机器学习基础术语
学习机器学习就像学习一门新语言,需要先掌握基本词汇。这些术语构成了机器学习的"语言系统",理解它们是深入学习的第一步。
想象一下你在教一个机器人认识水果:
- 数据:各种水果的图片和信息
- 特征:水果的颜色、形状、大小、味道
- 标签:这个水果叫什么名字(苹果、香蕉、橙子)
- 模型:机器人学到的"识别水果的方法"
- 训练:教机器人认识水果的过程
- 推理:机器人识别新水果的能力
数据(Data)
什么是数据?
数据是机器学习的"原材料",就像厨师做菜需要的食材一样。没有数据,机器学习就无法进行。

数据的类型
1. 结构化数据
特点:有明确的格式和组织方式,像表格一样整齐
结构化数据示例:学生信息表
实例
import pandas as pd
students_data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [18, 19, 20],
'成绩': [85, 92, 78],
'班级': ['一班', '二班', '一班']
}
df = pd.DataFrame(students_data)
print(df)输出:
姓名 年龄 成绩 班级
0 张三 18 85 一班
1 李四 19 92 二班
2 王五 20 78 一班2. 非结构化数据
特点:没有固定格式,需要特殊处理
例子:
-
文本:评论、文章、邮件
-
图像:照片、医学影像
-
音频:语音、音乐
-
视频:监控录像、电影
非结构化数据示例:文本和图像
text_data = "这个产品质量很好,我很满意!"
image_data = 一张产品的照片
audio_data = 顾客的语音评价
数据质量的重要性
垃圾进,垃圾出(Garbage In, Garbage Out)是机器学习的重要原则。数据质量直接决定模型效果。
实例
# 数据质量问题示例
import numpy as np
import pandas as pd
# 创建包含各种问题的数据
problematic_data = {
'价格': [100, 200, None, 300, -50], # 缺失值和异常值
'评分': [4.5, '好', 3.8, 4.2, 5.0], # 数据类型不一致
'销量': [1000, 1200, 800, 1500, '很多'] # 文本和数字混合
}
df = pd.DataFrame(problematic_data)
print("有问题的数据:")
print(df)
print("\n数据问题分析:")
print(f"缺失值数量:{df.isnull().sum().sum()}")
print(f"数据类型:\n{df.dtypes}")特征(Feature)
什么是特征?
特征是数据的"可观察属性",就像描述一个人的特征:身高、体重、发色、性格等。在机器学习中,特征是用来做预测的依据。
特征选择的重要性:
- 好的特征能让模型事半功倍
- 坏的特征会让模型事倍功半
- 特征工程往往是决定模型效果的关键
特征的类型
x1. 数值特征
特点:可以用数字表示,可以进行数学运算
# 数值特征示例
numerical_features = {
'年龄': [25, 30, 35, 40],
'收入': [5000, 8000, 12000, 15000],
'身高': [165, 170, 175, 180]
}2. 类别特征
特点:表示不同的类别,不能进行数学运算
# 类别特征示例
categorical_features = {
'性别': ['男', '女', '男', '女'],
'学历': ['本科', '硕士', '博士', '本科'],
'城市': ['北京', '上海', '广州', '深圳']
}3. 文本特征
特点:需要特殊处理才能被模型使用
# 文本特征示例
text_features = {
'评论': [
'这个产品很好用,推荐购买!',
'质量一般,不太满意。',
'性价比高,值得入手。'
]
}特征工程示例
# 特征工程示例:从原始数据创建有用特征
import pandas as pd
import numpy as np
# 原始数据:房屋信息
house_data = {
'面积': [80, 120, 60, 150, 90],
'卧室数': [2, 3, 1, 4, 2],
'建造年份': [2000, 2010, 1995, 2015, 2005],
'价格': [200, 350, 150, 500, 280]
}
df = pd.DataFrame(house_data)
# 创建新特征
df['房龄'] = 2023 - df['建造年份'] # 房屋年龄
df['每平米价格'] = df['价格'] / df['面积'] # 单价
df['卧室面积比'] = df['卧室数'] / df['面积'] * 100 # 卧室占比
print("原始数据 + 新特征:")
print(df)
# 特征重要性分析
correlation = df.corr()['价格'].sort_values(ascending=False)
# df.corr() 计算所有特征之间的相关系数矩阵
# ['价格'] 选取与"价格"的相关系数列
# sort_values(ascending=False) 按相关系数从大到小排序
print("\n特征与价格的相关性:")
print(correlation)标签(Label)
什么是标签?
