DeepStream 传统上更多用于结构化视频分析,例如目标检测、跟踪、分类、OSD 叠加和消息发送。但在新的 deepstream-vllm-plugin 示例中,DeepStream 被用来连接 Vision-Language Model,让视频流可以被大模型"看懂",并输出自然语言描述。
这个示例的核心思路是:
DeepStream 负责视频 pipeline,vLLM 负责大模型推理, nvvllmvlm 插件负责把视频帧送给 VLM。
整体 Pipeline
示例中的 pipeline 大致如下:
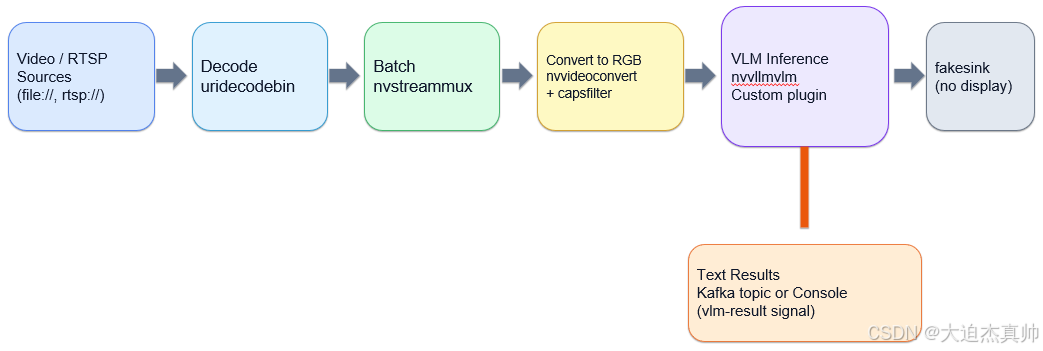
也就是说,输入仍然是普通视频文件或 RTSP 流。DeepStream 完成解码、batch、颜色格式转换,然后把 RGB 视频帧送入自定义插件 nvvllmvlm。nvvllmvlm 是把采样后的视频帧交给 VLM 做理解,最后输出文本结果。
功能简介
Segment-Based Processing:基于时间片段的视频处理
插件不会对每一帧都立即调用 VLM。它会先把视频流按照时间切成一个个 segment,例如每 5 秒或 30 秒一个片段,然后从这个片段里采样若干帧,最后把这些帧一起送给 VLM 推理。
这样做的好处是:
- 降低 VLM 推理频率,减少 GPU 压力
- 给模型一段时间范围内的上下文,而不是单帧图像
- 更适合生成"这段视频发生了什么"的自然语言描述
Flexible Frame Sampling:灵活的帧采样
插件支持两种采样方式:
- 按 FPS 采样,例如每秒取 1 帧
- 按间隔采样,例如每 N 帧取 1 帧
这很重要,因为 VLM 不一定需要看所有帧。对于场景描述、安全监控、事件总结等任务,通常只需要抽样帧即可。
例如:
segment:
length_sec: 5
selection_fps: 1
表示每 5 秒一个 segment,每秒采样 1 帧。
Async Inference:异步推理
VLM 推理通常比较慢。如果在 GStreamer pipeline 的主处理路径里同步等待模型输出,整个视频 pipeline 可能被阻塞。
这个插件使用后台 worker thread 做推理:
DeepStream pipeline 收帧
→ segment 满足条件后提交任务
→ 后台线程调用 vLLM
→ 推理完成后发出 result signal
这样视频 pipeline 可以继续运行,不必每次都卡住等 VLM 输出。
Multi-Stream Support:多路视频流支持
一个插件实例可以处理多路视频流。每一路 stream 都有自己的上下文,包括:
- 当前 segment
- 已处理帧数
- 已提交 segment 数量
- 最新推理结果
但所有 stream 共享同一个 VLM 模型实例。这样比"每路视频加载一个模型"更节省 GPU memory。
Per-Stream Prompts:每路视频使用不同 Prompt
多路视频可能来自不同场景,比如:
- stream 0 是仓库监控
- stream 1 是道路交通
- stream 2 是门店客流
它们需要不同的分析指令。插件支持在配置里给不同 stream 设置不同 prompt:
inference:
stream_prompts:
0:
user_prompt: "Monitor for warehouse safety hazards."
system_prompt: "You are a warehouse safety analyst."
1:
user_prompt: "Analyze traffic flow."
这样同一个 VLM 插件可以对不同视频流执行不同分析任务。
Configurable Models:可配置模型
默认模型是:
path: "nvidia/Cosmos-Reason2-8B"
但你可以换成其他 vLLM 支持的 VLM,例如 Qwen-VL 类模型。
同时可以配置:
max_model_lengpu_memory_utilizationtrust_remote_codevideo_modetensor_format
这让 sample 不绑定某一个固定模型,而是可以根据模型能力和硬件资源调整。
GPU-Optimized:面向 GPU 优化
DeepStream 本身使用 GPU/NVMM memory 处理视频帧,插件也尽量保持 GPU 路径。
典型流程是:
DeepStream RGB NVMM frame
→ buffer.extract()
→ DLPack
→ PyTorch tensor
→ vLLM inference
这样可以减少不必要的 CPU/GPU 数据拷贝。
另外,插件只加载一个 VLM 模型实例,并让多路流共享它,从而减少 GPU memory 占用。
需要注意:如果配置 tensor_format: pil 或 numpy,帧会转到 CPU 格式,因此不再是全程 zero-copy。
Flexible Input Formats:灵活的 VLM 输入格式
这里的输入格式不是指 DeepStream source 输入格式。DeepStream source 仍然是:
file://
rtsp://
video file path
"Flexible Input Formats" 指的是插件把 DeepStream 帧转换后,传给 VLM 的格式。
支持:
- PyTorch tensor
- PIL Image
- NumPy array
不同 VLM 或 Hugging Face processor 可能要求不同的输入格式,所以这个配置提高了模型兼容性。
例如:
model:
tensor_format: "numpy"
常用于 image-only VLM 模型。
为什么使用 vLLM?
