前言
AI 和 Agent 开发者几乎都会遇到这样的场景:脑海中智能交互的蓝图清晰无比,动手时却被繁杂的后端基建卡住------搭建服务架构、设计数据库表结构、配置认证体系、编写海量 API......好不容易让应用上线,新的问题又接踵而至:用户量未起时,闲置服务器空耗成本;用量起来后,流量洪峰又易引发服务崩溃。
在 TRAE 中构建 AI Agent 的浪潮中,是否有一种方案,能快速扫清后端障碍,让创意一键落地?今天,我们想与你分享一套实用的组合拳:TRAE × 火山引擎 Supabase。
这套组合旨在解决 AI 和 Agent 应用开发的"最后一公里"问题。TRAE 负责前端与 AI 逻辑的快速生成,而火山引擎 Supabase 则为你提供一个稳定、高效、开箱即用的后端服务(BaaS)。
现在,让我们一起探索,如何将这个强大的"数据引擎"集成到你的 TRAE 工作流中。
一、为什么选择这个组合?
在深入实践前,我们先花一分钟理解这个组合的价值所在。
- TRAE: 作为一个 AI 原生 IDE,它极大地加速了从想法到代码的过程。你可以通过自然语言生成项目、修复 Bug、优化代码,将开发重心完全放在"创造"本身。
- 火山引擎 Supabase: Suapbase 是最流行的后端服务部署产品,几乎所有 Vibe Coder 都对其熟知,目前已经成为 Lovable、Bolt 等第三方 Harness 的默认集成,以及 Codex、Claude Code 等 CLI agent 的 最佳后端推荐。火山引擎提供了 Suapbase 托管服务,你无需编写一行后端代码,就能获得一个功能完备的数据库、用户认证系统、对象存储,甚至边缘函数能力。
当两者结合,奇妙的化学反应便产生了:
- 开发效率最大化: TRAE 解决了前端和 AI 逻辑的创造问题,Supabase 解决了后端数据与服务的支撑问题。开发者可以真正专注于应用的核心价值。
- 全栈能力开箱即用: 你不再需要在前端和后端之间来回切换,也无需操心数据库的部署和运维。一个完整的全栈 AI 应用,在 TRAE 中就能闭环开发。
- 平滑的扩展曲线: 从一个简单的 Demo 小应用,到一个需要复杂用户系统和数据处理能力的正式产品,这套组合都能提供平滑的升级路径。
简而言之,TRAE 负责激发创意,火山引擎 Supabase 负责安放创意。
二、开始前的准备
在 TRAE 中接入火山引擎 Supabase,你只需要完成两项简单的准备工作。
1. 拥有 TRAE IDE
如果你的电脑上还没有安装 TRAE,可以访问 TRAE 官网(www.trae.cn/)进行下载和安装。
★
如果你的项目使用了 TRAE 国际版,这套开发与部署最佳实践同样适用。
2. TRAE 中安装 Skill,以驾驭火山引擎 Supabase
在 TRAE 中与火山引擎 Supabase 交互,我们推荐通过 Skill 完成。Skill 方式提供了更适合当前 AI 用法的命令。火山引擎 Supabase 提供了官方的 Skill 包,我们只需简单的安装,就可以使用全部服务。
- 通过自然语言安装
打开 TRAE AI 对话框,直接输入:
bash
请你下载这个压缩包 https://lf3-static.bytednsdoc.com/obj/eden-cn/veh7vhpeps/arkclaw-supabase-skills.zip 到临时目录,然后解压这个压缩包,byted-supabase 是一个Supabase skills,请你安装一下这个skills。volcengine-python-sdk-master 为其中的python依赖包火山引擎 Supabase 的使用指南,可参考 Findskill 中说明:findskill.com/bytedance/a...
