2026 年,AI 算力市场正从"大模型训练"逐渐转向"大模型推理"阶段。随着 DeepSeek、Qwen、Llama、Agent、多模态生成等应用持续落地,企业对于 GPU 的关注重点,也开始从单纯峰值性能,转向显存容量、长期稳定性与实际部署效率。
与此同时,市场环境也在发生明显变化。
RTX 5090 凭借极强的单卡性能,依然是当前 AI 本地部署市场中的热门选择,但受 GDDR7 显存供应影响,近期渠道价格持续波动,部分规格供货周期有所拉长;RTX PRO 6000 作为 96GB 旗舰专业 GPU,则更多面向超大规模训练与高端 AI 基础设施场景,市场需求持续增长。
在这种背景下,RTX PRO 5000 凭借 48GB / 72GB ECC 大显存、300W 低功耗、专业级稳定性与更灵活的部署方式,正在成为企业级 AI 推理与专业算力场景中的重要选择。
本文结合当前市场环境与实测数据,对 RTX PRO 5000 的核心能力、与 RTX 5090 及 RTX PRO 6000 的差异化定位,以及典型行业应用场景进行全面解析。
一、RTX PRO 5000核心能力与参数速览
RTX PRO 5000 基于 NVIDIA Blackwell 架构打造,定位专业工作站与 AI 服务器场景,提供 48GB 与 72GB 两种 ECC GDDR7 显存版本。
