上一篇写 Agent 做长任务。
那篇最想说的一点很简单:模型停了,不代表任务完成。
所以需要 Spec 把任务拆清楚,需要 ReAct 让模型进入执行现场,需要 Ralph 在外面套一层 loop,也需要 Codex Goal 这种 runtime 原生的目标管理能力。
但这些主要解决一个问题:
Agent 怎么持续把一个长任务往前推?
这篇继续往后看。
因为一个 Agent 能循环,不等于它真的好用。它可能每次都从零开始想,过程看不见;它看起来忙了很久,结果却没变好。
所以我想用这几张图,把 Agent 后面的东西讲清楚:
text
Loop:怎么跑起来
Runtime / HITL:怎么被控制
Goal:怎么判断没达标不能停
Skill:经验怎么沉淀和复用
Framework:过程怎么承载
Eval:效果怎么评估和迭代理解 Agent,不只是会调 API。更重要的是看懂运行循环、能力封装、框架机制和评测优化。
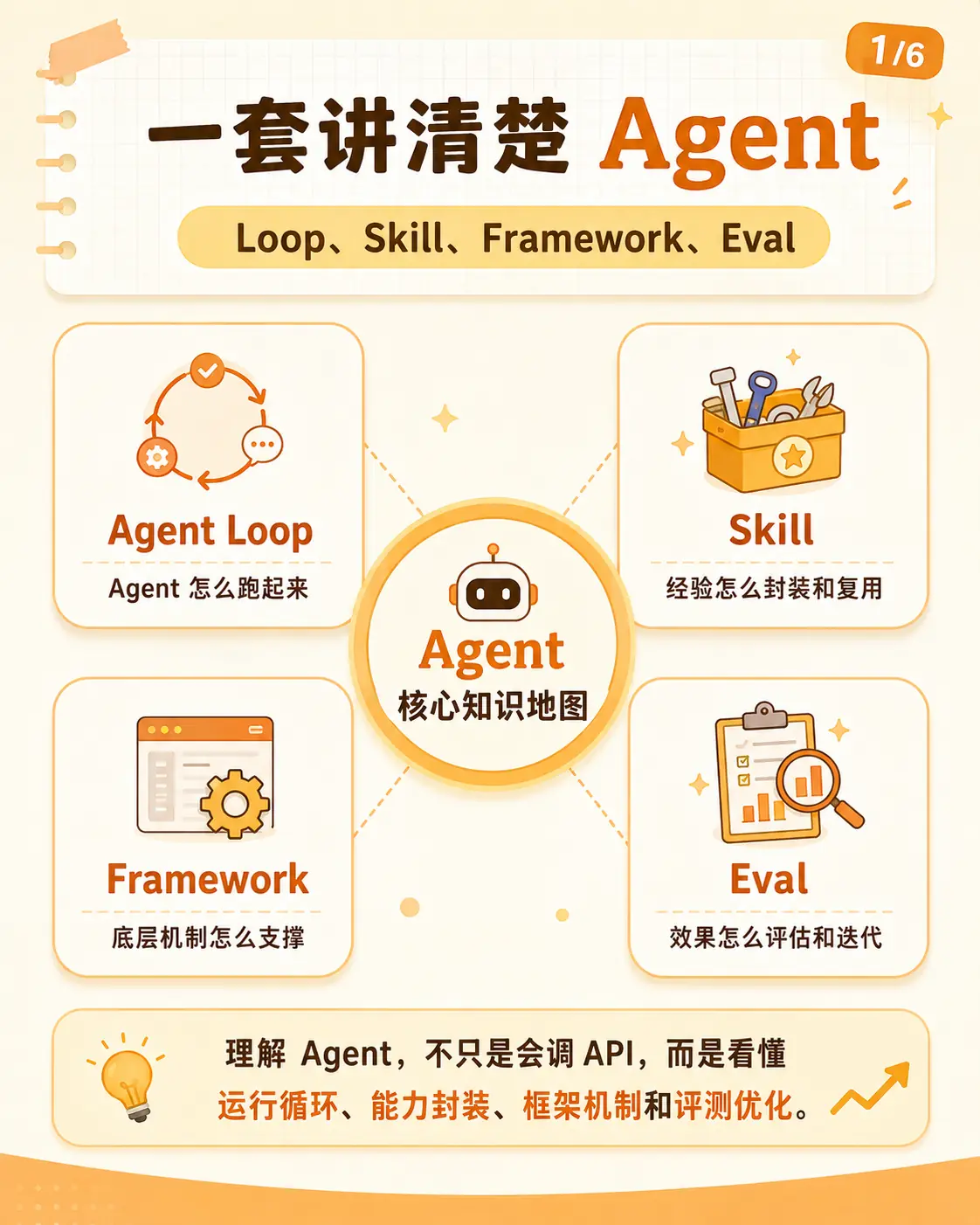
1. 总览:一套讲清楚 Agent
第一张图其实是整篇的目录。
很多人理解 Agent,会先从模型、工具调用、API 编排开始。这当然没错,但只看这些,很容易把 Agent 理解成"会自动调用工具的聊天机器人"。
跑起来以后,问题会变得具体很多:
text
它怎么一轮一轮往前走?
