前端同学应该都经历过这种场景:设计稿已经定了,页面也没有复杂交互,但真正落地时还是要一层层看尺寸、切图、补 CSS、对截图、调细节。页面稍微复杂一点,半天到一天很正常。
我做了一个工具,把这件事尽量自动化:输入一份设计 SVG,输出一份真实的像素级还原的 HTML/CSS 页面。把文本、布局、图标、背景、模块结构尽量还原成可维护的 DOM。
项目叫 SVG to HTML。
它目前支持扁平化 SVG,也能处理 5000px 以上高度、几十 MB 级别的大型设计稿。完整流程会自动拆模块、预提取文字和资源、调用模型生成 HTML,再用渲染截图做验证和反馈修复。实测样例里,全页像素 diff 可以压到 5% 左右,复杂页面在 5%-10% 区间更现实。
实测效果
下面是一组工作区里的样例。
| 样例 | 设计稿 | 还原结果 | Diff |
|---|---|---|---|
| demo,diff 4.98% |  |
 |
 |
这些结果还不是「完美像素级」。真实难点主要在字体渲染差异、复杂渐变、毛玻璃、阴影、半透明叠层、设计工具导出的奇怪 mask,以及个别 OCR 误差。但有了验证闭环以后,问题至少是可定位、可修复、可回滚的。目前使用gpt5.5high生成时间0.5小时左右,kimi k2.6生成时间1小时左右,效果gpt略好
上面的svg案例来源腾讯的ardot默认工程文件:ardot.tencent.com/
为什么从 SVG 入手
如果使用截图交给模型,让它「照着写一个页面」。这个方向能跑通 demo,但到了真实设计稿会遇到几个问题:
- 截图只有像素,没有节点结构,模型很容易猜错层级。
- 文字识别、图标识别、颜色、间距都混在一起,反馈修复没有稳定锚点。
- 页面越长,上下文越爆,模型容易漏区域、漏文字。
- 结果很难校验,只能靠肉眼看。
SVG 的优势是它天然有结构:节点、坐标、路径、填充色、文本片段、分组关系都在文件里。虽然设计工具导出的 SVG 经常很脏,可能有大量 wrapper、mask、clipPath、transform,但它至少给了我们一份可计算的源数据。
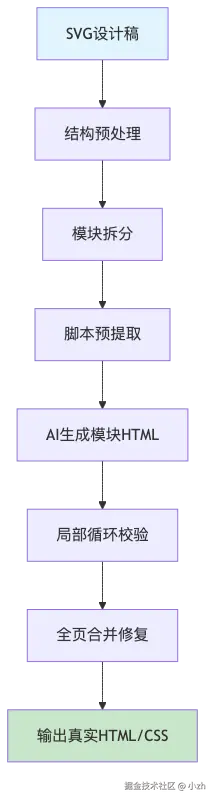
所以这个工具的核心思路不是「让 AI 看图自由发挥」,而是:
text
SVG 设计稿
-> 结构预处理
-> 模块拆分
-> 确定性信息预提取
-> AI 生成模块 HTML
-> 像素级校验和反馈修复
-> 合并全页并做最终 Gate下面说几个我觉得最关键的设计。
1. 先拆模块,不让模型一次吃完整页面
复杂页面最怕一口气扔给模型。上下文太大以后,模型会把精力浪费在无关节点上,最后出现某个模块缺一块、某段文字偏一行、样式突然换风格的问题。
工具会先判断复杂度。小设计可以整页作为一个模块,大设计会进入模块拆分流程。