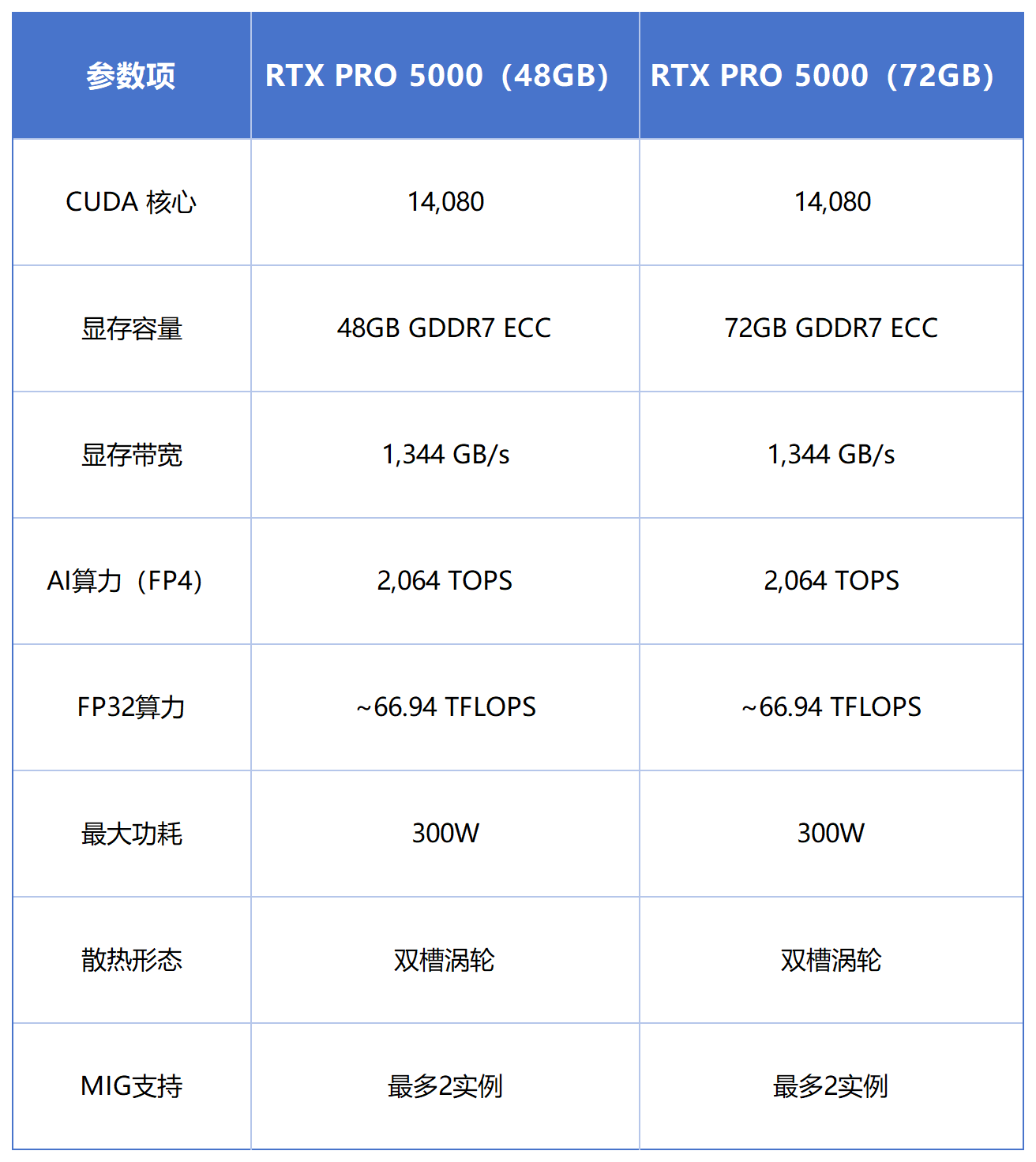
相比消费级 RTX 5090 与旗舰级 RTX PRO 6000,RTX PRO 5000 的核心特点并不是追求极限峰值性能,而是在显存容量、部署密度、长期稳定性与整体运营成本之间,提供更适合企业规模化部署的平衡方案。
300W 的 TDP 意味着单卡即可在标准服务器散热环境中稳定运行,4 卡、8 卡 AI 算力服务器也能够在标准 4U 风冷机架内完成部署,无需额外的液冷改造与复杂供电设计。
而 48GB / 72GB ECC 显存,则能够覆盖当前大量 AI 推理场景中的实际需求,包括:
●DeepSeek 本地部署
●Qwen 推理
●Agent 智能体
●RAG 企业知识库
●多模态生成
●自动驾驶仿真
●高校科研计算
Blackwell 架构带来的 FP4 精度支持,则进一步提升了大模型推理效率。
以 70B 参数模型为例,在 FP4 量化后,模型体积可压缩至约 35GB 左右,RTX PRO 5000 48GB 版本即可实现单卡完整部署,并预留 KV Cache 空间,从而减少多卡并行带来的通信损耗。
