工具执行完了,麻烦才刚开始
工具调用成功了,返回了结果。
但这个结果现在要进入上下文。从这一刻起,它会占据上下文里的一块空间,在后续所有推理里被模型"看到"------直到这个 Session 结束,或者被 Compaction 压缩掉。
如果返回值设计得不好,它会持续地污染后续的推理:
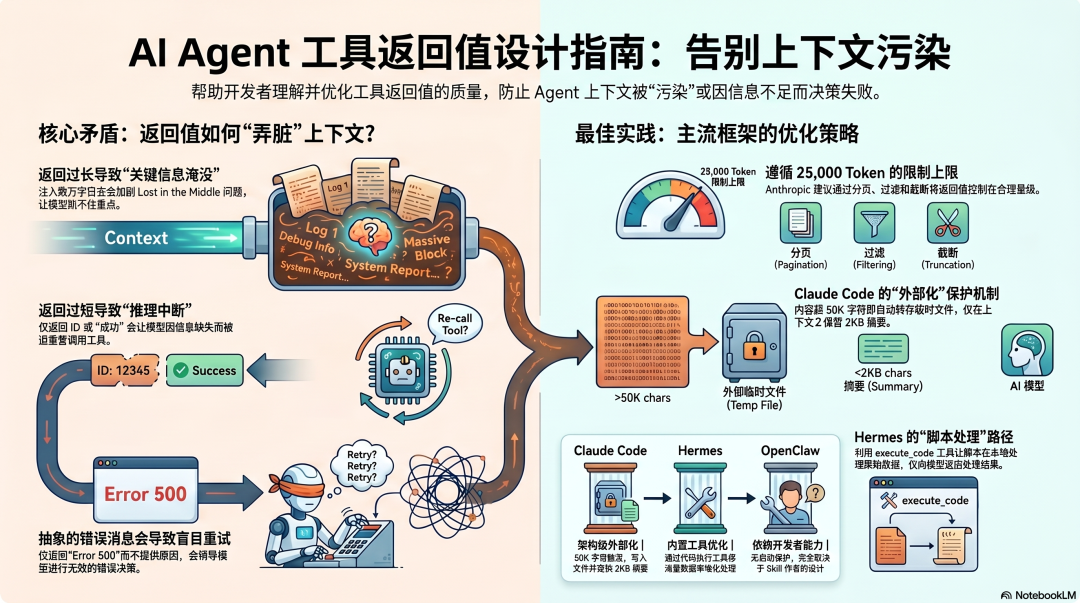
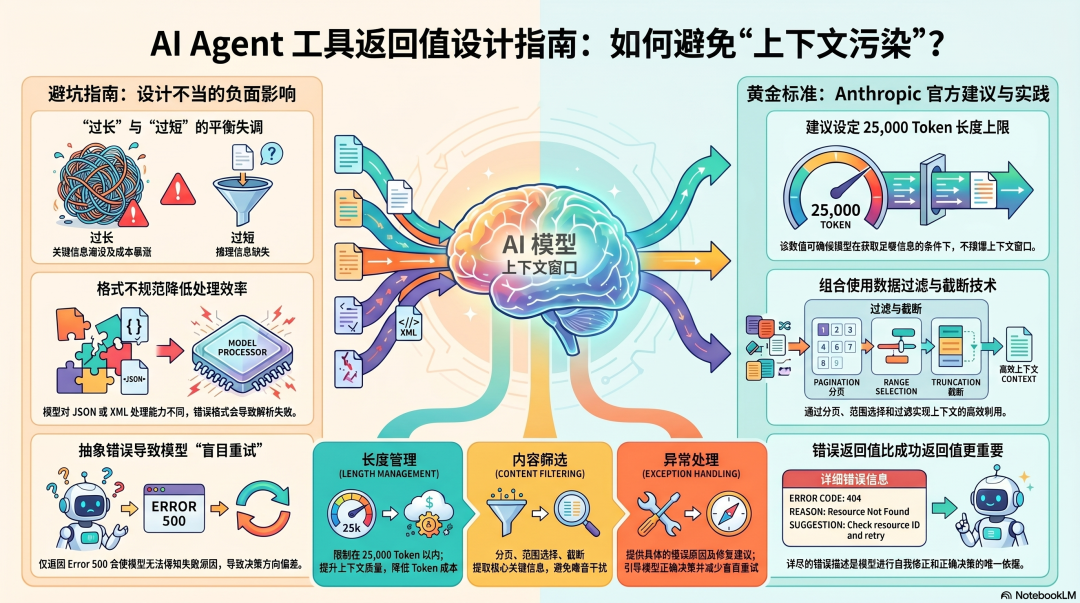
返回太长:5 万字的日志全量注入上下文,关键信息被淹没,Lost in the Middle 问题加剧,Token 成本暴涨,后续每次调用都带着这 5 万字作为"包袱"。
返回太短:只返回"成功"或者一个 ID,模型不知道接下来该怎么做,下一步推理质量下降,甚至会再次调用工具来获取本来应该一起返回的信息。
返回格式不对:模型对 JSON、XML、Markdown 的处理能力不同。格式不对,模型理解效率低,也可能产生解析错误。
错误消息太抽象:工具失败了,只返回"Error 500",模型不知道原因,不知道怎么修,可能会盲目重试或者换一个错误的方向继续。
返回值设计,是工具设计里最容易被忽视、但影响最持久的部分。
Anthropic 的官方建议:25,000 Token 上限
Anthropic 在工具设计指南里给出了明确的数字:
Claude Code 默认把工具返回值限制在 25,000 Token 以内。
这不是随意设定的数字。Anthropic 的理由是:
"优化上下文质量很重要,但优化工具返回给 Agent 的上下文数量同样重要。我们建议对任何可能消耗大量上下文的工具返回值,实现分页、范围选择、过滤、截断的某种组合,并设置合理的默认参数。"
25,000 Token 大约是 2 万字------够模型做出合理判断的信息量,但不会撑爆上下文。
