一、前言:
1.1 一个绕不开的反差
现在的 AI 已经能写代码、画插画、剪视频,水平都不低。但你让它指挥一个机械臂去开冰箱门、拧瓶盖、把杯子从桌上拿起来,大概率翻车。
不是模型不够大,是它没见过这些场景!
互联网上有几亿张猫的图片,但没人会专门拍一段"手指接触瓶盖时摩擦力如何分布"的视频上传。物理交互这件事,AI 在它现有的训练数据里根本找不到答案。
1.2 数据从哪里来
这两年具身智能圈子的人慢慢达成了一个共识:靠真机采集太贵也太慢,仿真数据是绕不开的一环。但仿真数据好不好用,关键看底层的仿真资产做得行不行。
资产差,仿真出来的就是看着像、用着假的废数据;资产好,AI 才能真在虚拟世界里学到能搬到现实里用的本事。这篇文章就聊聊孪界科技的 Synthesis(衍象)平台在仿真资产这件事上做了什么,以及为什么做了几十年真实工程这件事,反而成了它的核心优势。
衍象详细介绍及体验地址:https://www.extwin.com/col.jsp?id=157
二、问题在哪,好的资产又该是什么样
2.1 具身智能要的数据,不是互联网数据
具身智能要的数据,和大语言模型要的数据,根本不是一回事。大语言模型吃文本,文生图模型吃图片------都是静态的、单模态的。但具身智能要训练的是"感知---决策---动作---反馈"的连续闭环:机器人伸手去拿一个杯子,过程中视觉、深度、力觉、位姿、动作轨迹、环境状态全都在变,缺一不可。
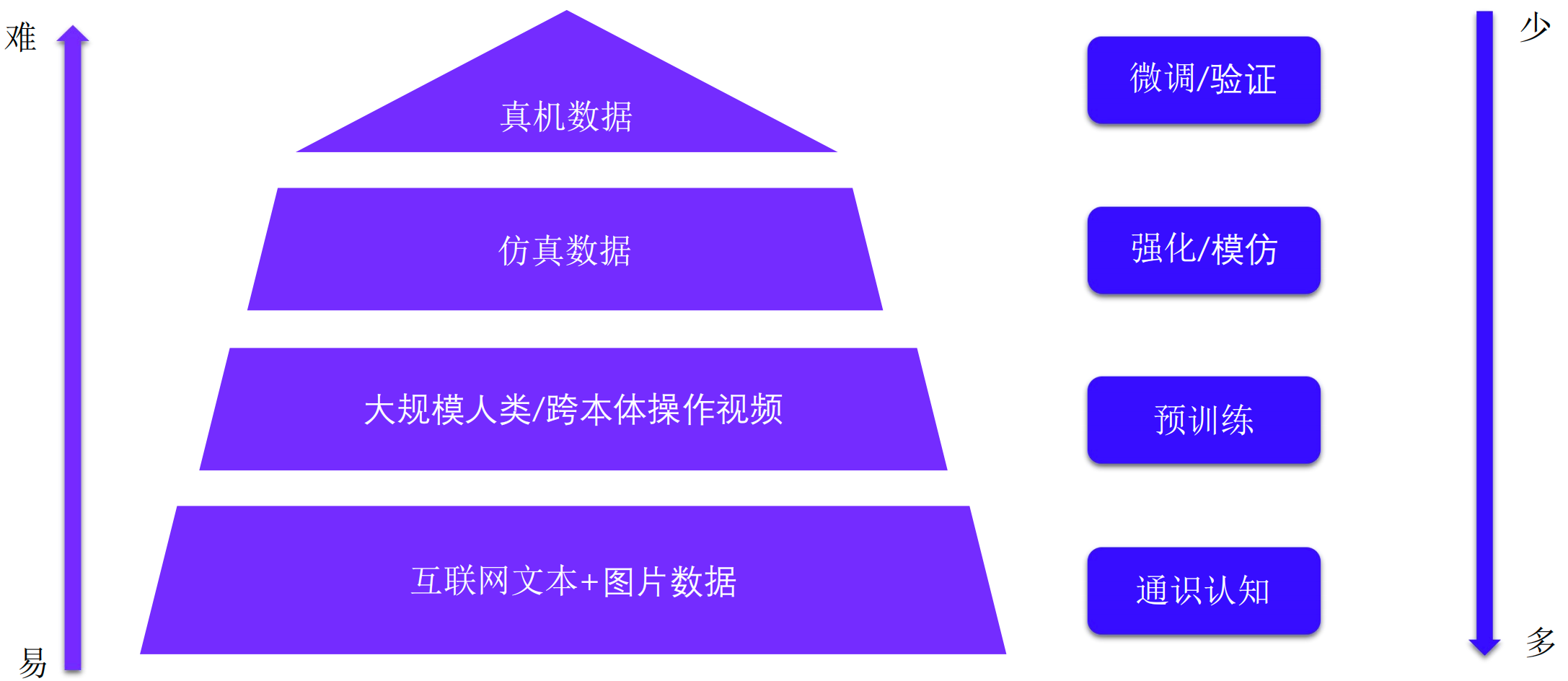
这意味着数据获取难度比互联网数据高几个数量级。
2.2 真机采集扛不住,仿真又有四个老问题
最理想的当然是真机数据。
机器人在真实世界里抓一万次杯子,学到的东西最准。但真机采集要承担四类成本:时间(遥操作效率低)、设备(机器人和场地都不便宜)、安全(碰撞、跌倒、人员伤害风险)、长尾(异常工况根本没法主动复现)。指望靠真机堆出亿级数据集,不现实。
