一、什么是机器学习
1.1、机器学习概念
机器学习(Machine Learning 简称ML)是实现人工智能(AI)的主要方法;它的核心思想是:让计算机自己从大量的数据中"学习"规律,并利用这些规律对未知的情况做出预测或决策;
它不追求一开始就有一个完美的黑箱 ,但允许这个黑箱不断地变化,通过不断地引导和学习,让他在某一个任务上表现的越来越好;
做一个生动的比喻,例如训狗:
当你发出坐的指令,如果它做对了,你给他奖励,做错了(朝你龇牙或者无动于衷),就给它一个大逼斗;长此以往,狗狗这个黑箱,就知道坐这个指令和它动作之间的关系,类似条件反射;于是一只会听指令的聪明小狗,就训练完成了;
1.2、举个栗子
像上面这样,把在学习的对象从狗狗变成机器,比如:训练一个可以识别图片中数据的黑箱;
准备
只需要准备一个具有学习能力的机器,然后收集很多数字的图片,人工标注出每张图片里的数字是什么;
过程
把一张张图片展示在这个机器面前,让它预测里面的数字到底是什么?如果它预测对了,就给它奖励,预测错了,就给它惩罚;让这个机器不断地自我调整;量变引起质变,当它见过的图片越来越多之后,就能够神奇的做到识别图片里的数字是什么了;
看到这里,聪明的小伙伴可能要问了:
1、哪来这种神奇黑箱?
2、怎么奖励一个机器?
3、机器怎么建立条件反射?

其实这三个问题分别对应的是机器学习的:模型结构、损失函数、训练过程;
二、感知机(联结主义的图腾)
我们先看机器学习 的第一个问题,如何搭建起一个有学习能力的黑箱机器呢,有没有一种万能的超级强大的黑盒,无论什么样的对应关系,它都能表示和学会呢?
此时就不得不提到,实现人工智能的流派:联结主义,而说到联结主义,就绕不开感知机;
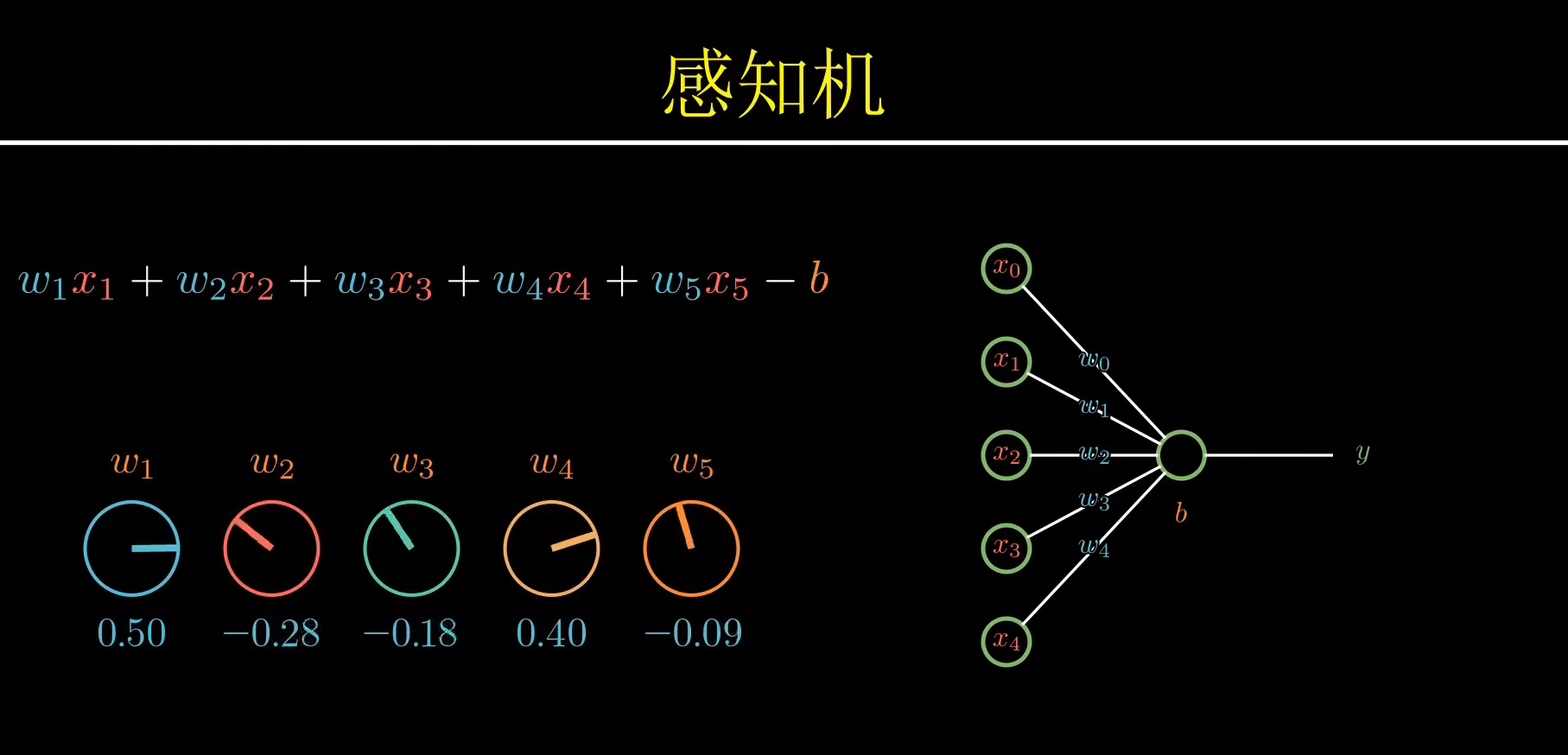
2.1、什么是感知机
