概念导读:Pre-Training、SFT、RLHF 的关系是什么?
导读:概念解释
大家在阅读大模型相关的论文时,经常会看到将大模型训练分为 Pre-Training(预训练) 阶段和 Post-Training(后训练) 阶段:
- Pre-Training(预训练): 在 Bert 时期,这指的是 Mask 训练和相似度训练方法;在 LLMs(大语言模型)时期,指的是用连续文本对模型进行自监督训练的过程,这也是 RLHF 训练大模型的第一阶段。
- Post-Training(后训练): 在 Bert 时期通常被称为 Fine-Tuning(微调);在 LLMs 时期,Post-Training 的核心意义就是对齐(Alignment)。因此,使用强化学习训练奖励模型,以及使用全参、LoRA、数据蒸馏等方法对模型进行微调,都统称为 Post-Training 阶段的工作。
💡 补充理解:
Pre-Training 可以从两个方面来理解:
- 预训练方法: 比如 Bert 和大模型在预训练时使用的方法。
- 预训练模型: 比如 Bert 预训练模型或预训练大语言模型。但通常语境下所说的"预训练大语言模型",指的是经过强化学习对齐后的最终模型,而不仅仅是刚跑完预训练方法的"毛坯"模型。虽然训练后的大模型通常能直接适配大部分场景,但很多垂直领域仍需要用这些成熟的大模型再进行 SFT 或数据整理来定向微调。
一、Pre-Training 预训练
1.1 什么是 Pre-Training?
预训练是大模型训练的第一阶段,指的是使用大型数据集对模型进行自监督训练。其核心思想是让模型学习并掌握世界通用的规律与知识,为后续的定向优化打下坚实的基础。
- Bert 时代: 先进行 Pre-Training,再在预训练模型的基础上针对特定数据集进行 Fine-Tuning。
- 大模型时代: 必须先进行 Pre-Training,随后再进行 SFT 和 RLHF。
1.2 为什么要进行 Pre-Training?
- 学习通用知识: 预训练阶段,模型会接触海量的各类数据,这些数据包含了丰富的世界知识与常识。不同类型的任务之间往往存在通用的底层特征。这就像人类从幼儿园到高中的学习过程一样,是一个打牢基础、吸收通用知识的阶段。
- 节约计算资源: 从头训练一个复杂的深度神经网络模型需要耗费惊人的算力和时间。预训练虽然也耗时耗力,但它是基于通用数据一次性完成的。一旦预训练模型就绪,后续针对下游任务进行微调时就可以直接"站在巨人的肩膀上",大幅减少计算量。
- 加快下游任务收敛与提升泛化能力: 模型在预训练中掌握了大量的通用特征表示。当应用到下游任务时,模型无需重新学习基础语言知识,能更快适应新任务,并在面对未见过的数据时表现出更好的推理和预测能力。
1.3 怎么进行 Pre-Training?
大模型的预训练主要聚焦于海量的无标签语料,采用自监督学习。通过错位构造训练数据集,借用"下一个 token"作为标签来展开训练。其核心公式为:
L=−∑n=1Nlogp(xn∣x1,x2,...,xn−1;θ)L=-\sum_{n=1}^{N}\log p(x_{n}|x_{1},x_{2},...,x_{n-1};\theta)L=−n=1∑Nlogp(xn∣x1,x2,...,xn−1;θ)
模型依据上下文来精准预测下一个最可能的单词,通过计算预测的对数似然损失来进行连续文本的自回归预测。这个过程无需人工标注,完全借由文本自身构造监督标签,赋予模型"Generate(生成)"的能力,从而突破数据与知识的瓶颈。
二、SFT 有监督微调
2.1 什么是 SFT?
