12-Factor Agents:2026 年生产级 LLM 软件工程方法论深度解析
摘要 :当 AI Agent 从 Demo 走向生产,开发者面临的不再是"能不能跑通"的问题,而是"能不能在客户手上可靠运行"。GitHub 上 20K+ stars 的
12-Factor Agents项目给出了一份答案------将 Heroku 经典的 12-Factor App 方法论移植到 LLM 驱动的软件中。本文逐条拆解 12 条原则,结合 Java + Python 双语言代码示例和架构图解,帮助读者从零搭建一套可维护、可扩展、可调试的生产级 Agent 系统。
一、背景:从 12-Factor App 到 12-Factor Agents
1.1 软件架构的三次演进
过去三十年,软件工程经历了三次重大范式转移:
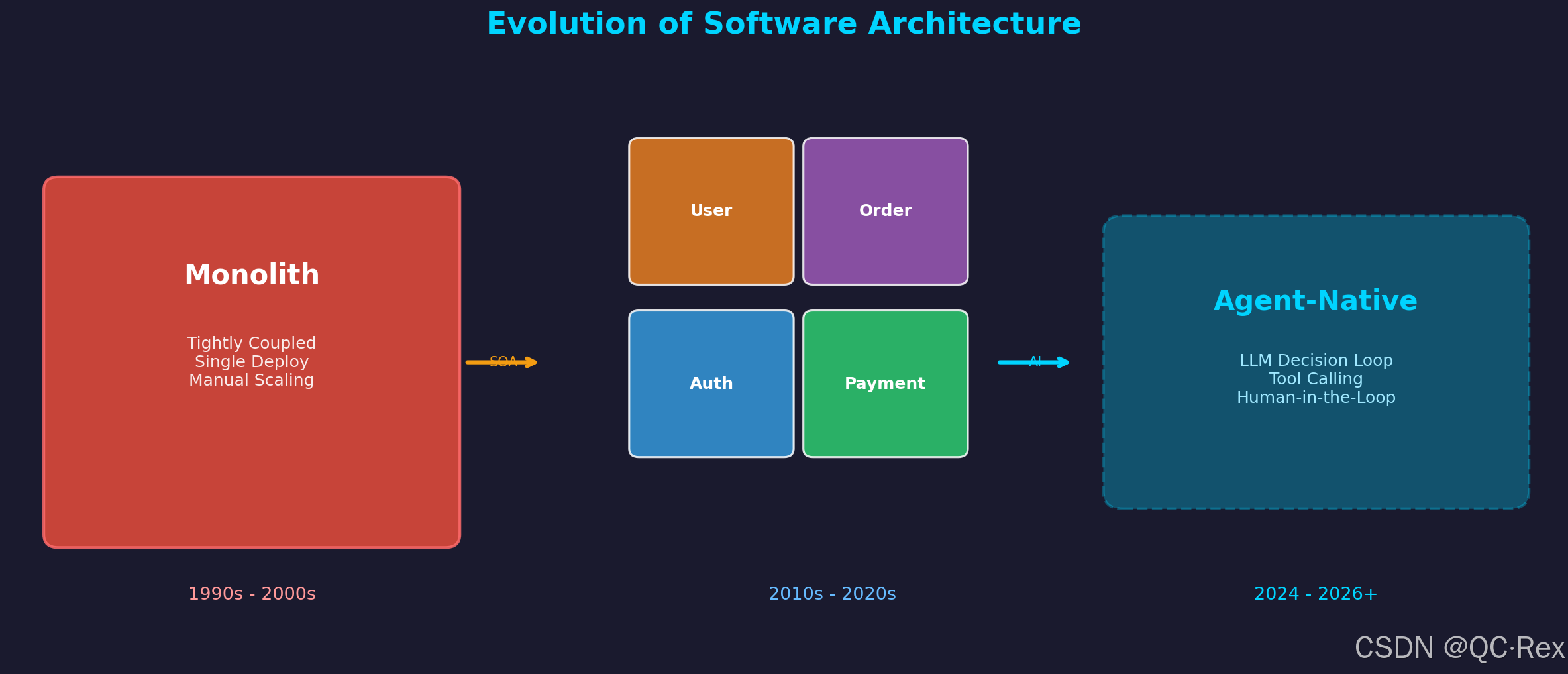
软件架构演进
第一次:单体时代(1990s--2000s)。所有代码打包在一个进程里,部署简单但扩展困难,修改一行代码需要重新编译整个应用。
第二次:微服务时代(2010s--2020s)。Docker + Kubernetes 将系统拆分为独立部署的服务,每个服务有明确的 API 边界。Airflow、Dagster 等工作流编排器引入了 DAG(有向无环图)模式,让复杂流程可视、可控。
第三次:Agent 原生时代(2024--至今)。LLM 的出现打破了 DAG 的确定性------你不再需要写死每一步的路径,而是给 Agent 一个目标和一组工具,让它在运行时动态决策。
GitHub 上 humanlayer/12-factor-agents 项目(20,651 stars,每日增长近 400 星)和 HKUDS/CLI-Anything 项目(36,731 stars,"让所有软件 Agent 原生")标志着这一范式转移正在从学术研究走向工程实践。
1.2 为什么需要新的方法论?
