起因很简单:想做个小工具,打几个字出一张图。结果一路踩坑踩着踩着,发现搞出来的不是工具------是个五体联动的 Agent。它能看(前端算法当眼睛)、能想(大模型当脑子)、能画(Canvas 当手)、还能自我反省(迭代修正)、甚至自带工具箱(绘图模式库)。
这篇文章就是讲我们怎么一步步从"画了个寂寞"走到"画了个 Agent"的。
一、起点:一个胆大包天的想法
用户打几个字,AI 出一张图------这事儿 DALL-E、Midjourney 早就干得风生水起了。问题是,我们手头只有 DeepSeek,一个纯文本模型。它别说看图了,它连"红色长什么样"都不知道。
正常人到这一步就该去买 API 了。但我们偏不------
模型不会画图?那让它写画图的代码呢?
浏览器的 Canvas 2D API 本来就是个绘图引擎,给段 JavaScript 就能画圆画线画渐变。模型要是能输出 Canvas 代码,浏览器跑一下,图不就来了?
ini
用户:"画一个心形"
↓
模型输出代码:
ctx.beginPath();
ctx.moveTo(W*0.5, H*0.25);
ctx.bezierCurveTo(...);
ctx.fillStyle = '#e74c3c';
ctx.fill();
↓
浏览器跑代码 → Canvas 渲染 → 真出图了!"文字 → 代码 → 跑代码 → 图"------这条链路,就是整个故事的起点。
跟扩散模型不是一回事:扩散模型是在像素层面直接生成,我们是先出代码再跑。好处是:出来的不是一坨不可解释的像素,而是一段能读、能改、能复用 的代码。改一行 fillStyle 就换个颜色,扩散模型做梦都做不到。
当然,这是后话------当时我还沉浸在"居然跑通了"的喜悦里,完全不知道接下来要被现实教做人。
二、现实的第一巴掌:画出来辣眼睛
用户输入"蜡笔小新",满心期待会看到一个萌萌的小新------
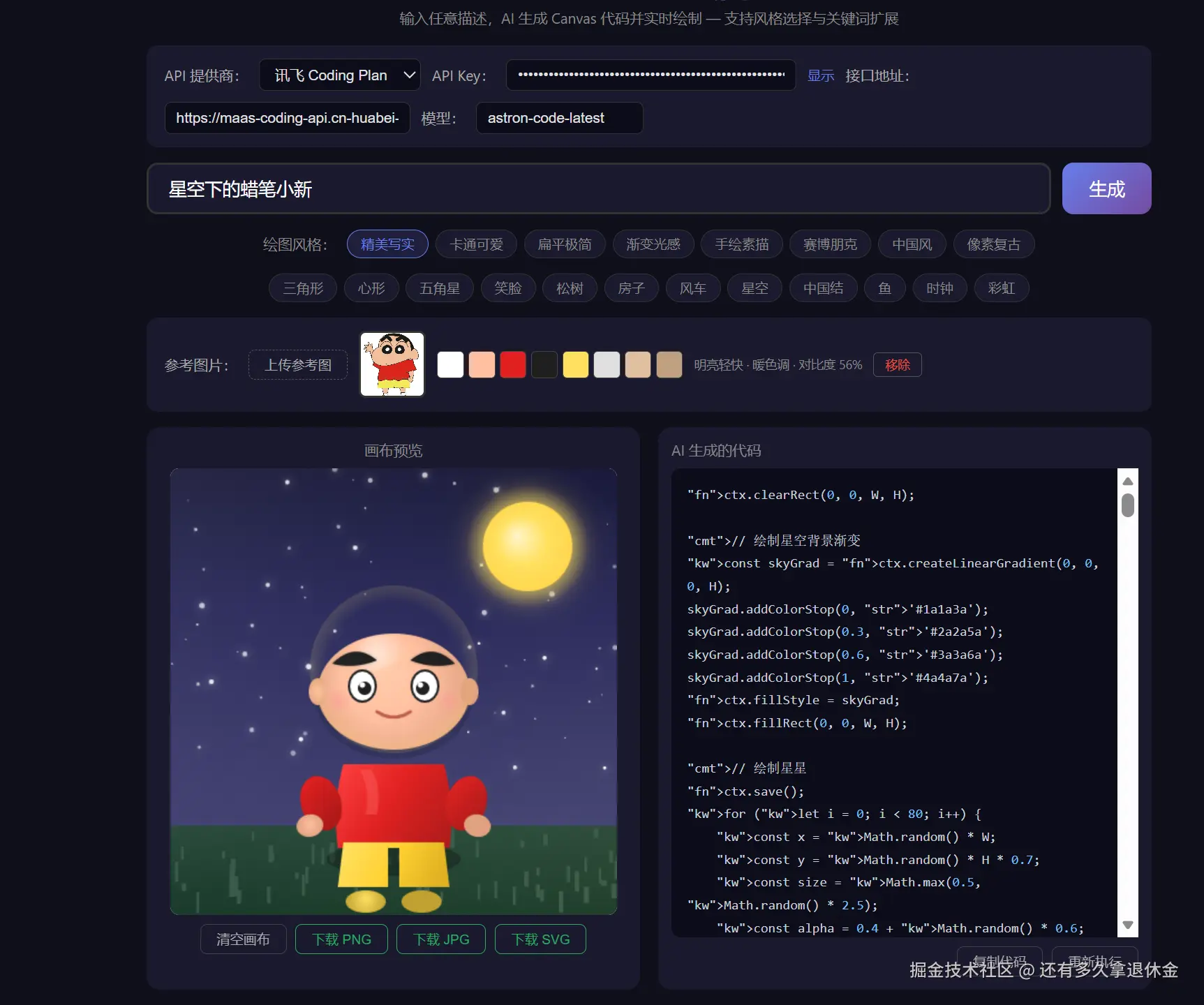
------然后我们看到这个。
几根线条拼的火柴人,脑袋是个圆,身体就几条线。没渐变没阴影,脸倒是画了,但跟毕加索抽象画似的。说它是蜡笔小新吧,不如说是蜡笔小新的灵魂出窍版。
为啥这么丑?因为模型就知道"蜡笔小新"四个字。它哪知道:
- 小新的脑袋得是大椭圆,不是正圆------正圆那是足球
- 腮红得用淡粉色半透明圆叠上去,不是画个红色方块------方块那是腮红贴纸
- 粗眉毛得有粗细变化,不是两条直线------直线的那是 = 号