三、动手实践:亲自从 0 到 1 构建一个待办事项记录应用
理论讲了这么多,接下来本章节将采用 Skill 方式,以创建一个经典的"待办事项(ToDo List)"应用为例,完整演示如何在 TRAE 工作区内,利用火山引擎 Supabase Skill,一站式完成从后端搭建、前端开发到应用发布的完整闭环。你将看到,整个过程无需离开 TRAE,创意即可高效落地。
告诉 TRAE 你的需求,它会自动生成包含数据库操作和 API 接口的后端代码。
步骤一:配置环境变量
-
配置火山引擎的 AK、SK: 登录火山引擎控制台,在"访问控制">"API 访问密钥"中创建并获取一对 Access Key ID 和 Secret Access Key。
在 TRAE 终端中,通过环境变量来配置凭证。可以将凭证存储在
~/.bash_profile或~/.zshrc等文件中,并由 TRAE 加载。
ini
export VOLCENGINE_ACCESS_KEY=YOUR_ACCESS_KEY_IDexport VOLCENGINE_SECRET_KEY=YOUR_SECRET_ACCESS_KEY- 验证安装成功: 可以在 Trae AI 对话框中,询问 AI 是否能正确使用 supabase skills。
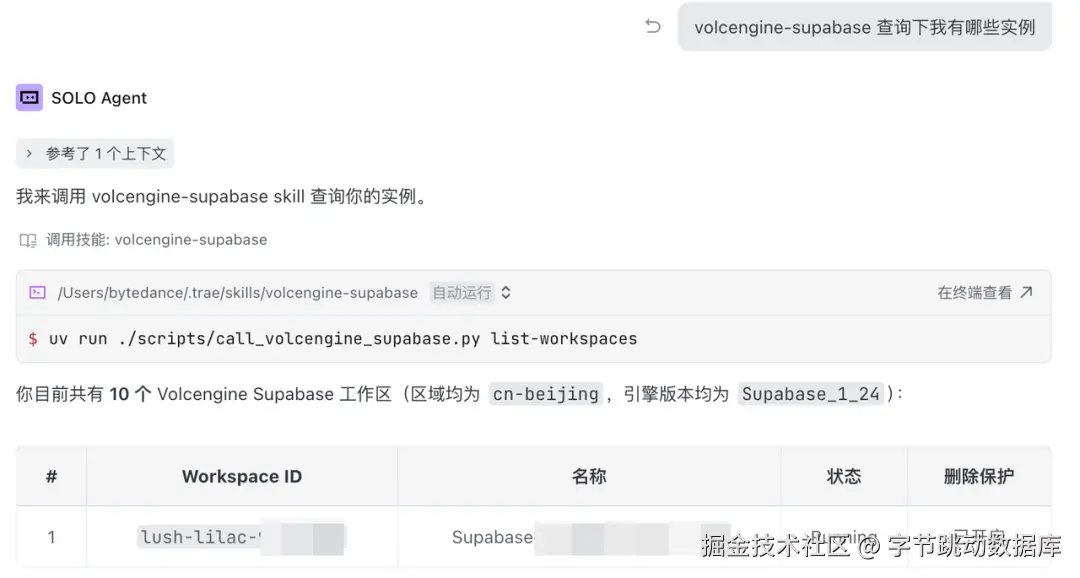
步骤二:创建 workspace 并获取信息
-
创建工作区: 一个工作区对应一个独立的 Supabase 项目。
帮我创建一个 火山引擎 supabase 工作区,名称为 todo-test
-
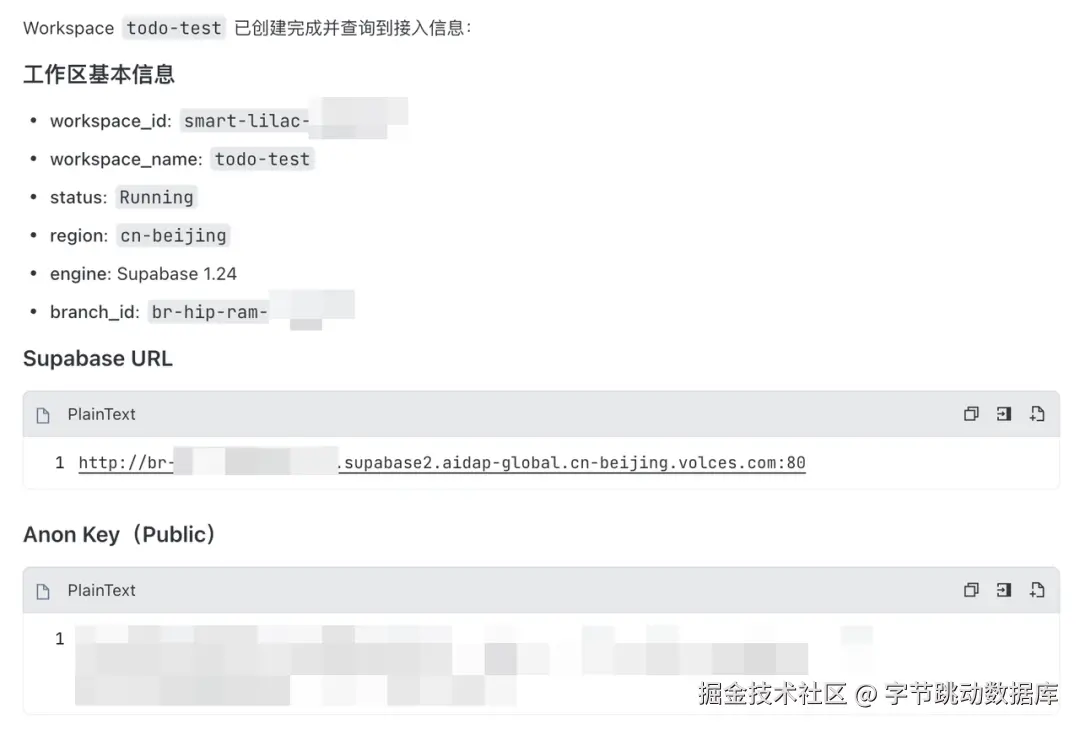
获取连接串: 在创建成功后,可以让 AI 这样获取到 URL 和