它什么时候该停?
它能不能复用以前的经验?
执行过程能不能被用户看见?
失败后能不能恢复?
怎么知道这次改动真的变好了?所以我更愿意把 Agent 拆成四块看:
text
Loop:让它能持续执行
Skill:让经验能留下来
Framework:让过程能被承载
Eval:让改进有证据上一篇讲的是 Loop。这篇的重点,是 Loop 之后还缺什么。
2. Loop:Agent 怎么跑起来
Agent 不是一次性回答问题,而是一个循环。
最基础的形态就是 ReAct:
text
思考 → 行动 → 观察 → 再思考模型先判断下一步要做什么,然后调用工具,拿到结果,再根据结果继续判断。这个循环跑起来以后,Agent 才不只是"回答",而是在"做事"。
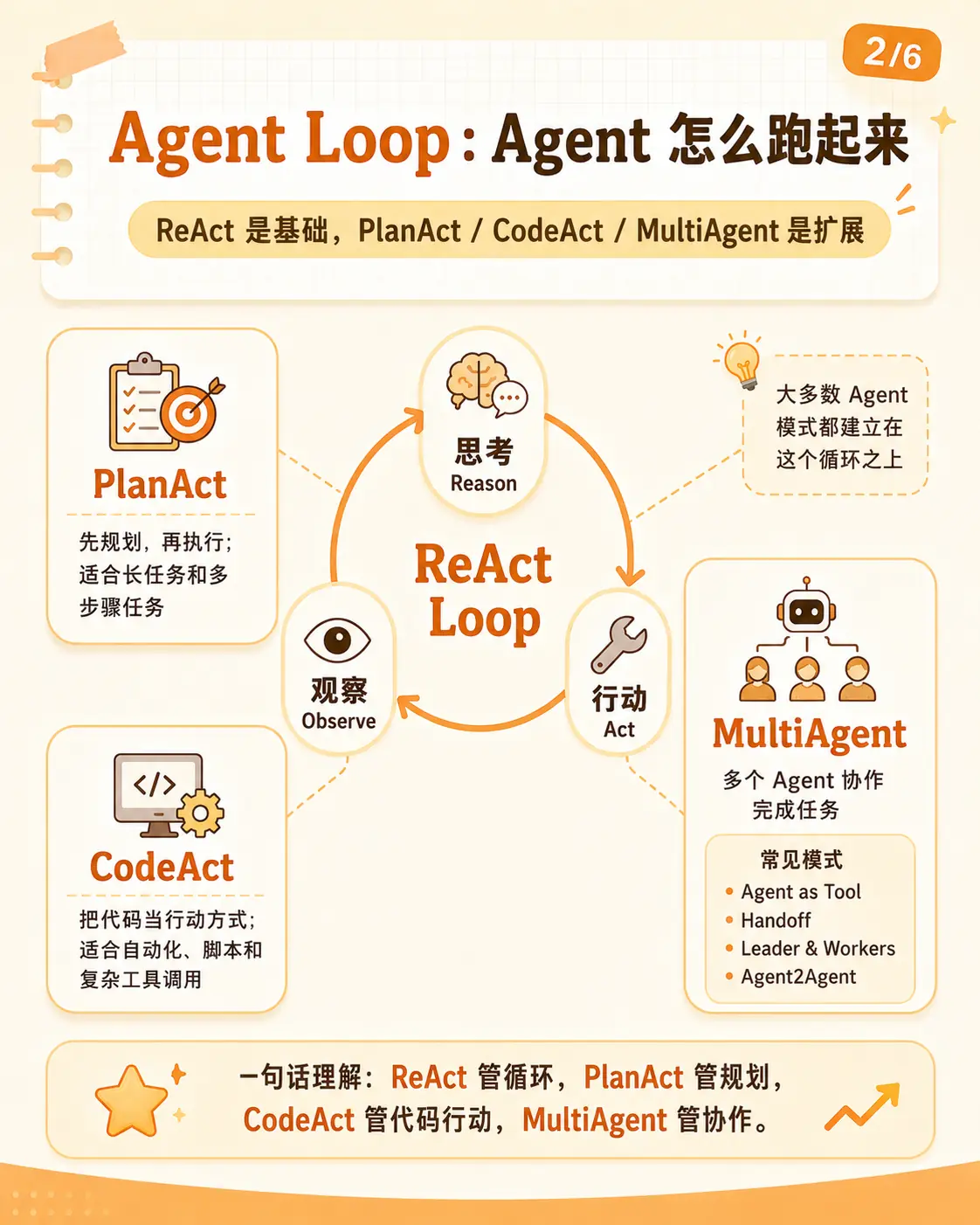
PlanAct、CodeAct、MultiAgent 都可以放在这个循环上理解。
PlanAct 是先规划,再执行。它适合长任务、多步骤任务,不然模型很容易做到哪算哪。
CodeAct 是把代码当成行动方式。对自动化、脚本、复杂工具调用来说,代码比自然语言动作更稳定。
