前言
b站文件上传,发现在上传过程中,在不断的向服务器发送请求,为什么?因为文件过大的话。要只发送一次请求,那么时间就会非常长,如果请求中发生问题,比如网络断开,就要重新上传,代价高,所以要对文件进行分片
上传文件比较大,会容易遇到一下问题:
- 上传时间久
- 中间一旦出错就需要重新上传
- 一般服务端会对文件的大小进行限制
体验不好,解决:分片上传
原理:
将一个比较大的文件分成一个一个的数据小块,每个小块大小相同,利用单文件上传,把小文件逐个传到服务器,上传的时候 ,可以同时上传多个小块,也可以一个一个的上传,上传每个小块后,服务器会保存这些小块,并记录他们的顺序和位置。
把所有小块上传完成后,在服务器会按照正确的顺序把全部小文件组装起来(后端完成组装),还原成完整的大文件,前端要做的核心:把文件进行分片
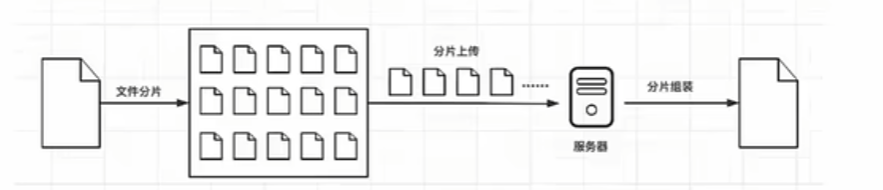
好处:
减少失败风险,如果在上传过程中遇到了问题,只需要重新上传出错的小片,而不需要重新上传完整的大文件。另外还可以提高上传速度
实现
1. 项目搭建
接下来创建一个demo项目
前端:vue3 + vite
初始化前端项目:
bash
npm create vite@latest client -- --template vue
cd client
npm install
//启动命令
npm run dev后端:express 框架,用到的工具包:multiparty、fs-extra、cors、body-parser、nodemon
初始化后端项目:
bash
mkdir server
cd server
npm init -y
npm install express multiparty fs-extra cors body-parser
npm install --save-dev nodemon完整项目目录
latex
fenpian/
├── client/ # 前端 Vue 项目
│ ├── src/
│ │ ├── components/ # 组件目录
│ │ ├── App.vue
│ │ └── main.js
│ ├── index.html
│ ├── vite.config.js
│ └── package.json
└── server/ # 后端 Express 项目
├── uploads/ # 上传文件存放目录(稍后创建)
├── app.js # 后端入口文件
└── package.json后端server/app.js基础代码
javascript
const express = require("express");
const cors = require("cors");
const bodyParser = require("body-parser");
const path = require("path");
const multiparty = require("multiparty");
const fse = require("fs-extra");
const app = express();
const PORT = 3000;
app.use(cors());
app.use(bodyParser.json());
// 路由入口
app.get('/', (req, res) => {
res.send('大文件分片上传服务器已启动');
});
app.listen(PORT, () => {
console.log(`服务器运行在 http://localhost:${PORT}`);
});
server/package.json
"scripts": {
"start": "node app.js",
"dev": "nodemon app.js"
}2. 读取文件
通过监听input的change事件,当选取了本地文件后,可以在回调函数中拿到对应的文件
typescript
<template>
<div>
<input @change="handleUpload" type="file"></input>
</div>
</template>
<script setup lang="ts">
const handleUpload = (e: Event) => {
// console.log((e.target as HTMLInputElement).files)//FileList 大括号包裹,但是有索引,像数组-->伪数组:可以通过下标获取每一项,但是没有数组的方法
const files=(e.target as HTMLInputElement).files
if(!files) return
console.log(files[0]);
}
</script>3. 文件如何进行分片?