- 整体得有粗黑轮廓线(lineWidth=4),不是细线勾边------细线那是草图
它不是不会画,是不知道怎么画才好看。
这就好比你跟一个从没画过画的人说"画个小新"------他说"我知道小新长啥样",然后画了个这玩意儿。你得手把手告诉他"脑袋用椭圆、腮红用半透明粉色圆、眉毛 lineWidth=4、整体 Q 萌圆润",他才能画得像那么回事。
这就是第一个教训:给模型"方向"没用,得给"技法"。
三、发现一:说"画好看点"跟没说一样
我们做了一个对比实验,只改 Prompt,模型不动:
笼统说(画得丑出天际)
markdown
你是 Canvas 绘图代码生成器。要求:
1. 代码必须精美
2. 善用渐变和阴影
3. 图形大小适中模型看到"善用渐变",心想"行,加个渐变",然后加了个最简陋的 createLinearGradient 就交差了。就像跟厨师说"菜做好吃点",他多放了点味精就觉得完事了。
给技法(效果炸裂)
ini
▶ 立体感技法:
- 球体:用径向渐变 ctx.createRadialGradient,高光偏左上,阴影偏右下
- 发光效果:ctx.shadowBlur=20; ctx.shadowColor='rgba(255,200,0,0.8)';
- 高光:用白色半透明弧线 ctx.strokeStyle='rgba(255,255,255,0.3)'效果直接跳了一个档次。
为什么?因为大语言模型的本质就是续写。你给它 ctx.shadowBlur=20,它顺理成章就接着写 shadowColor------这俩本来就该配对出现,模型见过无数次了。你给它"善用渐变"四个字,它得自己猜你要啥渐变,猜出来的当然是最偷懒的那种。
原理其实很有意思:LLM 的训练数据里 Canvas 代码多如牛毛,但"善用渐变"这四个字很难把相关代码从记忆里捞出来。而具体的 API 调用和参数值,就像钥匙------一捅就开,相关的代码模式哗啦啦全涌出来了。
别给抽象指令,给代码片段。 这是第一条铁律。
 哇趣更丑了,也是没招了~
哇趣更丑了,也是没招了~
四、发现二:风格这玩意儿不能靠"悟"
"赛博朋克风格"------你脑子里立马霓虹灯、深色背景、发光线条全来了。但模型呢?它可能觉得"赛博朋克=未来感",给你画个蓝色渐变就完事。就好比你跟理发师说"剪个帅的",出来的永远是寸头。
所以我们把 8 种风格全从虚词描述 改成了精确配方:
scss
❌ "赛博朋克:使用霓虹色系,深色背景,添加发光线条效果"
→ 模型:懂了,蓝色渐变走起!