根据 vLLM 实测数据,GPT-OSS 20B 模型在 INT4 精度下,可实现约 3,359 tokens/s 吞吐能力,TPOT(单 Token 生成延迟)低至 16.8ms,已经能够满足企业级知识库、智能问答与中高并发推理场景需求。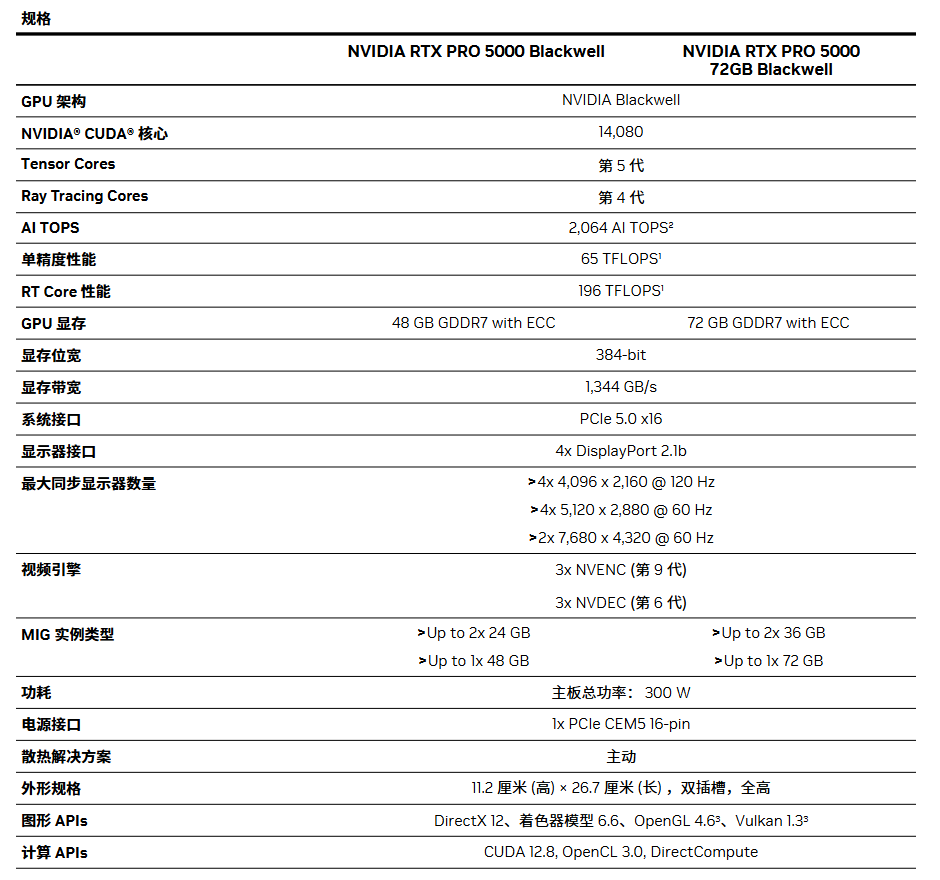
二、实测性能参考
结合公开 vLLM 基准测试,RTX PRO 5000 在主流大模型推理场景中的表现如下:
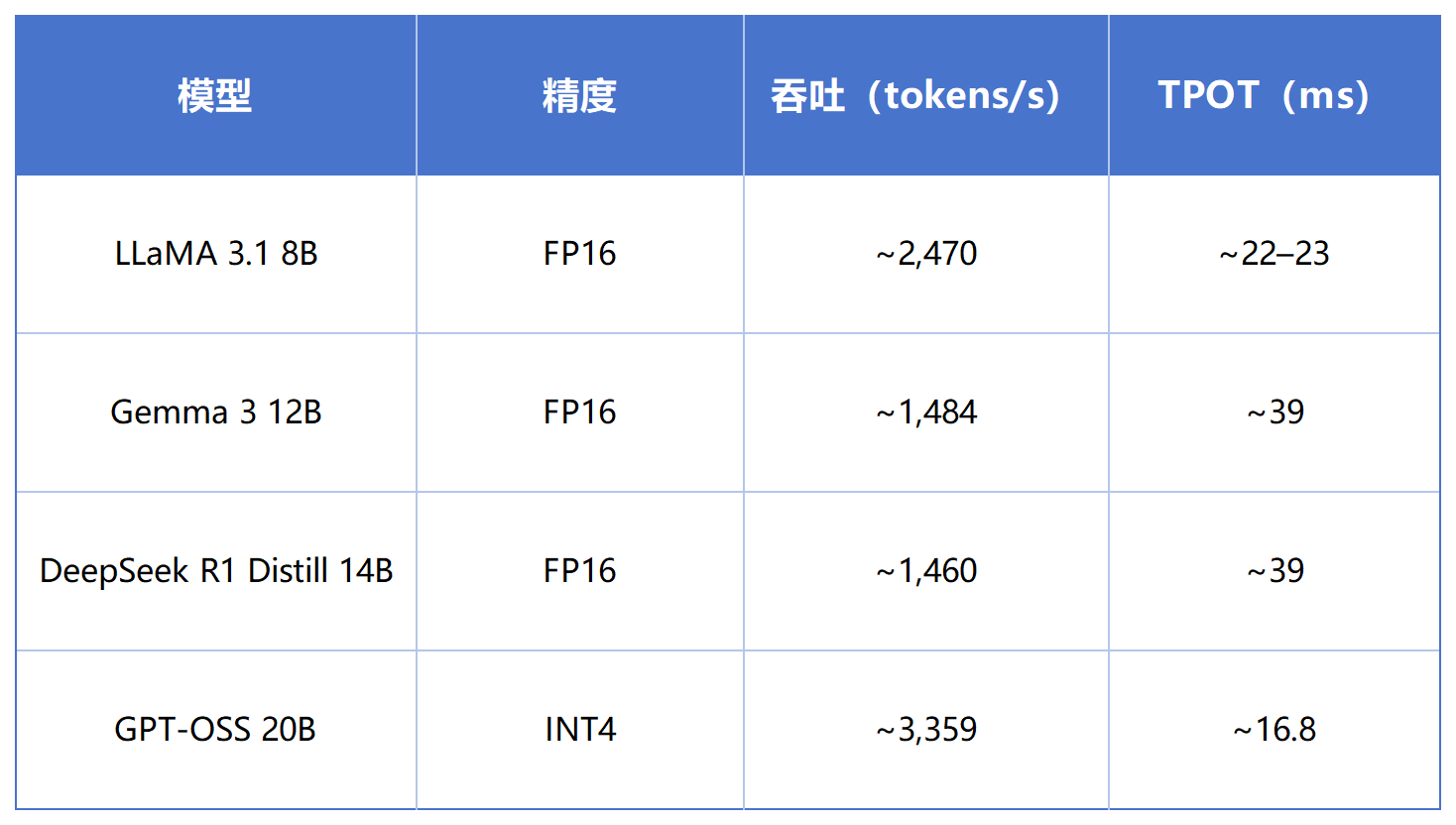
从实际业务角度来看:
8B 级模型已经能够支撑高 QPS 在线推理服务;
14B 级模型可满足企业知识库、智能客服、AI Agent 等中等并发场景;
20B 量化模型则进一步体现了 FP4 / INT4 推理在吞吐效率上的优势。
对于以推理为核心、需要本地部署与长期稳定运行的团队而言,RTX PRO 5000 已经处于"性能、显存与部署成本"相对均衡的区间。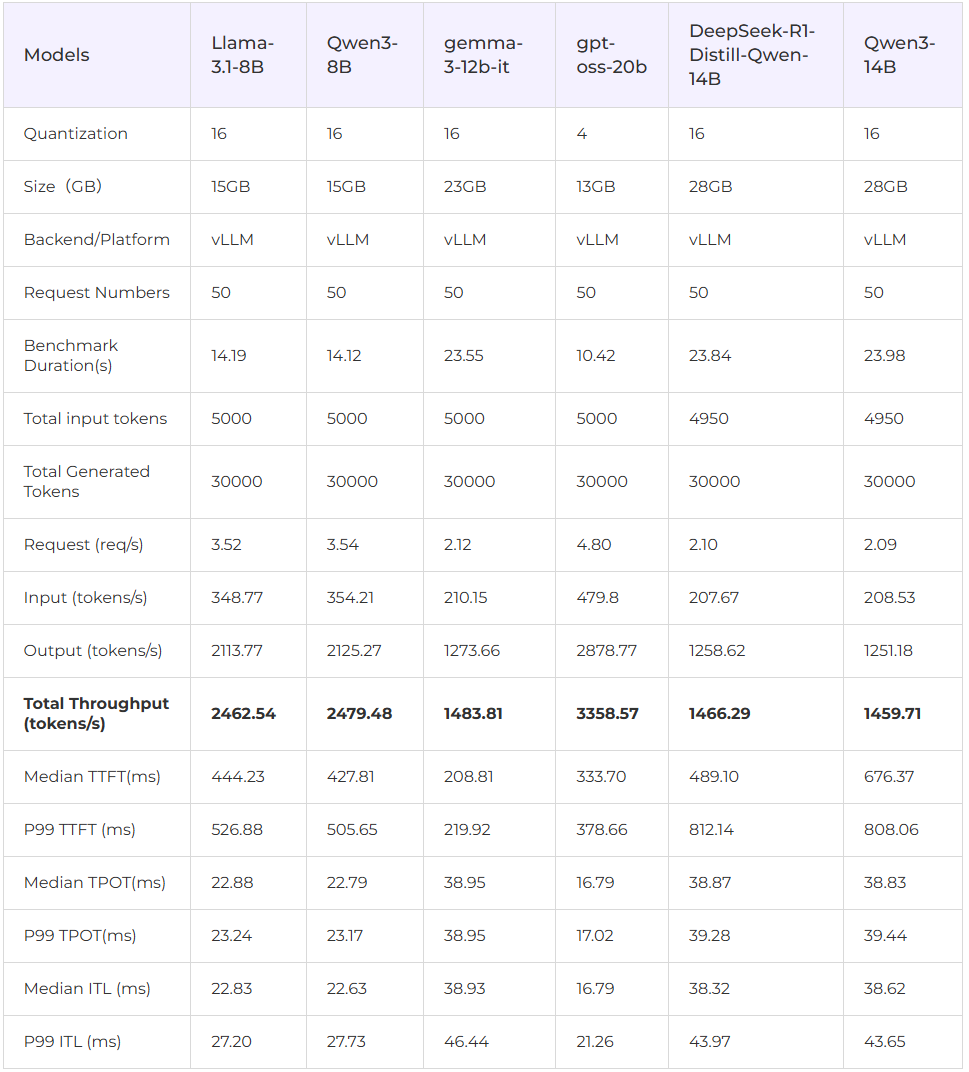
三、RTX 5090、RTX PRO 5000、RTX PRO 6000 如何选择?
当前 AI 算力市场中,RTX 5090、RTX PRO 5000 与 RTX PRO 6000 正逐渐形成三条不同的部署路线。
RTX 5090 更偏向极致性能与高性价比推理;
RTX PRO 5000 更强调企业级稳定性、大显存与长期运行能力;
