把 Agent 从能跑到可靠,关键不在模型神准,而在状态、上下文和协作工程。 原文链接 :AI 小老六
聊 Agent 时,很多讨论容易落到模型能力上:模型会不会推理,代码写得准不准,能不能理解复杂需求。这些当然重要,但真正把 Agent 做到可用以后,会发现麻烦往往不在"想不明白",而在"执行过程中会散"。
模型可以给出不错的判断,却不会天然知道自己刚才读过哪些文件;它可以规划十步任务,却可能在第五步被一段日志带跑;它能调用工具,但每一次工具返回的内容都会塞进上下文,越做越重。再往后,如果要让多个 Agent 一起做事,还会冒出通信、审批、退出、状态同步这些更琐碎的问题。
所以我更愿意把 Agent 看成一个状态工程问题。模型负责判断,系统负责让判断落地,并且让落地过程可追踪、可恢复、可约束。
下面不是按功能清单罗列,而是按一个 Agent 从"能跑起来"到"能长期干活"的过程,把几个关键设计放在一起讲。  图:可靠 Agent 的核心不是单次推理,而是可追踪、可恢复的状态工程。
图:可靠 Agent 的核心不是单次推理,而是可追踪、可恢复的状态工程。
Tool-Calling Runtime:把推理闭环接入真实执行环境
最原始的模型只是一个文本系统。你把代码贴进去,它能分析;你把日志贴进去,它能猜根因。但它不会自己打开 src/auth.js,不会自己跑 npm test,也不会知道当前目录下到底有什么。
Agent Loop 解决的是这个入口问题:模型决定要不要调用工具,Harness 执行工具,再把结果交回给模型。这个循环一直持续到模型不再请求工具。
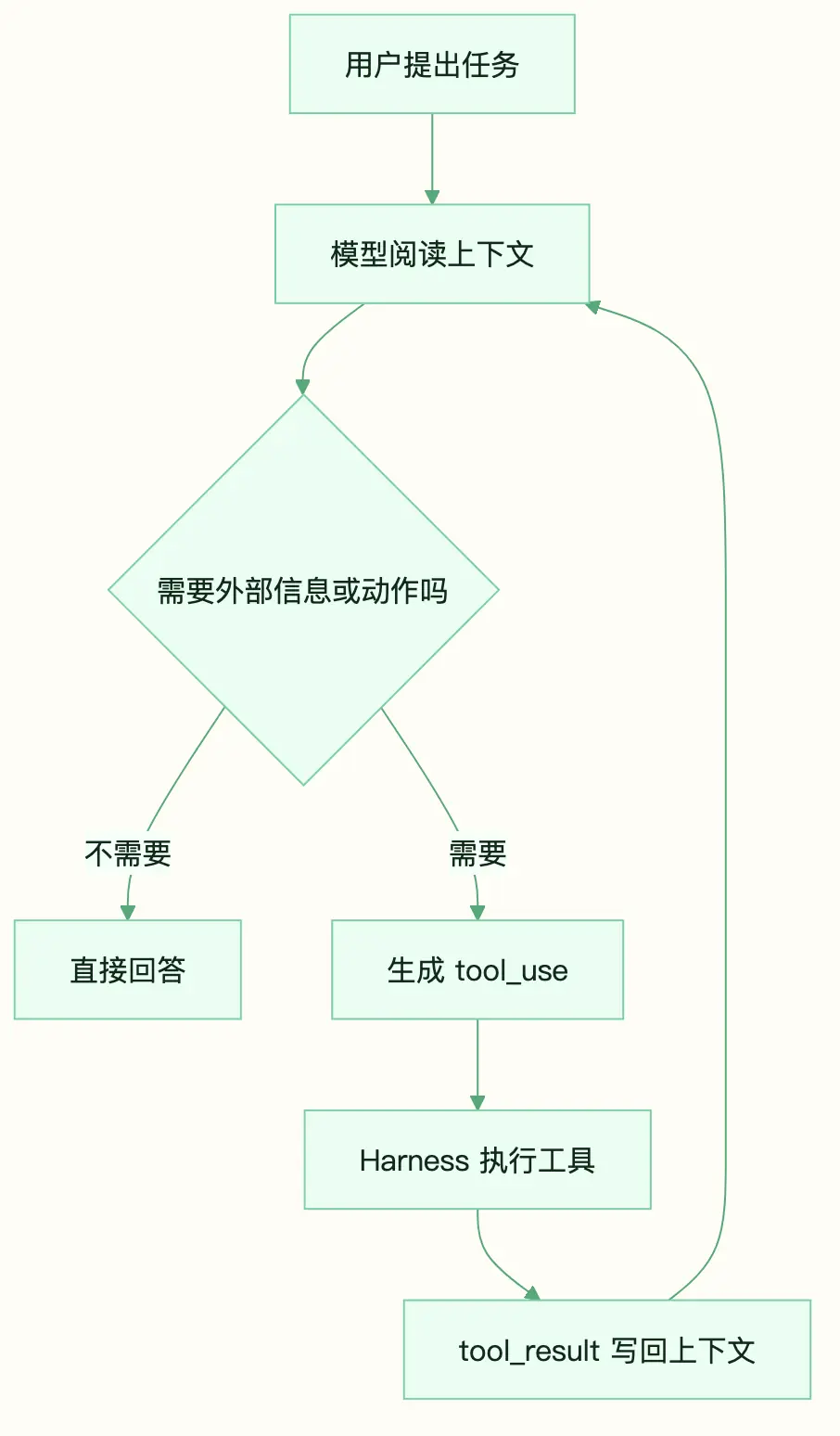
图:Agent Loop 将模型判断、工具执行和结果回写串成闭环
一个极简实现大概长这样:
python
messages = [{"role": "user", "content": query}]
while True:
response = client.messages.create(
model=MODEL,
system=SYSTEM,
messages=messages,
tools=TOOLS,
max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return response.content
results = []
for block in response.content:
if block.type != "tool_use":
continue
output = run_tool(name=block.name, input=block.input)
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})这里有个分工很重要:模型只做选择,Harness 负责执行。工具层必须有自己的安全边界,不能指望模型每次都谨慎。
比如一个 Bash 工具,至少要拦掉明显危险的命令,限制路径逃逸,避免 shell=True 带来的注入风险。
python
import os
import subprocess
def run_bash_simple_secure(command: str) -> str:
dangerous = ["rm", "sudo", "shutdown", "reboot", ">", "|", "&", ";"]
if any(part in dangerous for part in command.split()):
return "Error: dangerous command blocked."
if "../" in command or command.startswith("/"):
return "Error: path must stay inside workspace."
try:
args = command.split()
result = subprocess.run(
args,
cwd=os.getcwd(),
capture_output=True,
text=True,
timeout=10,
shell=False,
)
text = (result.stdout + result.stderr).strip()
return text[:50000] if text else "(no output)"