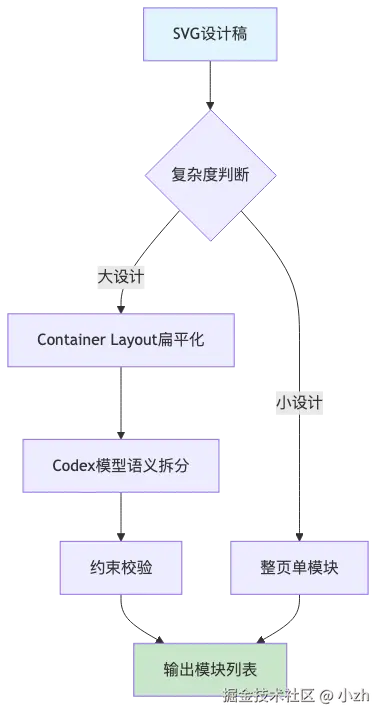
拆分前会先做一层 Container Layout 处理:把只负责嵌套的 wrapper 折叠掉,保留更有结构意义的容器、文本、图片、装饰节点。然后结合 OCR 文本框、容器框和 SVG 节点坐标,让模型输出语义模块,例如顶部区域、列表区域、底部区域等。
这里有几条硬约束:
- 不能切穿可见文字。
- 不能切穿卡片、列表项这类完整视觉单元。
- 小装饰要归入最近模块。
- 大背景、长底图这类跨模块元素可以作为共享层处理。
拆完模块后,每个模块可以并行生成,也可以单独验证和返修。这样模型面对的是一个局部问题,而不是一整张巨大的设计稿。
2. 模型给语义边界,脚本负责几何吸附
模型擅长判断「这块区域语义上属于哪里」,但不擅长保证边界刚好停在安全像素上。如果直接相信模型输出的 y 坐标,很容易切穿文字、卡片阴影、分割线。
所以模块边界不是直接采用模型结果,而是会再做一轮自动吸附。
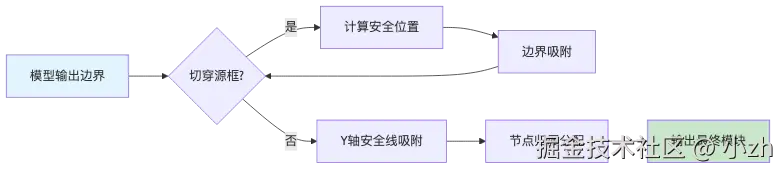
大致流程是:
- 收集 OCR text box 和 container box。
- 检查模型边界是否切穿源框。
- 如果切穿,寻找最近的安全位置。
- 把相邻源框之间的空隙中点作为 Y 轴安全线。
- 最后按节点和模块区域的交叉面积分配 SVG 节点归属。
这一步很重要。它把模型的语义判断和脚本的几何确定性结合起来:语义交给模型,边界安全性交给程序。
3. AI 之前,先把能确定的东西都提取出来
如果把原始 SVG 直接丢给模型,它会被大量路径、属性、嵌套结构淹没。更好的方式是先用脚本把确定性信息整理出来,让模型只处理真正需要判断的部分。
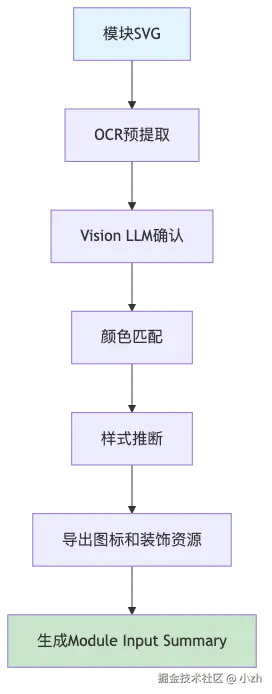
目前预提取会做这些事:
- OCR 识别文字内容和位置。
- Vision 模型辅助校准 OCR,减少漏字和误字。
- 从 SVG fill、stroke 和附近节点推断文字颜色。
- 根据文本框高度、行高和视觉尺寸推断 font-size / font-weight。
- 从 SVG 节点导出图标、装饰、复杂背景等资源。
- 生成 Module Input Summary,作为模块 agent 的输入摘要。
这里还有一个原则:普通可读文字必须是 DOM 文本,不能烘焙到图片里。图标、复杂装饰、纯视觉背景可以导出为 asset,但如果 asset 里包含普通 UI 文案,就要拆出来用 HTML 重建。
这样做的好处是,模型不需要读完整 SVG,也不需要猜所有细节。它拿到的是更像「工程上下文」的材料:模块尺寸、文本清单、资源清单、关键节点、约束规则。
4. 用像素 diff 做闭环,而不是只生成一次
