企业 AI 有一条隐形的门槛,很少被人明说:
功能能跑,和企业真的敢用,是两件事。
这两天翻提交记录,没有一个单独的功能让人觉得特别亮眼。但整体看完,这是近几周最扎实的一次迭代------因为团队一直在补这两件事之间的距离。
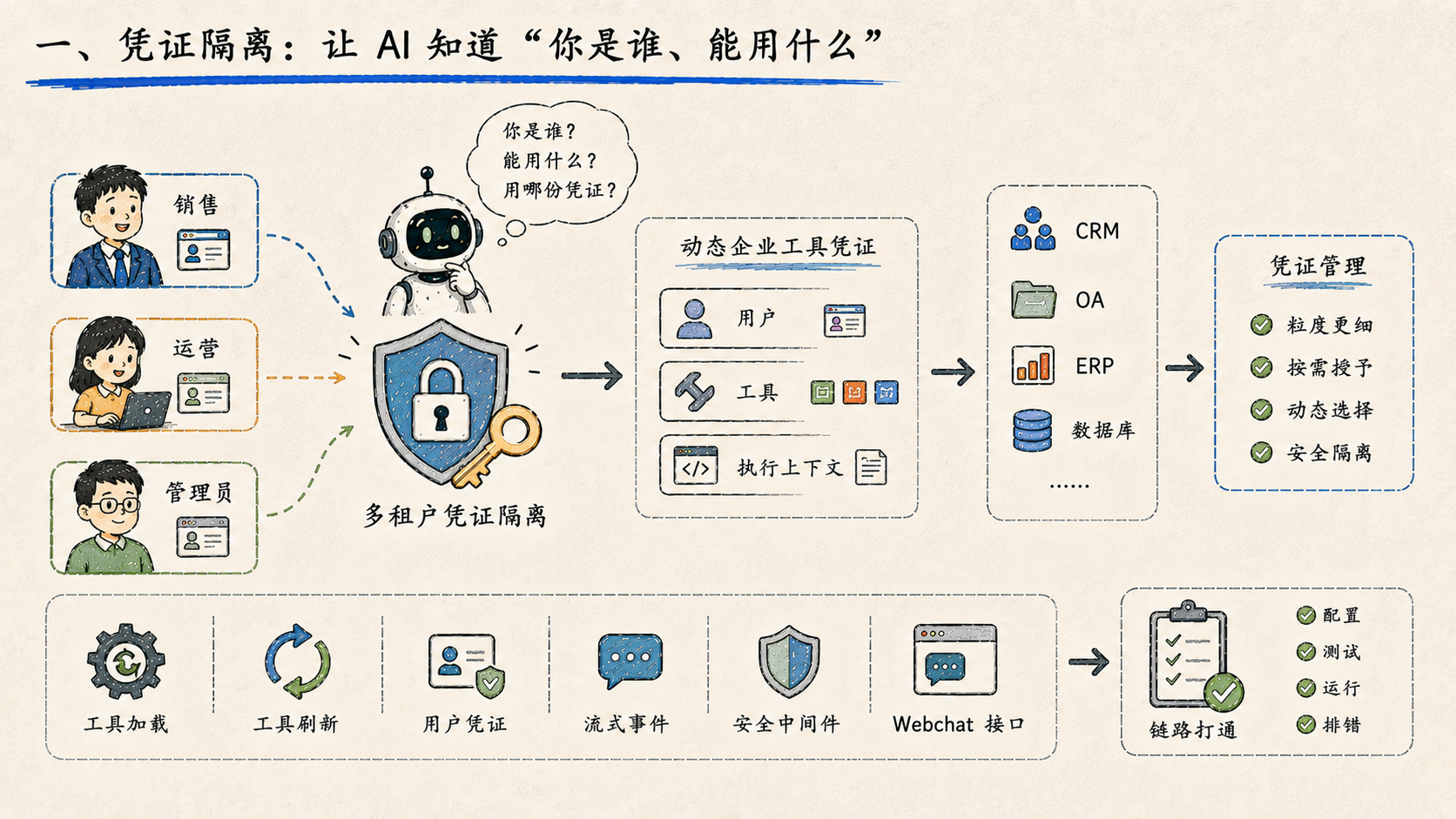
一、凭证隔离:让 AI 知道"你是谁、能用什么"
平台新增了动态企业工具凭证能力。
听起来很工程,但它解决的是一个非常现实的问题:企业不是个人玩具场景。一个销售、一个运营、一个管理员,他们能用的系统、能看到的数据、能调用的工具,天然就不该一样。AI 如果要真正进入业务系统,就必须知道"你是谁""你能用什么""这次调用该用哪份凭证"。