except FileNotFoundError:
return f"Error: command '{args[0]}' not found."
except Exception as e:
return f"Error: {e}"工具也别做成一个大杂烩。读文件、写文件、编辑文件、跑命令,最好各管各的。Loop 里只需要一个分发表,把模型说出的工具名映射到真实处理函数。
python
TOOL_HANDLERS = {
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
}到这一步,Agent 算是有了眼睛和手。但能动手不代表能把长任务做稳。
Progress Externalization:用外部状态锁住长任务进度
短任务里,模型的表现通常不错。让它读一个文件、解释一个报错、改一个小函数,来回几轮就能收尾。
麻烦出现在多步任务里。比如一次重构要做十件事:先读模块,再设计接口,再改实现,再补测试,再跑验证。前几步通常没问题,后面就开始漂。它可能重复读已经读过的文件,也可能跳过前置设计,直接改代码;更常见的是被某个局部问题吸住,忘了用户真正要的是什么。
这不是"模型笨",而是任务状态只放在上下文里太脆弱。上下文会被日志、代码、报错和解释不断稀释。
TodoManager 的作用很朴素:把进度写到外面。不要让模型靠记忆维护计划。
| 设计点 | 为什么需要 |
|---|---|
pending / in_progress / completed |
让任务进度显式化 |
同一时间只允许一个 in_progress |
避免模型同时推进多件互相冲突的事 |
| 最多 20 个任务 | 防止拆任务本身变成噪声 |
| 可渲染文本 | 让模型每次都能快速读懂当前局面 |
一个简化版实现如下:
python
from typing import Dict, List
class TodoManager:
MAX_ITEMS = 20
VALID_STATUSES = ("pending", "in_progress", "completed")
MARKERS = {
"pending": "[ ]",
"in_progress": "[>]",
"completed": "[x]",
}
def __init__(self) -> None:
self.items: List[Dict[str, str]] = []
def update(self, items: List[Dict[str, str]]) -> str:
if len(items) > self.MAX_ITEMS:
raise ValueError(f"Max {self.MAX_ITEMS} todos allowed")
in_progress = 0
checked: List[Dict[str, str]] = []
for i, item in enumerate(items):
text = str(item.get("text", "")).strip()
status = str(item.get("status", "pending")).lower()
item_id = str(item.get("id", i + 1))
if not text:
raise ValueError(f"Item {item_id}: text required")
if status not in self.VALID_STATUSES:
raise ValueError(f"Item {item_id}: invalid status '{status}'")
if status == "in_progress":
in_progress += 1
checked.append({"id": item_id, "text": text, "status": status})
if in_progress > 1:
raise ValueError("Only one task can be in_progress at a time")
self.items = checked
return self.render()
def render(self) -> str:
if not self.items:
return "No todos."
