Agent 时代,为什么需要新的可观测范式?
先从一个真实场景出发:某团队上线了一款客服 Agent,并规范地接入了 Prometheus、Grafana、ELK 等主流的可观测性工具。从监控大盘来看,各项核心指标非常完美:P99 延迟为 0.2 秒,错误率为 0.001%,Token 消耗曲线表现平稳,所有系统指标均处于健康状态。
然而,产品团队很快在用户反馈中发现了一个问题:系统把一个明明符合退款政策的订单,直接回复用户"根据政策无法退款"。研发人员随后调取日志排查,发现从 HTTP 状态码到 Token 用量,从工具调用链路到模型的响应时间,没有任何一个传统可观测指标出现异常。但结果是,Agent 在业务层给出了错误的答案。
过去十几年,软件可观测性核心回答的问题是:系统有没有正常运行? 而在 Agent 时代,更紧迫的问题变成了:在系统正常运行的同时,任务真的做对了吗?
传统可观测为什么无法满足 Agent 的可靠性需求?
可观测的目标是保障系统的可靠性,类似上面的场景中面临 Agent 可靠性的需求,传统可观测手段却失效了。当用户反馈"这个 Agent 不靠谱"时,团队只能猜:是模型不行?是 Prompt 不行?是知识库不准?是工具调用错了?还是评估标准本身不清晰?这背后的原因是什么呢?
- 影响 Agent 可靠性的因素要更多
传统软件系统大多遵循确定性的执行逻辑,输入、代码路径、数据库状态基本可控。研发阶段通过单元测试和集成测试,运行阶段监控报错率和延迟,基本就能判定系统是否健康。
但 Agent 不是这样工作的。Agent 应用具有长链路和概率性的特征,其执行过程包含:意图理解、上下文检索、Prompt 动态拼装、LLM 推理 、工具调用、结果整合 、多轮决策。同样的输入,在不同的上下文、模型版本或温度参数下可能产生不同的输出。Agent 的出错,往往不是传统意义上的系统故障,而是语义层面和业务效果层面的偏差,这是无法单纯用错误率和吞吐量来衡量的。
- 传统可观测侧重于系统性能与稳定性,而非业务效果
传统可观测在 Agent 出现之前已经存在几十年,它是为相对确定的软件和服务设计的,通过收集 CPU、内存、硬盘、网络等指标数据,程序运行的日志,服务之间相互调用的 Trace,来监测系统运行的状态,发现甚至预测异常和故障。
它收集的数据和监测手段能够回答服务有没有宕机、接口是否超时、数据库查询是否变慢等问题,但无法判断 Agent 产出的内容是否符合预期。它缺乏对 Agent 业务效果数据的采集能力与评估机制。