仿真理论上能解决这些问题,但实际用起来,下面这几件事一直没解决好:
- 量级差距大:业界期望亿级,现实交付百万级
- 资产缺物理标签和工程语义:网上能下到的三维模型大多只"好看",没有质量、摩擦、关节、材料这些信息
- Sim-to-Real 不稳定:仿真里训得好好的策略,搬到真机上经常不工作
- 不符合工程实际:训练场景往往是"凑数搭的",不符合真实建筑、工艺、运维的规则
这四个问题归根结底都指向同一个根源:仿真资产本身的质量不够。视觉真实不等于物理真实,看着像也不等于训得动。

2.3 一个能用的仿真资产,要满足四条
行业现在常说一句话:"仿真合成数据的核心是工程正确性"。这句话拆开来看,对仿真资产其实提了四个具体要求:
- 几何要可碰撞、可测量、可编辑。一个微波炉模型如果只是一个壳,里面是空的,那机器人去开门时撞到的是空气------这种数据训练出来的策略毫无意义。
- 语义要完整。AI 不只是要看见一把椅子,还得知道这是办公椅、属于办公室场景、能坐能滚轮移动。空间、工艺、拓扑、材料、用途,缺一类泛化能力就少一层。
- 物理要可交互、可推演、可训练。质量、摩擦、刚度、阻尼、运动学属性一个都不能少。门要能开、抽屉要能拉、按钮要能按------也就是要带铰链关节,这是物理 AI 训练区别于普通三维浏览的关键。
- 工程上要符合标准。机器人最终要在医院走廊、工厂车间、厨房里干活,这些空间是按设计规范、施工规范、运维规则建出来的。仿真里如果都是随手定的尺寸,训出来的机器人到真实建筑里就会处处碰壁。
这四条加起来,意味着仿真资产不是"做一个好看的三维模型"那么简单。它需要工程能力、图形学能力、物理仿真能力,缺一个都做不出来。
三、Synthesis是怎么做的
讲到这里,问题就来了,一家公司要凭什么能做出满足这四条的资产?
孪界科技给出的答案是:靠几十年真实工程项目的积累,加上十年以上数字孪生引擎的技术沉淀,构建一条自主的仿真资产生产工具链。