MultiAgent 不是一个新的底层循环,而是多个 Agent 怎么组织起来协作。常见的形态包括 Agent as Tool、Handoff、Leader & Workers、Agent2Agent。
一句话:
text
ReAct 管循环
PlanAct 管规划
CodeAct 管代码行动
MultiAgent 管协作但 Loop 只能说明 Agent 能跑。能跑之后,问题马上变成:谁来控制它?
3. Runtime / HITL:Agent 怎么被控制
好的 Agent 不只是能跑,还要能暂停、恢复、审查、被人接管。
这就是 Runtime 和 HITL 要解决的问题。
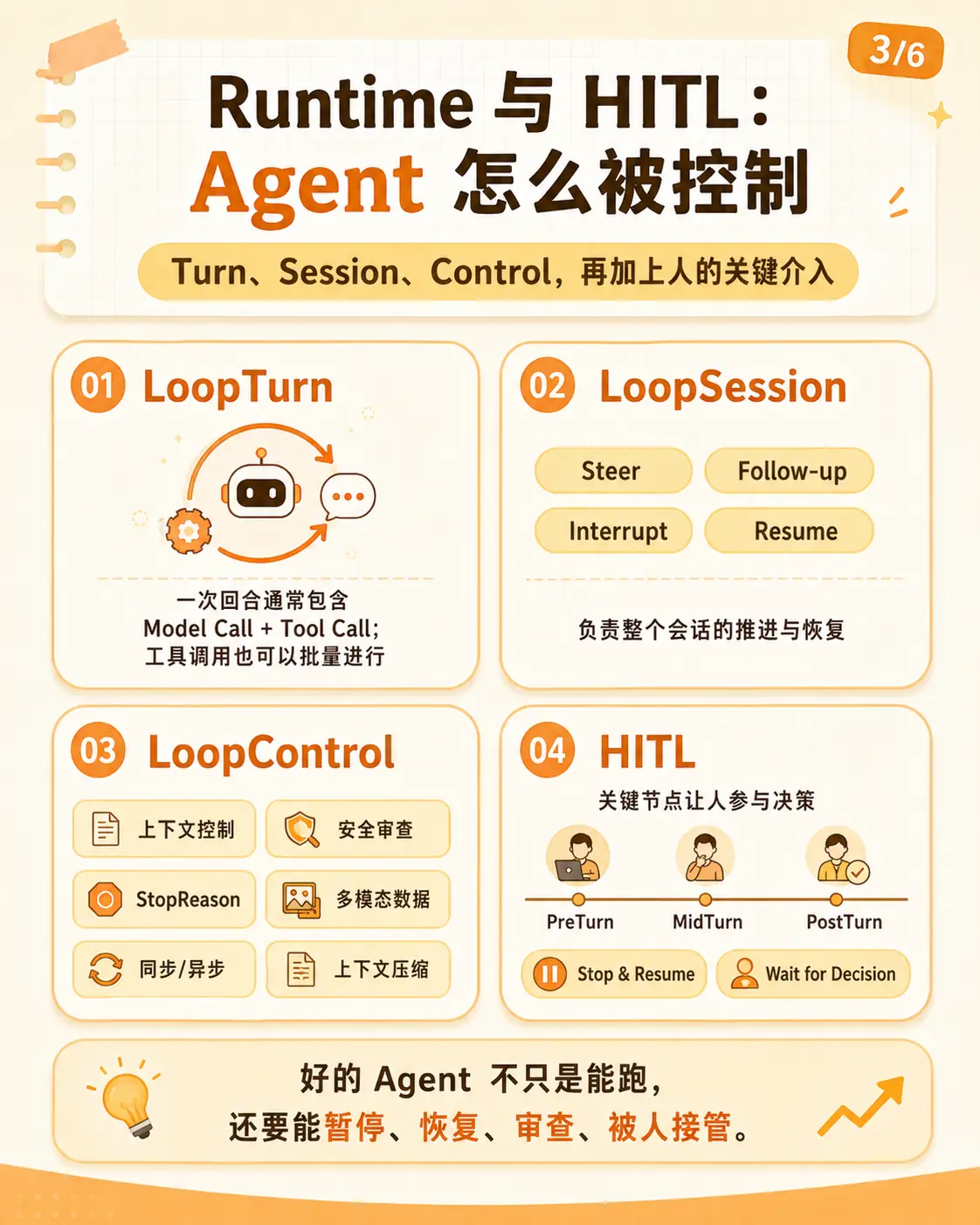
这里可以分三层看:
text
LoopTurn:一次执行回合
LoopSession:一次完整任务
LoopControl:控制循环怎么继续、暂停、恢复、结束LoopTurn 是一步。里面通常有模型调用、工具调用、观察结果,有时还会有批量工具调用。
LoopSession 是一整件事。用户交给 Agent 的不是"一次模型调用",而是一段会持续推进的任务。
