到系统资源的回收。比如,如果是关闭TCP连接,那么CLOSE就要走四次挥手。
到了Redis4.0,Redis官方又引入了异步删除大key的后台线程。
因为对于一个huge_hash,直接DEL,可能会耗时几百毫秒,主线程卡住,整个Redis都会卡住。
c
typedef enum bio_worker_t {
BIO_WORKER_CLOSE_FILE = 0,
BIO_WORKER_AOF_FSYNC,
BIO_WORKER_LAZY_FREE,
BIO_WORKER_NUM
} bio_worker_t;0号线程完成主线程交给的关闭文件的任务。
1号线程完成AOF持久化的异步刷盘。
2号线程完成大key的删除。
BIO_WORKER_NUM=3,说明BIO线程数是固定的,只有三个。
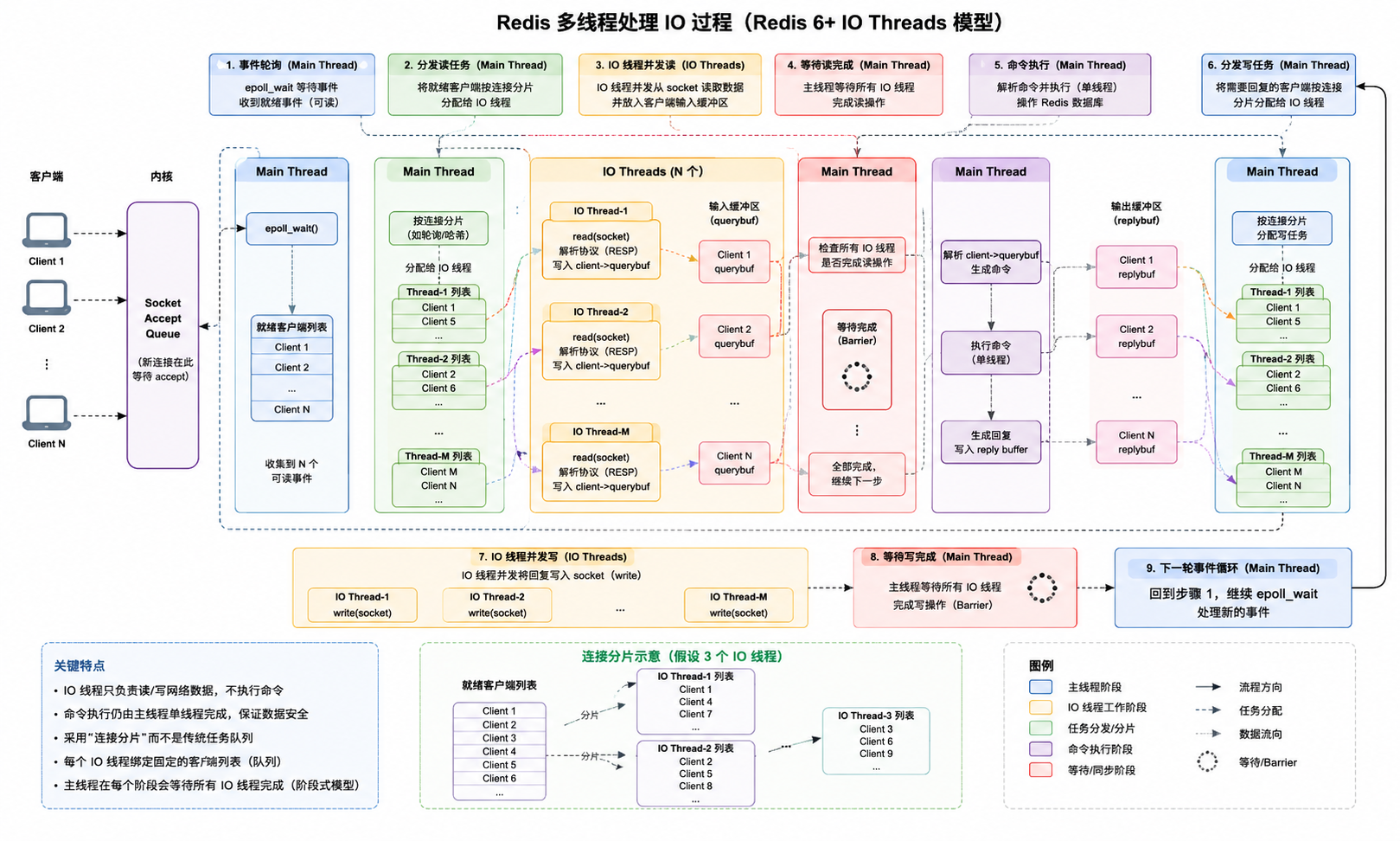
到了Redis6,引入了IO Thread Pool。
因为Redis官方发现,主线程很多时间花在读数据、写数据、协议解析以及数据拷贝 上。
在Redis6以前,当数据就绪后,主线程调用read将数据从内核缓冲区拷贝到客户端的读缓冲区querybuf,然后进行协议解析,执行命令,最后将结果拷贝到写缓冲区replybuf,并发送给客户端。于是,网络IO成为了性能瓶颈。
- 引入IO Thread Pool之后,主线程通过