lines = []
for item in self.items:
lines.append(f"{self.MARKERS[item['status']]} #{item['id']}: {item['text']}")
done = sum(1 for item in self.items if item["status"] == "completed")
lines.append(f"\n({done}/{len(self.items)} completed)")
return "\n".join(lines)光有 todo 还不够。模型有时会连续几轮不看清单。Nag Reminder 就是一个轻量提醒器:如果模型太久没碰 todo,就在下一次工具结果里塞一行提醒。
它不强行改模型动作,只是把注意力拽回来一下。
python
NAG_THRESHOLD = 3
NAG_TEXT = "<reminder>Update your todos.</reminder>"
TODO_TOOL = "todo"
def agent_loop(messages):
rounds_since_todo = 0
while True:
response = client.messages.create(
model=MODEL,
system=SYSTEM,
messages=messages,
tools=TOOLS,
max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
tool_uses = [b for b in response.content if b.type == "tool_use"]
results = []
for block in tool_uses:
output = dispatch_tool(block.name, block.input)
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
used_todo = any(block.name == TODO_TOOL for block in tool_uses)
rounds_since_todo = 0 if used_todo else rounds_since_todo + 1
if rounds_since_todo >= NAG_THRESHOLD:
results.append({"type": "text", "text": NAG_TEXT})
rounds_since_todo = 0
messages.append({"role": "user", "content": results})DAG Task System:从待办清单升级到依赖调度
TodoManager 解决的是"别忘事"。但复杂工程不只是很多事项并列放着,它们之间有先后关系。
接口没定,调用方就不该改;数据结构没定,存储层就不该写死;基础能力没完成,集成测试跑了也只是浪费时间。扁平清单没法表达这些约束。