Heroku 的 12-Factor App(2011)定义了云原生应用的最佳实践:代码库跟踪、依赖显式声明、配置与代码分离等。这些原则在今天仍然适用,但 LLM 驱动的软件引入了全新的挑战:
- 控制流不确定:LLM 的决策不是确定性的 if/else,而是概率性的 token 采样
- 上下文窗口有限:对话历史、工具调用、系统提示全部挤在有限的 token 预算里
- 工具调用需要人工审批:涉及资金、部署、数据修改等高风险操作不能自动执行
- 错误表现形式不同:LLM 可能产生幻觉、遗漏参数、调用错误的工具
12-Factor Agents 正是为了解决这些问题而诞生的。它不绑定任何框架,而是提供一组可以渐进式采纳的工程原则。
二、12 条原则逐条拆解

12-Factor Agents 概览
Factor 1:自然语言到工具调用(Natural Language to Tool Calls)
这是 Agent 最核心的能力------将用户的自然语言意图翻译为结构化的 API 调用。
举个例子,用户说"帮我给 Terri 创建一个 750 美元的赞助付款链接",Agent 需要输出:
json
{
"function": "create_payment_link",
"parameters": {
"amount": 750,
"customer": "cust_128934",
"product": "prod_8675309",
"memo": "February AI tinkerers meetup sponsorship"
}
}关键点在于:LLM 只做翻译,不直接执行。翻译后的结构化对象由确定性代码来处理。这保证了关键操作(如付款)的执行逻辑是可控、可审计的。
Java 实现示例(JDK 21+):
java
/**
* Factor 1: 自然语言转工具调用
* JDK 21+, 使用 OpenAI Java SDK
* 依赖: com.openai:openai-java:2.0.0+
*/
import com.openai.client.OpenAIClient;
import com.openai.models.chat.completions.ChatCompletion;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
import com.openai.models.chat.completions.ChatCompletionCreateParams.Tool;
import com.openai.models.chat.completions.FunctionDefinition;
public class NaturalLanguageToolCall {
private final OpenAIClient client;
public NaturalLanguageToolCall(OpenAIClient client) {
this.client = client;
}
/**
* 将用户自然语言输入翻译为结构化工具调用
* @param userInput 用户的自然语言请求
* @return LLM 返回的工具调用结构
*/
public ChatCompletion translateToToolCall(String userInput) {
// 定义 Agent 可用的工具列表
ChatCompletionCreateParams params = ChatCompletionCreateParams.builder()
.model("gpt-4o")
.addSystemMessage("你是一个支付助手。将用户请求翻译为工具调用。")
.addUserMessage(userInput)
// 注册可用的工具
.addTool(Tool.fromChatCompletionToolFunction(
FunctionDefinition.builder()
.name("create_payment_link")
.description("创建 Stripe 付款链接")
.buildStrictJsonSchema("""
{
"type": "object",
"properties": {
"amount": {"type": "number", "description": "金额(美元)"},
"customer": {"type": "string", "description": "客户ID"},
"memo": {"type": "string", "description": "备注"}
},
"required": ["amount"]
}
""")
.build()
))
.maxTokens(500)
.build();
return client.chat().completions().create(params);
}
public static void main(String[] args) {
OpenAIClient client = OpenAIClient.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.build();
NaturalLanguageToolCall agent = new NaturalLanguageToolCall(client);
ChatCompletion result = agent.translateToToolCall(
"帮我给 Terri 创建 750 美元的赞助付款链接"
);
// 提取工具调用(Factor 4 会详细展开)
result.choices().forEach(choice -> {
choice.message().toolCalls().forEach(tc -> {
System.out.println("Function: " + tc.function().name());
System.out.println("Arguments: " + tc.function().arguments());
});
});
}
}Python 对照实现(Python 3.10+):
python
"""
Factor 1: 自然语言转工具调用
Python 3.10+, 使用 openai SDK >= 1.0.0
"""
from openai import OpenAI
import json
class NaturalLanguageToolCall:
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
self.tools = [{
"type": "function",
"function": {
"name": "create_payment_link",
"description": "创建 Stripe 付款链接",
"parameters": {
"type": "object",
"properties": {
"amount": {"type": "number", "description": "金额(美元)"},
"customer": {"type": "string", "description": "客户ID"},
"memo": {"type": "string", "description": "备注"},
},
"required": ["amount"],
},
}
}]
def translate_to_tool_call(self, user_input: str) -> dict:
response = self.client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个支付助手。将用户请求翻译为工具调用。"},
{"role": "user", "content": user_input},
],
tools=self.tools,
max_tokens=500,
)
return response.choices[0].message
if __name__ == "__main__":
agent = NaturalLanguageToolCall(api_key="sk-...")