RTX PRO 6000 则面向超大规模训练与高端 AI 基础设施场景。
三者并不存在绝对替代关系,而是分别对应不同预算、不同业务阶段与不同部署目标。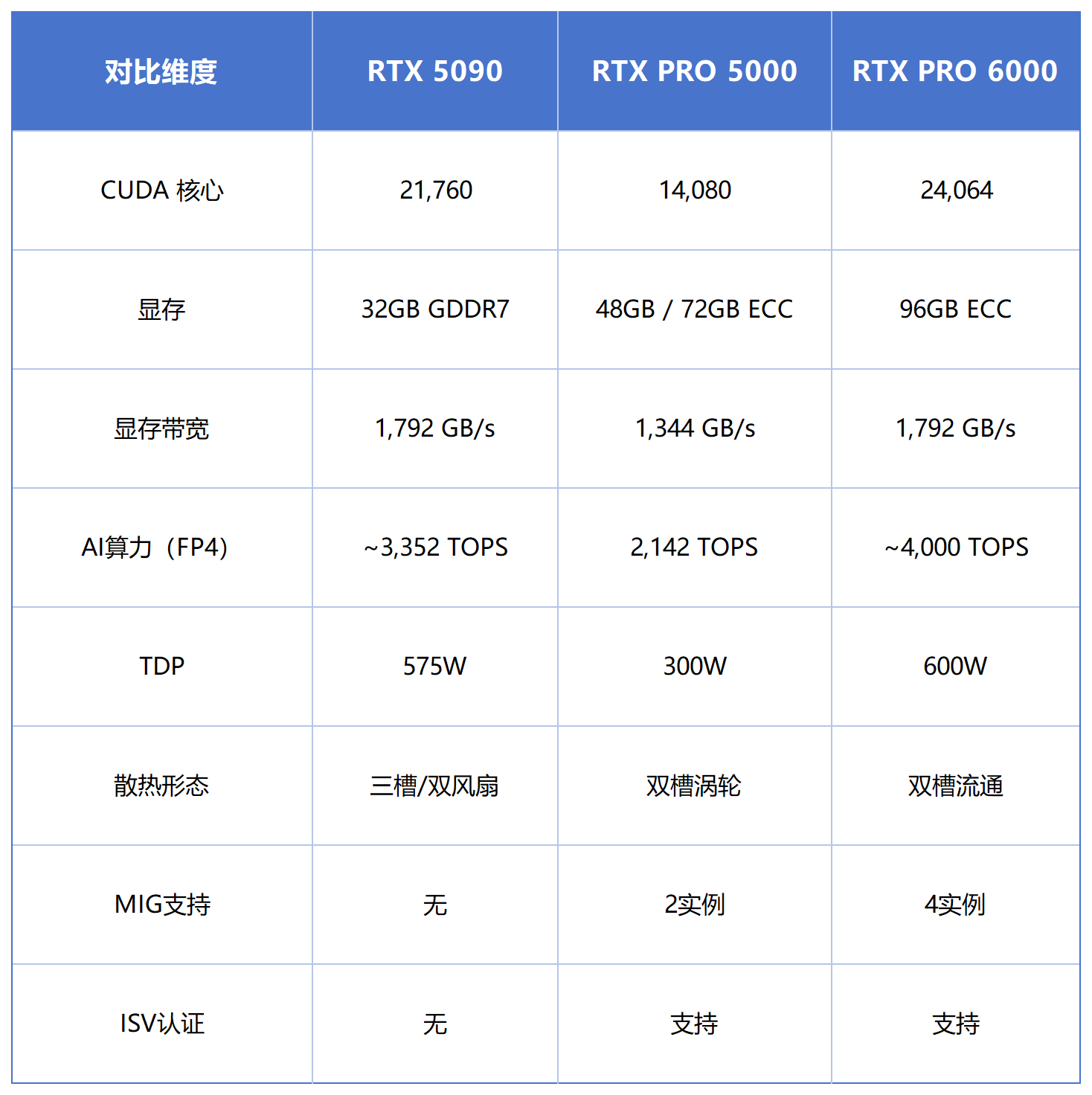
RTX 5090 的核心优势,在于更高的单卡性能密度与极强的性价比。其 21,760 CUDA Core 与更高显存带宽,在:
●AI 内容生成
●视频生成
●Stable Diffusion
●Flux
●ComfyUI
●AI 开发测试
●中小规模推理
等场景中,依然具备极高市场热度。
目前大量 DeepSeek、Qwen 本地部署方案,仍然以 RTX 5090 作为核心推理平台。
RTX PRO 6000 则属于真正的旗舰级专业 GPU,96GB ECC 大显存,使其能够更好支持:
●超长上下文
●超大参数模型
●大规模训练
●多用户高并发
●超大型 AI 集群
在自动驾驶、科研超算与大型训练平台中具备明显优势。
RTX PRO 5000 的核心价值,则在于"规模化部署平衡能力"。
相比 RTX 5090:它拥有更大的 ECC 显存、更低功耗以及更适合多卡部署的结构设计;
相比 RTX PRO 6000:它又拥有更灵活的部署成本与更高的整体性价比。