以前的做法是全局写死一套配置。现在改成了围绕用户、工具和执行上下文做细颗粒度的凭证管理。对应的改动覆盖了工具加载、工具刷新、用户凭证、流式事件、安全中间件以及 Webchat 侧的接口。企业接管和企业发现能力这一轮也做了修复和增强------配置、测试、运行、排错这一整条链路,正在慢慢打通。
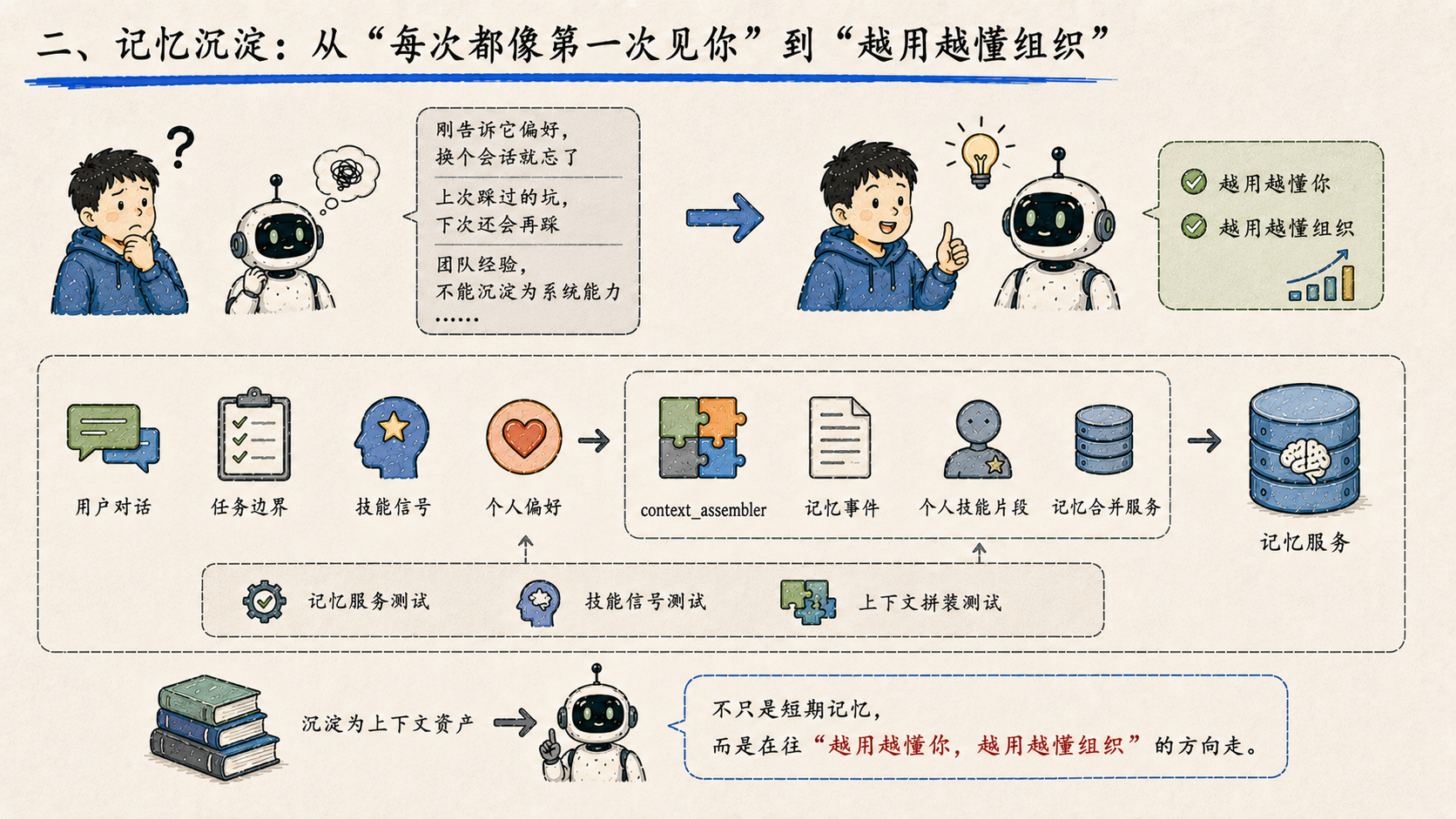
二、记忆沉淀:从"每次都像第一次见你"到"越用越懂组织"
很多 AI 产品的问题不是它不会回答,而是它每次都像第一次见用户。刚告诉它一个偏好,换个会话它就忘了;上次踩过的坑,下次它还会再带人踩一遍;团队里沉淀出来的经验,它不能变成系统的一部分。
