【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Agent】【OpenCode】bash 工具提示词(完结)
分析了 bash 工具的参数说明,该提示词规定了 AI 在调用 bash 工具时,必须遵守的数据格式规范,并详细分析了其中的 4 个核心字段:command(核心指令,AI 必须在这里填入一条标准的 Linux Bash 命令),description(人类可读的摘要,这是给人看的,不是给机器看的,也是必填项,意味着 AI 不能只写命令,而不写解释),workdir(工作目录,环境上下文),用来解决路径依赖问题,AI 可以通过 workdir 参数设定命令执行目录,而不能在 bash 工具里使用 cd 命令随意改变工作目录,timeout(超时机制,AI 需要判断任务的轻重缓急来设定超时时间,防止任务无限期挂起),这套参数设计可以让整个自动化流程变得可审计,可追踪,可解释,用户看到的是一个带有自然语言解释的操作日志,下面继续分析
OpenCode
下面继续看下一个 Read 工具
其路径位于 opencode/packages/opencode/src/tool/read.txt
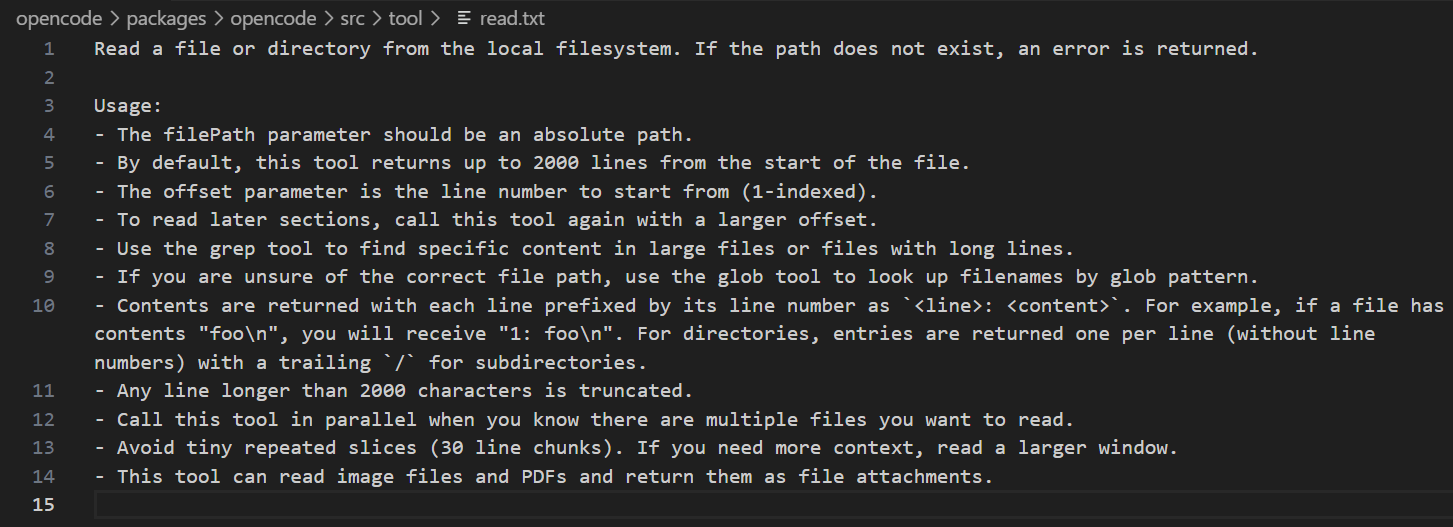
Read 工具可以读取文件或目录,如果路径不存在的话,返回错误,下面来看下使用说明
- 强制要求绝对路径 :提示词明确要求 AI 提供的 filePath 必须是绝对路径,比如
/home/admin/test.txt,而不是./test.txt,这意味着 AI 在读取文件之前,必须先明确知道文件在硬盘上的完整坐标,不能依赖相对路径,容易产生模糊性,以保证文件定位的绝对准确性 - 工具默认只返回文件开头的 2000 行,如果文件超过 2000 行,后面的内容将被截断
- 基于 offset(偏移量)的翻页机制:如果 AI 需要看文件后面的内容,必须再次调用工具,并传入 offset 参数(从第几行开始读,1-indexed 表示从 1 开始计数)
- 善用 Grep 工具:如果文件非常大(比如几十万行的日志),提示词这里就建议 AI 不要再用 offset 去一页页翻了,而是直接调用 Grep 工具去搜索特定内容,通过 Grep 工具去精准定位
- 如果 AI 不确定文件的具体路径 ,比如只知道一个叫
config.json的文件,但不知道在哪个文件夹下,这里提示词提示应该先用 Glob 工具(通配符模式查找文件)来下限定位文件的位置,再读取文件内容 - 锚点机制 :如果读的是文件内容,返回的不是纯文本,而是每行都带上了行号,格式为
<line>: <content>,而如果读的是目录(也就是文件夹),则会列出该目录下的所有条目,并在子目录的末尾处加上/斜杠作为区分 - 超长行截断保护:如果某一行超过 2000 个字符,会被强制截断,防止某些被压缩过,没有换行符的巨型日志或乱码文件,瞬间撑爆 OpenCode 的上下文窗口,导致系统崩溃或响应变慢
- 并行读取:如果 AI 准备读 A,B,C 三个文件,应该同时发出三个去读请求,而不是读完 A 再读 B,这是最大化执行效率的关键
- 避免挤牙膏式的读取:这里提示词特意强调,避免每次只读 30 行这种小段落,如果每次只读一点点,那读完一个 2000 行的文件就要调用 60 多次工具,会极大地浪费系统资源并拖慢速度,所以如果需要上下文,就应该一次性读一个大点的窗口,比如一次读 500 行或 1000 行
- 多媒体文件读取 :当遇到如
.jpg,.png或.pdf文件时,OpenCode 不会尝试将它们当作文本去解析(那样只会得到一堆乱码),而是会直接将这些多媒体文件作为文件附件返回,这意味着 AI 具备了看到图片和 PDF 内容的能力,可以通过多模态视觉模型来识别
这套读取规则可以让 AI 在处理本地代码库或文档时,既能保证速度,又能精准命中用户需要的信息
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Agent】【OpenCode】glob 工具提示词