标签是我们想要预测的"答案",就像考试题的正确答案一样。在监督学习中,每个数据样本都有一个对应的标签。
标签的作用:
- 指导模型学习方向
- 评估模型学习效果
- 定义问题的类型
标签的类型
1. 分类标签
特点:离散的类别值
# 分类标签示例
classification_labels = {
'邮件类型': ['垃圾邮件', '正常邮件', '垃圾邮件', '正常邮件'],
'情感倾向': ['正面', '负面', '中性', '正面'],
'疾病诊断': ['患病', '健康', '健康', '患病']
}2. 回归标签
特点:连续的数值
# 回归标签示例
regression_labels = {
'房价': [250000, 320000, 180000, 450000],
'温度': [25.5, 28.3, 22.1, 30.0],
'股票价格': [100.5, 105.2, 98.7, 110.3]
}标签质量的重要性
# 标签质量问题示例
import numpy as np
# 模拟图像分类任务中的标签问题
image_data = ['cat1.jpg', 'dog1.jpg', 'cat2.jpg', 'dog2.jpg']
problematic_labels = ['猫', '犬', '猫咪', '狗'] # 标签不一致
# 标签标准化
label_mapping = {
'猫': 'cat', '猫咪': 'cat',
'犬': 'dog', '狗': 'dog'
}
standardized_labels = [label_mapping[label] for label in problematic_labels]
print("原始标签:", problematic_labels)
print("标准化标签:", standardized_labels)模型(Model)
什么是模型?
模型是机器学习算法从数据中学到的"规律"或"模式",就像学生从课本中学到的知识一样。
模型的本质:
- 数学函数:输入特征,输出预测
- 参数集合:学到的规律的具体表示
- 决策规则:如何从输入得到输出
模型的表示
# 简单线性模型示例
import numpy as np
import matplotlib.pyplot as plt
# 模拟数据
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 6, 8, 10])
# 线性模型:y = w * x + b
# 学习到的参数:w = 2, b = 0
w, b = 2, 0
def linear_model(x):
"""线性模型函数"""
return w * x + b
# 预测
predictions = linear_model(X)
# 可视化
plt.scatter(X, y, color='blue', label='真实数据')
plt.plot(X, predictions, color='red', label='模型预测')
plt.xlabel('输入 X')
plt.ylabel('输出 y')
plt.title('线性模型示例')
plt.legend()
plt.grid(True)
plt.show()
print(f"模型参数:w = {w}, b = {b}")
print(f"预测结果:{predictions}")模型的复杂度
# 模型复杂度对比
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
import numpy as np
# 生成非线性数据
np.random.seed(42)
X = np.random.rand(20, 1) * 10
y = np.sin(X) + np.random.randn(20, 1) * 0.1
# 简单模型(线性)
simple_model = LinearRegression()
simple_model.fit(X, y)
# 复杂模型(高次多项式)
poly_features = PolynomialFeatures(degree=10)
X_poly = poly_features.fit_transform(X)
complex_model = LinearRegression()
complex_model.fit(X_poly, y)
# 可视化
X_test = np.linspace(0, 10, 100).reshape(-1, 1)
X_test_poly = poly_features.transform(X_test)
plt.scatter(X, y, color='blue', label='训练数据')
plt.plot(X_test, simple_model.predict(X_test), color='green', label='简单模型')
plt.plot(X_test, complex_model.predict(X_test_poly), color='red', label='复杂模型')
plt.xlabel('X')
plt.ylabel('y')
plt.title('模型复杂度对比')
plt.legend()
plt.grid(True)
plt.show()简单模型
y = w₀ + w₁ × x特点:
-
参数数量:2 个(截距 + 斜率)
-
拟合能力:只能捕捉线性关系
-
对非线性数据会欠拟合
PolynomialFeatures 的作用:
原始特征 x 被扩展为:
[1, x, x², x³, x⁴, x⁵, x⁶, x⁷, x⁸, x⁹, x¹⁰]模型形式:
y = w₀ + w₁×x + w₂×x² + w₃×x³ + ... + w₁₀×x¹⁰特点:
-
参数数量:11 个
-
拟合能力:非常灵活,可以拟合复杂曲线
-
对噪声数据容易过拟合
训练(Training)
什么是训练?