anon key。
vbnet
帮我查询 Supabase 的 URL,还有 anon key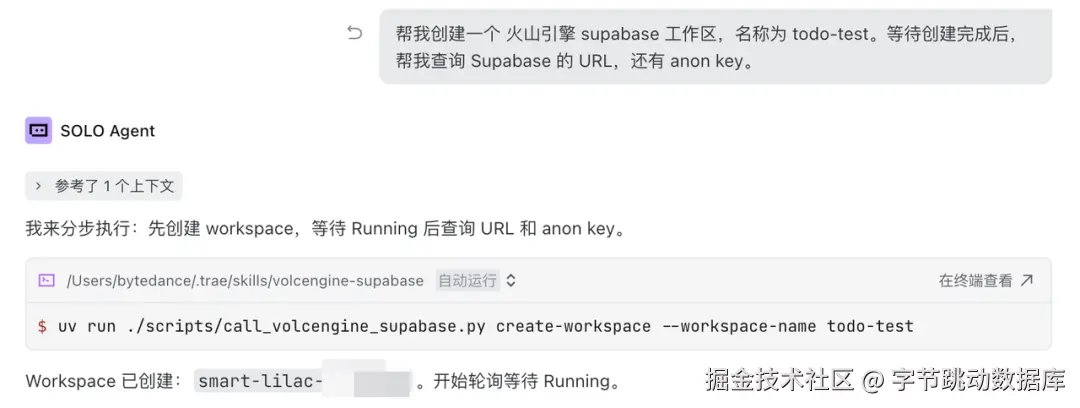
步骤三:数据面操作
- 执行 SQL 与启用扩展: 让 TRAE 为我们的应用创建 todos 表。
scss
在todo-test的数据库里,帮我创建一张名为 'todos' 的表,包含 id、task (文本)、is_completed (布尔)、created_at (时间戳) 字段。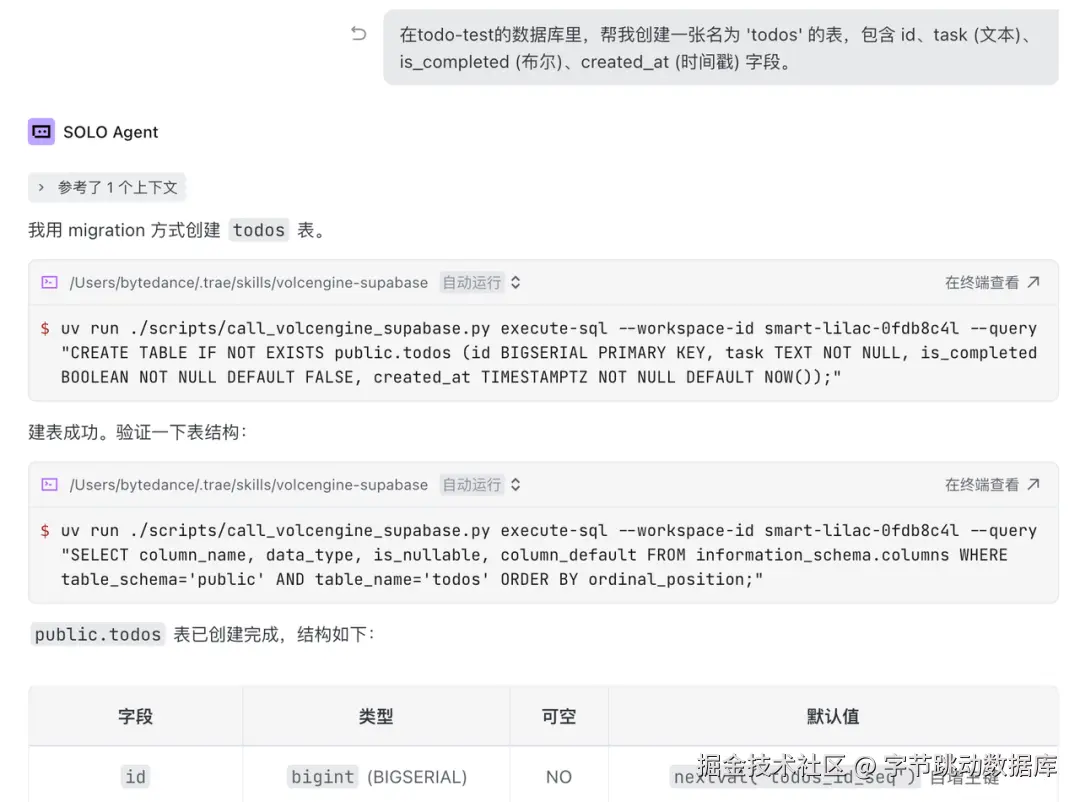
步骤四:开发后端接口与部署到 Edge Functions
- 生成后端代码: 告诉 TRAE 你的需求,它会自动生成包含数据库操作和 API 接口的后端代码。
go
