写在前面
下面这个案例使用的方法不是最优的,可以自己调着玩。
一、分块讲解
可以大致按照以下思路去开发代码:
一、模型训练:
1:1个配置文件
4:4个准备------准备训练数据、准备模型、准备损失函数、准备优化器
2:2个循环------外层循环控制轮次、内层循环控制批次
5:5个核心步骤------前向传播、计算损失、梯度清零、反向传播、更新参数
1:1个存储------训练好的模型存储下来
二、模型评估:
1:1个配置文件
2:2个准备------准备测试数据、准备模型
1:1个循环
2:2个核心步骤------前向传播、计算准确率/精确率/召回率/F1-SCORE1.模型训练
1个配置文件
一般来说,我们会把参数都维护到一个配置文件里,这样后续调参就可以不动代码。
在本案例中,图省事我直接写在一块代码里了。
python
BATCH_SIZE = 16
INPUT_SIZE = 13 # 输入的特征数量
OUTPUT_SIZE = 3 # 输出的分类数量
LR = 1e-2
MOMENTUM = 0.9
EPOCHS = 100
OPTIMIZER = "SGD"
ACTIVATION = "sigmoid"4个准备
- 准备数据 :
我们可以在这一步做数据预处理、加载与分批
python
def data_pre_processing(batch_size):
# 读取数据
dataset = load_wine(as_frame=True)
df = dataset.frame
x = df.iloc[:, :-1]
print(x, x.shape)
y = df.iloc[:,-1]
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=666)
# 数据标准化
tf = StandardScaler()
x_train = tf.fit_transform(X_train)
x_test = tf.transform(X_test)
# 数据加载与分批
# 加载
train_dataset = TensorDataset(torch.from_numpy(x_train).float(), torch.from_numpy(y_train.values))
test_dataset = TensorDataset(torch.from_numpy(x_test).float(), torch.from_numpy(y_test.values))
# 分批
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader- 准备模型 :
这一步的要点是1个继承,2个重写。
python
class MyModel(torch.nn.Module):
"""1个继承,2个重写"""
def __init__(self, input_size, output_size, activation):
# 重写__init__魔法方法
# 继承父类init
super().__init__()
self.activation = activation
self.l1 = torch.nn.Linear(input_size, 64)
self.l2 = torch.nn.Linear(64, 64)
self.out = torch.nn.Linear(64, output_size)
def forward(self, x):
# 重写forward
activation_map = {
"sigmoid": torch.sigmoid,
"relu": torch.relu,
}
act_fn = activation_map[self.activation]
layer_list = [
self.l1,
self.l2
]
for layer in layer_list:
x = act_fn(layer(x))
return self.out(x)- 准备损失函数 :
这一步,我们根据具体的任务选择合适的损失函数。本案例是多分类任务,我们选择交叉熵损失函数。
python
loss_fn = torch.nn.CrossEntropyLoss()- 准备优化器 :
由于该数据集的特征少,样本小,因此我们设计的神经网络层数也比较浅。故选择随机梯度下降+Momentum作为优化器。
python
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)2个循环
在真实训练中,我们不可能一次性跑完所有数据,因此我们都是分批跑的。
- 外层循环:通过外层循环,我们控制训练的轮次
- 内层循环:通过内层循环,我们在一轮中分批训练
python
for epoch in range(1, epochs + 1):
model.train()
loss_sum = 0.0
batch_num = 0
for batch_x, batch_y in train_data_loader:
# 前向传播
pred_y = model(batch_x)
# 计算损失
loss = loss_fn(pred_y, batch_y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
loss_sum += loss.item()
batch_num += 1
scheduler.step()
avg_loss = loss_sum / batch_num
avg_loss_list.append(avg_loss)5个核心步骤
在内层循环中,我们通过执行五个核心步骤来训练模型。
python
# 前向传播
pred_y = model(batch_x)
# 计算损失
loss = loss_fn(pred_y, batch_y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()2.模型评估
在评估前可以先关掉张量的梯度计算来提升速度
python
def eval_model(model, test_data_loader):
"""模型评估"""
model.eval()
with torch.no_grad():
pred_true_num = 0
for batch_x, batch_y in test_data_loader:
logits_y = model(batch_x)
pred_y = logits_y.argmax(dim=-1)
pred_true_num += (pred_y == batch_y).sum()
acc = pred_true_num / len(test_data_loader.dataset)
return acc二、完整代码
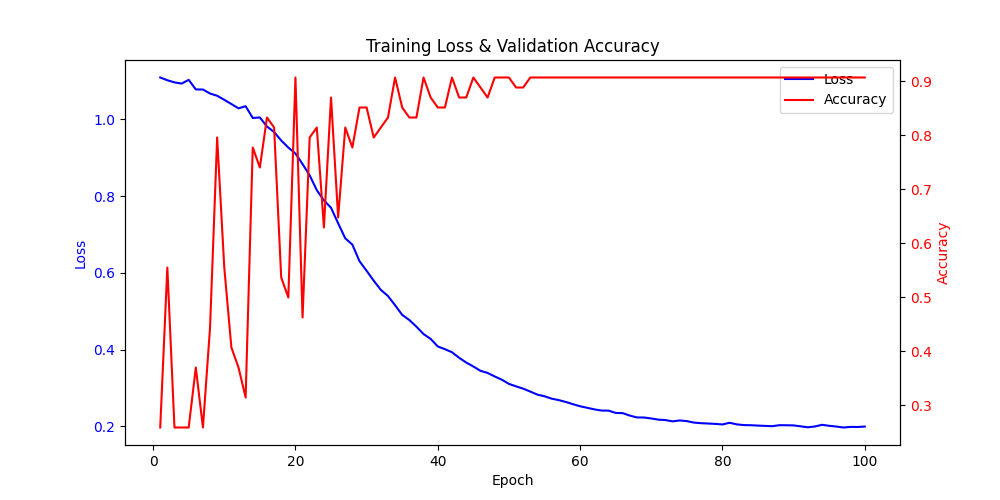
以下代码运行结果如图
python
from sklearn.datasets import load_wine
import torch
import pandas
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import TensorDataset, DataLoader
from matplotlib import pyplot as plt
import os
import datetime
def data_pre_processing(batch_size):
# 读取数据
dataset = load_wine(as_frame=True)
df = dataset.frame
x = df.iloc[:, :-1]
print(x, x.shape)
y = df.iloc[:,-1]
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=666)
# 数据标准化
tf = StandardScaler()
x_train = tf.fit_transform(X_train)
x_test = tf.transform(X_test)