result = agent.translate_to_tool_call(
"帮我给 Terri 创建 750 美元的赞助付款链接"
)
if result.tool_calls:
tc = result.tool_calls[0]
print(f"Function: {tc.function.name}")
print(f"Arguments: {tc.function.arguments}")Factor 2:拥有你的提示词(Own Your Prompts)
不要将提示词硬编码在框架配置里。提示词是你的业务逻辑,应该像代码一样被版本控制、测试和迭代。
实践建议:
- 将提示词存储为独立文件(YAML/JSON),与代码仓库一起版本管理
- 为每个提示词编写单元测试:给定输入,验证输出格式
- 使用 A/B 测试比较不同提示词版本的效果
- 记录每次提示词变更的影响(延迟、准确率、token 消耗)
yaml
# prompts/payment_agent_v2.yaml
name: payment_agent
version: "2.1"
system_prompt: |
你是一个专业的支付助手。
你的职责是帮助用户创建付款链接。
规则:
1. 金额必须是正数
2. 如果用户未提供客户ID,先查询客户列表
3. 金额超过 1000 美元时,需要人工审批(Factor 7)
可用工具:
- create_payment_link: 创建付款链接
- list_customers: 列出客户
- list_products: 列出产品
temperature: 0.1
max_tokens: 1024Factor 3:拥有你的上下文窗口(Own Your Context Window)
上下文窗口是 Agent 的"工作记忆"。不管理好它,Agent 就会遗忘关键信息或被冗余内容淹没。
核心策略:
| 策略 | 描述 | 适用场景 |
|---|---|---|
| 滑动窗口 | 只保留最近 N 条消息 | 短对话 |
| 摘要压缩 | 将旧对话压缩为摘要 | 长对话 |
| 关键信息置顶 | 用户身份、偏好等始终保留 | 所有场景 |
| 按需检索 | 从向量数据库中按需拉取相关上下文 | 知识库场景 |
python
"""
Factor 3: 上下文窗口管理
使用摘要 + 关键信息置顶策略
"""
class ContextManager:
def __init__(self, max_tokens: int = 8000, summary_threshold: int = 6000):
self.max_tokens = max_tokens
self.summary_threshold = summary_threshold
self.permanent_context: list[dict] = [] # 始终保留的系统信息
self.messages: list[dict] = [] # 动态对话历史
def add_message(self, role: str, content: str):
self.messages.append({"role": role, "content": content})
self._maybe_compact()
def _maybe_compact(self):
"""当上下文接近 token 上限时,压缩旧消息"""
total_tokens = self._estimate_tokens()
if total_tokens > self.summary_threshold:
# 保留最近 2 条消息,其余压缩
recent = self.messages[-2:]
to_summarize = self.messages[:-2]
summary = self._generate_summary(to_summarize)
self.messages = [{"role": "system", "content": summary}] + recent
def get_context(self) -> list[dict]:
return self.permanent_context + self.messages
def _estimate_tokens(self) -> int:
"""粗略估算 token 数(每 4 个字符约 1 个 token)"""
return sum(len(m.get("content", "")) for m in self.messages) // 4
def _generate_summary(self, messages: list[dict]) -> str:
"""调用 LLM 将旧消息压缩为摘要"""
# 实际实现中调用 LLM 生成摘要
passFactor 4:工具就是结构化输出(Tools are Structured Outputs)
很多人把"工具调用"看作 LLM 的魔法功能,但本质上它就是:让 LLM 输出符合 JSON Schema 的结构化数据。理解这一点后,你可以用任何支持结构化输出的模型来构建 Agent,而不依赖特定框架的 tool calling 接口。
python
"""
Factor 4: 不使用 tool calling,用结构化输出实现
"""
import json
from pydantic import BaseModel, Field
from openai import OpenAI
class PaymentRequest(BaseModel):
"""定义期望的结构化输出"""
amount: float = Field(description="付款金额(美元)")
customer_name: str = Field(description="客户姓名")
memo: str = Field(description="备注信息")
def extract_structured_output(user_input: str) -> PaymentRequest:
client = OpenAI(api_key="sk-...")
