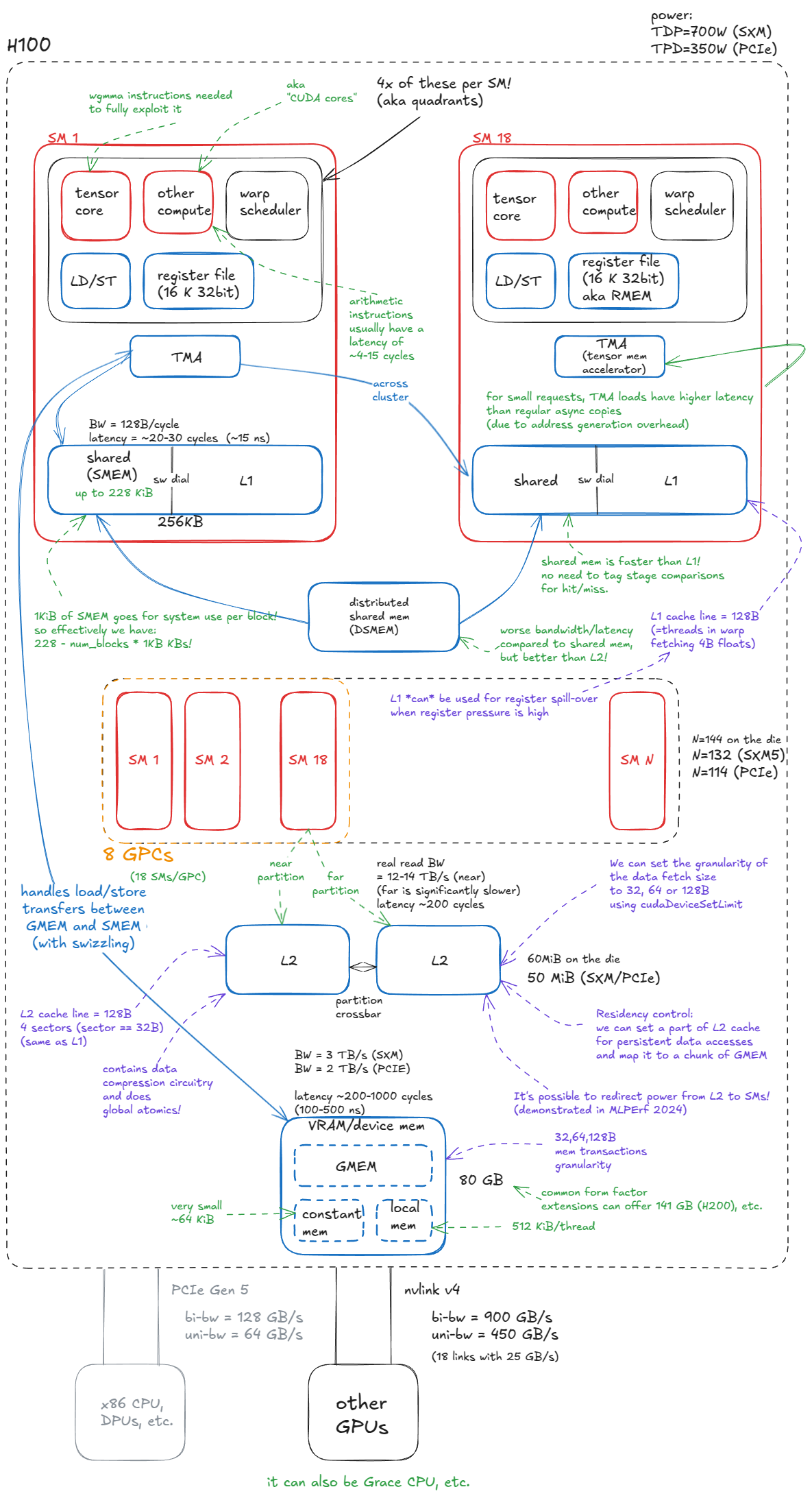
好的,这张图是一张非常详尽的NVIDIA H100 GPU 架构分解图。它从硬件组件、连接关系、性能指标和编程模型等多个维度,对H100的内部工作原理进行了深入剖析。
让我们按照从内到外、从计算核心到外部接口的顺序,来详细解读这张图。
最上层:GPU芯片整体信息
- H100: 明确了这是针对H100架构的分析。
- power : 标注了两种主要型号的功耗:
TDP=700W (SXM): 这是用于高性能服务器(如DGX H100)的SXM版本,性能更强,功耗也更高。TDP=350W (PCIe): 这是可以插入标准服务器PCIe插槽的版本,功耗和性能都相对较低。
核心计算单元:流式多处理器 (SM)
这张图展示了GPU的核心计算引擎------SM的内部结构。一个H100 GPU包含多个SM(图中以SM 1到SM 18为例)。
1. SM内部的子结构:象限 (Quadrants)
4x of these per SM! (aka quadrants): 这句话点明了一个关键事实:每个SM内部又被划分为4个更小的、功能相似的子单元 ,称为象限或分区。图中所画的那个包含tensor core,other compute等的小方框,实际上在每个SM里有4个。
2. SM内的计算与控制单元 (红色框)
tensor core: 张量核心 。这是H100的王牌,专门用于加速矩阵乘法(matmul)等AI运算。注释指出,需要使用wgmma指令来充分利用它。other compute: 其他计算单元,也被称为"CUDA cores"。这些是执行标准浮点运算(如FMA)和整数运算的通用计算核心。warp scheduler: Warp调度器。这是SM的大脑,负责管理和调度Warp(32个线程的执行单元),将指令发送给计算单元。每个象限有一个调度器,所以一个SM总共有4个,这也是为什么一个SM能在一个时钟周期内同时执行来自4个不同Warp的指令。
3. SM内的内存与数据通路 (蓝色框)
register file (16K x 32bit): 寄存器文件 。这是最快、最靠近计算核心的存储。每个象限有一个16K个32位寄存器的文件,所以一个SM总共有16K * 4 = 64K个32位寄存器,总容量为256 KiB。它也被称为RMEM 。- 注释:
arithmetic instructions usually have a latency of ~4-15 cycles。这意味着从寄存器读取数据到计算单元完成一次算术运算,通常需要4到15个时钟周期的延迟。
- 注释:
LD/ST: 加载/存储单元。负责执行从内存(如SMEM或VRAM)加载数据到寄存器,或从寄存器存储数据到内存的指令。TMA (tensor mem accelerator): 张量内存加速器 。这是Hopper架构新增的重量级功能。它是一个专门的硬件引擎,用于异步地 在全局内存(GMEM)和共享内存(SMEM)之间高效传输大块的张量数据。- 注释1:
handles load/store transfers between GMEM and SMEM (with swizzling)。TMA不仅负责传输,还能在传输过程中自动进行数据重排(swizzling),以优化后续在SMEM中的访问模式,避免bank冲突。 - 注释2:
for small requests, TMA loads have higher latency than regular async copies (due to address generation overhead)。对于小数据块的传输,TMA的启动开销(如地址计算)可能比传统的异步拷贝指令更高,所以它更适合大块数据的批量传输。
- 注释1:
shared (SMEM)和L1: 共享内存和L1缓存 。它们共享一块256KB 的物理SRAM。- 带宽/延迟 :
BW = 128B/cycle, latency = ~20-30 cycles (~15 ns)。这是非常高带宽、低延迟的片上存储。 sw dial: "软件旋钮",指程序员可以通过软件API来调整SMEM和L1缓存的分配比例。最多可以将228 KiB分配给SMEM。- 与L1的关系 : 注释指出
shared mem is faster than L1! no need to tag stage comparisons for hit/miss。SMEM比L1更快,因为它是由程序员直接管理的,地址直接映射,不需要像L1缓存那样进行复杂的标签比较来判断命中/未命中。 - 系统开销 :
1KiB of SMEM goes for system use per block!。每个线程块都会占用1KiB的SMEM作为系统开销,所以实际可用SMEM会略少。
- 带宽/延迟 :
GPU的中层架构:集群与全局缓存
1. 图形处理集群 (GPCs)
8 GPCs (18 SMs/GPC): H100芯片被划分为8个GPC。每个GPC包含18个SM(在完整的die上)。- 注释:
N=144 on the die, N=132 (SXM5), N=114 (PCIe)。这解释了为什么实际产品中的SM数量少于理论值(18*8=144)。因为良率等问题,部分SM在出厂时被禁用了。
- 注释:
distributed shared mem (DSMEM): 分布式共享内存 。这是GPC内的一个关键特性。它允许一个GPC内的所有SM互相访问彼此的SMEM,形成一个更大的共享内存池。- 注释:
worse bandwidth/latency compared to shared mem, but better than L2!。通过DSMEM访问邻居SM的SMEM,虽然比访问自己的SMEM要慢,但仍然比访问L2缓存要快得多。这是实现高效多SM协作的关键。
