大家好,我是孟健。
这周我翻了 510 个 Agent session。最明显的感受是:Agent 越强,人越要会管理。
别再只研究 prompt 和模型版本了。真正拉开差距的,是你有没有给 Agent 设目标、定考核、给反馈、沉淀流程。

01 翻完 510 个 session,我看到的不是自动化,是管理问题
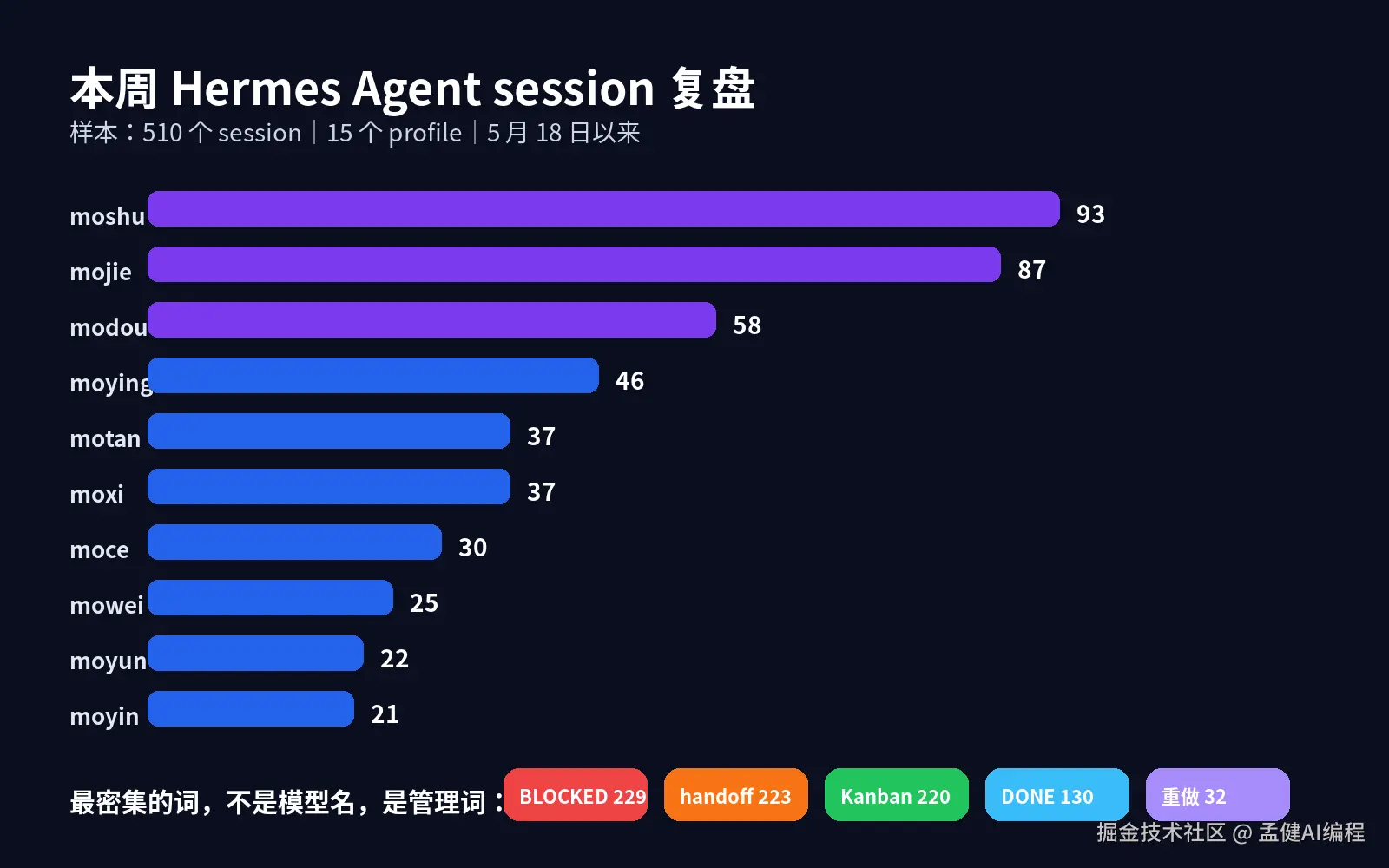
510 个 session,覆盖 15 个 Agent,时间范围一周。
session 数最多的几个:后端 93 个,前端 87 个,短视频 58 个,设计 46 个,市场侦察 37 个,SEO 37 个,产品策略 30 个。
然后我数了一下高频词,出现频次 Top:
确认 247 次、BLOCKED 229 次、handoff 223 次、Kanban 220 次、review 194 次、QA 147 次、DONE 130 次、deploy 130 次、验收 56 次、重做 32 次。
注意,出现频率最高的词,没有一个是模型名,没有一个是 prompt 技巧。
全是交接、阻塞、验收、复盘。
这说明什么?多 Agent 系统进入真实工作流之后,暴露出来的问题从"会不会写代码"变成了:任务怎么交,谁来判断完成,卡住了怎么办,做错了往哪复盘。
这是管理问题,不是技术问题。
02 把 Agent 当工具用,很快会卡住
很多人现在用 AI 的方式还是:写个 prompt,等输出,盯实现,不对就重来或者换模型。
这个方式在单次对话里没问题。但用来带 Agent 团队,很快会卡住。
原因很简单:Agent 的单次执行能力已经够用,瓶颈在协作结构。给它任务的时候,如果没说清楚:目标是什么、上下文是什么、什么情况要停下来等确认、怎么算做完------它也只能靠猜。猜出来的结果,有时对,更多时候需要大量返工。
外部研究也说明这点。Human-Agent Collaboration 领域的综述研究指出:人类在交互中持续提供信息、反馈和控制,是提升 Agent 可靠性和安全性的关键。完全自主的 Agent 在 hallucination、复杂任务、伦理边界上仍有系统性局限,换个更强模型不能彻底解决这些问题。
TheAgentCompany 做了一个模拟真实软件公司的 benchmark,让 Agent 处理真实工作任务:写代码、浏览 Web、与"同事"沟通。论文摘要里说,最强 baseline agent 完成 30% 的任务。
全自动不是当下的主线,协作方式才是。
03 人类的价值,正在从"会实现"变成"会校准"
这周有个短视频任务,是个很好的例子。
Agent 交付了内容,我看了一眼:BGM 不对,文案来源模糊,选题也不是当天的最佳方向。
我把问题反馈回去,Agent 自查后承认------没有完全按流程走,只能算半流程产物,不建议直接发。
然后呢?