只生成一次很难稳定。真正有效的是把生成结果渲染出来,和源设计稿截图做对比,再把差异反馈给模型修。
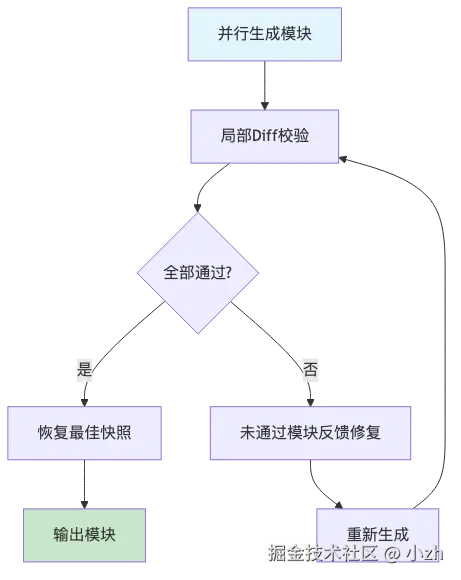
每个模块都会走局部验证:
- 渲染模块 HTML。
- 渲染对应 SVG 区域。
- 做像素 diff,找主要差异块。
- 生成反馈提示,指出偏差区域、明暗趋势、热点网格、可能的文字问题。
- 如果超过阈值,让模型基于反馈修复。
- 保存每轮快照,最终取历史最优版本。
这套机制比「你看起来不太对,重新写」稳定很多,因为反馈是有坐标、有差异方向、有可回滚版本的。
除了像素 diff,验证里还会跑几类 Gate:
- OCR 文本校验:检查文字是否漏掉、错字、位置偏差。
- layout box 检查:看 DOM 盒子和目标视觉区域是否对齐。
- workflow lint:检查是否违规使用原始 SVG、整图截图、不可维护结构。
- final-output-policy:确保最终结果是真 HTML/CSS,不是把源图包一层。
- module-region diff:全页合并后按模块区域看 diff,避免局部看着过了、全页拼接出问题。
5. 合并后再全局修一次
模块都通过以后,还不能直接结束。因为局部模块正确,不代表合并后的全页一定正确:CSS 作用域、共享背景、模块间距、滚动高度、全局字体都会影响结果。

合并阶段会做几件事:
- 给模块 CSS 加作用域,避免互相污染。
- 合并 text-layout 和模块 DOM。
- 注入 scaffold,生成最终 HTML。
- 跑全页 verify。
- 如果硬 Gate 不通过,触发全局修复。
- 如果修复导致 diff 回退或 Gate 从通过变不通过,自动回滚。
这也是我后来加上的保护:自动化系统不能只会往前冲,还要知道什么时候别把已经变好的东西修坏。
技术栈
- TypeScript + Node.js + Express
- OpenAI SDK / Codex SDK
- Chrome DevTools Protocol 负责页面渲染和截图
- Swift Vision / Tesseract 做 OCR
一点总结
AI 写页面不是不能用,但前提是人要先把方向和路线设计清楚。哪些事情适合交给模型判断,哪些信息必须由脚本先算出来,生成后又该用什么标准验证和回拉,这些编排层如果没有搭好,模型就很容易在空中自由发挥,最后看似跑了很多轮,却走不到正确结果。
真正能落地的方式,是先把工作流设计对:把任务拆小,把确定性部分前置计算,把模型输出放进可验证、可回滚、可反馈的闭环里。模型负责生成和判断,脚本负责测量和兜底,验证系统负责持续校准方向,最终把结果一点点推近目标。
欢迎交流,也欢迎试试你手上的 SVG 设计稿。