感知机是一种二分类的线性模型,也就是用来判断输入属于哪一类(比如"是/否")。在20世纪50年代,科学家罗森布拉特(Frank Rosenblatt)深受"联结主义"思想的影响------他坚信智能源于模仿大脑。于是他在1958年发明了感知机(Perceptron)。
可以思考一下,我们是如何识别苹果的?从颜色、尺寸、味道等特征来进行识别;
如何让机器也能识别呢?如果我们将这些特征进行打分 ,并且赋予一定的权重系数 ,通过所有特征的打分系数各自乘以权重系数,然后减去一个阈值,最后判断是否大于零,大于零,输出是苹果,否则,不是苹果;这就是一个苹果感知机;
核心思想:
- 对输入特征进行加权求和;
- 加上一个偏置项;;
- 通过一个激活函数(通常是符号函数)决定输出类别;
感知机极其简单,用数学公式表达就是:
y=f(∑i=1nwixi+b)y = f(\sum_{i=1}^{n} w_i x_i + b)y=f(i=1∑nwixi+b)
它接收几个输入,乘以权重,加个偏置,然后输出结果。这是人类历史上第一个真正意义上的神经网络模型。
2.2、感知机的限制
感知机很简单,也有局限性:
- 只能解决线性可分问题,比如AND、OR可以,但XOR(异或)不行;
- 激活函数简单,难以表达复杂关系;
这也是后来多层感知机和深度神经网络出现的原因,它们可以处理非线性问题;
三、神经网络
联结主义是一种哲学思想和认知理论,而神经网络则是实现这种理论的具体技术、模型和工具。

3.1 前言
正如前面提到的,在1969年,符号主义泰斗马文·明斯基出版《感知机》一书,从数学上严谨地证明了"单层感知机连简单的'异或'逻辑问题都无法解决"。这一致命一击,直接把联结主义打入冷宫;
因此神经网络一度陷入了极度的寒冬;所有人都认为神经网络是垃圾和骗子的代名词,基金资助大为减少,研究者纷纷转行,AI研究也因此陷入长达十几年的寒冬。但与此同时,依然有一批研究者在坚持,他们最后守得云开见月明,成为后来深度学习的奠基人,并获得图灵奖;