训练是模型学习的过程,就像学生上课学习知识一样。在训练过程中,模型不断调整参数,使预测结果越来越接近真实标签。
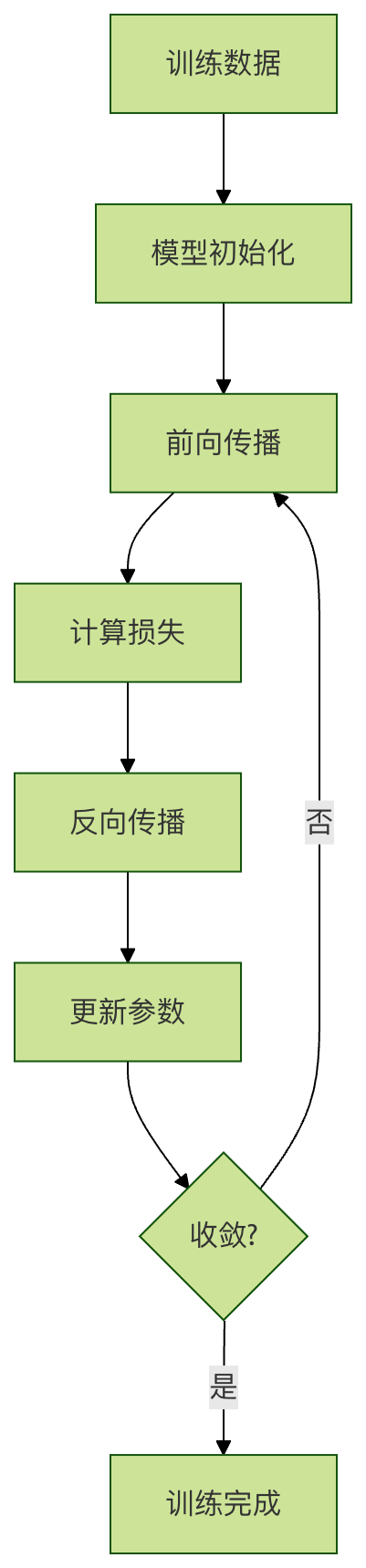
训练过程示例
# 训练过程示例:简单线性回归
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 生成训练数据
np.random.seed(42)
X = np.random.rand(50, 1) * 10
y = 3 * X + 2 + np.random.randn(50, 1) * 2
# 初始化模型参数
w, b = 0.0, 0.0
learning_rate = 0.01
epochs = 100
# 记录训练过程
loss_history = []
# 训练循环
for epoch in range(epochs):
# 前向传播
y_pred = w * X + b
# 计算损失(均方误差)
loss = np.mean((y_pred - y) ** 2)
loss_history.append(loss)
# 计算梯度
dw = np.mean(2 * X * (y_pred - y))
db = np.mean(2 * (y_pred - y))
# 更新参数
w -= learning_rate * dw
b -= learning_rate * db
if epoch % 10 == 0:
print(f"Epoch {epoch}: Loss = {loss:.4f}, w = {w:.4f}, b = {b:.4f}")
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(loss_history)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('训练损失变化')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.scatter(X, y, color='blue', label='训练数据')
plt.plot(X, w * X + b, color='red', label='训练后的模型')
plt.xlabel('X')
plt.ylabel('y')
plt.title('训练结果')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
print(f"最终模型参数:w = {w:.4f}, b = {b:.4f}")梯度下降训练过程详解
这个训练循环是机器学习最核心的算法------梯度下降。下面我从"为什么这样做"的角度,逐步解释每一步的数学原理和直观理解。
一、整体目标:我们要解决什么问题?
