1.通信的意义
如管道这种功能,有时候我们需要进行进程之间的通信。
原因:
(1)多进程之间要用进行数据传输。
(2)不同进程之间要共享资源
(3)进程之间要进行通知或彼此控制
通信操作的本质:让不同进程看到同一份资源。
由于进程之间具有独立性,因此这份资源要由OS提供,也就是内存。
2.匿名管道
一个进程将其的文件缓冲区的数据刷新给另一个进程
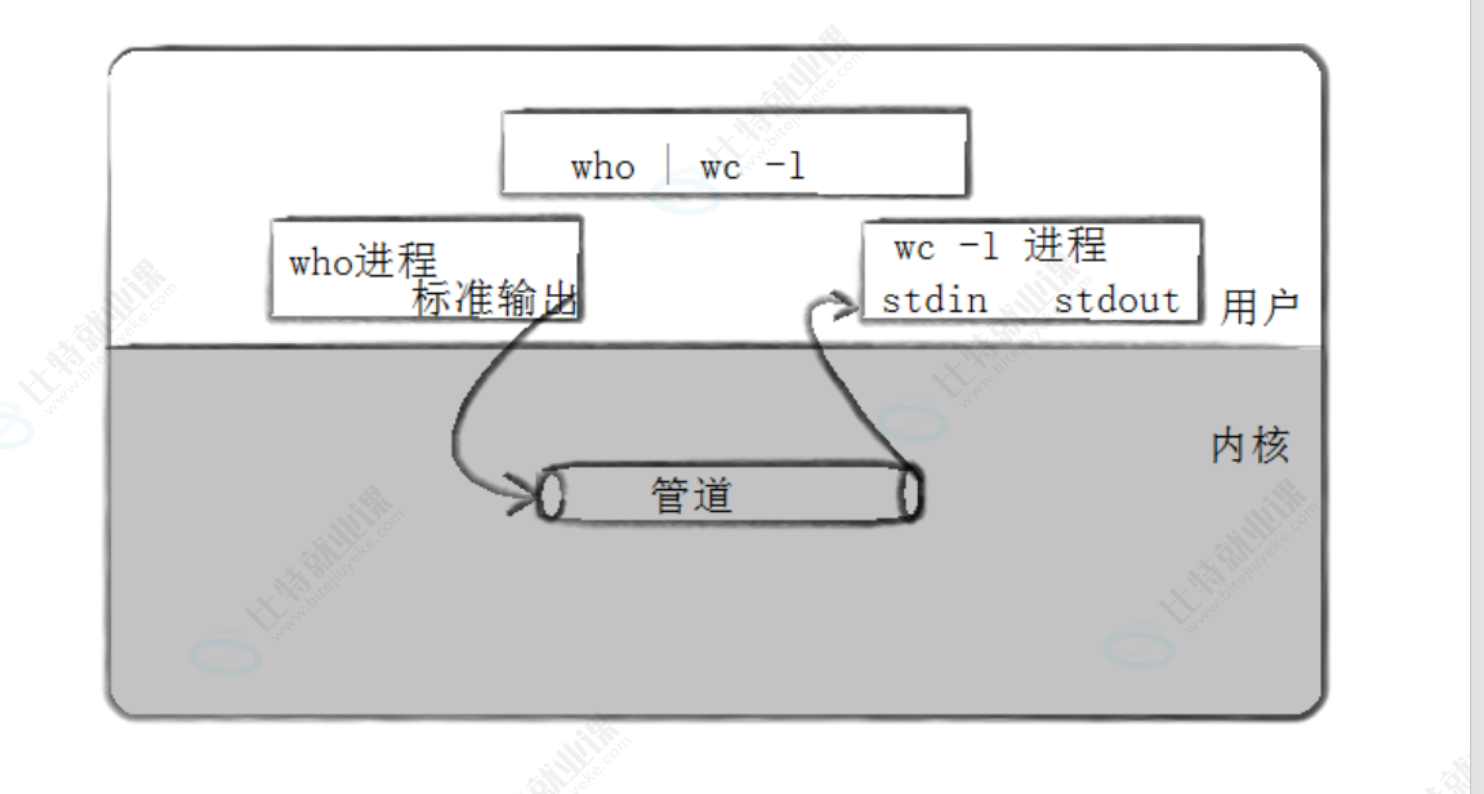
此处文件缓冲区就充当了管道的位置。
匿名管道只能用于有血缘关系的进程之间通信。