LoopControl 管的是运行规则。比如上下文怎么压缩,危险命令要不要拦截,工具失败要不要重试,什么时候需要用户确认,什么时候应该停止。
HITL 也应该放在这里看。
不是所有事情都该让 Agent 自己决定。删文件、发邮件、提交代码、调用高成本模型、修改配置,这些节点都可能需要人介入。
所以我对 Runtime 的判断标准不是"它能不能调用模型",而是:
text
能不能停
能不能恢复
能不能审查
能不能让人接管
能不能知道自己为什么继续或停止这也引出下一张图:Goal。
4. Goal:没达标为什么不能停
Codex 的 /goal 可以看成一个很具体的例子。
它不是把"目标"写进 prompt 里就完事,而是把目标挂到 Session 上,让整个任务有一个持续存在的完成条件。
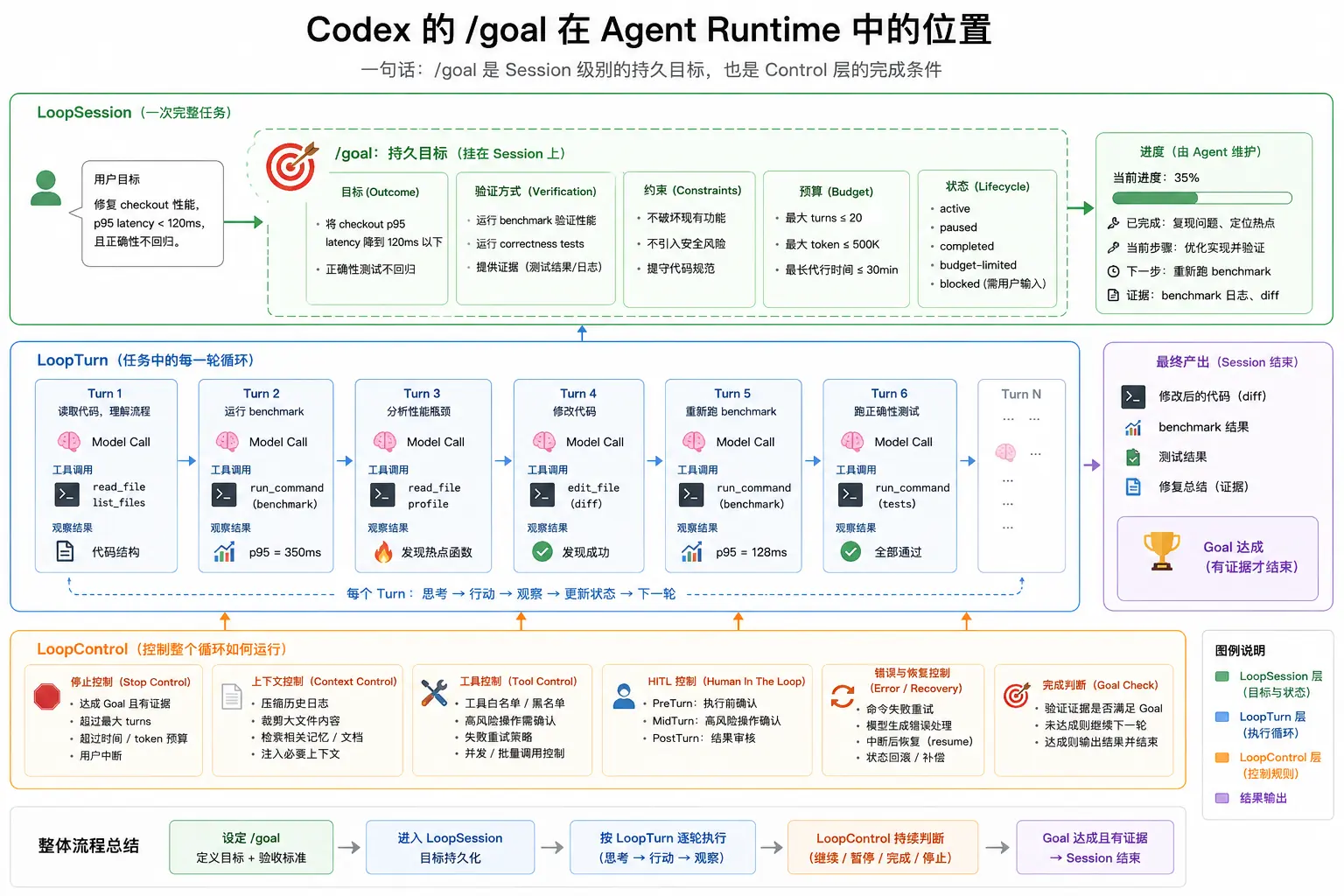
没有 Goal 时,Agent 很容易变成这样:
text
用户说一个任务
Agent 做几轮
Agent 觉得差不多了
输出总结
等待用户继续追问问题是,模型觉得差不多,不代表任务真的完成。