这话听起来有点大,但拆开看其实很具体。
3.1 20000+ 真实工程项目的全精度模型
孪界背后是北京市建筑设计研究院,70 多年来做了 25000+ 个项目,2.5 亿平方米的设计工作量。机场、地铁、医院、住宅、市政、水利、电力、商业......基本覆盖了具身智能可能落地的所有典型场景。

这意味着 Synthesis 平台上的建筑空间和工程模型,不是临时建模凑出来的,而是直接来自真实交付过的工程项目。门多宽、走廊多高、厨房灶台离冰箱多远、消防通道留多少米------全都符合国家标准、地方标准和行业规范。
这是别人没法在短期内补上的差距。 设计院的工程积累是几十年沉淀出来的,不是花钱就能买到。
3.2 数字孪生引擎的十年积累
光有工程数据还不够,得能把这些数据"翻译"成仿真器能用的格式。这就要靠 Multiverse 数字孪生引擎------孪界自己研发了十年以上的核心产品,覆盖三维模型、建筑数据、图形学、工程经验的跨界融合能力。
200+ 企业客户、100+ 知识产权、1000+ 项目应用、20+ 重大工程(引江济淮、大兴机场、京张高铁、塔里木油田、北京城市副中心等)
这些都是 Multiverse 引擎实战过的项目。
简单说:别人是从游戏引擎或图形学起家做仿真,孪界是从真实工程做了十几年之后,反过来切到仿真这件事。 起点不一样,能处理的数据复杂度也不一样。
3.3 自主的仿真资产生产工具链
工程模型从设计软件里出来,到能丢进仿真器训练,中间要经过的步骤非常多。
工程模型从设计软件里出来,到能丢进仿真器训练,中间要经过的步骤非常多。孪界自己开发了一整套数据连接器(Connector),支持 100+ 种主流三维格式的原生转换------Revit、3ds Max、MicroStation、AutoCAD、PDMS、Catia、SketchUp、Navisworks、Inventor、Rhino、SolidWorks、SmartPlant、Tekla 都能直接用。