重要的是:这个限制预计会随着上下文窗口的增大而调整,但"需要上下文高效的工具"这个需求不会消失。 上下文窗口扩大,不是"可以随便返回大量数据"的理由,而是"可以处理更复杂任务"的能力扩展。
错误返回值:比成功返回值更重要
工具失败了,返回的错误消息是模型决策的唯一依据。
一个真实的案例:Anthropic 发布 Claude 的网页搜索工具时,发现模型会在搜索查询里无缘无故加上"2025",导致搜索结果出现年份偏差。修复方法不是改模型,而是改工具描述------在描述里明确说明"不要在查询里添加年份约束,除非用户明确要求"。
这说明工具的返回值和描述,会系统性地塑造模型的行为。 一个工具的设计问题,会在每次调用这个工具的任务里反复出现。
三个框架对返回值设计的不同态度
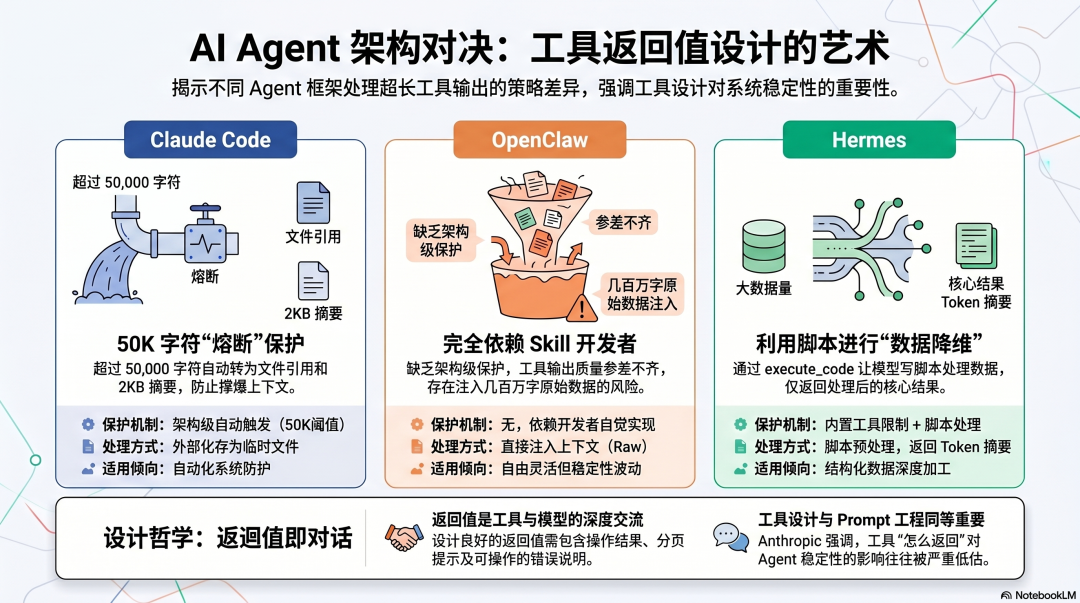
Claude Code:50K 外部化是架构级保护
Claude Code 对超长返回值有一个框架级别的保护机制:
当工具调用返回内容超过 50,000 字符,自动触发外部化------完整内容写入临时文件,上下文里只注入约 2KB 的摘要和文件引用。模型需要更多细节时,通过文件读取工具按需获取。
工具返回 100,000 字符的日志 ↓超过 50,000 字符阈值 ↓完整内容写入 /tmp/tool_output_xxx.txt ↓上下文注入:"工具返回了大量输出,已保存到 tool_output_xxx.txt。摘要:发现 127 条 ERROR 级别日志,主要集中在 14:30-15:00。如需查看完整输出,使用 read_file 工具读取文件。"这个机制保护了主上下文不被单次工具调用撑爆,同时给了模型继续工作的信息(摘要)和获取更多信息的路径(文件引用)。
OpenClaw:无架构级保护,依赖 Skill 作者
OpenClaw 没有类似 Claude Code 的 50K 外部化机制。