有 Goal 后,Session 上会多一层目标契约:
text
Outcome:要达到什么结果
Verification:用什么证据验证
Constraints:不能破坏什么约束
Budget:预算和运行边界是什么
Lifecycle:当前是 active、paused、blocked,还是 completed这件事听起来像产品功能,其实是 Agent Runtime 的核心问题。
长任务不能只靠模型自觉。它需要一个地方持续记录目标、进度、证据和状态。每一轮执行之后,都要回到这个目标上检查:继续、暂停、完成,还是停下来等人。
Ralph 和 Goal 的区别,也可以这样看:
text
Ralph:外部 LoopControl,有人在外面催它继续
Goal:内置 LoopSession + LoopControl,目标本身参与状态判断Goal 解决的是"没达标不能停"。但它还没有解决另一个问题:
下次遇到类似任务,Agent 能不能不要从零开始想?
这就到了 Skill。
5. Skill:经验怎么变成可复用能力
Skill 这张图里,我最想强调的是中间那句话:
Skill = Experience 的编码。
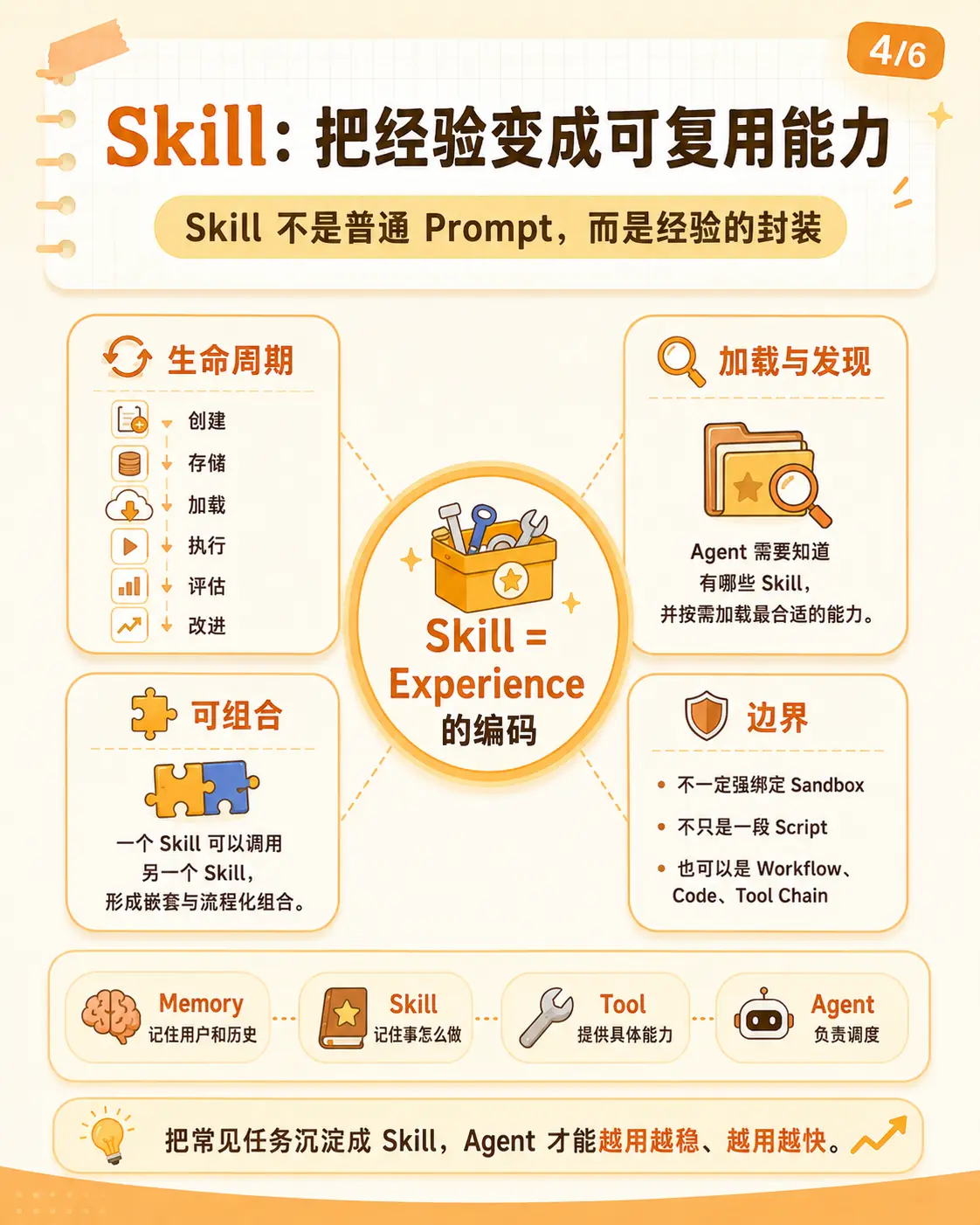
如果每次任务都让 Agent 从零推理,它很难变得稳定。
比如这些任务:
text
阅读 PDF 并生成总结
写小红书读书笔记
分析一个项目为什么跑不起来
修复一个测试失败
生成一份竞品调研
把一篇文章改成博客风格这些事都有套路。
先收集什么信息,怎么判断重点,什么时候调用工具,输出格式是什么,失败时怎么重试,最后怎么验收。把这些经验每次都写进 prompt,是一次性经验。沉淀成 Skill,才开始能复用。
这里有个区分要先说清:
text
Memory 记住"用户是谁"和历史偏好
Tool 提供"能做什么"
Skill 记住"事情怎么做"
Agent 负责"什么时候用什么能力"Tool 是手。
Skill 是手艺。
但 Skill 麻烦的地方,不是写一个 SKILL.md。麻烦在后面:
text
Agent 怎么发现有哪些 Skill?
怎么判断哪个 Skill 适合当前任务?
Skill 太长时怎么加载?
Skill 之间能不能组合?
私有 Skill 怎么分享?