VLM 模型,例如 Cosmos-Reason2、Qwen-VL 等,通常比传统检测模型大很多。它们不仅看图像,还要结合 prompt 生成文本,因此需要更适合大模型推理的后端。
这个示例使用 vLLM,是因为 vLLM 可以:
- 加载 Hugging Face 上的 VLM 模型
- 支持 multimodal input
- 支持图像或视频输入格式
- 管理大模型的 GPU memory
- 用一个模型实例服务多路视频流
代码中只创建了一个共享的 vLLM 模型实例:
python
self.llm = LLM(
model=self.model,
max_model_len=self.max_model_len,
trust_remote_code=self.trust_remote_code,
gpu_memory_utilization=self.gpu_memory_utilization,
enforce_eager=True,
max_num_seqs=1,
)这意味着多路视频流不会每一路都加载一份模型,而是共享同一个 VLM backend。
Segment-Based Processing
VLM 推理很重,所以示例不是每一帧都调用模型,而是把视频按时间切成 segment。
例如配置中:
bash
segment:
length_sec: 5
overlap_sec: 0
subsample_interval: 1
selection_fps: 1含义是:
- 每 5 秒作为一个视频片段
- 每秒选择一定数量的帧
- 把这些采样帧组成一个 segment
- 对这个 segment 做一次 VLM 推理
这样可以在性能和语义理解之间取得平衡。VLM 不需要看每一帧,也可以理解一段时间内发生了什么。
配置 VLM 模型
默认配置使用 Cosmos Reason 2:
bash
model:
path: "nvidia/Cosmos-Reason2-8B"
max_model_len: 8192
trust_remote_code: true
gpu_memory_utilization: 0.3
gpu_id: 0
video_mode: 1
tensor_format: "pytorch"其中最重要的是 video_mode:
video_mode: 1 表示使用 video-native 模式,把多帧作为视频输入交给 VLM。
如果使用 image-only VLM,例如某些 Qwen-VL 模型,可以改成:
bash
model:
path: "Qwen/Qwen2.5-VL-7B-Instruct"
video_mode: 0
tensor_format: "numpy"video_mode: 0 表示把采样帧作为多张 image 输入,而不是一个 video 输入。
输入格式是什么意思?
配置里有:
tensor_format: "pytorch"
可选值包括:
pytorch
pil
numpy
这不是说 DeepStream source 可以直接输入 PyTorch / PIL / NumPy。DeepStream 的输入仍然是视频或 RTSP。
真正含义是:nvvllmvlm 从 DeepStream buffer 中提取 RGB frame 后,可以把 frame 转换成不同的 Python 数据格式,再交给 vLLM。
例如 image mode 中,插件会把每一帧转换为指定格式:
python
image_tensors = [
self._convert_tensor_to_format(
batch_tensor[i], self.tensor_format
)
for i in range(num_frames)
]
inputs = {
"prompt": prompt_text,
"multi_modal_data": {"image": image_tensors},
}所以:
pytorch:传 PyTorch tensorpil:传 PIL Imagenumpy:传 NumPy array
不同 VLM 或 processor 对输入格式要求不同,这个配置提供了灵活性。
Prompt 与输出
VLM 的能力来自"图像/视频 + prompt"。配置里可以写:
python
inference:
user_prompt: "Describe what you see in detail"
max_tokens: 128
temperature: 0.7也可以使用占位符:
python
user_prompt: "These are {num_frames} frames from stream {stream_id}, sampled at {timestamps}. Describe the scene."插件推理完成后,会发出 vlm-result signal。应用可以把结果打印到 console,也可以发送到 Kafka。
运行 dry-run 模式:
python
python3 vllm_ds_app_kafka_publish.py \
/opt/nvidia/deepstream/deepstream-9.0/samples/streams/sample_1080p_h264.mp4 \
--dry-run多路视频:
python
python3 vllm_ds_app_kafka_publish.py video1.mp4 video2.mp4 --dry-run发送到 Kafka:
python
python3 vllm_ds_app_kafka_publish.py video1.mp4 video2.mp4 \
--kafka-bootstrap localhost:9092 \
--topic vlm-results这个示例适合什么场景?
传统 DeepStream 检测模型通常回答:
画面里有什么目标?
目标在哪里?
目标 ID 是多少?
VLM 可以回答更高层的问题:
这段视频发生了什么?
是否有异常行为?
交通是否拥堵?
仓库是否有安全隐患?
画面中人物在做什么?
因此,这个示例适合:
- 视频摘要
- 安防场景理解
- 交通事件描述
- 工业巡检解释
- 多路视频自然语言分析
- 将视频理解结果发送到 Kafka 给下游系统
总结
deepstream-vllm-plugin 展示了一种新的 DeepStream 使用方式:
DeepStream 管视频流
vLLM 管大模型
VLM 负责语义理解
Kafka / Console 输出文本结果
这种架构把 DeepStream 的实时视频处理能力和 VLM 的自然语言理解能力结合起来,让视频分析从"检测目标"进一步扩展到"理解场景"。