这次新增了 context_assembler、记忆事件、个人技能片段和记忆合并服务,同时补上了围绕记忆服务、技能信号、上下文拼装的测试。平台开始把用户对话、任务边界、技能信号、个人偏好这些信息,变成可以被后续 Agent 调用的上下文资产。不只是短期记忆,而是在往**"越用越懂你,越用越懂组织"**的方向走。
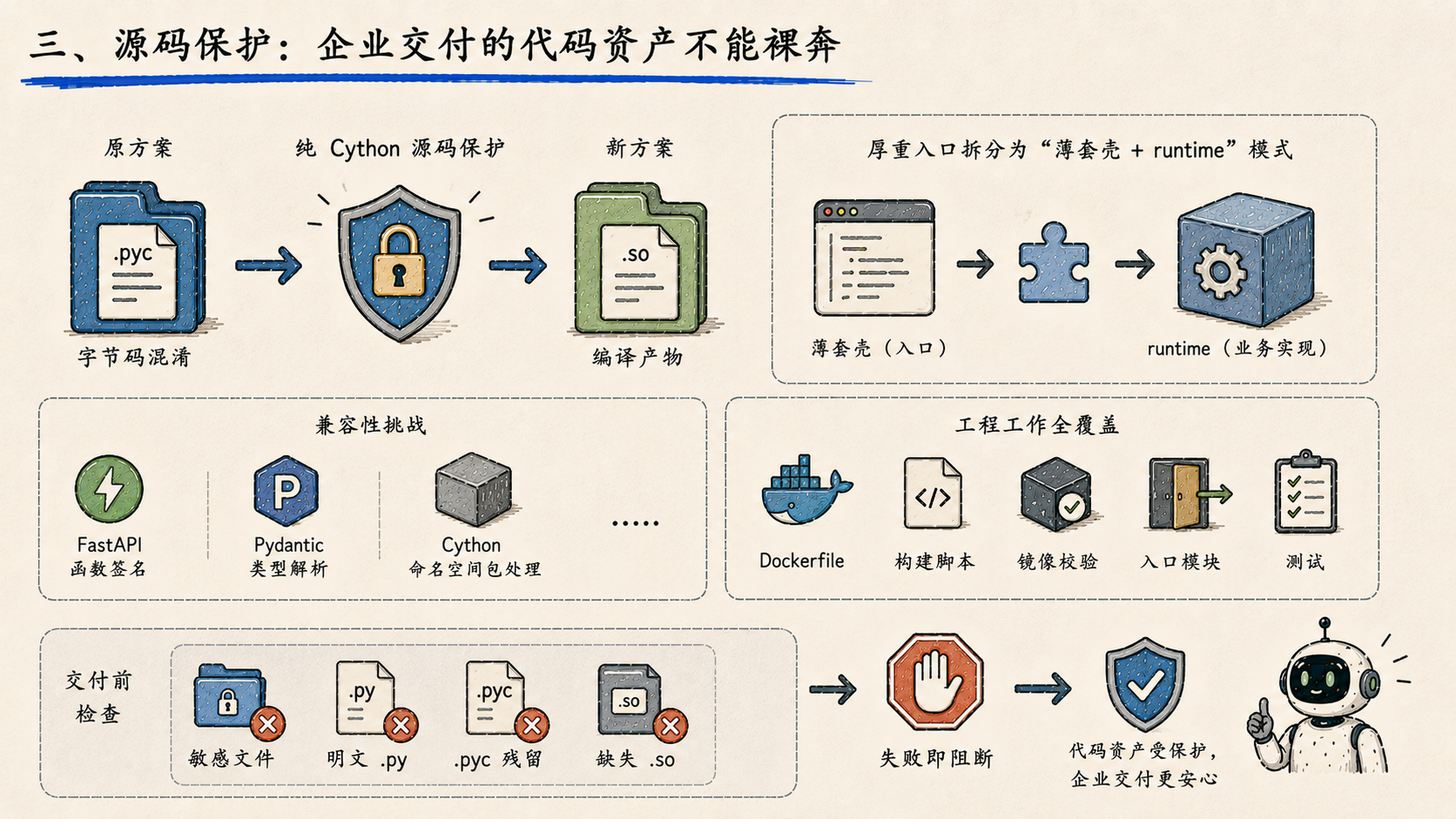
三、源码保护:企业交付的代码资产不能裸奔
引入了纯 Cython 源码保护方案,把 15 个核心业务模块编译成 .so 文件,替代原来的字节码混淆方案。同时把厚重的业务入口拆成"薄套壳 + runtime"的模式,让真正的业务实现进入编译产物。