- 注释:
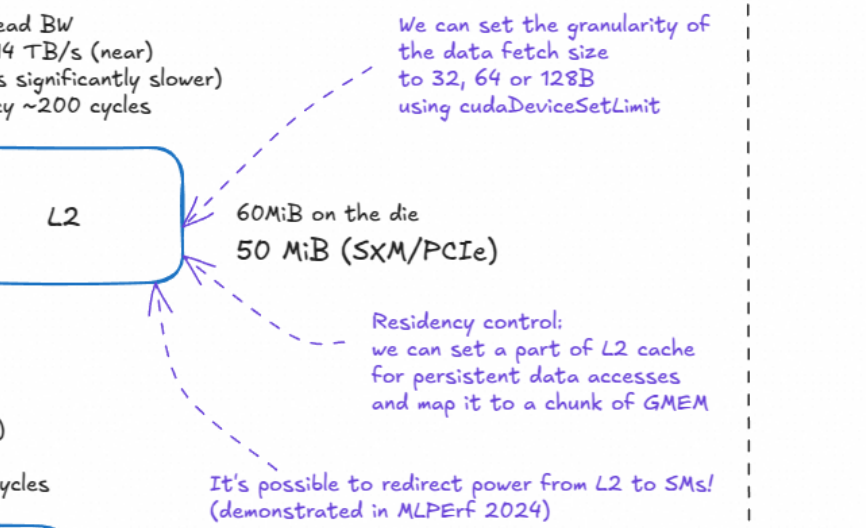
2. L2缓存 (L2 Cache)
L2: H100的L2缓存被物理地划分为两个分区 ,通过一个**交叉开关(partition crossbar)**连接。每个SM都直接连接到一个"近"分区(near partition),并通过交叉开关访问另一个"远"分区(far partition)。- 注释:访问远分区的延迟和带宽都比近分区要差。
- 容量 :
60MiB on the die,实际产品(SXM/PCIe)中可用50 MiB。 - 带宽/延迟 :
real read BW = 12-14 TB/s (near),latency ~200 cycles。 - 缓存行 :
L2 cache line = 128B, 4 sectors (sector == 32B)。L2的缓存行大小和L1相同,都是128字节。 - 其他功能 :
contains data compression circuitry and does global atomics!。L2缓存还集成了数据压缩硬件和执行全局原子操作的功能。 - Residency control : 我们可以设置L2缓存的一部分作为持久化数据访问的区域,并将其映射到一块全局内存上,这对于需要反复访问同一数据集的应用非常有用。
GPU的底层内存与外部接口
1. 显存 (VRAM/device mem)
- 80 GB: H100 SXM5/PCIe版本的标准显存容量。
- 类型 : 内部包含GMEM、常量内存(
constant mem)和本地内存(local mem)。GMEM: 全局内存,主要的数据存储区。constant mem: 常量内存,用于存储只读数据,有专门的缓存优化。local mem: 本地内存,当寄存器不够用时,数据会"溢出"到这里。它物理上是VRAM的一部分,访问速度非常慢,是性能杀手。
- 带宽/延迟 :
BW = 3 TB/s (SXM),latency ~200-1000 cycles (100-500 ns)。这是整个内存层次中速度最慢、延迟最高的一层。
2. 外部连接接口
PCIe Gen 5: 连接到CPU或其他设备(如DPU)的标准总线。bi-bw = 128 GB/s, uni-bw = 64 GB/s。双向带宽128GB/s,单向64GB/s。与GPU内部的TB/s级带宽相比,这是主要的瓶颈之一。
nvlink v4: NVIDIA自家的高速互联总线,用于连接多个GPU,或者连接到Grace CPU。bi-bw = 900 GB/s, uni-bw = 450 GB/s。带宽是PCIe的数倍,是构建多GPU高性能计算集群的关键。
总结:这张图告诉我们什么?