核心:用Blob对象的slice方法 ,在上一步获取到选择的文件是一个File 对象,他继承于Blob ,所以可以用slice对文件进行分片
typescript
let blob=instanceOfBlob.slice([start [,end [,contentType]]])start和end代表Blob里的下标,表示被拷贝进新的Blob的字节的起始位置和结束位置,接下来用slice方法实现对文件的分片
javascript
const createChunks = (file: File) => {
let cur = 0; //看看文件分到哪里了
let chunks = [];
//还没有分完的话就会继续分
while (cur < file.size) {
const blob = file.slice(cur, cur + CHUNK_SIZE); //每一片
chunks.push(blob); //分出来的片放进数组里
cur += CHUNK_SIZE; //下一片开始位置,下标得移动
}
return chunks;
};
分片过程非常快,几乎是瞬间完成,原因:
File对象,Blob对象,它里面保存的只是文件的基本信息,size,type,name等,并没有保存文件的数据,要读数据,需要使用fileReader
网络中断后,客户端和服务端要发生一次对话
客户端问:这个文件还需要传递哪些分片?
服务端答:你还需要传递9-25范围内的分片
4. hash计算
思考:那么服务端怎么知道客户端指的是那个文件呢?
- 用文件名区分?不可以,因为文件名是可以随便修改的
- 用文件内容区分:要找到一个能唯一代表这个文件的东西:文件hash值,根据文件内容产生一个唯一的hash值,内容发生变化,hash值就会跟着变化,所以可以用这个方法来区分不同文件
hash:任何数据-->一个固定长度的字符串(这个转化叫做hash算法)常用算法:md5
通过这个方法,可以实现秒传的功能:
服务器在处理上传文件的请求时,先判断下对应文件的hash值有没有记录。如果A和B先后上传同一份内容相容的文件,所以这两份文件的hash值是一样的,当A上传的时候会根据文件内容分生成一个对应的hash值,然后在服务器上就会有一个对应的文件,B再上传的时候,服务器就会发现这个文件的hash值之前已经有记录了,说明和之前已经上传过相同内容的文件,所以就不用处理B的这个上传请求了,给用户的感觉就像是实现了秒传。
计算hash值:
第三方库:spark-md5,需要安装
bash
npm i spark-md5在上一步获取到了文件的所有切片,我们可以用这些切片来计算该文件的hash值,如果一个文件特别大,每个切片的所有内容都参与计算的话会很耗时,所以采取以下策略:
- 第一个和最后一个切片的内容全部参与计算
- 中间剩余的切片,我们分别在前面,后面和中间区2 个字节参与计算
这样既保证了所有切片都参与计算,也保证不耗费很长时间
javascript
const calculateHash = (chunks: Blob[]) => {
return new Promise((resolve) => {
//1. 第一个和最后一个切片全部参与计算
//2. 中间的切片只计算前面两个字节,中间两个字节,最后两个字节
const targets: Blob[] = []; //存储所有参与计算的切片
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
chunks.forEach((chunk, index) => {
if (index == 0 || index == chunks.length - 1) {
targets.push(chunk);
} else {
targets.push(chunk.slice(0, 2)); //前面两个字节
targets.push(chunk.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2)); //中间两个字节
targets.push(chunk.slice(CHUNK_SIZE - 2, CHUNK_SIZE)); //最后两个字节
}
});
fileReader.readAsArrayBuffer(new Blob(targets));
fileReader.onload = (e) => {
spark.append((e.target as FileReader).result as ArrayBuffer);
console.log("hash:"+spark.end());//文件的hash值
resolve(spark.end());
};
});
};
5. 文件上传
5.1. 前端实现
我们以1G的文件来分析,假如每个分片的大小为1M,那么总的分片数将会是1024个,如果我们同时发送这1024个分片,浏览器肯定处理不了,原因是切片文件过多,浏览器一次性创建了太多的请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。因此,我们有必要限制前端请求个数。
怎么做呢,我们要创建最大并发数的请求,比如6个,那么同一时刻我们就允许浏览器只发送6个请求,其中一个请求有了返回的结果后我们再发起一个新的请求,依此类推,直至所有的请求发送完毕。
上传文件时一般还要用到 FormData 对象,需要将我们要传递的文件还有额外信息放到这个 FormData 对象里面。
javascript
const uploadChunks = async (chunks: Blob[]) => {
//将对象数组转换成FormData对象
const formDatas = chunks.map((chunk, index) => {
const formData = new FormData();