这块的工程含金量比看起来要高。源码保护不是简单地"把代码藏起来"就完了------FastAPI 的函数签名、Pydantic 的类型解析、Cython 对命名空间包的处理,每一处都有兼容性问题要踩。这次 Dockerfile、构建脚本、镜像校验、入口模块、测试全部一起补齐,镜像构建也从提醒式校验升级成失败即阻断 ------敏感文件、明文 .py、.pyc 残留、缺失 .so,全部进入交付前检查。
企业交付不是 demo,代码资产本身也需要被保护。这是平台开始认真面对这件事的信号。
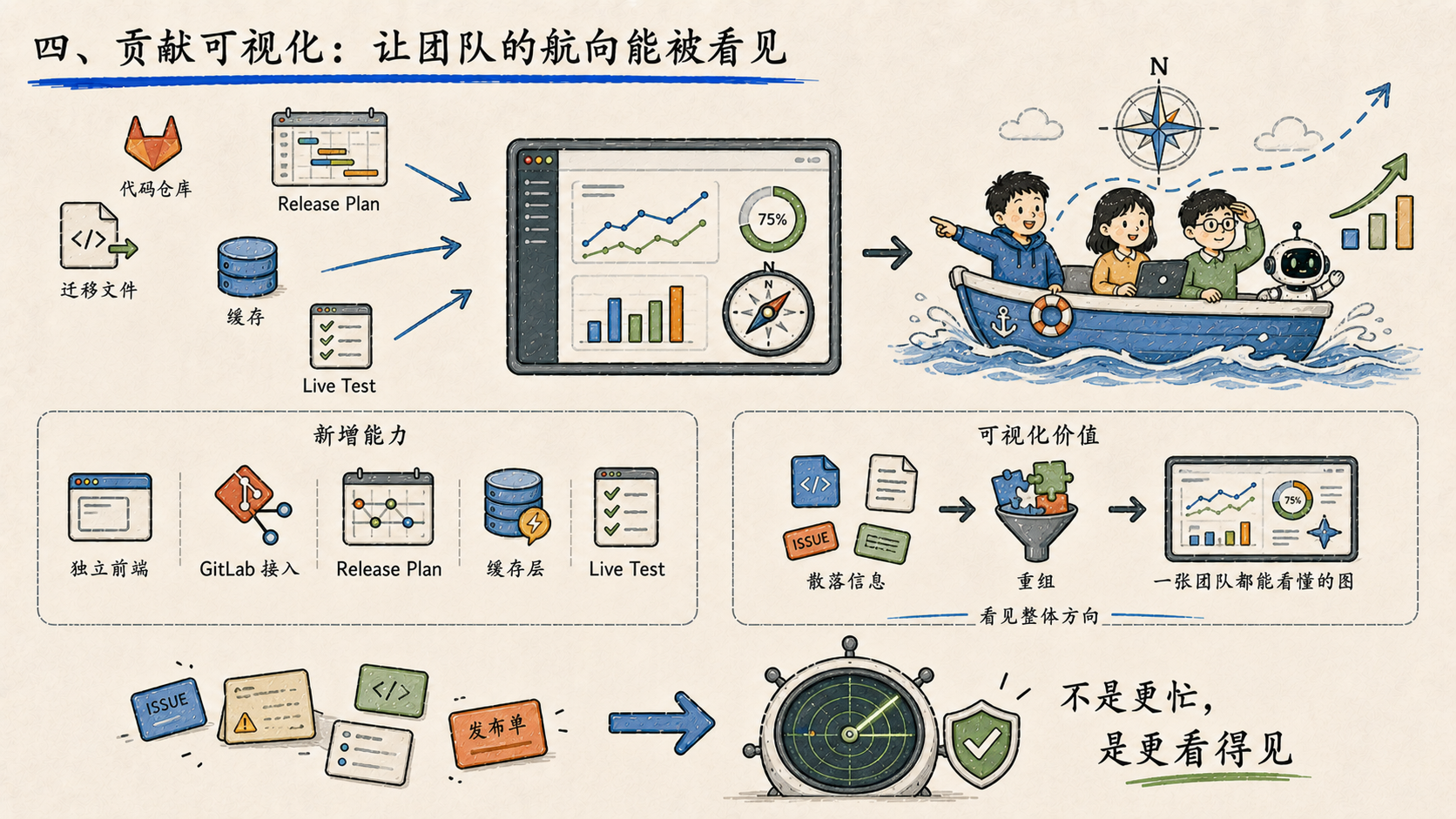