转换过程大致是这样的:
- 几何数据:可控精度的几何优化、坐标和定位点设置、几何数据压缩
- 属性信息:分类编码、属性数据、对象定义、拓扑关系
- 元数据:材质定义、纹理文件、扩展数据
这三类信息汇总到自研的 .MV 中间格式,再经过转换服务统一处理:
- 自动化任务调度和模型转换
- 按 Sim-Ready 标准组织数据
- 碰撞体自动生成
- 物理属性预设
- 几何优化、压缩
- 结构化存储
最终输出三种格式:OpenUSD、SDF、MJCF------分别对应 Isaac Sim、Gazebo、MuJoCo 三个主流仿真器。
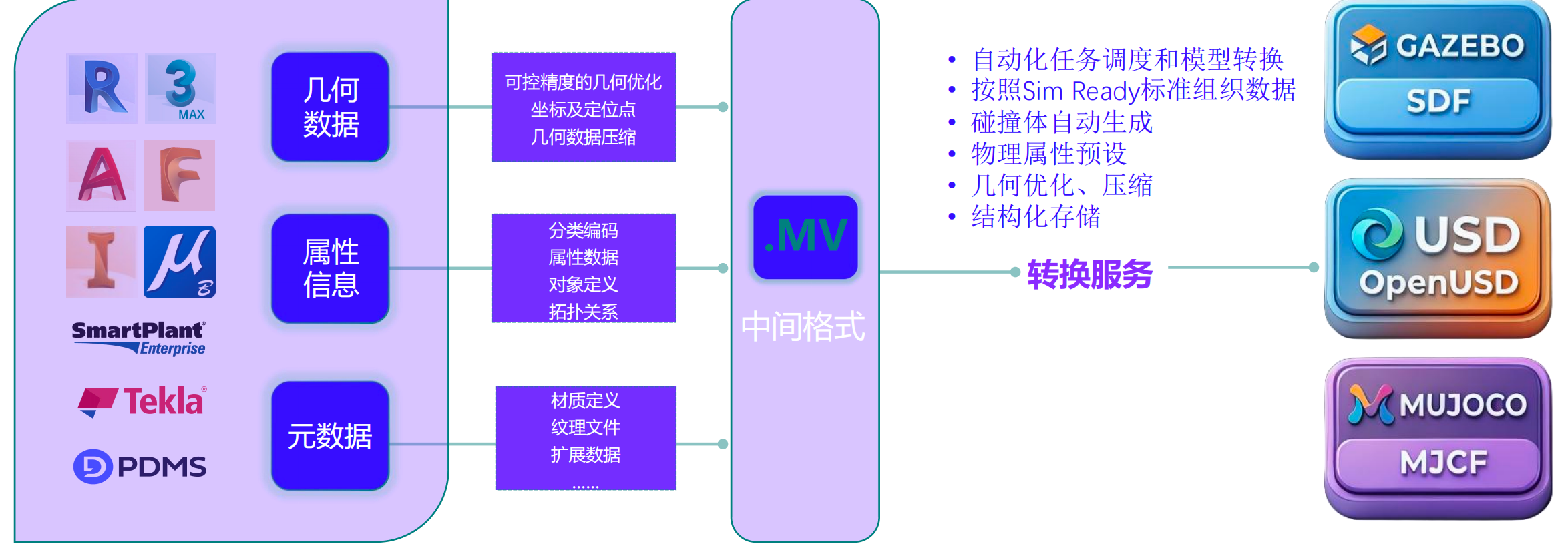
这条流水线的价值是什么?它把"从一个工程模型变成一个能直接训机器人的资产"中间所有的脏活累活,都自动化了。 别人手工干一个礼拜的事情,这条流水线几小时就能搞定,而且质量稳定、参数统一。
3.4 打开平台先看到什么
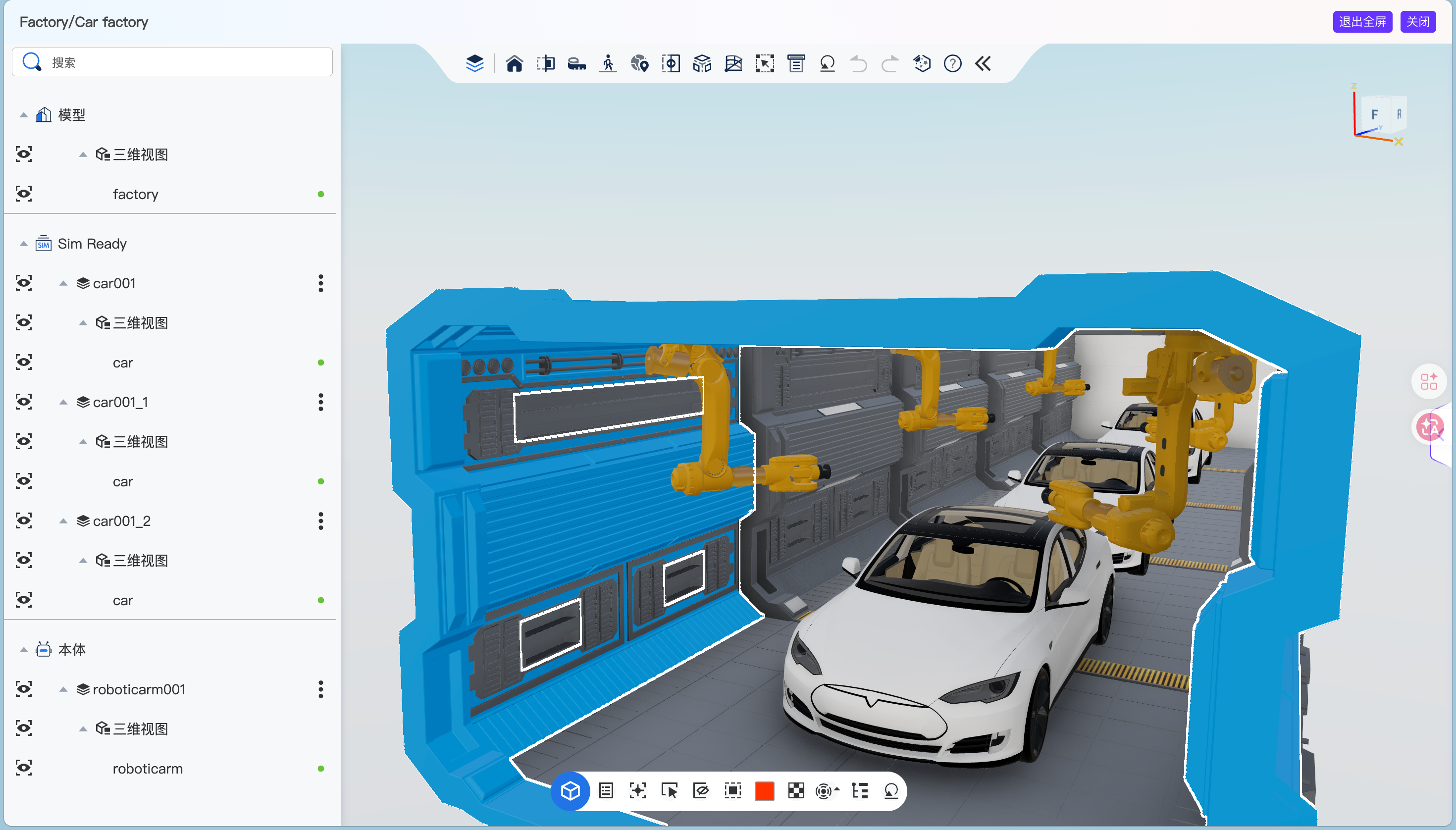
打开 synthesis.extwin.com,资产组织方式分得很清楚。
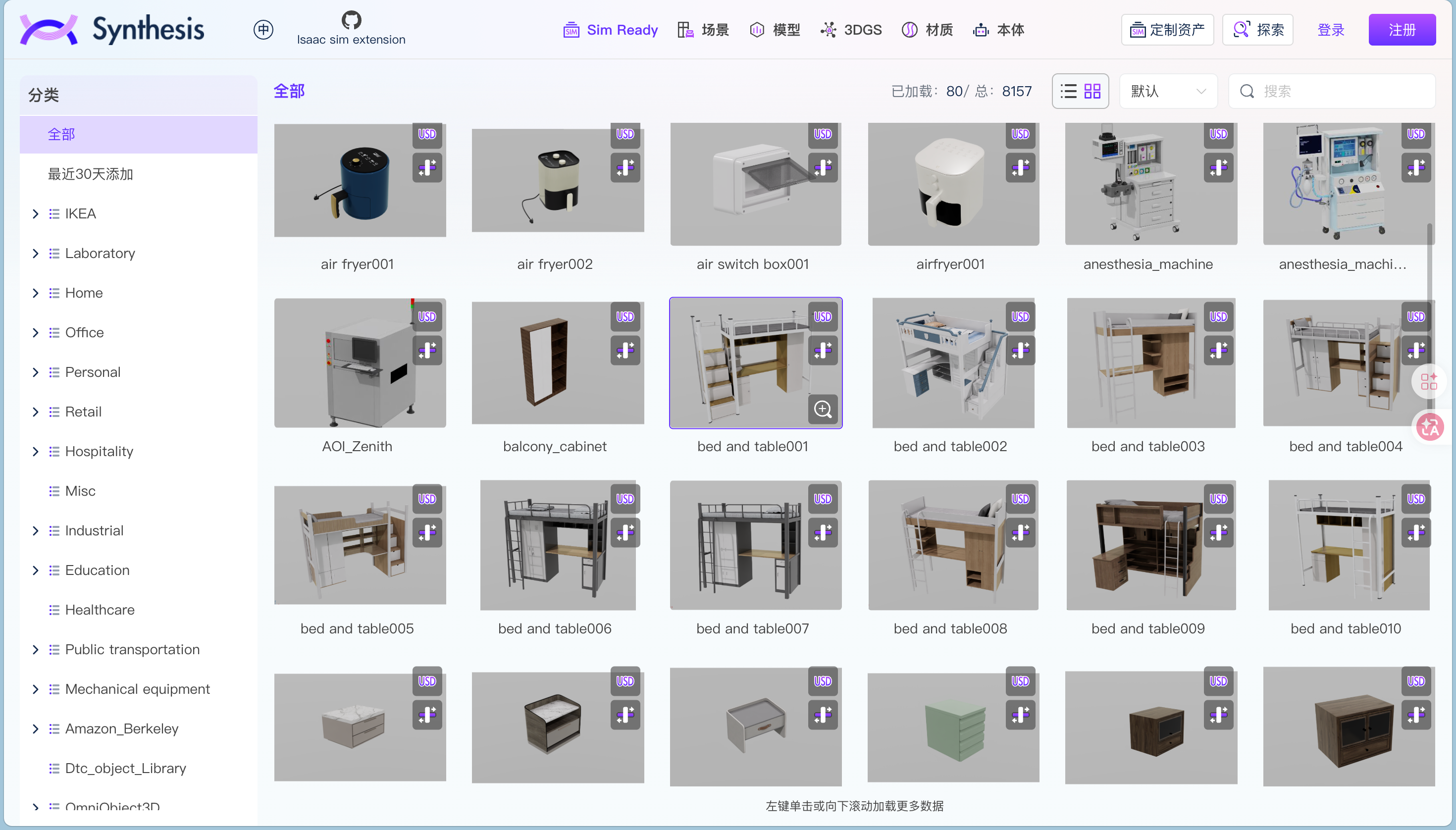
顶部按类型切换:Sim Ready 资产、模型、3DGS(高斯泼溅)、场景、材质、本体(机器人)。
左侧按使用场景分类:IKEA、Laboratory、Home、Office、Retail、Hospitality、Industrial、Education、Healthcare、Public transportation、Mechanical equipment 等。
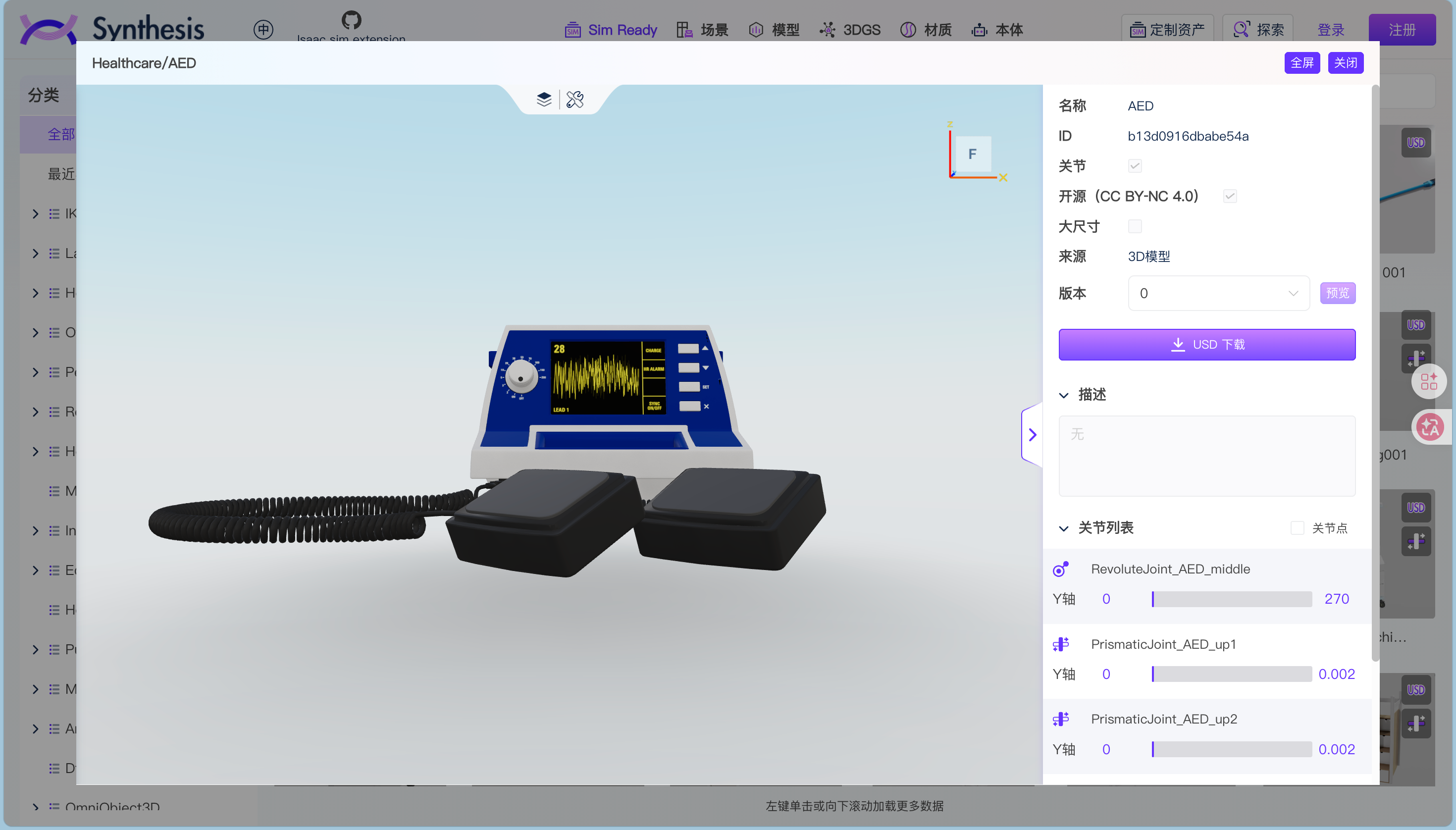