对于大多数企业级 AI 推理项目而言,RTX PRO 5000 往往更容易在预算、显存与长期运行之间形成合理平衡。
四、当前市场行情与采购节奏建议
2026 年 GPU 市场的核心变量,依然是 GDDR7 显存供应。
由于全球 AI 数据中心需求持续增长,GDDR7 与 HBM 产能分配持续紧张,RTX 5090 与 RTX PRO 6000 的渠道价格与供货周期均受到一定影响。
RTX 5090 当前依然是 AI 本地部署市场中的热门产品,尤其在 AI 创业团队、内容生成与开发测试环境中需求旺盛;
RTX PRO 6000 则更多集中于高端训练市场与大型 AI 基础设施项目。
相比之下,RTX PRO 5000 当前整体供货状态相对稳定,48GB 与 72GB 双版本能够覆盖更多企业级推理需求,因此在当前阶段具备较高部署灵活性与交付确定性。
对于希望快速完成 AI 基础设施落地、同时兼顾长期运行稳定性的团队而言,RTX PRO 5000 是当前值得重点关注的专业级方案之一。
五、典型应用场景适配
AI大模型推理与微调
48GB 显存已经能够支持大量 70B 级模型的 FP4 量化推理;
72GB 版本则更适合长上下文、多并发与 FP8 推理场景。
配合 vLLM、TensorRT-LLM 等框架,可本地构建高性能推理平台,满足金融、医疗、政务等对数据隐私与本地部署有要求的行业场景。