工具返回什么、返回多少,完全由 Skill 作者决定。如果 Skill 作者没有实现分页和截断,工具可能返回几十万字的原始内容,全部注入上下文,没有任何自动保护。
ClawHub 上工具返回值设计的质量参差不齐。有质量好的 Skill,会在工具描述里明确说明返回值大小限制和分页参数;也有质量差的 Skill,直接暴露底层 API 的原始输出,没有任何裁剪。
Hermes:内置工具设计合理,execute_code 是特殊路径
Hermes 的 40+ 内置工具,大多数遵循了合理的返回值设计:有限制最大返回量、支持分页参数、错误消息有基本的可读性。
Hermes 最有特色的是 execute_code 工具------模型可以写脚本来处理数据,脚本的输出作为工具返回值。
原始日志可能有 10 万行,但脚本只返回了几十个 Token 的摘要。 模型"看到"的是处理结果,不是原始数据。这本质上是把"数据处理"放在了工具里,而不是让模型来处理原始数据。
这也是 Hermes 处理长文档的推荐方式(第二十七篇讲过的):对于结构化数据,让 execute_code 处理,返回摘要;对于非结构化内容,才考虑直接读取。
返回值是工具和模型之间的对话
工具的返回值,不只是"给了模型一个结果"。它是工具在告诉模型:
"发生了什么"------操作的结果。
"还有什么可以做"------分页提示、相关工具建议。
"如果出错了,下一步怎么办"------可操作的错误说明。
设计得好的返回值,让模型每次读完都知道接下来该做什么。设计得差的返回值,让模型每次都要在大量噪音里找信号,或者因为信息不足而做出错误决策。
Anthropic 在指南里说的那句话,在返回值设计这里同样适用:
"工具设计和 prompt 工程一样,需要同等程度的投入。"
工具能调出什么,往往被高估。工具返回什么、怎么返回,往往被低估。但后者对 Agent 稳定性的影响,一点都不亚于前者。