这时任务系统要从 list 变成 DAG。
图:复杂工程任务从扁平清单升级为依赖图
一种直接的做法是把每个任务存成独立 JSON 文件,放在 .tasks/ 目录里。
.tasks/
├── task_1.json
├── task_2.json
└── task_3.json任务字段不用复杂,但要足够表达依赖。
| 字段 | 含义 |
|---|---|
id |
任务唯一标识 |
title |
任务标题 |
description |
更完整的任务说明 |
status |
pending / in_progress / completed |
blockedBy |
当前任务依赖哪些前置任务 |
createdAt |
创建时间 |
completedAt |
完成时间 |
Agent 每次只需要回答三个问题。
| 问题 | 判断方式 |
|---|---|
| 现在能做什么 | status=pending |
且 blockedBy=[] |
|
| 什么还不能做 | blockedBy |
| 非空 | |
| 完成后影响谁 | 找出依赖当前任务的后续任务 |
任务完成时,系统把它的 ID 从其他任务的 blockedBy 里删掉。如果某个任务的 blockedBy 变成空数组,它就解锁了。
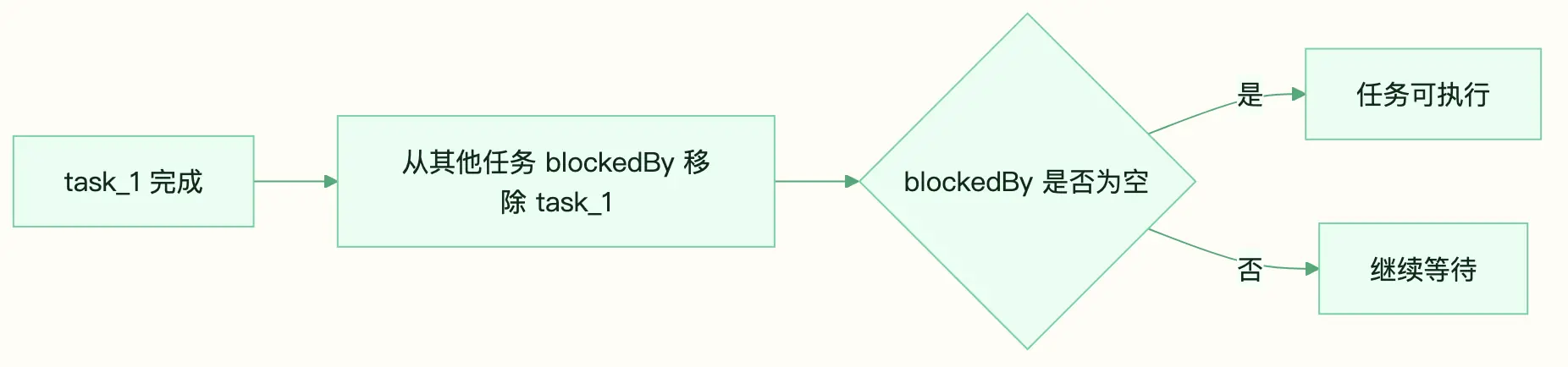
图:前置任务完成后,系统自动释放可执行任务
这个变化不显眼,但很关键。它把"模型凭感觉挑下一步",改成了"系统告诉模型哪些步骤已经具备前置条件"。
Context Compaction:控制 Token 膨胀和信息半衰期

图:把长历史压缩成摘要,让主上下文只保留当前真正需要的信息。
Agent Loop 有个副作用:工具结果会持续进入上下文。读文件、跑命令、查日志、搜索代码,每一次都可能带来几千 tokens。几轮下来,主上下文很快就变成垃圾堆。
这时会出现两个问题。第一,模型注意力被旧信息稀释;第二,真正有用的远端信息可能被截断或召回不到。
粗略看一次工程任务的上下文消耗:
| 操作 | 数量 | 估算消耗 |
|---|---|---|
| 读取源码文件 | 30 个 | 约 60,000 tokens |
| 执行 Shell 命令 | 20 条 | 约 30,000 tokens |
| 工具调用往返 | 15 次 | 约 20,000 tokens |
| 模型输出 | 多轮持续生成 | 约 15,000 tokens |
这就是为什么需要 compact。压缩不是删除历史,而是把历史从"模型当前必须看见的内容"里移出去。
| 层次 | 做什么 | 类比 |
|---|---|---|
micro_compact |
把几轮前的工具结果换成占位符 | 页面置换 |
auto_compact |
上下文超阈值后,保存全文并摘要替换 | Swap |
compact |
||
| 工具 | 模型主动触发压缩 | 手动 GC |