多模态AI与内容生成
RTX PRO 5000 可流畅运行:
●Stable Diffusion XL
●FLUX
●ComfyUI
●视频生成模型
3× NVENC + 3× NVDEC 编解码能力,可支持 4K / 8K 内容处理与多任务生成流程。
对于影视后期、广告创意与 AI 内容生产团队而言,既能兼顾生成性能,也能保障长期运行稳定性。
自动驾驶仿真
在 NVIDIA Omniverse 环境下,RTX PRO 5000 可同时完成:
●3D 场景渲染
●传感器仿真
●AI 模型推理
●多节点协同计算
ECC 显存与双槽涡轮结构,更适合长时间高负载运行。
4 卡 / 8 卡服务器方案,可构建自动驾驶高并发仿真平台。
高校科研与科学计算
14,080 CUDA Core 能够同时兼顾:
●AI 推理
●分子动力学
●CFD
●FEA
●科学计算
300W 双槽结构,也更适合在标准工作站与高校机房环境中部署高密度 GPU 集群。
工业仿真与数字孪生
RTX PRO 5000 支持:
●ANSYS
●Siemens STAR-CCM+
●工业数字孪生
●实时渲染
●IoT 可视化
能够满足工业级 7×24 小时运行需求。
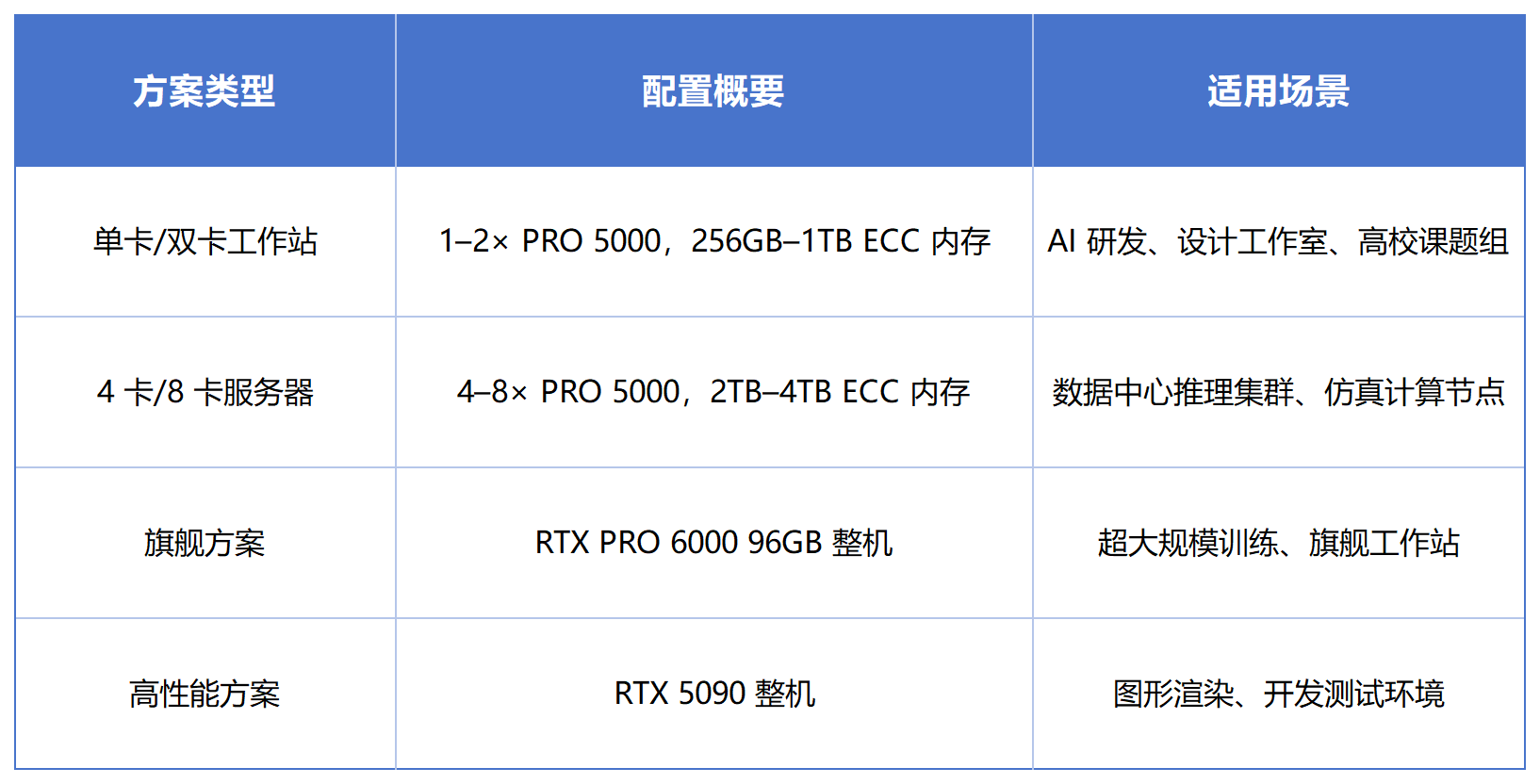
六、整机方案与交付能力