问题定义
我们有一组数据 (X, y),假设它们满足线性关系:
y_true = w × X + b + 噪声我们的任务 :找到最优的 w(权重)和 b(偏置),让模型的预测值 y_pred = w × X + b 尽可能接近真实值 y。
直观理解
想象你在一个山谷中(代表损失函数),你的目标是走到最低点(最小化损失):
text
损失
↑
| ★ 最优点(我们要找到这里)
| /
| /
| ● 起点 /
| ↘ /
| ↘ /
| ◆
+----------------→ 参数 (w, b)核心问题:如何从起点走到最低点?
二、为什么需要"迭代"(for epoch in range(epochs))?
问题:一次计算就能找到最优解吗?
答案:对于简单问题(如线性回归),理论上可以一步求解(正规方程),但:
| 方法 | 公式 | 优点 | 缺点 |
|---|---|---|---|
| 正规方程 | w = (X^T X)^(-1) X^T y | 一步到位 | 矩阵求逆慢,数据量大时不可行 |
| 梯度下降 | 逐步迭代 | 可扩展,适用于大数据 | 需要多步迭代 |
为什么用迭代:
-
数据量大时,正规方程无法计算(矩阵求逆复杂度 O(n³))
-
深度学习中,损失函数极其复杂,无法一步求解
-
迭代方法更符合"学习"的直觉------逐步改进
"学习"的本质
初始状态(无知)→ 犯错 → 吸取教训 → 改进 → 再次犯错(更小)→ ... → 掌握规律三、前向传播:y_pred = w * X + b
这一步在做什么?
作用 :使用当前的参数 (w, b) 对输入 X 进行预测。
为什么要这样做?
这是"评估当前模型表现"的必要步骤。就像考试前先做题,看看自己能得多少分。
示例计算
假设:
-
X = 1, 2, 3, 4, 5(5个样本)
-
w = 0.5, b = 1(当前参数)
y_pred = 0.5 × X + 1
结果: [1.5, 2.0, 2.5, 3.0, 3.5]
关键点
-
这是前向传播(信息从输入流向输出)
-
当前预测很可能很差(初始时 w=0, b=0 → 预测全部为 0)
-
我们需要知道"有多差"才能改进
四、计算损失:loss = np.mean((y_pred - y) ** 2)
这一步在做什么?
作用:量化当前模型的预测误差有多大。
为什么用均方误差(MSE)?
| 损失函数 | 公式 | 特点 |
|---|---|---|
| 绝对误差 | |y_pred - y| | 不可导(在0点) |
| 均方误差 | (y_pred - y)² | 处处可导,放大较大误差 |
| Huber | 混合 | 鲁棒但复杂 |
选择 MSE 的原因:
-
可导:我们需要梯度来更新参数
-
凸函数:只有一个全局最小值(容易优化)
-
放大较大误差:让模型更关注预测很差的样本
详细计算示例
假设:
-
y_pred = 1.5, 2.0, 2.5, 3.0, 3.5
-
y_true = 2.0, 2.5, 3.0, 3.5, 4.0
步骤1:计算误差
errors = y_pred - y_true = [-0.5, -0.5, -0.5, -0.5, -0.5]
步骤2:平方
squared_errors = [0.25, 0.25, 0.25, 0.25, 0.25]
步骤3:求平均
loss = (0.25 + 0.25 + 0.25 + 0.25 + 0.25) / 5 = 0.25
损失的含义
| 损失值 | 含义 |
|---|---|
| 0 | 完美预测 |
| 越小 | 预测越准 |
| 越大 | 预测越差 |
损失就像考试分数:我们希望分数(损失)越来越低。
五、计算梯度:dw = np.mean(2 * X * (y_pred - y)) 和 db = np.mean(2 * (y_pred - y))
这一步在做什么?
作用 :计算损失函数对参数 w 和 b 的"敏感度"------如果稍微改变 w,损失会如何变化?
为什么需要梯度?