不同 runtime 怎么复用同一套 Skill?这也是我做 skill-deck 的原因。
我手上已经有不少本地 Skill,但它们有几个现实问题:
text
散落在不同目录里
不同 Agent Runtime 的接入方式不一样
模型不一定知道什么时候该找 Skill
私有 Skill 想分享,又不能直接把本地路径和敏感信息发出去skill-deck 不是想重新定义 Skill。它更像一个适配层,把本机的 SKILL.md 变成模型看得见、用得上、也分享得出去的能力牌组。
它解决三个问题。
第一个是接入。
OpenAI Agents SDK、Claude Code、Cursor、自研 runtime,都可能想复用同一批 Skill。如果每个平台都手写 schema、handler、stable id 和加载逻辑,维护成本会很快上来。skill-deck 会扫描、解析和校验 SKILL.md,再生成 provider-neutral tools 和 runtime handlers,让同一套 Skill 可以接到不同环境里。
第二个是发现。
只暴露 list_skills 和 read_skill 还不够。模型在复杂任务里不一定会主动想起"我应该先查一下本地 Skill"。所以 skill-deck 做了 Skill Activation,把 Skill 通过 MCP tools/resources 暴露出来,并提供 compact、guided、active 三种模式。Skill 很多时可以保持工具列表短;想提高自动发现概率时,也可以让常用 Skill 直接出现在 tools/list 里。
第三个是分享。
很多 Skill 是私人工作流,里面可能有本地路径、私有 URL,甚至不该外发的上下文。直接把目录发给别人不合适,只截图又没法搜索、下钻和复用。skill-deck 的 Share 能让 agent 生成静态分享页和两张图,默认做脱敏,适合发给同事、同行,或者拿去社交平台展示。
所以 Skill System 最后看的不是"我有几个 prompt 文件",而是这些经验能不能被发现、被加载、被执行、被评测,最后还能被安全地分享出去。
6. Framework:别只看 API,要看执行过程
很多时候我们看 Agent Framework,容易只看三件事:
text
怎么调用模型
怎么定义工具
怎么写一个 Agent这些当然要看。但到了产品里,更麻烦的是执行过程。
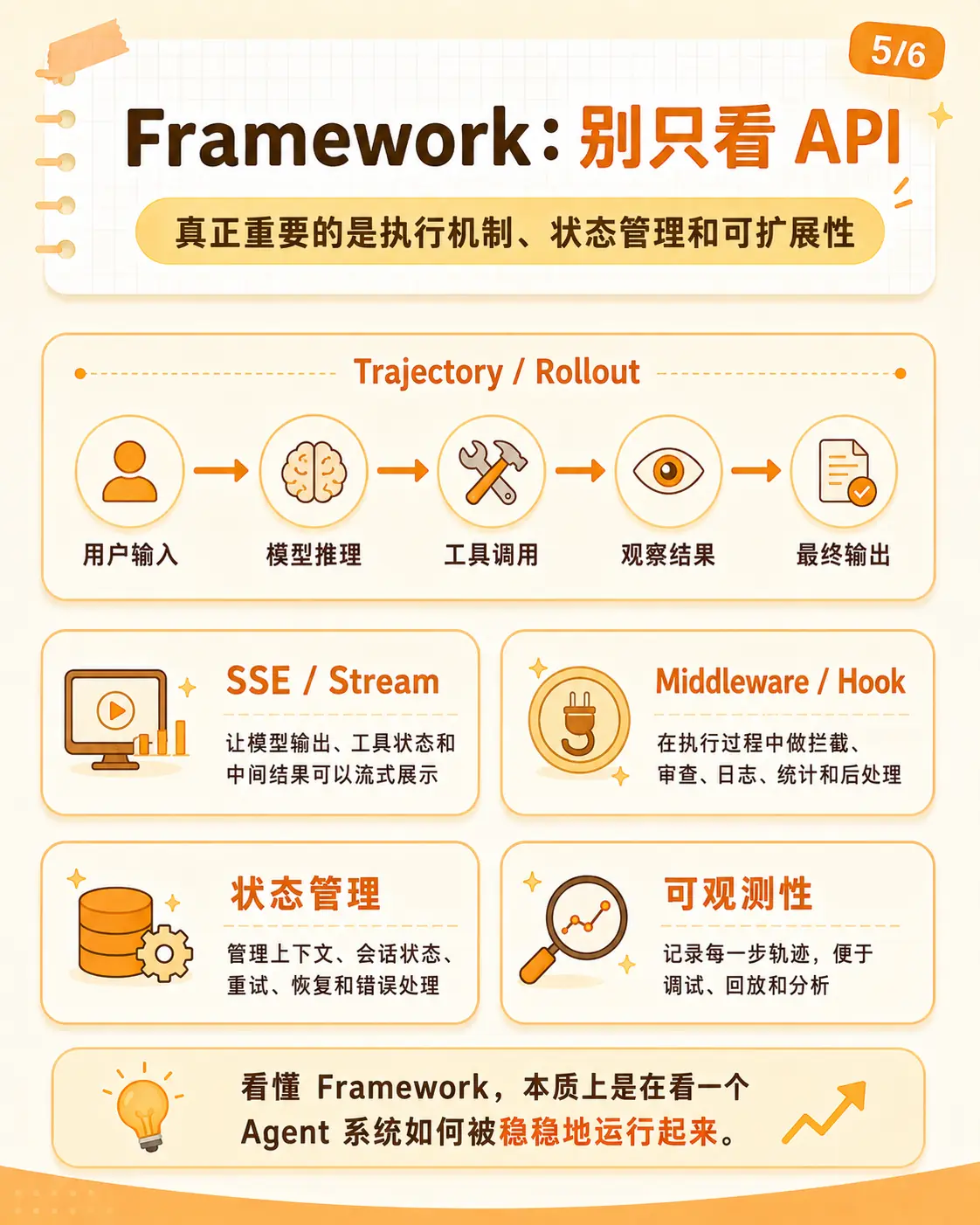
一个 Agent 在执行任务时,会不断产生事件:
text
模型开始输出
模型决定调用工具
工具开始执行
工具执行完成
文件被修改
命令开始运行
测试失败
Agent 准备重试
Agent 需要用户确认
Agent 暂停或恢复如果这些过程都不可见,用户看到的就是一个黑盒。
黑盒的问题是,出错时不知道错在哪,变慢时不知道慢在哪,成本变高时也不知道该改 prompt、tool、skill,还是换模型。
所以 Framework 的价值,不只是封装一次模型调用,而是承载整个执行过程。
我会重点看四个东西:
text
Stream:过程能不能流出来
Trajectory:轨迹能不能记录下来
Hook / Middleware:关键节点能不能拦截