# 使用 response_format 而非 tool calling
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": "从用户输入中提取付款信息。"},
{"role": "user", "content": user_input},
],
response_format=PaymentRequest,
)
return response.choices[0].message.parsed
# 使用示例
result = extract_structured_output("给 Terri 转 750 美元,赞助 AI 聚会")
print(f"金额: ${result.amount}, 客户: {result.customer_name}")
# 输出: 金额: $750.0, 客户: TerriFactor 5:统一执行状态与业务状态(Unify Execution State and Business State)
Agent 的每一次工具调用、每一次 LLM 决策都应该作为事件持久化存储。这样你才能:
- 回溯 Agent 的完整决策链路
- 在中断后从断点恢复
- 审计 Agent 的行为(谁在什么时间做了什么)
java
/**
* Factor 5: 统一执行状态 - 线程 + 事件模型
* JDK 21+, 使用 record 定义不可变事件
*/
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public record ThreadState(
String threadId,
String status, // running, paused, completed, failed
Instant createdAt,
Instant updatedAt,
List<Event> events // 所有事件的完整记录
) {
/**
* 向线程追加一个新事件
*/
public ThreadState appendEvent(Event event) {
List<Event> newEvents = new ArrayList<>(this.events);
newEvents.add(event);
return new ThreadState(
this.threadId,
"running",
this.createdAt,
Instant.now(),
newEvents
);
}
/**
* 获取最后一个事件
*/
public Event lastEvent() {
return events.isEmpty() ? null : events.get(events.size() - 1);
}
}
public sealed interface Event {
record ToolCallEvent(String toolName, String parameters, Instant timestamp) implements Event {}
record ToolResultEvent(String toolName, String result, Instant timestamp) implements Event {}
record HumanApprovalEvent(boolean approved, String reason, Instant timestamp) implements Event {}
record ErrorMessageEvent(String error, Instant timestamp) implements Event {}
record CompletionEvent(String finalAnswer, Instant timestamp) implements Event {}
}Factor 6:用简单 API 实现启动/暂停/恢复(Launch/Pause/Resume)
生产环境中 Agent 不是跑完就结束的单次任务。它可能需要:
- 等待人工审批(暂停)
- 等待外部 Webhook 回调(暂停)
- 收到新输入后继续(恢复)
python
"""
Factor 6: 启动/暂停/恢复 API
"""
from enum import Enum
from dataclasses import dataclass, field
from typing import Optional
import json
class ThreadStatus(Enum):
RUNNING = "running"
PAUSED = "paused"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class AgentThread:
thread_id: str
status: ThreadStatus = ThreadStatus.PAUSED
events: list = field(default_factory=list)
pause_reason: Optional[str] = None
def start(self, initial_event: dict) -> None:
"""启动线程"""
self.events.append({"type": "start", "data": initial_event})
self.status = ThreadStatus.RUNNING
def pause(self, reason: str) -> None:
"""暂停并保存状态"""
self.events.append({"type": "pause", "reason": reason})
self.status = ThreadStatus.PAUSED
self.pause_reason = reason
self._persist()
def resume(self, webhook_data: dict) -> None:
"""从暂停状态恢复"""
if self.status != ThreadStatus.PAUSED:
raise ValueError(f"Cannot resume from {self.status}")
self.events.append({"type": "resume", "data": webhook_data})
self.status = ThreadStatus.RUNNING
self.pause_reason = None
self._run_loop()
def _persist(self) -> None:
"""持久化到数据库"""
# db.save(self)
pass
def _run_loop(self) -> None:
"""主执行循环"""
while self.status == ThreadStatus.RUNNING:
# 决定下一步 -> 执行 -> 追加结果
passFactor 7:通过工具调用联系人类(Contact Humans with Tool Calls)
当 Agent 遇到需要人工决策的场景时,不要静默跳过或自作主张。应该像调用其他工具一样,显式地调用"联系人"工具:
python
"""
Factor 7: Agent 通过工具调用来联系人
"""
def handle_next_step(thread: AgentThread):
"""
Agent 主循环中的工具分发器
区分同步工具和需要人工介入的异步工具
"""
next_step = llm.determine_next_step(thread_to_prompt(thread))
if next_step.function == "create_payment_link":
params = next_step.arguments
if params["amount"] > 1000:
# 大额付款需要人工审批
thread.events.append({
"type": "human_approval_request",
"tool": "create_payment_link",
"params": params,
"reason": f"金额 ${params['amount']} 超过 1000 美元阈值"
})
thread.pause("waiting_human_approval")
send_slack_notification(
f"⚠️ 需要审批: 创建付款链接 ${params['amount']}"
)
return # 中断循环,等待 webhook 回调
else:
# 小额直接执行
result = stripe.create_payment_link(**params)
thread.events.append({"type": "tool_result", "result": result})
elif next_step.function == "contact_human":
# Agent 主动请求人工帮助
thread.events.append({
"type": "human_clarification",
"question": next_step.arguments["question"]
})
thread.pause("waiting_clarification")
returnFactor 8:拥有你的控制流(Own Your Control Flow)
这是 12-Factor Agents 中最具争议也最重要的一条原则。作者 Dex 通过调研上百个 SaaS 团队发现:
大多数在客户面前运行的"AI Agent"产品,其实大部分代码是确定性的,只是在关键位置点缀了 LLM 步骤。

控制流对比
完全依赖框架的问题:
| 问题 | 描述 |
|---|---|
| 黑盒执行 | 无法在工具调用之间插入自定义逻辑 |
| 无法暂停 | 不能在关键操作前请求人工审批 |
| 调试困难 | 出错时难以定位是哪一步出了问题 |
| 框架锁定 | 更换框架意味着重写所有逻辑 |
推荐做法: 自己编写控制流循环,将 LLM 当作循环中的一个组件,而不是整个循环的管理者。
java
/**
* Factor 8: 自定义控制流引擎
* JDK 21+,使用 Switch Pattern Matching
*/
public class ControlFlowEngine {