- 缺乏对 AI 生态与语义的原生支持
另一个不算本质但是影响使用体验的问题是:传统可观测为单机程序、微服务做了优化,但是没有为 AI 应用、Agent 做 Native 的支持。
比如大模型 SDK、AI 开发框架、AI 低代码开发平台、AI 网关等 AI 生态组件,传统可观测没有深入集成,更没有识别 AI 语义如 LLM 请求、Tool 调用、Retrieval、Token 等,很难满足 AI 开发者、产品等角色的对话语言和分析需求。
(注:目前 OpenTelemetry 社区正在推进 GenAI 相关的语义约定和遥测数据标准化,这也印证了传统服务观测模型向 AI 场景扩展的必然趋势。)
面向 Agent 可观测与效果评估的深度融合
目前,一些团队仍试图通过在旧有的监控体系中补几个 LLM 调用的埋点来解决问题。这类似于在早期用物理服务器的监控思路去管理容器,虽然能跑通,但无法触及核心。
针对传统手段的不足,一种新的工程范式正在兴起:面向 Agent 的可观测与效果评估深度融合。
在这种新范式下,主要包含以下几个核心动作:
- 上线前:通过测试集与评估器,量化对比不同版本的回答效果。
- 上线后:持续采集真实用户的交互轨迹与 Agent 的内部执行路径。
- 异常排查:发现 Bad Case 后,能够自动或半自动地归因至 Prompt、上下文、模型或工具问题。
- 持续迭代:将高价值的 Bad Case 转化为评测样本,在下一轮迭代中验证优化效果
这就是 Agent 时代的核心工程闭环:观测 → 评估 → 归因 → 优化 → 再评估。
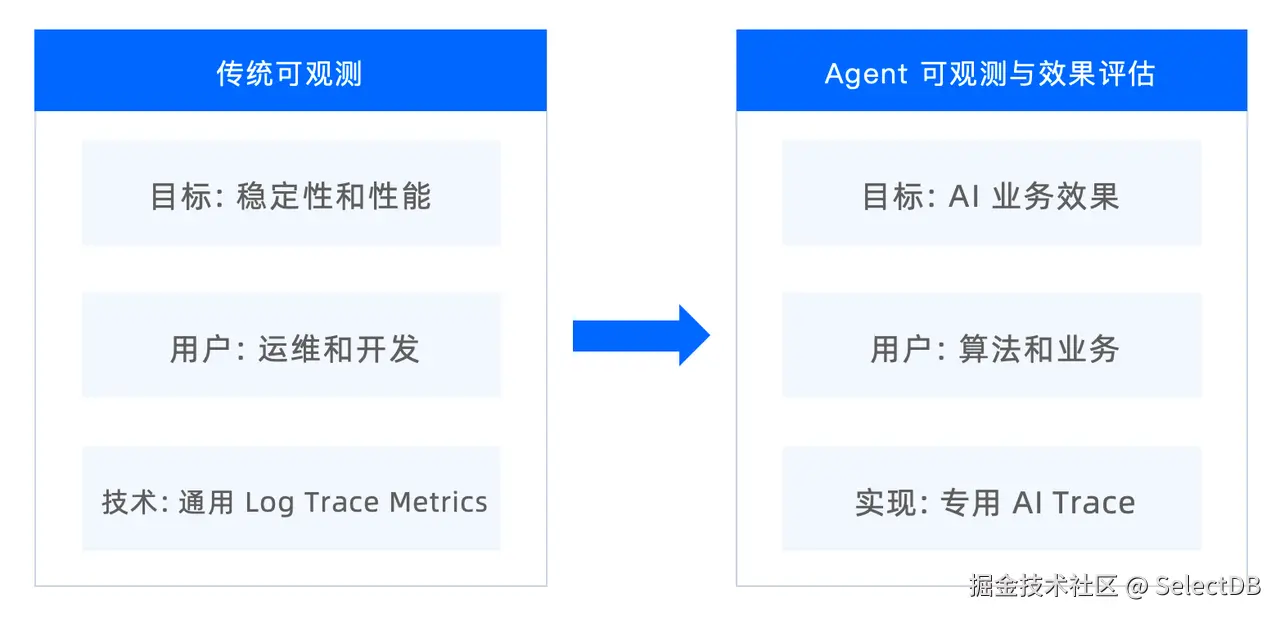
而它与传统可观测工具的区别在于:
- 不止于可观测,更注重效果评估和优化。可观测除了解开 Agent 的行为黑盒,方便具体 bad case 的分析,更重要的是跟效果评估联动,可观测为效果评估提供数据燃料,效果评估的过程又被观测起来,方便开发者对评估 bad case 做深入分析找到原因。为了方便开发者进行效果评估,提供测试集管理、人工标注、大模型自动评估等功能。
- 主要用户从工程团队变成算法业务团队。传统可观测的用户主要是工程团队,包括运维和研发,主要使用场景是监控告警和故障分析,Agent 可观测与效果评估的用户主要是 AI 应用团队,包括算法、分析师、产品等,主要使用场景是效果跟踪、评估和优化。
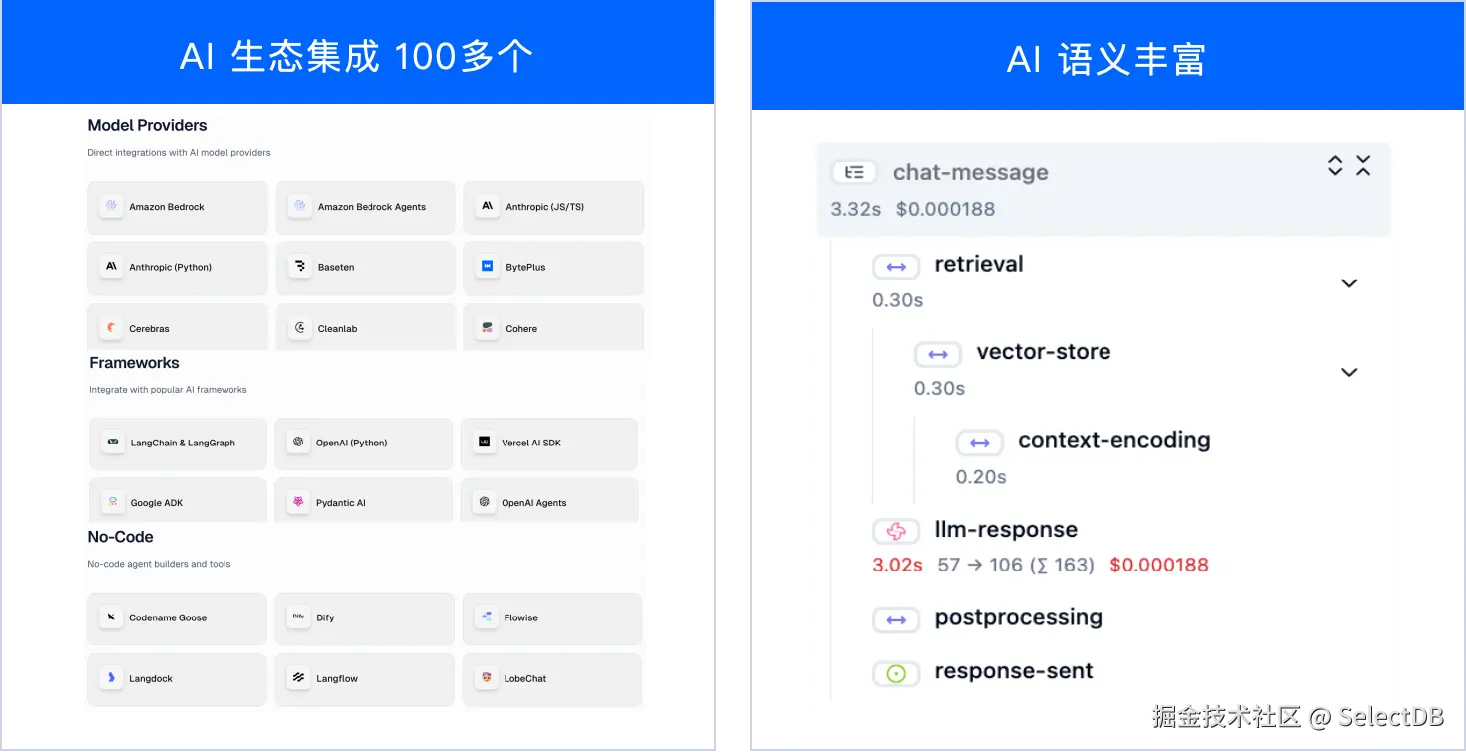