每个资产卡片右上角标着 USD 和铰链标识,意思是这个资产已经按 Sim-Ready 标准准备好了,可以直接导入 Isaac Sim 之类的仿真器。不用自己再补物理参数、配关节、生成碰撞体。
目前平台上的资产规模:
- 500+ 高质量铰链关节资产
- 7500+ 全尺寸扫描重建资产
- 8000+ 实物物品资产
- 资产类型覆盖刚体和软体
- 30+ 全交互场景(家居、办公、医院、工厂、实验室等)
这是一个能直接拿来训模型的量级,不是 demo 级别。

3.5 如何去使用
Synthesis 把在线化做得比较彻底。
从浏览资产、搭场景到跑仿真、采数据,整条链路不用在本地装 Isaac Sim,也不用配 GPU 工作站,浏览器登录就行。
第一步:在线浏览资产
打开网页就能看资产、建筑模型和 3D 高斯泼溅模型,每个资产的属性、语义标签、关节信息都能直接查。看到合适的,可以在线转成 OpenUSD 格式,部分开源资产能直接下载。
第二步:拖拉拽搭场景
Web 端内置了场景搭建工具,资产、建筑、3D 高斯模型直接拖进场景、调位置,就能搭出一个符合真实逻辑的交互环境。如果想要更多训练样本,平台集成了基于大模型的泛化能力,自动调整灯光、天气、材质和物体位置------一个场景能扩展出大量变体,省去人工反复布置的麻烦。
第三步:云端跑 Isaac Sim
搭好场景后不用导出文件本地跑。Synthesis 基于 NVIDIA Isaac Sim 的 WebRTC 推流方案做了深度定制,搭了一套 Isaac Sim 集群,可以部署在公有云或私有云。仿真和数据采集人员浏览器登录就能加载场景、做交互、采数据,平台会监控每个 Isaac Sim 实例的状态并动态调度 GPU。
对团队来说,这意味着不需要给每个工程师配工作站,也不用担心 GPU 闲置。
进阶用法:本地操作 + 云端同步采集
如果是做遥操作数据采集,平台还提供了定制的通信组件,能把传感器数据(IoT、遥操信号)低延迟广播到集群里的每个 Isaac Sim 实例。一台终端操作,多个云端环境同步采集。