- 分层是核心:从寄存器到VRAM,性能(带宽、延迟)呈数量级下降,而容量呈数量级上升。高性能编程就是一场在不同层级之间巧妙移动数据的艺术。
- Hopper架构的创新 :TMA和DSMEM是Hopper相对于前代架构的巨大飞跃。
- TMA 将大数据块的传输任务从计算核心卸载到了专门的硬件上,实现了计算与通信的高度重叠。
- DSMEM 打破了SM之间的内存壁垒,使得更大规模、更紧密的片上协作成为可能。
- 细节是魔鬼 :图中充满了各种性能优化的线索和陷阱。
- 要利用的:SMEM、Tensor Core、TMA、NVLink。
- 要避免的:寄存器溢出(Local Mem)、非合并的全局内存访问、SMEM的bank冲突。
- 软硬件协同 :图中的很多特性都需要特定的编程模型(如
wgmma指令、集群启动)来利用。不理解硬件,就无法写出真正榨干硬件性能的软件。
这张图可以说是对H100 GPU进行高性能编程的"地图"和"说明书",为开发者提供了理解性能瓶颈、进行针对性优化的宝贵信息。
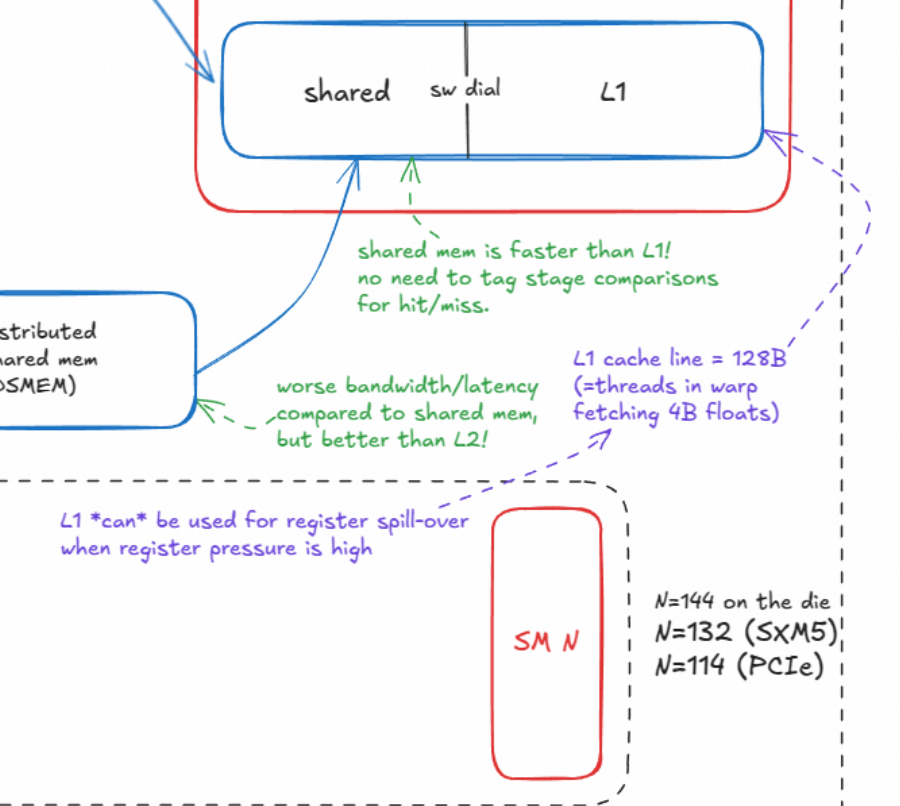
这个注释 L1 cache line = 128B (=threads in warp fetching 4B floats) 是在解释L1缓存工作的一个核心概念:缓存行(Cache Line) 的大小及其与GPU并行执行模型(特别是Warp)的关系。
让我们来详细分解这句话的意思。
1. 什么是缓存行 (Cache Line)?