四、贡献可视化:让团队的航向能被看见
新增了一个贡献工作可视化 dashboard,包括独立前端、GitLab 数据接入、release plan 模型、缓存层和 live integration 测试。
这件事很像给团队装了一个仪表盘。工程团队一旦变大,最怕的不是没人干活,而是大家都在干活,但没人知道整体在往哪里走。可视化的价值是把散落在 GitLab、迁移文件、发布计划里的信息,重新组织成一张能被团队理解的图。
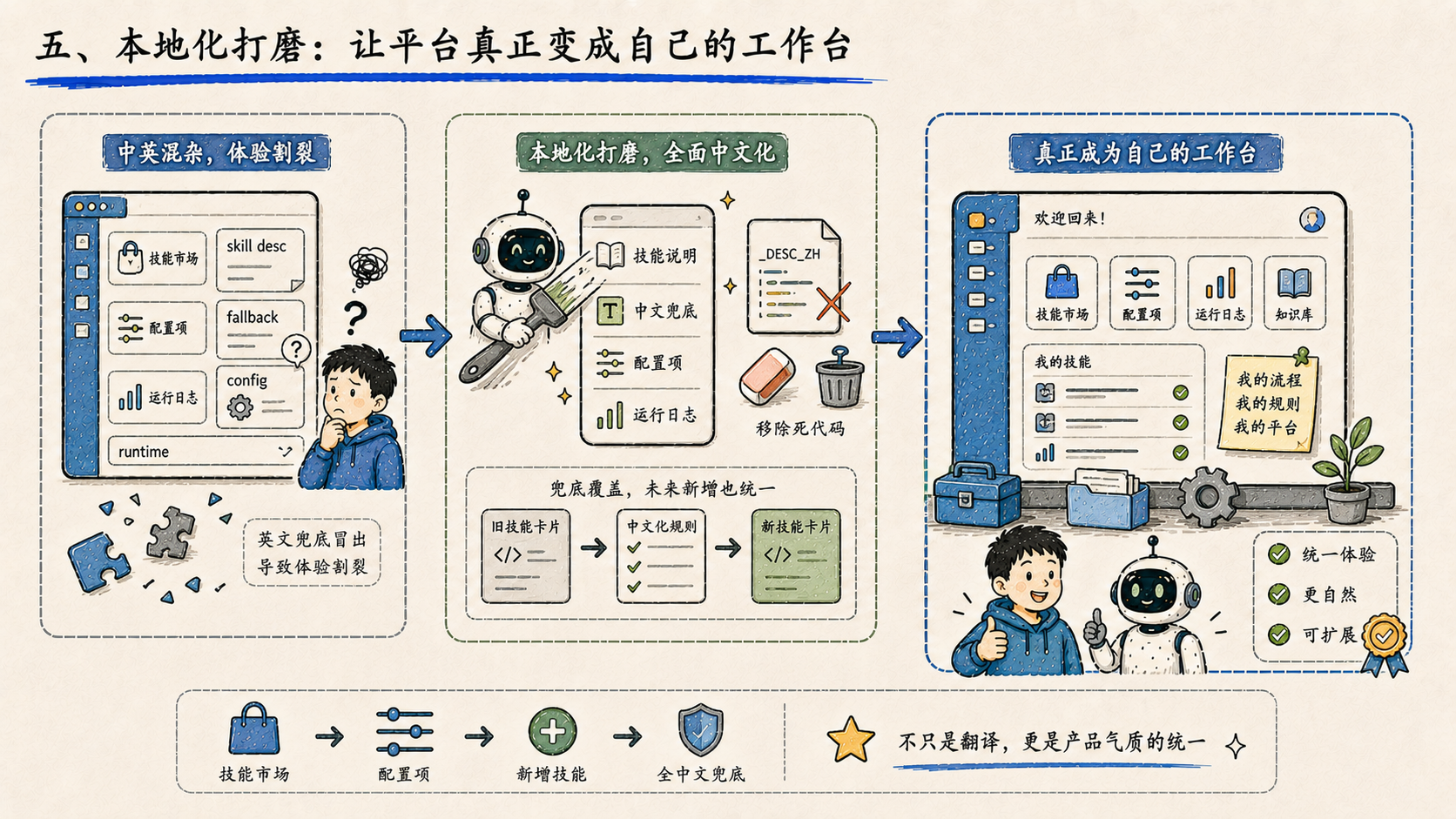
五、本地化打磨:让平台真正变成自己的工作台
技能描述全面中文化,项目技能兜底也改成了中文,同时移除了 _DESC_ZH 死代码,让本地化逻辑更干净。