State:长任务状态能不能保存和恢复Stream 解决的是"用户能不能看见它在干什么"。没有 Stream,前端只能显示 loading;有了 Stream,用户至少知道 Agent 卡在读取文件、跑测试,还是等待确认。
Trajectory 解决的是"事后能不能复盘"。一次任务里发生过什么,模型为什么调用这个工具,失败后怎么重试,最后证据是什么,都要留下来。
Hook / Middleware 解决的是"控制逻辑放在哪里"。权限检查、删除确认、预算判断、格式校验、失败重试,不应该全靠 prompt 里的自觉。
State 解决的是"长任务能不能活过中断"。用户打断、上下文变长、工具失败、预算耗尽、明天继续,这些都要求 runtime 知道当前任务走到哪了。
看懂 Framework,其实是在看一个 Agent 系统怎么稳定运行起来。
7. Eval:效果怎么评估和迭代
最后是 Eval。
Agent 最大的问题是,它看起来很努力,但不一定真的完成任务。

所以 Agent Eval 不能只看回答是否流畅、格式是否好看。Agent 是来完成任务的,更应该看这些东西:
text
任务有没有完成
工具有没有用对
成本有没有失控
响应有没有变慢
过程有没有安全风险
失败后能不能恢复
多次执行是否稳定
用户是否真的接受结果代码修复类任务,就看测试是否通过、diff 是否合理、有没有引入新问题。
资料处理类任务,就看文件是否读对、信息是否完整、输出是否符合使用场景。
写作类任务,就看是否贴近用户口吻、重点是否对、用户是否还要反复改。
这里还要区分 Offline Eval 和 Online Eval。
Offline Eval 是上线前评测。准备一批固定任务,每次改模型、改 prompt、改 skill、改框架,都重新跑一遍,看成功率、成本、耗时、失败类型有没有变化。它的好处是可重复。
Online Eval 是上线后评测。它看真实用户是否采纳结果,是否频繁追问修改,是否中途取消,是否触发人工介入,最后任务有没有真的完成。它更脏,但更接近现实。
Skill 也应该被 Eval 驱动。
一个 Skill 写完之后,不应该只问"写得漂不漂亮",而要问:
text
用了它以后,成功率有没有提升?
平均成本有没有下降?
用户修改次数有没有减少?
任务完成时间有没有缩短?
失败模式有没有变少?
有没有引入新的风险?否则 Skill 只是看起来更专业的 prompt。
有用的 Skill,会在失败案例里一轮一轮改出来。
结尾
上一篇讲的是:
Agent 怎么持续把长任务跑完?
这篇想补的是:
Agent 跑起来之后,怎么变成一个可复用、可观测、可评测的系统?
现在我会这样收束:
text
Loop 解决执行
Runtime / HITL 解决控制
Goal 解决完成判断
Skill 解决经验复用
Framework 解决过程承载
Eval 解决持续迭代只做 Loop,Agent 只是能跑。
加上 Goal,它才不容易假装完成。
加上 Skill,它才开始留下经验。
加上 Framework,它才像一个能被用户信任的系统。
加上 Eval,我们才知道它到底有没有变好。
所以 Agentic Engineering 不只是"让 AI 多干几轮"。更准确地说,是把任务、经验、过程和评测都留下来,让下一次执行比这一次更稳一点。