SFT(Supervised Fine-Tuning)是预训练之后的定向优化阶段。它的本质是"手把手教模型做具体的事",通过利用带标签的监督数据来调整模型,把通用能力转化为解决特定任务的能力。这是模型从"通用"走向"可用"的关键过程,也为后续的 RLHF 打下了基础。
2.2 SFT 的实现方法
SFT 需要人工整理高质量的标签来进行学习。虽然其模型结构和训练方法与预训练相似,但存在两大核心差异:
- 数据不同: Pre-Training 使用的是连续的自然文本;SFT 则需要人工梳理"问题"与"对应的答案(Response)",数据通常围绕特定任务展开。
- Loss 计算不同: 预训练需要对输入的每个 token 都计算 loss;而 SFT 一般只针对 Response(回答)部分计算 loss,无需对 Prompt(提示词/问题)部分计算 loss。
具体实现层面,可以进行全参微调,也可以采用高效微调方案(如 LoRA、QLoRA、数据蒸馏等)以少量参数撬动大型模型。
2.3 Fine-Tuning 和 SFT 有什么区别?
Fine-Tuning(微调)是一个宽泛的概念,而 SFT 则是 Fine-Tuning 的一种具体实现方式。
| 维度 | Fine-Tuning (微调) | SFT (有监督微调) |
|---|---|---|
| 数据标注情况 | 数据不一定都经过人工标注。在半监督/无监督场景中,可能会结合少量标注数据与大量无标注数据。 | 明确使用有标注的任务特定数据集,标注内容紧紧围绕特定任务展开。 |
| 训练监督方式 | 方式多样,除有监督学习外,还包括半监督、无监督微调(如利用自编码器技术学习潜在表示)。 | 采用严格的有监督学习,通过标注数据明确告诉模型输入与输出的对应关系。 |
| 适用场景和目的 | 场景更广,目的不仅是提升特定任务性能,还包括让模型适应新领域的数据分布、提高泛化能力等。 | 侧重于让预训练模型快速适配具体的下游任务,直接提升该任务的表现。 |