private final Database db;
private final LLMClient llm;
private final ToolRegistry tools;
public ControlFlowEngine(Database db, LLMClient llm, ToolRegistry tools) {
this.db = db;
this.llm = llm;
this.tools = tools;
}
/**
* 处理下一步决策,根据不同意图类型执行不同流程
*/
public void handleNextStep(ThreadState thread) {
while (thread.status().equals("running")) {
var nextStep = llm.determineNextStep(threadToPrompt(thread));
// 使用 JDK 21 的模式匹配 switch
switch (nextStep.intent()) {
case "request_clarification" -> {
// 需要用户澄清 -> 暂停,等待人工回复
var updated = thread.appendEvent(
Event.HumanClarificationEvent.of(nextStep.data())
);
sendToHuman(nextStep.data());
db.saveThread(updated.pause("clarification"));
return; // 中断循环
}
case "fetch_data" -> {
// 同步工具调用 -> 执行后继续
var result = tools.execute(nextStep.toolName(), nextStep.args());
var updated = thread.appendEvent(
Event.ToolResultEvent.of(nextStep.toolName(), result)
);
db.saveThread(updated);
// continue -> 继续循环
}
case "deploy_service" -> {
// 高风险操作 -> 需要审批
var updated = thread.appendEvent(
Event.HumanApprovalEvent.of(nextStep.data())
);
requestApproval(nextStep.data());
db.saveThread(updated.pause("approval"));
return;
}
default -> {
// 未知意图 -> 记录错误并压缩
var updated = thread.appendEvent(
Event.ErrorMessageEvent.of("Unknown intent: " + nextStep.intent())
);
db.saveThread(updated);
compactErrors(updated);
}
}
}
}
}Factor 9:将错误压缩到上下文窗口(Compact Errors into Context Window)
当 Agent 出错时,简单的重试只会浪费 token 并可能重复同样的错误。正确的做法是:
- 捕获错误
- 将错误信息压缩为简短的提示
- 将压缩后的错误追加到上下文
- 让 LLM 基于新的上下文重新决策
python
"""
Factor 9: 错误压缩策略
"""
def compact_errors(thread: AgentThread, max_error_tokens: int = 200):
"""
将最近的错误压缩为简短摘要,避免上下文被冗长的错误堆栈淹没
"""
recent_errors = [
e for e in thread.events[-10:]
if e.get("type") == "error"
]
if len(recent_errors) >= 3:
# 连续 3 次错误 -> 生成压缩摘要
error_summary = (
f"最近 {len(recent_errors)} 次调用失败。"
f"错误类型: {[e.get('error_type') for e in recent_errors]}。"
f"请尝试不同的方法。"
)
# 清除旧错误,替换为摘要
thread.events = [
e for e in thread.events if e.get("type") != "error"
] + [{"type": "error_summary", "content": error_summary}]Factor 10:小型、专注的 Agent(Small, Focused Agents)
不要构建一个什么都能做的巨型 Agent。相反,构建多个小型、专注的 Agent,每个只负责一个明确的职责:
| Agent | 职责 | 工具 |
|---|---|---|
| ResearchAgent | 信息检索和整理 | 搜索、网页抓取 |
| CodeAgent | 代码生成和审查 | 文件读写、lint |