科普一下
神经元:神经系统中最基本的结构和功能单位,也被称为神经细胞;负责接收、处理和传递信息;人脑中大约有860亿个神经元,它们通过复杂的网络连接形成了我们的思维、记忆、情感和行为的基础;
神经元的部分组成:
- 细胞体:负责整合接收到的信息;
- 树突:接收来自其他神经元的信号;
- 轴突:输出信号;
下文中提到的神经元,并非生物神经元,而是仿造生物神经元,所创建的神经节点
3.2、什么是神经网络
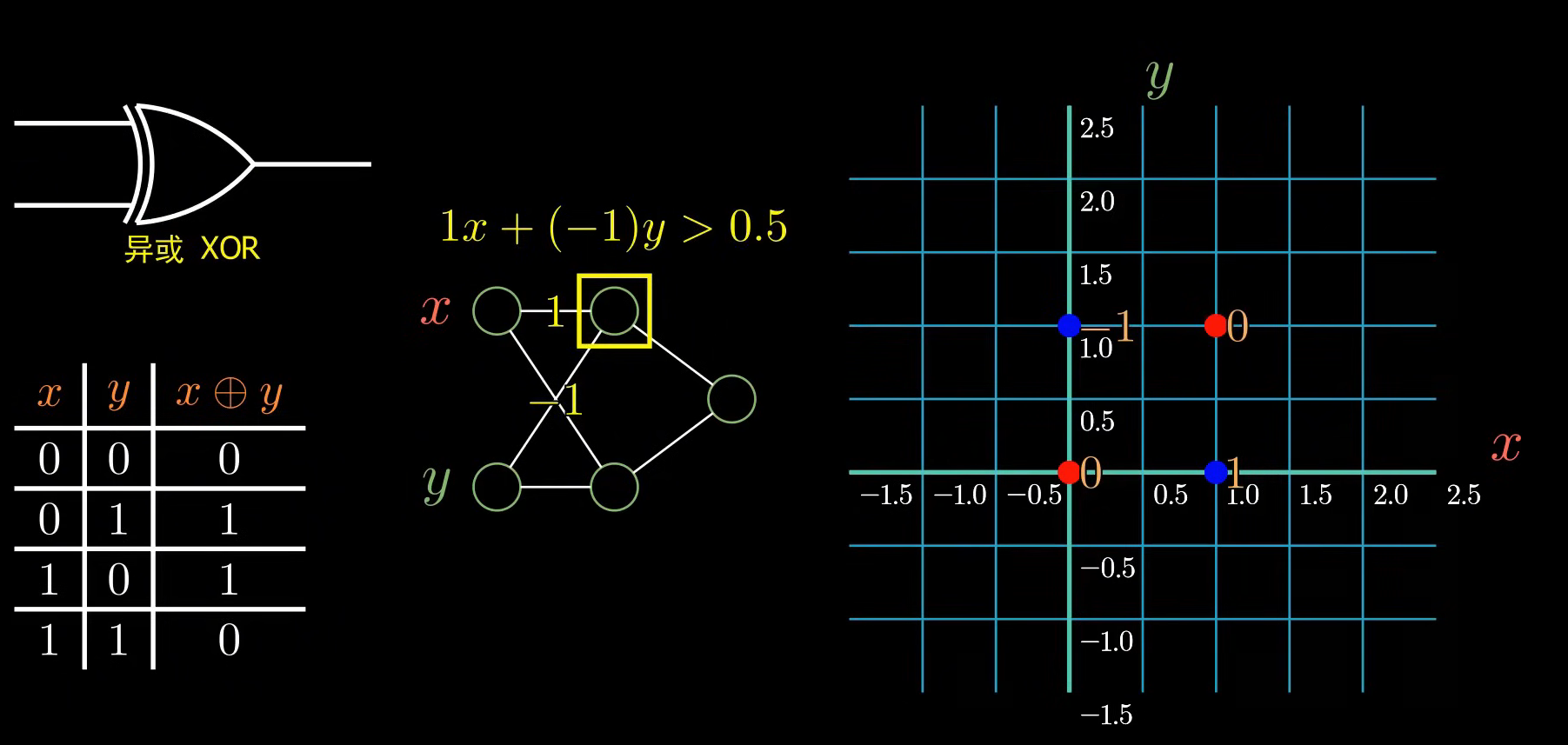
还是接着上面的异或 故事说,既然一个神经元,无法解决异或的问题,那么多来几个神经元(像俄罗斯套娃一样),上一个神经元的输出,作为下一个神经元的输入;结果发现,可以完美解决异或问题,而这就是后来大名鼎鼎的多层感知机(MLP)(神经元层数>=2)。
其中的层数可以不止两层,当这些神经元层层叠叠的时候,就是鼎鼎大名的神经网络;
这里可能有点误解,在此澄清一下,神经网络是一个广义的概念,它是由大量神经元(节点)和它们之间的连接组成的计算系统,用来模拟人脑处理信息的方式。感知机和多层感知机,以及n多层神经元组成的结构,都是神经网络;
神经网络是人工智能中的一种重要模型,灵感来自于人类大脑的结构和工作方式,属于机器学习的核心方法之一;
简单来说,它是一种由多个"神经元"(节点)组成的计算机系统,这些神经元通过连接(类似大脑中的神经连接)来处理信息;
计算机科学家证明,只要神经网络的宽度和深度足够大,那么理论上它可以拟合任何一种函数,表达任何一种智能所需要的输入与输出之间的对应关系;
3.3、卷积神经网络(CNN)
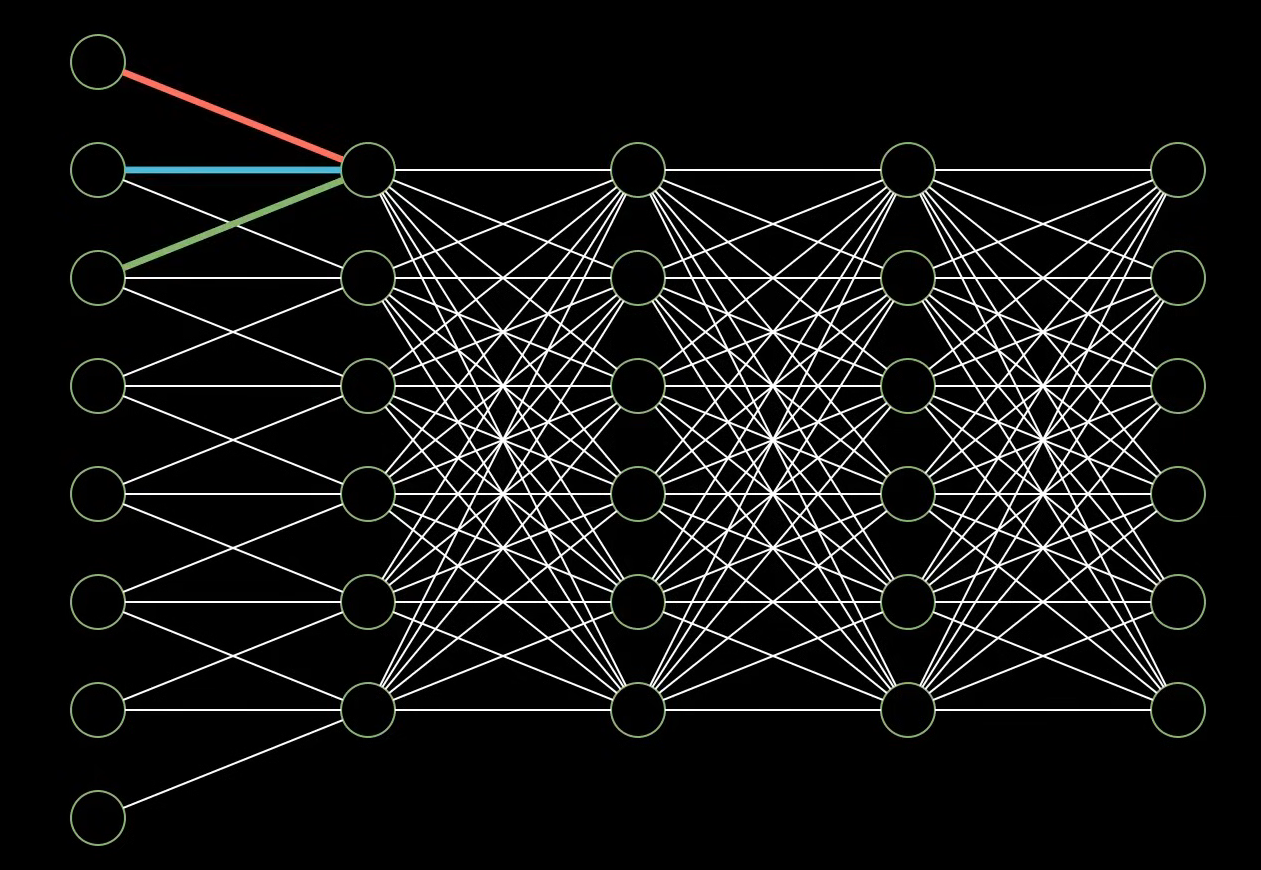
3.3.1、CNN概念