这类改动看起来小,但影响产品气质。一个中文企业平台,如果技能市场、配置项里不断冒出英文兜底,会很割裂------用户会感觉这个东西还没真正变成自己的工作台。这次不只是做翻译,而是把未来新增技能的兜底逻辑也一起覆盖了。
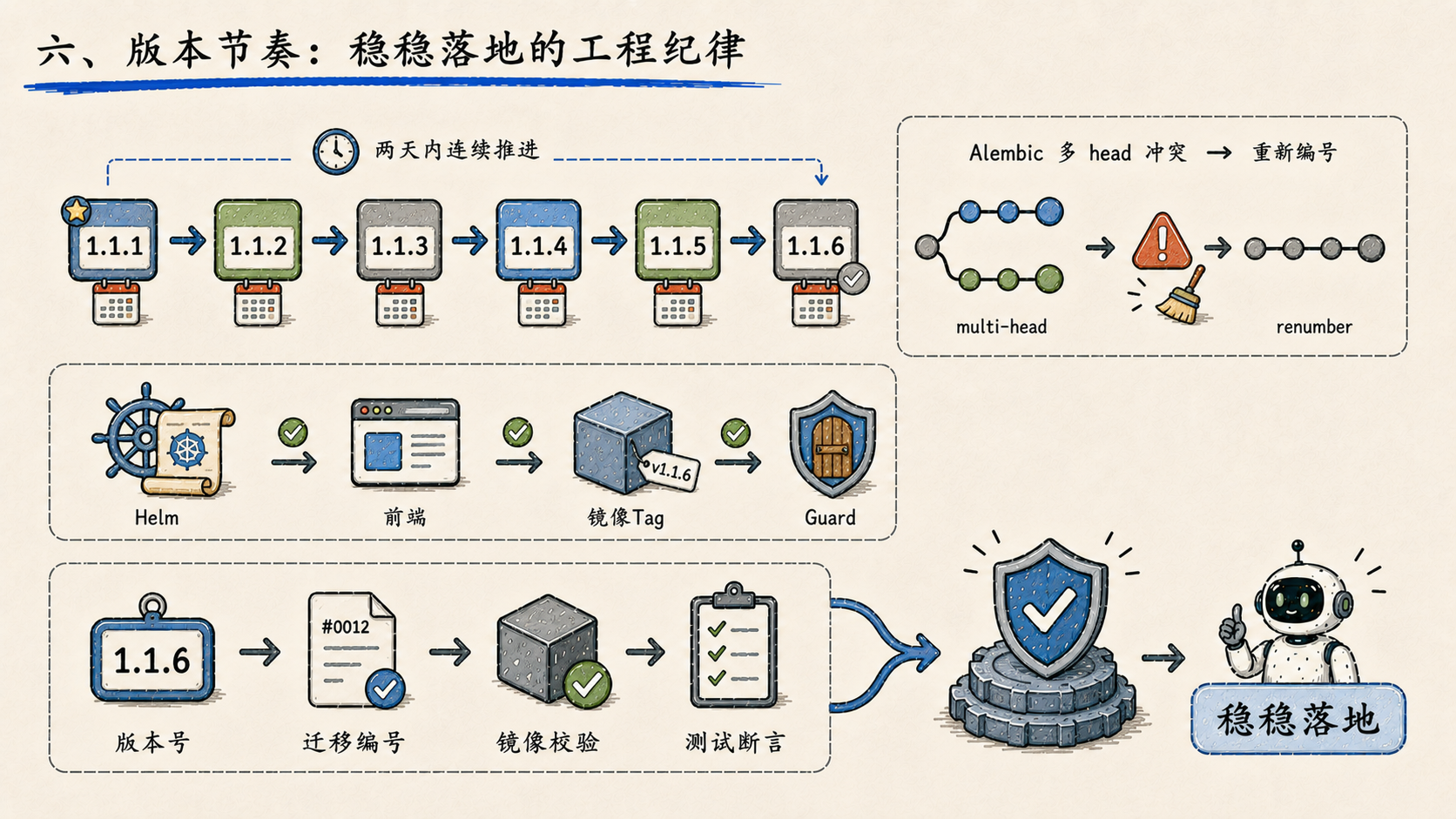
六、版本节奏:稳稳落地的工程纪律
两天内测试环境从 1.1.1 连续推进到 1.1.6,期间多次同步 Helm、前端版本号、镜像标签和 migration 守卫。动态工具的数据库迁移在 head 变化后重新编号,避免 Alembic 多 head 冲突。
很朴素,但很关键。企业级系统更多时候看的不是有没有新功能,而是变更能不能稳稳落地。版本号、迁移编号、镜像校验、测试断言------这些东西决定了平台能不能持续迭代而不把自己绊倒。
如果把这两天收成一句话:
平台不是在堆功能,而是在补企业级 AI 系统真正需要的几块骨架------工具按人授权,记忆沉淀成组织资产,工程贡献可被看见,交付代码被保护,发布链路被验证。
这是从"能用"到"可信"之间,那段最容易被忽略、但最重要的路。
有人问:这些东西用户看得见吗?
回应是:看不见。但地基就是这样,看不见它,上面什么都立不住。
这,是第三十天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。