micro_compact 最简单。超过 3 轮的旧工具结果,保留调用痕迹,删掉大块输出。
csharp
[Previous: used read_file]
[Previous: used bash]压缩收益很大:一次 2000 tokens 的文件读取结果,可能只剩十来个 tokens。模型仍知道自己"读过文件",但不会每轮都背着全文走。
auto_compact 再激进一点。上下文超阈值时,系统先把完整 transcript 写入磁盘,再让模型生成任务摘要,用摘要替代活跃历史。
yaml
.transcripts/
├── 2026-05-14_task-refactor-auth-module.md
├── 2026-05-14_task-fix-api-endpoint.md
└── 2026-05-13_task-setup-ci-pipeline.md摘要应该保留用户目标、关键决策、当前状态和剩余事项。日志全文、试错过程、已经过期的文件内容,都不该继续占着窗口。
还有一种情况适合让模型自己调用 compact:任务进入新阶段,或者它预判接下来要读很多文件。这时主动清理,比等系统阈值触发更稳。
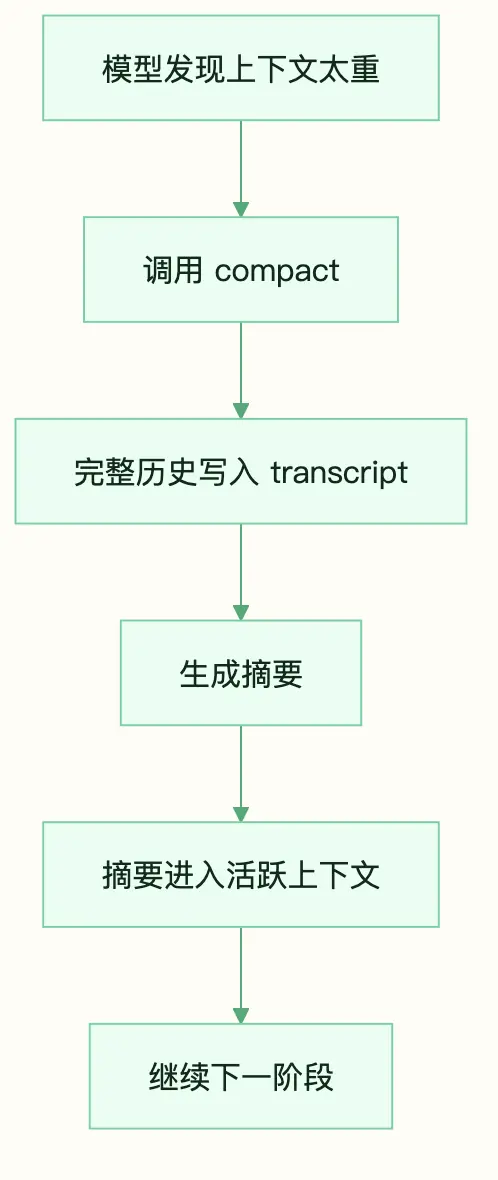
图:compact 将完整历史归档,并把摘要留在活跃上下文
Subagent Isolation:隔离高噪声探索链路
并不是所有工作都适合主 Agent 亲自做。比如排查一个测试失败,可能要读很多文件、跑很多命令、试几个假设。主流程真正需要的是最后的结论:问题在哪,证据是什么,建议怎么修。
Subagent 就是为这种场景准备的。它拿到一个子任务,在独立上下文里完成探索,然后只把结论交还给主 Agent。中间那些日志、搜索结果、错误尝试,不进入主上下文。

图:子 Agent 在独立上下文中探索,只把结论交还主流程
实现上有几个约束值得保留:子 Agent 不继承主对话;子 Agent 没有再派生子 Agent 的工具;最多运行固定轮次;返回值只取最终文本。
python
CHILD_TOOLS = [bash, read_file, write_file, edit_file]
PARENT_TOOLS = CHILD_TOOLS + [task]
def run_subagent(prompt: str) -> str:
sub_messages = [{"role": "user", "content": prompt}]
for _ in range(30):
response = client.messages.create(
model=MODEL,
system=SUBAGENT_SYSTEM,
messages=sub_messages,
tools=CHILD_TOOLS,
max_tokens=8000,
)
sub_messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
break
results = []
for block in response.content:
if block.type != "tool_use":
continue
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"unknown tool: {block.name}"
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(output)[:50000],
})
sub_messages.append({"role": "user", "content": results})
return "".join(
block.text for block in response.content if hasattr(block, "text")
) or "(no summary)"这个设计不是为了"多一个智能体显得高级",只是为了保护主上下文。主 Agent 像负责人,子 Agent 像临时调查员。负责人不需要看完整侦查录像,只需要拿到结论和证据。
Skill Injection:让领域工作流按需进入上下文
Agent 往往要遵守很多工作流:Git 提交规范、单测规范、Code Review 清单、接口设计约定、文档写作模板。把这些都写进系统提示,看起来省事,实际很浪费。
假设一个 Skill 完整内容约 2000 tokens,10 个 Skill 全量注入就是 20000 tokens。而一次任务通常只会用到 1 到 2 个。
更好的方式是两层加载。
第一层只放索引,让模型知道有哪些 Skill。
yaml
Available Skills:
- git-conventions: Git 提交和分支命名规范
- test-patterns: 单元测试编写规范与最佳实践
- code-review: 代码审查清单与安全检查项
- api-design: RESTful API 设计规范
- docs-writing: 技术文档写作模板第二层按需加载完整内容。
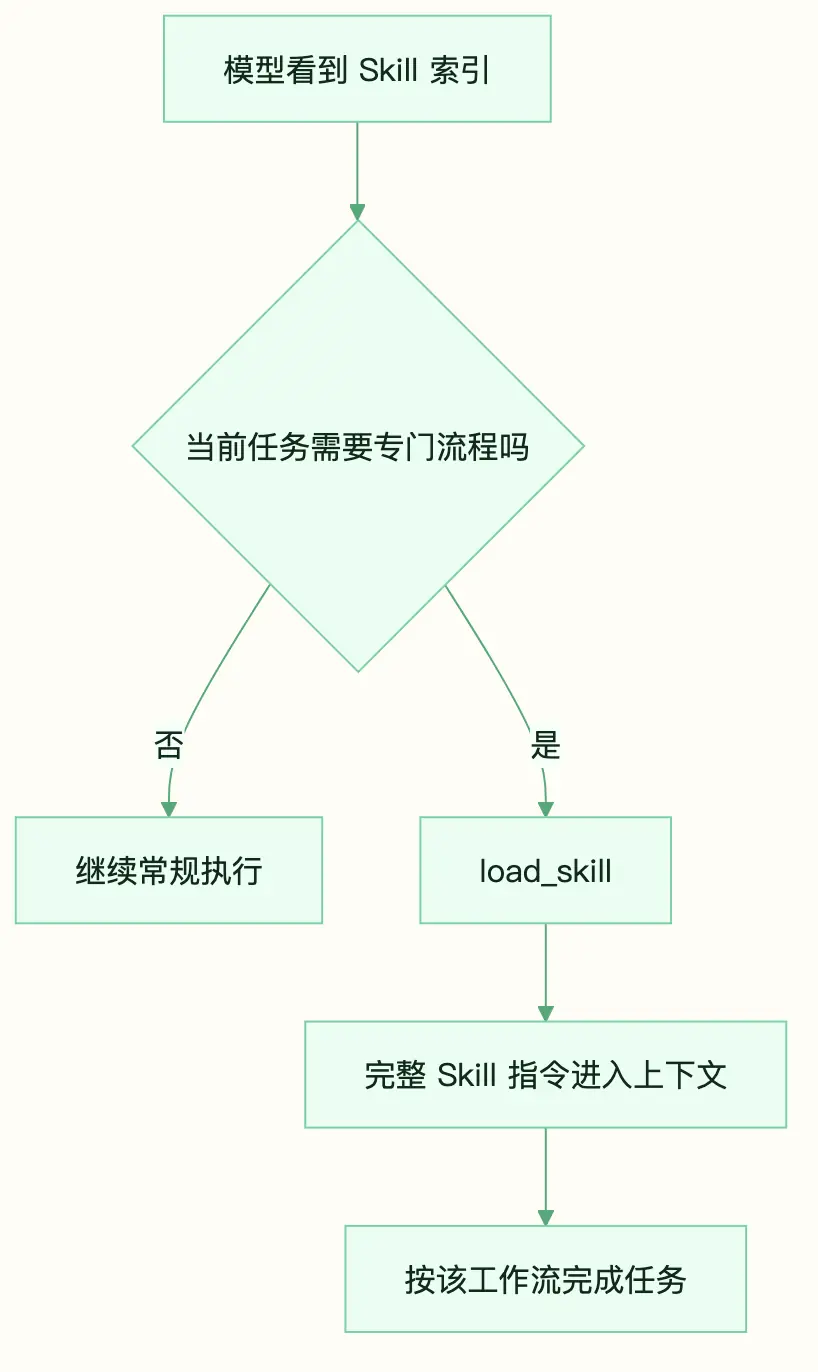
图:常驻索引与按需加载正文的两层 Skill 机制
这和工具类似:索引常驻,正文临时进入。上下文里只放当前有用的东西。
Background Execution:把阻塞式工具调用改成异步任务
很多命令本身不需要模型参与。npm install 是下载依赖,pytest 是跑测试,docker build 是按 Dockerfile 构建镜像。它们可能跑很久,但中间不需要 Agent 做判断。
| 命令 | 典型耗时 | 主要工作 |
|---|---|---|
npm install |
30-120 秒 | 下载和安装依赖 |
pytest |
60-300 秒 | 执行测试套件 |
docker build |
60-600 秒 | 构建镜像层 |
如果 Agent Loop 阻塞等待,模型的推理时间就被浪费了。后台任务管理器的做法是:慢命令交给子进程跑,Agent 立刻继续做别的事;命令结束后,结果进入队列,在下一次合适的调用边界注入。