既不占本地算力,又能成倍提高效率。

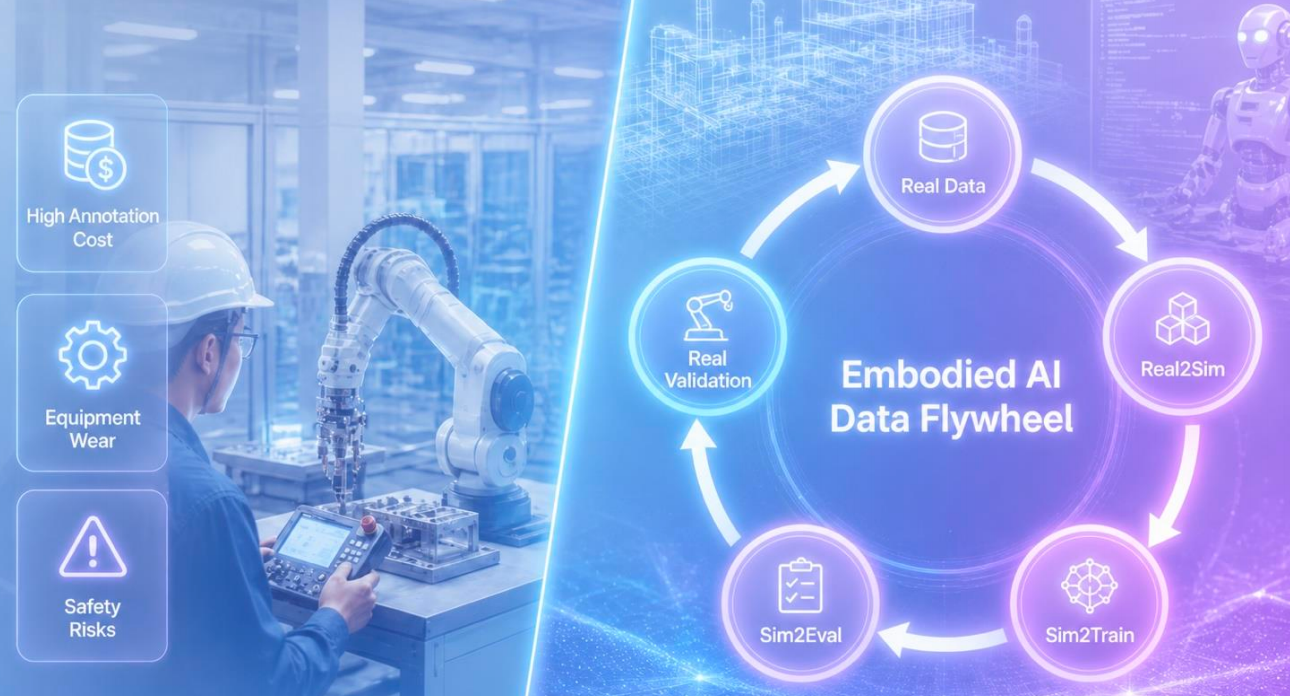
3.6 完整的数据飞轮
除了仿真资产本身,Synthesis 还接入了真实工程世界中的多源异构数据:工程模型、GIS 数据、720 全景、IoT 数据、点云倾斜摄影、图档信息。
所有这些都可以汇入同一个仿真环境。
这才是一个完整的"数据飞轮":
- 真实数据提供物理世界的基准分布和锚点
- Real2Sim(数字孪生) 把真实空间、设备、流程转化为可仿真的数字环境
- Sim2Train(仿真训练) 批量生成任务、扰动、失败样本和长尾场景
- Sim2Eval(仿真评测) 做回归测试、安全性测试和鲁棒性测试
- 真机验证在真实设备和场地中验证策略表现,反馈再回流到孪生体系
这条飞轮转起来,仿真和真机之间的差距才能越来越小。
四、效果说话:ArtVIP 项目的实证
理论讲得再好,最后还是得看实验数据。
4.1 ArtVIP 是什么
ArtVIP 全名是 Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning,是孪界参与建设的开源铰链资产数据集------216 个铰链资产 + 6 个全交互场景。
它有几个硬指标:
- AI 顶会 ICLR 2026 接收
- Nvidia Isaac Sim 官方文档推荐的仿真资产库(全球只有两家入选)
- Hugging Face 累计下载超 10 万次
- EAI-100 年度具身智能十大数据集
- 与北京人形机器人创新中心共同维护,持续更新

4.2 ArtVIP 资产是怎么做出来的
ArtVIP 的资产构造方式很值得细看。
它能讲清楚"为什么孪界这条工具链做出来的资产,比公开数据集高一个档次"。
每个资产都是按"自顶向下的组装原则"构造的。以一个微波炉为例:
- 先定义主体 body(带 mesh 和材质)