formData.append("fileHash", fileHash.value);//文件hash
formData.append("chunkHash", fileHash.value + "-" + index);//切片文件的hash
formData.append("chunk", chunk);//切片文件
return formData;
});
// console.log(formDatas);
//最大并发请求数
const max = 6;
const sendRequest = async (formData: FormData) => {
try {
const res = await fetch("http://localhost:3000/upload", {
method: "POST",
body: formData,
});
const data = await res.json();
console.log(data);
} catch (err) {
console.log(err);
}
}
const promise: Promise<any>[] = [];
// for (let i = 0; i < formDatas.length; i++) {
// promise.push(sendRequest(formDatas[i]));
// //如果请求队列中的请求数达到最大并行请求数时,得等之前的请求完成再循环下一个
// if (promise.length === max || i === formDatas.length - 1) {
// await Promise.all(promise);
// promise.length = 0;
// }
// }
//上述写法有缺陷,使用Promise.all(),等待六个请求全部完成,再开始下一批,会有等待最慢请求的时间;应该使用Promise.race()
for (let i = 0; i < formDatas.length; i++) {
const task = sendRequest(formDatas[i]);
taskPool.push(task);
// 完成后自动移除自己
task.then(() => {
const idx = taskPool.indexOf(task);
if (idx > -1) taskPool.splice(idx, 1);
});
// 达到最大并发 → 任意一个完成,立刻补充新任务,不会等到,效率高
if (taskPool.length >= max) {
await Promise.race(taskPool);
}
}
// 等待所有剩余请求结束
await Promise.all(taskPool);
//通知服务器去合并分片
mergeRequest();
};5.2. 后端实现
javascript
const UPLOAD_DIR = path.resolve(__dirname, "uploads");
app.post("/upload", function (req, res) {
console.log("req:", req.body);
const form = new multiparty.Form();
form.parse(req, async function (err, fields, files) {
if (err) {
res.status(401).json({
ok: false,
message: "上传失败",
});
}
console.log("fields:", fields); //包含fileHash和chunkHash
console.log("files:", files); //是一个chunk数组,里面是一个对象
//临时存放目录
const fileHash = fields.fileHash[0];
const chunkHash = fields.chunkHash[0];
//存放切片的临时文件夹
const chunkPath = path.resolve(UPLOAD_DIR, fileHash);//这个方法返回的是一个绝对路径:UPLOAD_DIR/fileHash
//如果不存在这个文件夹,则创建
if (!fse.existsSync(chunkPath)) {
//创建文件夹是异步操作
await fse.mkdir(chunkPath);
console.log("创建文件夹成功:", chunkPath);
}
//这个是临时路径
const oldPath = files["chunk"][0]["path"];
//将切片放到文件夹里
//chunkHash是新的文件名,将临时文件移动到指定的chunkPath目录
//UPLOAD_DIR/fileHash/chunkHash
await fse.move(oldPath, path.resolve(chunkPath, chunkHash));
res.status(200).json({
ok: true,
message: "上传成功",
});
});
});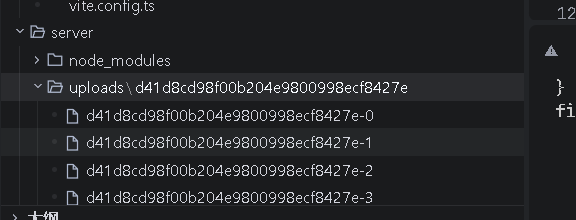
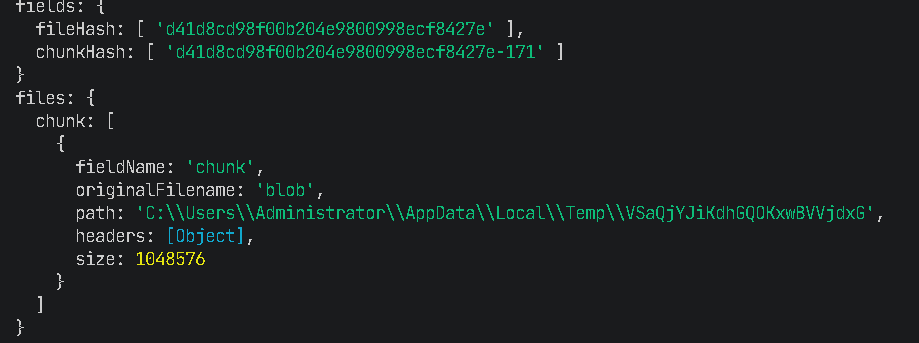
写到这里上传成功后会发现uploads下回出现一个以fileHash命名的文件夹,里面是chunkHash
6. 文件合并
将所有切片都上传到服务器后,需要将所有的切片合并成一个完整的文件
6.1. 前端实现
只需要向服务器发送一个合并的请求,为了区分要合并的文件,需要将文件的hash值传过去
javascript
const mergeRequest = () => {
fetch("http://localhost:3000/merge", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