✅ "赛博朋克风格。必须使用:
(1) 深色背景 #0a0a1a
(2) 霓虹色 #ff00ff / #00ffff / #ff6600
(3) shadowBlur=25 + shadowColor=同色做发光
(4) 细线条网格/电路
(5) 高对比度 + 故障效果"
→ 模型:好的配方收到,照做!模型不用"理解"赛博朋克,照配方做就行。做饭给厨师"适量盐"不如给"5克盐",道理一模一样。
风格 = 参数配方,不是文字描述。 凡是靠模型"悟"的地方,一律转成参数列表。悟性这东西,模型真没有。

五、发现三:模型没眼睛?那就给它装一双
用户想传一张参考图让 AI 照着画。但 DeepSeek 是纯文本模型,图片根本喂不进去------就好比让一个盲人临摹蒙娜丽莎。
换别人可能就放弃了。我们换了个思路:模型看不见图,但浏览器能啊。 用前端算法帮模型"看",然后把看到的东西翻译成它能懂的语言。
怎么给模型"装眼睛"
用户上传图片后,浏览器里跑三层分析,不到 100ms 搞定,一分钱 API 费用不花:
第一层:8×8 颜色网格------把图缩到 200×200,切成 64 格,每格算平均颜色。相当于把一张高清图变成 64 个色块,粗是粗了点,但大方向有了:
css
[深蓝][深蓝][蓝色][蓝色][绿色][绿色][深绿][深绿] ← 上面:天空
[深蓝][蓝色][蓝色][绿色][绿色][深绿][深绿][棕色] ← 中间:过渡
[绿色][绿色][深绿][深绿][棕色][棕色][棕色][棕色] ← 下面:大地第二层:Sobel 边缘检测------用 3×3 的卷积核扫一遍,算出每个像素的梯度大小,轮廓就显形了。这个是正经的计算机视觉算法,上世纪的发明的,到现在还好使:
scss
Sobel 水平核: Sobel 垂直核:
[-1 0 1] [-1 -2 -1]
[-2 0 2] [ 0 0 0]
[-1 0 1] [ 1 2 1]
梯度 = √(水平² + 垂直²)然后把边缘图切成 3×3 九宫格,数每个格子里有多少边缘:
- 中心密度高 + 左右对称 → "中间有个对称的东西(圆/心形/菱形)"
- 上下都有水平边缘 → "有地平线"
- 左右都有垂直边缘 → "有建筑/树"
第三层:对称性 + 构图分析------左右边缘密度差多少判断是否对称,中心和四角密度差多少判断主体是否居中。
关键转折:别翻译成话了,直接出代码!