- 再定义门 door(带 mesh,通过 revolute joint 与主体连接)
- 然后是两个旋钮 knob A/B(一个用 revolute joint,一个用 prismatic joint)
- 一个按钮 button
- 内部还有灯 light
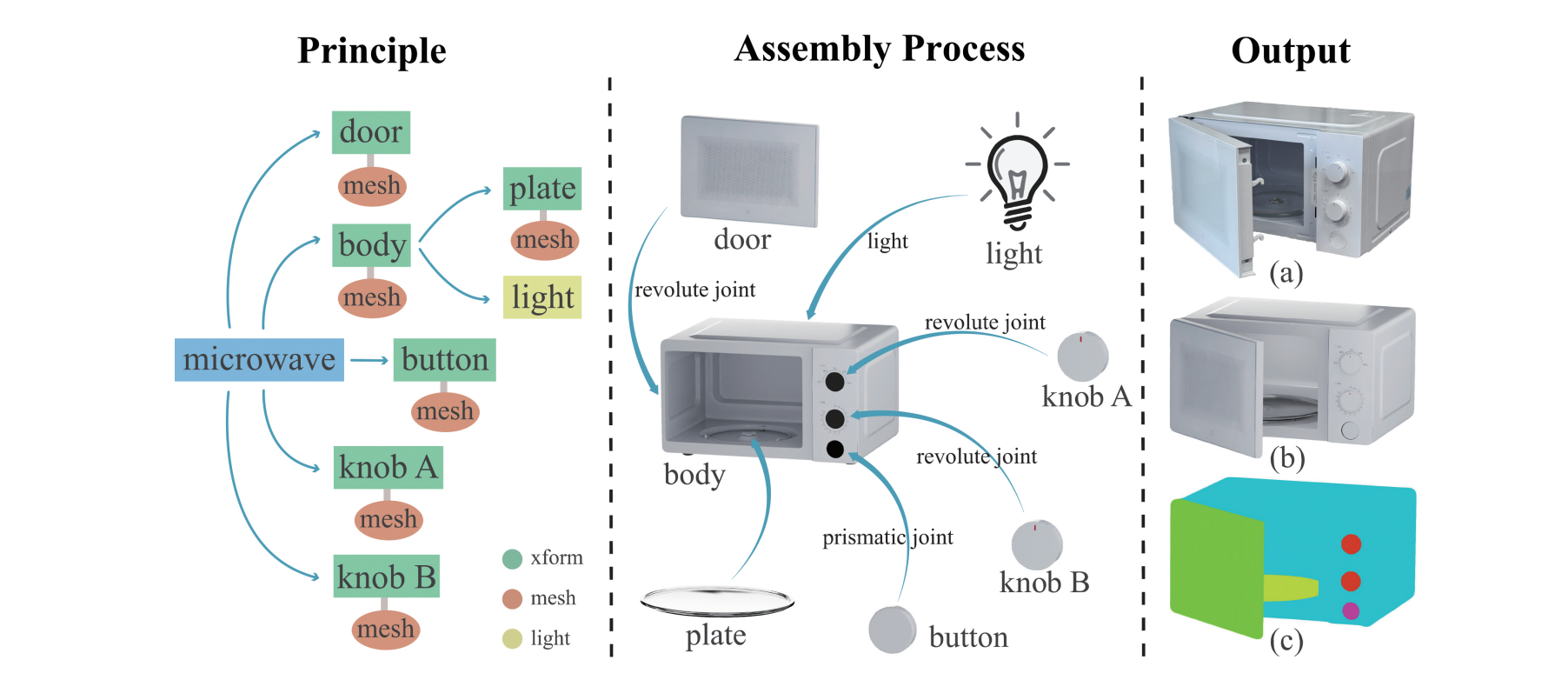
每个组件之间的运动学关系、铰链类型、坐标系、碰撞体都被精确定义。最终输出三件套:真实物体照片 → 数字孪生模型 → 语义标注,三者严格对齐。
这种做法的结果是什么?看数据:
- 资产的三角面片数远高于 PartNet-Mobility 和 Behavior-1K,意味着几何精度更高
- 视觉真实度在 ArtVIP / Behavior-1K / PartNet-Mobility 三者中排名最高
- CLIP 特征分布显示 ArtVIP 资产的特征分布与真实世界数据高度对齐,而其他数据集(OmniGibson、Sim-OmniGibson)则明显偏离
4.3 关键实验数据
最有说服力的是迁移实验。研究团队用 Franka 机械臂做了四个真实世界任务的模仿学习实验:拉抽屉、开柜门、推拉书架门、关烤箱门。
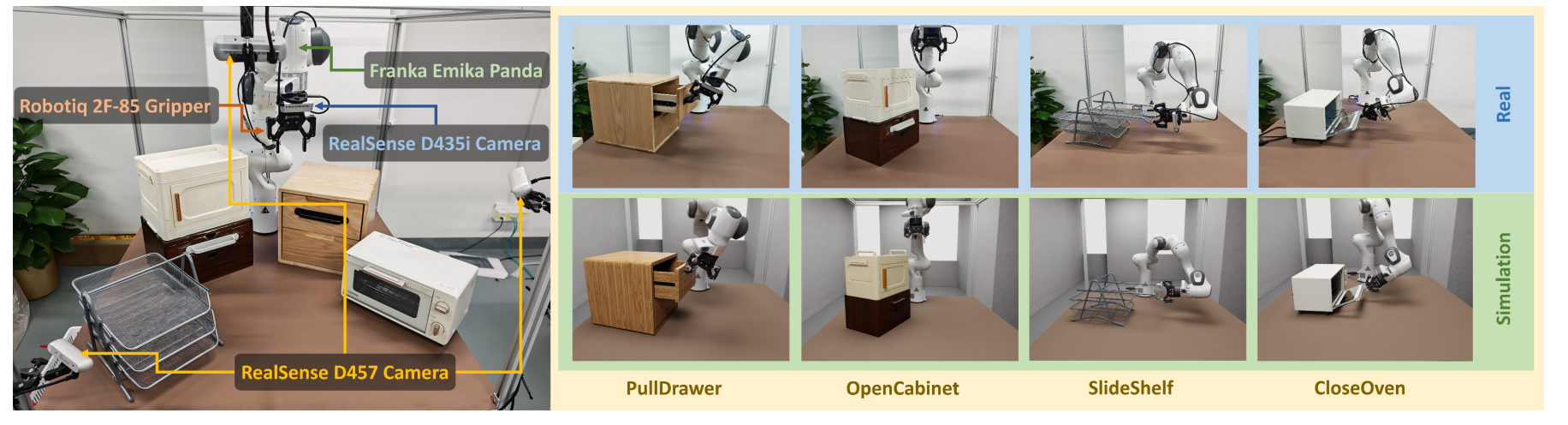
实验设置:三种数据配置------只用真机数据(RO)、只用仿真数据(SO)、真机+仿真混合(RSM)。
核心结果:
- 数据分布与真实世界对齐度,比同类仿真资产提升 47%
- 只用 ArtVIP 仿真数据训练 的 Diffusion Policy,零样本迁移到真实 Franka 机械臂做关门任务,成功率 30%
- 加少量真机数据混合训练 后,开门任务成功率跃升至 80%
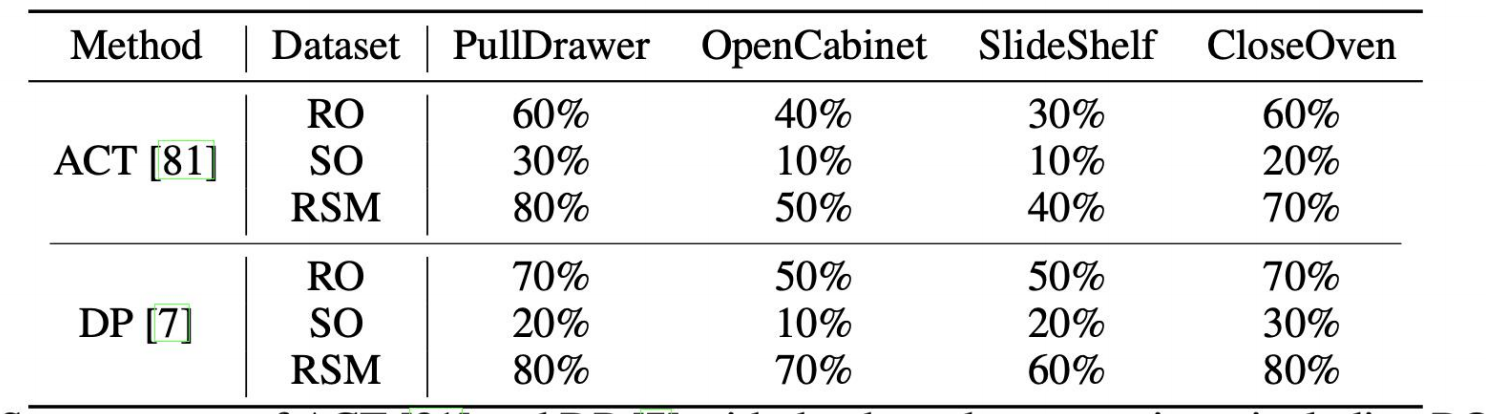