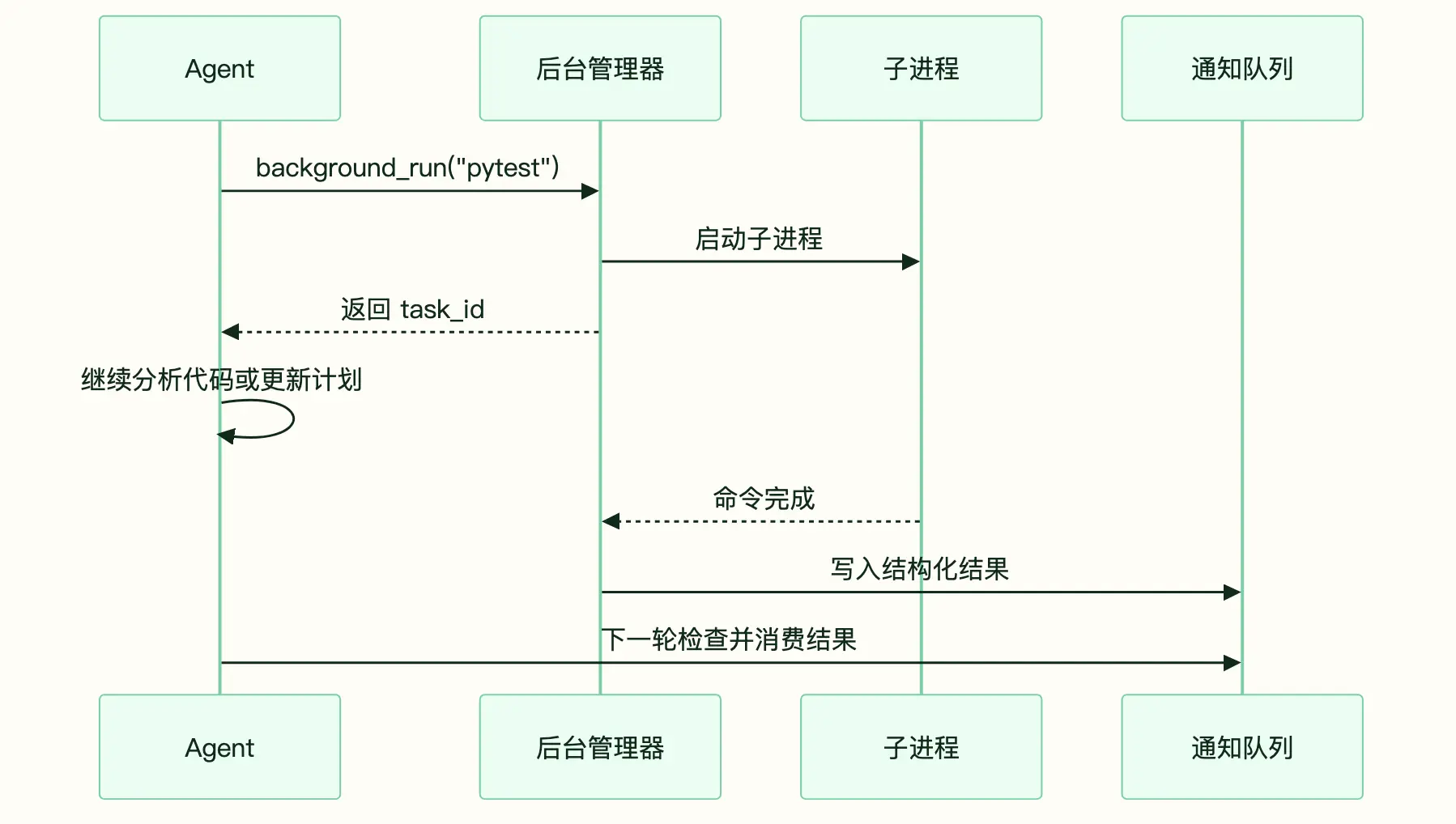
图:慢命令进入后台执行,结果通过队列回到主循环
组件其实很少。
| 组件 | 作用 |
|---|---|
| Agent 主循环 | 保持推理串行,避免并发推理混乱 |
| 守护线程或进程 | 盯着子进程结束 |
| 子进程 | 真正执行慢命令 |
| 通知队列 | 让执行和消费解耦 |
这个机制让 Agent 不必把时间花在"等"上。它可以一边跑测试,一边读下一组文件,或者把已经确定的代码先写掉。
Persistent Agent Teams:从临时子任务到稳定协作单元

图:稳定身份、消息通道和审批协议,让多个 Agent 像团队一样协同。
Subagent 适合临时探索,但它不是团队。真正的大任务需要长期协作:前端、后端、测试、文档各自有角色;每个人有自己的上下文和工具;任务可以异步分发和交付。
这时需要两个东西:稳定身份和异步通信。
一种够简单的通信方式是 JSONL 邮箱。每个 Agent 有一个 inbox 文件,发消息就是追加一行 JSON,收消息就是读取并清空自己的 inbox。
.messages/
├── frontend-agent.inbox.jsonl
├── backend-agent.inbox.jsonl
└── test-agent.inbox.jsonl消息格式保持结构化。
json
{"from": "leader", "to": "frontend-agent", "timestamp": "2026-05-14T10:00:00Z", "type": "task", "content": "请实现登录页面的表单验证"}
{"from": "backend-agent", "to": "frontend-agent", "timestamp": "2026-05-14T10:05:00Z", "type": "info", "content": "API 接口已就绪,端点是 POST /api/login,参数为 {email, password}"}JSONL 不花哨,但在这个场景里很合适。消息频率不高,文件足够快;内容可读,方便审计;进程挂了,消息也还在磁盘上。
| 方案 | 好处 | 问题 |
|---|---|---|
| 数据库 | 有事务 | 太重,要维护 schema |
| 内存共享 | 快 | 进程崩溃就丢 |
| JSONL 文件 | 简单、持久、人能看 | 性能不是最优 |
团队成员由 TeammateManager 管。它维护一个 config.json,记录每个成员的角色、技能和系统提示。
json
{
"teammates": [
{
"name": "frontend-agent",
"role": "前端开发",
"skills": ["react", "typescript", "css"],
"system_prompt": "你是一个专注于前端开发的工程师..."