fileHash: fileHash.value,
fileName: fileName.value,
size: CHUNK_SIZE,
}),
}).then((res) => {
console.log(res);
if (res.status === 200) {
alert("合并成功");
resetKey.value++; // 重置 input,允许再次选择相同文件
} else {
alert("合并失败");
}
});
};6.2. 后端实现
合并的时候需要从对应的文件中获取所有的切片,然后利用文件的读写操作,实现文件的合并,合并完成后,将生成的文件以filehash值+文件后缀命名存放到对应位置就可以了
javascript
// 提取文件后缀名
const extractExt = filename => {
return filename.slice(filename.lastIndexOf('.'), filename.length)
}
app.post("/merge", async function (req, res) {
const { fileHash, fileName, size } = req.body;
console.log("fileHash:", fileHash);
console.log("fileName:", fileName);
console.log("size:", size);
//如果文件已存在,就没必要合并了
const filePath = path.resolve(UPLOAD_DIR, fileHash + extractExt(fileName));
if (fse.existsSync(filePath)) {
return res.status(200).json({
ok: true,
message: "文件已合并",
});
}
//如果切片目录不存在,则无法合并切片,报异常
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
if (!fse.existsSync(chunkDir)) {
return res.status(401).json({
ok: false,
message: "合并失败,请重新上传",
});
}
//合并操作
const chunkPaths = await fse.readdir(chunkDir);//读取存放切片的目录,获取所有切片文件名。
console.log("chunkPaths:", chunkPaths);
//对每个切片进行排序,文件系统读取目录时,返回的文件顺序是不确定的!
chunkPaths.sort((a, b) => {
return a.split("-")[1] - b.split("-")[1];
});
const list = chunkPaths.map((chunkName, index) => {
return new Promise((resolve, reject) => {
const chunkPath = path.resolve(chunkDir, chunkName);//找到该切片
const readStream = fse.createReadStream(chunkPath);//读取切片
const writeStream = fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size,
});//写入目标文件,起始位置和结束位置,字节为单位
readStream.on("error", (err) => {
console.error("读取切片失败:", err);
reject(err);
});
writeStream.on("error", (err) => {
console.error("写入切片失败:", err);
reject(err);
});
writeStream.on("finish", async () => {
try {
await fse.unlink(chunkPath);// 删除已合并的切片
resolve(); // 标记该切片合并完成
} catch (err) {
console.error("删除切片失败:", err);
reject(err);
}
});
readStream.pipe(writeStream);//将读取流的数据直接管道传输到写入流,实现文件合并。
});
});
//等所有的合并请求完成
await Promise.all(list);
//删除临时存放的文件夹
await fse.remove(chunkDir);
res.status(200).json({
ok: true,
message: "合并成功",
});
});
7. 秒传
在上传之前可以加一个判断,如果有对应的这个文件,就不用再重复上传了,直接告诉用户上传成功,给用户的感觉就像是实现了秒传。
7.1. 前端实现
javascript
const verify = async () => {
const res = await fetch("http://localhost:3000/verify", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
fileHash: fileHash.value,
fileName: fileName.value,
}),
});
const data = await res.json();
console.log(data);
return data;// data中包含对应的表示服务器上有没有该文件的查询结果
};
const handleUpload = async (e: Event) => {
//...