请基于 Supabase skill,为我的待办事项 APP 开发一个完整的后端。它需要能对 'todos' 表进行增删改查。代码请生成在 `todo-app-backend` 目录。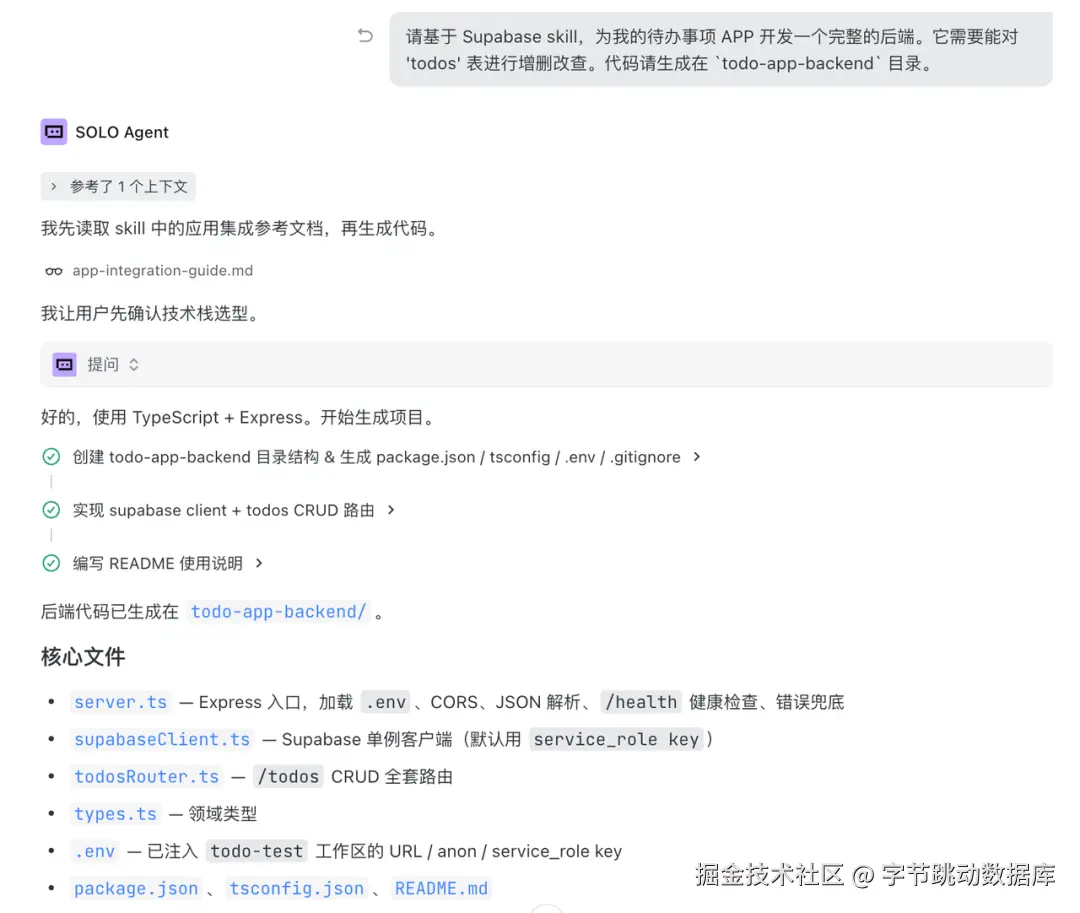
-
部署到 Edge Functions: 将生成的代码一键部署为无服务器函数。
请将 todo-app-backend 目录中的后端代码部署到 Edge Functions 中,并帮我验证一下各个接口是否可以正常访问。
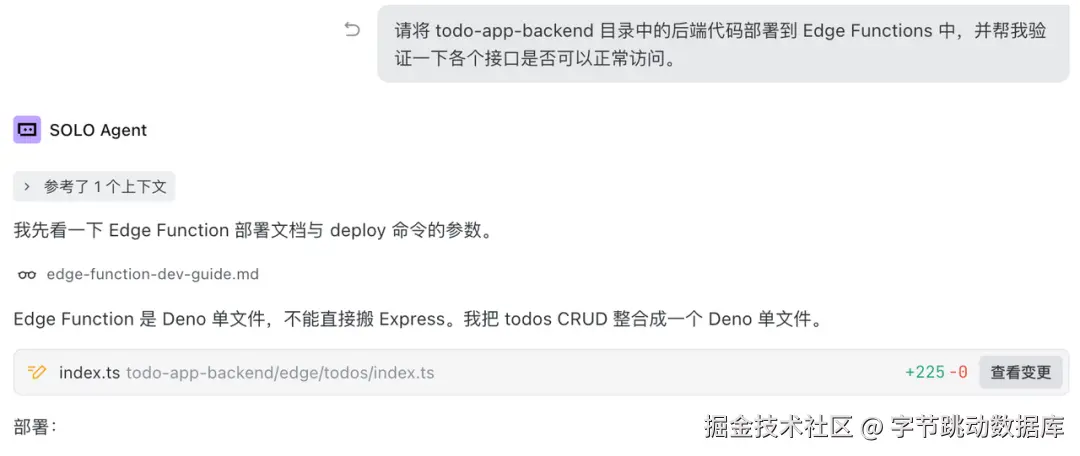

步骤五:开发前端并联通后端
-
开发前端: 为 Supabase 应用创建对应的前端代码。
后端已经部署好了,现在请为我开发一个配套的前端页面。要求支持任务的增删改查,并能调用刚才部署的后端接口。界面简洁美观,完成后在本地运行起来。代码请存放在 todo-app-frontend。