epoll_wait()拿到所有就绪的客户端fd。假设有100个连接的读事件就绪,有4个IO线程,那么主线程将会进行分片,将这100个客户端分给4个IO线程。这4个IO线程,每一个都有自己专属的队列来保存要处理的客户端。 - IO线程调用read,将对应连接的数据从内核缓冲区拷贝到用户态的看,客户端专属
querybuf,并完成协议解析。 - 主线程等待所有IO线程完成,这个期间,主线程忙等,其他的什么都不做。不过,这个等待时间通常都是很短的。
- 所有的IO线程处理完毕后,主线程才开始向后执行。主线程依次执行每个客户端的命令,并将结果写入到客户端对应的
replybuf。 - 主线程执行完客户端的命令后,收集要写回的客户端,然后再次进行分片,将写回的任务交给IO线程。
- IO线程收到后,调用write将数据写回给客户端。
总而言之,读、写、协议解析和数据拷贝,都交给了IO线程,但是命令的执行依旧保持单线程执行。
上面说到,每个IO线程都有自己专属的队列,不像普通的线程池,只有一个任务队列,所有线程都从这个任务队列中拿任务。

这种情形下,会存在多线程之间的锁竞争。
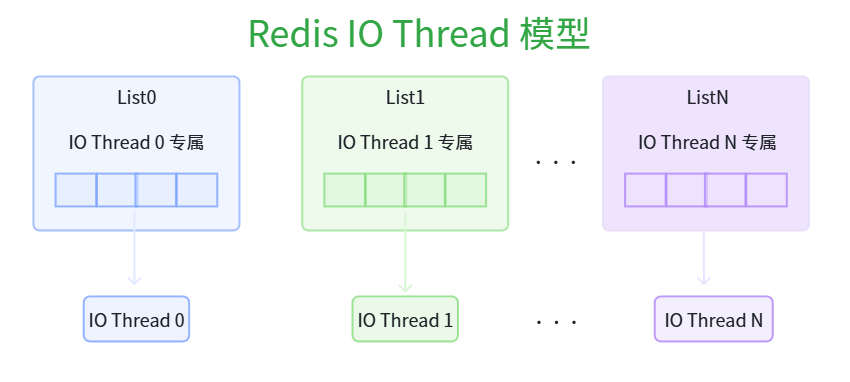
Redis IO Thread 模型中,给每一个IO Thread都分配一个专属的队列,好处在于不需要加锁,这也是Redis设计的巧妙之处所在。
总的来说,Redis的IO Thread工作流程可以用下面一张图来展示。
3.结语
欢迎批评指正!