最开始我们把分析结果转成一段中文扔给模型:

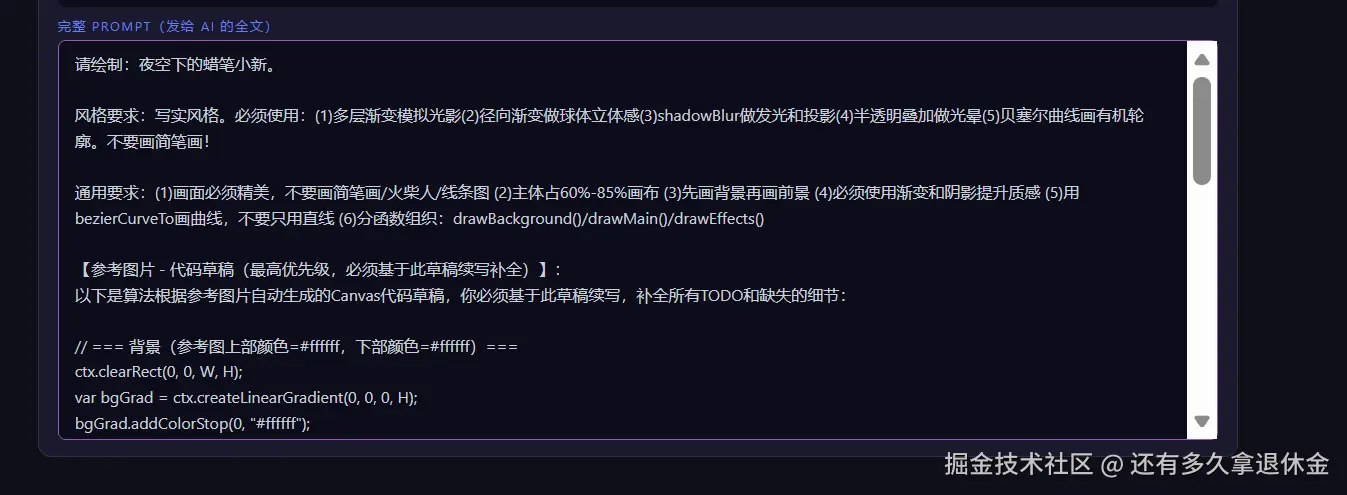
模型收到这段话,还得自己翻译成代码------这一步又丢精度,就像你跟老外说"那个圆圆的、红红的、亮亮的东西",他得猜你说的是苹果还是西红柿。
后来一拍大腿:干嘛不直接给代码呢?
于是 generateCodeDraft() 的输出从文字变成了 Canvas 代码片段:
javascript
// 算法直接出的代码草稿------颜色都是真从图里提的
ctx.clearRect(0, 0, W, H);
var bgGrad = ctx.createLinearGradient(0, 0, 0, H);
bgGrad.addColorStop(0, "#1a3a5c"); // ← 从颜色网格提的:上面主色
bgGrad.addColorStop(0.5, "#2d5a27"); // ← 中间主色
bgGrad.addColorStop(1, "#4a3210"); // ← 下面主色
ctx.fillStyle = bgGrad;
ctx.fillRect(0, 0, W, H);
// TODO: 中心画主体(边缘检测发现中心有对称轮廓)
ctx.save();
ctx.beginPath();
ctx.moveTo(W * 0.5, H * 0.2);
ctx.bezierCurveTo(W * 0.75, H * 0.2, W * 0.8, H * 0.5, W * 0.5, H * 0.8);
ctx.bezierCurveTo(W * 0.2, H * 0.5, W * 0.25, H * 0.2, W * 0.5, H * 0.2);
// TODO: 加渐变、高光、阴影
ctx.restore();模型拿到这段代码,只需要接着往下写。不用从零开始。这就像给建筑师一张草图让他细化,比给他一段文字让他从头画靠谱一万倍。
这是整个优化里效果最猛的一步。 模型从"翻译者"变成了"完善者",而续写代码恰恰是 LLM 最拿手的活------这不就是它的本职工作嘛。
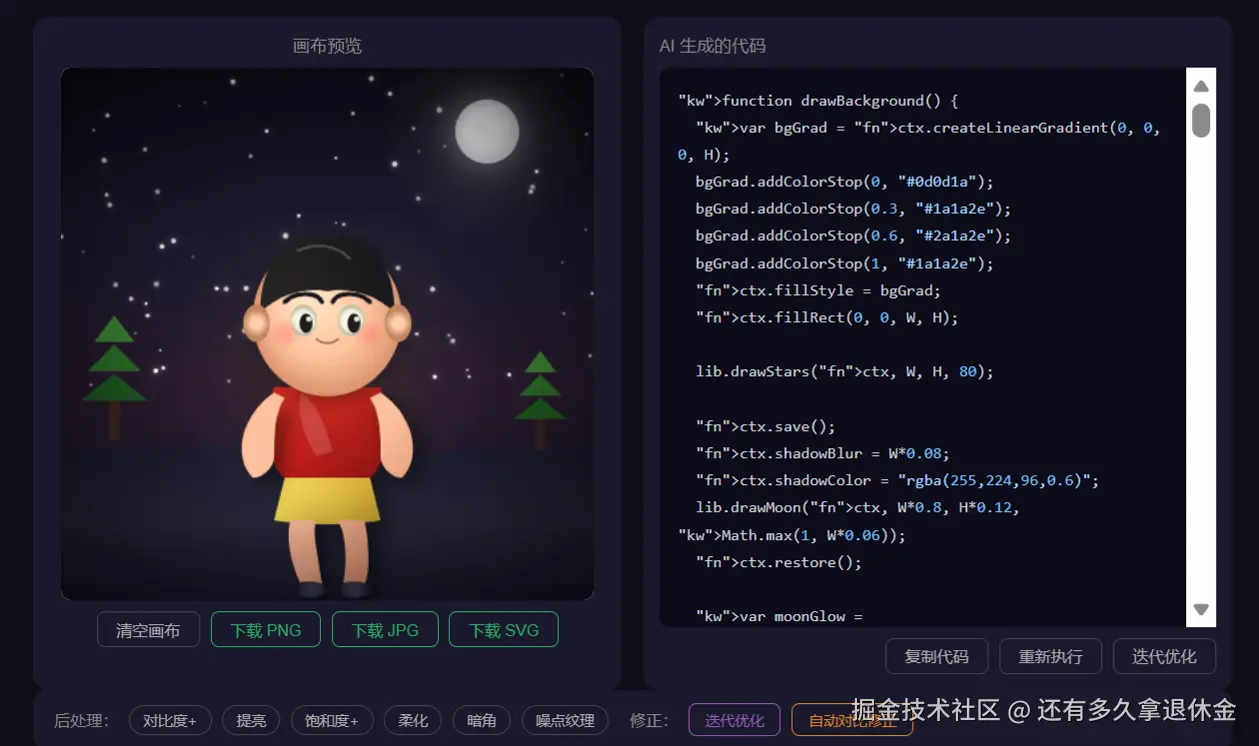 没招了,主包心疲力竭!!
没招了,主包心疲力竭!!
六、发现四:像人一样分层画、反复改
分层画:多遍渲染