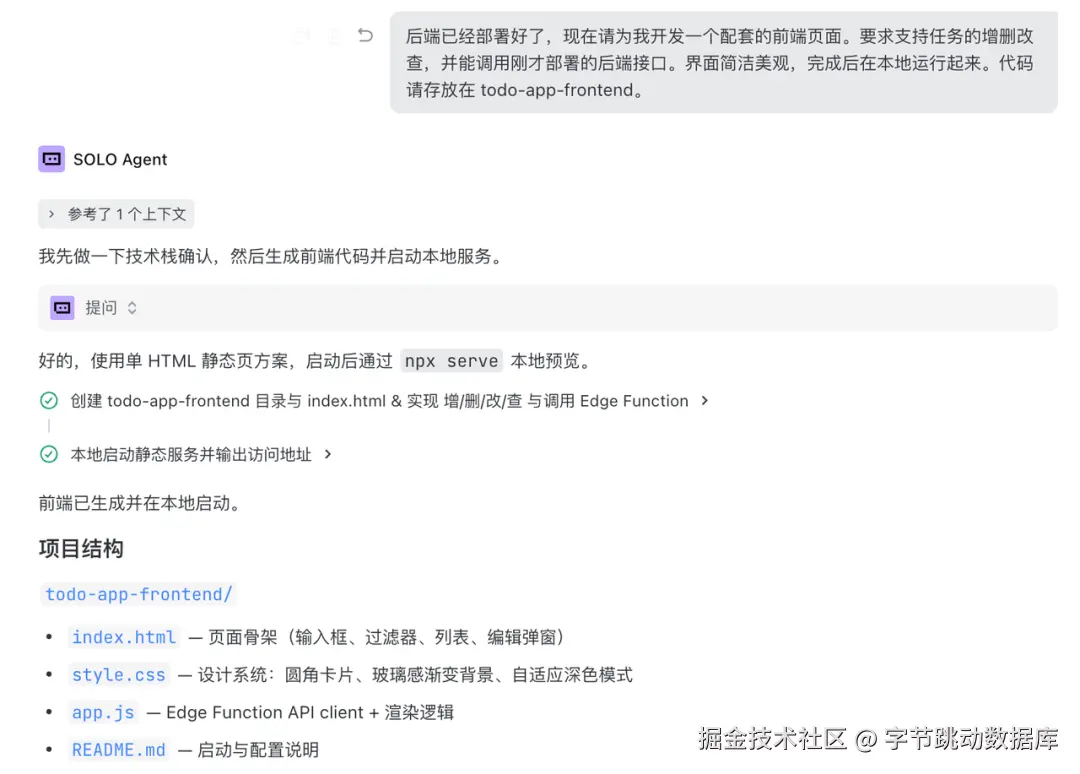
TRAE 会生成前端代码并在本地启动一个 Web 服务
★
如果期望将 Web 服务一键部署到火山引擎中,可以在 TRAE 中使用 IGA Pages 服务,具体参考《IGA Pages × TRAE :TRAE 如何快速实现一键部署》
步骤六:测试与交付
- 前端验证: 打开浏览器访问 TRAE 提供的本地地址,你应该能看到一个功能完整的待办事项应用。可以尝试添加、修改、删除任务,所有操作都会通过后端 API 实时同步到 Supabase 数据库。
- 数据确认: 你可以随时回到 Supabase 的控制台,检查 todos 表中的数据是否与前端操作一致,以确认整个链路已成功打通。