在传统的全连接神经网络中,每一层的每一个神经元都与上一层的每一个神经元相连,
在 CNN 出现之前,多层感知机(MLP)处理图像有一个致命痛点:参数量爆炸。如果输入一张 1000×10001000 \times 10001000×1000 像素的彩色图片(3通道),单单第一层全连接网络就需要 1000×1000×3=3,000,0001000 \times 1000 \times 3 = 3,000,0001000×1000×3=3,000,000 个输入节点。如果隐藏层有 1000 个神经元,那么第一层就需要 30亿个权重参数,这几乎无法训练。
动物视觉神经系统的神经元,不需要和前一层的所有神经元,全都稠密的连接,而只需要和局部的几个神经元连接就行 ,而且每个神经元和前一层连接的参数结构,又都类似。
在设计神经网络时,借鉴动物视觉的这种神经元结构,从而减少参数和运算量,提升神经网络的性能,这就是大名鼎鼎的卷积神经网络(CNN);
3.3.2、CNN核心思想
局部连接 :每个神经元不再盯着整幅图,而是只看一个局部区域(感受野);
权重共享::在同一张图片上移动的"滤镜"使用的是同一套参数;
3.4、残差网络(Resnet)
当卷积层堆多了之后,训练起来有困难,又增加了一种跳跃式的连接,这就是残差网络(Resnet);
3.5、稠密卷积网络(DenseNet)
将神经网络的任何两层都跳跃连接起来,这就是稠密卷积网络(DenseNet);
3.6、Transformer
Transformer 是目前人工智能(尤其是大语言模型)中最核心、最重要的神经网络架构。
它由 Google 在 2017 年发表的论文《Attention Is All You Need》中提出,从根本上改变了自然语言处理(NLP)领域,并成为 ChatGPT、Grok、Llama、DeepSeek、Qwen 等几乎所有现代大模型的基础。