原理(与子父进程为例):父进程与子进程之间的数据拷贝时浅拷贝,也就是多个进程之间是共用同一个文件管理的数据的,因此父进程关闭,子进程也能继续运行的原因就在于文间管理的数据采用了引用计数的方式。
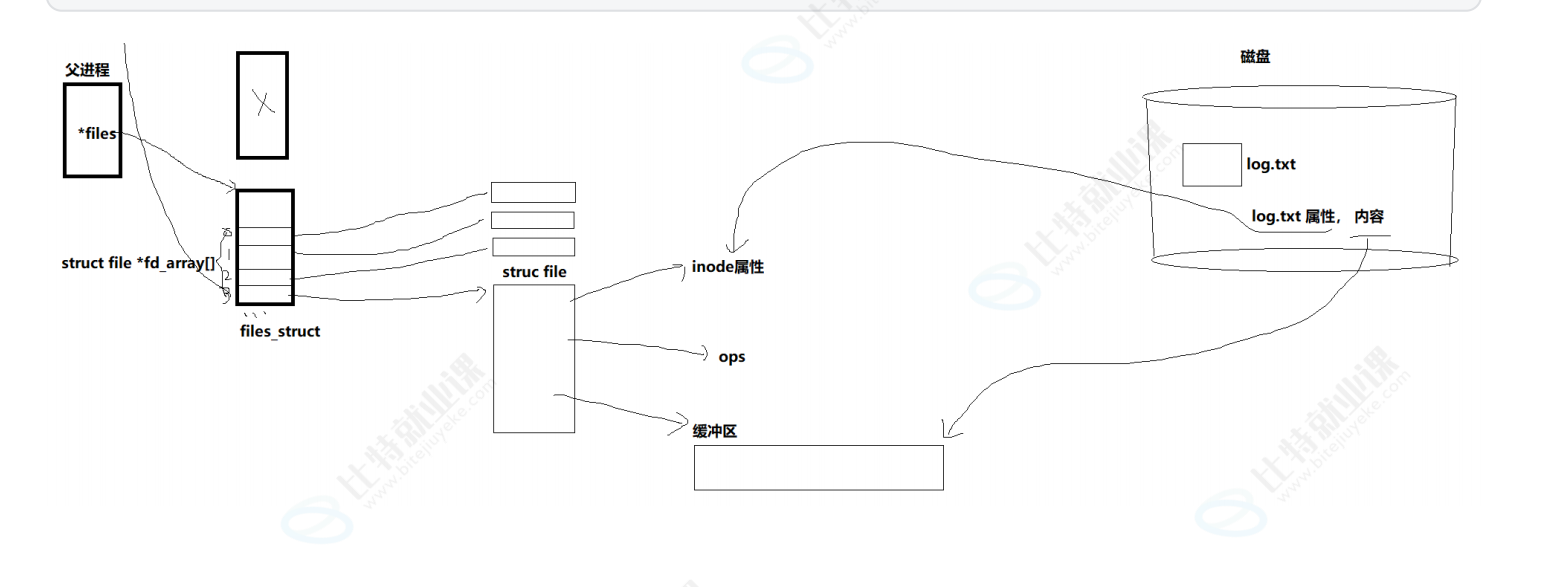
也就是父子进程的struct file都指向了同一个文件缓冲区。充当管道交流的文件缓冲区已经不具备刷新数据到磁盘的能力了,可以视为变成了内存级缓冲区了。
操作解释:
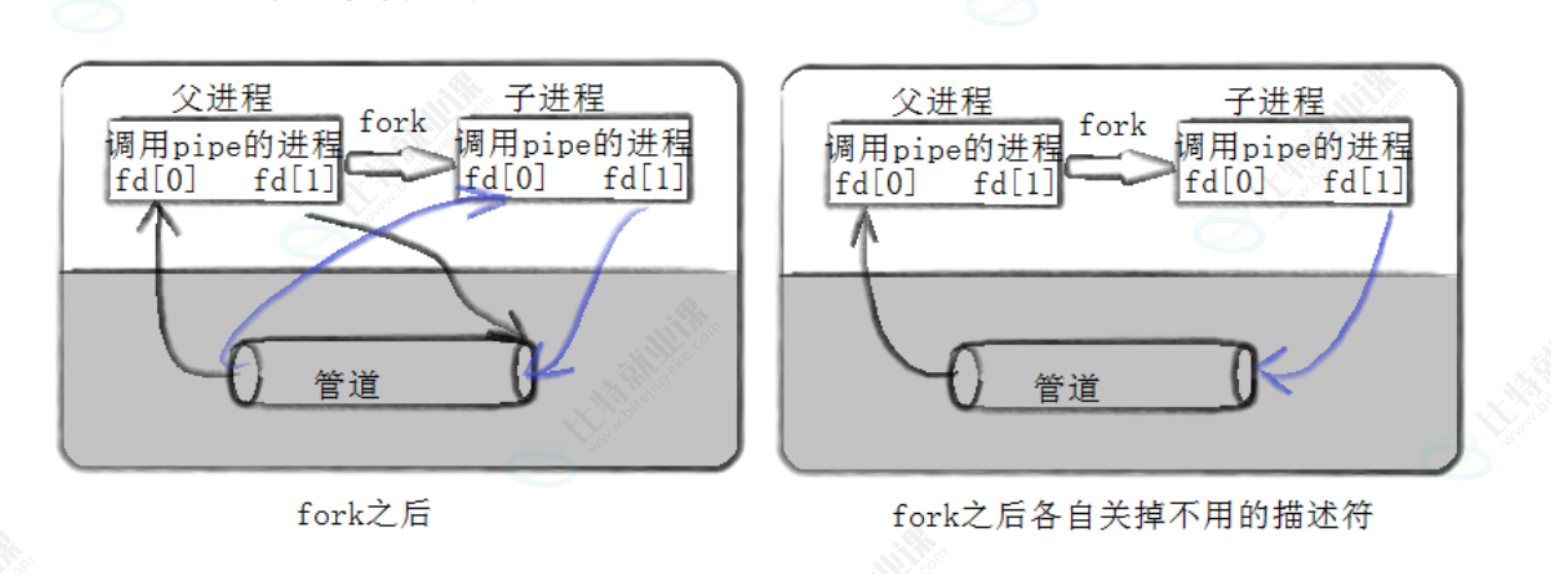
(1)有父进程生成管道,管道本身可被视为内存级文件,分别采用读写方式打开,占用两个fd.
(2)父进程fork出子进程,子进程就可以通过浅拷贝与父进程连接到同一个管道中
(3)这里的通信是单项通信,例父进程通过关闭fd0(默认是读),子进程通过关闭fd1(默认是写),从而保证是父进程的数据写入传输给子进程。
管道其实是由OS单独设计的,它遵循各种代码的功能设计,其作为OS级功能自然也有其自己单独的系统调用。
//pipefd是一个输出型参数,用于存储对应管道的两个fd,成功返回1,失败返回0.