深圳昊源诺信提供 RTX PRO 5000 全系列整机方案,现货覆盖单卡工作站到 8 卡服务器配置,同时可提供 RTX PRO 6000 旗舰整机与 RTX 5090 高端整机,支持按预算与场景灵活选型。
并可根据客户需求完成:
●CUDA 与驱动部署
●Docker 与 AI 环境预装
●TensorRT-LLM / vLLM 调优
●DeepSeek / Qwen 本地部署
●RAG 企业知识库搭建
●多机集群联调
实现真正的软硬一体化交付。
交付层面支持:
●全国范围上门安装调试
● 7×24 小时远程技术支持
●长期运维服务
●固件更新与硬件维保
帮助企业更快完成 AI 基础设施落地。
赋能科技,智创未来
当前 AI 行业已经进入"推理部署时代"。企业真正关注的,不再只是 GPU 峰值性能,而是:
●显存容量
●长期稳定性
●部署效率
●本地化能力
●综合运营成本
RTX 5090、RTX PRO 5000 与 RTX PRO 6000,也正在形成更加清晰的市场分层:
RTX 5090 代表极致性能与高性价比推理路线;
RTX PRO 5000 更适合企业级规模化部署;
RTX PRO 6000 则面向更高端的大模型训练与超大规模 AI 基础设施场景。
FAQ常见答疑
Q1:RTX PRO 5000 和 RTX 5090 如何选择?