- 将可观测融入 AI生态。内置对大模型 SDK、AI 开发框架、AI 低代码开发平台、AI 网关等 AI 生态组件的支持,Agent 开发者不用自己为不同的组件一个个去写可观测代码,集成的成本大幅降低。
- 系统设计面向 AI 语义。 AI 语义如 LLM 请求、Tool 调用、Retrieval、Token、Sub Agent、Embedding 模型等,在系统中是一等公民,在可视化展示、API 等方面都是这些 AI 相关的内容,而不像传统 Trace 里面只是一堆扩展属性中的一个。
Agent 时代的核心矛盾,逐渐从系统的稳定性 向输出的可信度转移。解决可信度问题,需要一套语义原生、评估驱动、与迭代闭环深度耦合的新型基础设施。
谁能率先在这件事上想明白,谁就能在 Agent 产品化的下一轮竞争中拿到先发优势。
Litefuse
这也是我们开发 Litefuse 的初衷。
我们把 Litefuse 定位为面向 Agent 时代的可观测与效果评估平台。它不仅完整记录 Agent 的执行过程(包括每一次模型调用、上下文构造、工具执行和任务路径),更通过自动化评估与语义级质量分析,帮助团队真正明确:我的 Agent 到底做得好不好,有没有越做越好?
更重要的是,Litefuse 的核心价值在于,协助团队将线上的 Bad Case、用户反馈与评估结果沉淀下来,使 Agent 的行为可追踪、效果可评估、优化可持续。
目前,Litefuse 已上线 SaaS 服务(litefuse.cloud)并提供免费使用额度。如果您正在构建或优化 Agent,欢迎尝试使用 Litefuse 来量化和加速您的迭代循环。您也可以把 Hermes、OpenClaw、Claude Code 等通用 Agent 一键接入 litefuse。
在重构 Agent 可观测性的过程中,我们深刻体会到:AI 语义的解析与海量执行轨迹的实时分析,对底层数据引擎提出了全新的挑战。 无论是高并发的业务指标、非结构化的文本检索,还是复杂的链路 Trace,都需要更强大的实时数据处理能力支撑。
在 6 月 11 日举行的 SelectDB 产品发布会上,我们将进一步分享 Doris / SelectDB 在实时分析、混合检索、Agentic Analytics、AI Agent 可观测、多模数据处理等方向上的最新进展,也会系统呈现我们对下一代数据架构的系统思考。
欢迎搜索视频号:SelectDB,关注 SelectDB 产品发布会------面向 Agent 的实时数据引擎。我们期待和大家一起讨论:Agent 时代的数据基础设施,究竟会走向哪里。