补了几条硬规则:必须真实调用指定创作流程,BGM 必须有可商用授权记录,必须有 contact-sheet 和机械门禁检查。补完之后重做,这次机械门禁 PASS,内容可以发。
这次反馈的价值,不是"我发现了一个错误"。而是:人类的每一次校准,都是在给 Agent 标注训练样本。
反馈变成了 guardrails、变成了 playbook,下一次 Agent 就更稳。人不是监工,人是测试集。
你盯的不应该是每一步怎么实现,而是最终交付了什么、有没有可验证的证据、出了问题能不能快速定位到哪一步出的错。
04 我现在怎么给 Agent 下任务
这是我摸索出来的下任务模板,不是理论,是实际在用的。
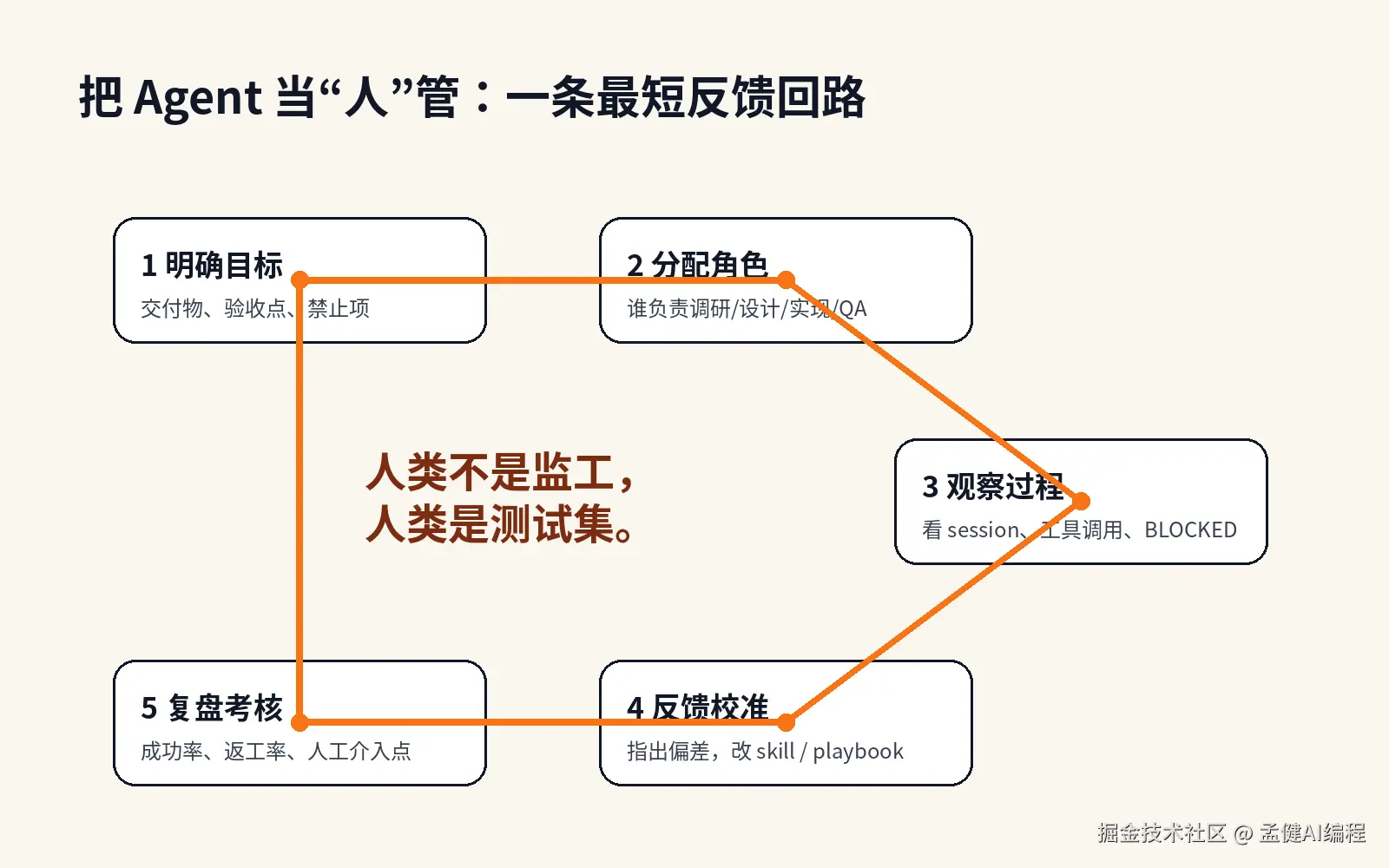
每次给 Agent 分配任务,我会明确六件事:
目标:这个任务要达成什么结果。别只写"写篇文章",要写清读者是谁、核心观点是什么、发布后看哪个指标。目标越具体,Agent 越容易对齐。
输入:给 Agent 的材料是什么。截图、数据、上游任务的输出、参考样本------越具体越好。不要让它自己去猜上下文,猜出来的假设一旦偏了,整个任务方向就歪了。
输出格式:要一个 markdown 文档,还是一段可直接复制的文案,还是图片加说明。格式不明确,返工率极高,因为 Agent 默认的输出结构往往和你实际需要的不一样。
验收条件:怎么判断任务完成。有没有字数要求、有没有质量门禁、有没有必须通过的检查项。这是最容易被跳过的一步,也是最重要的------没有验收条件,任务就没有终点。
禁区:哪些操作不允许自主执行。不能直接发布内容,不能修改生产数据,不能代表账号公开发言------这些必须明确写出来,不能靠 Agent 自己判断边界在哪里。
失败回调:出了问题怎么处理。是静默失败、报错等待人工,还是降级跑备用流程。没有失败回调的任务,出了问题会让整条链路卡住,没人知道从哪里重启。
这六件事,缺一件,任务就有漏洞。
人不需要盯每一步实现。但你得能在任务结束后,用交付证据判断:这次 Agent 到底做到了没有。如果做不到这个判断,就说明任务没有设计好,而不是 Agent 不行。
05 真正好用的 Agent 团队,需要考核系统
另一个案例是多 Agent 协作流水线。
在某个节点,几个下游 Agent 同时 BLOCKED------原因是上游前端还没有 final commit、没有 deploy、没有 checkpoint。