梯度告诉我们方向:
-
站在山谷的某一点
-
梯度指向上升最快的方向(上坡)
-
我们要去最低点,所以应该往梯度的反方向走
数学推导(为什么是这个公式?)
损失函数定义
L = (1/n) × Σ (y_pred_i - y_i)²
其中 y_pred_i = w × x_i + b对 w 求偏导
∂L/∂w = (1/n) × Σ 2 × (y_pred_i - y_i) × (∂y_pred_i/∂w)
= (1/n) × Σ 2 × (y_pred_i - y_i) × x_i
= np.mean(2 × X × (y_pred - y))对 b 求偏导
∂L/∂b = (1/n) × Σ 2 × (y_pred_i - y_i) × (∂y_pred_i/∂b)
= (1/n) × Σ 2 × (y_pred_i - y_i) × 1
= np.mean(2 × (y_pred - y))梯度的直观理解
对于 w(权重):
-
dw的正负取决于X和(y_pred - y)的乘积 -
如果预测值偏大(y_pred > y),且 X 为正,
dw > 0→ 需要减小 w -
如果预测值偏小(y_pred < y),且 X 为正,
dw < 0→ 需要增大 w
对于 b(偏置):
-
db的正负取决于整体误差的方向 -
如果大部分预测偏大(y_pred > y),
db > 0→ 需要减小 b -
如果大部分预测偏小(y_pred < y),
db < 0→ 需要增大 b
具体数值示例
假设:
-
X = 1, 2, 3, 4, 5
-
y_pred = 1.5, 2.0, 2.5, 3.0, 3.5
-
y_true = 2.0, 2.5, 3.0, 3.5, 4.0
-
errors = -0.5, -0.5, -0.5, -0.5, -0.5
计算 dw
terms = 2 * X * errors = 2 × [1,2,3,4,5] × [-0.5,-0.5,-0.5,-0.5,-0.5]
= [-1, -2, -3, -4, -5]
dw = mean(terms) = -3.0计算 db
terms = 2 * errors = [-1, -1, -1, -1, -1]
db = mean(terms) = -1.0
解释:
-
dw = -3.0:增加 w 会减少损失(因为负梯度) -
db = -1.0:增加 b 会减少损失
六、更新参数:w -= learning_rate * dw 和 b -= learning_rate * db
这一步在做什么?
作用:根据梯度的方向,调整参数,使损失减小。
为什么是"减"而不是"加"?
w = w - learning_rate × dw原因:
-
梯度
dw指向损失增加最快的方向 -
我们要减小损失,所以往反方向走
-
因此是减去梯度乘以学习率
学习率的作用
学习率控制步长大小:
# 学习率太小(步长小)
新参数 = 旧参数 - 0.001 × dw # 走得慢,需要很多步
# 学习率适中(推荐)
新参数 = 旧参数 - 0.01 × dw # 稳步下降
# 学习率太大(步长大)
新参数 = 旧参数 - 0.5 × dw # 可能跳过最优点,甚至发散可视化:学习率的影响
损失
↑
| 学习率太小:步长小,需要很多步
| →→→→→→→→→→→→→→→→→→→→→→
|
| 学习率适中:稳步下降
| ↘
| ↘
| ◆ 最优点
|
| 学习率太大:震荡
| ↘ ↗ ↘ ↗
| ↙ ↘ ↙
+----------------→ 参数具体计算示例
接上例:
-
dw = -3.0, db = -1.0
-
learning_rate = 0.01
-
当前 w = 0.5, b = 1.0
w_new = 0.5 - 0.01 × (-3.0) = 0.5 + 0.03 = 0.53
b_new = 1.0 - 0.01 × (-1.0) = 1.0 + 0.01 = 1.01
观察:
-
dw 为负数 → 我们需要增加 w
-
更新后 w 从 0.5 增加到 0.53 ✓
-
db 为负数 → 我们需要增加 b
-
更新后 b 从 1.0 增加到 1.01 ✓
推理(Inference)
什么是推理?