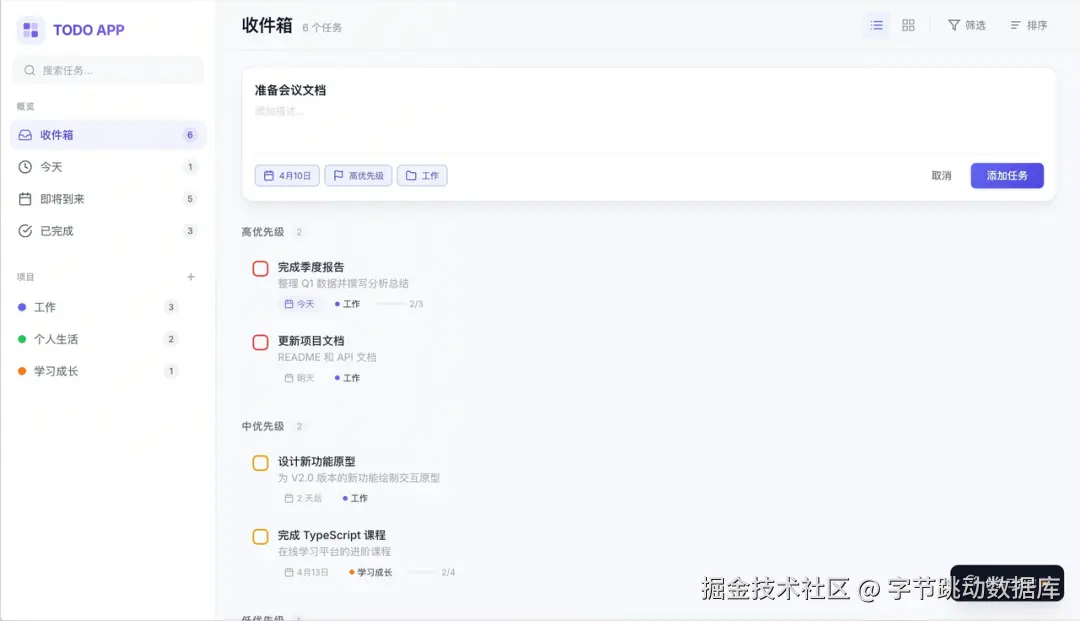
至此,你已经无需离开 TRAE,仅需几轮对话,就完成了从后端搭建、前端开发、联调测试到最终发布的全过程。一个由火山引擎 Supabase 驱动的 AI 应用,就这样诞生了。
写在最后
数据与后端基础设施交给 Supabase 托管,智能开发体验交给 TRAE,真正与业务场景深度绑定的仍然属于开发者与产品团队。更低的门槛,让不懂运维部署的同学也能自如落地一个有真实数据的 AI 应用;更顺畅的节奏,让从想法、建表、接口到前端 Demo 与发布变成一次连贯的对话。
现在就打开 TRAE,装上火山引擎 Supabase 这台"数据引擎",把你的第一个 AI 想法交给它,让一个真正可用、连通数据世界的智能应用,在几分钟内出现在所有人面前!
关注公众号"字节跳动数据库",获取更多技术干货!