int pipe(int pipefd[2]);可以发现这种管道不需要文件路径,也不需要文件名,但其却是一个用于通信文件,因此取名叫匿名管道。
文件系统的范围:存inode属性的结构体,各种底层硬件的调用接口和文件缓冲区。
也就是说struct file本身并不属于文件系统的一部分,具体体现在父子进程有各自独立的struct file。
管道由文件系统管理,也就是管道其实就是一种特殊的文件。
3.管道的特性
1.匿名管道只能用于有血缘关系的进程之间。
2.多个进程同时往同一块内存空间写入其实是可以的,但管道文件的通信中使用了read接口使其自带阻塞机制,也就是自带同步机制使读方不能在写方操作时读取该内存数据。
3.管道是面向字节流的,也就是OS知道写时数据的格式,但读时是不知道的,因此最终会导致读取数据时和我们预期(与写时的数据相同)情况不符。
4.管道在定义上讲是单向通信的。
在任意一个时候,一个发,一个收,叫半双工。
在任意一个时候,可以同时收发,叫全双工。
也就是一个人听,一个人说叫半双工,两个人吵架叫全双工。
管道属于半双工的一种特殊情况,管道是固定一端处然后的收发,而半双工是不固定的。
5.管道文件的生命周期是随进程的
4.四种通信情况
1.写慢,读快,读端进程就会阻塞来等写端
2.写快,读慢,如果知道管道文件写满了读端也没有读,写端就会阻塞来等读端
3.写端直接关闭但读端还开着,read会直接返回0,也就是视为读到文件结尾了
4.读端直接关闭但写端还开着,此时的写端写入是无意义的,OS不允许所有无意义的事情发生,因此OS会直接发送异常信号13(SIGPIPE)杀死写端进程
ubuntu下的管道文件大小是64KB。
原子性的解释(1):只关心结果,不关心过程。
写入使得数据小于PIPE_BUF(4KB)时,写的方式遵循原子性
例:写端写入很多个"hello world"但总大小没有大于4KB,那么即使这个写端可能还在写着,但他之前写的"hello world"可能已经被读了。
5.进程池的代码实现
其实我们应该将先描述在组织细化为,描述,创建,组织三步走。
下面的代码注重于有用户自己生成所要用的函数功能,父进程负责发送任务码给子进程然后由子进程运行函数功能。
1.pipe.hpp
cpp
#include<iostream>
#include<string>
#include<vector>
#include<cstdlib>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<functional>
#include<ctime>
using namespace std;
//描述一个管道
class channel
{
public:
channel(int wfd,int pid)
:_wfd(wfd)
,_pid(pid)
{}
//让父进程给子进程输入操作指令
void _send(int cmd)
{
write(_wfd,&cmd,sizeof(cmd));
}
//关闭写端就能顺便让子进程关闭了
void _close()
{
close(_wfd);
}
pid_t _getpid()
{
return _pid;
}
int _getwfd()
{
return _wfd;
}
private:
//管道的写端
int _wfd;
//子进程的pid
int _pid;
};
using task_t = function<void()>;
class ProcessPool
{
public:
ProcessPool(int n,vector<task_t> tasks)
:_processnum(n)
,_tasks(tasks)
{}
void Run(int cmd)
{
_tasks[cmd]();
}
void Work(int rfd)
{
//一直读,直到写端关闭
while(1)
{
int cmd = 0;
int n = read(rfd,&cmd,sizeof(cmd));
if(n == sizeof(cmd))
{
Run(cmd);
}
else if(n == 0)break;
}
}
//创建进程池同时用数据结构管理
bool IntProcess()
{
for(int i = 0;i < _processnum;i++)
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0)return false;
pid_t id = fork();
//子进程操作
if(id == 0)
{
//先关闭之前父进程的所有写端
for(auto& ch:_channels)
{
close(ch._getwfd());
}
close(pipefd[1]);
Work(pipefd[0]);
exit(0);
}
//父进程操作
close(pipefd[0]);
_channels.emplace_back(pipefd[1],id);
}
return true;
}
int SelectTask()
{
return rand()%_tasks.size();
}
void SendMisson(int count)
{
//分发给哪个子进程
int who = 0;
//分发多少次
int num = count;
while(num--)
{
//任务对应的任务码
int task = SelectTask();
channel& cur = _channels[who++];
who %= _channels.size();
cur._send(task);
}
}
void CleanProcessPool()
{
for(auto& e:_channels)
{
e._close();
pid_t id = waitpid(e._getpid(),NULL,0);
}
}
private:
vector<channel> _channels;
int _processnum;
vector<task_t> _tasks;
};2.main.cpp
cpp
#include"pipe.hpp"
vector<task_t> __tasks;
int main()
{
srand(time(nullptr));
__tasks.push_back([](){cout << "fuck " << getpid() << endl;});
__tasks.push_back([](){cout << "love " << getpid() << endl;});
__tasks.push_back([](){cout << "shit " << getpid() << endl;});
__tasks.push_back([](){cout << "shock " << getpid() << endl;});
ProcessPool* test = new ProcessPool(5,__tasks);
test->IntProcess();
test->SendMisson(10);
test->CleanProcessPool();
delete test;
return 0;
}