很多人看到这个会觉得:怎么又卡了?
我的判断反过来:这是成熟表现。
下游不拿不确定的输入硬做,意味着任务系统开始像真实团队一样运作。状态不清,就停下来等,不胡乱推进。
要让这种机制稳定工作,需要五件事:
- 目标:这个任务要达成什么结果,用什么指标衡量
- 禁止动作:哪些操作不允许自主执行,必须等确认
- 验收命令:怎么判断任务完成,谁来确认
- 回滚方式:出了问题怎么恢复
- 人工确认点:哪些节点必须人过一遍
Kanban 作为 source of truth,记录任务状态。Telegram 只负责可见性,不做决策依据。
这个设计背后的逻辑,和 principal-agent 理论高度一致:人把任务委托给 Agent,但 delegation、oversight、accountability 的结构必须设计好,不能全靠 Agent 自己摸索。
还有一个增长/社区预热的任务,做了一系列动作,但互动结果弱。
我让 Agent 做深度复盘。发现 OKR 部分有效,但策略偏保守,不够触发互动。
这个结果指向的不是"Agent 没用"。复盘的终点是下一轮任务的输入------考核的目的是把下一步说清楚,而不是判定这一次对不对。
复盘出 P1/P0 问题,这些问题直接变成下一轮任务的输入。迭代才是主线,不是追求一次做对。

06 以后会有一类人,专门"带 Agent"
我越来越确信,接下来会出现一类新的高价值角色:
不是 prompt 工程师,也不一定写每行代码。
他们知道:什么任务可以交出去,什么节点必须人工确认,什么指标没动就是失败。他们能把业务流程拆解成 Agent 能安全接手的任务系统,能给 Agent 写好目标和边界,能从输出里识别出哪里需要校准。
叫 AI team manager,或者 agent operator,名字不重要。
重要的是:这个能力,现在没有多少人在系统地培养。
对独立开发者来说,下一项能力不是再买一个新模型,不是刷最新 benchmark。而是把自己的业务改造成 Agent 能安全接手的任务系统。
以前我会盯 Agent 每一步怎么做。现在我更关心它最后交付什么、有没有证据、出了问题能不能复盘。
这个转变发生在某一个时刻,你会突然意识到:你不是在用工具,你在带团队。
你现在用 AI,是在"问答",还是在"管理"?
欢迎留言。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