正经画师不是一笔画完的。先铺底色,再画主体,最后加细节。你见过谁先画睫毛再画脸的?
我们把这个规矩写进 System Prompt,让模型乖乖按层次来:
javascript
function drawBackground() { ... } // 天空、地面、水面------先铺底
function drawMidground() { ... } // 山、建筑、树------再加景
function drawMain() { ... } // 主体人物/物体------画主角
function drawEffects() { ... } // 光晕、阴影、粒子------最后加特效
ctx.clearRect(0, 0, W, H);
drawBackground();
drawMidground();
drawMain();
drawEffects();为啥管用 :模型一口气写 200 行代码容易出幺蛾子------变量冲突、状态乱套、画到一半忘了 ctx.restore()。但一次只写 40 行(一个层次)就稳多了。就像写论文,一口气写 2000 字容易跑题,拆成 5 个 400 字的小节就靠谱多了。
反复改:迭代修正循环
扩散模型有 50 步去噪迭代,每步都在修上一步的结果。我们的模型倒好,一次性吐完代码就完事了------画错了?那就错了。
所以我们给它加了两个修正机制,让它学会"画了看看、看看再改":
手动迭代:用户说"颜色太暗、主体偏左",模型改代码重新跑。就像甲方说"Logo 再大一点",乙方改了再提交。
自动对比修正:渲染完自动把生成图和参考图放一块比------
javascript
// 算一下生成图有多亮
var genBright = 算Canvas平均亮度();
var genTopColor = 提取主色();
// 和参考图比对
if (|genBright - refBright| > 30) {
反馈 += "亮度不对," + (生成图亮了 ? "降" : "提") + "亮度";
}
if (genTopColor != refTopColor) {
反馈 += "主色不对,应该用 " + refColor;
}
// 把反馈喂给模型,让它改代码改一轮,好一档。这玩意儿干了两件事:一是模拟了扩散模型的去噪过程(每轮都在逼近目标),二是模拟了人类画师的工作习惯------哪有画一遍就交稿的?