缓存行是缓存与主内存之间数据交换的最小单位。
可以把它想象成一个固定大小的"集装箱"。当CPU或GPU需要从主内存(VRAM)中读取一个数据时(比如一个4字节的浮点数),硬件并不会只把那4个字节拿过来。相反,它会把包含这4个字节的、一整块连续的内存数据------也就是一个缓存行------都搬到缓存里。
为什么这么设计?
这是基于一个非常重要的计算机原理:空间局部性 (Spatial Locality)。该原理指出,如果程序访问了某个内存地址,那么它很可能在不久的将来会访问该地址附近的内存。
因此,一次性加载一整块数据(一个缓存行)到高速缓存中,可以极大地提高效率。如果下一次要访问的数据恰好在这个已经加载的"集装-箱"里,那就直接从高速缓存里拿,速度飞快,这就是一次缓存命中 (Cache Hit)。
2. L1缓存行的大小:128B
这张图明确指出,在H100架构中,L1缓存的缓存行大小是 128字节 (128B)。
这意味着,无论你只是想从全局内存读取1个字节还是4个字节,硬件的L1缓存(如果发生缓存未命中)都会从L2或VRAM中抓取整整128字节的数据块来填充自己。
3. (=threads in warp fetching 4B floats):与Warp的关系
这部分是解释为什么128B这个大小在GPU上是"天作之合"的关键。
- Warp : 在NVIDIA GPU中,线程是以 Warp 为单位进行调度和执行的。一个Warp包含 32个线程。
- 4B floats :
4B指的是4个字节(Byte),这正好是一个标准的单精度浮点数 (float) 的大小。 threads in warp fetching 4B floats: 这描述了一个非常常见的情景------一个Warp中的32个线程,每个线程都去读取一个4字节的浮点数。
现在我们来算一下:
32个线程 × 4字节/线程 = 128字节
这个计算结果不多不少,正好等于一个L1缓存行的大小!
这揭示了什么?------ 内存合并访问 (Memory Coalescing)
这个等式完美地解释了GPU编程中最重要的性能优化原则之一:内存合并访问。
当一个Warp中的32个线程连续地、对齐地 访问全局内存时,硬件可以将这32个独立的内存请求合并 (coalesce) 成一个单一的、高效的 128字节内存事务 (memory transaction)。
-
理想情况(合并访问):
- 线程0访问地址
A - 线程1访问地址
A + 4 - 线程2访问地址
A + 8 - ...
- 线程31访问地址
A + 124 - 这32个线程总共访问了从地址
A开始的连续128字节。硬件看到这种情况,就会发出一个单一的128字节读取请求,正好填满一个L1缓存行。效率极高,只产生一次内存事务。
- 线程0访问地址
-
糟糕情况(非合并访问):
- 如果这32个线程访问的是分散在内存各处的、不连续的地址,硬件就无法将它们合并。
- 最坏的情况下,如果每个线程访问的地址都位于不同的128字节缓存行中,硬件可能需要发起多达32次独立的内存事务来满足这个Warp的需求。效率极低,性能急剧下降。
总结
所以,L1 cache line = 128B (=threads in warp fetching 4B floats) 这句注释的含义是:
L1缓存与主内存交换数据的基本单位是128字节,这个大小被精心设计成与一个Warp(32个线程)同时请求连续的32位数据(如float)的总量完全匹配。这种设计是实现高效"内存合并访问"的硬件基础,也是GPU能达到超高内存带宽的关键原因之一。
理解这一点,就能明白为什么在编写CUDA代码时,要极力保证同一个Warp内的线程访问连续的内存地址了。