//校验hash值,如果服务器有这个文件就不用重复上传,实现秒传功能
const data = await verify();
console.log(data);
if (!data.data.shouldUpload) {
alert("秒传成功");
resetKey.value++; // 重置 input,允许再次选择相同文件
return;
}
//服务器上不存在该文件,上传分片
uploadChunks(chunks,data.data.existChunks);
};7.2. 后端实现
合并文件成功后,文件名是以文件的hash值+文件后缀命名的,所以只需要看服务器上有没有对应的这个命名的那个文件就行了
javascript
app.post("/verify", async function (req, res) {
const { fileHash, fileName } = req.body;
console.log(fileHash, fileName);
const filePath = path.resolve(UPLOAD_DIR, fileHash + extractExt(fileName));
//如果存在,不用上传
if (fse.existsSync(filePath)) {
console.log("文件已存在");
return res.status(200).json({
ok: true,
data: {
shouldUpload: false,
},
});
}else{
//不存在,重新上传
console.log("文件不存在");
return res.status(200).json({
ok: true,
data: {
shouldUpload: true,
existChunks:chunkPaths
},
});
}
});8. 断点续传
对于网络中断需要重新上传的问题没有解决,那该如何解决呢?
如果我们之前已经上传了一部分分片了,我们只需要再上传之前拿到这部分分片,然后再过滤掉是不是就可以避免去重复上传这些分片了,也就是只需要上传那些上传失败的分片,所以,再上传之前还得加一个判断。
8.1. 前端实现
javascript
const uploadChunks = async (chunks: Blob[],existChunks:string[]) => {
//将对象数组转换成FormData对象
//把服务器上已经存在的切片过滤掉
console.log("已上传的切片",existChunks)
const formDatas = chunks.filter((index)=>!existChunks.includes(fileHash.value + "-" + index))
.map((item, index) => {
const formData = new FormData();
formData.append("fileHash", fileHash.value);
formData.append("chunkHash", fileHash.value + "-" + index);
formData.append("chunk", item);
return formData;
});
//...
};
const handleUpload = async (e: Event) => {
//...
//校验hash值,如果服务器有这个文件就不用重复上传,实现秒传功能
const data = await verify();
console.log(data);
if (!data.data.shouldUpload) {
alert("秒传成功");
resetKey.value++; // 重置 input,允许再次选择相同文件
return;
}
//上传分片
uploadChunks(chunks,data.data.existChunks);
};8.2. 后端实现
只需要在 /verify 这个接口中加上已经上传成功的所有切片的名称就可以,因为所有的切片都存放在以文件的hash值命名的那个文件夹,所以需要读取这个文件夹中所有的切片的名称。
javascript
app.post("/verify", async function (req, res) {
const { fileHash, fileName } = req.body;
console.log(fileHash, fileName);
const filePath = path.resolve(UPLOAD_DIR, fileHash + extractExt(fileName));
//返回服务器上已经上传的切片
const chunkDir = path.join(UPLOAD_DIR, fileHash);
let chunkPaths = [];
if (fse.existsSync(chunkDir)) {
chunkPaths = await fse.readdir(chunkDir);
console.log("chunkPaths:", chunkPaths);
}
//如果存在,不用上传
if (fse.existsSync(filePath)) {
console.log("文件已存在");
return res.status(200).json({
ok: true,
data: {
shouldUpload: false,
},
});
} else {
//不存在,重新上传
console.log("文件不存在");
return res.status(200).json({
ok: true,
data: {
shouldUpload: true,
//返回服务器上已经存在的切片
existChunks: chunkPaths,
},
});
}
});