# 数据加载与分批
# 加载
train_dataset = TensorDataset(torch.from_numpy(x_train).float(), torch.from_numpy(y_train.values))
test_dataset = TensorDataset(torch.from_numpy(x_test).float(), torch.from_numpy(y_test.values))
# 分批
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
class MyModel(torch.nn.Module):
"""1个继承,2个重写"""
def __init__(self, input_size, output_size, activation):
# 重写__init__魔法方法
# 继承父类init
super().__init__()
self.activation = activation
self.l1 = torch.nn.Linear(input_size, 64)
self.l2 = torch.nn.Linear(64, 64)
self.out = torch.nn.Linear(64, output_size)
def forward(self, x):
# 重写forward
activation_map = {
"sigmoid": torch.sigmoid,
"relu": torch.relu,
}
act_fn = activation_map[self.activation]
layer_list = [
self.l1,
self.l2
]
for layer in layer_list:
x = act_fn(layer(x))
return self.out(x)
def train_model(train_data_loader, test_data_loader, input_size, output_size, lr, momentum, epochs, activation, opt):
"""训练模型"""
# 准备模型
model = MyModel(input_size=input_size, output_size=output_size, activation=activation)
# 准备损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 准备优化器
if opt == "SGD":
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
elif opt == "AdamW":
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
# 调优:余弦退火
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=EPOCHS)
# 两个循环
avg_loss_list = []
acc_list = []
log = ""
for epoch in range(1, epochs + 1):
model.train()
loss_sum = 0.0
batch_num = 0
for batch_x, batch_y in train_data_loader:
# 前向传播
pred_y = model(batch_x)
# 计算损失
loss = loss_fn(pred_y, batch_y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
loss_sum += loss.item()
batch_num += 1
scheduler.step()
avg_loss = loss_sum / batch_num
avg_loss_list.append(avg_loss)
# 模型评估
acc = eval_model(model, test_data_loader)
acc_list.append(acc)
info = f"==========第{epoch}轮avg_loss:{avg_loss},acc:{acc}"
print(info)
log = log + "\n" + info
return avg_loss_list, acc_list, log
def eval_model(model, test_data_loader):
"""模型评估"""
model.eval()
with torch.no_grad():
pred_true_num = 0
for batch_x, batch_y in test_data_loader:
logits_y = model(batch_x)
pred_y = logits_y.argmax(dim=-1)
pred_true_num += (pred_y == batch_y).sum()
acc = pred_true_num / len(test_data_loader.dataset)
return acc
def show_img(x_list, acc_list, loss_list):
"""训练数据可视化"""
fig, ax1 = plt.subplots(figsize=(10, 5))
# 左 Y 轴 ------ Loss
line1, = ax1.plot(x_list, loss_list, 'b-', label='Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color='b')
ax1.tick_params(axis='y', labelcolor='b')
# 右 Y 轴 ------ Accuracy
ax2 = ax1.twinx()
line2, = ax2.plot(x_list, acc_list, 'r-', label='Accuracy')
ax2.set_ylabel('Accuracy', color='r')
ax2.tick_params(axis='y', labelcolor='r')
# 合并图例(可选)
lines = [line1, line2]
labels = [l.get_label() for l in lines]
ax1.legend(lines, labels, loc='best')
plt.title('Training Loss & Validation Accuracy')
plt.show()
def train_history(msg):
file_name = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
with open(f"{file_name}.txt", "w", encoding="utf8") as f:
f.write(msg)
if __name__ == '__main__':
torch.manual_seed(1)
# 配置文件
BATCH_SIZE = 16
INPUT_SIZE = 13 # 输入的特征数量
OUTPUT_SIZE = 3 # 输出的分类数量
LR = 1e-2
MOMENTUM = 0.9
EPOCHS = 100
OPTIMIZER = "SGD"
ACTIVATION = "sigmoid"
train_loader, test_loader = data_pre_processing(BATCH_SIZE)
loss_list, acc_rate_list, log = train_model(
train_loader,
test_loader,
INPUT_SIZE,
OUTPUT_SIZE,
LR,
MOMENTUM,
EPOCHS,
ACTIVATION,
OPTIMIZER
)
img_x_list = [i for i in range(1, EPOCHS + 1)]
show_img(img_x_list, acc_rate_list, loss_list)