RTX 5090 更适合追求极致性能与高性价比推理的场景,在 DeepSeek、本地大模型部署、AI 内容生成等方向依然是热门方案。
RTX PRO 5000 则更强调大显存、ECC 稳定性与长期运行能力,更适合企业级 AI 推理、多卡服务器与生产环境部署。
Q2:48GB 和 72GB 版本应该怎么选?
48GB 版本已经能够覆盖多数主流大模型推理场景;
72GB 版本则更适合长上下文、更高并发以及更复杂的多模态推理任务,显存冗余空间更充足。
Q3:RTX PRO 6000 更适合哪些场景?
RTX PRO 6000 更偏向超大规模训练、高端科研与超长上下文推理场景。
96GB ECC 大显存,更适合大型 AI 集群与高端 AI 基础设施平台。
Q4:RTX PRO 5000 是否支持 DeepSeek、Qwen 等模型本地部署?
支持。
RTX PRO 5000 已能够很好支持 DeepSeek、Qwen、Llama 等主流模型的本地推理与私有化部署,并兼容 TensorRT-LLM、vLLM 等主流推理框架。
Q5:是否支持整机交付与本地部署?
支持。昊源诺信可提供 RTX PRO 5000、RTX PRO 6000、RTX 5090 全系列 AI服务器整机方案,并支持 CUDA 环境部署、模型调试、推理优化、RAG 知识库搭建以及全国范围交付与技术支持。