三、RLHF 人类反馈强化学习
3.1 什么是 RLHF?
RLHF(Reinforcement Learning with Human Feedback)是一种结合了强化学习 与人类反馈的技术,主要用于微调大模型,使其行为和价值观更符合人类的偏好与预期。
3.2 为什么要进行 RLHF?
- 弥补 SFT 的局限性: SFT 后的模型虽然能给出正确的答案,但不一定能满足个性化需求。例如,对于"如何减肥",SFT 模型可能只会机械罗列方法;而经过 RLHF 优化后,模型会朝着更受人类欢迎的方向输出,能根据潜在需求(如不想运动、时间紧迫)提供更具人情味和针对性的建议。
- 提高模型综合思考能力: 用户的需求复杂多变,固定的 SFT 标注数据难以全面覆盖。RLHF 具备动态优化能力,能根据实时的人类反馈灵活调整输出。
- 大幅提升用户体验: 即使模型准确率很高,如果回答过于冗长、生硬,体验依然会很差。RLHF 能让模型学习到交互过程中的偏好,如简洁性、友好度和时效性。
3.3 RLHF 的训练方法
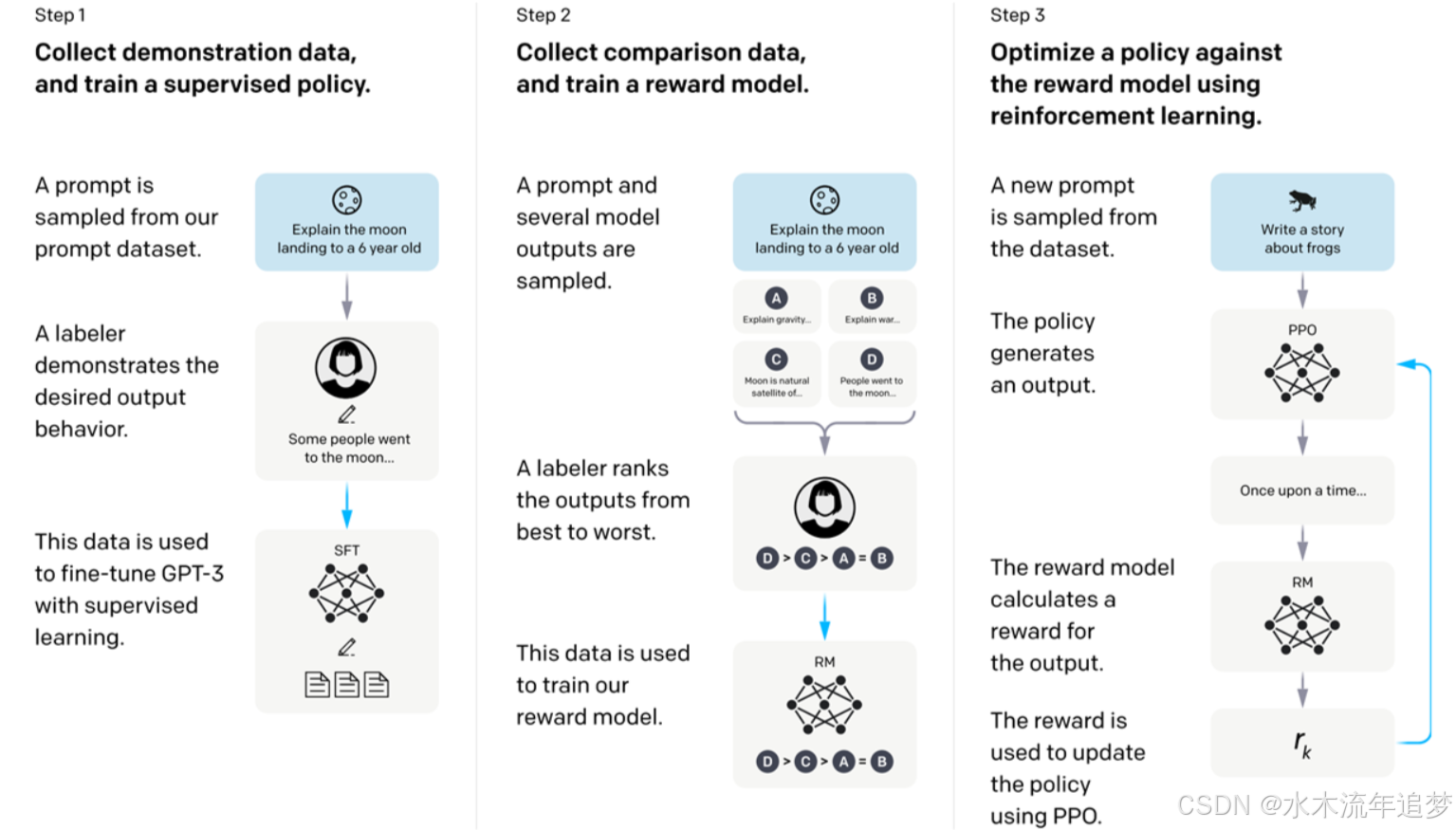
以 ChatGPT 为例,其核心使用了 PPO(近端策略优化) 方法进行训练。整个过程通常分为三步:
- 第一步: 使用 Pre-Training + SFT 训练出初始的基座模型与微调模型。
- 第二步: 训练 Reward Model(奖励模型)。收集人类对不同模型输出的偏好排序数据,训练一个能够模拟人类打分的模型。
- 第三步: 使用 PPO 强化学习方法优化语言模型。利用第二步的奖励模型作为裁判,不断指导和更新生成模型的策略。
延伸: 在基础 PPO 算法之后,目前业界又演进出了多种优化策略,例如 GRPO(组内相对策略优化)、DAPO(提高裁剪上限 & 动态采样优化策略)、GSPO(分组序列策略优化)等,进一步提升了对齐训练的效率和上限。

python
print('hello world')