七、发现五:与其让模型现发明轮子,不如给它一个轮子
模型每次画图,都得从零琢磨"云怎么画""水面怎么画"。但说真的,云就是几个半透明圆叠一块,水面就是波浪线加反光------画法是固定的,让模型每次重新发明纯属浪费时间。这就好比每次做菜都从打铁造锅开始。
所以我们建了一个绘图模式库(DRAW_LIB),12 个现成函数,直接调:
| 函数 | 画啥 | 怎么画的 |
|---|---|---|
lib.drawSky(ctx,W,H,'sunset') |
天空 | 线性渐变4色过渡 |
lib.drawCloud(ctx,x,y,25) |
云朵 | 5个半透明圆叠一块+发光 |
lib.drawSun(ctx,x,y,r,true) |
太阳 | 径向渐变+光晕shadowBlur |
lib.drawMoon(ctx,x,y,r) |
月亮 | 径向渐变+画几个环形坑 |
lib.drawStars(ctx,W,H,60) |
星星 | 随机撒点+shadowBlur发光 |
lib.drawMountain(...) |
山 | 贝塞尔曲线+前后色差 |
lib.drawTree(...,'pine') |
树 | 三角叠加或圆形树冠 |
lib.drawWater(...) |
水面 | 波浪线+反光 |
lib.drawGrass(...) |
草地 | 随机弧线+渐变底色 |
lib.drawFlame(...) |
火焰 | 贝塞尔曲线+径向渐变 |
lib.drawVignette(...) |
暗角 | 径向渐变遮罩 |
lib.drawNoise(...) |
噪点 | 3000个随机透明度小点 |
以前模型要自己琢磨天空渐变怎么画,现在一行 lib.drawSky(ctx, W, H, 'sunset') 搞定。
这就跟 React 组件库一个道理 ------你不手写 <div> 拼页面,你用 <Button> <Card>。绘图模式库就是 Canvas 的组件库。
原理很简单:把"画什么"和"怎么画"拆开。 模型负责决定"画面里要有什么"(创意层),模式库负责"怎么画好看"(技法层)。模型出创意,库出技术,各司其职。
八、回过神来:等等,我们造了个 Agent?
写着写着自己都觉得不对劲------回头看整个系统,它其实是一个五体联动的 Agent:
css
┌─────────────────────┐
│ 用户输入 / 参考图 │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ 感知 Agent(眼睛) │
│ Sobel + 颜色网格 │
│ + 对称性分析 │
│ → 输出:代码草稿 │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ 规划 Agent(大脑) │
│ 文本大模型 │
│ + 技法式Prompt │
│ + 风格参数配方 │
│ + 坐标约束 │
│ → 输出:Canvas代码 │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ 执行 Agent(双手) │
│ Canvas 2D 运行时 │
│ + 绘图模式库 │
│ → 输出:渲染图像 │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ 评估 Agent(裁判) │
│ 亮度/主色/对比度对比 │
│ → 输出:差异反馈 │
└──────────┬──────────┘
│
┌──────────▼──────────┐
│ 修正 Agent(反思) │
│ 迭代修正循环 │
│ → 回到"规划Agent" │
└─────────────────────┘最离谱的是:这五个体不是五个模型,而是一个模型 + 四套算法。
- 眼睛不是视觉模型,是 Sobel 边缘检测 + 颜色网格------穷人的视觉皮层
- 大脑不是多模态模型,是普通文本模型 + 技法式 Prompt------嘴替型大脑
- 手不是扩散模型,是 Canvas 2D API + 模式库------工具人之手