},
{
"name": "backend-agent",
"role": "后端开发",
"skills": ["python", "fastapi", "postgresql"],
"system_prompt": "你是一个专注于后端开发的工程师..."
},
{
"name": "test-agent",
"role": "质量保障",
"skills": ["pytest", "e2e-testing", "ci-cd"],
"system_prompt": "你是一个专注于测试的 QA 工程师..."
}
]
}spawn() 一个队友后,它有自己的上下文窗口、工具集和执行循环。主 Agent 不需要盯着它每一步,只要通过消息收发任务和结果。
Team Protocols:用请求-响应协议约束多 Agent 协作
多 Agent 之间能发消息以后,很快会遇到新的问题。
比如领导 Agent 想停掉一个队友,如果直接杀线程,可能文件写到一半、数据库连接没关、任务状态没更新。再比如某个队友想删除旧认证模块重写,这种高风险动作不应该没有确认就执行。还有消息格式,如果一会儿自然语言、一会儿 JSON、一会儿只发个 ok,接收方也会浪费推理能力猜意思。
所以团队需要协议。
最小可用协议其实很简单:request-response 加一个三态状态机。A 发起请求,B 批准或拒绝。状态只有三个:pending、approved、rejected。
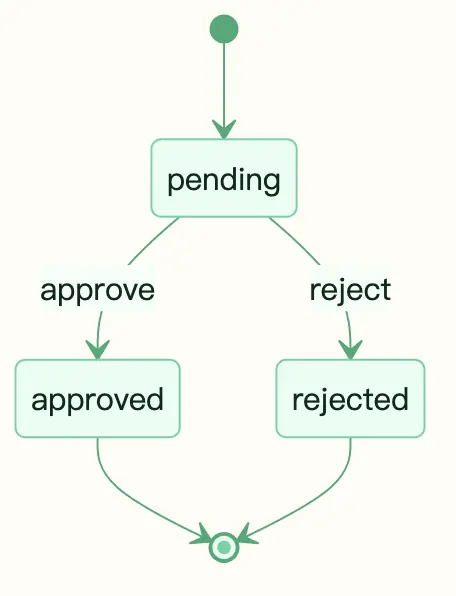
图:多 Agent 协作中的请求审批三态协议
它比 2PC、Raft、Pub/Sub 都轻得多,也更贴近 Agent 之间的真实交互。
| 协调方式 | 复杂度 | 适配度 |
|---|---|---|
| 两阶段提交 | 高,需要 prepare 和 commit | 对 Agent 协作太重 |
| Raft/Paxos | 极高,需要投票和日志复制 | 不是这个问题 |
| Pub/Sub | 中等,需要 topic 管理 | 一对一请求用不上广播 |
| Request-Response + 三态 FSM | 低,两条消息就够 | 适合请求和审批 |
后续要加新协议也不难。只要定义新的 request type,状态机可以复用。
python
"shutdown_request" # pending -> approved/rejected
"plan_request" # pending -> approved/rejected
"resource_request" # pending -> approved/rejected
"merge_request" # pending -> approved/rejected如果一次交互需要补充信息,再加一个 needs_info 状态即可。
css
[pending] -> [needs_info] -> [pending] -> [approved/rejected]工程化收束:可靠 Agent 本质上是状态系统
Agent 工程没有想象中那么玄。很多设计看起来像"智能体架构",拆开以后其实都是老问题:状态怎么存,任务怎么排,日志怎么处理,慢任务怎么异步,团队怎么通信,高风险动作怎么审批。
模型确实带来了新的执行方式,但工程上的账不会消失。你不把状态显式化,状态就会散在上下文里;你不压缩历史,历史就会拖慢每一轮推理;你不定义协议,多 Agent 协作就会变成一群模型互相发散。
能用的 Agent,不是因为模型每一步都神准,而是因为系统允许它犯小错、能把它拉回任务、能记录它做过什么,也能在必要时让它停下来等一个确认。