推理是使用训练好的模型进行预测的过程,就像学生用学到的知识解答考试题一样。
推理过程示例
# 推理过程示例
import numpy as np
# 假设我们已经训练好了一个房价预测模型
class HousePriceModel:
def __init__(self):
# 模拟训练好的参数
self.feature_weights = {
'面积': 2.5,
'卧室数': 10.0,
'房龄': -1.0,
'地段评分': 50.0
}
self.bias = 50.0
def predict(self, features):
"""
使用训练好的模型进行房价预测
"""
price = self.bias
for feature_name, feature_value in features.items():
if feature_name in self.feature_weights:
price += self.feature_weights[feature_name] * feature_value
return price
# 创建训练好的模型
model = HousePriceModel()
# 推理:预测新房价
new_houses = [
{'面积': 80, '卧室数': 2, '房龄': 5, '地段评分': 8},
{'面积': 120, '卧室数': 3, '房龄': 2, '地段评分': 9},
{'面积': 60, '卧室数': 1, '房龄': 10, '地段评分': 6}
]
print("房价预测结果:")
for i, house in enumerate(new_houses, 1):
predicted_price = model.predict(house)
print(f"房子{i}:预测价格 {predicted_price:.2f} 万元")
# 批量推理
def batch_predict(model, house_list):
"""批量预测"""
return [model.predict(house) for house in house_list]
batch_prices = batch_predict(model, new_houses)
print(f"\n批量预测结果:{batch_prices}")常见机器学习网络类型
| 模型类型 | 中文全称 | 英文简写 | 核心适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 传统机器学习 | 决策树 | DT | 分类、回归、特征重要性分析 | 可解释性强,无需数据归一化 | 易过拟合,对噪声敏感 |
| 随机森林 | RF | 分类、回归、异常检测 | 抗过拟合,稳定性高 | 高维数据下计算成本高 | |
| 逻辑回归 | LR | 二分类、概率预测 | 训练快,可解释性强 | 难以拟合非线性关系 | |
| 支持向量机 | SVM | 分类、高维小样本数据 | 泛化能力强,适合特征维度高的场景 | 对大规模数据训练慢,调参复杂 | |
| 朴素贝叶斯 | NB | 文本分类、垃圾邮件识别 | 训练速度极快,对缺失数据不敏感 | 假设特征独立,实际场景中可能不成立 | |
| XGBoost | XGBoost | 分类、回归、竞赛级任务 | 精度高,支持并行计算,自带正则化 | 容易过拟合,对超参数敏感 | |
| LightGBM | LightGBM | 大规模数据分类、回归 | 训练速度快,内存占用低 | 小数据集上可能不如XGBoost稳定 | |
| 深度学习 | 人工神经网络 | ANN | 简单分类、回归任务 | 结构简单,易于理解 | 难以处理高维、复杂数据 |
| 卷积神经网络 | CNN | 图像识别、目标检测、视频分析 | 自动提取空间特征,参数共享 | 训练需要大量数据和计算资源 | |
| 循环神经网络 | RNN | 序列数据处理、文本生成 | 处理可变长度序列 | 存在梯度消失/爆炸问题,难以捕捉长依赖 | |
| 长短期记忆网络 | LSTM | 长序列文本翻译、语音识别 | 解决RNN长依赖问题 | 结构复杂,训练速度较慢 | |
| 门控循环单元 | GRU | 序列数据处理、情感分析 | 比LSTM结构简单,训练更快 | 长序列场景下性能略逊于LSTM | |
| 生成对抗网络 | GAN | 图像生成、风格迁移、数据增强 | 生成数据质量高,多样性强 | 训练不稳定,容易模式崩溃 | |
| Transformer | Transformer | 自然语言处理、多模态任务 | 并行计算效率高,捕捉长依赖能力强 | 计算成本高,小数据集上易过拟合 | |
| 自编码器 | AE | 数据压缩、异常检测、特征提取 | 无监督学习,结构简单 | 生成数据质量通常低于GAN | |
| 图神经网络 | GNN | 社交网络分析、分子结构预测 | 处理图结构数据,挖掘节点关系 | 训练难度大,对图结构预处理要求高 |