- 裁判不是人类标注,是像素级亮度/颜色自动对比------无情打分机
- 反思不是 RLHF,是迭代修正循环------自我反省靠循环
算法补位,不等模型进化。 缺啥能力就自己写算法补上,别等模型厂商更新。这就是整个发现的方法论。
九、这事儿在 Agent 领域意味着啥
1. Agent 不一定非得是多模态
现在的主流观点是:视觉任务得用视觉模型。但我们的实践说:把视觉信息转成代码,用代码做中间人,文本模型照样能干视觉的活。
代码这个中间表示极其牛------比自然语言精确 100 倍,又比像素矩阵好理解 1000 倍。它刚好卡在"人能读懂"和"机器能执行"的甜蜜点上。
2. 工具是 Agent 能力的放大器
绘图模式库让模型从"我得发明怎么画云"变成"调 drawCloud() 就行"。跟人用工具一个道理------厨师不用自己打铁造菜刀,程序员不用自己写排序算法。
预置技能包 = Agent 的工具箱。 工具越多能干的事越多,但每个工具模型不用"学会"------知道怎么调就行。调 API 谁不会啊。
3. 闭环控制是 Agent 质量的关键
没修正循环的 Agent 是开环------出来啥样就啥样,像蒙着眼射箭。加了修正变成闭环------出来→评估→改→再出来,每轮都更接近目标,像有瞄准镜的射击。
我们的自动对比逻辑挺糙的(就比亮度和主色),但已经证明闭环管用。如果对比维度更细(构图位置、元素完整性、风格匹配度),效果还能再上一个台阶。
4. 代码空间比像素空间更适合 Agent 搞事
扩散模型在像素层面操作,想"只改颜色不改形状"?做不到。代码空间天然支持精确的局部修改 ------改一行 fillStyle 就改颜色,改一行 bezierCurveTo 参数就改形状,互不影响。
Agent 在代码空间里自由度更大、控制力更精确。这对需要反复修正的场景是决定性优势------就像修图用图层比直接画死在画布上强一万倍。
十、总结
分量
- 文本模型 + 代码执行 = 图像生成,跑通了,成本就是聊一次天的钱
- 输出可编辑------改一行代码换个颜色,扩散模型做梦做不到
- 输出可复用------画天空的函数随便搬到别的图里用,像素图做不到
- 全程透明------从感知到规划到执行到评估到修正,每步都能看能调试
- 算法补位 > 模型升级------不等模型进化,缺啥能力自己补
短板(说点实话)
- Canvas 2D 的天花板就是卡通/插画级别,别指望画照片------它终究不是 Photoshop
- 超过 3 个元素的场景模型就慌了,坐标开始乱飘------画个人还行,画个广场舞就崩溃
- 自动对比修正维度太少(就亮度/主色/对比度),需要更细------目前约等于色盲体检
- Sobel 只能看出"这有轮廓",认不出"这是只猫"------它是个算边缘的,不是认猫的
接下来想搞的
- 加物体检测(比如前端跑个轻量 YOLO),让"眼睛"从"看到轮廓"升级到"认出东西"
- 更细的评估维度(构图偏差、元素有没有画全、风格匹不匹配)
- 学用户喜好------记住"这人喜欢暗色调",以后自动注入
- 模式库继续扩------像 npm 包一样攒,12 个变 100+ 个
结语
这个发现的核心不是"Canvas 能画图"------谁不知道 Canvas 能画图啊。核心是:一个文本模型怎么靠代码这个中间层,获得了它本来没有的视觉能力。
代码是连接"语言"和"画面"的桥。模型说"画个红圆",这话变成代码 ctx.arc(W*0.5, H*0.5, 50, 0, Math.PI*2); ctx.fillStyle='#e74c3c'; ctx.fill(),浏览器一跑就出图了。
从"说"到"画",中间就隔一层代码。而代码,恰好是大语言模型最拿手的东西。
这不是要跟 DALL-E 掰手腕。是在 DALL-E 够不着的地方------零成本、可编辑、可复用、全程透明------蹚出一条路来。而这条路的尽头,是一个五体联动的 Agent:有眼睛、有脑子、有手、有判断力、还能自己改自己。
虽然画出来的蜡笔小新还是有点灵魂出窍,但至少------它是带着灵魂出窍的。