这说明仿真数据不是只能"预训练",而是能实打实地撑起最后一公里。在 ACT 和 DP 两种主流策略上,RSM(混合训练)的成功率在所有四个任务上都显著高于纯真机或纯仿真。
也就是说:好的仿真资产 + 少量真机数据,能跑赢只用真机数据的方案。 这对成本和效率都是数量级的提升。
4.4 ArtVIP 为什么能做出来
回到本文的核心论点:为什么是孪界做出了 ArtVIP,而不是别人?
不是因为算法多牛------开门关门这些任务,用的都是公开的 Diffusion Policy 和 ACT。差距在资产本身。
ArtVIP 的每一个铰链资产,都要经过几何重建、关节标定、材质映射、物理参数预设、碰撞体生成、语义标注、人在环验证这一整套流程。如果没有自主的资产生产工具链,靠人工一个一个做,216 个资产可能要做两年;有了工具链,效率高一个数量级,质量还更稳定。
而这条工具链的搭建,又依赖于背后十几年数字孪生引擎的积累、几十年真实工程数据的训练,以及顶级设计院的专业团队资源。这是一条别人想抄都不容易抄的护城河。
五、行业在动,方向已经清楚
不只是孪界一家在做这件事。
全国多地都在加速建具身智能训练场,北京亦庄、石景山、上海、广州、宁波、苏州、合肥都有项目落地。2025 世界机器人大会发布的"十大发展趋势"里,"物理实践、物理模拟器与世界模型协同"明确入选。更广的产业趋势上,NVIDIA、Apple、Pixar、Microsoft等科技巨头全都在押注 OpenUSD 作为三维场景描述与互操作中间层。
仿真合成数据,本质上是给物理 AI 准备一个能反复练习的世界。这个世界做得越接近真实,AI 走出实验室之后摔的跟头就越少。而要做出一个真实正确的世界,光靠图形学不够,光靠物理引擎也不够,还得有几十年的工程数据、几十年的标准规范理解、几十年的真实场景积累打底。
这有点像盖楼:
大家都关心楼顶上的景观和外立面,但决定楼能盖多高的,永远是地基下面那几十米看不见的桩。
仿真资产就是物理 AI 这栋楼的桩。