| DeployAgent | 部署和运维 | CI/CD API、SSH |
| ApprovalAgent | 人工审批路由 | Slack、邮件 |
这种设计带来的好处:
- 每个 Agent 的 prompt 更短更精准
- 错误范围被隔离
- 可以独立测试和部署
- 更容易理解和调试
Factor 11:从任何地方触发,在用户所在处交付(Trigger from Anywhere)
Agent 的触发源不应该是单一的 Web UI。它应该能响应:
- Webhook:GitHub push、CI 构建完成
- 定时任务:每天早上的数据汇总
- API 调用:其他服务的直接调用
- 聊天消息:Slack、微信、钉钉的消息
python
"""
Factor 11: 多触发源统一入口
"""
from fastapi import FastAPI, Request
import json
app = FastAPI()
@app.post("/webhook/github")
async def github_webhook(request: Request):
"""GitHub Webhook 触发 Agent"""
payload = await request.json()
event = {"source": "github", "data": payload}
thread = AgentThread(thread_id=generate_id())
thread.start(event)
thread.resume_with_webhook(payload)
return {"thread_id": thread.thread_id}
@app.post("/webhook/cron")
async def cron_trigger(request: Request):
"""定时任务触发 Agent"""
payload = await request.json()
event = {"source": "cron", "schedule": payload.get("schedule")}
thread = AgentThread(thread_id=generate_id())
thread.start(event)
return {"thread_id": thread.thread_id}
@app.post("/chat/message")
async def chat_message(request: Request):
"""聊天消息触发 Agent"""
payload = await request.json()
event = {"source": "chat", "message": payload.get("message")}
thread = AgentThread(thread_id=generate_id())
thread.start(event)
return {"thread_id": thread.thread_id}Factor 12:让你的 Agent 成为无状态 Reducer(Stateless Reducer)
这是函数式编程思想在 Agent 领域的应用:Agent 本身不保存状态,所有状态都来自持久化存储。
新事件 + 持久化的线程状态 -> Agent 处理 -> 新状态写入存储这样做的好处:
- 进程崩溃后可以完全恢复
- 多个实例可以并行处理不同的线程
- 部署和升级不影响正在运行的任务
- 符合云原生无状态部署的最佳实践
python
"""
Factor 12: 无状态 Reducer 模式
"""
def agent_reducer(state: ThreadState, event: dict) -> ThreadState:
"""
纯函数:给定当前状态和新事件,返回新状态
不依赖任何外部可变状态
"""
if event["type"] == "start":
return ThreadState(
thread_id=generate_id(),
status="running",
events=[event]
)
elif event["type"] == "tool_result":
new_events = state.events + [event]
# 检查是否需要暂停
if requires_approval(event):
return ThreadState(
thread_id=state.thread_id,
status="paused",
events=new_events,
pause_reason="approval_needed"
)
return ThreadState(
thread_id=state.thread_id,
status="running",
events=new_events
)
elif event["type"] == "human_approval":
if event["approved"]:
return ThreadState(
thread_id=state.thread_id,
status="running",
events=state.events + [event]
)
else:
return ThreadState(
thread_id=state.thread_id,
status="completed",
events=state.events + [event],
final_answer="操作已被拒绝"
)
return state三、架构总览:生产级 Agent 系统
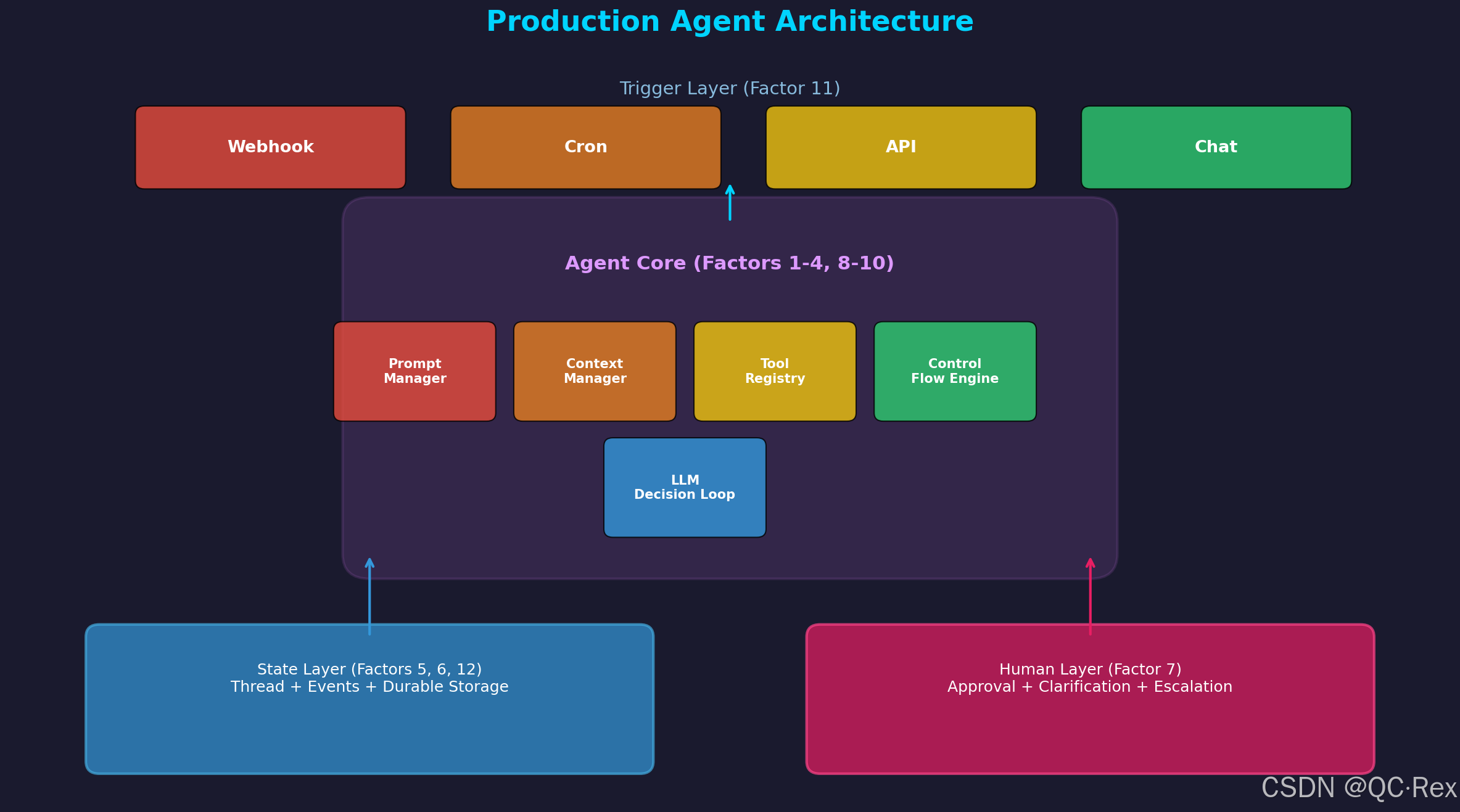
生产级 Agent 架构
上图展示了一个完整的 12-Factor Agent 系统架构,分为三层:
触发层(顶部):Webhook、定时任务、API、聊天消息------任何来源都可以作为 Agent 的输入(Factor 11)。
Agent 核心层(中间):
- Prompt Manager:版本化的提示词管理(Factor 2)
- Context Manager:上下文窗口的压缩和检索(Factor 3)
- Tool Registry:结构化的工具定义和执行(Factors 1, 4)
- Control Flow Engine:自定义的控制流循环(Factor 8)
- LLM Decision Loop:核心决策引擎(Factors 1, 9, 10)
状态层 + 人工层(底部):
- State Layer:持久化的线程和事件存储(Factors 5, 6, 12)
- Human Layer:审批、澄清和升级机制(Factor 7)
四、与传统开发方式的对比
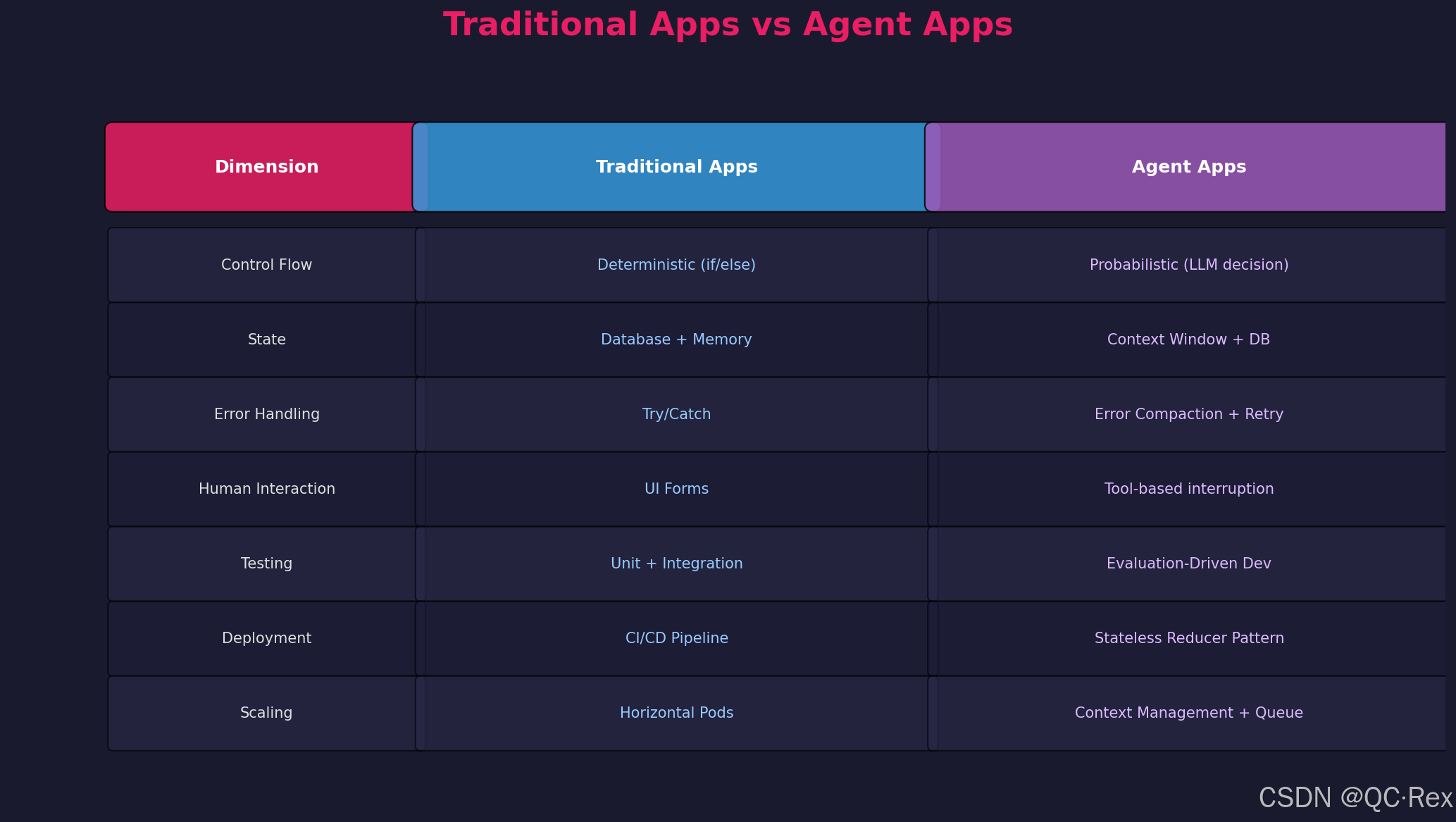
传统应用 vs Agent 应用
| 维度 | 传统应用 | Agent 应用 |
|---|---|---|
| 控制流 | 确定性(if/else) | 概率性(LLM 决策) |
| 状态管理 | 数据库 + 内存 | 上下文窗口 + 数据库 |
| 错误处理 | Try/Catch | 错误压缩 + 重试 |
| 人工交互 | UI 表单 | 工具级中断 |
| 测试方法 | 单元 + 集成测试 | 评估驱动开发(EDD) |
| 部署模式 | CI/CD 流水线 | 无状态 Reducer 模式 |
| 扩展方式 | 水平 Pod 扩展 | 上下文管理 + 队列 |
OSCHINA 近期报道的 Litefuse 平台(Agent 可观测与评估平台)提出的 EDD(Evaluation Driven Development)方法论,与 12-Factor Agents 的理念高度一致------Agent 的质量不是通过单元测试保证的,而是通过评估驱动的持续优化来实现的。
同时,Linux 内核维护者 Greg Kroah-Hartman 开始使用 AI 模糊测试工具挖掘内核漏洞(项目代号 gkh_clanker),以及 DeepMind 前工程师关于"LLM 评估体系将失效"的警告,都说明了一个趋势:AI 系统需要全新的工程和评估方法论,传统软件开发实践需要被重新思考和适配。
五、实践建议:如何在现有项目中引入 12-Factor 原则
你不需要从头重写整个系统。12-Factor Agents 的设计哲学是渐进式采纳:
第一阶段:从 Factor 1 + 4 开始
在现有应用中引入自然语言到结构化输出的能力。这是 ROI 最高的第一步------用户用自然语言交互,你的代码用结构化数据执行。
第二阶段:加入 Factor 2 + 3
将提示词外部化、版本化,并实现基础的上下文窗口管理。这一步让 Agent 的行为变得可控和可迭代。
第三阶段:实现 Factor 5 + 6 + 8
引入事件持久化和自定义控制流。这一步让 Agent 从"能跑"变成"能用于生产"。
第四阶段:完善 Factor 7 + 9 + 10 + 12
加入人工审批、错误压缩、小 Agent 拆分和无状态部署。这一步让 Agent 系统达到企业级标准。
六、总结
12-Factor Agents 不是又一个 AI 框架,而是一套工程原则的集合。它告诉我们:
- LLM 是组件,不是架构------将 LLM 嵌入到你自己的控制流中,而不是把整个架构交给框架
- 确定性 + 概率性 = 可靠系统------关键路径用确定性代码,灵活路径用 LLM
- 状态必须持久化------Agent 本身应该是无状态的 Reducer
- 人应该被显式地纳入流程------通过工具调用联系人,而不是让 Agent 自作主张
- 渐进式采纳胜过革命式重写------从现有代码中逐步引入 Agent 能力
正如项目作者 Dex 所说:"即使 LLM 继续变得更强大,仍然有一些核心工程技巧会让 LLM 驱动的软件更可靠、更可扩展、更易维护。"
在 2026 年的今天,AI Agent 正在从"好玩的技术演示"变成"客户面前的核心功能"。12-Factor Agents 提供了一份从 Demo 到生产的路线图------它不完美,也不完整,但它代表了一个方向:用软件工程的严谨态度来构建 AI 驱动的软件。
版权声明 :本文内容为原创,基于 GitHub 开源项目 humanlayer/12-factor-agents 和 HKUDS/CLI-Anything 的公开资料独立撰写。文中示例代码可自由使用于学习和个人项目。转载或引用请注明出处。